Nous avons déjà écrit dans le
tout premier article de notre blog d'entreprise sur le fonctionnement de l'algorithme de détection des emprunts transférables. Seuls quelques paragraphes de cet article sont consacrés au sujet de la comparaison des textes, bien que l'idée mérite une description beaucoup plus détaillée. Cependant, comme vous le savez, on ne peut pas tout dire immédiatement, même si on le veut vraiment. Dans une tentative de rendre hommage à ce sujet et à l'architecture du réseau appelé "
auto-encoder ", auquel nous avons des sentiments très chaleureux,
Oleg_Bakhteev et moi-même avons rédigé cette critique.

Source:
Deep Learning pour PNL (sans Magic)Comme nous l'avons mentionné dans cet article, la comparaison des textes était «sémantique» - nous n'avons pas comparé les fragments de texte eux-mêmes, mais les vecteurs qui leur correspondent. Ces vecteurs ont été obtenus à la suite de la formation d'un réseau de neurones, qui affichait un fragment de texte d'une longueur arbitraire en un vecteur de grande dimension mais fixe. Comment obtenir une telle cartographie et comment enseigner au réseau à produire les résultats souhaités est une question distincte, qui sera discutée ci-dessous.
Qu'est-ce qu'un encodeur automatique?
Formellement, un réseau de neurones est appelé un auto-encodeur (ou auto-encoder), qui s'entraîne à restaurer les objets reçus à l'entrée du réseau.
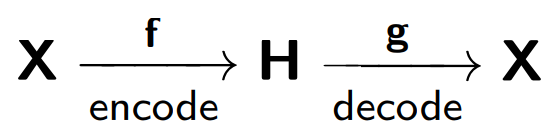
L'auto-encodeur se compose de deux parties: un encodeur
f , qui encode l'échantillon
X dans sa représentation interne
H , et un décodeur
g , qui restaure l'échantillon d'origine. Ainsi, l'autocodeur essaie de combiner la version restaurée de chaque objet exemple avec l'objet d'origine.
Lors de la formation d'un encodeur automatique, la fonction suivante est minimisée:
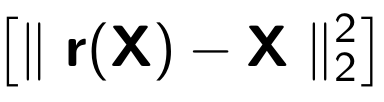
Où
r représente la version restaurée de l'objet d'origine:

Prenons l'exemple fourni dans
blog.keras.io :

Le réseau reçoit un objet
x en entrée (dans notre cas, le numéro 2).
Notre réseau code cet objet dans un état caché. Ensuite, selon l'état latent, la reconstruction de l'objet
r est restaurée, ce qui devrait être similaire à x. Comme on le voit, l'image restaurée (à droite) est devenue plus floue. Cela s'explique par le fait que nous essayons de ne garder dans une vue cachée que les signes les plus importants de l'objet, de sorte que l'objet est restauré avec des pertes.
Le modèle d'auto-encodeur est formé sur le principe d'un téléphone endommagé, où une personne (encodeur) transmet des informations
(x ) à la deuxième personne (décodeur
) , et lui, à son tour, le dit à la troisième
(r (x)) .
L'un des principaux objectifs de ces auto-encodeurs est de réduire la dimension de l'espace source. Lorsque nous avons affaire à des auto-encodeurs, la procédure d'apprentissage du réseau de neurones elle-même permet à l'auto-encodeur de se souvenir des principales caractéristiques des objets à partir desquelles il sera plus facile de restaurer les exemples d'échantillons d'origine.
Nous pouvons ici faire une analogie avec la
méthode des composantes principales : il s'agit d'une méthode de réduction de la dimension, dont le résultat est la projection de l'échantillon sur un sous-espace dans lequel la variance de cet échantillon est maximale.
En effet, l'auto-encodeur est une généralisation de la méthode du composant principal: dans le cas où l'on se limite à la considération de modèles linéaires, l'auto-encodeur et la méthode du composant principal donnent les mêmes représentations vectorielles. La différence survient lorsque nous considérons des modèles plus complexes, par exemple, des réseaux de neurones multicouches entièrement connectés, comme codeur et décodeur.
Un exemple de comparaison de la méthode des composants principaux et de l'auto-encodeur est présenté dans l'article
Réduire la dimensionnalité des données avec les réseaux de neurones :
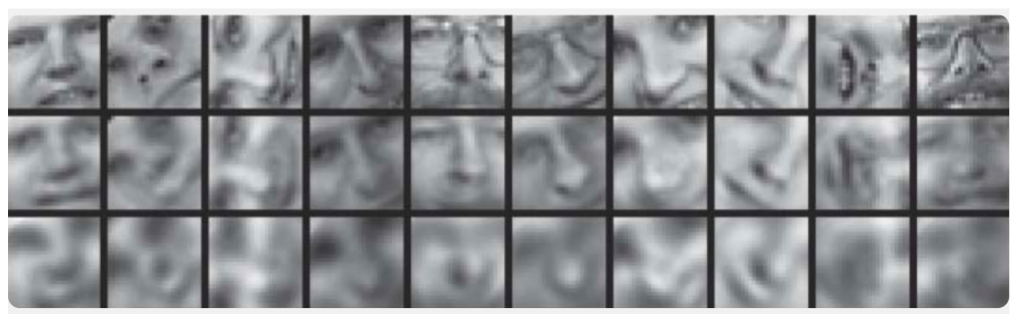
Ici, les résultats de la formation de l'auto-encodeur et de la méthode des composants principaux pour l'échantillonnage d'images de visages humains sont démontrés. La première ligne montre les visages des personnes de l'échantillon témoin, c'est-à-dire à partir d'une partie spécialement différée de l'échantillon qui n'a pas été utilisée par les algorithmes dans le processus d'apprentissage. Sur les deuxième et troisième lignes se trouvent les images restaurées des états cachés de l'auto-encodeur et de la méthode du composant principal, respectivement, de la même dimension. Ici, vous pouvez voir clairement à quel point l’encodeur automatique a fonctionné.
Dans le même article, un autre exemple illustratif: comparer les résultats de l'auto-encodeur et de la méthode
LSA pour la tâche de récupération d'informations. La méthode LSA, comme la méthode des composants principaux, est une méthode d'apprentissage automatique classique et est souvent utilisée dans les tâches liées au traitement du langage naturel.

