Institut de technologie du Massachusetts. Cours magistral # 6.858. "Sécurité des systèmes informatiques." Nikolai Zeldovich, James Mickens. 2014 année
Computer Systems Security est un cours sur le développement et la mise en œuvre de systèmes informatiques sécurisés. Les conférences couvrent les modèles de menace, les attaques qui compromettent la sécurité et les techniques de sécurité basées sur des travaux scientifiques récents. Les sujets incluent la sécurité du système d'exploitation (OS), les fonctionnalités, la gestion du flux d'informations, la sécurité des langues, les protocoles réseau, la sécurité matérielle et la sécurité des applications Web.
Cours 1: «Introduction: modèles de menace»
Partie 1 /
Partie 2 /
Partie 3Conférence 2: «Contrôle des attaques de pirates»
Partie 1 /
Partie 2 /
Partie 3Conférence 3: «Débordements de tampon: exploits et protection»
Partie 1 /
Partie 2 /
Partie 3Conférence 4: «Séparation des privilèges»
Partie 1 /
Partie 2 /
Partie 3Conférence 5: «D'où viennent les systèmes de sécurité?»
Partie 1 /
Partie 2Conférence 6: «Opportunités»
Partie 1 /
Partie 2 /
Partie 3Conférence 7: «Native Client Sandbox»
Partie 1 /
Partie 2 /
Partie 3 Il y a une mise en garde dans la règle
C4 . Vous ne pouvez pas "sauter" la fin d'un programme. La dernière chose à laquelle vous pouvez accéder est la dernière instruction. Cette règle garantit donc que lorsque le programme est exécuté dans le processus «moteur», il n'y aura pas de divergence.
La règle
C5 indique qu'il ne peut pas y avoir d'instructions supérieures à 32 octets. Nous avons envisagé une certaine version de cette règle lorsque nous avons parlé de la multiplicité des tailles d'instruction à 32 octets, sinon vous pouvez sauter au milieu de l'instruction et créer un problème avec l'appel système, qui peut s'y «cacher».
La règle
C6 stipule que toutes les instructions disponibles peuvent être désassemblées dès le début. Ainsi, cela garantit que nous voyons chaque instruction et peut vérifier toutes les instructions qui s'exécutent lorsque le programme s'exécute.
La règle
C7 stipule que tous les sauts directs sont corrects. Par exemple, vous passez directement à la partie de l'instruction où la cible est indiquée, et bien qu'il ne s'agisse pas d'un multiple de 32, c'est toujours l'instruction correcte à laquelle le désassemblage est appliqué de gauche à droite.
 Public:
Public: quelle est la différence entre
C5 et
C3 ?
Professeur: Je pense que
C5 dit que si j'ai une instruction multi-octets, elle ne peut pas traverser les frontières des adresses adjacentes. Supposons que j'ai un flux d'instructions et qu'il y ait une adresse 32 et une adresse 64. Ainsi, une instruction ne peut pas franchir le multiple de 32 octets, c'est-à-dire qu'elle ne doit pas commencer par une adresse inférieure à 64 et se terminer par une adresse supérieure à 64.

C'est ce que dit la règle
C5 . Parce qu'autrement, après avoir fait un saut de multiplicité 32, vous pouvez entrer au milieu d'une autre instruction, où l'on ne sait pas ce qui se passe.
Et la règle
C3 est un analogue de cette interdiction du côté du saut. Il indique que chaque fois que vous sautez, la longueur de votre saut doit être un multiple de 32.
C5 prétend également que tout ce qui est dans la plage d'adresses qui est un multiple de 32 est une instruction sûre.
Après avoir lu la liste de ces règles, j'ai eu un sentiment mitigé, car je n'ai pas pu évaluer si ces règles sont suffisantes, c'est-à-dire que la liste est minimale ou complète.
Réfléchissons donc aux devoirs que vous devez accomplir. Je pense qu'en fait il y a une erreur dans le fonctionnement du
Native Client lors de l'exécution de certaines instructions compliquées dans le sandbox. Je pense qu'ils n'avaient pas le bon codage de longueur, ce qui pourrait conduire à quelque chose de mauvais, mais je ne me souviens pas exactement de l'erreur.
