Institut de technologie du Massachusetts. Cours magistral # 6.858. "Sécurité des systèmes informatiques." Nikolai Zeldovich, James Mickens. 2014 année
Computer Systems Security est un cours sur le développement et la mise en œuvre de systèmes informatiques sécurisés. Les conférences couvrent les modèles de menace, les attaques qui compromettent la sécurité et les techniques de sécurité basées sur des travaux scientifiques récents. Les sujets incluent la sécurité du système d'exploitation (OS), les fonctionnalités, la gestion du flux d'informations, la sécurité des langues, les protocoles réseau, la sécurité matérielle et la sécurité des applications Web.
Cours 1: «Introduction: modèles de menace»
Partie 1 /
Partie 2 /
Partie 3Conférence 2: «Contrôle des attaques de pirates»
Partie 1 /
Partie 2 /
Partie 3Conférence 3: «Débordements de tampon: exploits et protection»
Partie 1 /
Partie 2 /
Partie 3Conférence 4: «Séparation des privilèges»
Partie 1 /
Partie 2 /
Partie 3 Ainsi, notre dessin représente une «œuvre d'art», que ses créateurs ont essayé de protéger contre les menaces. Dans leur cas, je pense qu'ils étaient très inquiets, car en créant le
site de rencontres
okcupid.com , ils voulaient vraiment s'assurer que la réputation des utilisateurs du site ne serait pas affectée par la divulgation des données personnelles. D'après une conversation avec l'un des développeurs du site qui a écrit l'article à ce sujet, il est connu qu'ils n'ont pas été réellement compromis. Au moins, aucune fuite de données due à l'utilisation de l'architecture
OKWS et en partie due à la surveillance d'activités malveillantes ne s'est produite.
La raison pour laquelle les gens ne décomposent pas leurs applications en composants plus petits est que ce processus demande un certain effort. Il est nécessaire de sélectionner toutes les parties du code, de définir des interfaces claires entre elles et de décider à quelles données chaque composant doit avoir accès. Si vous décidez d'implémenter une nouvelle fonction, vous devrez modifier les données auxquelles chaque composant du programme a accès, lui donner de nouveaux privilèges ou en sélectionner, etc. C'est donc un processus assez long.

Essayons de comprendre comment le serveur Web est conçu, et peut-être une façon de le faire est de suivre comment la demande http est traitée par le serveur
OKWS . Donc, semblable à celui montré dans la figure précédente, nous avons un navigateur Web qui veut aller sur
okcupid.com . Les développeurs du projet de site ont imaginé qu'ils auraient un tas de machines, mais nous ne regarderons que l'interface du site où
OKWS fonctionnera, et une autre machine en arrière-plan qui stockera la base de données. Cette deuxième machine utilise
MySQL car c'est un bon logiciel pour de nombreuses tâches. Ils veulent vraiment protéger ces données car il est vraiment difficile d'accéder à un disque
brut ou à une base de données avec des datagrammes bruts bruts.
Alors, comment fonctionne la demande, comment la demande est-elle traitée par le serveur
OKWS ? Tout d'abord, il arrive et est traité par un processus appelé
okd pour le répartiteur
OKWS . Il vérifie qu'il demande cette demande, puis fait deux ou trois choses. Comme vous devrez peut-être d'abord enregistrer cette demande, il la redirige vers un composant appelé
oklogd , après quoi vous devrez créer des modèles, et il peut être nécessaire de les créer avant même que la demande n'arrive. Et il fait un autre composant appelé
pubd .