La figure montre une projection 2D de plusieurs documents obtenus à l'aide de l'auto-encodeur et de la méthode LSA. Les couleurs indiquent le thème du document. On peut voir que la projection de l'auto-encodeur décompose bien les documents par sujet, tandis que le LSA produit un résultat beaucoup plus bruyant.
Une autre application importante des auto-
encodeurs est la pré-formation réseau . La formation préalable au réseau est utilisée lorsque le réseau optimisé est suffisamment profond. Dans ce cas, la formation du réseau «à partir de zéro» peut être assez difficile, par conséquent, tout le réseau est d'abord représenté comme une chaîne d'encodeurs.
L'algorithme de pré-formation est assez simple: pour chaque couche, nous formons notre propre codeur automatique, puis nous définissons que la sortie du codeur suivant est simultanément l'entrée pour la couche réseau suivante. Le modèle résultant se compose d'une chaîne d'encodeurs formés pour préserver avec empressement les caractéristiques les plus importantes des objets, chacune sur sa propre couche. Le programme de pré-formation est présenté ci-dessous:
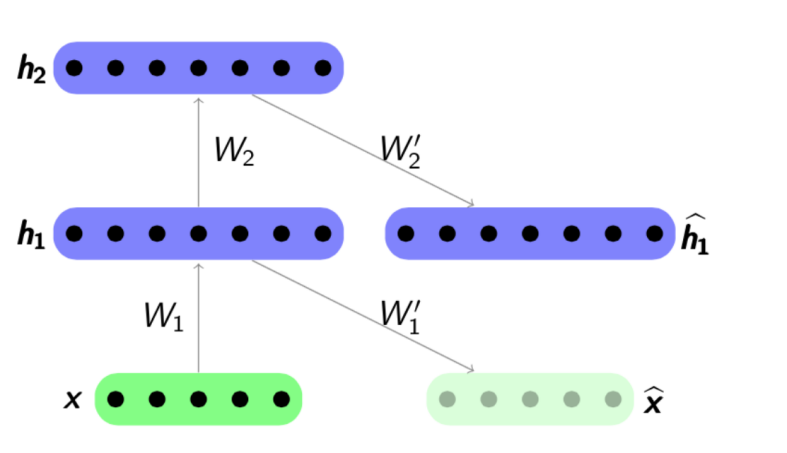
Source:
psyyz10.imtqy.comCette structure est appelée Stacked Autoencoder et est souvent utilisée comme «overclocking» pour former davantage le modèle de réseau profond complet. La motivation pour une telle formation d'un réseau de neurones est qu'un réseau de neurones profond est une fonction non convexe: dans le processus de formation d'un réseau, l'optimisation des paramètres peut «se coincer» au minimum local. Une pré-formation gourmande des paramètres réseau vous permet de trouver un bon point de départ pour la formation finale et ainsi d'éviter de tels minima locaux.
Bien sûr, nous n'avons pas considéré toutes les structures possibles, car il existe des
encodeurs automatiques clairsemés ,
des encodeurs automatiques de débruitage ,
des encodeurs automatiques contractifs ,
des encodeurs automatiques reconstructifs . Ils diffèrent entre eux en utilisant diverses fonctions d'erreur et termes de pénalité. Toutes ces architectures, à notre avis, méritent un examen séparé. Dans notre article, nous montrons tout d'abord le concept général des auto-encodeurs et les tâches spécifiques d'analyse de texte qui sont résolues en l'utilisant.
Comment ça marche dans les textes?
Nous passons maintenant à des exemples spécifiques de l'utilisation d'autocodeurs pour les tâches d'analyse de texte. Nous nous intéressons aux deux côtés de l'application - les deux modèles pour obtenir des représentations internes, et l'utilisation de ces représentations internes comme attributs, par exemple, dans le problème de classification supplémentaire. Les articles sur ce sujet abordent le plus souvent des tâches telles que l'analyse des sentiments ou la détection de reformulation, mais il existe également des travaux décrivant l'utilisation d'auto-encodeurs pour comparer des textes dans différentes langues ou pour la traduction automatique.
Dans les tâches d'analyse de texte, le plus souvent l'objet est la phrase, c'est-à-dire séquence ordonnée de mots. Ainsi, l'auto-encodeur reçoit exactement cette séquence de mots, ou plutôt des représentations vectorielles de ces mots tirées d'un modèle préalablement formé. Que sont les représentations vectorielles des mots, elle a été considérée sur Habré de manière suffisamment détaillée, par exemple
ici . Ainsi, l'auto-encodeur, en prenant une séquence de mots comme entrée, doit former une représentation interne de la phrase entière qui réponde aux caractéristiques qui sont importantes pour nous, en fonction de la tâche. Dans les problèmes d'analyse de texte, nous devons mapper des phrases à des vecteurs afin qu'ils soient proches dans le sens d'une fonction de distance, le plus souvent une mesure de cosinus:
Source:
Deep Learning pour PNL (sans Magic)Richard Socher a été l'un des premiers auteurs à montrer l'utilisation réussie des auto-encodeurs dans l'analyse de texte.
Dans son article
Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection, il décrit une nouvelle structure d'autocodage - Unfolding Recursive Autoencoder (Unfolding RAE) (voir la figure ci-dessous).