Supposons qu'un validateur de bac à sable obtienne incorrectement la longueur d'une sorte d'instruction. Quel mal peut arriver dans ce cas? Comment utiliseriez-vous ce feuillet?
Public: par exemple, vous pouvez masquer l'appel système ou l'instruction return return.
Professeur: oui. Supposons qu'il existe une version sophistiquée de l'instruction
AND que vous avez notée. Il est possible que le validateur se soit trompé et ait considéré que sa longueur est de 6 octets avec la longueur réelle de 5 octets.
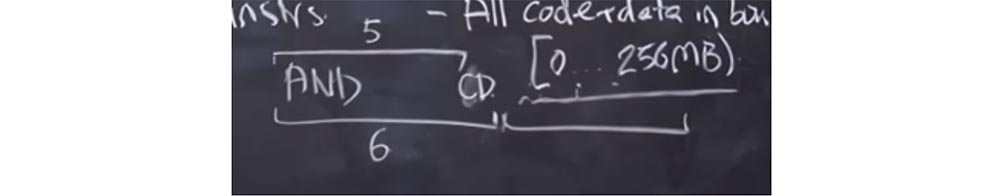
Que va-t-il se passer? Le validateur considère que la longueur de cette instruction est de 6 octets et a une autre instruction valide derrière elle. Mais le processeur, lors du lancement du code, utilise la longueur réelle de l'instruction, soit 5 octets. Par conséquent, nous avons un octet libre à la fin de l'instruction
AND , où nous pourrions insérer un appel système et l'utiliser à notre avantage. Et si nous insérons un octet de
CD ici, ce sera comme le début d'une autre instruction. Ensuite, nous mettrons quelque chose dans la prochaine plage de 6 octets, et cela ressemblera à une instruction qui commence par l'octet
CD , bien qu'en fait elle fasse partie de l'instruction
AND . Après cela, nous pouvons effectuer un appel système et «s'échapper» du bac à sable.
Ainsi, le validateur
Native Client doit synchroniser ses actions avec les actions du
CPU , c'est-à-dire «deviner» exactement comment le processeur interprétera chaque instruction. Et cela devrait être à tous les niveaux du bac à sable, ce qui est assez difficile à mettre en œuvre.
En fait, il existe d'autres erreurs intéressantes dans le
client natif . L'un d'eux est le nettoyage incorrect de l'environnement du processeur lors du passage au
Trusted Service Runtime . Je pense que nous en parlerons dans une seconde. Mais le
Trusted Service Runtime fonctionnera essentiellement avec le même ensemble de registres
CPU qui sont conçus pour exécuter des modules non approuvés. Donc, si le processeur oublie d'effacer quelque chose ou de redémarrer, le runtime peut être trompé en considérant le module non fiable comme une application de confiance et en faisant quelque chose qu'il n'aurait pas dû faire ou qui n'était pas l'intention des développeurs.
Où en sommes-nous maintenant? Pour le moment, nous comprenons comment démonter toutes les instructions et comment empêcher l'exécution d'instructions interdites. Voyons maintenant comment nous stockons la mémoire et les liens pour le code et les données dans le module
Native Client .
Pour des raisons de performances, les gars de
Native Client commencent à utiliser la prise en charge matérielle pour s'assurer que le stockage de la mémoire et des liens ne cause pas vraiment beaucoup de surcharge. Mais avant d'envisager le support matériel qu'ils utilisent, je veux entendre des suggestions, comment pourrais-je faire de même sans le support matériel? Pouvons-nous simplement fournir l'accès à tous les processus de mémoire dans les limites définies par la machine plus tôt?
Public: Vous pouvez instrumenter des instructions pour effacer tous les bits hauts.
 Professeur:
Professeur: oui, c'est vrai. En fait, nous voyons que nous avons cette instruction
ET ici, et chaque fois, par exemple, que nous sautons quelque part, cela efface les bits bas. Mais si nous voulons conserver tout le code possible qui s'exécute dans les 256 Mo bas, nous pouvons simplement remplacer le premier attribut
f par
0 et obtenir
$ 0x0fffffe0 au lieu de
$ 0xffffffe0 . Cela efface les bits bas et définit une limite supérieure de 256 Mo.
