
Au cours des dernières années, le sujet de l'intelligence artificielle et de l'apprentissage automatique a cessé d'être quelque chose pour les gens du domaine de la fiction et est fermement entré dans la vie quotidienne. Les réseaux sociaux proposent d'assister à des événements qui nous intéressent, les voitures sur les routes ont appris à se déplacer sans chauffeur, et un assistant vocal au téléphone indique quand il vaut mieux quitter la maison pour éviter les embouteillages et s'il faut prendre un parapluie avec vous.
Dans cet article, nous examinerons les outils d'apprentissage automatique proposés par les développeurs Apple, analyserons ce que l'entreprise a montré de nouveau dans ce domaine lors de la WWDC18, et essayer de comprendre comment mettre tout cela en pratique.
Apprentissage automatique
Ainsi, l'apprentissage automatique est un processus au cours duquel un système, utilisant certains algorithmes d'analyse de données et traitant un grand nombre d'exemples, identifie des modèles et les utilise pour prédire les caractéristiques de nouvelles données.
L'apprentissage automatique est né de la théorie selon laquelle les ordinateurs peuvent apprendre par eux-mêmes, pas encore programmés pour effectuer certaines actions. En d'autres termes, contrairement aux programmes conventionnels avec des instructions prédéfinies pour résoudre des problèmes spécifiques, l'apprentissage automatique permet au système d'apprendre à reconnaître indépendamment les modèles et à faire des prédictions.
BNNS et CNN
Apple utilise la technologie d'apprentissage automatique sur ses appareils depuis un certain temps: Mail identifie les spams, Siri vous aide à trouver rapidement des réponses à vos questions, Photos reconnaît les visages sur les images.
Lors de la WWDC16, la société a introduit deux API basées sur un réseau de neurones - les sous-programmes de réseau de neurones de base (BNNS) et les réseaux de neurones à convolution (CNN). BNNS fait partie du système Accelerate, qui est la base pour effectuer des calculs rapides sur le CPU, et CNN est la bibliothèque Metal Performance Shaders qui utilise le GPU. Vous pouvez en savoir plus sur ces technologies, par exemple, ici .
Core ML et Turi Create
L'année dernière, Apple a annoncé un cadre qui facilite grandement le travail avec les technologies d'apprentissage automatique - Core ML. Il est basé sur l'idée de prendre un modèle de données pré-formé et de l'intégrer dans votre application en quelques lignes de code.
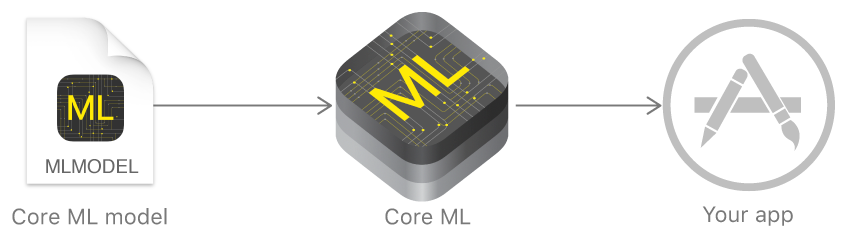
En utilisant Core ML, vous pouvez implémenter de nombreuses fonctions:
- définition d'objets dans une photo et une vidéo;
- saisie de texte prédictive;
- suivi et reconnaissance des visages;
- analyse de mouvement;
- définition de code à barres;
- compréhension et reconnaissance du texte;
- reconnaissance d'image en temps réel;
- stylisation d'image;
- et bien plus.
Core ML, quant à lui, utilise de bas niveau Metal, Accelerate et BNNS, et donc les résultats des calculs sont très rapides.
Le noyau prend en charge les réseaux de neurones, les modèles linéaires généralisés, l'ingénierie des fonctionnalités, les algorithmes de prise de décision basés sur des arbres (ensembles d'arbres), la méthode des machines à vecteurs de support, les modèles de pipeline.
Mais Apple n'a pas initialement montré ses propres technologies pour créer et former des modèles, mais a seulement fait un convertisseur pour d'autres cadres populaires: Caffe, Keras, scikit-learn, XGBoost, LIBSVM.
L'utilisation d'outils tiers n'était souvent pas la tâche la plus facile, les modèles formés étaient assez volumineux et la formation elle-même prenait beaucoup de temps.
À la fin de l'année, la société a présenté Turi Create - un cadre pour les modèles de formation, dont l'idée principale était la facilité d'utilisation et la prise en charge d'un grand nombre de scénarios - classification d'images, définition d'objets, systèmes de recommandation, et bien d'autres. Mais Turi Create, malgré sa relative facilité d'utilisation, ne supportait que Python.
Créer ML
Et cette année, Apple, en plus de Core ML 2, a enfin montré son propre outil de formation pour les modèles - le framework Create ML utilisant les technologies natives d'Apple - Xcode et Swift.
Cela fonctionne rapidement et la création de modèles de modèles avec Create ML est vraiment facile.
À la WWDC, les performances impressionnantes de Create ML et Core ML 2 ont été annoncées en utilisant l'exemple de l'application Memrise. Si auparavant, il fallait 24 heures pour former un modèle en utilisant 20 000 images, alors Create ML réduit ce temps à 48 minutes sur le MacBook Pro et jusqu'à 18 minutes sur l'iMac Pro. La taille du modèle entraîné est passée de 90 Mo à 3 Mo.
Create ML vous permet d'utiliser des images, des textes et des objets structurés comme des tableaux, par exemple, comme données source.