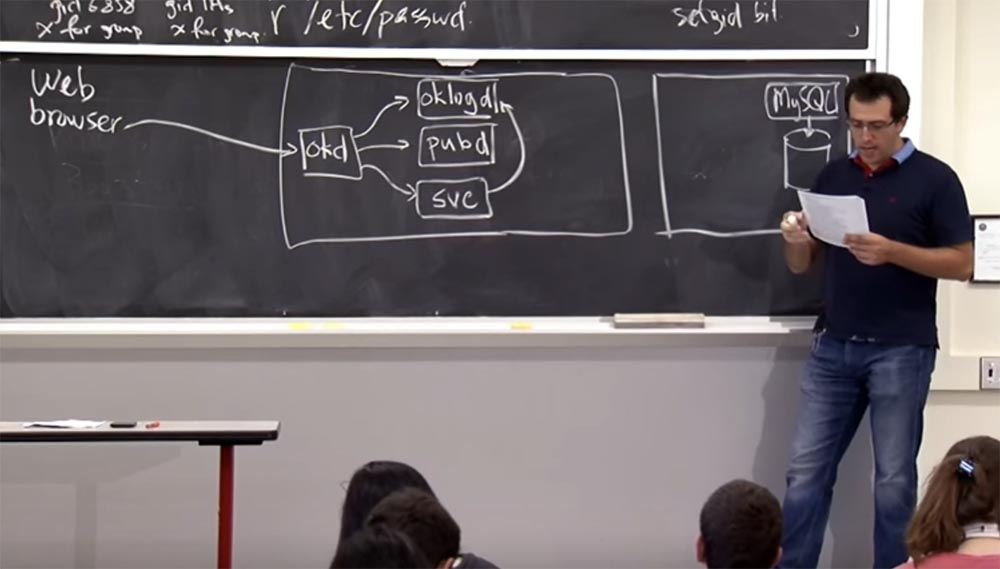
Et enfin, il y a un service spécifique auquel cette demande est envoyée, donc dans
okd il y a un tableau de l'ensemble des services qu'il prend en charge. Vraisemblablement, cette demande vient à l'un de ces services, donc après avoir examiné
okd redirigera cette demande vers un processus de service
svc spécifique. Ce service fera exactement ce que la demande requiert, par exemple, abonner l'utilisateur à la newsletter, ou permettre de visualiser l'annuaire des utilisateurs d'
ocupid , en utilisant la base de données, etc.
Et pour cela, vous avez probablement besoin du service pour laisser les informations d'application dans le
journal des composants
oklogd . Et à la fin de la journée, il devrait "parler" à la base de données. Les créateurs du site ont implémenté ce processus de «communication» un peu différemment de ce qui se passe habituellement dans
Apache , où vous communiquez simplement avec la base de données et émettez
des requêtes
SQL arbitraires. Ils ont proposé ce concept de proxy de base de données,
dbproxy , qui est situé en face de la
base de données MySQL et accepte les demandes du service
svc pour les exécuter. Je pense que cette illustration montre essentiellement comment fonctionne
OKWS .

Il y a un autre composant qui initie tout cela, il s'appelle
okld , et il est responsable du démarrage de tous les processus dans l'interface de ce serveur Web. J'espère que certaines de ces choses vous semblent familières, car c'est exactement l'architecture qui a été prise en compte dans le laboratoire. Il semble que ce soit un bon design. Vous n'aviez pas
pubd ,
logd et
dbproxy dans LR , mais vous aviez
okd et
svc . Vous avez des questions sur
OKWS ?
Public: avons-nous bien compris que
dbproxy n'accepte pas les requêtes SQL, mais un type de requête différent?
Professeur: oui, c'est ça! À quoi ressemble cette interface? Ils ne décrivent pas cela en détail, mais une chose que vous pourriez faire avec ce
dbproxy est de stocker de nombreux arguments pour
les modèles de requête
SQL . Par exemple, il peut s'agir d'un modèle de requête de recherche pour vos amis, en les sélectionnant par
ID .