Ainsi, cela fait exactement ce que vous proposez, en vous assurant que chaque fois que vous sautez, vous êtes à moins de 256 Mo. Et le fait que nous procédions au démontage permet également de vérifier que tous les sauts directs sont à portée de main.
La raison pour laquelle ils ne le font pas pour leur code est que sur la plate-forme
x86 , vous pouvez très efficacement coder
AND , où tous les bits supérieurs sont 1. Cela se traduit par l'existence d'une instruction de 3 octets pour
AND et d'une instruction de 2 octets pour le saut. Ainsi, nous avons une dépense supplémentaire de 3 octets. Mais si vous avez besoin d'un bit élevé non unitaire, comme ce
0 au lieu de
f , vous avez soudainement une instruction de 5 octets. Par conséquent, je pense que dans ce cas, ils sont préoccupés par les frais généraux.
Public: Y a
- t-il un problème avec l'existence de certaines instructions qui incrémentent la version que vous essayez d'obtenir? Autrement dit, vous pouvez dire que votre instruction peut avoir un biais constant ou quelque chose comme ça?
Professeur: Je pense que oui. Vous interdirez probablement les instructions qui sautent à une formule d'adresse complexe et ne supporterez que les instructions qui sautent directement à cette valeur, et cette valeur obtient toujours
AND .
Public: il est plus nécessaire d'accéder à la mémoire que ...
Professeur: oui, parce que c'est juste du code. Et pour accéder à la mémoire sur la plate-forme
x86 , il existe de nombreuses façons étranges d'accéder à un emplacement de mémoire spécifique. Habituellement, vous devez d'abord calculer l'emplacement de la mémoire, puis ajouter un
ET supplémentaire
, et ensuite seulement y accéder. Je pense que c'est la vraie raison de leur inquiétude quant à la baisse des performances due à l'utilisation de cette boîte à outils.
Sur la plate-forme
x86 , ou au moins sur la plate-forme 32 bits décrite dans l'article, ils utilisent la prise en charge matérielle au lieu de restreindre le code et les données d'adresse référençant les modules non approuvés.
Voyons à quoi il ressemble avant de découvrir comment utiliser le module
NaCl dans un bac à sable. Ce matériel est appelé segmentation. Il est survenu avant même que la plate-forme
x86 ne reçoive un fichier d'échange. Sur la plate-forme
x86 , une table matérielle prise en charge existe pendant le processus. Nous l'appelons le tableau des descripteurs de segments. Il s'agit d'un groupe de segments numérotés de 0 à la fin d'un tableau de n'importe quelle taille. C'est quelque chose comme un descripteur de fichier sous
Unix , sauf que chaque entrée se compose de 2 valeurs: la base de
base et la longueur.
Ce tableau nous indique que nous avons une paire de segments, et chaque fois que nous nous référons à un segment spécifique, cela signifie dans un sens que nous parlons d'un morceau de mémoire qui commence à l'adresse de
base de la
base et continue sur la
longueur .

Cela nous aide à garder les limites de la mémoire sur la plate-forme
x86 , car chaque instruction, accédant à la mémoire, fait référence à un segment spécifique dans ce tableau.
Par exemple, lorsque nous exécutons
mov (% eax), (% ebx) , c'est-à-dire que nous déplaçons la valeur de la mémoire d'un pointeur stocké dans le registre
EAX vers un autre pointeur stocké dans le registre
EBX , le programme sait quelles sont les adresses de début et de fin. en vue de, et enregistrera la valeur dans la deuxième adresse.
Mais en fait, sur la plate-forme
x86 , lorsque nous parlons de mémoire, il existe une chose implicite appelée un descripteur de segment, similaire à un descripteur de fichier sous
Unix . Il s'agit simplement d'un index dans la table des descripteurs et, sauf indication contraire, chaque code d'opération contient un segment par défaut.
Par conséquent, lorsque vous exécutez
mov (% eax) , il fait référence à
% ds ou au registre de segment de données, qui est un registre spécial dans votre processeur. Si je me souviens bien, c'est un entier de 16 bits qui pointe vers cette table de descripteurs.
Et il en va de même pour
(% ebx) - il fait référence au même sélecteur de segment
% ds . En fait, en
x86, nous avons un groupe de 6 sélecteurs de code:
CS, DS, ES, FS, GS et
SS . Le
sélecteur d'appel CS est implicitement utilisé pour recevoir des instructions. Donc, si le pointeur de votre instruction pointe sur quelque chose, il fait référence à celui qui a sélectionné le sélecteur de segment
CS .
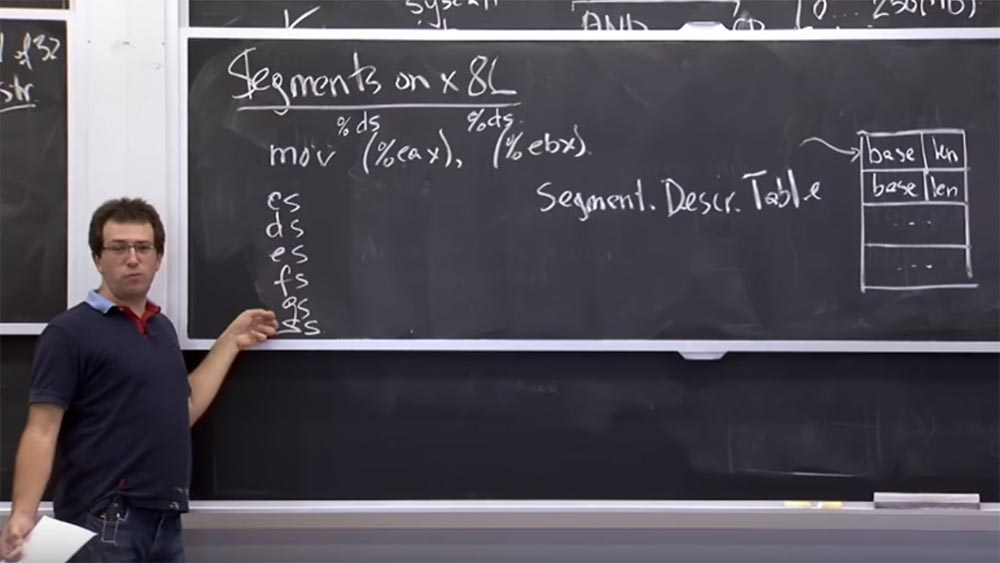
La plupart des références de données utilisent implicitement
DS ou
ES ,
FS et
GS indiquent des choses spéciales, et
SS est toujours utilisé pour les opérations de pile. Et si vous faites du
push & pop , ils viennent implicitement de ce sélecteur de segment. C'est une mécanique plutôt archaïque, mais elle s'avère extrêmement utile dans ce cas particulier.
Si vous avez accès à une adresse, par exemple, dans le sélecteur
% ds: addr , le matériel la redirigera vers l'opération avec la table
adrr + T [% ds] .base . Cela signifie qu'il prendra l'adresse de longueur de module de la même table. Ainsi, chaque fois que vous accédez à la mémoire, il dispose d'une base de données de sélecteurs de segments sous la forme d'entrées de table de descripteurs, et il prend l'adresse que vous spécifiez et la fait correspondre avec la longueur du segment correspondant.
Public: alors pourquoi n'est-il pas utilisé, par exemple, pour protéger le tampon?
Professeur: oui, c'est une bonne question! Pourrions-nous l'utiliser pour se protéger contre les dépassements de tampon? Par exemple, pour chaque tampon que nous avons, vous pouvez mettre la base du tampon ici et là la taille du tampon.
Public: que se passe-t-il si vous n'avez pas besoin de le mettre dans un tableau avant de l'écrire? Vous n'avez pas besoin d'être là en permanence.
Professeur: oui. Par conséquent, je pense que la raison pour laquelle cette approche n'est pas souvent utilisée pour se protéger contre les débordements de tampon est que le nombre d'entrées dans ce tableau ne peut pas dépasser 2 au 16e degré, car les descripteurs sont de 16 bits, mais en fait en fait, quelques bits de plus sont utilisés pour d'autres choses. Donc, en fait, vous ne pouvez placer que 2 au 13e pouvoir des enregistrements dans ce tableau. Par conséquent, si vous avez dans votre code un tableau de données supérieur à 2
13 , un débordement de cette table peut se produire.
De plus, il serait étrange que le compilateur gère directement cette table, car elle est généralement manipulée à l'aide d'appels système. Vous ne pouvez pas écrire directement dans cette table, vous devez d'abord effectuer un appel système au système d'exploitation, après quoi le système d'exploitation placera l'enregistrement dans cette table. Par conséquent, je pense que la plupart des compilateurs ne voudront tout simplement pas gérer un système de gestion de mémoire tampon aussi complexe.

Soit dit en passant,
Multex utilise cette approche: il dispose de 2
18 enregistrements pour divers segments et de 2
18 enregistrements pour d'éventuels décalages. Et chaque fragment de bibliothèque ou fragment de mémoire commun est un segment distinct. Ils sont tous vérifiés pour la plage et ne peuvent donc pas être utilisés à un niveau variable.
Public: Vraisemblablement, le besoin constant d'utiliser le noyau ralentira le processus.
Professeur: oui, c'est vrai. Nous aurons donc des frais généraux dus au fait que lorsqu'un nouveau tampon est soudainement créé sur la pile, nous devons effectuer un appel système pour l'ajouter.
Alors, combien de ces éléments utilisent réellement le mécanisme de segmentation? Vous pouvez deviner comment cela fonctionne. Je pense que, par défaut, tous ces segments en
x86 ont une base égale à 0, et la longueur est de 2 à 32. Ainsi, vous pouvez accéder à toute la plage de mémoire que vous souhaitez. Par conséquent, pour
NaCl, ils codent la base 0 et définissent la longueur à 256 mégaoctets. Ensuite, ils pointent vers tous les registres de 6 sélecteurs de segment dans cet enregistrement pour la zone de 256 Mo. Ainsi, chaque fois que l'équipement accède à la mémoire, il la modifie avec un décalage de 256 Mo. La possibilité de modifier le module sera donc limitée à 256 Mo.
Je pense que vous comprenez maintenant comment ce matériel est pris en charge et comment il fonctionne, de sorte que vous pourriez finir par utiliser ces sélecteurs de segments.
Alors, qu'est-ce qui peut mal tourner si nous mettons simplement en œuvre ce plan? Peut-on sauter du sélecteur de segment dans un module non fiable? Je pense qu'une chose à laquelle il faut faire attention est que ces registres sont comme des registres normaux, et vous pouvez y déplacer des valeurs. Par conséquent, vous devez vous assurer que le module non approuvé ne déforme pas ces registres de sélection de segment. Parce que quelque part dans la table des descripteurs, il peut bien y avoir un enregistrement, qui est également le descripteur de segment source pour un processus qui a une base de 0 et une longueur maximale de 2
32 .

Donc, si un module non fiable a pu modifier
CS , ou
DS , ou
ES , ou l'un de ces sélecteurs afin qu'ils commencent à pointer vers ce système d'exploitation d'origine, qui couvre tout votre espace d'adressage, vous pouvez créer un lien mémoire vers ce segment et " sauter hors du bac à sable.
Ainsi, le
client natif a dû ajouter quelques instructions supplémentaires à cette liste interdite. Je pense qu'ils interdisent toutes les instructions comme
mov% ds, es et ainsi de suite. Par conséquent, une fois dans le bac à sable, vous ne pouvez pas modifier le segment auquel se réfèrent certaines choses qui s'y réfèrent. Sur la plate
- forme
x86, les instructions de modification de la table des descripteurs de segment sont privilégiées, mais la modification des
ds, es eux
- mêmes
, etc. La table est totalement sans privilèges.
Public: pouvez-vous initialiser le tableau afin que la longueur nulle soit placée dans tous les emplacements inutilisés?
Professeur: oui. Vous pouvez définir la longueur de la table pour quelque chose où il n'y a pas d'emplacements inutilisés. Il s'avère que vous avez vraiment besoin de cet emplacement supplémentaire contenant 0 et 2
32 , car l'environnement d'
exécution approuvé doit démarrer dans ce segment et accéder à toute la plage de mémoire. Cette entrée est donc nécessaire pour que l'environnement d'
exécution approuvé fonctionne.
Public: de quoi a-t-on besoin pour changer la longueur de la sortie du tableau?
Professeur: vous devez avoir des privilèges root.
Linux a en fait un système appelé
modify_ldt () pour la table de descripteurs locaux, qui permet à tout processus de modifier sa propre table, c'est-à-dire qu'il y a en fait une table pour chaque processus. Mais sur la plate-forme
x86, c'est plus compliqué, il y a à la fois une table globale et une table locale. Une table locale pour un processus spécifique peut être modifiée.
Essayons maintenant de comprendre comment nous sautons et sautons du processus d'exécution de
Native Client ou sortons du bac à sable. Que signifie sauter hors de nous?

Nous devons donc exécuter ce code de confiance, et ce code de confiance «vit» quelque part au-dessus de la limite de 256 Mo. Pour y aller, nous devrons annuler toutes les protections que
Native Client a installées. Fondamentalement, ils se résument à changer ces six sélecteurs. Je pense que notre validateur ne va pas appliquer les mêmes règles pour les choses situées au-dessus de la limite de 256 Mo, donc c'est assez simple.
Mais ensuite, nous devons en quelque sorte sauter dans le
runtime d'exécution de confiance et réinstaller les sélecteurs de segment aux valeurs correctes pour ce segment géant, couvrant l'espace d'adressage de l'ensemble du processus - cette plage va de 0 à 2
32 . Ils ont appelé de tels mécanismes existant dans les
trampolines et tremplins «trampoline»
Native Client . Ils vivent dans un module bas de 64k. Le plus cool est que ces «trampolines» et «sauts» sont des morceaux de code se trouvant dans les 64k inférieurs de l'espace de processus. Cela signifie que ce module peu fiable peut y sauter, car il s'agit d'une adresse de code valide dans les limites de 32 bits et de 256 Mo. Vous pouvez donc sauter sur ce trampoline.
Native Client «» - . ,
Native Client «», trampoline
trusted runtime . ,
DS, CS , .
, , -
malo , «», «» 32- .
, 4096 + 32 , . , ,
mov %ds, 7 ,
ds , 7 0 2
32 .
CS trusted service runtime , 256 .

, , ,
trusted service runtime , . , . DS , , , , - .
, ? , «»? , ?
: 64.
: , , . malo, 64, 32 . , , , .
, 32- , . , , 32 , 32- , . «»
trusted runtime 32 .

. , ,
DS, CS . , 256- ,
trusted runtime , . .
«»,
trusted runtime 256
Native Client . «»
DS , ,
mov %ds, 7 , ,
trusted runtime . . , «», - .
halt 32- «». «», .
trusted service runtime , 1 .
 trusted service runtime
trusted service runtime , , .
: «» ?
: «» 0 256 . 64- , , «», - -.
Native Client .
: ?
: , ? , «»? ?
: , ?
: , -
%eax ,
trusted runtime : «, »!
EAX ,
mov , «»
EAX ,
trusted runtime . , «»?
: , , . …
: , , — , , 0 2
32 . . «», 256 .
, «», . , «» , . , «» .
: «» 256 ?
: , . ,
CS - . «»,
halt , mov,
CS , , 256 .
, , «». ,
DS , ,
CSet sauter quelque part.Probablement, si vous essayiez, vous pourriez trouver une séquence d'instructions x86 qui pourrait le faire en dehors des limites de l'espace d'adressage du module Native Client .Alors, à la semaine prochaine et parlez de la sécurité Web.La version complète du cours est disponible ici .Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbit / s jusqu'en décembre gratuitement en payant pour une période de six mois, vous pouvez commander ici .Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?