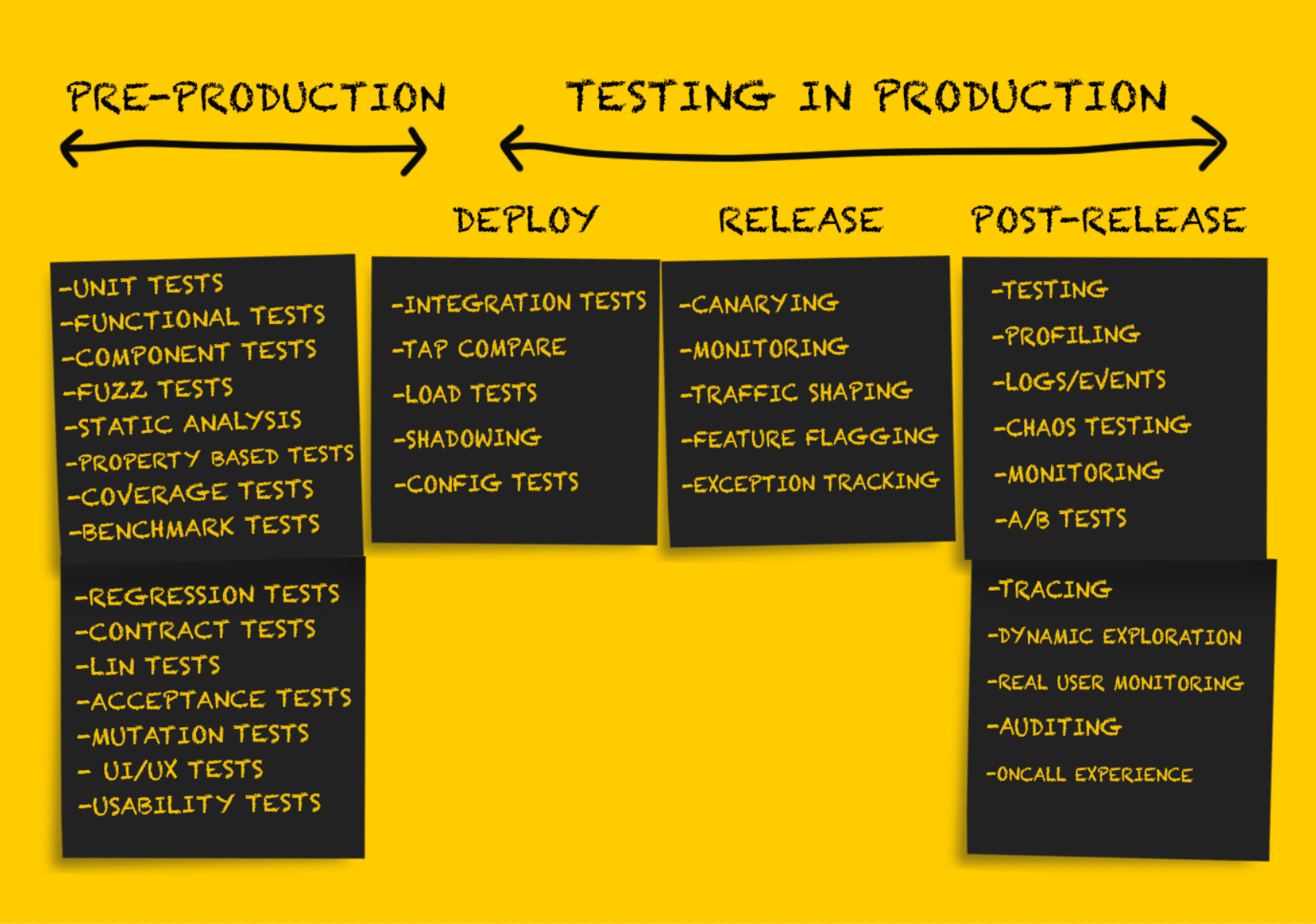
Dans cette partie de l'article, nous continuerons à considérer différents types de tests en production. Ceux qui ont sauté la première partie peuvent le lire
ici . Pour le reste - bienvenue au chat.
Tests de production: version
Après avoir testé le service après le
déploiement , il doit être préparé pour sa
publication .
