Remarque perev. : Cet article a été publié sur le blog officiel de Kubernetes et a été écrit par deux employés d'Intel qui sont directement impliqués dans le développement de CPU Manager, une nouvelle fonctionnalité de Kubernetes dont nous avons parlé dans la revue de la version 1.8 . Pour le moment (c'est-à-dire pour K8s 1.11), cette fonctionnalité a le statut bêta, et en savoir plus sur son objectif plus loin dans la note.La publication parle du
CPU Manager , une fonctionnalité bêta de Kubernetes. CPU Manager vous permet de mieux répartir les charges de travail dans Kubelet, c'est-à-dire sur l'agent hôte Kubernetes, en affectant des processeurs dédiés aux conteneurs d'un foyer spécifique.
Sonne bien! Mais le CPU Manager m'aidera-t-il?
Dépend de la charge de travail. Le seul nœud de calcul du cluster Kubernetes peut exécuter de nombreux foyers, et certains d'entre eux peuvent exécuter des charges actives dans la consommation du processeur. Dans ce scénario, les foyers peuvent rivaliser pour les ressources de processus disponibles sur ce nœud. Lorsque cette concurrence s'intensifie, la charge de travail peut se déplacer vers d'autres processeurs selon qu'elle a été
limitée et quels processeurs étaient disponibles au moment de la planification. De plus, il peut y avoir des cas où la charge de travail est sensible aux changements de contexte. Dans tous ces scénarios, les performances de la charge de travail peuvent être affectées.
Si votre charge de travail est sensible à de tels scénarios, vous pouvez activer CPU Manager pour fournir une meilleure isolation des performances en allouant des CPU spécifiques à la charge.
CPU Manager peut vous aider avec les fonctionnalités suivantes:
- Sensible aux effets de limitation du processeur
- sensible aux changements de contexte;
- le cache du processeur manque;
- Bénéficier de la division des ressources du processeur (par exemple, cache de données et instructions);
- mémoire sensible à la mémoire entre les sockets du processeur (une explication détaillée de ce que les auteurs ont en tête est donnée sur le Unix Stack Exchange - traduction approximative ) ;
- hyperthreads sensibles ou nécessitant le même noyau physique du CPU.
Ok! Comment l'utiliser?
L'utilisation de CPU Manager est simple. Tout d'abord,
activez-la à l'aide de la stratégie statique dans Kubelet exécutée sur les nœuds de calcul du cluster. Configurez ensuite la classe
de qualité de service garantie (QoS) pour l'âtre. Demandez un nombre entier de cœurs de processeur (par exemple
1000m ou
4000m ) pour les conteneurs qui ont besoin de cœurs dédiés. Créez sous la méthode précédente (par exemple,
kubectl create -f pod.yaml ) ... et le tour est joué - CPU Manager affectera des cœurs de processeur dédiés à chaque conteneur de foyer en fonction de leurs besoins en CPU.
apiVersion: v1 kind: Pod metadata: name: exclusive-2 spec: containers: - image: quay.io/connordoyle/cpuset-visualizer name: exclusive-2 resources: # Pod is in the Guaranteed QoS class because requests == limits requests: # CPU request is an integer cpu: 2 memory: "256M" limits: cpu: 2 memory: "256M"
Spécification d'un foyer demandant 2 CPU dédiées.Comment fonctionne le CPU Manager?
Nous considérons trois types de contrôle des ressources CPU disponibles dans la plupart des distributions Linux, qui seront pertinents pour Kubernetes et les objectifs de cette publication. Les deux premiers sont les partages CFS (quelle est ma part «honnête» pondérée du temps CPU dans le système) et le quota CFS (quel est le temps CPU maximum qui m'est alloué pour la période). CPU Manager utilise également un troisième, appelé affinité CPU (sur lequel les CPU logiques sont autorisés à effectuer des calculs).
Par défaut, tous les pods et conteneurs exécutés sur le nœud de cluster Kubernetes peuvent s'exécuter sur tous les noyaux système disponibles. Le nombre total de partages et de quotas attribués est limité par les ressources CPU réservées aux
Kubernetes et aux démons système . Cependant, des limites sur le temps CPU utilisé peuvent être déterminées en utilisant des
limites sur le CPU dans la spécification de l'âtre . Kubernetes utilise le
quota CFS pour appliquer les limites du processeur sur les conteneurs de foyer.
