Institut de technologie du Massachusetts. Cours magistral # 6.858. "Sécurité des systèmes informatiques." Nikolai Zeldovich, James Mickens. 2014 année
Computer Systems Security est un cours sur le développement et la mise en œuvre de systèmes informatiques sécurisés. Les conférences couvrent les modèles de menace, les attaques qui compromettent la sécurité et les techniques de sécurité basées sur des travaux scientifiques récents. Les sujets incluent la sécurité du système d'exploitation (OS), les fonctionnalités, la gestion du flux d'informations, la sécurité des langues, les protocoles réseau, la sécurité matérielle et la sécurité des applications Web.
Cours 1: «Introduction: modèles de menace»
Partie 1 /
Partie 2 /
Partie 3Conférence 2: «Contrôle des attaques de pirates»
Partie 1 /
Partie 2 /
Partie 3Conférence 3: «Débordements de tampon: exploits et protection»
Partie 1 /
Partie 2 /
Partie 3Conférence 4: «Séparation des privilèges»
Partie 1 /
Partie 2 /
Partie 3 Alors qu'avions-nous d'autre sur cette liste? Processus. La mémoire est quelque chose qui se produit simultanément avec le processus. Ainsi, si vous n'êtes pas dans ce processus, vous ne pouvez pas accéder à sa mémoire. La mémoire virtuelle améliore parfaitement cet isolement pour nous. De plus, le mécanisme de débogage vous permet de "pop" dans la mémoire d'un autre processus, si vous avez le même ID utilisateur
Ensuite, nous avons le réseau. Les réseaux sous
Unix ne correspondent pas tout à fait au modèle décrit ci-dessus, en partie du fait que le
système d' exploitation
Unix a d'abord été développé, puis un réseau est apparu, qui est rapidement devenu populaire. Il a un ensemble de règles légèrement différent. Par conséquent, les opérations dont nous devons vraiment nous occuper sont de connecter quelqu'un au réseau si vous gérez le réseau ou d'écouter un port si vous agissez en tant que serveur. Vous devrez peut-être lire ou écrire des données sur cette connexion, ou envoyer et recevoir
des paquets
bruts .

Ainsi, les réseaux sous
Unix sont pour la plupart sans rapport avec l'
ID utilisateur . Les règles sont que n'importe qui peut toujours se connecter à n'importe quelle machine ou n'importe quelle adresse IP ou ouvrir une connexion. Si vous voulez écouter sur un port, alors dans ce cas il y a une différence, c'est que la plupart des utilisateurs sont interdits d'écouter des ports avec un nombre inférieur à la «valeur magique» de 1024. En principe, vous pouvez écouter de tels ports, mais dans ce cas, vous devriez Soyez un utilisateur spécial appelé
"super utilisateur" avec
uid = 0 .
En général, sous Unix, il y a le concept d'administrateur, ou de superutilisateur, qui est représenté par l'identifiant uid = 0, qui peut contourner presque toutes ces vérifications, donc si vous travaillez avec des droits root, vous pouvez lire et écrire des fichiers, changer les droits d'accès pour eux. Le système d'exploitation vous permettra de le faire car il pense que vous devriez avoir tous les privilèges. Et vous avez vraiment besoin de tels privilèges pour écouter sur les ports avec un nombre <1024. Que pensez-vous d'une restriction aussi étrange?
Public: il identifie des numéros de port spécifiques pour des connexions spécifiques, par exemple, pour
http sur le port 80.
Professeur: oui, par défaut le
protocole HTTP utilise le port 80. En revanche, d'autres services peuvent utiliser des ports avec un nombre supérieur à 1024, pourquoi cette restriction est-elle nécessaire? Quelle est l'utilité ici?
Public: parce que vous ne voulez pas que quelqu'un écoute accidentellement votre
HTTP .
Professeur: oui. Je pense que la raison en est que vous aviez auparavant de nombreux utilisateurs sur la même machine. Ils se sont connectés avec leurs identifiants de connexion, ont lancé leurs applications, vous vouliez donc vous assurer qu'un utilisateur aléatoire, s'étant connecté à l'ordinateur, ne pourrait pas mettre la main sur le serveur Web en cours d'exécution. Parce que les utilisateurs se connectant de l'extérieur ne savent pas qui travaille sur ce port, et ils se connectent simplement au port 80. Si je veux entrer dans cette machine et démarrer mon propre serveur Web, je transfère simplement tout le trafic du serveur Web vers cette voiture. Ce n'est probablement pas un très bon plan, mais c'est la façon dont le sous-système réseau Unix empêche les utilisateurs aléatoires de contrôler les services connus s'exécutant sur ces numéros de port bas. Telle est la justification d'une telle limitation.

