Salut Je m'appelle Konstantin Evteev, je travaille à Avito en tant que chef de l'unité DBA. Notre équipe développe des systèmes de stockage Avito, aide à la sélection ou à la délivrance de bases de données et de l'infrastructure connexe, prend en charge l'objectif de niveau de service pour les serveurs de bases de données, et nous sommes également responsables de l'efficacité et de la surveillance des ressources, de conseiller sur la conception et éventuellement de développer des microservices, liés à des systèmes de stockage, ou des services pour le développement de la plateforme dans le cadre du stockage.
Je veux vous dire comment nous avons résolu l'un des défis de l'architecture de microservices - effectuer des transactions commerciales dans l'infrastructure de services construite à l'aide de la base de données par modèle de service. J'ai fait une présentation sur ce sujet lors de la conférence Highload ++ Siberia 2018 .

Théorie Le plus court possible
Je ne décrirai pas en détail la théorie des sagas. Je vais vous donner seulement une brève introduction pour que vous compreniez le contexte.
Comme avant (du début d'Avito à 2015-2016): nous vivions dans un monolithe, avec des bases monolithiques et des applications monolithiques. À un moment donné, ces conditions ont commencé à nous empêcher de grandir. D'une part, nous avons rencontré les performances d'un serveur avec une base de données principale, mais ce n'est pas la raison principale, car le problème de performances peut être résolu, par exemple, en utilisant le sharding. D'autre part, le monolithe a une logique très complexe, et à un certain stade de croissance, la livraison des changements (versions) devient très longue et imprévisible: il y a beaucoup de dépendances non évidentes et complexes (tout est étroitement lié), il est également difficile à tester, en général il y a beaucoup de problèmes. La solution est de passer à l'architecture de microservices. A ce stade, nous avions une question avec des transactions commerciales fortement liées aux ACID fournies par une base monolithique: on ne sait pas comment migrer cette logique métier. Lorsque vous travaillez avec Avito, il existe de nombreux scénarios différents mis en œuvre par plusieurs services, lorsque l'intégrité et la cohérence des données sont très importantes, par exemple, acheter un abonnement premium, débiter de l'argent, appliquer des services à un utilisateur, acheter des packages VAS - en cas de circonstances imprévues ou d'accidents, tout ne se passe pas de façon inattendue selon plan. Nous avons trouvé la solution dans les sagas.
J'aime la description technique des sagas de 1987 par Kenneth Salem et Hector Garcia-Molina, l'un des membres actuels du conseil d'administration d'Oracle. Comment le problème a été formulé: il existe un nombre relativement faible de transactions à long terme qui empêchent pendant longtemps l'exécution de petites opérations moins gourmandes en ressources et plus fréquentes. Comme résultat souhaité, vous pouvez donner un exemple de la vie: bien sûr, vous étiez nombreux à faire la queue pour copier des documents, et le copieur, s'il avait la tâche de copier un livre entier ou juste beaucoup de copies, faisait de temps en temps des copies d'autres membres de la file d'attente. Mais l'élimination des ressources n'est qu'une partie du problème. La situation est aggravée par les verrous à long terme lors de l'exécution de tâches gourmandes en ressources, dont la cascade sera créée dans votre SGBD. De plus, des erreurs peuvent se produire lors d'une longue transaction: la transaction ne se terminera pas et la restauration commencera. Si la transaction était longue, la restauration prendra également beaucoup de temps et il y aura probablement une nouvelle tentative à partir de l'application. En général, "tout est assez intéressant". La solution proposée dans la description technique de SAGAS est de scinder une longue transaction en plusieurs parties.
Il me semble que beaucoup l'ont abordé sans même lire ce document. Nous avons parlé à plusieurs reprises de notre defproc (procédures différées implémentées à l'aide de pgq). Par exemple, lorsque nous bloquons un utilisateur pour fraude, nous effectuons rapidement une courte transaction et répondons au client. Dans cette courte transaction, notamment, nous plaçons la tâche dans une file d'attente transactionnelle, puis de manière asynchrone, par petits lots, par exemple, dix annonces bloquent ses annonces. Nous l'avons fait en implémentant des files d'attente transactionnelles à partir de Skype .
Mais notre histoire d'aujourd'hui est un peu différente. Nous devons regarder ces problèmes de l'autre côté: scier un monolithe dans des microservices construits en utilisant la base de données par modèle de service.
L'un des paramètres les plus importants pour nous est d'atteindre la vitesse de coupe maximale. Par conséquent, nous avons décidé de transférer l'ancienne fonctionnalité et toute la logique telle qu'elle est vers les microservices, sans rien changer du tout. Exigences supplémentaires que nous devions remplir:
- Fournir des modifications de données dépendantes pour les données critiques de l'entreprise
- être en mesure de fixer un ordre strict;
- observer une cohérence à cent pour cent - coordonner les données même en cas d'accident;
- garantir le fonctionnement des transactions à tous les niveaux.
Sous les exigences ci-dessus, la solution sous forme de saga orchestrée est la plus appropriée.
Implémentation d'une saga orchestrée en tant que service PG Saga
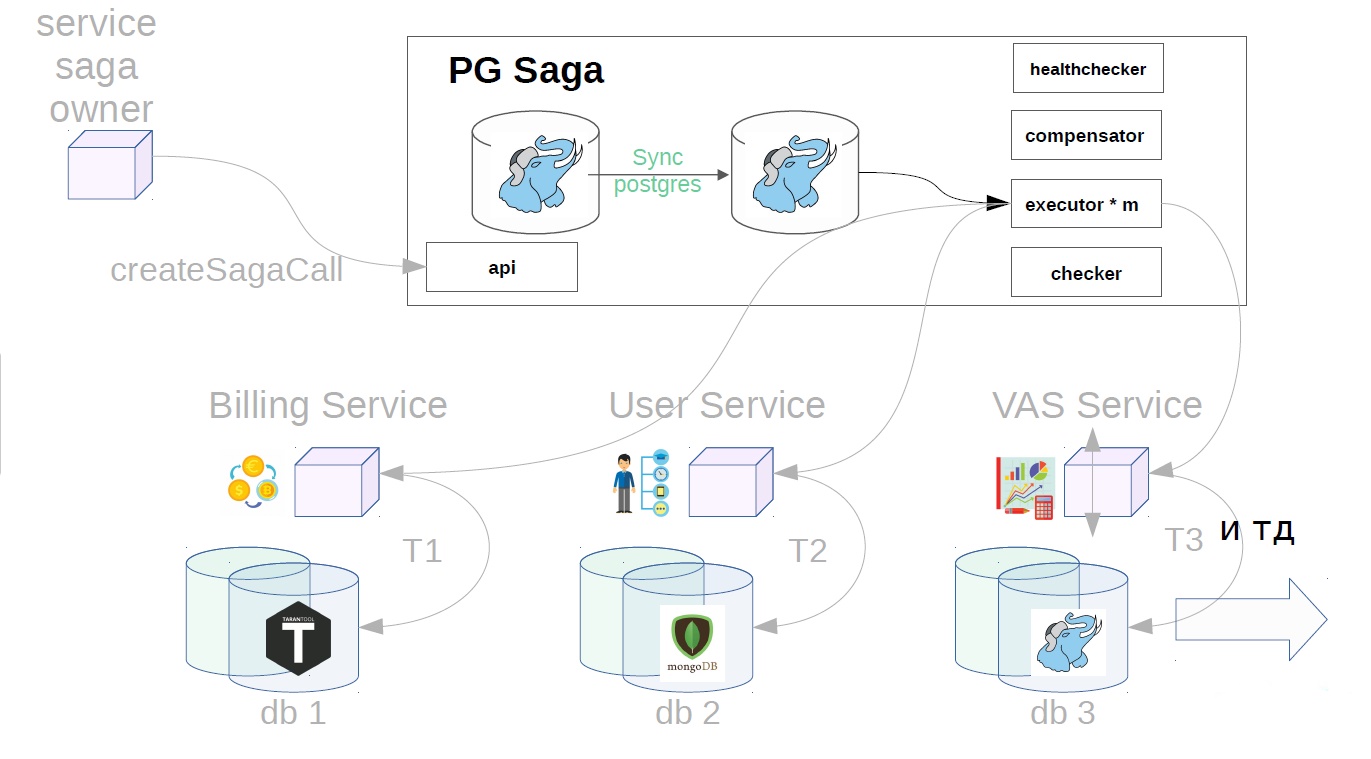
Voici à quoi ressemble le service PG Saga.
PG dans le nom, car PostgreSQL synchrone est utilisé comme référentiel de services. Quoi d'autre à l'intérieur:
- API
- exécuteur testamentaire;
- vérificateur;
- bilan de santé;
- compensateur.
Le diagramme montre également le propriétaire du service des sagas, et ci-dessous sont les services qui effectueront les étapes de la saga. Ils peuvent avoir différents référentiels.
Comment ça marche
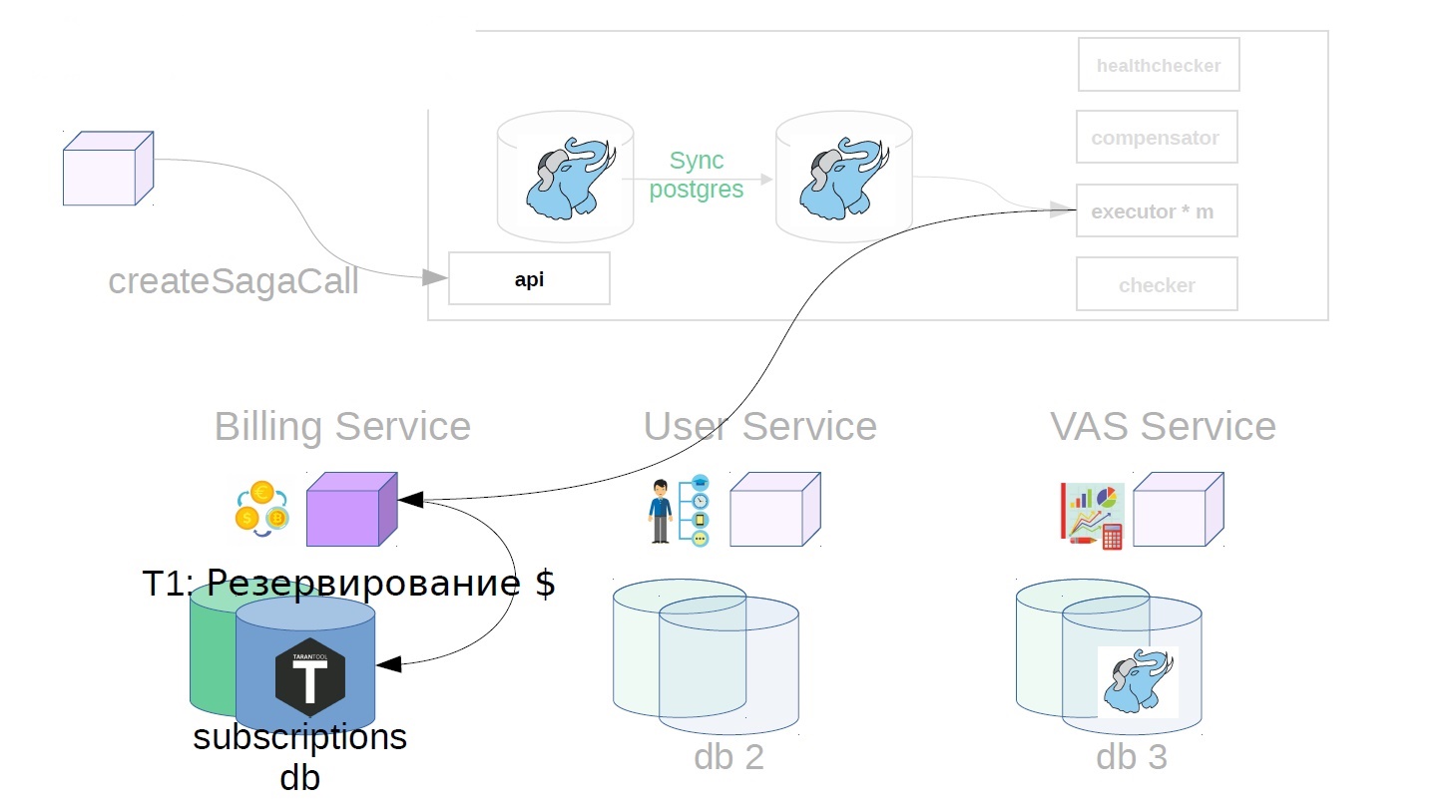
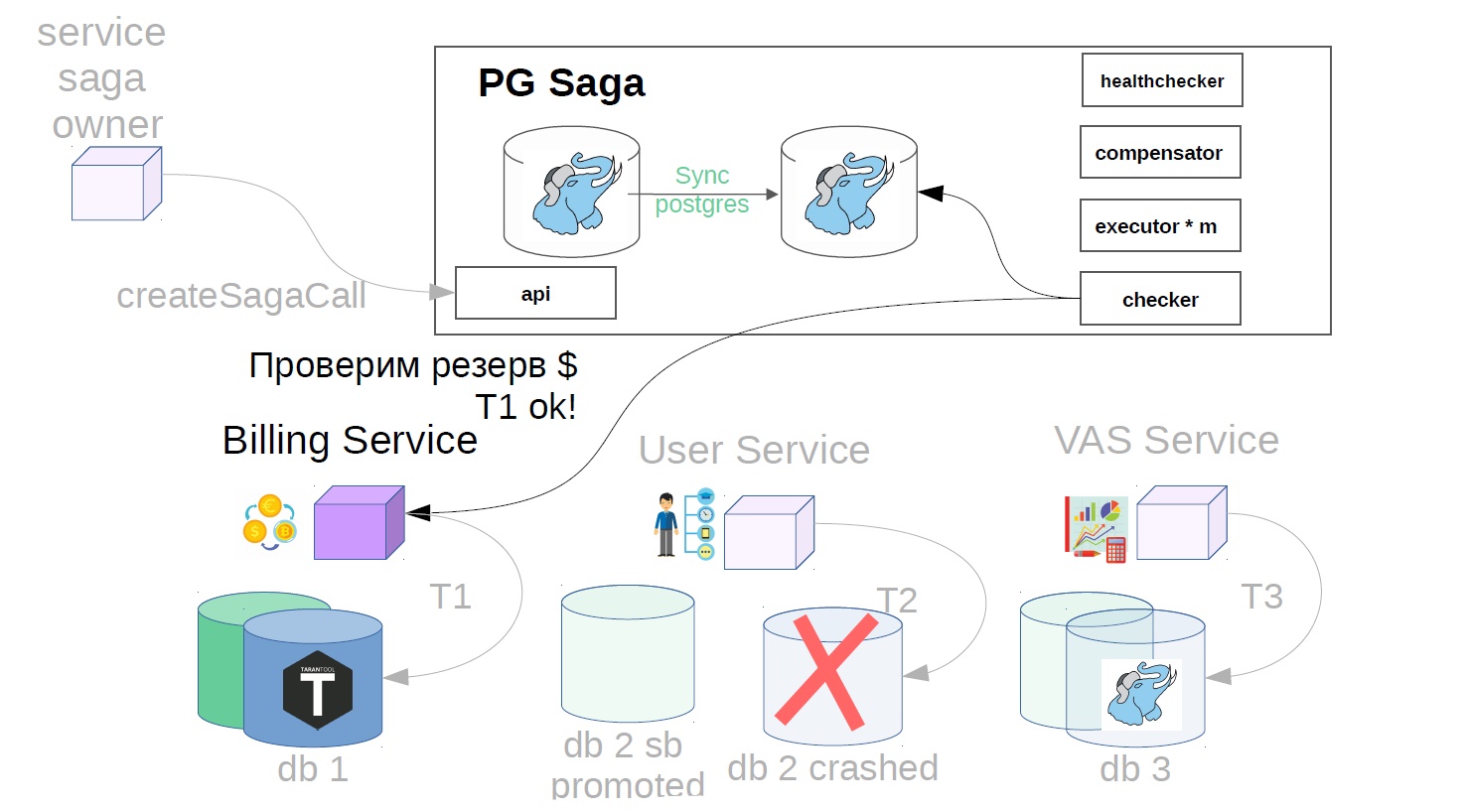
Prenons l'exemple de l'achat de packages VAS. VAS (services à valeur ajoutée) - services payants pour la promotion publicitaire.
Tout d'abord, le propriétaire du service de la saga doit enregistrer la création de la saga dans le service de la saga
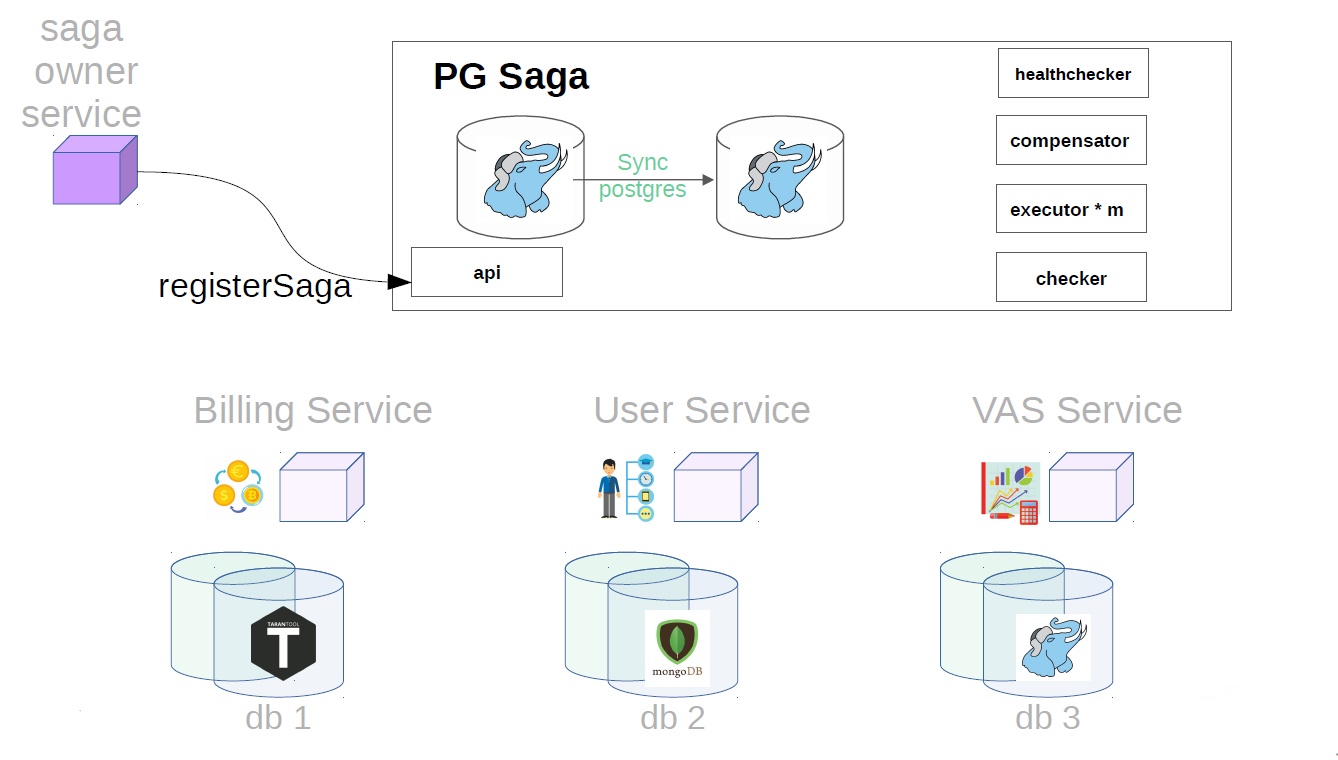
Après cela, il génère déjà une classe de saga avec Payload.
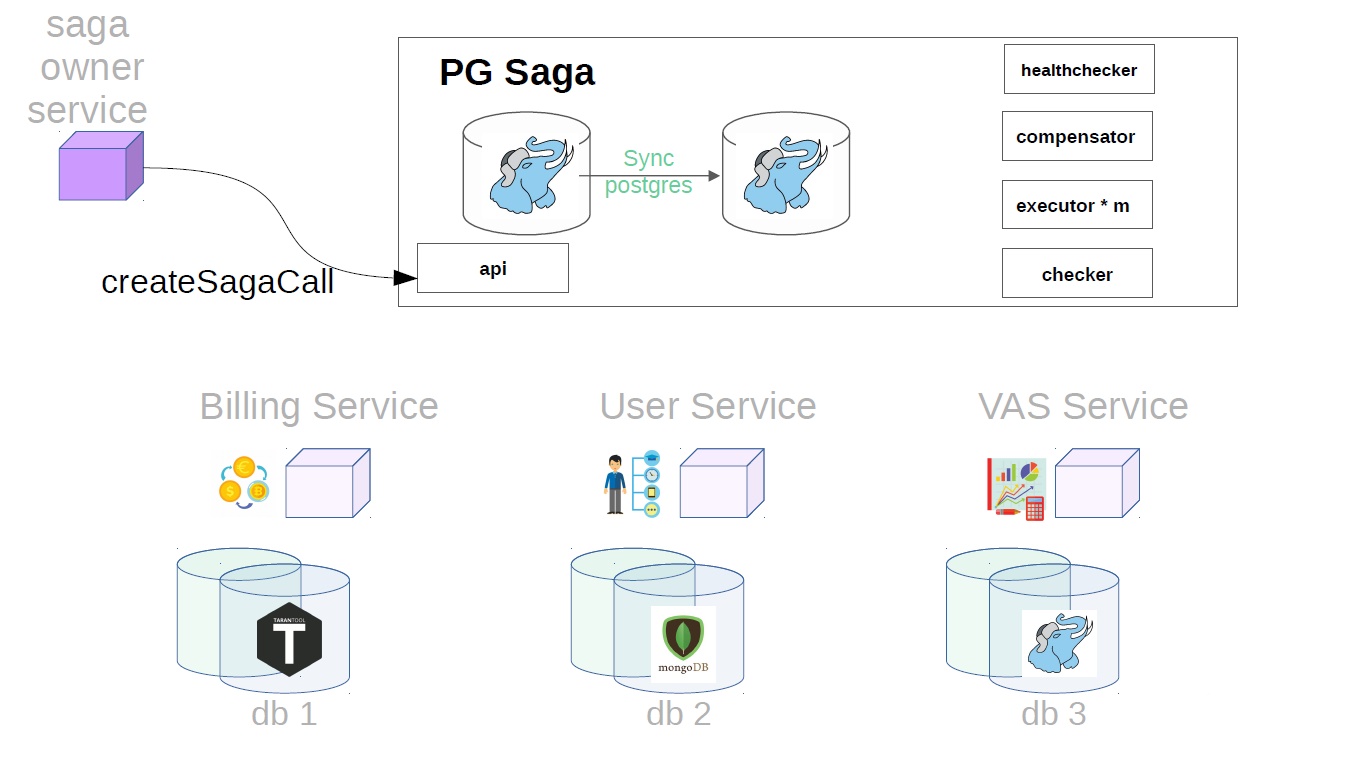
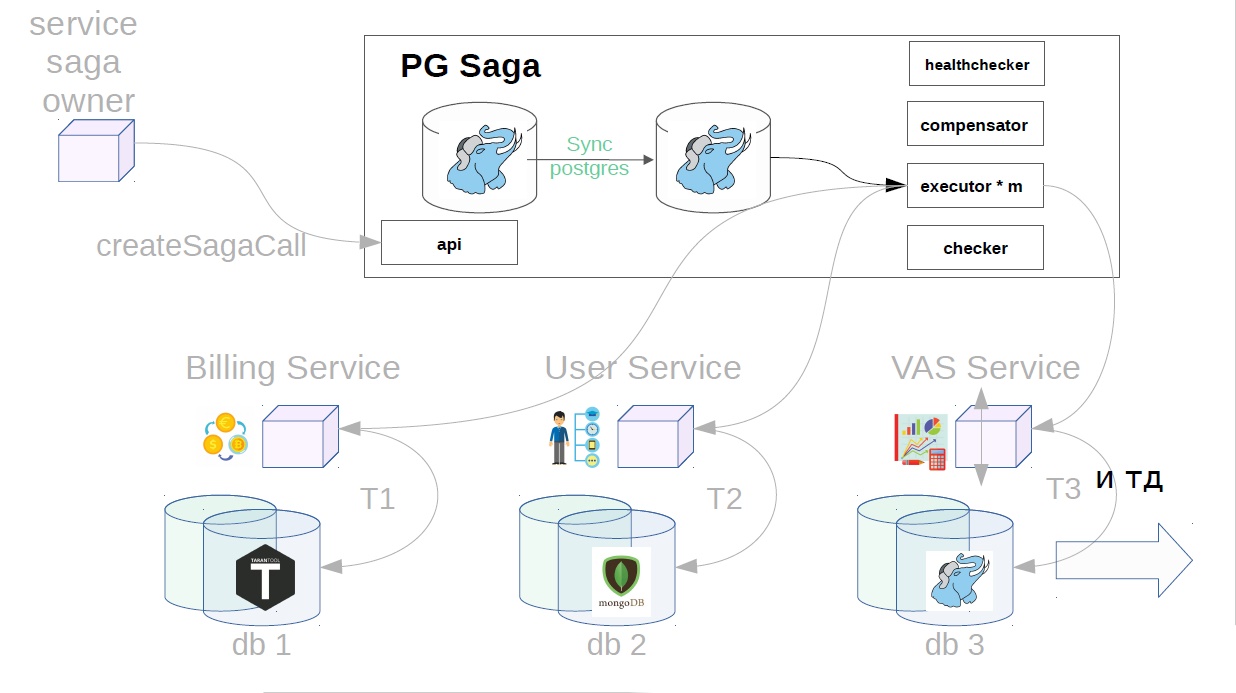
De plus, déjà dans le service sag, l'exécuteur récupère l'appel de saga précédemment créé dans le magasin et commence à l'exécuter par étapes. La première étape dans notre cas est d'acheter un abonnement premium. En ce moment, l'argent est réservé dans le service de facturation.

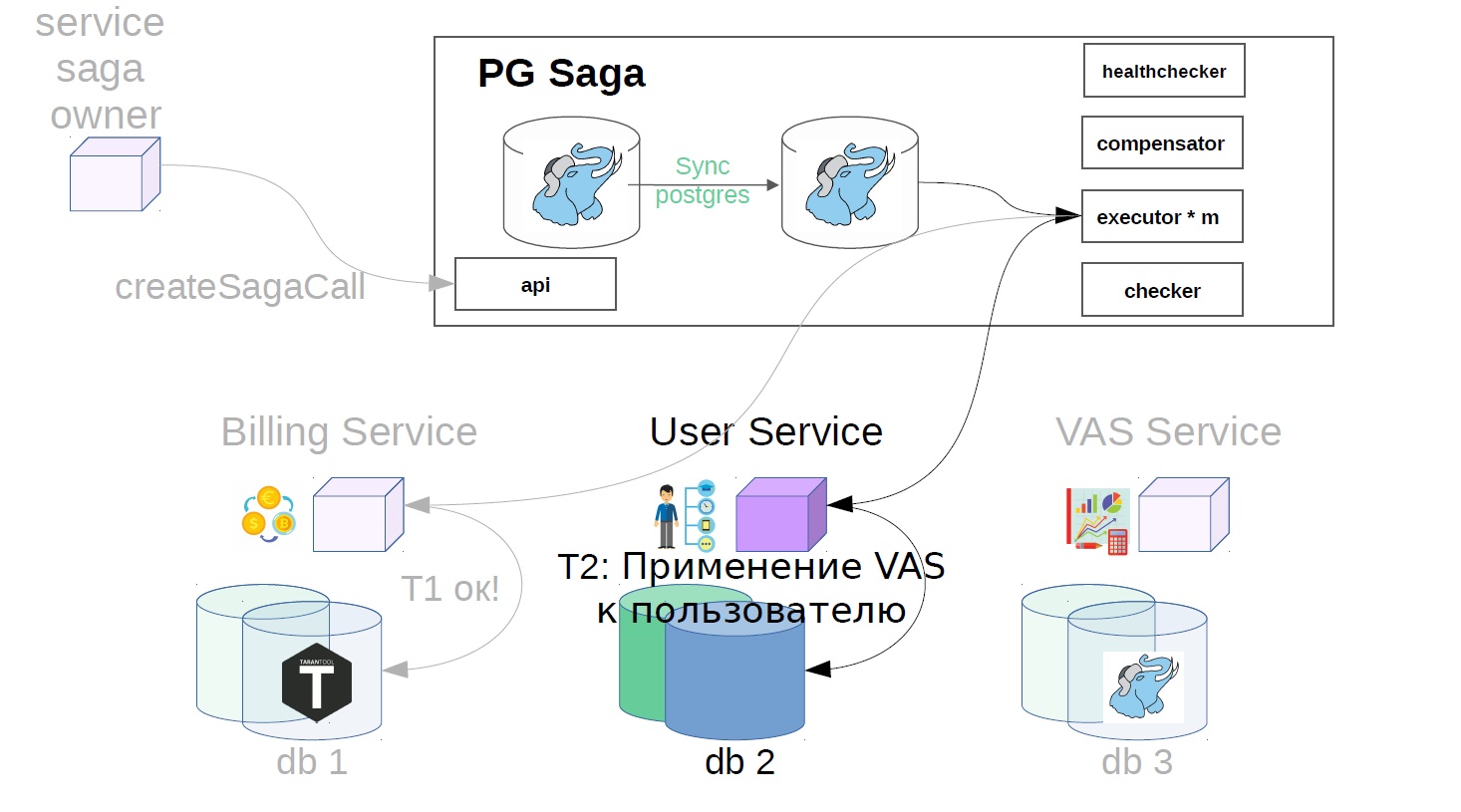
Ensuite, dans le service de l'utilisateur, les opérations VAS sont appliquées.
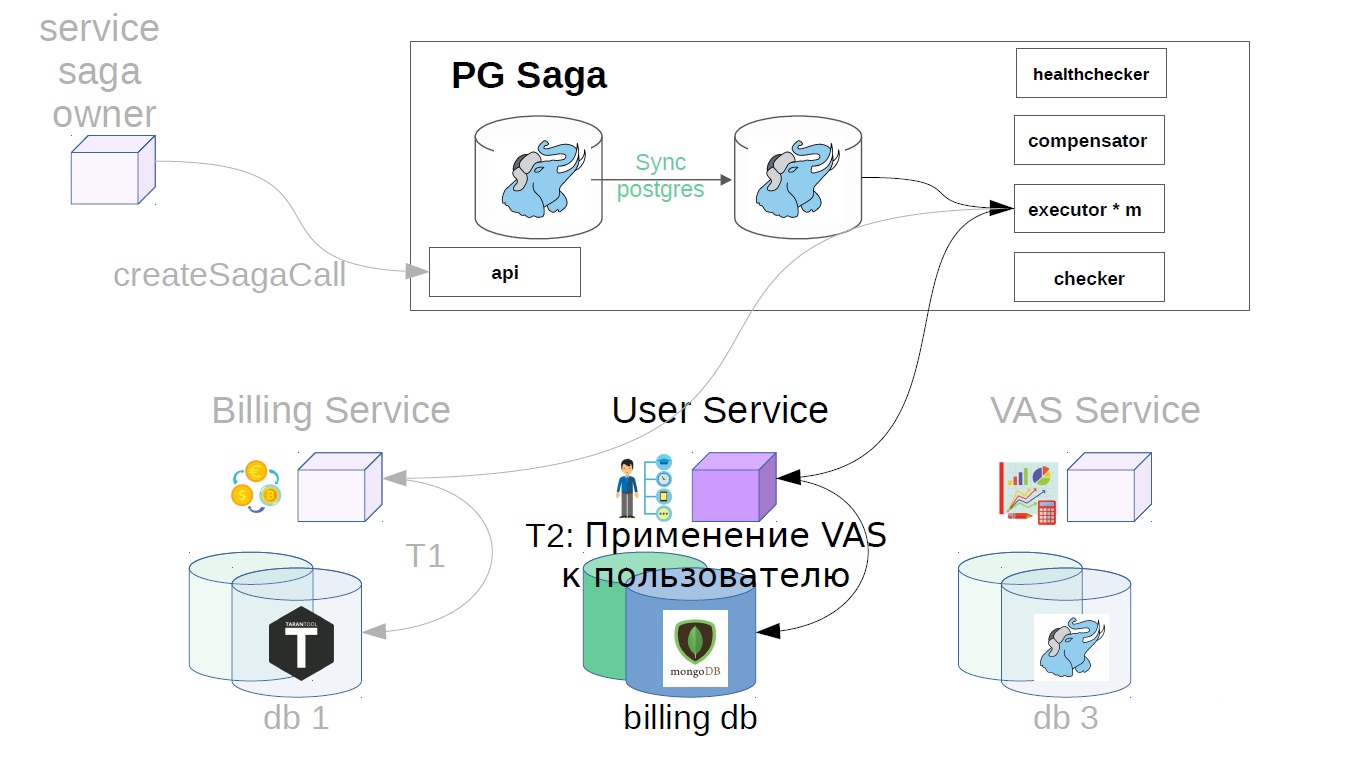
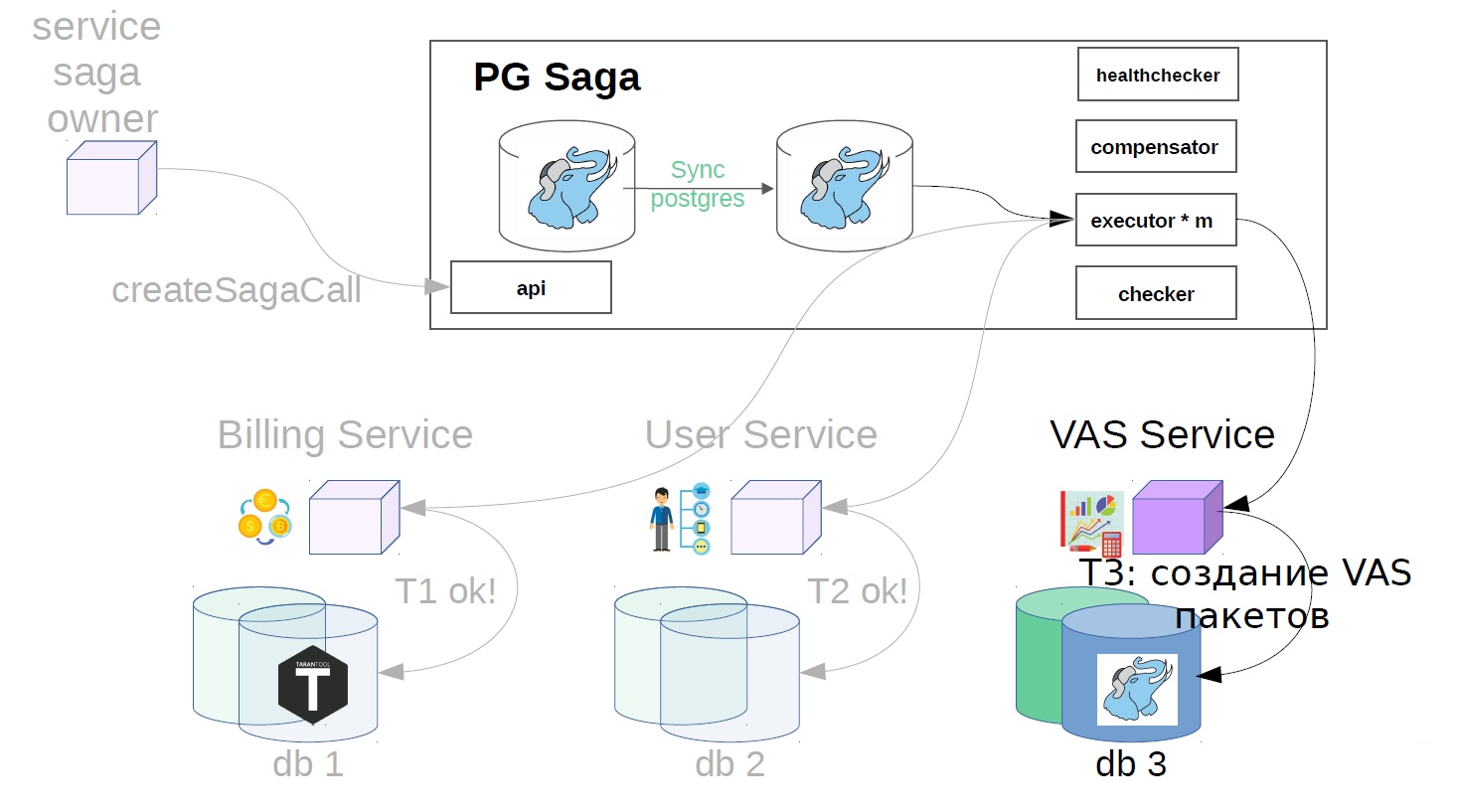
Les services VAS sont alors déjà en place et vos packages sont créés. D'autres étapes sont encore possibles, mais elles ne sont pas si importantes pour nous.
Crashes
Des accidents peuvent survenir dans n'importe quel service, mais il existe des astuces bien connues pour s'y préparer. Dans un système distribué, il est important de connaître ces techniques. Par exemple, l'une des limitations les plus importantes est que le réseau n'est pas toujours fiable. Approches qui résoudront les problèmes d'interaction dans les systèmes distribués:
- Nous réessayons.
- Nous marquons chaque opération avec une clé idempotente. Cela est nécessaire pour éviter la duplication des opérations. Plus d'informations sur les clés idempotentes peuvent être trouvées dans cet article.
- Nous compensons les transactions - une action caractéristique des sagas.
Compensation de transaction: comment cela fonctionne
Pour chaque transaction positive, nous devons décrire les actions inverses: un scénario commercial de l'étape au cas où quelque chose se passe mal.
Dans notre implémentation, nous proposons le scénario de rémunération suivant:
Si une étape de la saga a échoué et que nous avons fait de nombreuses tentatives, il est possible que la dernière répétition de l'opération soit un succès, mais nous n'avons tout simplement pas obtenu de réponse. Nous essaierons de compenser la transaction, bien que cette étape ne soit pas nécessaire si l'exécuteur de service de l'étape de problème est vraiment tombé en panne et est complètement inaccessible.
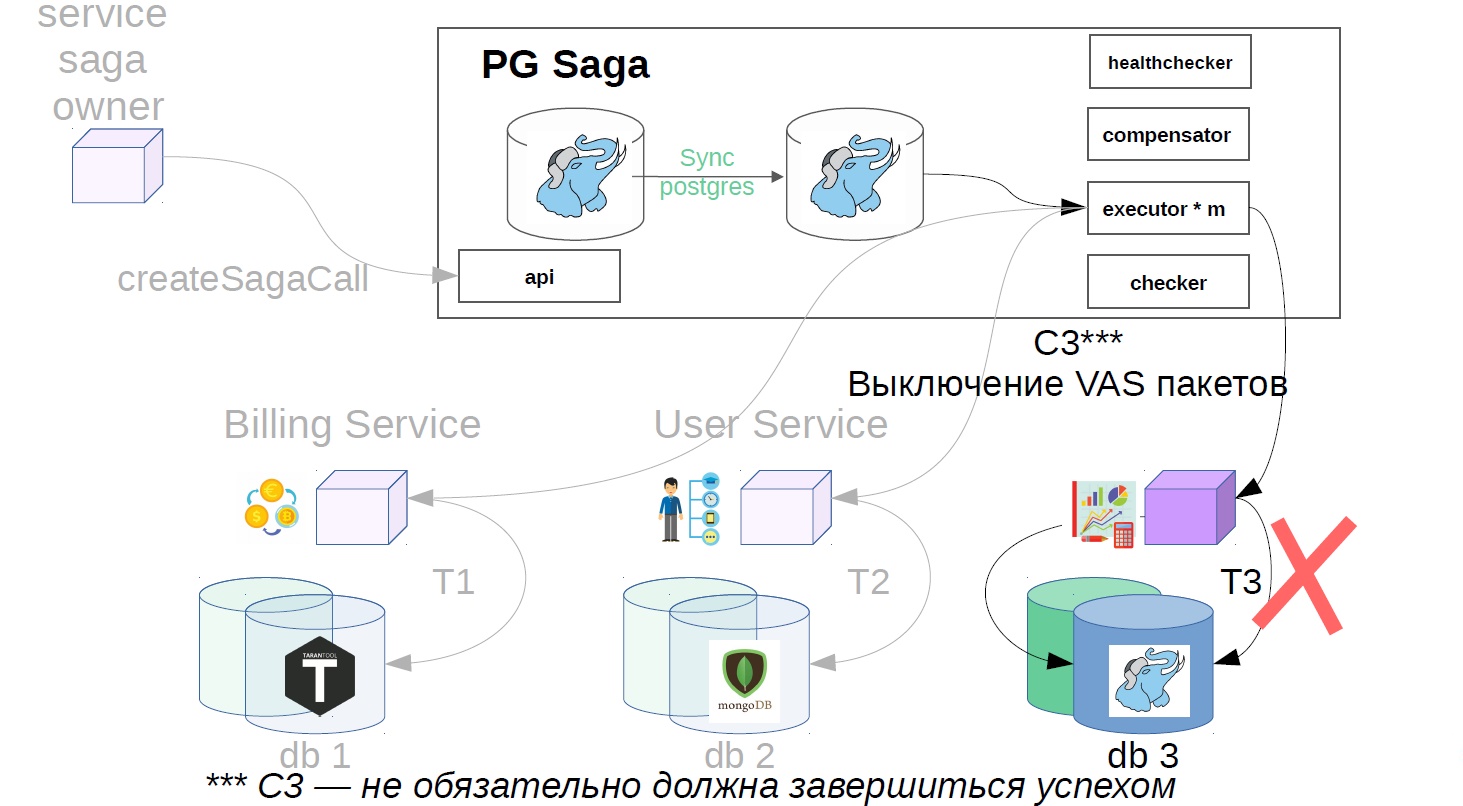
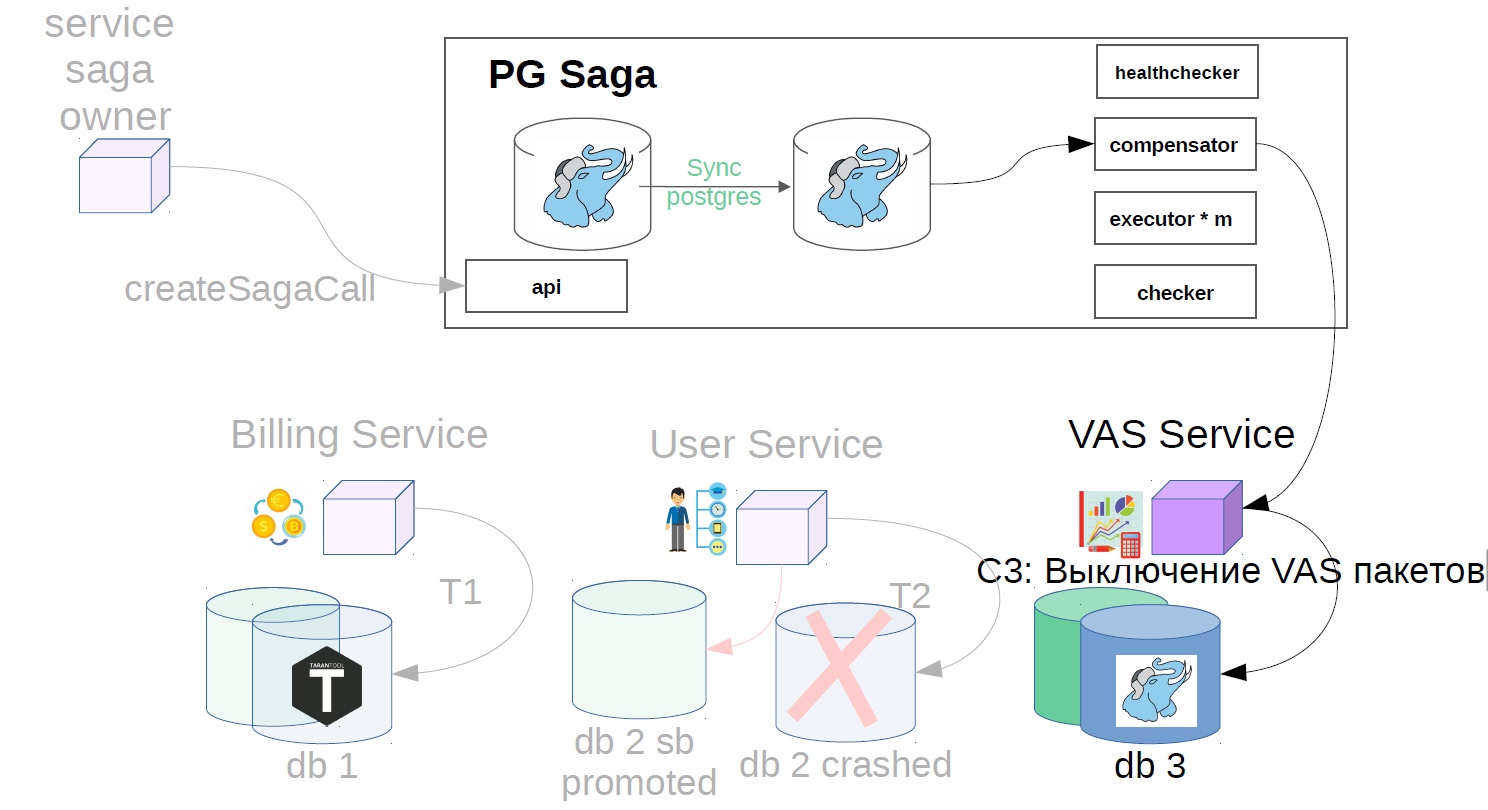
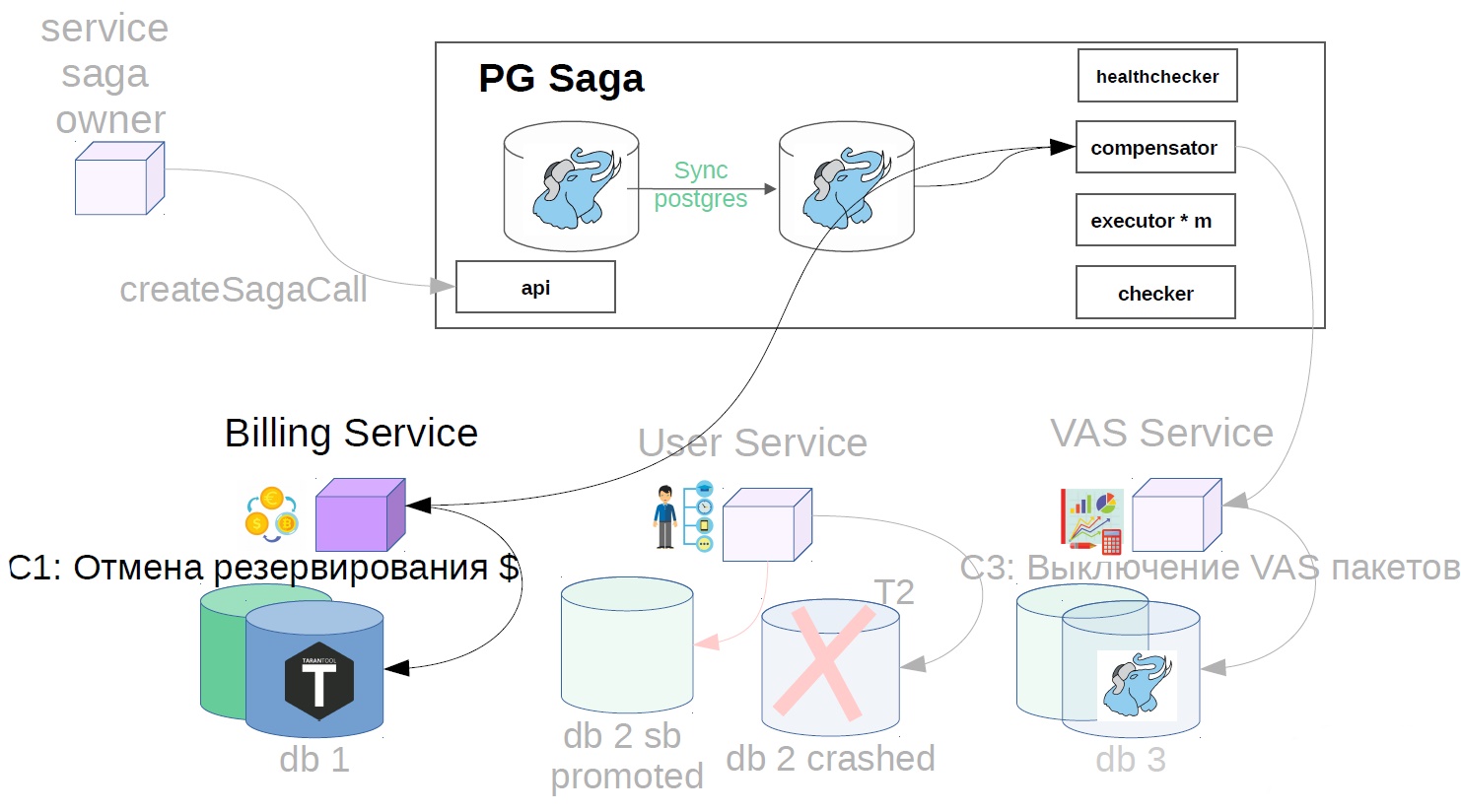
Dans notre exemple, cela ressemblera à ceci:
- Désactivez les packages VAS.
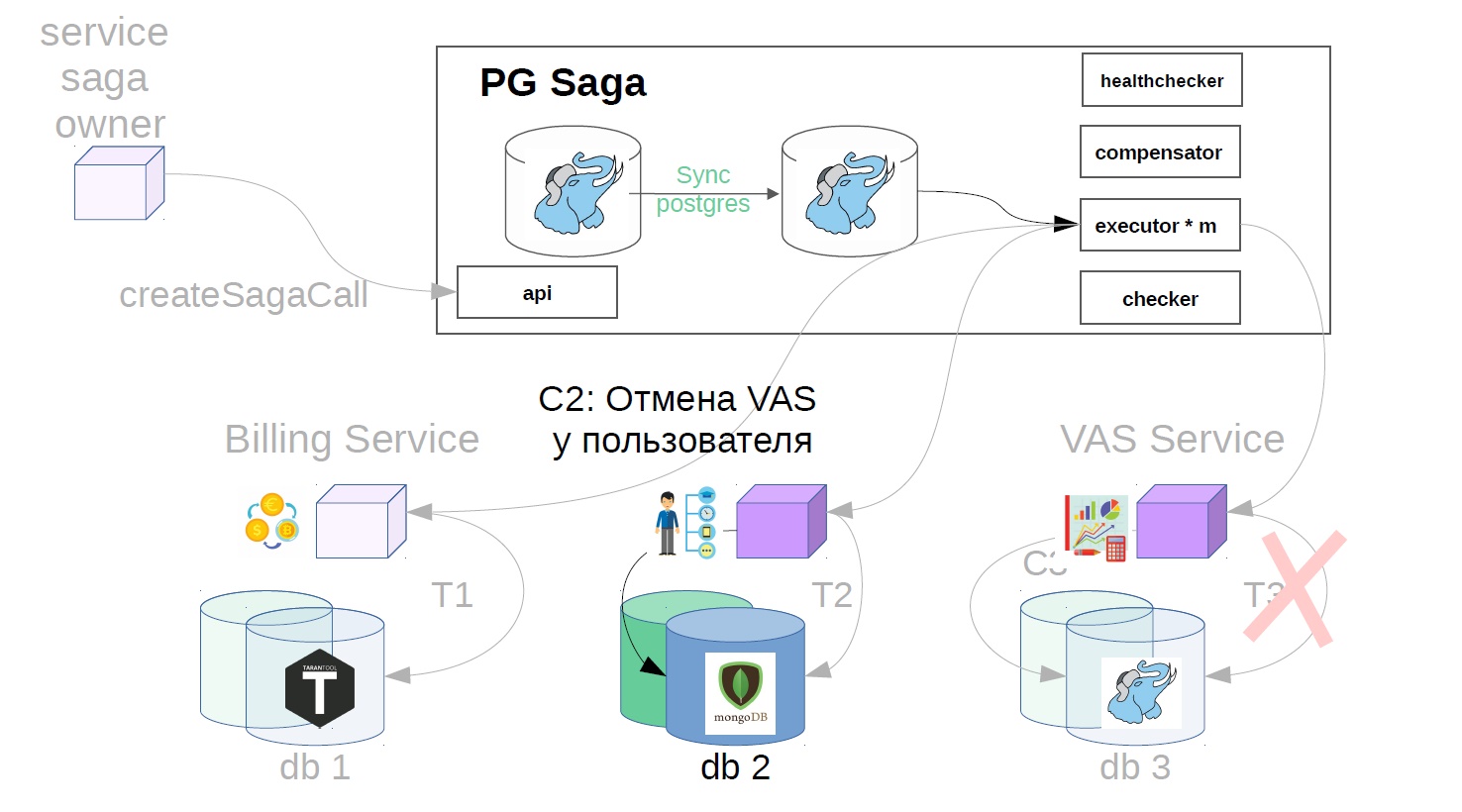
- Annulez l'opération utilisateur.
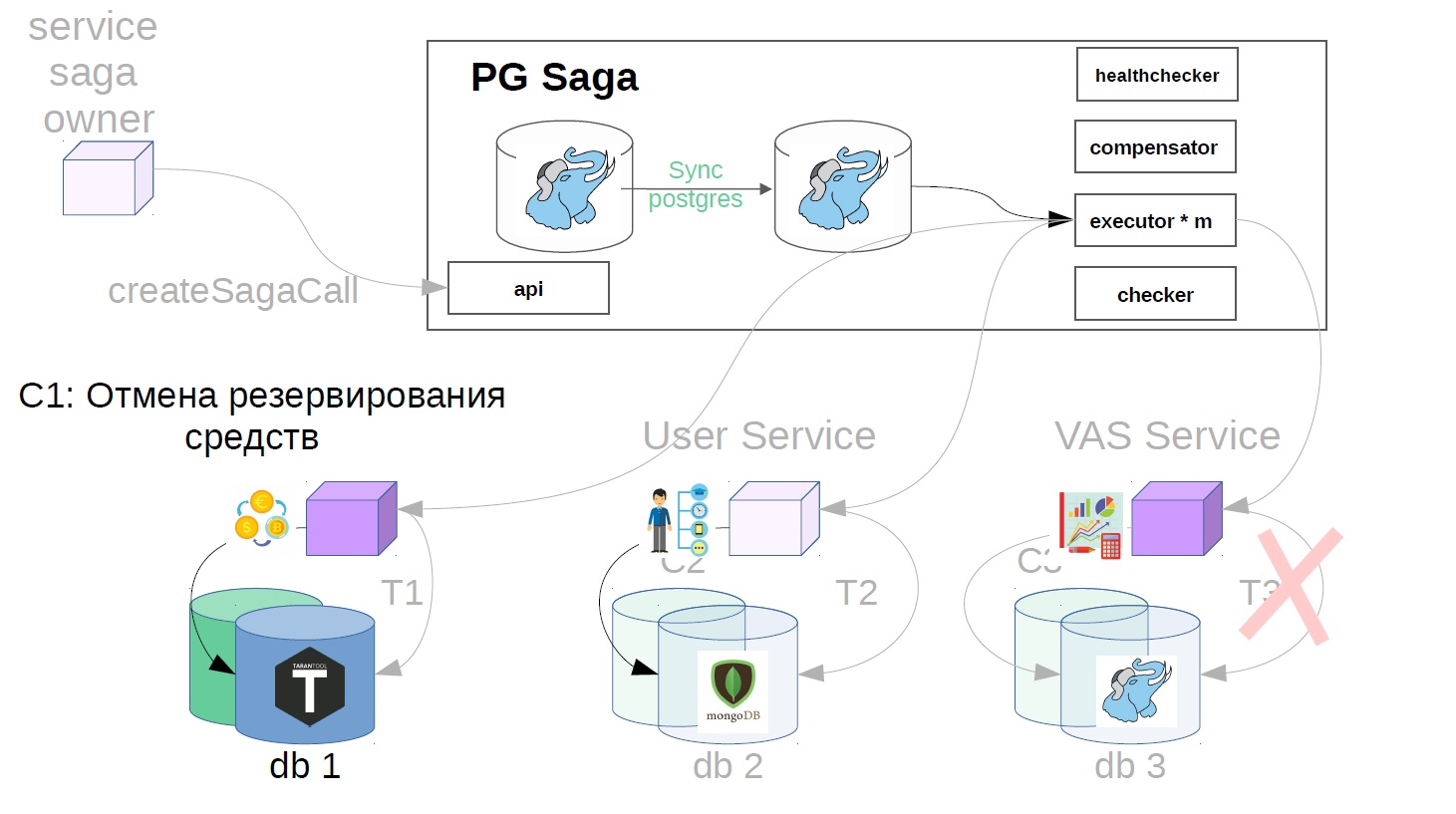
- Nous annulons la réservation des fonds.
Que faire si la compensation ne fonctionne pas
Évidemment, nous devons agir à peu près sur le même scénario. Encore une fois, appliquez une nouvelle tentative, des clés idempotentes pour compenser les transactions, mais si rien ne sort cette fois, par exemple, le service n'est pas disponible, vous devez contacter le propriétaire du service de la saga, vous informant que la saga a échoué. De plus, des actions plus sérieuses: escaladez le problème, par exemple, pour un essai manuel ou lancez l'automatisation pour résoudre de tels problèmes.
Ce qui est plus important: imaginez qu'une étape du service de saga n'est pas disponible. L'initiateur de ces actions va sûrement réessayer. Et à la fin, votre service de saga prend la première étape, la deuxième étape et son exécuteur n'est pas disponible, vous annulez la deuxième étape, annulez la première étape et des anomalies liées au manque d'isolement peuvent également se produire. En général, le service de saga dans cette situation est engagé dans un travail inutile, qui génère toujours une charge et des erreurs.
Comment faire Healthchecker doit interroger les services qui complètent les étapes d'affaissement et voir s'ils fonctionnent. Si le service est devenu indisponible, il y a deux façons: pour compenser les sagas qui sont en fonctionnement, et pour empêcher de nouvelles sagas de créer de nouvelles instances (appels), ou pour créer sans les faire fonctionner comme un exécuteur, afin que le service ne actions inutiles.
Un autre scénario d'accident
Imaginez que nous refaisons le même abonnement premium.
- Nous achetons des forfaits VAS et réservons de l'argent.
- Nous appliquons des services à l'utilisateur.
- Nous créons des packages VAS.
Ça semble bien. Mais soudain, une fois la transaction terminée, il s'avère que la réplication asynchrone est utilisée dans le service utilisateur et qu'un accident s'est produit sur la base principale. Un retard peut se produire pour plusieurs raisons: une charge spécifique sur le réplica qui ralentit la vitesse de lecture de la réplication ou bloque la lecture de la réplication. De plus, la source (maître) peut être surchargée et un décalage d'envoi des modifications apparaît du côté source. En général, pour une raison quelconque, la réplique était en retard et les modifications de l'étape terminée avec succès après l'accident ont soudainement disparu (résultat / état).
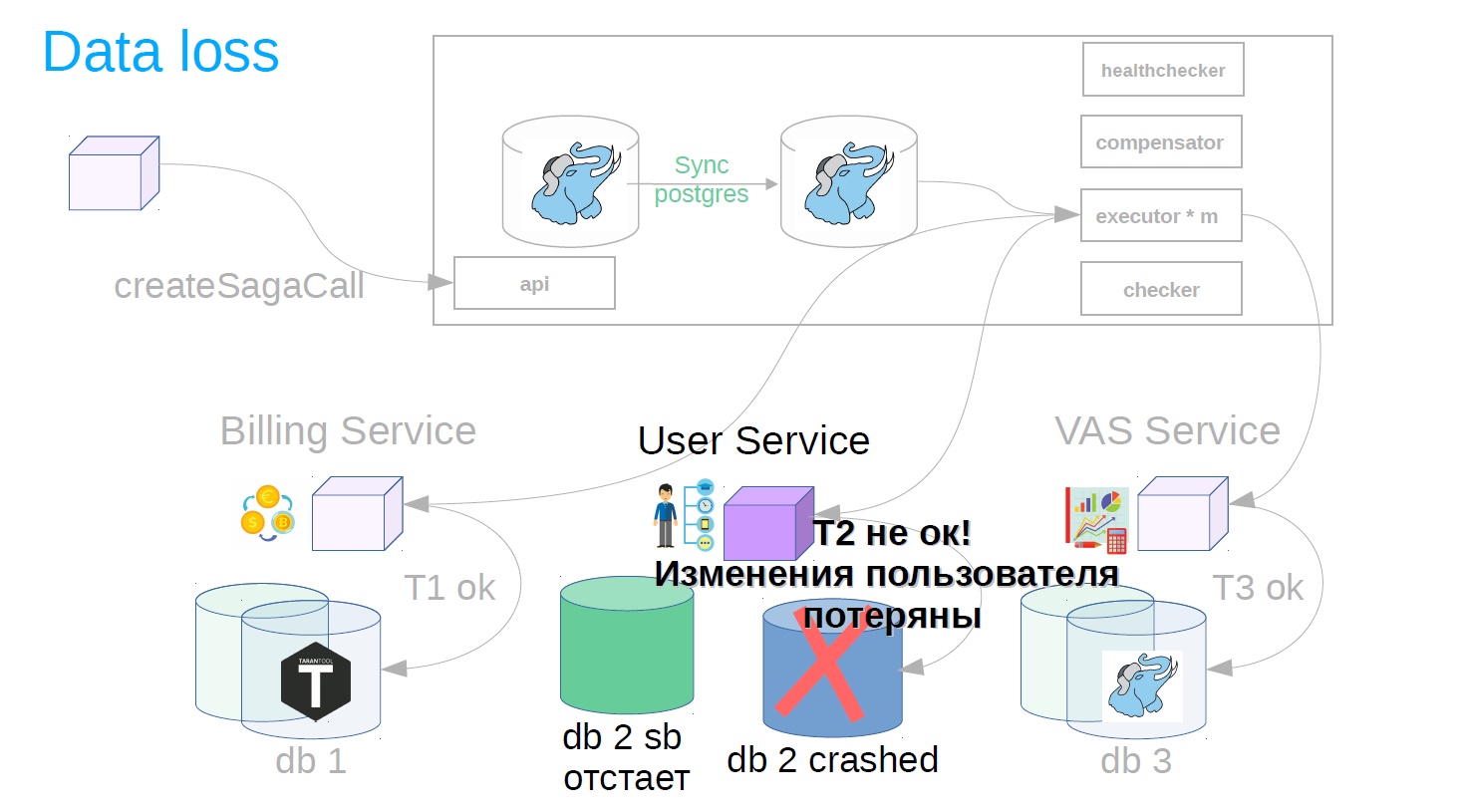
Pour ce faire, nous implémentons un autre composant dans le système - nous utilisons Checker. Checker passe par toutes les étapes des sagas réussies à travers un temps connu pour être supérieur à tous les décalages possibles (par exemple, après 12 heures), et vérifie si elles sont toujours terminées avec succès. Si l'étape échoue soudainement, la saga revient en arrière.
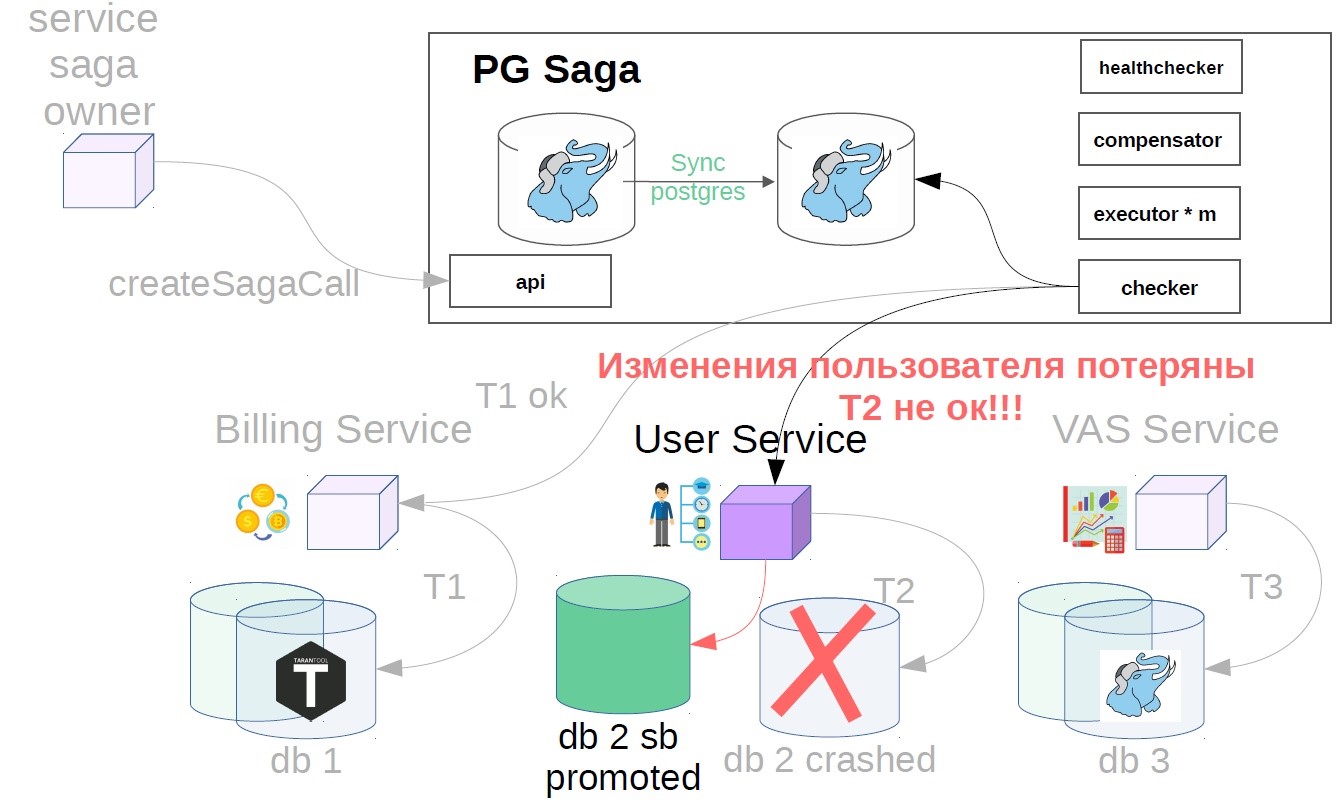
Il peut également y avoir des situations où après 12 heures il n'y a déjà rien à annuler - tout change et bouge. Dans ce cas, au lieu du scénario d'annulation, la solution peut être de signaler au service du propriétaire de la saga que cette opération n'est pas terminée. Si l'opération d'annulation n'est pas possible, par exemple, vous devez effectuer une annulation après avoir facturé l'utilisateur, et son solde est déjà nul et l'argent ne peut pas être radié. Nous avons de tels scénarios sont toujours résolus dans la direction de l'utilisateur. Vous pouvez avoir un principe différent, celui-ci est cohérent avec les représentants du produit.
En conséquence, comme vous l'avez peut-être remarqué, à différents endroits pour l'intégration avec le service sag, vous devez implémenter de nombreuses logiques différentes. Par conséquent, lorsque les équipes clientes veulent créer une saga, elles auront un ensemble très large de tâches très peu évidentes. Tout d'abord, nous créons une saga afin que la duplication ne fonctionne pas, pour cela nous travaillons avec une opération idempotente de création d'une saga et de son suivi. De plus, dans les services, il est nécessaire de réaliser la capacité de suivre chaque étape de chaque saga, afin de ne pas la réaliser deux fois d'une part, et, d'autre part, de pouvoir répondre si elle a été effectivement terminée. Et tous ces mécanismes doivent être entretenus d'une manière ou d'une autre afin que les référentiels de services ne débordent pas. De plus, il existe de nombreuses langues dans lesquelles les services peuvent être écrits et une vaste sélection de référentiels. À chaque étape, vous devez comprendre la théorie et implémenter toute cette logique dans différentes parties. Si vous ne le faites pas, vous pouvez faire tout un tas d'erreurs.
Il existe de nombreuses façons correctes, mais il n'y a pas moins de situations où vous pouvez «vous tirer une balle». Pour que les sagas fonctionnent correctement, vous devez encapsuler tous les mécanismes ci-dessus dans les bibliothèques clientes qui les implémenteront de manière transparente pour vos clients.
Un exemple de logique de génération de saga qui peut être caché dans la bibliothèque client
Cela peut être fait différemment, mais je propose l'approche suivante.
- Nous obtenons l'ID de demande par lequel nous devons créer la saga.
- Nous allons au service sag, obtenons son identifiant unique, l'enregistrons dans le stockage local en conjonction avec l'ID de demande du point 1.
- Exécutez la saga avec charge utile dans le service sag. Une nuance importante: je propose des opérations locales du service qui crée la saga, à concevoir, comme première étape de la saga.
- Il y a une certaine course où le service de la saga peut effectuer cette étape (point 3), et notre backend, qui initie la création de la saga, la réalisera également. Pour ce faire, nous effectuons des opérations idempotentes partout: une personne l'exécute et le deuxième appel reçoit simplement «OK».
- Nous appelons la première étape (point 4) et ce n'est qu'après que nous répondons au client qui a initié cette action.
Dans cet exemple, nous travaillons avec la saga comme base de données. Vous pouvez envoyer une demande, puis la connexion peut se rompre, mais l'action sera effectuée. Il s'agit de la même approche.
Comment tout vérifier
Il est nécessaire de couvrir l'ensemble du service des tests d'affaissement. Très probablement, vous apporterez des modifications et les tests écrits au début vous aideront à éviter les surprises inattendues. De plus, il est nécessaire de vérifier les sagas elles-mêmes. Par exemple, comment nous organisons le test du service sag et testons la séquence de fléchissement en une seule transaction. Il existe différents blocs de test. Si nous parlons du service d'affaissement, il sait comment effectuer des transactions positives et de compensation, si la compensation ne fonctionne pas, il informe le propriétaire de l'affaissement du service. Nous écrivons des tests de manière générale pour travailler avec une saga abstraite.
En revanche, les transactions positives et les transactions de compensation sur les services qui effectuent des étapes d'affaissement sont une simple API, et les tests de cette partie sont sous la responsabilité de l'équipe qui possède ce service.
Ensuite, l'équipe du propriétaire de la saga écrit des tests de bout en bout, où elle vérifie que toute la logique métier fonctionne correctement lorsque la saga est exécutée. Le test de bout en bout s'exécute sur un environnement de développement complet, toutes les instances de service sont déclenchées, y compris le service sag, et un scénario d'entreprise y est déjà testé.
Total:
- écrire plus de tests unitaires;
- écrire des tests d'intégration;
- écrire des tests de bout en bout.
La prochaine étape est CDC. L'architecture de microservice affecte les spécificités des tests. Chez Avito, nous avons adopté l'approche suivante pour tester l'architecture de microservices: les contrats axés sur le consommateur. Cette approche permet, tout d'abord, de mettre en évidence des problèmes qui peuvent être identifiés dans les tests de bout en bout, mais le test de bout en bout est «très coûteux».
Quelle est l'essence du CDC? Il existe un service qui fournit un contrat. Il a une API - c'est un fournisseur. Et il existe un autre service qui appelle l'API, c'est-à-dire qui utilise le contrat - consommateur.
Le service client écrit des tests pour le contrat du fournisseur et les tests que seul le contrat vérifiera ne sont pas des tests fonctionnels. Il est important pour nous de nous assurer que lors du changement d'API, les étapes dans ce contexte ne seront pas interrompues. Après avoir écrit les tests, un autre élément du Service Broker apparaît: des informations sur les tests CDC y sont enregistrées. Chaque fois que le service du fournisseur est modifié, il crée un environnement isolé et exécute les tests écrits par le consommateur. Quel est le résultat: l'équipe qui génère les sagas écrit des tests pour toutes les étapes de la saga et les enregistre.
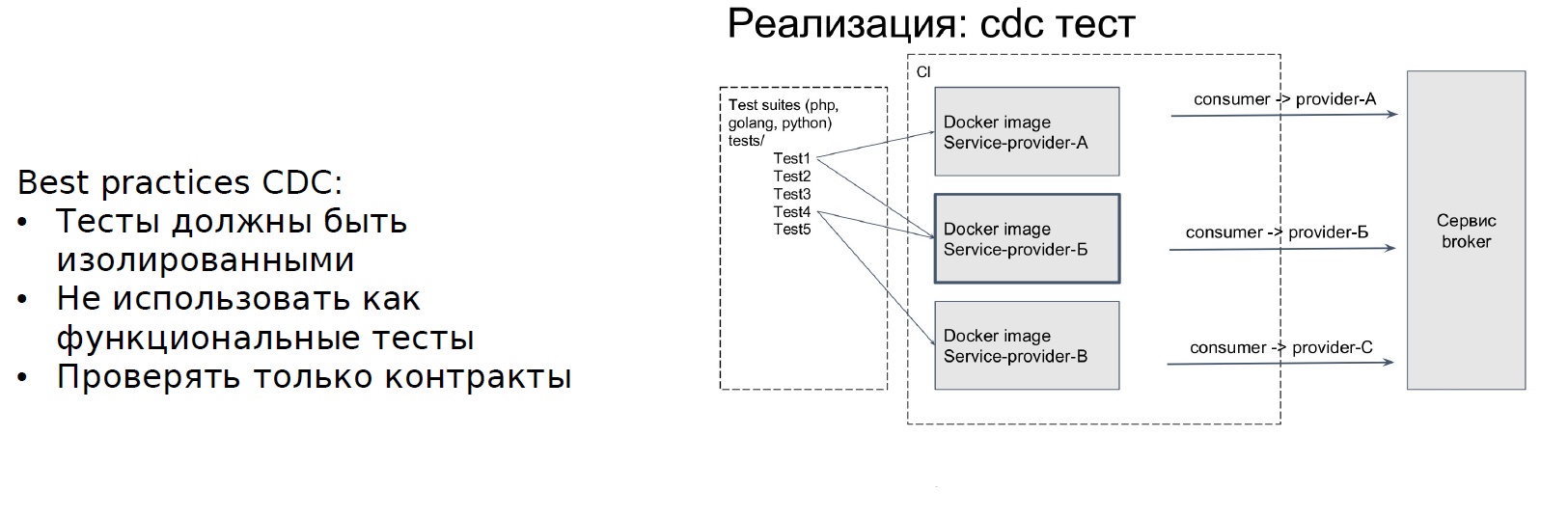
À propos de la façon dont Avito a mis en œuvre l'approche CDC pour tester les microservices, Frol Kryuchkov a parlé lors de RIT ++. Les résumés peuvent être trouvés sur le site Web Backend.conf - je vous recommande de vous familiariser.
Types de sagas
Dans l'ordre des appels de fonction
a) désordonné - les fonctions de la saga sont appelées dans n'importe quel ordre et n'attendent pas qu'elles se terminent;
b) ordonné - les fonctions de la saga sont appelées dans l'ordre donné, l'une après l'autre, la suivante n'est appelée que lorsque la précédente est terminée;
c) mixte - pour une partie des fonctions, l'ordre est défini, mais pas pour la partie, mais il est défini avant ou après les étapes pour les exécuter.
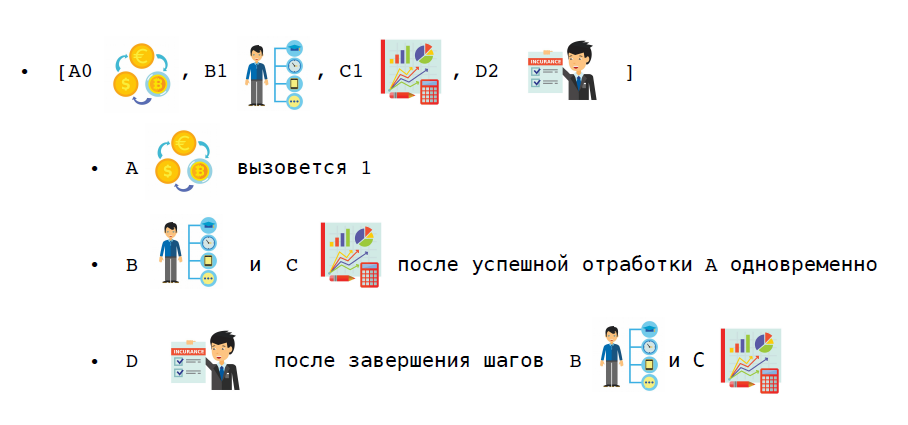
Considérez un scénario spécifique. Dans le même scénario d'achat d'un abonnement premium, la première étape consiste à réserver de l'argent. Nous pouvons maintenant apporter des modifications à l'utilisateur et créer des packages premium en parallèle, et nous n'informerons l'utilisateur que lorsque ces deux étapes seront terminées.
En obtenant le résultat de l'appel de fonction
a) synchrone - le résultat de la fonction est connu immédiatement;
b) asynchrone - la fonction renvoie immédiatement «OK» et le résultat est renvoyé ultérieurement, via un rappel à l'API du service sag à partir du service client.
Je veux vous mettre en garde contre une erreur: il vaut mieux ne pas faire de pas synchrones des sagas, surtout lors de l'implémentation d'une saga orchestrée. Si vous effectuez des étapes d'affaissement synchrones, le service d'affaissement attendra que cette étape soit terminée. C'est une charge supplémentaire, des problèmes supplémentaires au service des sagas, car il en est un, et il y a beaucoup de participants aux sagas.
Détartrage
La mise à l'échelle dépend de la taille du système que vous prévoyez. Considérez l'option avec une seule instance de stockage:
- un gestionnaire d'étape de saga, traiter les étapes avec des lots;
- n gestionnaires, nous implémentons un «peigne» - nous prenons des mesures pour le reste de la division: lorsque chaque exécuteur obtient ses propres étapes.
- n gestionnaires et skip verrouillés - seront encore plus efficaces et plus flexibles.
Et seulement alors, si vous savez à l'avance que vous allez rencontrer les performances d'un serveur dans un SGBD, vous devez effectuer le sharding - n instances de base de données qui fonctionneront avec leur ensemble de données. Le sharding peut être caché derrière l'API du service sag.
Plus de flexibilité
En outre, dans ce modèle, au moins en théorie, le service client (effectuant l'étape de la saga) peut accéder au service de sag et s'y intégrer, et la participation à la saga peut également être facultative. Il peut également y avoir un autre scénario: si vous avez déjà envoyé un e-mail, il est impossible de compenser l'action - vous ne pouvez pas retourner la lettre. Mais vous pouvez envoyer une nouvelle lettre que la précédente était erronée, et elle ressemble à telle ou telle chose. Il est préférable d'utiliser un scénario où la saga ne se jouera qu'en avant, sans aucune compensation. S'il ne fonctionne pas, il est nécessaire d'informer le service du propriétaire de la saga du problème.
Quand avez-vous besoin d'une serrure
Une petite digression sur les sagas en général: si vous pouvez faire votre logique sans la saga, alors faites-le. Les sagas sont difficiles. Avec un verrou, c'est à peu près la même chose: il vaut mieux toujours éviter les verrous.
Quand je suis venu à l'équipe de facturation pour parler des sagas, ils ont dit qu'ils avaient besoin d'une serrure. J'ai réussi à leur expliquer pourquoi il vaut mieux s'en passer et comment le faire. Mais si vous avez toujours besoin d'une serrure, cela doit être prévu à l'avance. Avant le service sag, nous avions déjà implémenté des verrous dans le cadre d'un SGBD. Un exemple avec defproc et un script pour bloquer les annonces de manière asynchrone et bloquer de manière synchrone un compte, lorsque nous effectuons d'abord une partie de l'opération de manière synchrone et définissons le verrou, puis de manière asynchrone en arrière-plan, nous terminons le reste du travail avec des lots.
Comment faire , , , , , - , . . . : , , .
-, , . , , . , , . . — , , .
ACID —
, , . . — durability. . . , . - , - - ,
— - , - , , - , . , - , - .
— .
:
- , , , , .
- , . , , , , , .
- .
- payload . eventual consistency — , , , . , , , -.
Suivi
. , . . checker. . , .
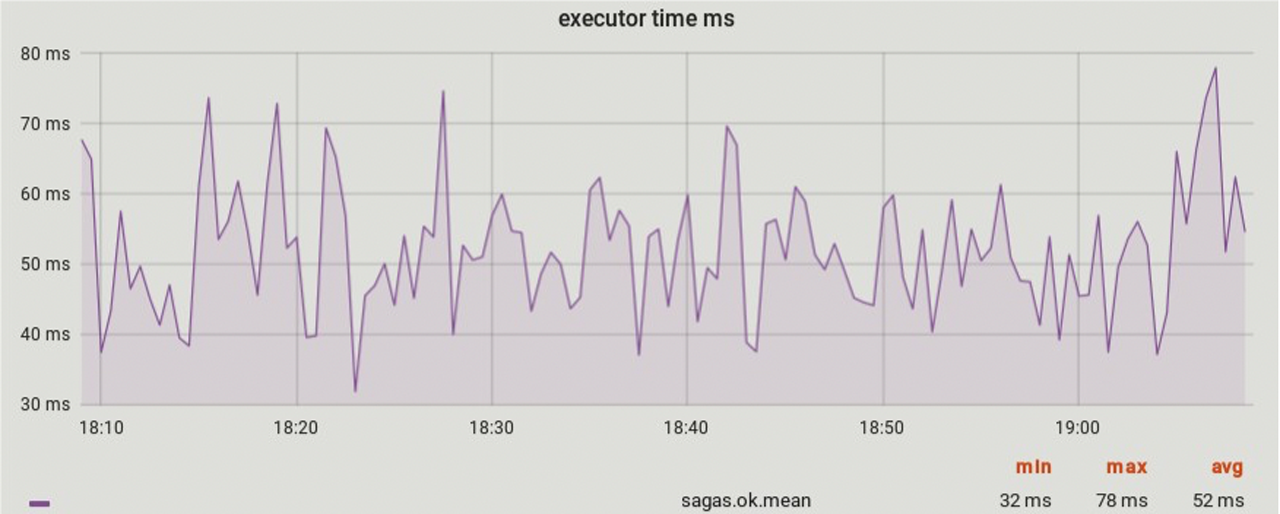
(50%, 75%, 95%, 99%), , - .
, — , . . , - . , — .
. , - ( ) . healthchecker endpoint' info (keep-alive) .
. -. -, - , - . , , , end-to-end. - . , , — .
. .
:
, healthchecker, - , . , . .
, . , , . . choreography — - . , choreography- , . choreography , . , . , , , .
. , , . , + .
API
, - - ( API ), , API. API . — . API , , 100% .
, , , , . — , , . .
, , , . ( ) .
, , , , .
. , , .
saga call ID
. API , .
—
- legacy . , ( «» ). « »? - , , , , - , . , , , . , « », , -. . — . , .
Je suis pour une approche pragmatique du développement, donc pour écrire un service de saga, un investissement dans l'écriture d'un tel service doit être justifié. De plus, très probablement, beaucoup de gens n'ont besoin que d'une partie de ce que j'ai décrit, et cette partie résoudra les besoins actuels. L'essentiel est de comprendre à l'avance ce qu'il faut exactement de tout cela. Et combien de ressources vous avez.
Si vous avez des questions ou souhaitez en savoir plus sur les sagas, écrivez dans les commentaires. Je serai ravi de répondre.