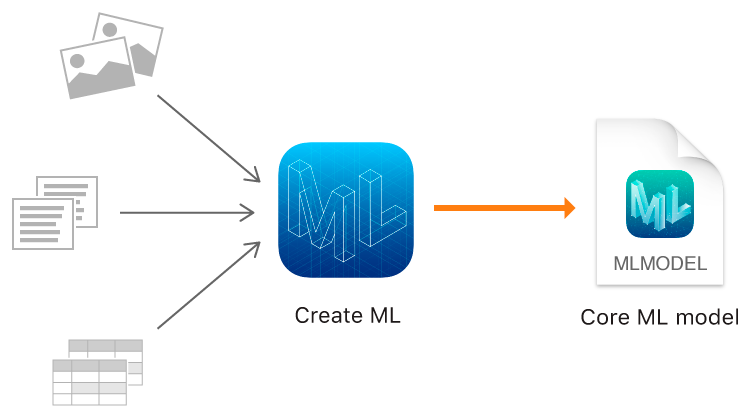
Classification d'image
Voyons d'abord comment fonctionne la classification des images. Pour former le modèle, nous avons besoin d'un premier ensemble de données: nous prenons trois groupes de photos d'animaux: chiens, chats et oiseaux et les distribuons dans des dossiers avec les noms correspondants, qui deviendront les noms des catégories du modèle. Chaque groupe contient 100 images avec une résolution allant jusqu'à 1920 × 1080 pixels et une taille allant jusqu'à 1 Mo. Les photographies doivent être aussi différentes que possible afin que le modèle formé ne se fonde pas sur des signes tels que la couleur de l'image ou l'espace environnant.
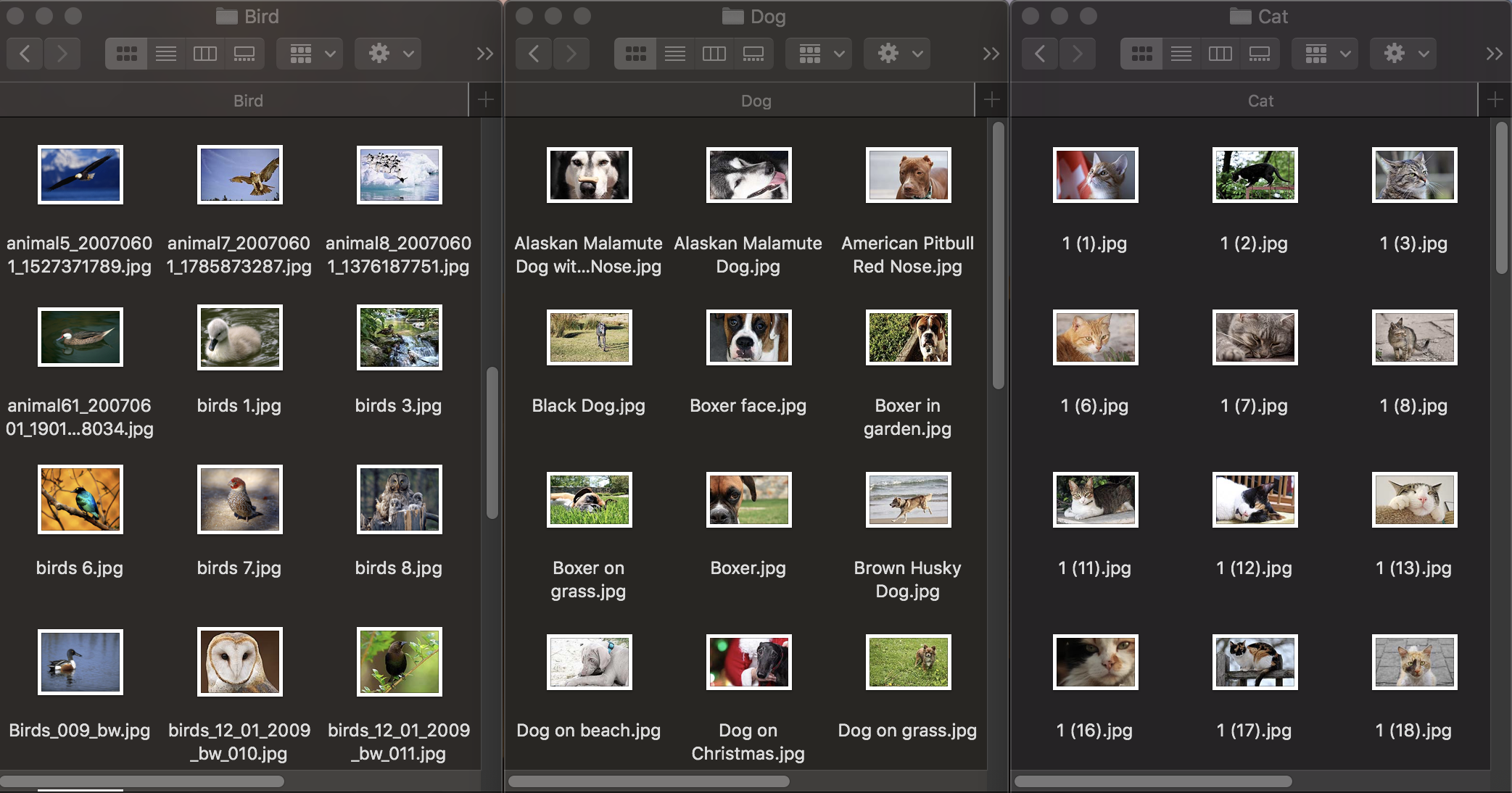
De plus, pour vérifier dans quelle mesure un modèle formé gère la reconnaissance d'objets, vous avez besoin d'un ensemble de données de test - des images qui ne figurent pas dans l'ensemble de données d'origine.
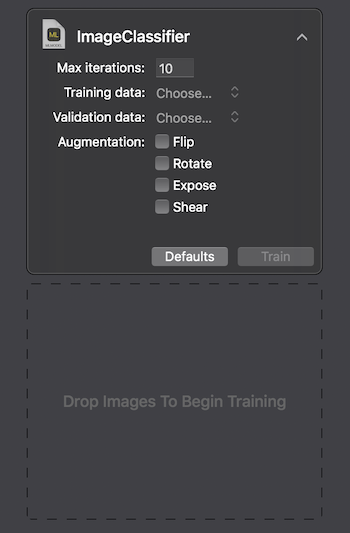
Apple propose deux façons d'interagir avec Create ML: en utilisant l'interface utilisateur sur le Maccode Playground Xcode et par programme en utilisant CreateMLUI.framework et CreateML.framework. En utilisant la première méthode, il suffit d'écrire quelques lignes de code, de transférer les images sélectionnées vers la zone spécifiée et d'attendre que le modèle apprenne.