Lorsque vous activez le gestionnaire de CPU avec une stratégie
statique , il gère un pool dédié de CPU. Initialement, ce pool contient la totalité du CPU du nœud de calcul. Lorsque Kubelet crée un conteneur dans l'âtre avec un nombre garanti de cœurs de processeur dédiés, les CPU attribuées à ce conteneur lui sont allouées pour sa durée de vie et sont supprimées du pool partagé. Les charges des conteneurs restants sont transférées de ces noyaux dédiés à d'autres.
Tous les conteneurs sans CPU dédiés (
Burstable ,
BestEffort et
Guaranteed with non-integer CPUs ) s'exécutent sur des noyaux laissés dans le pool partagé. Lorsqu'un conteneur avec des CPU dédiés cesse de fonctionner, ses noyaux retournent dans le pool partagé.
Plus de détails, s'il vous plaît ...

Le diagramme ci-dessus montre l'anatomie du CPU Manager. Il utilise la méthode
UpdateContainerResources de l'interface CRI (Container Runtime Interface) pour modifier les processeurs sur lesquels les conteneurs s'exécutent.
Le gestionnaire fait correspondre périodiquement
cgroupfs à l'état actuel des ressources CPU pour chaque conteneur en cours d'exécution.
Le gestionnaire de processeur utilise des
stratégies pour décider de l'allocation des cœurs de processeur. Deux stratégies sont mises en œuvre:
aucune et
statique . Par défaut, à partir de Kubernetes version 1.10, il est activé avec la stratégie
None .
La stratégie
statique attribue des conteneurs de pod alloués au processeur à la classe QoS garantie, qui demande un nombre entier de cœurs. La politique
statique essaie de désigner le CPU de la meilleure manière topologique et dans l'ordre suivant:
- Attribuez tous les CPU à un socket de processeur, si disponible et le conteneur nécessite un CPU dans la quantité d'au moins un socket de CPU entier.
- Affectez tous les processeurs logiques (hyperthreads) d'un cœur de processeur physique, le cas échéant, et le conteneur nécessite un processeur d'au moins la totalité du cœur.
- Attribuez tous les CPU logiques disponibles avec une préférence pour les CPU à partir d'un seul socket.
Comment CPU Manager améliore-t-il l'isolation des calculs?
Lorsque la stratégie
statique est activée dans CPU Manager, les charges de travail peuvent mieux fonctionner pour l'une des raisons suivantes:
- Les CPU dédiées peuvent être affectées à un conteneur avec une charge de travail, mais pas à d'autres conteneurs. Ces (autres) conteneurs n'utilisent pas les mêmes ressources CPU. Par conséquent, nous nous attendons à de meilleures performances en raison de l'isolement en cas d'apparition d'un «agresseur» (processus exigeants en CPU - environ Transl. ) Ou d'une charge de travail adjacente.
- Il y a moins de concurrence pour les ressources utilisées par la charge de travail, car nous pouvons diviser le processeur par la charge de travail elle-même. Ces ressources peuvent inclure non seulement le processeur, mais également les hiérarchies de cache et la bande passante mémoire. Cela améliore les performances globales de la charge de travail.
- Le gestionnaire de CPU attribue le CPU dans un ordre topologique basé sur les meilleures options disponibles. Si l'ensemble du socket est libre, il affectera tous ses CPU à la charge de travail. Cela améliore les performances de la charge de travail en raison du manque de trafic entre les sockets.
- Les conteneurs en dosettes avec QoS garantie sont soumis à la limite de quota CFS. Les charges de travail sujettes à des explosions soudaines peuvent être planifiées et dépasser leur quota avant la fin de la période qui leur est allouée, ce qui les limite . Les processeurs impliqués à ce stade peuvent avoir un travail à la fois important et peu utile. Cependant, ces conteneurs ne seront pas soumis à la limitation CFS lorsque le CPU de quota est complété par une politique d'allocation de CPU dédiée.
Ok! Avez-vous des résultats?
Pour voir les améliorations de performances et l'isolement fournis par l'inclusion du gestionnaire de CPU dans Kubelet, nous avons mené des expériences sur un nœud de calcul avec deux sockets (CPU Intel Xeon E5-2680 v3) et hyperthreading activé. Le nœud se compose de 48 CPU logiques (24 cœurs physiques, chacun avec hyperthreading). Les performances et les avantages d'isolation du CPU Manager capturés par les charges de travail de référence et réelles dans trois scénarios différents sont présentés ci-dessous.
Comment interpréter les graphiques?