Il est important de noter qu'à ce stade, l'annulation des changements n'est possible que dans des situations d'échec
durable , par exemple:
- boucle de panne de service;
- dépassement du temps d'attente pour un nombre important de connexions en amont, provoquant une forte augmentation de la fréquence des erreurs;
- changement de configuration inacceptable, par exemple, l'absence d'une clé secrète dans une variable d'environnement qui provoque l'échec du service (les variables d'environnement sont généralement mieux à éviter, mais c'est un sujet pour une autre discussion).
Des tests approfondis au stade du
déploiement me permettent de minimiser idéalement ou d'éviter complètement les mauvaises surprises au stade de la
sortie . Cependant, il existe un certain nombre de recommandations pour publier en toute sécurité un nouveau code.
Déploiement des Canaries
Le déploiement Canary est une
version partielle
d'un service en production. À mesure que le bilan de santé de base passe, les petites parties du trafic de l'environnement de production actuel sont envoyées aux parties validées. Les résultats des parties du service sont surveillés au fur et à mesure que le trafic est traité, les indicateurs sont comparés à ceux de référence (non liés à ceux des canaris), et s'ils tombent en dehors des valeurs de seuil acceptables, un retour à l'état précédent est effectué. Bien que cette approche soit généralement utilisée lors de la publication d'un logiciel serveur, le
test canari du logiciel client devient également plus courant.
Divers facteurs influencent le trafic qui sera utilisé pour le déploiement des canaris. Dans un certain nombre d'entreprises, les parties du service publiées ne reçoivent d'abord que du trafic utilisateur interne (appelé dogfooding). Si aucune erreur n'est observée, une petite partie du trafic de l'environnement de production est ajoutée, après quoi un déploiement complet est effectué. Il est
recommandé de revenir
automatiquement à l'état précédent en cas de résultats de déploiement canaries non valides, et des outils tels que
Spinnaker ont une prise en charge intégrée pour les fonctions automatisées d'analyse et de restauration.
Il y a quelques problèmes avec le test canari, et
cet article en donne un aperçu assez complet.
Suivi
La surveillance est une procédure absolument nécessaire à
chaque étape du déploiement du produit en production, mais cette fonction sera particulièrement importante au stade de la
version . La surveillance est bien adaptée pour obtenir des informations sur le niveau général de performances du système. Mais tout surveiller dans le monde n'est peut-être pas la meilleure solution.
Une surveillance
efficace est effectuée de manière ponctuelle, ce qui vous permet d'identifier un petit ensemble de modes de défaillance durable du système ou un ensemble de base d'indicateurs. Des exemples de tels modes de défaillance peuvent être:
- augmentation du taux d'erreur;
- une diminution de la vitesse globale de traitement des demandes tout au long du service, à un point de terminaison spécifique, ou, pire encore, un arrêt complet du travail;
- retard accru.
L'observation de l'un de ces modes de défaillance durable est à la base d'un retour immédiat à un état précédent ou d'un retour en arrière des nouvelles versions de logiciels
publiées . Il est important de se rappeler que le suivi à ce stade est peu susceptible d'être complet et indicatif. Beaucoup pensent que le nombre idéal de signaux surveillés pendant la surveillance est de 3 à 5, mais
certainement pas plus de 7-10. Le livre blanc de Kraken Facebook propose la solution suivante:
«Le problème est résolu à l'aide d'un composant de surveillance facilement configurable, qui signale deux indicateurs de base (le 99e centile du temps de réponse du serveur Web et la fréquence d'occurrence d'erreurs HTTP fatales) qui décrivent objectivement la qualité de l'interaction utilisateur.»Il est préférable de déterminer l'ensemble d'indicateurs système et d'application surveillés pendant la phase de publication lors de la conception du système.
Suivi des exceptions
Nous parlons de suivre les exceptions au stade de la publication, bien qu'il puisse sembler qu'au stade du
déploiement et après la publication, cela ne serait pas moins utile. Les outils de suivi des exceptions ne garantissent souvent pas la même rigueur, précision et couverture de masse que certains autres outils de surveillance du système, mais ils peuvent toujours être très utiles.
Les outils open source (tels que
Sentry ) affichent des informations avancées sur les demandes entrantes et créent des piles de données de trace et de variables locales, ce qui simplifie considérablement le processus de débogage, qui consiste généralement à afficher les journaux des événements. Le suivi des exceptions est également utile lors du tri et de la hiérarchisation des problèmes qui ne nécessitent pas un retour complet à un état précédent (par exemple, un cas limite qui lève une exception).