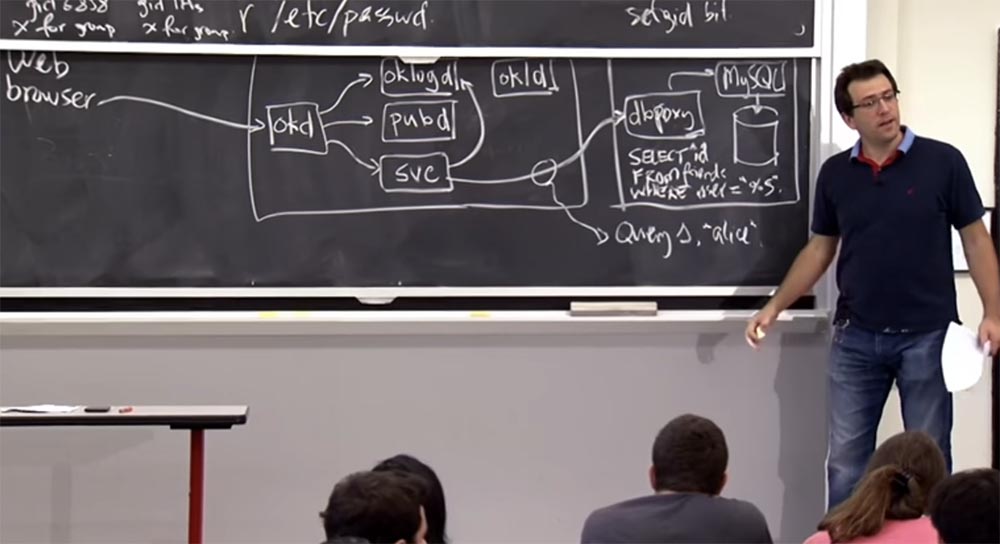
Supposons qu'il existe un modèle comme «sélectionnez
^ ID dans votre liste d'amis, où
^ ID =«% S » . Supposons que vous souhaitiez retrouver
Alice parmi vos amis et envoyer une requête
S , où l'argument est
«alice» . Faites savoir à notre application, disponible dans l'interface, que
dbproxy est prêt à exécuter trois types de requêtes en son nom. Si vous souhaitez exécuter la requête n ° 1 et que son argument est
"Alice" , cela vous donne accès à la base de données.
Public: un utilisateur externe au niveau d'un navigateur Web peut-il envoyer une telle demande à la base de données ou tout cela ne s'applique-t-il qu'aux utilisateurs internes du réseau?
Professeur: oui, peut-être. Alors comment ça marche? En fait, il est étrange que cette base de données se trouve sur une machine distincte, car vous pourriez simplement vous connecter à la base de données
OKWS ou au serveur
MySQL ? Alors qu'est-ce qui arrête ça?
Public: pare-feu?
Professeur: oui, probablement à un certain niveau. Les développeurs ne décrivent pas cela trop en détail, mais il y a probablement un réseau interne sur la deuxième machine, et il y a un basculement entre l'interface et la base de données qui ne peut pas être atteint du monde extérieur. En fait, les deux machines sont sur le même réseau, mais il existe un pare-feu
Fw qui a certaines règles. Peut-être que vous ne pouvez vous connecter à cet ordinateur d'interface que par le port 80, mais pas directement au serveur interne. C'est l'une des options de protection.