De plus, du point de vue de la lecture et de l'écriture des données de connexion, si vous avez un fichier descripteur pour un socket spécifique,
Unix vous permettra de lire et d'écrire toutes les données de cette
connexion TCP ou
uTP . Lors de l'envoi
de paquets
bruts ,
Unix se comporte comme un paranoïaque, il ne vous permettra donc pas d'envoyer des paquets arbitraires sur le réseau. Cela devrait être dans le contexte de la connexion spéciale, sauf si vous avez
root - le droit et vous pouvez faire ce que vous voulez.
Donc, une question intéressante que vous pourriez poser est d'où viennent tous ces
ID utilisateur ?
Nous parlons de processus ayant
userid ou
groupid . Lorsque vous lancez
PS sur votre ordinateur, vous verrez certainement une série de processus avec différentes valeurs
uid . D'où venaient-ils?
Nous avons besoin d'un mécanisme pour charger toutes ces valeurs d'
ID utilisateur .
Unix a plusieurs appels système conçus pour cela. Par conséquent, pour amorcer ces valeurs d'identificateur, il existe une fonction appelée
setuid (uid) , vous pouvez donc attribuer le numéro
uid d'un processus en cours à cette valeur. C'est en fait une opération dangereuse, comme tout le reste dans la tradition
Unix , car vous ne pouvez le faire que si votre
uid = 0 . En tout cas, il devrait en être ainsi.
Ainsi, si vous êtes un utilisateur avec des droits root et que
uid = 0 , vous pouvez appeler
setuid (uid) et basculer l'utilisateur vers n'importe quel processus. Il existe quelques autres appels système similaires pour initialiser le
gid lié au processus: ce sont
setgid et
setgroups . Par conséquent, ces appels système vous permettent de configurer les privilèges de processus.

Le fait que vos processus obtiennent les droits d'accès corrects lorsque vous vous connectez à la machine
Unix ne se produit pas car vous avez le même
ID que les processus, car le système ne sait pas encore qui vous êtes. Au lieu de cela, sous
Unix, il existe une sorte de procédure de connexion lorsque le
protocole de shell sécurisé
SSH démarre le processus pour quiconque se connecte à l'ordinateur et essaie d'authentifier l'utilisateur.
Ainsi, initialement, ce processus de connexion commence par
uid = 0 comme pour un utilisateur avec des droits root, puis, lorsqu'il reçoit un nom d'utilisateur et un mot de passe spécifiques, il les vérifie dans sa propre base de données de comptes. Généralement, sous
Unix, ces données sont stockées dans deux fichiers:
/ etc / password (pour des raisons historiques, les mots de passe ne sont plus stockés dans ce fichier) et dans le fichier
/ etc / shadow , dans lequel les mots de passe sont stockés. Cependant, il existe une table dans le fichier
/ etc / password qui affiche chaque nom d'utilisateur dans le système sous forme de valeur entière.
Ainsi, votre nom d'utilisateur est mappé à un entier spécifique dans ce fichier
/ etc / password , puis le processus de connexion vérifie si votre mot de passe est correct en fonction de ce fichier. S'il trouve votre
uid entier, il définit les fonctions
setuid sur cette valeur
uid et démarre le shell avec la commande
exec (/ bin / sh) . Vous pouvez maintenant interagir avec le shell, mais cela fonctionne sous votre
UID , vous ne pourrez donc pas endommager accidentellement cette machine.
 Public: est-
Public: est- il possible de démarrer un nouveau processus avec
uid = 0 si votre
uid n'est pas vraiment 0?
Professeur: si vous avez des privilèges root, vous pouvez vous limiter à un autre
uid , réduire votre autorité, mais dans tous les cas, vous pouvez créer un processus avec uniquement le même
uid que le vôtre. Mais il arrive que pour diverses raisons vous souhaitiez augmenter vos privilèges. Supposons que vous devez installer un package pour lequel vous avez besoin
des privilèges
root .
