Institut de technologie du Massachusetts. Cours magistral # 6.858. "Sécurité des systèmes informatiques." Nikolai Zeldovich, James Mickens. 2014 année
Computer Systems Security est un cours sur le développement et la mise en œuvre de systèmes informatiques sécurisés. Les conférences couvrent les modèles de menace, les attaques qui compromettent la sécurité et les techniques de sécurité basées sur des travaux scientifiques récents. Les sujets incluent la sécurité du système d'exploitation (OS), les fonctionnalités, la gestion du flux d'informations, la sécurité des langues, les protocoles réseau, la sécurité matérielle et la sécurité des applications Web.
Cours 1: «Introduction: modèles de menace»
Partie 1 /
Partie 2 /
Partie 3Conférence 2: «Contrôle des attaques de pirates»
Partie 1 /
Partie 2 /
Partie 3Conférence 3: «Débordements de tampon: exploits et protection»
Partie 1 /
Partie 2 /
Partie 3Conférence 4: «Séparation des privilèges»
Partie 1 /
Partie 2 /
Partie 3Conférence 5: «D'où viennent les systèmes de sécurité?»
Partie 1 /
Partie 2Conférence 6: «Opportunités»
Partie 1 /
Partie 2 /
Partie 3Conférence 7: «Native Client Sandbox»
Partie 1 /
Partie 2 /
Partie 3 Public: pourquoi la plage de capacité de mémoire de la plage d'adresses doit-elle recommencer à zéro?
Professeur: parce qu'en termes de performances, il est plus efficace d'utiliser le saut cible si vous savez qu'une adresse valide est un ensemble continu d'adresses commençant à zéro. Car alors vous pouvez le faire avec un seul masque
ET , où tous les bits hauts sont un et seulement une paire de bits bas est zéro.
Public: Je pensais que le masque
AND était censé assurer l'alignement.
Professeur: à droite, le masque assure l'alignement, mais pourquoi part-il de zéro? Je pense qu'ils dépendent du
matériel segmenté du matériel de segmentation. Donc, fondamentalement, ils pourraient l'utiliser pour déplacer la zone vers le haut, en termes d'espace linéaire. Ou peut-être est-ce simplement lié à la façon dont l'application «voit» cette plage. En fait, vous pouvez le placer à différents décalages dans votre espace d'adressage virtuel. Cela vous permettra d'effectuer certaines astuces avec du matériel segmenté pour exécuter plusieurs modules dans le même espace d'adressage.
 Public:
Public: Peut-être est-ce parce qu'ils veulent «attraper» le point de réception du pointeur nul?
Professeur: oui, car ils veulent attraper tous les points de réception. Mais vous avez un moyen de le faire. Parce que le pointeur nul fait référence au segment auquel vous accédez. Et si vous déplacez le segment, vous pouvez afficher une page zéro inutilisée au début de chaque segment. Cela vous aidera donc à créer certains modules.
Je pense que l'une des raisons de cette décision - commencer la gamme à partir de 0 - est due à leur désir de porter leur programme sur la plate-forme
x64 , qui a une conception légèrement différente. Mais leur article ne le dit pas. Dans la conception 64 bits, l'équipement lui-même s'est débarrassé de certains matériels de segmentation, sur lesquels ils s'appuyaient pour des raisons d'efficacité, ils ont donc dû prévoir une approche logicielle. Cependant, pour
x32, ce n'est toujours pas une bonne raison pour que l'espace recommence à zéro.
Donc, nous continuons la question principale - que voulons-nous assurer d'un point de vue de la sécurité. Abordons cette question quelque peu «naïvement» et voyons comment nous pouvons tout gâcher, puis essayons de le réparer.
Je crois qu'un plan naïf consiste à rechercher des instructions interdites en scannant simplement l'exécutable du début à la fin. Alors, comment pouvez-vous repérer ces instructions? Vous pouvez simplement prendre le code du programme et le mettre dans une ligne géante qui va de zéro à 256 mégaoctets, selon la taille de votre code, puis lancer la recherche.