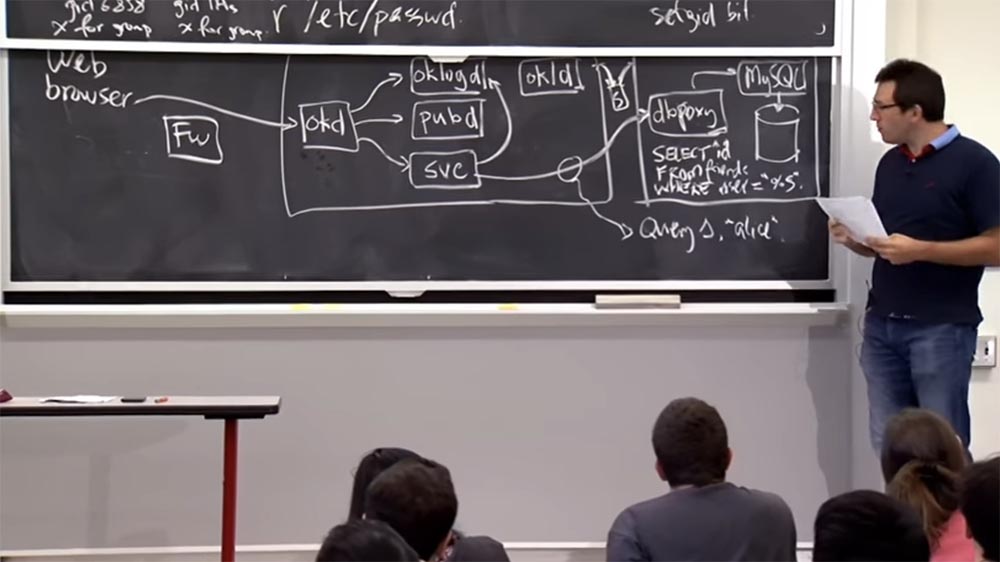
Un autre, probablement, est que lorsque vous vous connectez à ce
proxy de base de données
dbproxy , vous devez fournir un jeton cryptographique de 20 octets, ou clé, et si vous ne le fournissez pas,
dbproxy rejettera votre connexion. La règle est donc que vous ouvrez une connexion TCP, envoyez vos 20 octets, et s'ils sont incorrects, la connexion se ferme. C'est, je pense, le sens d'une telle conception de système.
Essayons donc de découvrir comment ces différents processus sont isolés ici. Comment pouvez-vous vous assurer que tous ces composants ne se submergent pas?
Public: différents droits root et différents ID utilisateur?
Professeur: oui, presque chacun de ces composants fonctionne comme un
uid différent, donc ici, dans la description du système, il y a un tableau complet qui décrit pour chaque composant où il fonctionne et avec quel
uid . Nous pouvons donc écrire que
okd a son propre
uid ,
pubd a son propre
uid et
oklogd a également son propre
uid .
Okld fonctionne en tant que
root , ce qui est plutôt infructueux, mais ce n'est peut-être pas un gros problème. Ensuite, il y a tout un tas d'identifiants d'utilisateurs attribués dynamiquement pour chaque service, par exemple l'ID 51001, etc.

Ainsi, cela garantit que chaque service ne peut pas interférer avec les processus des autres services.
Chroot est également largement utilisé ici, donc certains de ces composants ont des droits de
chroot dans des répertoires séparés. Par exemple,
okd et
svc sont dotés de droits de
chroot communs dans certains répertoires. Pourquoi pensez-vous que ces deux composants ont un séparé et pas commun avec d'autres composants
chroot ?
Public: car
okd n'a pas de privilèges root.
Professeur: oui, mais pourquoi ne mettent-ils pas
pubd ,
oklogd et tout le monde dans le même
chroot ?
Public: est- il possible que si les services ont besoin de partager beaucoup de données, devraient-ils être isolés les uns des autres?
Professeur: peut
- être. Je pense qu'ils devraient partager certaines données, mais ces données ne sont pas dans les fichiers, elles sont transférées via des sockets de
okd aux services. Mais en fait, aucun de ces composants ne stocke quelque chose d'intéressant dans le système de fichiers.
Par conséquent, il n'y a rien d'intéressant dans le répertoire
chroot , et je pense que les gars d'
OKWS ont simplement décidé de réduire les dépenses improductives pour
chroot , comme la nécessité de créer une copie du répertoire. Peut-être voulaient-ils également se débarrasser de certains frais généraux de gestion pour chaque commande
chroot . Mais comme il n'y a pas de vrais fichiers ici, alors tout est en ordre.