Pour chaque scénario, des graphiques sont affichés (
diagrammes d'étendue, diagrammes en boîte) illustrant le temps d'exécution normalisé et sa variabilité lors du démarrage d'un test de référence ou d'une charge réelle avec le gestionnaire de CPU activé et désactivé. Le temps de course est normalisé aux lancements les plus performants (1,00 sur l'axe Y représente le meilleur temps de démarrage: plus la valeur du graphique est basse, mieux c'est). La hauteur du tracé sur le graphique montre la variabilité des performances. Par exemple, si le site est une ligne, il n'y a aucune variation de performances pour ces lancements. Dans ces zones elles-mêmes, la ligne médiane est la médiane, le haut est le 75e centile et le bas est le 25e centile. La hauteur du tracé (c'est-à-dire la différence entre les 75e et 25e centiles) est définie comme l'intervalle interquartile (IQR). "Moustache" affiche les données en dehors de cet intervalle, et les points montrent les valeurs aberrantes. Les émissions sont définies comme toute donnée qui diffère de l'IQR de 1,5 fois - moins ou plus que le quartile correspondant. Chaque expérience a été réalisée 10 fois.
Protection agressive
Nous avons lancé six benchmark'ov à partir d'un
ensemble de PARSEC (charges de travail - "victimes")
[plus d'informations sur les charges de travail des victimes peuvent être lues, par exemple, ici - env. perev. ] à côté du conteneur qui charge le processeur (charge de travail «d'agresseur») avec le gestionnaire de processeur activé et désactivé.
Le conteneur d'agresseur est lancé
comme sous avec la classe
Burstable QoS demandant l'indicateur 23 CPU
--cpus 48 . Les benchmarks sont exécutés
sous forme de pods avec la classe QoS
garantie , qui nécessite un ensemble de CPU à partir d'un socket complet (soit 24 CPU sur ce système). Les graphiques ci-dessous montrent l'heure de début de pod normalisée avec un repère à côté de l'agresseur de pod, avec la politique
statique de CPU Manager et sans elle. Dans tous les cas de test, vous pouvez voir des performances améliorées et une variabilité des performances réduite avec la stratégie activée.

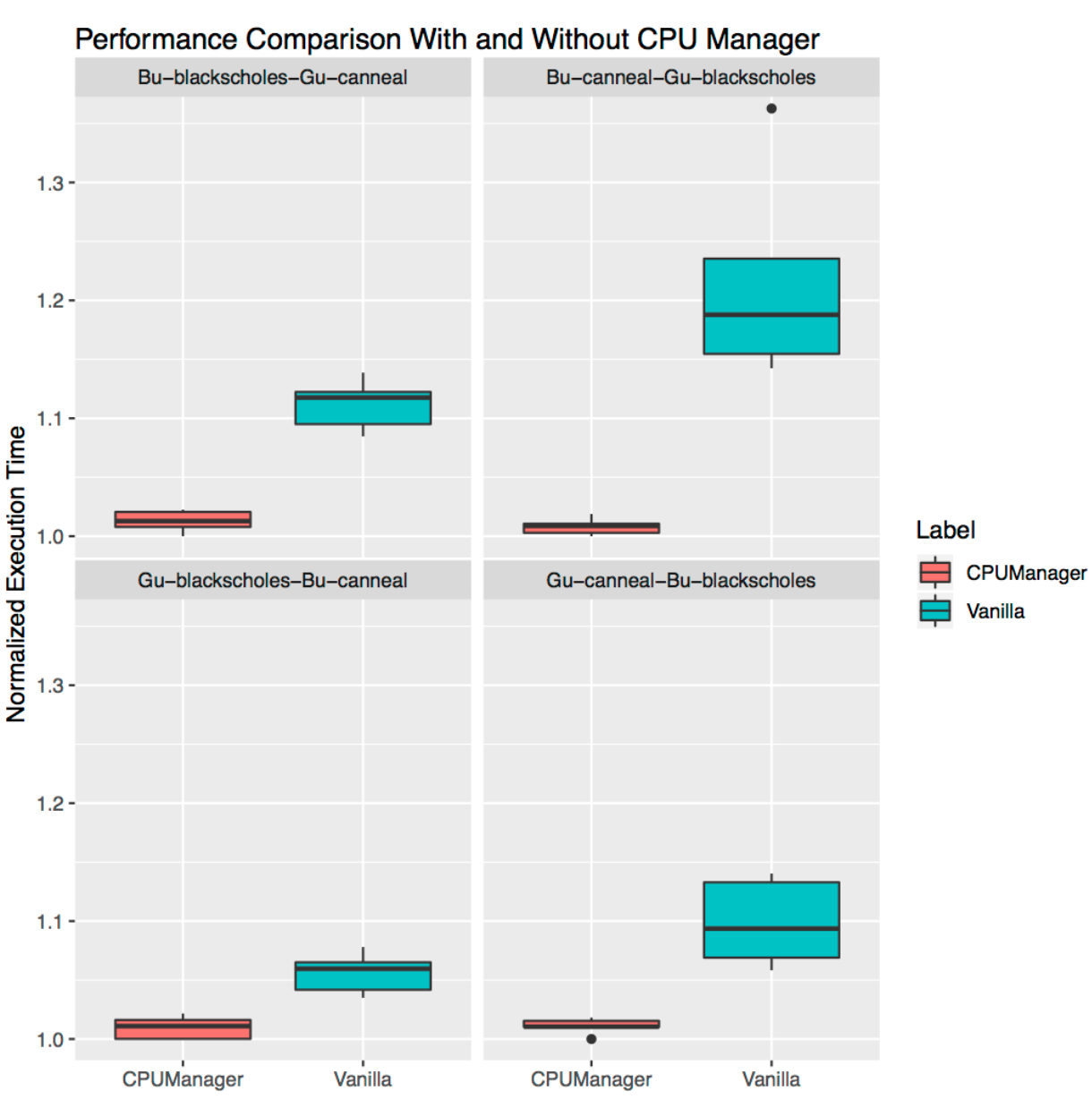