Cette ligne peut d'abord contenir le module d'instruction
NOP , puis le module d'instruction
ADD ,
NOT ,
JUMP, etc. Vous venez de rechercher, et si vous trouvez une mauvaise instruction, dites alors que c'est un mauvais module et jetez-le. Et si vous ne voyez aucun appel système à cette instruction, vous pouvez activer le lancement de ce module et faire tout dans la plage de 0 à 256. Pensez-vous que cela fonctionnera ou non? De quoi s'inquiètent-ils? Pourquoi est-ce si difficile?
Public: s'inquiètent-ils de la taille des instructions?
Professeur: oui, le fait est que la plate-forme
x86 a des instructions de longueur variable. Cela signifie que la taille exacte de l'instruction dépend des premiers octets de cette instruction. En fait, vous pouvez regarder le premier octet pour dire que l'instruction sera beaucoup plus volumineuse, puis vous devrez peut-être regarder quelques octets supplémentaires, puis décider de la taille nécessaire. Certaines architectures telles que
Spark ,
ARM ,
MIPS ont plus d'instructions de longueur fixe.
ARM a deux longueurs d'instructions - 2 ou 4 octets. Mais sur la plate
- forme
x86, la longueur des instructions peut être de 1, 5 et 10 octets, et si vous essayez, vous pouvez même obtenir une instruction assez longue de 15 octets. Cependant, ce sont des instructions complexes.
En conséquence, un problème peut apparaître. Si vous scannez cette ligne de code de façon linéaire, tout ira bien. Mais peut-être qu'au moment de l'exécution, vous irez au milieu d'une sorte d'instruction, par exemple
NON .

Il est possible qu'il s'agisse d'une instruction multi-octets, et si vous l'interprétez à partir du deuxième octet, elle sera complètement différente.
Un autre exemple dans lequel nous allons "jouer" avec l'assembleur. Supposons que nous ayons l'instruction
25 CD 80 00 00 . Après avoir regardé le 2e octet, vous l'interpréterez comme une instruction de cinq octets, c'est-à-dire que vous devrez regarder 5 octets en avant et voir qu'il est suivi par l'instruction
AND% EAX, 0x00 00 80 CD , en commençant par l'opérateur
AND pour le registre
EAX avec certains constantes définies, par exemple,
00 00 80 CD . C'est l'une des instructions sûres que le
client natif devrait simplement autoriser par la première règle de vérification des instructions binaires. Mais si, pendant l'exécution du programme, la
CPU décide qu'elle doit commencer à exécuter le code à partir du
CD , je marquerai cet endroit de l'instruction avec une flèche, alors l'instruction
% EAX, 0x00 00 80 CD , qui est en fait une instruction à 4 octets, signifiera l'exécution de
INT $ 0x80 , qui est un moyen de faire un appel système sous
Linux .
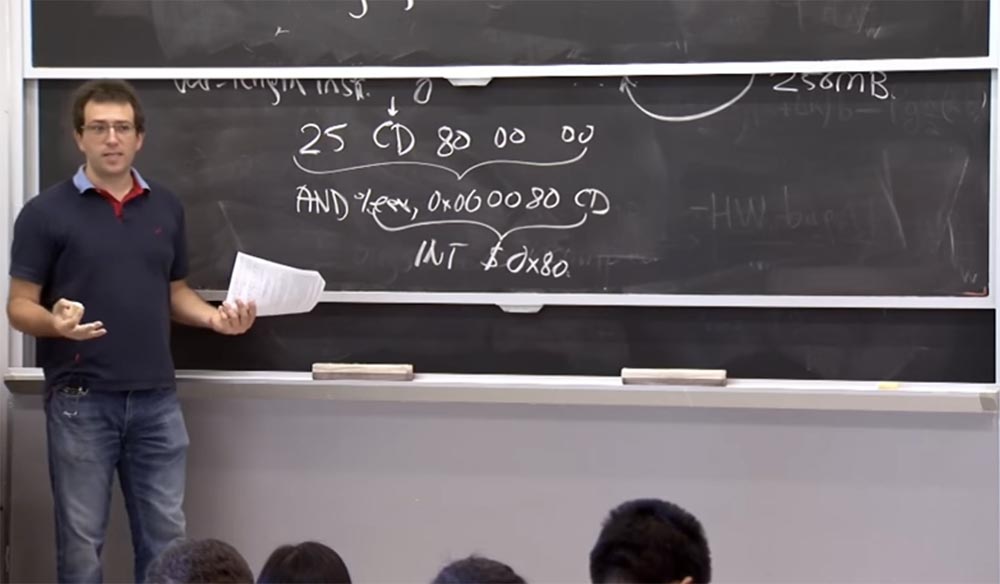
Donc, si vous manquez ce fait, laissez le module peu fiable "sauter" dans le noyau et faire des appels système, c'est-à-dire faire ce que vous vouliez empêcher. Comment éviter cela?