La raison pour laquelle ces gars-là ont attribué un
chroot différent pour les composants d'environnement est à cause de certaines choses intéressantes. Il peut y avoir des modèles, mais ici, peut-être, il y a un fichier journal, donc ils ne voudraient pas que le fichier journal soit lu accidentellement, etc.
Public: ces services ont-ils des fichiers, par exemple, comme
aspx ?
Professeur: comme ils le décrivent dans l'article, le service est un seul binaire
C ++ compilé, donc en fait il n'y a pas de fichiers supplémentaires.
Il existe des modèles, mais ils sont vraiment transmis par ce mécanisme étrange:
pubd a des modèles dans son répertoire, il les affiche dans certains pré-ordinateurs, sous forme d'accueil dans
okd , et
okd fournit déjà des modèles pour tous les services via des appels
RPC . Ainsi, ils restent en mémoire, mais sont en fait inaccessibles directement via le système de fichiers. C'est une conception un peu paranoïaque quand je ne peux même pas lire les modèles.
Alors, quel est l'intérêt de séparer tous ces composants? Pourquoi avons-nous besoin d'un
oklogd distinct?
Public: pour éliminer la possibilité d'écraser ou de rogner le journal?
Professeur: oui, donc nous voulons vraiment nous assurer que si quelque chose ne va pas, le journal, au moins, ne sera pas corrompu. Par conséquent, il existe un fichier journal distinct accessible en écriture par cet
uid , et tous les messages de journal sont envoyés en tant que
RPC pour ce service de journal. Et même si tout le reste est ruiné, eh bien, à l'exception de
okld , le magazine restera indemne.
Public: que se passe-t-il si vous avez accidentellement trouvé un moyen de lire le magazine et ne voyez pas ce que les autres en ont fait?
Professeur: non, je pense que si vous "piratez" un service, un
pubd ou autre chose, vous pouvez écrire n'importe quoi dans le journal. Par conséquent, la création d'une
entrée oklogd distincte est logique. En fait,
oklogd est un processus distinct, et pas seulement mis à jour en joignant des fichiers en tant
que fichier à ajouter uniquement . Ainsi,
oklogd ne peut pas ajouter d'informations supplémentaires à chaque entrée de journal, car si le système d'exploitation prend en charge le fichier à
ajouter uniquement , vous ne saurez pas que quelqu'un a écrit dans le fichier lorsque cela se produit. Tandis
qu'oklogd met un horodatage pour chaque message et vous permet de savoir quel service a effectué l'enregistrement ou s'il provient d'
okd . Par conséquent, vous obtenez réellement des informations supplémentaires dans ce fichier journal car il s'agit d'un service distinct.
Et quelle est la signification de la séparation
okld et pourquoi devrait-elle fonctionner avec les droits root? Je pense qu'il y a plusieurs raisons à cela.
Public: si vous voulez que personne d'autre n'agisse avec les privilèges root, vous devez déléguer la
fonction d'authentification utilisateur
okld .
 Professeur:
Professeur: oui. Quelqu'un doit configurer tout cela
chroot uid , et vous avez besoin de
root pour cet
Unix , donc
okld fournit cela. C’est une des raisons. Autre chose?
Public: définition de 80 ports?
Professeur: oui, bien sûr! Vous devez lier l'écoute au port 80, qui est
okld et fournit autre chose?
Public: il termine l'ouverture du fichier journal
oklogd car nous ne voulons pas laisser
oklogd ouvert pour empêcher l'accès au fichier journal.
Professeur: peut
- être. Mais je ne sais pas si les développeurs l'ont vraiment fait parce qu'ils n'ont pas regardé leur code source. Pensez-vous que
okld ouvre le fichier journal et le transmet
oklogd ? C'est possible.
Public: car sinon, un attaquant qui aurait compromis
oklogd pourrait effacer l'intégralité du journal.