Dépliage RAE
On suppose que la structure de la phrase est définie par un
analyseur syntaxique . La structure la plus simple est considérée - la structure d'un arbre binaire. Un tel arbre se compose de feuilles - mots d'un fragment, de nœuds internes (nœuds de branche) - de phrases et d'un sommet terminal. En prenant la séquence de mots (x
1 , x
2 , x
3 ) en entrée (trois représentations vectorielles des mots dans cet exemple), l'auto-encodeur code séquentiellement, dans ce cas, de droite à gauche, les représentations vectorielles des mots de phrase en représentations vectorielles des collocations, puis en vecteur Présentation de l'ensemble de l'offre. Plus précisément dans cet exemple, nous concaténons d'abord les vecteurs x
2 et x
3 , puis les multiplions par la matrice
W e ayant la dimension
cachée × 2visible , où
caché est l'endroit où la taille de la représentation interne cachée,
visible est la dimension du mot vecteur. Ainsi, nous réduisons la dimension, puis ajoutons la non-linéarité en utilisant la fonction tanh. À la première étape, nous obtenons une représentation vectorielle cachée pour la phrase deux mots
x 2 et
x 3 :
h 1 =
tanh (W e [x 2 , x 3 ] + b e ) . Sur le second, nous le combinons avec le mot restant
h 2 =
tanh (W e [h 1 , x 1 ] + b e ) et obtenons une représentation vectorielle pour la phrase entière -
h 2 . Comme mentionné ci-dessus, dans la définition d'un encodeur automatique, nous devons minimiser l'erreur entre les objets et leurs versions restaurées. Dans notre cas, ce sont des mots. Par conséquent, après avoir reçu la représentation vectorielle finale de la phrase entière
h 2 , nous allons décoder ses versions restaurées (x
1 ', x
2 ', x
3 '). Le décodeur fonctionne ici sur le même principe que le codeur, seuls la matrice des paramètres et le vecteur de décalage sont différents ici:
W d et
b d .
En utilisant la structure d'un arbre binaire, vous pouvez encoder des phrases de n'importe quelle longueur en un vecteur de dimension fixe - nous combinons toujours une paire de vecteurs de la même dimension, en utilisant la même matrice de paramètres
W e . Dans le cas d'un arbre non binaire, il suffit d'initialiser les matrices à l'avance si l'on veut combiner plus de deux mots - 3, 4, ... n, dans ce cas la matrice aura juste la dimension
cachée × invisible .
Il est à noter que dans cet article, des représentations vectorielles entraînées de phrases sont utilisées non seulement pour résoudre le problème de classification - quelques phrases sont reformulées ou non. Les données d'une expérience sur la recherche des voisins les plus proches sont également présentées - sur la base uniquement du vecteur d'offre reçu, les vecteurs les plus proches de l'échantillon sont recherchés qui lui sont proches en termes de:

Cependant, personne ne nous dérange d'utiliser d'autres architectures de réseau pour le codage et le décodage pour combiner séquentiellement des mots en phrases.
Voici un exemple d'un article de NIPS 2017 -
Déconvolutional Paragraph Representation Learning :

Nous voyons que le codage de l'échantillon
X dans la représentation cachée
h se produit à l'aide d'un
réseau neuronal convolutionnel , et le décodeur fonctionne sur le même principe.
Ou voici un exemple d'utilisation de
GRU-GRU dans l'article
Skip-Thought Vectors .
Une caractéristique intéressante ici est que le modèle fonctionne avec des triplets de phrases: (
s i-1 , s i , s i + 1 ). La phrase
s i est codée en utilisant des formules GRU standard, et le décodeur, en utilisant les informations de représentation interne
s i , essaie de décoder
s i-1 et
s i + 1 , également en utilisant GRU.

Le principe de fonctionnement dans ce cas ressemble au modèle standard de
traduction automatique de réseau de
neurones , qui fonctionne selon le schéma codeur-décodeur. Cependant, ici nous n'avons pas deux langues, nous soumettons une phrase dans une langue à l'entrée de notre unité de codage et essayons de la restaurer. Dans le processus d'apprentissage, il y a une minimisation de certaines fonctions de qualité interne (ce n'est pas toujours une erreur de reconstruction), puis, si nécessaire, des vecteurs pré-formés sont utilisés comme caractéristiques d'un autre problème.
Un autre article,
Bilingual Correspondence Recursive Autoencoders for Statistical Machine Translation , présente une architecture qui jette un regard neuf sur la traduction automatique. Premièrement, pour deux langues, les autocodeurs récursifs sont formés séparément (selon le principe décrit ci-dessus - où le déploiement du RAE a été introduit). Ensuite, entre eux, un troisième auto-encodeur est formé - une cartographie entre deux langues. Une telle architecture présente un avantage évident: lors de l'affichage de textes dans différentes langues dans un espace caché commun, nous pouvons les comparer sans utiliser la traduction automatique comme étape intermédiaire.
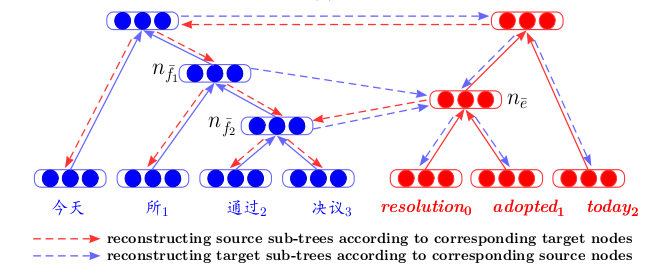
La formation des auto-encodeurs sur les fragments de texte se retrouve souvent dans les articles sur la
formation au classement . Là encore, le fait que nous formions la fonction finale de la qualité du classement est important, nous pré-formons d'abord l'auto-encodeur pour mieux initialiser les vecteurs de requêtes et réponses soumises à l'entrée du réseau.

Et, bien sûr, nous ne pouvons pas ne pas mentionner les
encodeurs automatiques variationnels , ou
VAE , comme modèles génératifs. Bien sûr, il est préférable de simplement regarder
cette entrée de conférence de Yandex . Il nous suffit de dire ce qui suit: si nous voulons
générer des objets à partir de l'espace caché d'un encodeur automatique conventionnel, alors la qualité de cette génération sera faible, car nous ne savons rien de la distribution de la variable cachée. Mais vous pouvez immédiatement entraîner l'auto-encodeur à générer, en introduisant une hypothèse de distribution.
Et puis, à l'aide de VAE, vous pouvez générer des textes à partir de cet espace caché, par exemple, comme le font les auteurs de l'article
Génération de phrases à partir d'un espace continu ou
Un autoencodeur variationnel convolutionnel hybride pour la génération de texte .
Les propriétés génératives de la VAE fonctionnent également bien dans les tâches de comparaison de textes dans différentes langues -
Une approche de codage automatique variationnel pour induire des incorporations de mots multilingues en est un excellent exemple.
En conclusion, nous voulons faire une petite prévision.
Apprentissage par la représentation - la formation aux représentations internes utilisant exactement la VAE, en particulier en conjonction avec les
réseaux adversaires génératifs , est l'une des approches les plus développées ces dernières années - cela peut être jugé par au moins les sujets d'articles les plus courants lors des dernières
conférences d' apprentissage machine de l'
ICLR 2018 et
ICML 2018 . C'est tout à fait logique - car son utilisation a contribué à améliorer la qualité dans un certain nombre de tâches, et pas seulement en rapport avec les textes. Mais c'est le sujet d'une revue complètement différente ...