Peut-être devrions-nous essayer de regarder le décalage de chaque octet. Parce que x86 ne peut commencer à interpréter une instruction que dans des limites d'octets et non de bits. Ainsi, vous devez regarder le décalage de chaque octet pour voir où commence l'instruction. Pensez-vous que ce plan soit réalisable?
Public: Je pense que si quelqu'un utilise réellement
AND , le processeur ne sautera pas à cet endroit, mais permettra simplement au programme de s'exécuter.
Professeur: oui, car fondamentalement il n'est pas sujet aux faux positifs. Maintenant, si vous le voulez vraiment, vous pouvez changer un peu le code pour l'éviter. Si vous savez exactement ce que recherche l'appareil de test, vous pouvez potentiellement modifier ces instructions. Peut-être en définissant
ET d' abord pour une instruction, puis en utilisant le masque sur une autre. Mais il est beaucoup plus facile d'éviter ces arrangements d'octets suspects, bien que cela semble plutôt gênant.
Il est possible que l'architecture inclue un changement de compilateur. Fondamentalement, ils ont une sorte de composant qui doit réellement compiler le code correctement. Vous ne pouvez pas simplement «décoller»
GCC et compiler du code pour le
client natif . Donc, fondamentalement, c'est faisable. Mais probablement, ils pensent simplement que cela cause trop de problèmes, ne sera pas une solution fiable ou performante, etc. De plus, plusieurs instructions
x86 sont interdites ou doivent être considérées comme dangereuses et doivent donc être interdites. Mais pour la plupart, leur taille est d'un octet, il est donc assez difficile de les trouver ou de les filtrer.
Par conséquent, s'ils ne peuvent pas simplement collecter et trier les instructions dangereuses et espérer le meilleur, ils doivent utiliser un plan différent afin de le démonter de manière fiable. Alors, que fait le
client natif pour s’assurer qu’il ne «trébuche» pas sur cet encodage de longueur variable?
Dans un sens, si nous analysons vraiment le fichier exécutable de gauche à droite et recherchons tous les codes incorrects possibles, et si c'est ainsi que le code s'exécute, nous sommes en bonne forme. Même s'il y a des instructions étranges et des biais, le processeur ne va toujours pas "sauter" là, il exécutera le programme dans le même ordre dans lequel les instructions sont scannées, c'est-à-dire de gauche à droite.

Ainsi, le problème d'un démontage fiable se pose du fait que quelque part dans l'application il peut y avoir des "sauts". Le processeur peut échouer s'il effectue un «saut» vers une instruction de code qu'il n'a pas remarquée lors de la numérisation de gauche à droite. Il s'agit donc d'un problème de démontage fiable en cours de développement. Et le plan principal est de vérifier où mènent tous les "sauts". En fait, c'est assez simple à un certain niveau. Il y a un tas de règles que nous considérerons dans une seconde, mais le plan approximatif est que si vous voyez une instruction de "saut", vous devez vous assurer que le but du "saut" a été remarqué plus tôt. Pour ce faire, en fait, il suffit de balayer de gauche à droite, c'est-à-dire la procédure que nous avons décrite dans notre approche naïve du problème.
Dans ce cas, si vous voyez une instruction de "saut" et l'adresse vers laquelle cette instruction pointe, alors vous devez vous assurer que c'est la même adresse que vous avez déjà vue lors du démontage de gauche à droite.