Professeur: oui, c'est vrai. Vous souhaitez peut-être l'ouvrir en mode
ajout , puis le passer
oklogd , puis vous avez plus de garanties de sécurité pour le journal. C'est quelque chose que vous ne pouvez pas faire sans privilèges root.
Donc, nous avions une question sur les devoirs, que se passera-t-il lorsque ce jeton de 20 octets sera «divulgué» pour accéder à la base de données. Quels dommages cela peut-il causer? Faut-il s'en inquiéter?
Public: dans ce cas, un attaquant peut prendre le contrôle d'un service particulier.
Professeur: oui, c'est vrai, car maintenant vous pouvez vous connecter et obtenir tous les modèles de requête. Cela semble en fait assez simple. Vous devrez probablement compromettre l'un de ces composants afin de pouvoir vous connecter à la base de données du serveur en premier. Je pense donc que si vous avez ce jeton et que vous pouvez compromettre l'un de ces composants illustrés dans la figure, vous pouvez utiliser toutes ces requêtes.
Voyons maintenant comment cette conception
OKWS peut être améliorée? Par exemple, vous pouvez allouer une unité
uid distincte pour chaque utilisateur, sauf pour allouer un
uid distinct pour chaque service. Ici, chaque service, par exemple les actualités, la recherche d'amis ou la création d'un compte, a un
ID utilisateur distinct, mais chaque utilisateur
OKWS n'est pas représenté comme un
UID Unix . En fait, il n'y a pas d'
ID utilisateur ici, seuls les
ID de service sont présents ici. Pensez-vous que vous devez avoir un
uid différent pour chaque client
OKWS ?
Public: dans ce cas, il s'avère que si un utilisateur «pirate» un service, il pourra accéder à toutes les données des autres utilisateurs de ce serveur.
Professeur: oui, c'est vrai!
Public: mais si vous aviez, en fait, un service et un
dbproxy distincts pour chaque utilisateur, il serait impossible d'accéder aux données des autres.
Professeur: oui, mais cela pourrait-il être un modèle plus fort? Je pense que les développeurs
OKWS ne prennent pas une telle mesure pour deux raisons. Le premier est la performance. Si vous avez quelques millions d'utilisateurs du site
okcupid , plusieurs millions de processus en cours d'exécution et quelques millions de
dbproxie , des
surcoûts de performances sont possibles. Et cela ne permettra pas d'atteindre les mêmes performances que celles
fournies par l' architecture
OKWS existante.
Public: la description
OKWS indique que les performances de ce système sont meilleures que celles des autres systèmes. Comment cela a-t-il été réalisé?
Professeur: Je pense que c'est en partie parce qu'ils ont affiné leur conception à une charge de travail spécifique, en plus, ils ont écrit tout cela en
C ++ . Une alternative est d'écrire certaines choses en
PHP , alors vous obtiendrez probablement des avantages sur ce front.
De plus, ils n'ont pas beaucoup des fonctionnalités d'
Apache . Il a une conception polyvalente, il a donc de nombreux processus de travail et il les recharge de temps en temps. Il existe de nombreuses connexions
TTP qui garantissent la durée du processus de connexion et maintiennent leur activité. Il augmente également le nombre de processus en cours d'exécution sur le système.
Apache a été rendu plus universel et peut faire tout ce que vous souhaitez obtenir du serveur Internet, et les gars d'
OKWS sont plus concentrés sur la résolution de problèmes spécifiques.
Mais je pense qu'il existe d'autres serveurs Web de nos
jours qui peuvent probablement correspondre
aux performances
OKWS . Par exemple,
Nginx est un serveur Web très optimisé que vous pouvez exécuter de nos jours. Si vous souhaitez des applications hautes performances côté serveur, vous souhaiterez probablement que le long processus soit très similaire au service
OKWS . Et pour qu'il ait un mécanisme pour une interface de passerelle
CGI commune rapide pour connecter un programme externe à un serveur Web, ou une sorte de protocole qui pourrait être utilisé côté serveur pour l'implémenter même dans
Apache ou
Nginx . Par conséquent, je pense que beaucoup de ces idées ne sont pas exclusives à
OKWS , elles peuvent être implémentées dans d'autres serveurs Web. Ils montrent simplement que l'amélioration de la sécurité n'empêche pas l'utilisation de ces «astuces». Je pense qu'ils ont commencé avec un schéma similaire à
Apache , mais pensaient que ce ne serait pas assez sûr.