Il existe deux façons de définir des privilèges sur
Unix . Celui que nous avons déjà mentionné est un descripteur de fichier. Donc, si vous voulez vraiment augmenter vos privilèges, vous pouvez parler à quelqu'un qui travaille sous les droits root et lui demander d'ouvrir ce fichier pour vous. Ou vous devez installer une nouvelle interface, puis cet assistant ouvre un fichier pour vous et vous renvoie un descripteur de fichier en utilisant le transfert
fd . C'est une façon d'augmenter vos privilèges, mais cela n'est pas pratique car dans certains cas, des processus s'exécutent avec un grand nombre de privilèges. Pour cela,
Unix a un mécanisme intelligent mais en même temps problématique appelé
"binaires setuid" . Ce mécanisme est un exécutable standard sur un
système de fichiers
Unix , sauf lorsque vous exécutez
exec sur le binaire
setuid , par exemple,
/ bin / su sur la plupart des machines, ou
sudo , au démarrage.
Un système
Unix typique a un tas de binaires
setuid . La différence est que lorsque vous exécutez l'un de ces binaires, il bascule réellement l'
ID utilisateur du processus vers le propriétaire de ce binaire. Ce mécanisme semble étrange lorsque vous le voyez pour la première fois. En règle générale, les façons de l'utiliser sont que ce «binaire» a très probablement un
UID de propriétaire
de 0, car vous voulez vraiment restaurer de nombreux privilèges.

Vous voulez restaurer les droits de superutilisateur afin que vous puissiez exécuter cette commande
su , et le noyau, lorsque vous exécutez ce binaire, basculera l'
uid du processus sur 0, de sorte que ce programme effectuera maintenant certaines choses privilégiées.
Public: si vous avez
uid = 0 et que vous changez l'
uid de tous ces binaires
setuid en autre chose que 0, pouvez-vous restaurer vos privilèges?
Professeur: non, de nombreux processus ne pourront pas restaurer les privilèges lors de la baisse du niveau d'accès, vous pouvez donc être bloqué à cet endroit. Ce mécanisme n'est pas lié à
uid = 0 . Comme tout utilisateur d'un système
Unix , vous pouvez créer n'importe quel fichier binaire, créer un programme, le compiler et définir ce bit
setuid sur le programme lui-même. Il vous appartient, l'utilisateur, votre ID utilisateur. Et cela signifie que toute personne qui exécute votre programme exécutera ce code avec votre ID utilisateur. Y a-t-il un problème avec cela? Que faut-il faire?
Public: c'est-à-dire, s'il y a eu une erreur dans votre candidature, quelqu'un pourrait-il en faire quoi que ce soit, en agissant avec vos privilèges?
Professeur: c'est vrai, cela arrive si mon application est "buggy", ou si elle vous permet d'exécuter tout ce que vous voulez. Supposons que je puisse copier le shell du système et le configurer pour moi, mais n'importe qui peut exécuter ce shell sous mon compte. Ce n'est probablement pas le meilleur plan d'action. Mais un tel mécanisme ne crée pas de problème, car la seule personne qui peut définir le bit
setuid sur un fichier binaire est le propriétaire de ce fichier. En tant que propriétaire du fichier, vous disposez du privilège
uid , vous pouvez donc transférer votre compte à une autre personne, mais cette autre personne ne pourra pas créer le binaire
setuid avec votre
ID utilisateur .
Ce bit setuid est stocké à côté de ces bits d'autorisation, c'est-à-dire que dans chaque
inode il y a aussi un bit
setuid qui indique si ce fichier exécutable devrait ou si le programme est passé à l'
uid du propriétaire pendant l'exécution.