Si une instruction de saut pour cet octet CD est trouvée, alors nous devons marquer ce saut comme invalide car nous n'avons jamais vu l'instruction commençant dans l'octet CD, mais nous avons vu une autre instruction commençant par le numéro 25. Mais si toutes les instructions de saut ordonné d'aller au début de l'instruction, dans ce cas à 25, alors tout est en ordre chez nous. Est-ce clair?
Le seul problème est que vous ne pouvez pas vérifier les objectifs de chaque saut dans le programme, car il peut y avoir des sauts indirects. Par exemple, en
x86, vous pourriez avoir quelque chose comme un saut à la valeur de ce registre
EAX . C'est idéal pour implémenter des pointeurs de fonction.

Autrement dit, le pointeur de fonction se trouve quelque part dans la mémoire, vous le tenez dans un registre, puis accédez à n'importe quelle adresse dans le registre de mouvement.
Alors, comment ces gars font-ils face aux sauts indirects? Parce que, en fait, je n'ai aucune idée si ce sera un «saut» à l'octet
CD ou à l'octet 25. Que font-ils dans ce cas?
Public: utiliser des outils?
Professeur: oui, l'instrumentation est leur principal truc. Par conséquent, chaque fois qu'ils voient que le compilateur est prêt à effectuer la génération, c'est la preuve que ce saut ne causera pas de problèmes. Pour ce faire, ils doivent s'assurer que tous les sauts sont effectués avec une multiplicité de 32 octets. Comment font-ils? Ils changent toutes les instructions de saut en ce qu'ils ont appelé des «pseudo instructions». Ce sont les mêmes instructions, mais préfixées, qui effacent les 5 bits bas du registre
EAX . Le fait que l'instruction efface 5 bits bas signifie qu'elle fait que la valeur donnée est un multiple de 32, de deux à cinq, puis un saut dans cette valeur est déjà effectué.

Si vous regardez cela pendant la vérification, assurez-vous que cette «paire» d'instructions ne «sautera» qu'avec une multiplicité de 32 octets. Et puis, afin de vous assurer qu'il n'y a aucune possibilité de «sauter» dans des instructions étranges, vous appliquez une règle supplémentaire. Il consiste en ce que lors du démontage, lorsque vous regardez vos instructions de gauche à droite, vous vous assurez que le début de chaque instruction valide sera également un multiple de 32 octets.
Ainsi, en plus de cette boîte à outils, vous vérifiez que chaque code qui est un multiple de 32 est l'instruction correcte. Par une instruction valide et valide, je veux dire une instruction qui est démontée de gauche à droite.
Public: Pourquoi le numéro 32 est-il choisi?
Professeur: oui, pourquoi ont-ils choisi 32 au lieu de 1000 ou 5? Pourquoi 5 est mauvais?
Public: car le nombre doit être une puissance de 2.
Professeur: oui, eh bien, c'est pourquoi. Parce qu'autrement, garantir l'utilisation de quelque chose qui est un multiple de 5 nécessitera des instructions supplémentaires entraînant des frais généraux. Et huit? Est-ce que huit est un nombre suffisant?
Public: vous pouvez avoir des instructions de plus de huit bits.
Professeur: oui, cela peut être pour la plus longue instruction autorisée sur la plate-forme x86. Si nous avons une instruction de 10 octets et que tout doit être un multiple de 8, nous ne pouvons l’insérer nulle part. La longueur devrait donc être suffisante dans tous les cas, car la plus grosse instruction que j'ai vue faisait 15 octets. Donc 32 octets suffisent.