Je pense donc que l'une des raisons pour lesquelles les créateurs d'
OKWS n'ont pas voulu introduire de privilèges distincts pour les utilisateurs était une possible dégradation des performances.

Une autre raison est que leur modèle d'application complet «tourne» autour d'un service qui essaie d'accéder aux données de chaque utilisateur, comme trouver des amis sur
okcupid ou quelqu'un que vous pouvez inviter à une date. Par conséquent, ce modèle d'isolement des utilisateurs n'a pas beaucoup de sens, car, en fin de compte, il devrait y avoir un service pour lequel vous envoyez une demande, et il examinera toutes les autres données pour trouver une correspondance pour votre demande. Donc, même si vous avez des identifiants utilisateur ou un mécanisme pour les isoler, vous devez toujours ouvrir l'accès au service pour chaque utilisateur.
Pour d'autres services, tels que
Gmail ou
Dropbox , qui sont beaucoup plus axés sur un utilisateur spécifique et ne fournissent pas une capacité ouverte de partager leurs fichiers, l'isolement des utilisateurs peut offrir plus d'avantages. Par exemple, sur le serveur
Dropbox, il existe un
ID utilisateur pour chaque client
Dropbox . Et s'il y a un processus en cours pour vous et un processus en cours pour quelqu'un d'autre, alors même en utilisant un exploit malveillant, vous ne pourrez pas mettre la main sur les informations des autres.
Voyons maintenant si
OKWS a vraiment réussi à améliorer la sécurité dans un tel modèle de serveur. Pour évaluer la sécurité, vous devez considérer chaque composant du système et déterminer quel type d'attaques pourrait lui nuire.
Commençons par
okd . Il peut être attaqué avec des requêtes via le navigateur, par exemple, provoquant un débordement de tampon. c++, , - ,
okd . ?
 :
: ?
: , , . ?
: , .
: , . , , ,
http , , , . , .
: ?
: , . , , , , ,
match.com . , ,
OkCupid . , - ? ?
: , ,
okd . , ?
: . ,
okd .
: , ?
: ! , , , , , . , , , , . , , . «»
okd , , , .
: DOS-?
: , , , «» «» , DOS- - .
: okd , , …
: , . , ,
okd ,
okd , .
okd , . ,
okd , , , , .
: .
: , . ,
okd . ,
oklogd ? ?
: .
: , , , ?
pubd , , , - .
: , , «»
oklogd .
: , . , ,
append-only , .
: , …
: , , . .
svc ? , , . , ,
okd oklogd . , , .
svc - -, , , . , , , .
okld ? , root. ? , .
dbproxy .
okld ? «»? ?
: , - ?
: , . , , . , , - , , , - . - . root- .
: -, , -
dbproxy .
: !
: , , ,
RPC , , , , , ! .
 :
: , .
dbproxy ? , . , «» ,
dbproxy - .
: ,
svc …
: ,
svc , !
: , , !
: , ,
«» , …
: dbproxy .
: . ,
dbproxy , .
J'espère que vous comprenez ce que le partage des privilèges d'application nous donne. Et comme nous pouvons le voir, ce n'est pas parfait. Il y a beaucoup d'autres choses qui peuvent mal tourner. Mais il semble que cette solution soit en tout cas meilleure que la conception d'applications individuelles sans privilèges d'accès, là où nous avons commencé.La version complète du cours est disponible ici .Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?