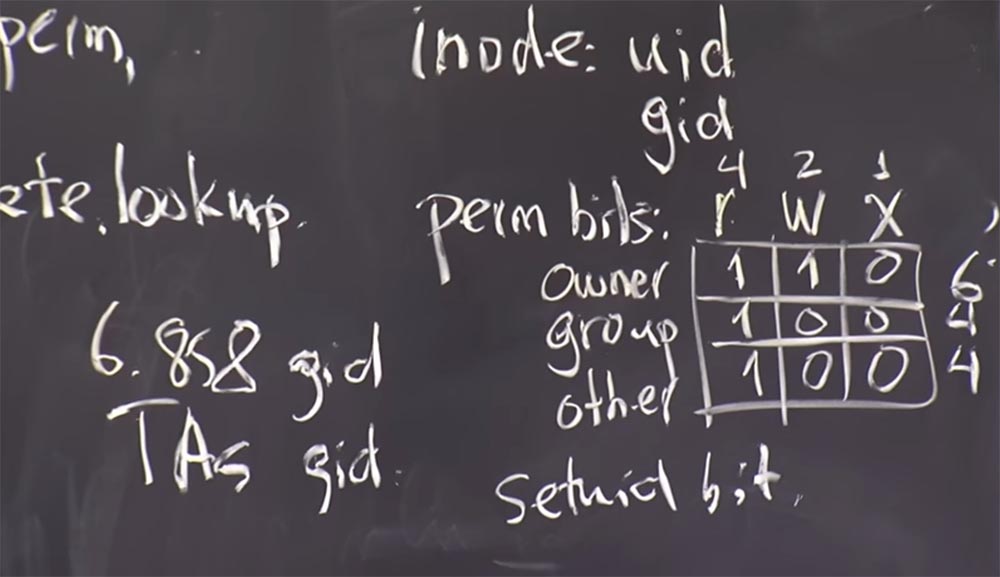
Il s'avère que c'est un mécanisme très délicat lorsqu'il est utilisé correctement, et grâce à lui, le noyau implémente le programme correctement. En fait, c'est assez facile à faire, car une seule vérification est effectuée: si ce bit
setuid existe, le processus passe à
uid . C'est assez simple.
Mais l'utiliser en toute sécurité est assez difficile, car, comme cela vient d'être indiqué, si ce programme contient des erreurs ou fait quelque chose d'inattendu, vous avez la possibilité de faire des choses arbitraires sous
uid = 0 ou sous tout autre
uid . Sous
Unix, lorsque vous exécutez un programme, vous héritez de beaucoup de choses de votre processus parent.
Par exemple, vous pouvez transmettre des variables d'environnement aux binaires
setuid . Le fait est que sous
Unix, vous pouvez spécifier la bibliothèque partagée à utiliser pour le processus en définissant la variable d'environnement, et les binaires
setuid ne se soucient pas de filtrer ces variables d'environnement.
Par exemple, vous pouvez exécuter
bin / su , mais utiliser des bibliothèques partagées pour la fonction
printf , afin que votre
printf démarre lorsque
bin / su imprime quelque chose, et vous pouvez exécuter le shell au lieu de printingf.
Il y a beaucoup de subtilités que vous devez comprendre correctement concernant la méfiance du programme envers les données que l'utilisateur entre. Parce que vous faites généralement confiance aux entrées utilisateur,
setuid n'a jamais été la partie la plus sûre d'un système
Unix complet. Vous avez des questions à ce sujet?
Public: setuid s'applique-t-il également aux groupes ou uniquement à l'utilisateur?
Professeur: il y a un bit
setgid symétrique au bit
setuid , que vous pouvez également régler. Si le fichier a un
gid spécifique et que ce bit
setgid est défini au démarrage du programme, vous l'obtiendrez.
Setgid n'est pas particulièrement utilisé, mais peut être utile dans les cas où vous souhaitez fournir des privilèges très spécifiques. Par exemple,
bin / su a probablement besoin de beaucoup de privilèges, mais il y a peut-être un programme qui a besoin de quelques privilèges supplémentaires, par exemple, pour écrire quelque chose dans un fichier journal spécial. Par conséquent, vous souhaiterez probablement lui fournir un certain groupe et créer un fichier journal pour elle qui sera accessible en écriture par ce groupe. Donc, même si le programme est «buggé», vous ne perdrez rien d'autre que ce groupe. Ceci est utile comme mécanisme qui, pour une raison quelconque, n'est pas utilisé trop souvent, car après tout, les gens devraient utiliser davantage les droits root.
Public: Existe-t-il des restrictions quant à qui peut modifier l'accès?