Isolation pour charges adjacentes
Cela montre à quel point le gestionnaire de processeur peut être utile pour de nombreuses charges de travail colocalisées. Les diagrammes d'étendue ci-dessous montrent les performances de deux benchmarks de l'ensemble PARSEC (
Blackscholes et
Canneal ) lancés pour les classes QoS
garanties (Gu) et
Burstable (Bu) qui sont adjacentes l'une à l'autre, avec la politique
statique activée et désactivée.
Dans le sens des aiguilles d'une montre à partir du graphique supérieur gauche, nous voyons les performances de
Blackscholes pour Bu QoS (en haut à gauche),
Canneal pour Bu QoS (en haut à droite),
Canneal pour Gu QoS (en bas à droite) et
Blackscholes pour Gu QoS (en bas à gauche). Sur chaque graphique, ils sont situés (à nouveau dans le sens des aiguilles d'une montre) avec
Canneal pour Gu QoS (en haut à gauche),
Blackscholes pour Gu QoS (en haut à droite),
Blackscholes pour Bu QoS (en bas à droite) et
Canneal pour Bu QoS (en bas à gauche) en conséquence. Par exemple, le
graphique Bu-blackscholes-Gu-canneal (en haut à gauche) montre les performances des
Blackscholes fonctionnant avec Bu QoS et situés à côté de
Canneal avec la classe Gu QoS. Dans chaque cas, under avec la classe Gu QoS nécessite un noyau socket complet (c'est-à-dire 24 CPU), et under avec la classe Bu QoS - 23 CPU.
Il y a de meilleures performances et moins de variation de performances pour les deux charges de travail adjacentes dans tous les tests. Par exemple, regardez
Bu-blackscholes-Gu-canneal (en haut à gauche) et
Gu-canneal-Bu-blackscholes (en bas à droite). Ils montrent les performances à la fois de l'exécution de
Blackscholes et de
Canneal avec le gestionnaire de processeur
activé et désactivé. Dans ce cas,
Canneal reçoit plus de cœurs dédiés du gestionnaire de processeur, car il appartient à la classe Gu QoS et demande un nombre entier de cœurs de processeur. Cependant,
Blackscholes obtient
également un ensemble dédié de processeurs, car il s'agit de la seule charge de travail dans le pool partagé. En conséquence,
Blackscholes et
Canneal profitent de l'isolation de la charge lors de l'utilisation de CPU Manager.