Si vous souhaitez adapter les instructions pour entrer ou quitter l'environnement de service de processus, vous devrez peut-être une quantité non triviale de code dans un emplacement de 32 octets. Par exemple, 31 octets, car 1 octet contient une instruction. Doit-il être beaucoup plus gros? Devrions-nous rendre cela égal à, disons, 1024 octets? Si vous avez de nombreux pointeurs de fonction ou de nombreux sauts indirects, chaque fois que vous voulez créer un endroit où vous allez sauter, vous devez le continuer jusqu'à la bordure suivante, quelle que soit sa valeur. Donc, avec 32 bits, c'est une taille tout à fait normale. Dans le pire des cas, vous ne perdrez que 31 octets si vous devez vous rendre rapidement à la prochaine frontière. Mais si vous avez une taille qui est un multiple de 1024 octets, il y a la possibilité de gaspiller un kilo-octet entier de mémoire en vain pour un saut indirect. Si vous avez des fonctions courtes ou de nombreux pointeurs de fonction, une taille aussi grande de la multiplicité de la longueur du "saut" entraînera un gaspillage de mémoire important.
Je ne pense pas que le nombre 32 soit une pierre d'achoppement pour le
Native Client . Certains blocs pourraient fonctionner avec une multiplicité de 16 bits, certains 64 ou 128 bits, peu importe. Seulement 32 bits leur semblaient la valeur optimale la plus acceptable.
Alors, faisons un plan pour un démontage fiable. Par conséquent, le compilateur doit être un peu prudent lors de la compilation de
code C ou
C ++ dans un binaire
Native Client et observer les règles suivantes.

Par conséquent, chaque fois qu'il fait un saut, comme indiqué dans la ligne du haut, il doit ajouter ces instructions supplémentaires données dans les 2 lignes du bas. Et indépendamment du fait qu'il crée une fonction vers laquelle il va "sauter", notre instruction sautera comme l'ajout
ET $ 0xffffffe0,% eax indique. Et il ne peut pas simplement le compléter avec des zéros, car tout cela doit avoir les bons codes. Ainsi, l'ajout est nécessaire afin de s'assurer que toutes les instructions possibles sont valides. Et, heureusement, sur la plate-forme
x86 , pas une seule fonction
noop n'est décrite par un seul octet, ou du moins il n'y a pas un seul
noop 1 octet de taille. Ainsi, vous pouvez toujours ajouter des choses à la valeur d'une constante.
Alors qu'est-ce que cela nous garantit? Assurons-nous de toujours voir ce qui se passe dans la terminologie des instructions qui seront suivies. Voici ce que cette règle nous donne: l'assurance qu'un appel système ne sera pas effectué par accident. Cela s'applique aux sauts, mais qu'en est-il des retours? Comment gèrent-ils les retours? Pouvons-nous faire un
retour à une fonction dans le
Native Client ? Que se passe-t-il si vous exécutez le code red-hot?
Public: il peut déborder de la pile.
Professeur: il est vrai qu'il apparaît de façon inattendue sur la pile. Mais le fait est que la pile utilisée par les modules
Native Client contient en fait des données à l'intérieur. Ainsi, lorsque vous traitez avec
Native Client, vous ne devez pas vous soucier du débordement de pile.
Public: attendez, mais vous pouvez tout mettre sur la pile. Et quand vous faites un saut indirect.
Professeur: c'est vrai. Le retour ressemble presque à un saut indirect de quelque part dans la mémoire, qui est situé en haut de la pile. Par conséquent, je pense qu'une chose qu'ils pourraient faire pour la fonction de
retour est de définir le préfixe de la même manière que lors de la vérification précédente. Et ce préfixe vérifie ce qui apparaît en haut de la pile. Vous vérifiez si cela est valide et lorsque vous écrivez ou utilisez l'opérateur
AND , vous vérifiez ce qui se trouve en haut de la pile. Cela semble un peu peu fiable en raison du changement constant de données. Parce que, par exemple, si vous regardez en haut de la pile et assurez-vous que tout va bien, puis écrivez quelque chose, le flux de données dans le même module peut modifier quelque chose en haut de la pile, après quoi vous vous référerez à la mauvaise adresse
Public: Cela ne s'applique-t-il pas au saut dans la même mesure?
Professeur: oui, alors que se passe-t-il avec un saut? Nos conditions de course peuvent-elles en quelque sorte invalider ce test?
Public: Mais le code n'est-il pas accessible en écriture?
Professeur: oui, le code ne peut pas être écrit, c'est vrai. Par conséquent, vous ne pouvez pas modifier AND. Mais un autre flux ne pourrait-il pas changer le but du saut entre ces deux instructions?
Public: c'est dans le registre, donc ...
Professeur: Oui, c'est cool. Parce que si un flux modifie quelque chose en mémoire ou dans ce qui est chargé depuis
EAX (par lui-même, vous le faites avant de télécharger), dans ce cas, cet
EAX sera dans un mauvais état, mais il effacera les mauvais bits. Ou bien il peut changer la mémoire après, lorsque le pointeur est déjà dans
EAX , donc peu importe qu'il change l'emplacement de la mémoire à partir de laquelle le registre
EAX a été chargé.
En fait, les threads ne partagent pas les ensembles de registres. Par conséquent, si un autre thread modifie le registre
EAX , cela n'affectera pas le registre
EAX de ce thread. Par conséquent, d'autres threads ne peuvent pas invalider cette séquence d'instructions.
Il y a une autre question intéressante. Pouvons-nous contourner cet
ET ? Je peux sauter où je veux n'importe où dans cet espace d'adressage. ,
AND .

, , , , ,
AND . .
jmp , .

, , - , 1237. , 32.
Native Client , , , . , , 1237 ?
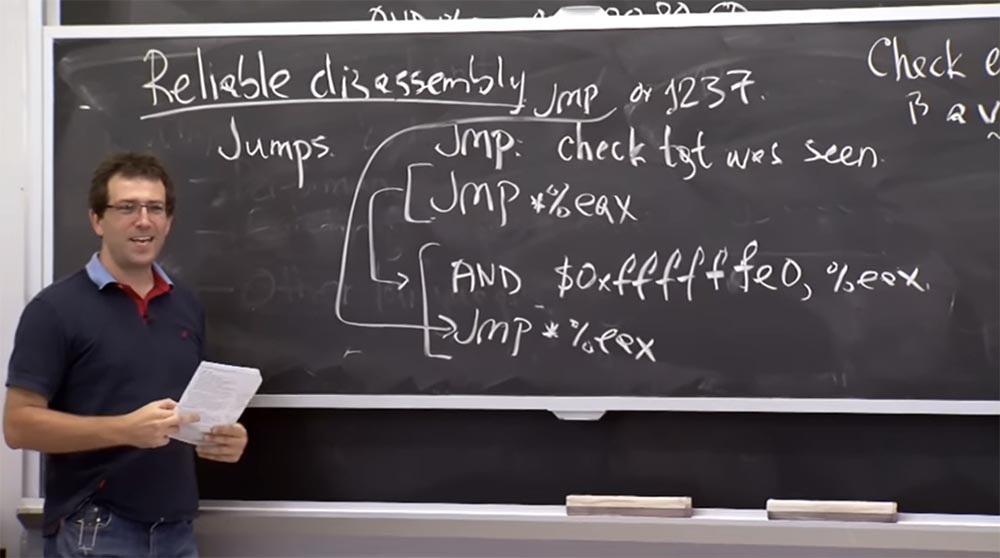
-
EAX , , , , . , ? ?
: NaCl , .
: , .
x86 , ,
NaCl , 2 . , , : «, , !»,
25 CD 80 00 00 . . ,
x86 .
,
Native Client . , , , ,
NaCl . , .
: , , . , . , , , , .
 :
: , . , . , , ,
EAX . , - .
EAX ,
EBX . , .
EAX EBX AND . , ,
EAX , . , -
64 .
Jmp *% eax AND .

, , , , .
Intel , , , , . , , .
AND ,
EAX , «» .
, , . , . , , , . , , , .
, ,
C1 C7 .
C1 , , . , «» . , , . , , - . , .
2 , 0
64 . , , . , , .
3 , , , . , , .
4 ,
hlt .
halt ? ,
C4 . , , - , .
, , ? , , - .
, , , , . , , , , . .

55:20
:
Cours MIT "Sécurité des systèmes informatiques". 7: « Native Client», 3.
, . Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
3 Dell R630 —
2 Intel Deca-Core Xeon E5-2630 v4 / 128GB DDR4 / 41TB HDD 2240GB SSD / 1Gbps 10 TB — $99,33 , ,
.
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?