Professeur: oui. Différentes implémentations
Unix ont des vérifications différentes pour cela. La règle générale est que seul root peut changer le propriétaire du fichier, car vous ne voulez pas créer de fichiers qui appartiendront à quelqu'un d'autre et bien sûr vous ne voulez pas vous approprier les fichiers d'autres personnes. Donc, si votre
UID n'est pas 0, alors vous êtes coincé. Vous ne pouvez pas modifier la propriété d'un fichier. Si votre
uid = 0 , vous avez des privilèges root et vous pouvez changer le propriétaire en n'importe qui. Il y a quelques complications si vous avez un
setuid binaire et que vous passez d'un
uid à un autre, c'est assez délicat, mais en gros vous ne pouvez pas changer le propriétaire du fichier si vous n'avez pas les privilèges root.
Par tous les comptes, c'est un système légèrement dépassé. Vous pourriez probablement imaginer de nombreuses façons de simplifier les processus décrits ci-dessus, mais en fait, la plupart des systèmes avancés ressemblent à ceci car ils évoluent avec le temps. Mais vous pouvez parfaitement utiliser ces mécanismes comme un "bac à sable".
Ce ne sont que des principes de base d'
Unix , qui apparaissent dans presque tous les systèmes d'exploitation de type Unix:
Mac OS X ,
Linux ,
FreeBSD ,
Solaris , si quelqu'un d'autre l'utilise, etc. Mais chacun de ces systèmes possède des mécanismes plus sophistiqués que vous pourriez utiliser. Par exemple, sous
Linux, il existe un ensemble «bac à sable»
COMP ,
Mac OS X utilise la
ceinture de sécurité «bac à sable». La semaine prochaine, je vous donnerai des exemples de bacs à sable disponibles sur chaque système basé sur
Unix .
Ainsi, l'un des derniers mécanismes, que nous examinerons avant de plonger dans
OKWS , explique comment vous devez gérer les binaires
setuid et montre comment vous protéger contre les failles de sécurité existantes. Le problème est que vous aurez inévitablement des binaires
setuid sur votre système, comme
/ bin / su , ou
sudo , ou autre chose, et il est probable que vos programmes auront des erreurs. Pour cette raison, quelqu'un pourra exécuter le binaire
setuid et le processus pourra accéder à la
racine , ce que vous ne voulez pas autoriser.

Le mécanisme
Unix , qui est souvent utilisé pour empêcher l'exécution d'un processus potentiellement malveillant à l'aide de binaires
setuid , consiste à utiliser l'espace de noms du système de fichiers pour le modifier à l'aide de l'appel système
chroot , l'opération de modification du répertoire racine.
OKWS , en tant que serveur Web spécialisé dans la création de services Web rapides et sécurisés, l'utilise assez largement.

Donc, sous
Unix, vous pouvez exécuter
chroot dans un répertoire spécifique, vous pouvez donc peut-être aussi exécuter
chroot ("/ foo") .
Il y a 2 explications pour ce que fait
chroot . Le premier est simplement intuitif, cela signifie qu'après avoir exécuté
chroot , le répertoire racine ou le répertoire situé derrière la barre oblique est fondamentalement équivalent à ce que
/ foo a utilisé avant d'appeler
chroot . Cela ressemble à limiter l'espace de noms sous votre
/ foo . Par conséquent, si vous avez un fichier qui s'appelait auparavant
/ foo / x , après avoir appelé
chroot, vous pouvez obtenir ce fichier simplement en ouvrant
/ x . Limitez donc votre espace de noms à un sous-répertoire. Voici ce qu'est la version intuitive.

Bien sûr, en matière de sécurité, ce n'est pas la version intuitive qui compte, mais que fait exactement le noyau avec cet appel système? Et cela fait essentiellement deux choses. Tout d'abord, il change la valeur de cette barre oblique, donc chaque fois que vous accédez ou lorsque vous démarrez le nom du répertoire avec une barre oblique, le noyau inclut tout fichier que vous avez fourni avec des opérations
chroot . Dans notre exemple, il s'agit du fichier
/ foo avant d'appeler
chroot , c'est-à-dire que nous obtenons ce
/ = / foo .

La prochaine chose que le noyau essaiera de faire est de vous empêcher de "vous échapper" de votre
/ si vous le faites
/../ . Parce que sur
Unix, je pourrais vous demander de me donner, par exemple,
/../etc/password . Donc, si je venais de compléter cette ligne comme ceci:
/foo/../etc/password , ce ne serait pas bien, car je pourrais simplement quitter
/ foo et continuer pour obtenir
/ etc / password .
La deuxième chose que le noyau fait avec un appel système
Unix est que lorsque vous appelez
chroot pour ce processus particulier, il change la façon dont
/../ est évalué dans ce répertoire. Par conséquent, il modifie
/../ afin que
/ foo pointe vers lui-même. Ainsi, cela ne vous permet pas de «vous échapper», et ce changement ne s'applique qu'à ce processus et n'affecte pas le reste. Quelles idées avez-vous sur la façon de «s'échapper» de l'environnement
chroot en utilisant la façon dont il est mis en œuvre?
Fait intéressant, le noyau ne surveille qu'un seul répertoire
chroot , vous pouvez donc probablement effectuer l'opération
chroot = (/ foo) , mais vous seriez coincé à cet endroit. Vous voulez donc obtenir
/ etc / password , mais comment faire? Vous pouvez maintenant ouvrir le répertoire racine en tapant
open (* / *) . Cela vous donnera un descripteur de fichier décrivant ce qu'est
/ foo . Ensuite, vous pouvez à nouveau appeler
chroot et exécuter
chroot (`/ bar) .

, :
root /foo ,
/foo/bar /../ /foo / bar/..
,
/foo .
fchdir (fd) (*/*) ,
chdir (..) .

 /foo
/foo ,
/../ .
/foo ,
root , .
, , . .
Unix root-
chroot ,
chroot . ,
Unix uid = 0 ,
chroot . . , ,
chroot ,
userid . ,
Unix , ,
root , .
, , , .
chroot — . .
: ,
inod , ?
: ! , , , : «
inode 23», -
hroot . ,
Unix inode inode , , , root-.
, , ,
OKWS . ,
OKWS .
, -, , - , . , ,
httpd , ,
Apache .
userid www /etc/password . , ,
SSL ,
PHP , . , , ,
MySQL , .
MySQL .
MySQL , , , .
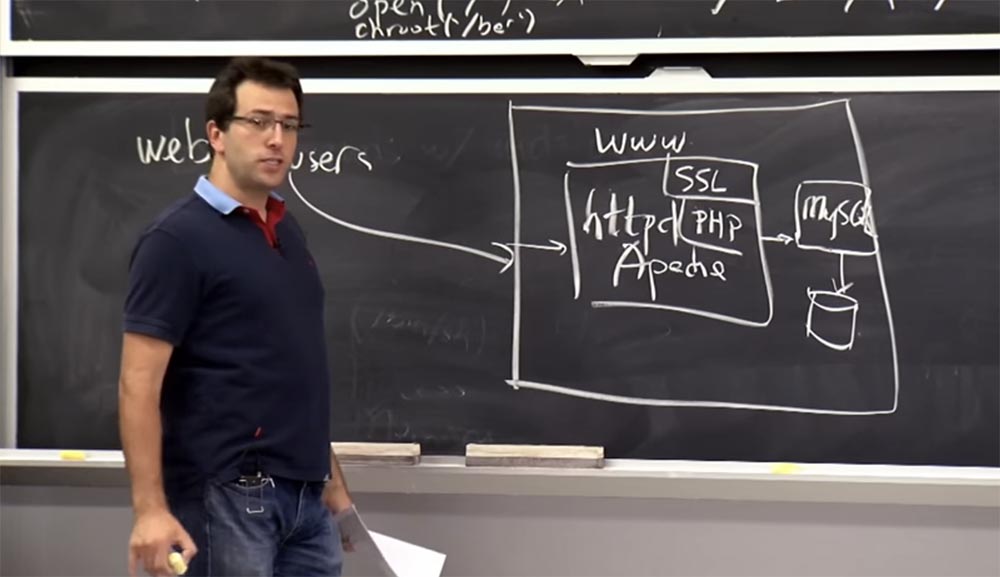
, , ,
MySQL , , .
, , , , . , , ,
Apache , ou en SSL , ou peut-être dans le code d'application ou dans l'interpréteur PHP . Et comme il y a des erreurs, vous pouvez les utiliser pour obtenir l'intégralité du contenu de l'application.52:30 minSuite:Cours MIT "Sécurité des systèmes informatiques". Conférence 4: «Partager les privilèges», partie 2La version complète du cours est disponible ici .Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?