Sur le Macbook Pro 2017 dans la configuration maximale, la formation a duré 29 secondes pendant 10 itérations et la taille du modèle formé était de 33 Ko. C'est impressionnant.
Essayons de comprendre comment nous avons réussi à atteindre ces indicateurs et ce qui est «sous le capot».
La classification des images est l'une des utilisations les plus populaires des réseaux de neurones convolutifs. Tout d'abord, cela vaut la peine d'expliquer ce qu'ils sont.
Une personne, voyant une image d'un animal, peut rapidement l'attribuer à une certaine classe sur la base de toute caractéristique distinctive. Un réseau de neurones agit de manière similaire en recherchant des caractéristiques de base. Prenant le tableau initial de pixels comme entrée, il transmet séquentiellement des informations à travers des groupes de couches convolutives et construit des abstractions de plus en plus complexes. Sur chaque calque suivant, elle apprend à mettre en évidence certaines caractéristiques - ce sont d'abord des lignes, puis des ensembles de lignes, des formes géométriques, des parties du corps, etc. Sur la dernière couche, nous obtenons la conclusion d'une classe ou d'un groupe de classes probables.
Dans le cas de Create ML, l'entraînement du réseau neuronal n'est pas effectué à partir de zéro. Le cadre utilise un réseau de neurones préalablement formé sur un énorme ensemble de données, qui comprend déjà un grand nombre de couches et a une grande précision.
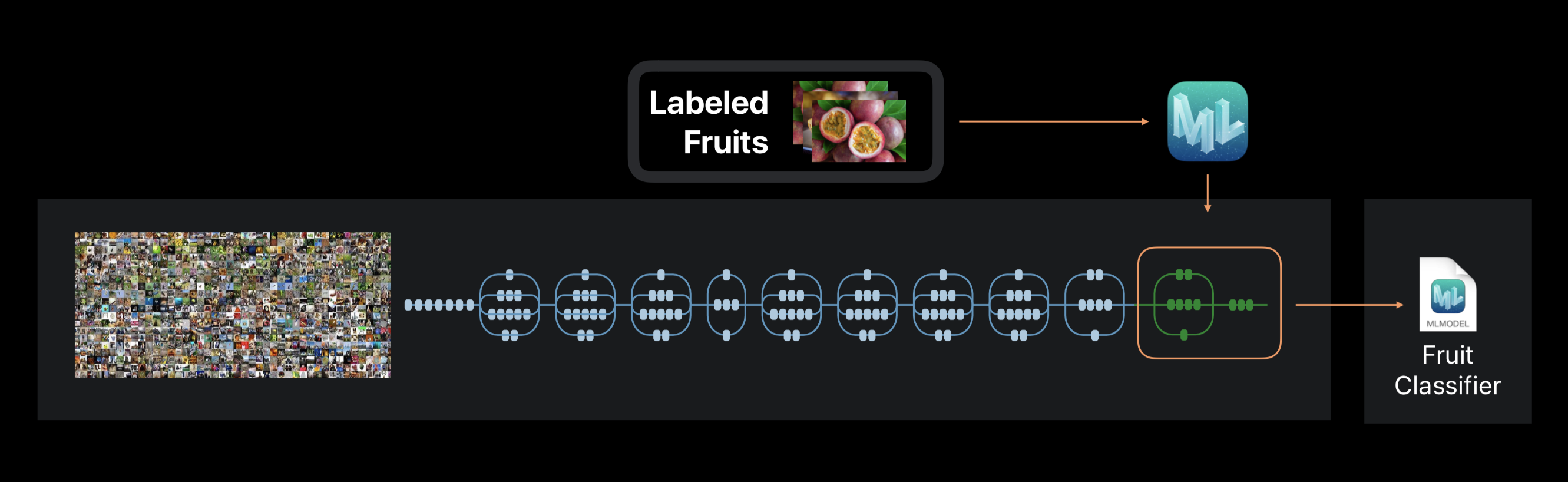
Cette technologie est appelée apprentissage par transfert. Avec lui, vous pouvez changer l'architecture d'un réseau pré-formé afin qu'il soit adapté à la résolution d'un nouveau problème. Le réseau modifié est ensuite formé sur un nouvel ensemble de données.
Créez ML pendant l'entraînement des extraits de la photo d'environ 1000 caractéristiques distinctives. Cela peut être la forme des objets, la couleur des textures, l'emplacement des yeux, les tailles et bien d'autres.
Il convient de noter que l'ensemble de données initial sur lequel le réseau de neurones utilisé est formé, comme le nôtre, peut contenir des photographies de chats, de chiens et d'oiseaux, mais ces catégories ne sont pas spécifiquement attribuées. Toutes les catégories forment une hiérarchie. Par conséquent, il est tout simplement impossible d'appliquer ce réseau dans sa forme pure - il est nécessaire de le recycler sur nos données.
À la fin du processus, nous voyons avec quelle précision notre modèle a été formé et testé après plusieurs itérations. Pour améliorer les résultats, nous pouvons augmenter le nombre d'images dans le jeu de données d'origine ou modifier le nombre d'itérations.
Ensuite, nous pouvons tester le modèle nous-mêmes sur un ensemble de données de test. Les images qu'il contient doivent être uniques, c'est-à-dire N'entrez pas dans l'ensemble source.
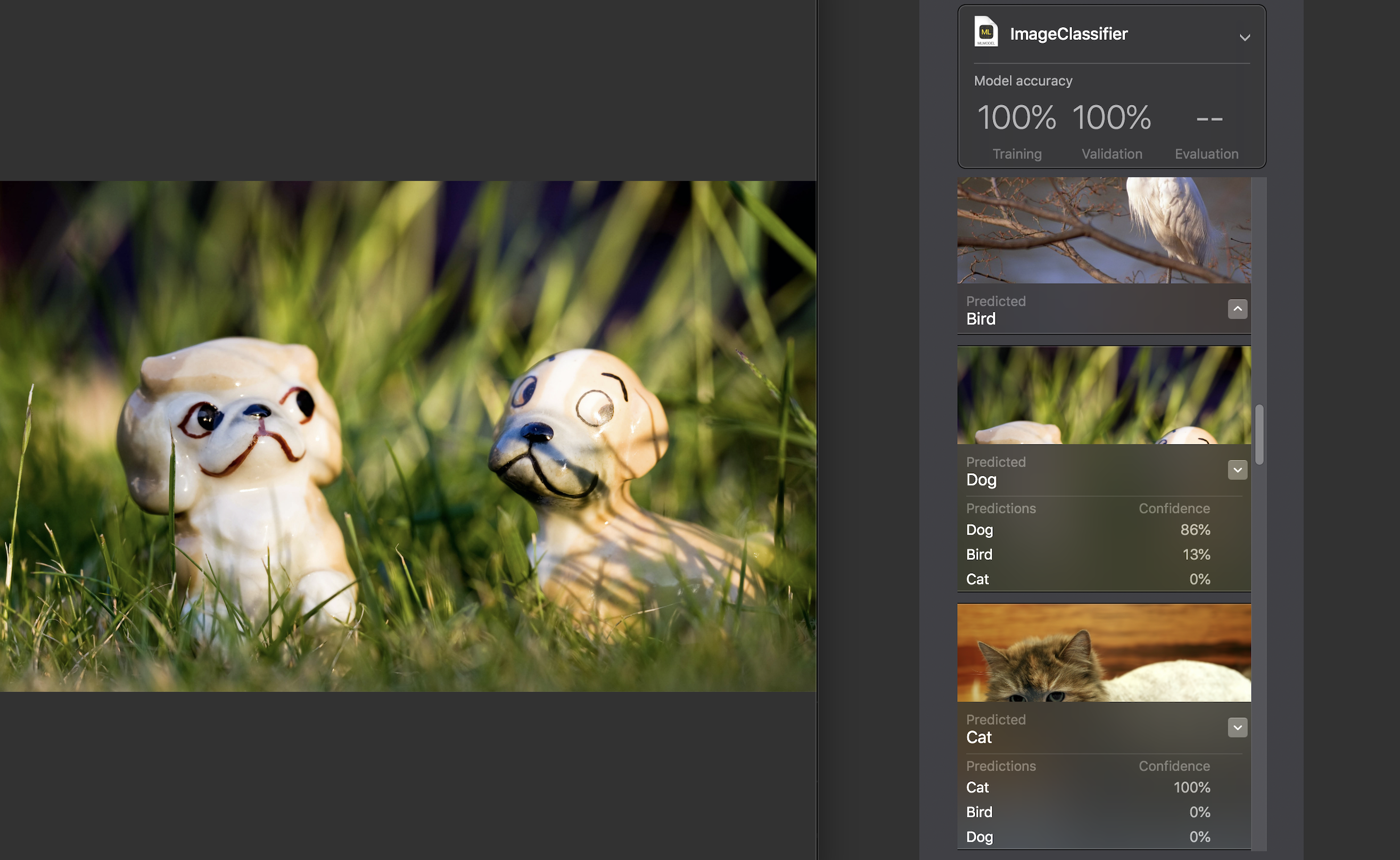
Pour chaque image, un indicateur de confiance est affiché - avec quelle précision à l'aide de notre modèle la catégorie a été reconnue.
Pour presque toutes les photos, à de rares exceptions près, ce chiffre était de 100%. J'ai spécifiquement ajouté l'image que vous voyez ci-dessus à l'ensemble de données de test et, comme vous pouvez le voir, Create ML a reconnu 86% du chien et 13% de l'oiseau.
La formation sur les modèles est terminée et il ne nous reste plus qu'à enregistrer le fichier * .mlmodel et à l'ajouter à votre projet.
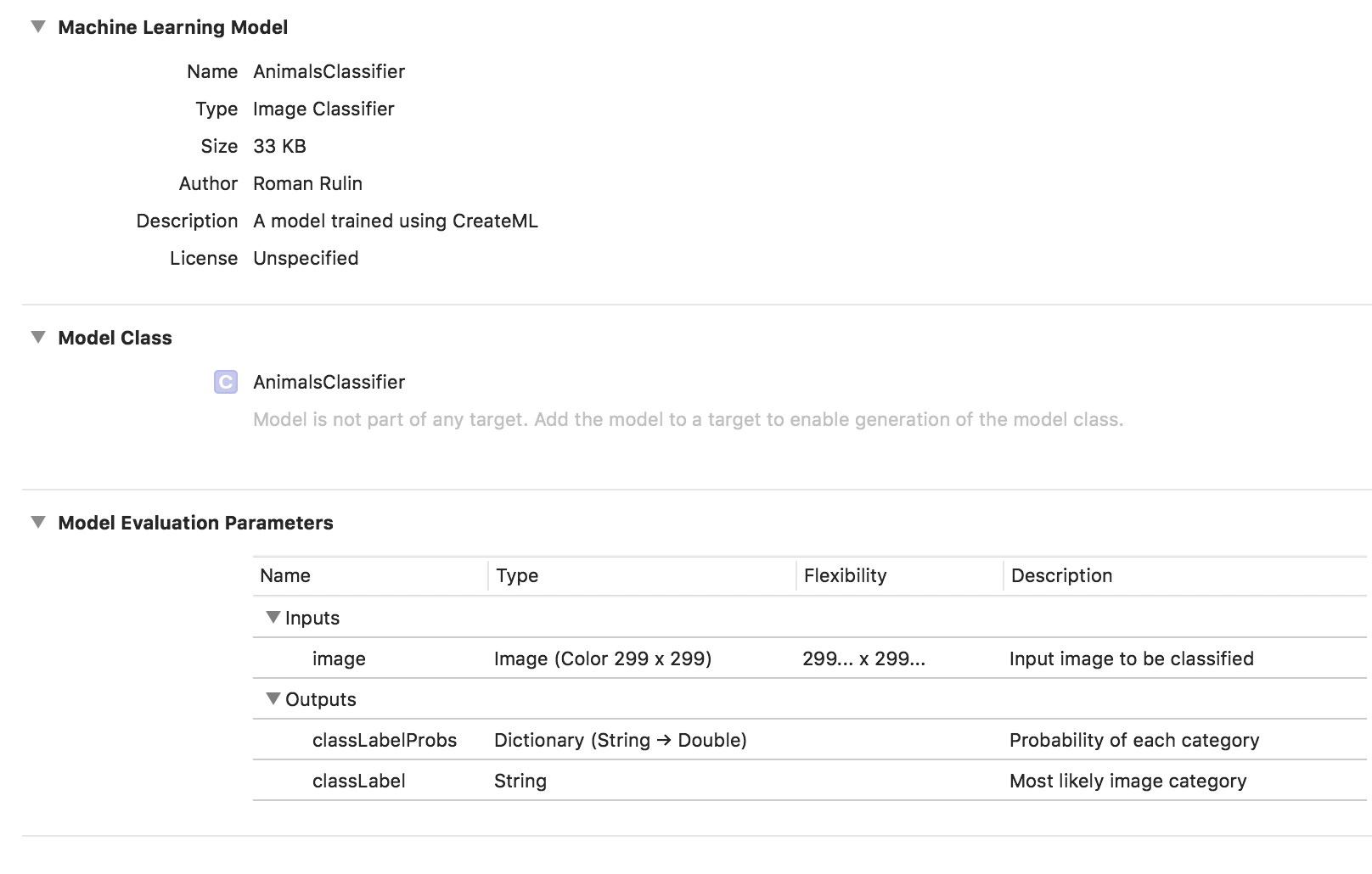
Pour tester le modèle, j'ai écrit une application simple utilisant le framework Vision. Il vous permet de travailler avec des modèles Core ML et de résoudre des problèmes en les utilisant, tels que la classification d'images ou la détection d'objets.
Notre application reconnaîtra l'image de la caméra de l'appareil et affichera la catégorie et le pourcentage de confiance dans la classification.
Nous initialisons le modèle Core ML pour travailler avec Vision et configurons la requête:
func setupVision() { guard let visionModel = try? VNCoreMLModel(for: AnimalsClassifier().model) else { fatalError("Can't load VisionML model") } let request = VNCoreMLRequest(model: visionModel) { (request, error) in guard let results = request.results else { return } self.handleRequestResults(results) } requests = [request] }
Ajoutez une méthode qui traitera les résultats de VNCoreMLRequest. Nous ne montrons que ceux avec un indicateur de confiance supérieur à 70%:
func handleRequestResults(_ results: [Any]) { let categoryText: String? defer { DispatchQueue.main.async { self.categoryLabel.text = categoryText } } guard let foundObject = results .compactMap({ $0 as? VNClassificationObservation }) .first(where: { $0.confidence > 0.7 }) else { categoryText = nil return } let category = categoryTitle(identifier: foundObject.identifier) let confidence = "\(round(foundObject.confidence * 100 * 100) / 100)%" categoryText = "\(category) \(confidence)" }
Et le dernier - nous ajouterons la méthode déléguée AVCaptureVideoDataOutputSampleBufferDelegate, qui sera appelée avec chaque nouvelle image de la caméra et exécutera la demande:
func captureOutput( _ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) { guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else { return } var requestOptions: [VNImageOption: Any] = [:] if let cameraIntrinsicData = CMGetAttachment( sampleBuffer, key: kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, attachmentModeOut: nil) { requestOptions = [.cameraIntrinsics:cameraIntrinsicData] } let imageRequestHandler = VNImageRequestHandler( cvPixelBuffer: pixelBuffer, options: requestOptions) do { try imageRequestHandler.perform(requests) } catch { print(error) } }
Vérifions dans quelle mesure le modèle fait face à sa tâche:

La catégorie est déterminée avec une précision assez élevée, ce qui est particulièrement surprenant lorsque l'on considère la rapidité de la formation et la petite taille du jeu de données d'origine. Périodiquement, sur un fond sombre, le modèle révèle des oiseaux, mais je pense que cela peut être facilement résolu en augmentant le nombre d'images dans l'ensemble de données d'origine ou en augmentant le niveau de confiance minimum acceptable.
Si nous voulons recycler le modèle pour classer une autre catégorie, ajoutez simplement un nouveau groupe d'images et répétez le processus - cela prendra quelques minutes.
À titre expérimental, j'ai réalisé un autre ensemble de données, dans lequel j'ai changé toutes les photos de chats sur la photo d'un chat sous différents angles, mais sur le même fond et dans le même environnement. Dans ce cas, le modèle a presque toujours commis des erreurs et reconnu la catégorie dans une pièce vide, en s'appuyant apparemment sur la couleur comme caractéristique clé.
Une autre fonctionnalité intéressante introduite dans Vision cette année seulement est la possibilité de reconnaître des objets dans l'image en temps réel. Il est représenté par la classe VNRecognizedObjectObservation, qui vous permet d'obtenir la catégorie d'un objet et son emplacement - boundingBox.

Maintenant, Create ML ne permet pas de créer des modèles pour implémenter cette fonctionnalité. Apple suggère d'utiliser Turi Create dans ce cas. Le processus n'est pas beaucoup plus compliqué que ci-dessus: vous devez préparer des dossiers de catégorie avec des photos et un fichier dans lequel pour chaque image les coordonnées du rectangle où se trouve l'objet seront indiquées.
Traitement du langage naturel
La prochaine fonction Create ML consiste à former des modèles pour classer les textes en langage naturel - par exemple, pour déterminer la coloration émotionnelle des phrases ou détecter le spam.
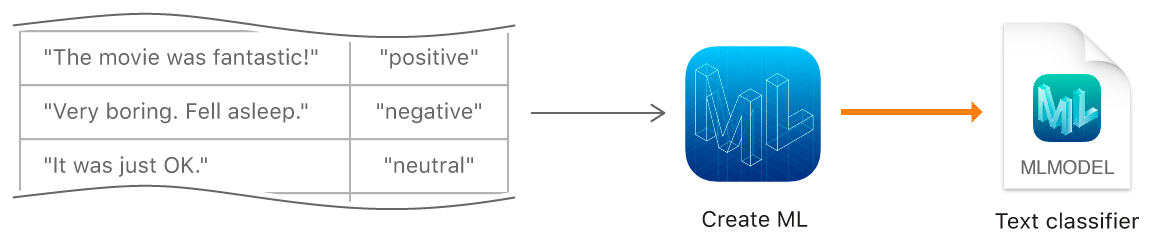
Pour créer un modèle, nous devons collecter un tableau avec l'ensemble de données d'origine - phrases ou textes entiers affectés à une certaine catégorie, et former le modèle à l'aide de l'objet MLTextClassifier:
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/CreateMLTest/texts.json")) let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5) let textClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label") try textClassifier.write(to: URL(fileURLWithPath: "/Users/CreateMLTest/TextClassifier.mlmodel"))
Dans ce cas, le modèle entraîné est de type Classificateur de texte:
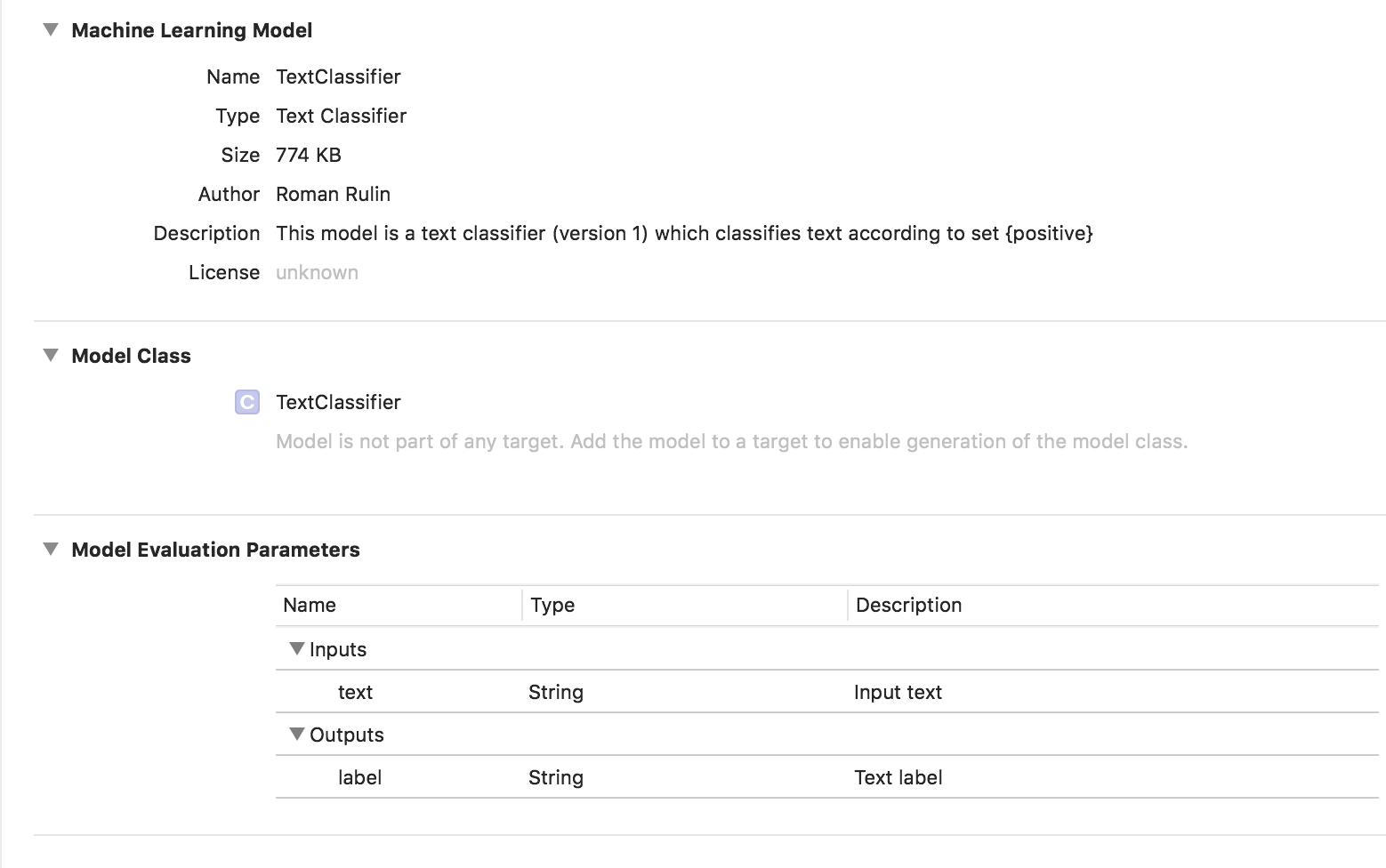
Données tabulaires
Examinons de plus près une autre caractéristique de Create ML - la formation d'un modèle à l'aide de données structurées (tableaux).
Nous allons écrire une application de test qui prédit le prix d'un appartement en fonction de son emplacement sur la carte et d'autres paramètres spécifiés.
Nous avons donc un tableau avec des données abstraites sur les appartements à Moscou sous forme de fichier csv: la superficie de chaque appartement, l'étage, le nombre de chambres et les coordonnées (latitude et longitude) sont connus. De plus, le coût de chaque appartement est connu. Plus le centre est proche ou plus la zone est grande, plus le prix est élevé.
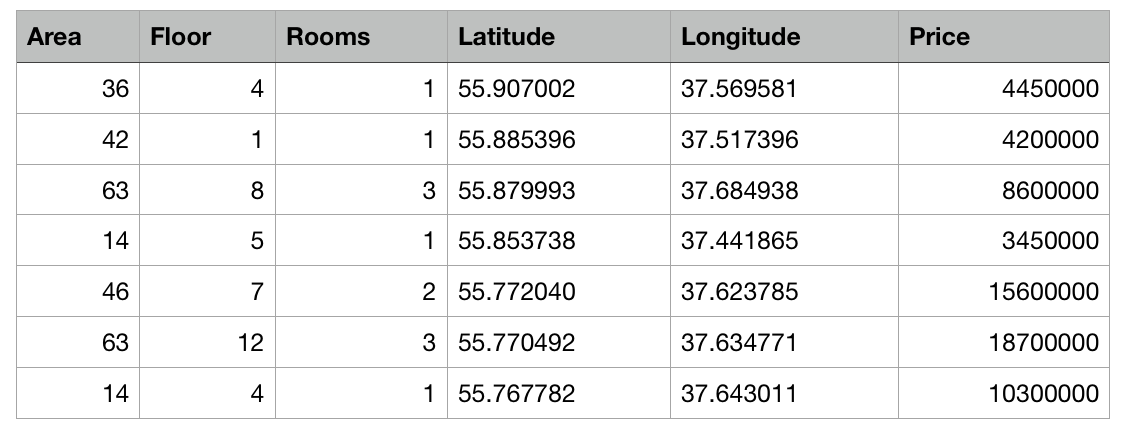
La tâche de Create ML sera de construire un modèle capable de prédire le prix d'un appartement en fonction de ces caractéristiques. Une telle tâche dans l'apprentissage automatique est appelée tâche de régression et est un exemple classique d'apprentissage avec un enseignant.
Create ML prend en charge de nombreux modèles - régression linéaire, régression d'arbre de décision, classificateur d'arbre, régression logistique, classificateur de forêt aléatoire, régression d'arbres boostés, etc.
Nous utiliserons l'objet MLRegressor, qui sélectionnera la meilleure option en fonction des données d'entrée.
Tout d'abord, initialisez l'objet MLDataTable avec le contenu de notre fichier csv:
let trainingFile = URL(fileURLWithPath: "/Users/CreateMLTest/Apartments.csv") let apartmentsData = try MLDataTable(contentsOf: trainingFile)
Nous divisons l'ensemble de données initial en données pour la formation et les tests du modèle dans un pourcentage de 80/20:
let (trainingData, testData) = apartmentsData.randomSplit(by: 0.8, seed: 0)
Nous créons le modèle MLRegressor, indiquant les données pour la formation et le nom de la colonne dont nous voulons prédire les valeurs. Le type de régresseur spécifique à la tâche (linéaire, arbre de décision, arbre boosté ou forêt aléatoire) sera automatiquement sélectionné en fonction de l'étude des données d'entrée. Nous pouvons également spécifier des colonnes d'entités - des colonnes de paramètres spécifiques pour l'analyse, mais dans cet exemple, cela n'est pas nécessaire, nous utiliserons tous les paramètres. À la fin, enregistrez le modèle formé et ajoutez-le au projet:
let model = try MLRegressor(trainingData: apartmentsData, targetColumn: "Price") let modelPath = URL(fileURLWithPath: "/Users/CreateMLTest/ApartmentsPricer.mlmodel") try model.write(to: modelPath, metadata: nil)
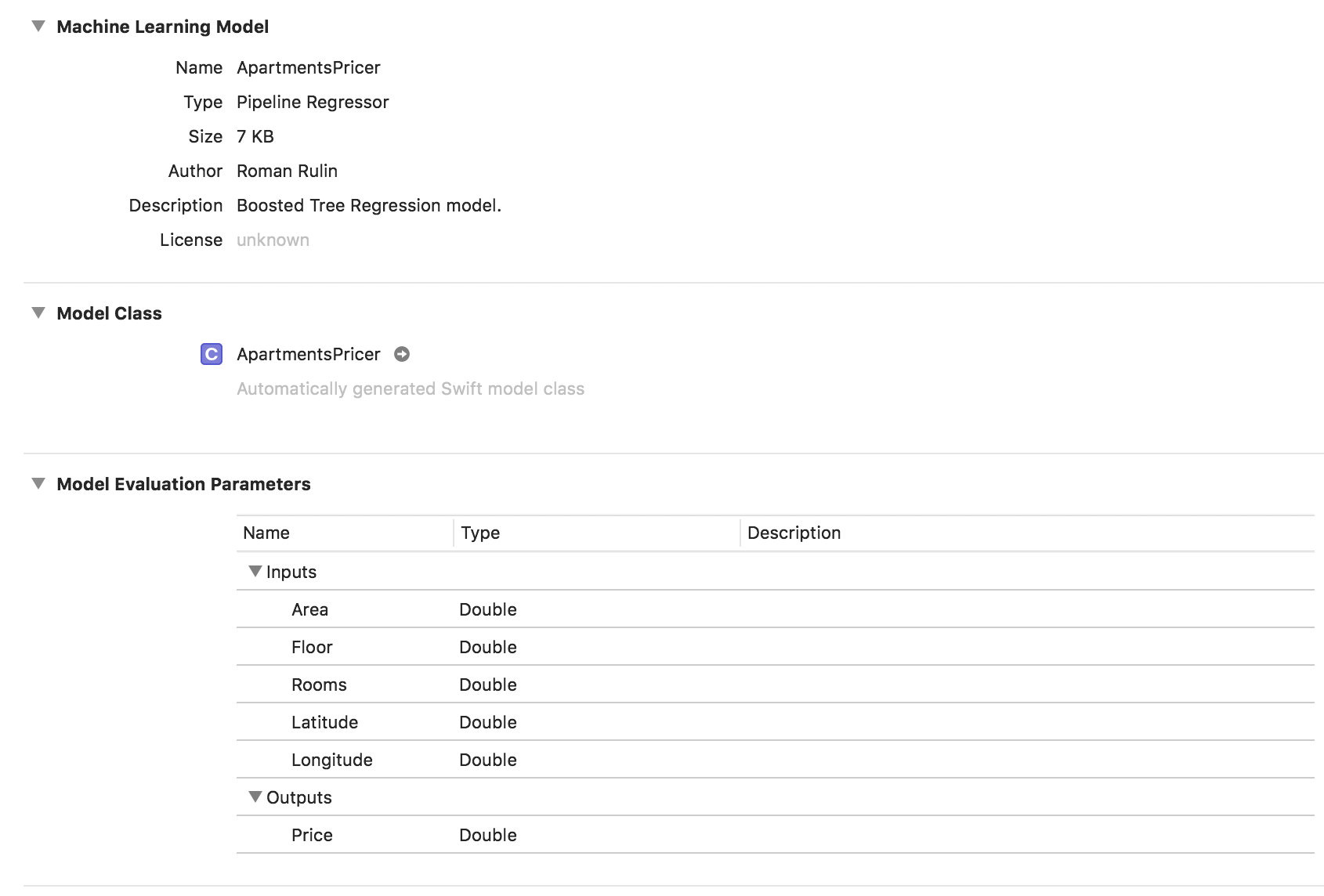
Dans cet exemple, nous voyons que le type de modèle est déjà Pipeline Regressor, et le champ Description contient le type de régresseur sélectionné automatiquement - Boosted Tree Regression Model. Les paramètres Entrées et Sorties correspondent aux colonnes du tableau, mais leur type de données est devenu Double.
Vérifiez maintenant le résultat.
Initialisez l'objet modèle:
let model = ApartmentsPricer()
Nous appelons la méthode de prédiction, en lui passant les paramètres spécifiés:
let area = Double(areaSlider.value) let floor = Double(floorSlider.value) let rooms = Double(roomsSlider.value) let latitude = annotation.coordinate.latitude let longitude = annotation.coordinate.longitude let prediction = try? model.prediction( area: area, floor: floor, rooms: rooms, latitude: latitude, longitude: longitude)
Nous affichons la valeur prédite du coût:
let price = prediction?.price priceLabel.text = formattedPrice(price)
En modifiant un point sur la carte ou les valeurs des paramètres, nous obtenons le prix de l'appartement assez proche de nos données de test:
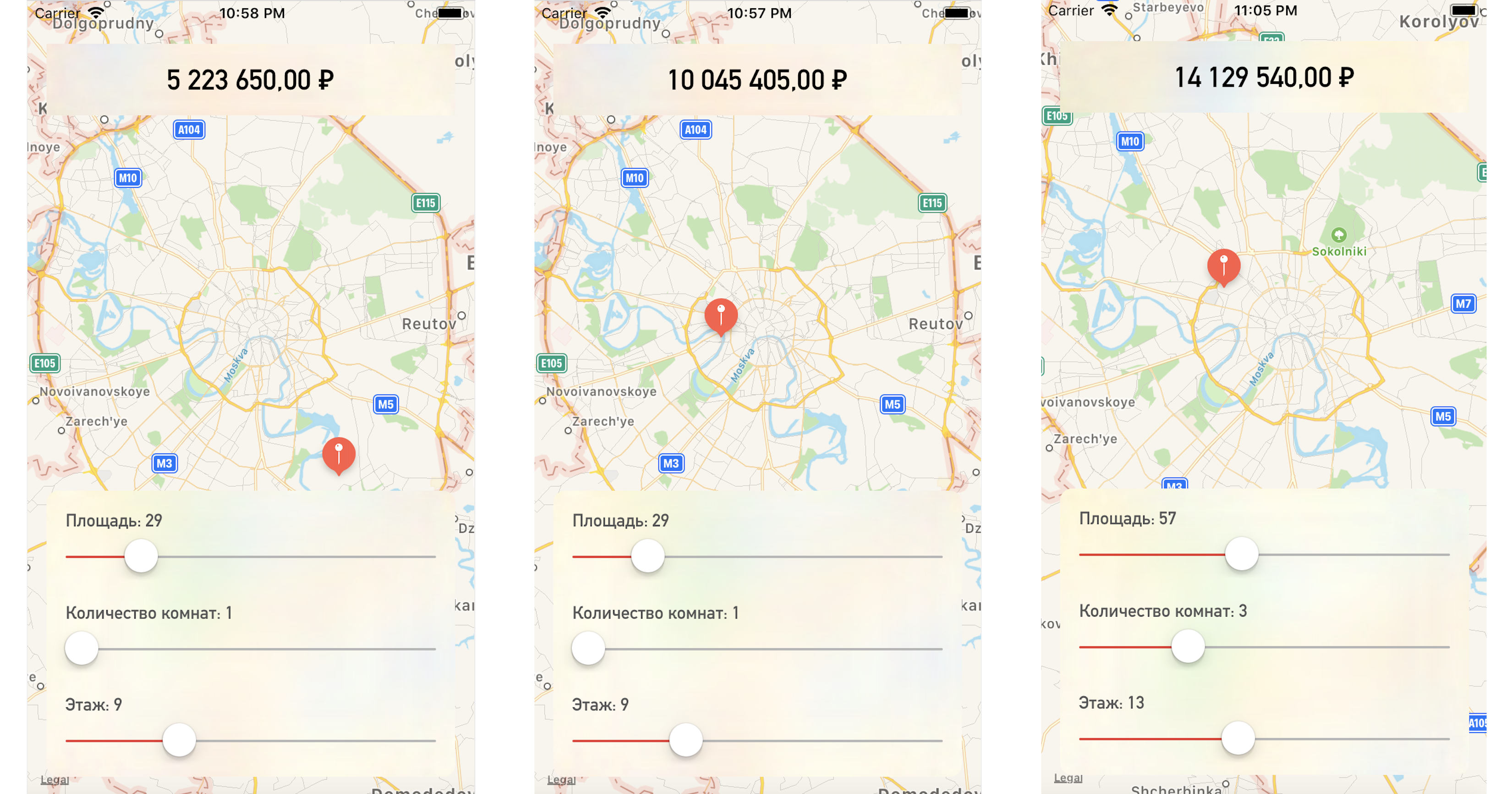
Conclusion
Le framework Create ML est désormais l'un des moyens les plus simples de travailler avec les technologies d'apprentissage automatique. Il ne permet pas encore de créer des modèles pour résoudre certains problèmes: reconnaissance d'objets dans une image, stylisation d'une photo, détermination d'images similaires, reconnaissance d'actions physiques basées sur les données d'un accéléromètre ou d'un gyroscope, que Turi Create, par exemple, gère.
Mais il convient de noter qu'Apple a réalisé des progrès assez importants dans ce domaine au cours de l'année écoulée et, à coup sûr, nous verrons bientôt le développement des technologies décrites.