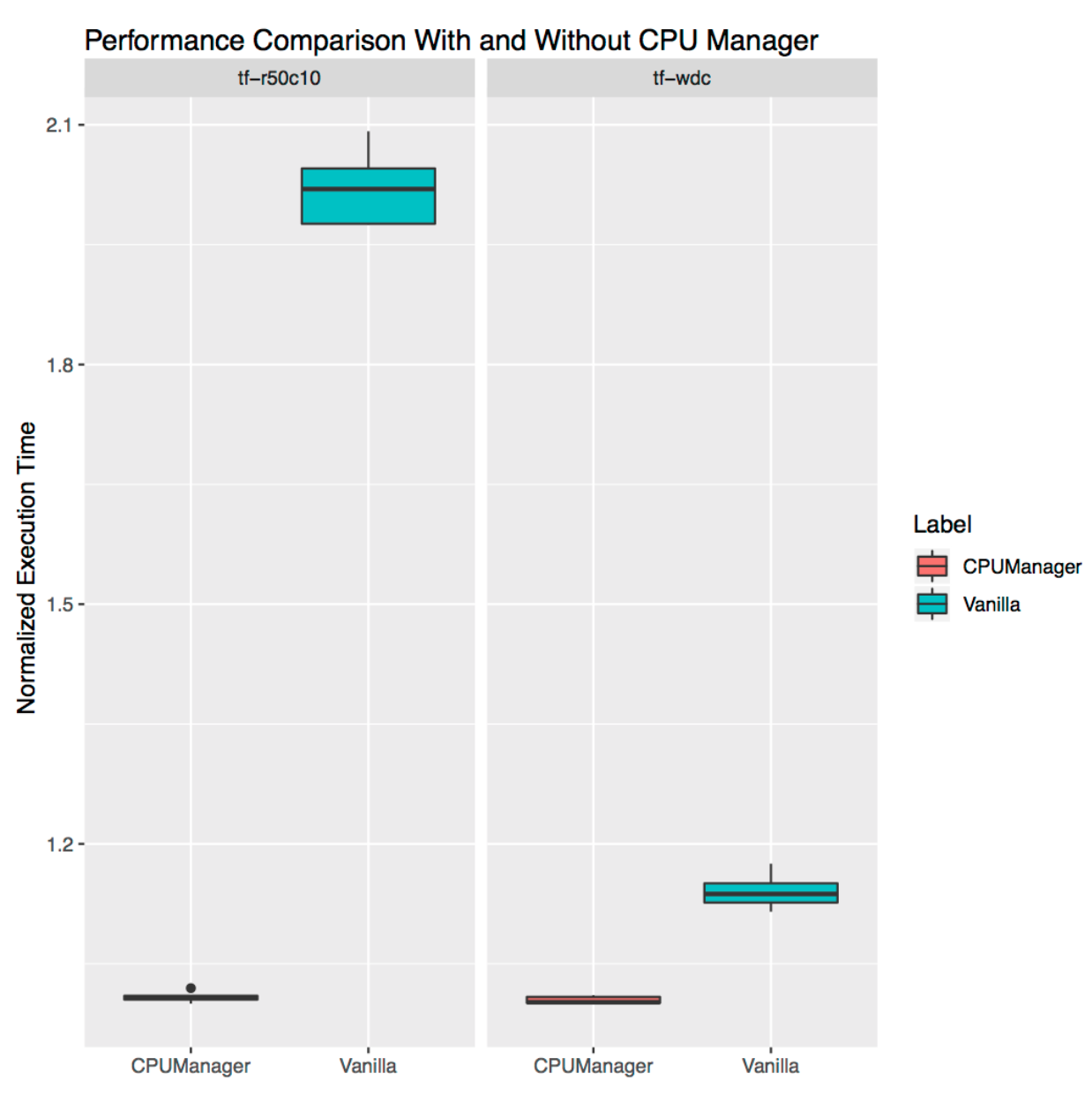
Isolation pour charges autoportantes
Il montre à quel point CPU Manager peut être utile pour les charges de travail autonomes de la vie réelle. Nous avons pris deux charges des
modèles officiels TensorFlow :
large et profonde et
ResNet . Des ensembles de données typiques leur sont utilisés (recensement et CIFAR10, respectivement). Dans les deux cas, les
foyers (
larges et profonds ,
ResNet ) nécessitent 24 CPU, ce qui correspond à un socket complet. Comme le montrent les graphiques, dans les deux cas, le gestionnaire de CPU offre une meilleure isolation.
Limitations
Les utilisateurs peuvent souhaiter obtenir des CPU alloués sur un socket proche du bus se connectant à un périphérique externe tel qu'un accélérateur ou une carte réseau hautes performances pour éviter le trafic entre les sockets. Ce type de configuration n'est pas encore pris en charge dans le gestionnaire de CPU. Étant donné que le gestionnaire de processeur fournit la meilleure allocation possible de processeurs appartenant à un socket ou à un noyau physique, il est sensible aux cas extrêmes et peut entraîner une fragmentation. CPU Manager ne prend pas en compte le paramètre de démarrage du noyau Linux
isolcpus , bien qu'il soit utilisé comme pratique courante dans certains cas
(pour plus de détails sur ce paramètre, voir, par exemple, ici - env .
PS du traducteur
Lisez aussi dans notre blog: