Table des matières
Mnémonique est un mot ou une phrase qui nous aide à nous souvenir de quelque chose. Le mnémonique le plus célèbre est «chaque chasseur veut savoir où se trouve le faisan». Celui que vous demandez, tout le monde la connaît.
Mais dans le domaine professionnel, tout est un peu plus triste. Demandez à vos camarades s'ils savent ce qu'est SPDFOT ou RCRCRC. Loin d'un fait ... Mais les mnémoniques nous aident à exécuter les tests, sans oublier de vérifier les plus importants. La liste de contrôle s'est effondrée en une seule phrase!
Des collègues testeurs anglophones utilisent activement les mnémoniques. Un ami qui lit des blogs étrangers dit que les Américains viennent avec eux pour presque tous les éternuements.
Et je pense que c'est super. Les mnémoniques étrangères peuvent ne pas convenir spécifiquement à votre système ou à vos processus. Et le sien, cher, vous rappellera «de ne pas attendre pour vérifier ceci et cela» et limiter le nombre de bugs en production.
Aujourd'hui, je veux partager avec vous mes mnémoniques BMW pour l'étude des valeurs limites. Cela peut être:
- donner junior pour le développement général dans la conception de tests;
- utiliser lors de l'entretien - le candidat résout généralement la tâche «trouver la frontière en nombre», mais trouvera-t-il la frontière dans la ligne ou pour télécharger le fichier?
BMW Mnemonics
B - grand
M - petit
B - juste

C'est facile à retenir. N'oubliez pas cette voiture cool et immédiatement le décryptage est prêt! Mais qu'est-ce que cela signifie et comment cela aidera-t-il dans les entretiens?
Parfaitement

En principe, «juste ce qu'il faut», vous testez sans aucune mnémonique. Nous commençons toujours par des tests positifs pour vérifier que le système fonctionne en principe.
Si le champ est numérique, entrez la valeur commune. Disons que nous avons une boutique en ligne de vente au détail. Dans la quantité de marchandises, nous pouvons vérifier 1 ou 2.
Un test positif - c'est "juste ce qu'il faut". J'ai montré des mnémoniques sous la forme d'une souris. Ici, c'est une taille standard.
Grand
Ensuite, nous disons que la souris doit être gonflée à une taille incroyable, afin qu'elle ne rentre pas directement dans l'image. Et voyez comment le système fonctionnera avec.

Dans ce cas, nous allons simplement «loin en avant». TRÈS LOIN La grosse souris représente une recherche d'une frontière technologique quelque part, en dehors d'une frontière arbitraire.
Pour saisir la quantité de marchandises, ce sera "999999999999999999999999999999999999999999999999999999999999 ...". Pas seulement une grande valeur (9999), mais TRÈS grande. Souvenez-vous de la souris - elle a tellement explosé qu'elle ne rentre même pas dans l'image.
La différence est importante, une grande importance aidera à trouver une frontière arbitraire, et une énorme aidera à trouver une frontière technologique. Le test pour "grand" est souvent effectué, pour "énorme" - non. Mnemonics se souvient précisément de lui.
Petit
On perce la souris, et elle est emportée à une taille microscopique.

La petite souris est une recherche de valeurs proches de zéro. La plus petite valeur positive.
Qu'en est-il du test pour "0.00000001"? Vérifié pour zéro, mais n'oubliez pas de creuser côte à côte.
Et qu'y a-t-il?
Cela semble dire des choses évidentes. Il semble que tout le monde le sait déjà. Donnez juste une interview sur une tâche numérique, le même triangle (une
tâche de Myers ), et vous comprenez que ce n'est pas le cas ... Très peu de gens iront chercher une frontière technologique ou essayer d'entrer une valeur fractionnaire proche de zéro. Maximum zéro et proposera de vérifier.
Et si vous proposez de NE PAS tester un nombre, alors c'est une stupeur encore plus grande. Avec le nombre, d'accord, on a vérifié zéro et la bordure selon l'énoncé des travaux, c'est déjà pas mal. Et dans la ligne quoi tester? Et dans le dossier?
Je veux en parler dans l'article. Comment pouvez-vous utiliser des mnémoniques dans la vraie vie et en même temps attraper des bugs. Commençons par des exemples courants - que l'on retrouve sur chaque projet. Et qui peut être donné lors de l'entretien sous la forme d'une petite tâche.
Et puis je vais raconter des exemples de mon travail. Oui, ils sont spécifiques. Oui, il s'agit de technologies spécifiques. Et alors? Mais ils montrent comment appliquer des mnémoniques dans des endroits plus complexes.
Le sens est le même: les frontières sont presque partout. Il suffit de trouver le nombre et de l'expérimenter. Et n'oubliez pas les mnémoniques BMW, car c'est sur B et M que l'on rencontre souvent des bugs.
Exemples courants
Exemples qui se trouvent dans n'importe quel projet: un champ numérique, une chaîne, une date ... Nous considérerons dans cet ordre:
Numéro
- 10
- 0,00000001
- 999999999999999999999999 ....
Dites une boîte avec le nombre de livres, de robes ou de paquets de jus. Comme test positif, nous choisissons une quantité adéquate: 3, 5, 10.
En tant que petite valeur, sélectionnez aussi près de zéro que possible. N'oubliez pas que la souris doit être très petite. Ce n'est pas seulement une unité, mais la Nième décimale. Soudain, il arrondira à zéro et quelque part dans les formules plantera? De plus, sur le chiffre «1», tout fonctionnera bien.
Eh bien, le maximum est atteint en entrant 10 millions de neuf. Générez une telle chaîne en utilisant des outils comme Perlclip, et allez-y, testez TRÈS beaucoup!
Voir aussi:Classes d'équivalence pour une chaîne qui dénote un nombre - encore plus d'idées pour les tests de chaînes numériques
Comment générer une grande chaîne, outils - aide à générer une grande valeur
Date
- 26/05/2017
- 01/01/1900
- 21/12/003
Une date positive est «aujourd'hui» si nous envoyons le rapport à une certaine date. Ou votre propre date de naissance, si nous parlons de DR, ou d'une autre qui convient à votre processus commercial.
Comme petite date, nous prenons la date magique "01/01/1900", à laquelle les applications se désagrègent souvent. A partir de cette date, le temps commence dans Excel. Il se glisse également dans les applications. Vous exposez ce nombre magique - et le rapport s'effondre, même s'il existe une protection contre le fou aux zéros. Je le recommande donc fortement pour vérification.
Si nous parlons d'une très petite souris, vous pouvez toujours cocher "00.00.0000". Ce sera un contrôle zéro, ce qui est également important. Mais les développeurs sont plus souvent protégés d'un tel idiot qu'à partir du 01/01/1900.
Far Ahead peut également être différent. Vous pouvez entrer dans un négatif et vérifier une date ou un mois qui n'existe vraiment pas: 40/05/2018. Ou recherchez la frontière technologique en utilisant la date 99.99.9999. Et vous pouvez prendre un peu plus de valeur réelle, qui ne viendra tout simplement pas bientôt: 2400 ou 3000.
Voir aussi:Classes d'équivalence pour une chaîne qui dénote une date - encore plus d'idées pour tester une date

String
- Vasya
- (un espace)
- (Il y avait beaucoup de texte)
Disons que lors de l'inscription, il y a un champ avec un nom. Un test positif est un nom commun: Olga, Vasya, Peter ...
Lors de la recherche d'une petite souris, nous prenons une ligne vide ou un hack de vie: un ou deux espaces. Dans ce cas, la ligne reste vide (il n'y a pas de caractères), mais elle semble remplie.
Quel est l'objectif lors de la recherche d'une grosse souris? Lorsque nous testons une grande chaîne, nous devons tester la GRANDE chaîne! Rappelez-vous que la souris doit être GRANDE. Parce que j'explique généralement aux étudiants comment tout cela fonctionne, comment chercher une frontière technologique, etc. Et puis ils me donnent DZ et écrivent "J'ai vérifié 1000 caractères - il n'y a pas de frontière technologique."
21 siècle dans la cour, eh bien, qu'est-ce que 1000 caractères? Nous prenons n'importe quel outil qui nous permet d'en générer 10 millions et d'en insérer 10. Maintenant, ce sera la recherche d'une frontière technologique. Et il y a déjà des bugs à ce sujet, le système peut se casser. Mais 1000 caractères? Non.
Voir aussi:Comment générer une grande chaîne, outils - aide à générer une grande valeur
Mais ok, tout est clair ici aussi. Et que se passera-t-il si nous testons le fichier?
Fichier
Où puis-je trouver un numéro dans un fichier?
Tout d'abord, le fichier a sa taille:
Lors du test d'un fichier volumineux, ils essaient généralement quelque chose comme 30 Mo, et ils se calment à ce sujet. Et puis vous chargez 1 Go - et c'est tout, le serveur se fige.
Bien sûr, si vous êtes un débutant et que vous testez de l'expérience sur un vrai site, vous ne devez pas le charger à l'insu du propriétaire. Mais lorsque vous testez au travail, assurez-vous de vérifier la grosse souris.
Deuxièmement, le fichier a un nom → et c'est la longueur de la ligne que nous venons de discuter.
Mais le fichier a aussi son contenu! Il y a un certain nombre de colonnes (colonnes) et de lignes. Tests en ligne:
- 5 lignes
- 1 rangée
- 10000000000 de lignes
Et ici, le plaisir commence. Parce que même dans le même Excel dans différentes versions, il existe différentes restrictions sur le nombre de lignes qu'il prend en charge:
- Excel en dessous de 97-16 384
- Excel 97-2003 - 65 536
- Excel 2007 - 1 048 576
Mais quand même les chiffres sont assez importants, ce n'est pas intéressant. Mais l'ancien exel n'a pas ouvert plus de 256 dans les colonnes, et c'est une sérieuse limitation:
- Excel 2003 - 256
- Excel 2007 - 16 385
Son frère libre, LibreOffice, ne peut pas ouvrir plus de 1024 colonnes.

Histoire de vie
Nous écrivons quelques autotests au format CSV. A l'entrée de la table, à la sortie de la table. Ouvrez et modifiez dans LibreOffice pour voir où se trouve la colonne. Tout est super, tout fonctionne. Alors que le nombre de colonnes ne sort pas pour 1024.
C'est là que commence la douleur de la vie. Le test LibreOffice ne s’ouvrira plus, au format CSV, il est gênant, car il est difficile de comprendre où se trouve la colonne 555. Vous ouvrez le test dans Excel, éditez, enregistrez, lancez le test ... Il tombe à 10 nouveaux endroits: le TIN a mal tourné. Il est long, par exemple, 7710152113. Excel le traduit volontiers au format 1.2E + 5.
D'autres numéros longs sont également perdus.
Si la valeur était entre guillemets, elle est entourée de guillemets supplémentaires auxquels le test ne s'attend pas.
Et vous corrigez déjà ces petites choses au format CSV, en vous réprimandant mentalement Excel ... Il y a donc une limitation, il faut s'en souvenir! Bien qu'il n'apparaisse pas sur le système lui-même, il peut simplement compliquer la vie du testeur.
Table dans Oracle (base de données)
Et puisque nous parlons de 1024 colonnes, nous nous souviendrons d'Oracle (une base de données populaire). Il y a la même restriction: dans une table, il peut y avoir un maximum de 1024 colonnes.
Il vaut mieux s'en souvenir à l'avance! Nous avions une table dans laquelle il y avait environ 1000 colonnes, mais la moitié était réservée pour l'avenir: «un jour, cela nous sera utile, cela nous suffira longtemps.» Assez, mais pas pour longtemps ...
Nulle part où étendre la table - a rencontré une limitation. Donc, soit divisez la table en deux, soit emballez le contenu dans un BLOB: c'est quelque chose qu'une archive zip avec des données s'avère occuper une colonne, mais à l'intérieur elle en contient autant que vous le souhaitez.
Mais en tout cas, c'est la migration des données. Et la migration des données est toujours pénible. Sur une grande base, cela prend beaucoup de temps, pose de nouveaux problèmes qui ne peuvent être abattus qu'en six mois ... Brrr! Si vous pouvez vous passer de la migration, il vaut mieux le faire.
Si vous avez un tableau avec BEAUCOUP de données, pensez à l'avenir. Serez-vous toujours en 1024 colonnes? Devrez-vous migrer plus tard? Après tout, plus le système dure longtemps, plus le transfert sera difficile. Et «assez pour 5 ans» signifie qu'un volume de cinq ans devra être migré.
Comment le tester? Oui, par code, évaluez vos tableaux de données, regardez où ils se trouvent. Faites attention à la grosse souris: ces tables qui ont déjà beaucoup de colonnes. Y aura-t-il des problèmes à l'avenir?
Rapport dans le système
Mais pourquoi téléchargeons-nous des fichiers sur le système ou pompons-nous des données depuis Oracle? Très probablement afin de construire une sorte de rapport. Et ici, vous pouvez également appliquer ces mnémoniques.
Les données peuvent être à la fois en entrée (beaucoup, un peu, juste à droite) et en sortie! Et cela est également important, car ce sont des classes d'équivalence différentes.
En conséquence, nous testons la quantité:
- colonnes de rapport
- lignes
- données d'entrée;
- données de sortie (dans le rapport lui-même).
Structure (colonnes et lignes)Pouvons-nous influencer le nombre de lignes ou de colonnes? Parfois oui, nous le pouvons. Lors du deuxième travail, j'ai testé le concepteur de rapports: à gauche, vous avez des cubes avec les noms des paramètres que vous pouvez lancer horizontalement ou verticalement dans le rapport lui-même. C'est-à-dire que vous décidez du nombre de lignes et du nombre de colonnes.
Appliquez des mnémoniques. Après un rapport standard (test positif, souris "juste à droite") nous essayons de faire un peu:
- 1 colonne, 0 lignes;
- 0 colonnes, 1 ligne;
- 1 colonne, 1 ligne.
Et puis beaucoup:
- colonnes maximum, 1 ligne (tous les cubes sont jetés dans les colonnes);
- lignes maximum, 1 colonne;
- si les cubes peuvent être dupliqués, puis ça et là au maximum, mais c'est douteux;
- maximum de niveaux imbriqués (c'est lorsque deux autres sont dans une colonne d'agrégateur).
Ensuite, nous testons les données d'entrée et de sortie. Nous pouvons les influencer dans n'importe quel rapport, même s'il n'y a pas de constructeur et que le nombre de lignes et de colonnes est toujours le même.
Entrer les donnéesNous découvrons comment le rapport est formé. Supposons que chaque jour, certaines données soient renseignées, par exemple le nombre de robes vendues, de robes d'été, de t-shirts. Et dans le rapport, nous voyons un regroupement de données par catégories, couleurs, tailles. Combien est vendu par jour / mois / heure.
Nous construisons un rapport, et nous influençons nous-mêmes les données d'entrée:
- Le nombre habituel (5 robes par jour, bien que sur des sites énormes ce nombre puisse être 2000 ou plus, vous devez clarifier ce qui sera le plus positif pour votre système).
- Vide, n'a pas vendu / vendu 1 article par mois.
- Le volume est irréaliste, avec un maximum de chaque produit, chaque couleur, chaque taille. Nous fixons le maximum de «mensonges dans l'entrepôt» et vendons tout: en un mois voire un jour. Que diront les reportages?
Données de sortieEn théorie, les données de sortie sont en corrélation avec les données d'entrée. A l'entrée un peu → à la sortie il y en aura un peu. A l'entrée il y en a beaucoup - à la sortie il y en a beaucoup.
Mais cela ne fonctionne pas toujours. Parfois, les données d'entrée peuvent être éliminées ou, inversement, multipliées. Et puis nous pouvons en quelque sorte jouer avec.
Par exemple, le système
Dadat . Vous téléchargez un fichier avec une colonne de nom complet, à la sortie, vous obtenez plusieurs à la fois:
- Nom d'origine, ce qui était dans le dossier;
- Nom démonté (si vous pouviez distinguer);
- Rod cas;
- Dat cas;
- Creat. cas;
- Nom de famille
- Prénom;
- Deuxième prénom;
- Statut d'analyse - reconnaissance sûre par un mécanisme ou vérifiée par une personne;

Nous avons obtenu 9. D'une cellule. Et ce n'est que par nom, et le système peut également analyser les adresses. Là, près de 50 sont obtenus à partir d'une cellule: en plus des composants granulaires, il existe toutes sortes de codes KLADR, FIAS, OKATO ...
Et ici c'est intéressant. Il s'avère que nous pouvons avoir peu de données à l'entrée, mais beaucoup à la sortie. Et si nous examinons le maximum en colonnes, nous avons deux options:
- 500 colonnes en sortie (soit environ 10 adresses en entrée);
- 500 colonnes à l'entrée (et tout un tas à la sortie).
Le principe fonctionne également en sens inverse. Que se passe-t-il si l'entrée est un tas de données et la sortie est zilch? Si au lieu d'un nom complet, il y a une sorte de non-sens comme "op34e8n8pe"? Ensuite, il s'avère que toutes les colonnes supplémentaires sont vides, seul le statut de l'analyse "vous m'avez envoyé des ordures". Nous obtenons donc un minimum à la sortie (une petite souris), ce qui vaut également la peine d'être vérifié.
Et si les enceintes peuvent être exclues! Il est possible de vérifier la classe d'équivalence «zéro» lorsque le zéro est en sortie, le fichier source n'est pas vide. Vous pouvez vérifier au moins quand ils ont laissé 1 colonne sur cent.
L'essentiel ici est de se rappeler qu'en plus des données d'entrée, nous avons des données de sortie. Et parfois, vous pouvez vérifier les limites, qui ne dépendront pas des données d'entrée. Et puis cela doit être fait.
Applications mobiles
La communication
Il existe différentes options de communication:
- Normal
- Très figue (petite souris);
- Super rapide (grand).
De plus, une mauvaise communication peut être partiellement: si vous êtes dans une zone avec une connexion Wi-Fi normale et un réseau cellulaire pauvre. Internet fonctionne bien, mais le SMS est mauvais.
Quantité de mémoire
Il est également important de disposer de la mémoire de l'application:
- Montant normal;
- Très peu;
- Beaucoup.
Et si dans ce cas les premier et troisième tests dans ce cas peuvent être combinés, alors la petite souris est très intéressante. Et il existe différentes options:
- exécutez l'application sur le téléphone, qui a déjà peu de mémoire;
- exécuter lorsque la mémoire est normale, s'effondrer, déployer quelque chose de grand, essayer de revenir à la première application.
Maintenant, si l'application ne sait pas comment réserver normalement de la mémoire, alors dans le deuxième cas, elle se bloquera simplement, alors la mémoire a déjà été pressée.
Diagonale de l'appareil
- Standard (nous étudions le marché, regardons ce qui est le plus populaire parmi nos utilisateurs).
- Minimum (téléphone).
- Maximum (grande tablette).
Résolution d'écran
- Standard;
- Le plus petit;
- Le plus gros;
Ne confondez pas la résolution et la diagonale, ce sont deux choses différentes. Vous avez peut-être un ancien appareil avec un grand écran, mais j'ai un nouveau smartphone à la mode, où la résolution est 5 fois meilleure. Et ce qui se passera dans 20 ans est effrayant à imaginer.
Chemins GPX
Les chemins GPX sont des fichiers XML avec des coordonnées séquentielles. Ils peuvent être téléchargés sur des émulateurs mobiles afin que le téléphone pense qu'il se déplace dans l'espace à une certaine vitesse.
Utile si l'application lit les coordonnées GPS pour certains de ses objectifs. Il détermine donc lui-même si vous partez, courez ou roulez. Et vous ne pouvez pas courir, il suffit d'alimenter les coordonnées de l'application, de définir le coefficient de leur passage et de tester en étant assis au bureau.
Quelles chances valent la peine de vérifier? Tout selon les mnémoniques:
- 1 - coefficient normal, remplace la marche simple;
- 0,01 - comme si vous glissiez meeeeeeeeeeeeeeeeeeeeeeeballyly;
- 200 - ne courez même pas, mais volez!
Pourquoi tout cela devrait-il être vérifié? Quels bogues peuvent être trouvés?
Par exemple, l'application peut se bloquer dans l'avion - elle s'est lancée, mais elle s'est immédiatement effondrée. Puisqu'il lit les coordonnées et essaie de déterminer votre vitesse. Mais qui savait que la vitesse serait supérieure à 130?
À faible vitesse, l'application peut se bloquer. Il se fixera un million de points intermédiaires et ne pourra pas les garder en mémoire. Et c'est tout!
Voir aussi:Quels sont les chemins GPX et pourquoi ont-ils besoin d'un testeur? - plus sur les chemins gpx et un exemple d'un tel fichier
Résumé des exemples courants
Je veux montrer ici qu’il semblerait que «grand, petit» est un champ numérique et c’est tout!
Mais en fait, les mnémoniques peuvent être utilisés partout, que ce soit des fichiers, des jouets, des rapports ... Et cela nous aide vraiment à trouver des bugs. Voici quelques exemples de ma pratique:Petite souris (borne inférieure)- Date 01/01/1900Quand j'ai travaillé en freelance, cette date a ruiné tous les rapports pour moi. Parce que même si le développeur a défini la protection contre le fou, il a défini la protection à partir de 0000. Mais il n'a pas défini la protection à partir de 1900.- Un personnage solitaire en fin de ligneCe test m'a été suggéré par un collègue plus expérimenté lorsque nous avons discuté d'exemples d'utilisation de mnémoniques. Si le système vérifie que le fichier est vide, il est nécessaire de vérifier qu'il n'est pas complètement vide.Je recommande ce test: ajoutez un terminateur de ligne au fichier. Pas même un espace, mais un caractère spécial. Et voyez comment le système réagit. Et elle ne répond pas toujours bien =)Big mouse (borne supérieure)Si nous parlons d'une grosse souris, il y a généralement un nombre infini de bugs:- Guerre et paix;- Beaucoup de données;- 2 Go.Vous pouvez télécharger guerre et paix dans un champ de texte, télécharger un énorme fichier sur le système, obtenir beaucoup de données en entrée ou en sortie. Ce sont toutes des erreurs courantes que j'ai rencontrées dans ma pratique. Et pas seulement moi, la limite supérieure est souvent vérifiée simplement parce qu'ils savent qu'il peut y avoir des bugs. Ils oublient plutôt la petite souris.Un autre exemple d'une grosse souris est le test de résistance. Oh!
J'ai de tels exemples, alors nous allons au hardcore.Si vous connaissez le contexte, si vous savez comment votre application fonctionne à l'intérieur, dans quel langage de programmation elle est écrite, dans quelle base de données elle utilise, vous pouvez également utiliser ce mnémonique. Et je veux montrer cela avec des exemples concrets.Mes exemples de pratique
Grosse souris
Linux, Lucene, Mmap
Dans le système d'exploitation Linux, il existe un paramètre pour le nombre maximal de descripteurs de fichiers ouverts:- redhat-6 - /etc/security/limits.conf
- redhat-7 - / etc / systemd / system / [nom du service] .service.d / limits.conf (pour chaque service qui lui est propre)
Un descripteur de fichier est ouvert pour toute action avec des fichiers:- créer une connexion à la base de données;
- lire le fichier;
- écrire dans un fichier.
- ...
Si votre système fonctionne activement avec des fichiers et effectue de nombreuses opérations, le paramètre doit être augmenté. Sinon, la moindre charge vous mettra.Notre système utilise l'index de recherche Lucene. C'est à ce moment que nous prenons des données de la base de données et les téléchargeons sur le disque, afin que nous puissions les rechercher plus rapidement plus tard. Et si nous construisons l'index en utilisant la technologie mmap, alors il crée beaucoup de fichiers pour l'écriture pendant la construction de l'index.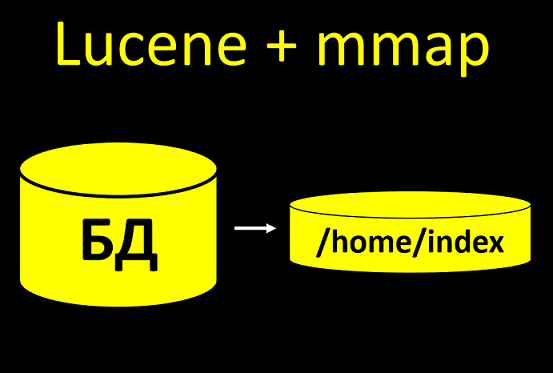 La base de test compte généralement 100 clients, enfin, 1000. Pas tellement. La reconstruction s'exécute sans problème, même si vous ne configurez pas les descripteurs.Et dans le système réel, il y aura plus de 10 millions de clients. Et si vous ne configurez pas le nombre de descripteurs de fichiers là-bas, alors lorsque vous commencez à créer des index, tout se bloquera.Vous devez le savoir et écrire immédiatement une instruction: configurer le système d'exploitation sur le serveur, sinon il y aura telle ou telle conséquence. Et de son côté, il est important d'effectuer non seulement des tests fonctionnels, mais aussi des tests de stress, sur une quantité réelle de données.
La base de test compte généralement 100 clients, enfin, 1000. Pas tellement. La reconstruction s'exécute sans problème, même si vous ne configurez pas les descripteurs.Et dans le système réel, il y aura plus de 10 millions de clients. Et si vous ne configurez pas le nombre de descripteurs de fichiers là-bas, alors lorsque vous commencez à créer des index, tout se bloquera.Vous devez le savoir et écrire immédiatement une instruction: configurer le système d'exploitation sur le serveur, sinon il y aura telle ou telle conséquence. Et de son côté, il est important d'effectuer non seulement des tests fonctionnels, mais aussi des tests de stress, sur une quantité réelle de données.Redhat 6 ≠ Redhat 7
Lorsque vous testez une grosse souris (charge), n'oubliez pas que dans différentes configurations, l'application fonctionnera différemment. Si vous prenez les instructions du dernier paragraphe, il faut non seulement les écrire, mais aussi les vérifier. Et vérifiez dans l'environnement du client.Parce que différents systèmes d'exploitation fonctionnent différemment. Et nous avons eu une telle situation que tout semble être configuré, mais le système se bloque et dit "Je n'ai pas assez de descripteurs de fichiers ouverts". Nous disons:- Vérifiez le paramètre.- Il est configuré, tout est selon vos instructions!Comment ça?
Il s'avère que nous avons des instructions pour Redhat 6, et ils ont Redhat 7, où le réglage est dans un endroit complètement différent! En conséquence, ils l'ont fait selon des instructions qui ne fonctionnaient pas et comme s'ils ne l'avaient pas fait du tout.Donc, si vous travaillez avec différentes versions des distributions Linux, vous devez toutes les vérifier. Et non seulement déployez les services sur une machine, mais effectuez également des tests de charge au moins une fois: assurez-vous que tout fonctionne. Après tout, il est préférable d'attraper un bogue dans un environnement de test que de comprendre la production plus tard.Java et ramassage des ordures
Nous utilisons le langage java, qui a un récupérateur de place intégré ... Parfois, il semble que si l'application utilise beaucoup de mémoire et est sur le point de OOM (Out of Memory) pour une opération complexe, vous pouvez résoudre ce problème facilement en augmentant simplement la quantité de mémoire disponible ! Pourquoi tester?Pas vraiment. Donnez beaucoup de Xmx - l'application va s'accrocher au garbage collector ... Et elle se manifeste très soudainement pour l'utilisateur. Ici la nuit, ils ont déposé une grosse charge, téléchargé beaucoup de données - surtout après les heures, afin de ne déranger personne. Le matin, l'utilisateur arrive, alors qu'il est le seul à travailler avec le système, il n'y a presque pas de charge et tout gèle. Et il ne comprend même pas pourquoi.Mais en fait, la charge est passée, la charge est partie, et le ramasse-miettes est sorti pour tout nettoyer, à cause de cette frise. Et bien qu'il n'y ait plus de charge et qu'un utilisateur solitaire travaille, il est triste.Par conséquent, il suffit d'allouer beaucoup de mémoire à l'application "et vous ne pouvez pas la tester" - cela ne fonctionne pas. Mieux vaut vérifier.
Et elle se manifeste très soudainement pour l'utilisateur. Ici la nuit, ils ont déposé une grosse charge, téléchargé beaucoup de données - surtout après les heures, afin de ne déranger personne. Le matin, l'utilisateur arrive, alors qu'il est le seul à travailler avec le système, il n'y a presque pas de charge et tout gèle. Et il ne comprend même pas pourquoi.Mais en fait, la charge est passée, la charge est partie, et le ramasse-miettes est sorti pour tout nettoyer, à cause de cette frise. Et bien qu'il n'y ait plus de charge et qu'un utilisateur solitaire travaille, il est triste.Par conséquent, il suffit d'allouer beaucoup de mémoire à l'application "et vous ne pouvez pas la tester" - cela ne fonctionne pas. Mieux vaut vérifier.Wildfly
Le serveur d'applications java WildFly ne permettra pas de télécharger des fichiers volumineux s'il n'est pas configuré en conséquence. Nous utilisons le serveur d'application Jboss, alias Wildfly. Et il s'avère que par défaut, vous ne pouvez pas y télécharger de gros fichiers. Et nous nous souvenons que la souris doit être GRANDE. Si nous testons 5 Mo ou 50, tout fonctionne, tout va bien.Mais si vous essayez de télécharger 2 Go, le système génère une erreur 404 et vous ne pouvez rien comprendre des journaux: les journaux de l'application sont vides. Étant donné que cette application ne peut pas télécharger un fichier, Wildfly le coupe lui-même.Si vous n'effectuez pas de tests de votre côté, le client peut rencontrer ce problème. Et ce sera très désagréable, il viendra avec la question "Pourquoi n'est-il pas chargé?", Et sans le développeur vous ne pouvez rien dire. Par conséquent, il est préférable de ne pas oublier de tester les limites, y compris les gros fichiers à insérer dans le système. Au moins, vous saurez le résultat de telles actions.Et ici, soit nous le corrigeons en augmentant le paramètre max-post-size, soit nous donnons des informations sur la restriction et la prescrivons dans l'énoncé des travaux.
Nous utilisons le serveur d'application Jboss, alias Wildfly. Et il s'avère que par défaut, vous ne pouvez pas y télécharger de gros fichiers. Et nous nous souvenons que la souris doit être GRANDE. Si nous testons 5 Mo ou 50, tout fonctionne, tout va bien.Mais si vous essayez de télécharger 2 Go, le système génère une erreur 404 et vous ne pouvez rien comprendre des journaux: les journaux de l'application sont vides. Étant donné que cette application ne peut pas télécharger un fichier, Wildfly le coupe lui-même.Si vous n'effectuez pas de tests de votre côté, le client peut rencontrer ce problème. Et ce sera très désagréable, il viendra avec la question "Pourquoi n'est-il pas chargé?", Et sans le développeur vous ne pouvez rien dire. Par conséquent, il est préférable de ne pas oublier de tester les limites, y compris les gros fichiers à insérer dans le système. Au moins, vous saurez le résultat de telles actions.Et ici, soit nous le corrigeons en augmentant le paramètre max-post-size, soit nous donnons des informations sur la restriction et la prescrivons dans l'énoncé des travaux.Journalisation
Un autre exemple pour tester la "grosse" souris. Oui, elle se rappelle en quelque sorte plus d'exemples ... Plus souvent qu'autrement, elle attrape des bugs!Disons que nous vérifions la journalisation des erreurs. Que l'erreur est écrite dans la trace de pile dans le journal. Alors on a vérifié, on est super: oui, tout est cool, tout est enregistré! Et j'ai tout compris de la pile sur le texte d'erreur. Si le client tombe, je comprendrai immédiatement pourquoi. Et que se passera-t-il si nous n'avons pas une erreur, mais plusieurs? Tout va bien aussi, tout est enregistré, tout va bien! Mais nous nous souvenons que la souris doit être GRANDE:
Et que se passera-t-il si nous n'avons pas une erreur, mais plusieurs? Tout va bien aussi, tout est enregistré, tout va bien! Mais nous nous souvenons que la souris doit être GRANDE: que se passera-t-il si nous avons BEAUCOUP d'erreurs? Nous venons d'avoir cette situation. Le système source télécharge les données dans la table tampon de la base de données. Notre système prend ces données à partir de là et fonctionne d'une manière ou d'une autre avec elles.Le système source s'est écrasé et il a téléchargé un incrément incorrect, où toutes les données étaient erronées. Notre système a pris l'incrément et il y a 13 600 erreurs. Et lorsque Java a tenté de générer une trace de pile pour les erreurs de 13 Ko, elle a mangé toute la mémoire qui lui était allouée, puis a dit «Oh, jeap heap space».Comment y remédier? Nous avons ajouté le paramètre maxStoredErrors (100 par défaut) à la tâche de chargement - le nombre maximal d'erreurs stockées en mémoire pour un flux. Une fois ce montant atteint, les erreurs sont enregistrées et la liste est effacée.Nous avons également supprimé la duplication des messages d'erreur sur l'exécution d'une tâche par notre tâche et Quarz RunShell, augmentant le niveau de journalisation de ce dernier pour avertir (le message est affiché dans info). En raison de la duplication, la pile a doublé ...Et quelle est la conclusion de cette histoire? Il ne suffit pas de cocher «juste». C'est un test important et utile, oui, personne ne le conteste. Nous regardons si l'erreur est enregistrée en principe, dans quel test, etc. Mais alors il est très important de vérifier la GRANDE souris. Que se passe-t-il s'il y a beaucoup d'erreurs?Et vous devez comprendre que "beaucoup" - cela signifie beaucoup. Si vous chargez un incrément de 10 erreurs et dites que "10 erreurs sont également normales, le système affiche toutes les traces de pile", il semble qu'ils aient fait les tests, mais ils n'ont pas révélé le problème. Si nous voyons que le système affiche tous les messages, nous devons penser à l'avance: que se passera-t-il s'il y en a BEAUCOUP? Et regardez.
que se passera-t-il si nous avons BEAUCOUP d'erreurs? Nous venons d'avoir cette situation. Le système source télécharge les données dans la table tampon de la base de données. Notre système prend ces données à partir de là et fonctionne d'une manière ou d'une autre avec elles.Le système source s'est écrasé et il a téléchargé un incrément incorrect, où toutes les données étaient erronées. Notre système a pris l'incrément et il y a 13 600 erreurs. Et lorsque Java a tenté de générer une trace de pile pour les erreurs de 13 Ko, elle a mangé toute la mémoire qui lui était allouée, puis a dit «Oh, jeap heap space».Comment y remédier? Nous avons ajouté le paramètre maxStoredErrors (100 par défaut) à la tâche de chargement - le nombre maximal d'erreurs stockées en mémoire pour un flux. Une fois ce montant atteint, les erreurs sont enregistrées et la liste est effacée.Nous avons également supprimé la duplication des messages d'erreur sur l'exécution d'une tâche par notre tâche et Quarz RunShell, augmentant le niveau de journalisation de ce dernier pour avertir (le message est affiché dans info). En raison de la duplication, la pile a doublé ...Et quelle est la conclusion de cette histoire? Il ne suffit pas de cocher «juste». C'est un test important et utile, oui, personne ne le conteste. Nous regardons si l'erreur est enregistrée en principe, dans quel test, etc. Mais alors il est très important de vérifier la GRANDE souris. Que se passe-t-il s'il y a beaucoup d'erreurs?Et vous devez comprendre que "beaucoup" - cela signifie beaucoup. Si vous chargez un incrément de 10 erreurs et dites que "10 erreurs sont également normales, le système affiche toutes les traces de pile", il semble qu'ils aient fait les tests, mais ils n'ont pas révélé le problème. Si nous voyons que le système affiche tous les messages, nous devons penser à l'avance: que se passera-t-il s'il y en a BEAUCOUP? Et regardez.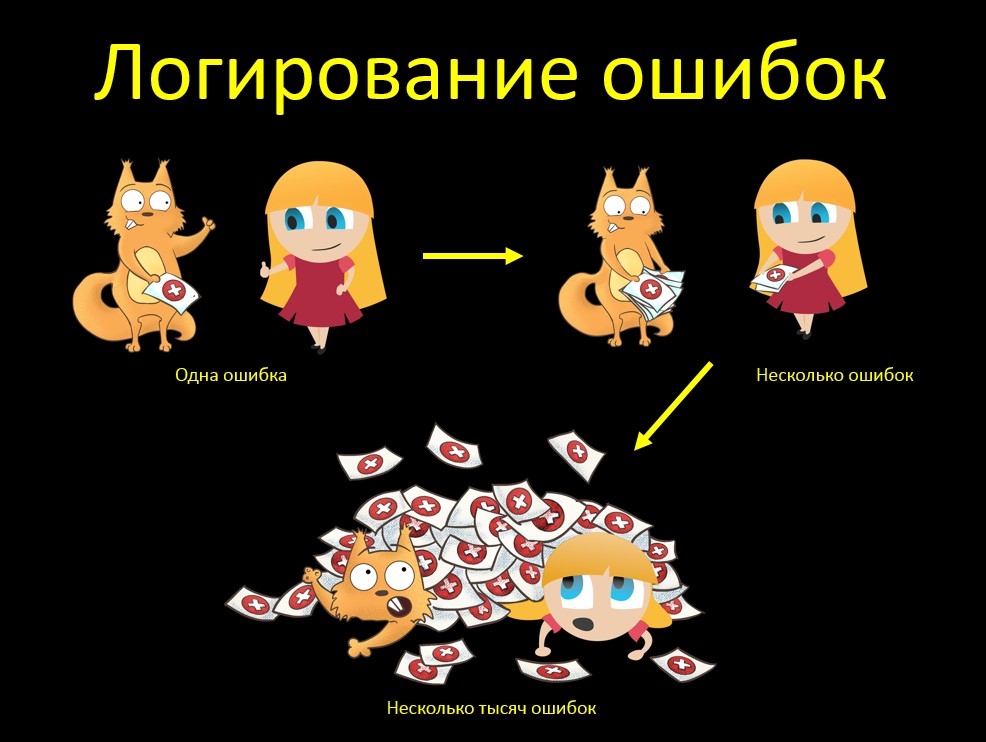
Translittération
Si vous avez une sorte de principe de translittération, vous pouvez essayer de le découvrir, mais comment fonctionne-t-il même à l'intérieur? S'il transcrit deux lettres en une seule, que se passera-t-il si nous introduisons trois lettres ou quatre lettres identiques?OO = ULLC =? Et que se passera-t-il si nous en introduisons beaucoup? Il est possible que le système commence à trier les options et entame une récursion infinie, puis se fige. Vérifiez donc la longue chaîne:OoooOOOoooOOOooOOOOooOOooOOOoooooOOOooooElle application se bloque bien, si les développeurs ne prennent pas en compte les options de cycle sans fin « oo »
Et que se passera-t-il si nous en introduisons beaucoup? Il est possible que le système commence à trier les options et entame une récursion infinie, puis se fige. Vérifiez donc la longue chaîne:OoooOOOoooOOOooOOOOooOOooOOOoooooOOOooooElle application se bloque bien, si les développeurs ne prennent pas en compte les options de cycle sans fin « oo »
Oracle RAC
Oracle est une base de données populaire. Oracle RAC est lorsque vous avez plusieurs instances de base de données. Il est nécessaire de garantir le bon fonctionnement des systèmes critiques de l'entreprise: même si une instance est cassée, les autres continuent de fonctionner, l'utilisateur n'en sera même pas informé.
Si vous utilisez Oracle RAC - il est OBLIGATOIRE d'effectuer des tests de charge sur celui-ci. Si vous ne l'avez pas, vous devez demander au client avec qui il se trouve d'effectuer la charge sur le côté.
Ici, la question peut se poser - pourquoi alors ne l'avez-vous pas? C'est simple, le matériel de test est généralement toujours pire. Et si le système se concentre uniquement sur Oracle et que RAC utilise un client sur vingt, l'acheter pour les tests ne sera pas rentable, car RAC est très cher. Il est plus facile de négocier avec un client et de l'aider à effectuer des tests.
Que se passe-t-il si le test de charge n'est pas effectué? Voici un exemple tiré de la vie.
Dans la base de données, il est possible de créer une colonne et de dire qu'il s'agit d'un champ à incrémentation automatique. Cela signifie que vous ne remplissez pas du tout le champ; la base de données le génère. Il y a une nouvelle ligne? J'ai enregistré la valeur "1". Une autre nouvelle ligne? Elle aura une valeur de "2". Et chaque nouvelle valeur sera de plus en plus.
Ainsi, par exemple, il est très pratique de générer des identifiants. Vous savez toujours que votre identifiant est unique. Et pour chaque nouvelle ligne, c'est plus que pour la précédente. En théorie ...
Nous avons deux identifiants d'entité dans notre système:
- id - identifiant d'une version spécifique, champ d'incrémentation automatique;
- hid est un identifiant historique; pour une entité, il est toujours constant et ne change pas.
En conséquence, vous pouvez sélectionner en fonction d'une version spécifique, ou vous pouvez sélectionner par le cache d'une entité et voir son historique complet.
Lorsqu'une entité est créée, id = hid. Et puis l'id augmente, il est toujours plus grand pour les nouvelles versions que caché. Par conséquent, la formule pour déterminer la version:
version = (id - caché) + 1Il ne peut pas être négatif, car id est créé par la base de données elle-même.
Mais ici, ils viennent à nous avec une question en substance et montrent les enregistrements de la base de données. Je ne me souviens pas de la raison de cette question, et cela n'a pas d'importance. Je regarde les enregistrements et je n'en crois pas mes yeux: là, la version a des valeurs négatives. Comment ça ?? C'est impossible. Cela s'est avéré possible.
Dans RAC, chaque nœud a son propre cache. Et il peut arriver que les nœuds n'aient pas le temps de se notifier et que vous ayez deux fois le même numéro dans la tablette:
- Crée une entité. Noda regarde dans le cache, quelle est la dernière valeur du champ d'incrémentation automatique? Oui, 10. Je vais donc donner l'identifiant 11.
- Immédiatement, une nouvelle entité arrive au deuxième nœud (les demandes sont arrivées simultanément et l'équilibreur en a lancé une au nœud 1 et la seconde au nœud 2).
- Le deuxième nœud regarde dans son cache, quelle est la dernière valeur du champ? Oui, 10 (le premier nœud n'a pas encore réussi à informer le second qu'il a pris ce numéro). Je vais donc donner l'identifiant 11.
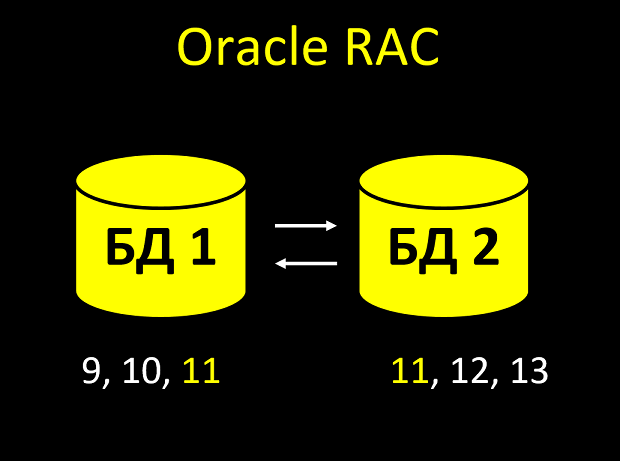
Au total, nous recevons la valeur non unique d'un champ unique. Et après tout, avec une lourde charge de telles intersections d'identifiants, il n'y en aura pas un ou même deux ... Si vous avez toute la logique métier liée au fait que l'id est toujours unique et augmente toujours, ce sera OH.
Dans notre cas, rien de catastrophique ne s'est produit et les tests de charge sur le banc d'essai du client ont aidé. Nous avons trouvé le problème tôt, car il s'est avéré que les versions négatives du système n'interfèrent pas avec la vie. Mais nous avons ajouté le séquençage séquentiel aux scripts de création de base de données, juste pour de tels cas.
La morale de cette fable est la suivante: il est TRÈS important d'effectuer des tests de charge sur le même matériel qui sera dans PROD. Tout peut affecter le résultat: les paramètres de l'OS lui-même, les paramètres de la base de données, oui n'importe quoi. Ce que vous ne soupçonniez même pas.
Testez à l'avance. Et rappelez-vous que tous les problèmes ne peuvent pas être trouvés par des tests fonctionnels. Dans cet exemple, un simple test ne trouverait pas de bogues. En effet, si vous créez des entités manuellement, c'est-à-dire lentement, tous les nœuds de base de données auront le temps de notifier les nœuds voisins, donc nous n'obtiendrons pas d'incohérence.
Petite souris
Json vide
Si vous utilisez la bibliothèque Axis ouverte, essayez d'envoyer du JSON vide à l'application. Il pourrait très bien l'accrocher complètement.
Et surtout - vous ne pouvez rien y faire de votre côté! Il s'agit d'un bogue dans une bibliothèque tierce. Voici donc soit l'attente d'une correction officielle, soit le changement de bibliothèque, ce qui peut être très difficile.
En fait, ce bug a déjà été corrigé dans la nouvelle version d'Axis. Il semblerait que juste mettre à jour, et c'est tout! Mais ... Le système utilise rarement une bibliothèque tierce. Habituellement, il y en a plusieurs, ils sont liés les uns aux autres. Pour les mettre à jour, vous devez tout mettre à jour en même temps. Il est nécessaire d'effectuer un refactoring, car ils fonctionnent désormais différemment. Les ressources des développeurs doivent être allouées.
En général, la simple mise à jour de la version de la bibliothèque prend parfois une version complète d'un développeur sympa. Ainsi, par exemple, lorsque nous sommes passés à la nouvelle version de Lucene, nous avons consacré 56 heures à la tâche, soit 7 jours-homme, une semaine de développeur à temps plein et plus les tests. La tâche elle-même ressemble à ceci, l'architecte le dit:
Lucene Passer à l'utilisation de PointValues au lieu de Long / IntegerField
Le dock Lucene Migration 5 -> 6 contient une clause sur la suppression du champ Long (Integer / Double) en faveur de PointValues.
Lors du passage à Lucene 6.3.1, j'ai quitté les anciens champs (toutes les classes ont été renommées avec l'ajout du préfixe Legacy), car la traduction tire vers une tâche distincte.
Vous devez abandonner les anciens champs et utiliser les classes Long (Integer / Double) Point, qui sont plus rapides et moins pondérées dans l'index par les tests. Je dois réécrire beaucoup de code.
Bien sûr! La transition doit être rétrocompatible afin que la recherche (au moins les fonctions clés) ne s'arrête pas avec la mise à niveau de la version. Il doit fonctionner sur l'ancien index (avant la reconstruction) et après la reconstruction (à un moment opportun pour le client), de nouveaux champs doivent être récupérés.
Et ce n'est qu'une mise à jour de la bibliothèque! Et abandonner une bibliothèque à cause d'un bogue est généralement effrayant d'imaginer combien de temps cela prendra ...
Il est donc tout à fait possible que vous viviez simplement avec un bug pendant un certain temps. Connaissez-le, mais ne changez rien. Au final, "il n'y a rien pour envoyer des demandes idiotes".
Mais dans tous les cas, vous devez au moins connaître la présence d'un bug. Parce que si un utilisateur vient à vous et vous dit: «Tout vous a raccroché», vous devez comprendre pourquoi. Étant donné que les journaux sont vides. Parce que ce n'est pas votre application qui se bloque, tout se bloque à l'étape de conversion JSON.
Il semblerait - une demande vide! Et ici, cela peut conduire à ... Autrement dit, même si vous ne savez pas qu'Axis a un tel bogue, vous pouvez simplement vérifier que JSON est vide, une demande SOAP vide. Au final, c'est un excellent exemple de test zéro dans le contexte d'une requête JSON.
N'oubliez pas de tester zéro. Et la moindre valeur est la petite souris, car elle apporte également des bugs, parfois si effrayants.
Voir aussi:La classe d'équivalence "Zero-not zero" - en savoir plus sur le test zéro
"Moscou" dans le champ d'adresse
Le service
de Dadat est capable de standardiser les adresses - disposer l'adresse en une seule ligne sur des composants granulaires + déterminer la zone de l'appartement, si elle se trouve dans l'annuaire.
Lors des tests, un bug amusant a été trouvé - si vous entrez le mot "Moscou" dans l'adresse, le système détermine la zone de l'appartement. Bien que, semble-t-il, où se trouve l'appartement dans cette «adresse»?

Je pense que c'est un excellent exemple de "petite souris". Parce que ce qui est généralement vérifié? L'adresse habituelle, l'adresse de la rue, de la maison ... Un champ vide. Tout caractère unique - cela est considéré comme un test unitaire.
Mais si vous entrez une lettre, le système déterminera l'entrée comme une corbeille complète et effacera l'adresse. Il se comporte correctement, mais il s'agit d'un cas négatif par unité. Il s'agit d'une vérification de la longueur du champ exclusivement.
Et ici, il vaut mieux y réfléchir - y a-t-il une unité positive? Il y en a. Un mot, un tel système déterminera. Et ici aussi, il existe différentes classes d'équivalence: il peut s'agir d'un mot du début de l'adresse (ville), ou bien du milieu (rue). Cela vaut la peine d'essayer les deux. Mais si vous vous limitez uniquement à "unité dans le champ de texte = un caractère", vous ne trouverez jamais ce bug.
Total
Mnémonique il y en a beaucoup. Et les utiliser peut vous aider. Parce que vous regardez déjà votre candidature pour la 10ème, 100ème fois ... Vous avez déjà perdu vos yeux, vous pouvez sauter l'erreur évidente. Et si vous utilisez des mnémoniques existantes, examinez l'application d'une nouvelle manière. Ce qui aidera à détecter de nouveaux bugs.
Et même des mnémoniques aussi simples que BMW aident beaucoup. Mais, il semblerait ... Grand, petit, pensez! Valeurs limites simples. Mais ils doivent toujours être mémorisés et toujours vérifiés! Il apporte des fruits et une variété de bugs.
En utilisant mes exemples, je voulais montrer que vous pouvez rechercher des bordures non seulement dans un champ texte ou numérique. Mnemonics fonctionne partout: dans Oracle RAC, Java, Wildfly, n'importe où! Apprenez à regarder les frontières au-delà de la compréhension habituelle de «entrer dans la guerre et la paix dans la zone de texte».
Bien sûr, l'accent est mis sur la "grosse souris", elle apporte le plus de bugs. Ce sont précisément ces cas qui sont rappelés lorsque vous pensez vous être rencontrés sur votre projet.
Mais il ne faut pas oublier la "petite souris". Oui, j'ai pu rappeler quelques exemples spécifiques à mon travail. Mais cela ne veut pas dire que je ne trouve pas de bugs sur une petite souris. Je le trouve! Celles qui se trouvent dans la section des exemples généraux: date du 01.01.1900, fichier de 1 ko, rapport vide lorsque les données sont renseignées ...
Les frontières sont très importantes. N'oubliez pas de les tester. J'espère que mes exemples vous inspireront, et les mnémoniques BMW apparaîtront toujours dans ma tête lors de la mise en évidence des classes d'équivalence.
Ou peut-être que vous arriverez à vos propres mnémoniques. Ce sera pour vous, pour votre équipe, pour vos fonctionnalités, pour vos processus. Et c'est aussi super, c'est aussi du succès. L'essentiel est que ça aide!
PS est un extrait de
mon livre pour les testeurs débutants. J'ai également parlé de mnémoniques dans un rapport sur SQA Days,
vidéo ici .