Mise en forme du trafic
La mise en forme du trafic (redistribution du trafic) n'est pas tant une forme indépendante de test qu'un outil pour soutenir l'approche canarienne et la publication progressive d'un nouveau code. En fait, la mise en forme du trafic est assurée par la mise à jour de la configuration de l'équilibreur de charge, qui vous permet de rediriger progressivement plus de trafic vers la nouvelle version
publiée .
Cette méthode est également utile pour le déploiement progressif de nouveaux logiciels (distinct du déploiement normal). Prenons un exemple. Imgix devait déployer une architecture d'infrastructure fondamentalement nouvelle en juin 2016. Après les premiers tests de la nouvelle infrastructure avec une certaine quantité de trafic sombre, ils ont commencé à se déployer en production, redirigeant initialement environ 1% du trafic de l'environnement de production vers une nouvelle pile. Puis, au cours de plusieurs semaines, le volume de données arrivant sur la nouvelle pile a augmenté (résolvant les problèmes en cours de route), jusqu'à ce qu'il commence à traiter 100% du trafic.
La popularité de l'architecture de maillage de service a déclenché une nouvelle vague d'intérêt pour les serveurs proxy. En conséquence, les anciens (nginx, HAProxy) et les nouveaux (Envoy, Conduit) proxys ont ajouté un support pour de nouvelles fonctions afin de dépasser les concurrents. Il me semble que l'avenir, dans lequel la redistribution du trafic de 0 à 100% au stade de la sortie du produit se fait automatiquement, approche à grands pas.
Tests de production: après publication
Les tests post-publication sont effectués comme une vérification effectuée
après une publication réussie
du code. À ce stade, vous pouvez être sûr que le code dans son ensemble est correct, qu'il a été correctement
publié en production et traite correctement le trafic. Le code déployé est directement ou indirectement utilisé dans des conditions réelles, au service de clients réels ou pour l'exécution de tâches ayant un impact significatif sur l'entreprise.
Le but de tout test à ce stade est principalement de vérifier l’opérabilité du système, en tenant compte des différentes charges et schémas de trafic possibles. La meilleure façon de le faire est de collecter des preuves documentaires de tout ce qui se passe en production et de les utiliser à la fois pour le débogage et pour obtenir une image complète du système.
Marquage de fonctionnalité ou lancement sombre
La publication la plus ancienne sur l'utilisation réussie des indicateurs de fonctionnalité que j'ai trouvée a été publiée il y a près de dix ans.
Featureflags.io fournit le guide le plus complet à ce sujet.
«Le marquage des fonctionnalités est une méthode utilisée par les développeurs pour marquer une nouvelle fonction à l'aide d'instructions if-then, ce qui permet un meilleur contrôle sur sa sortie. En signalant une fonction et en l'isolant de cette manière, le développeur peut activer et désactiver cette fonction quel que soit l'état du déploiement. Cela sépare efficacement la publication de la fonction du déploiement du code. "En signalant le nouveau code, vous pouvez tester ses performances et ses performances en production selon vos besoins. Le signalement des fonctionnalités est l'un des types de tests généralement acceptés en production, il est bien connu et est souvent
décrit dans
diverses sources . Le fait que cette méthode puisse être utilisée pour tester le
transfert de bases de données ou de logiciels pour des systèmes personnels est beaucoup moins connu.
Les auteurs d'articles écrivent rarement sur les meilleures méthodes de développement et d'utilisation des drapeaux de fonction. L'utilisation incontrôlée de drapeaux peut être un problème grave. Le manque de discipline en termes de suppression des indicateurs inutilisés après une période spécifiée conduit parfois au fait que vous devez effectuer un audit complet et supprimer les indicateurs obsolètes accumulés au cours des mois (sinon des années) de travail.
Test A / B
Les tests A / B sont souvent effectués dans le cadre d'une analyse expérimentale et ne sont pas considérés comme des tests en production. Pour cette raison, les tests A / B sont non seulement largement utilisés (parfois même de manière
douteuse ), mais également
activement étudiés et
décrits (y compris des articles sur
ce qui détermine un tableau de
bord efficace pour les expériences en ligne). Beaucoup moins souvent, les tests A / B sont utilisés pour tester diverses configurations matérielles ou machines virtuelles. Ils sont souvent appelés «tuning» (par exemple, tuning JVM), mais ils ne sont pas classés comme des tests A / B typiques (bien que le tuning puisse être considéré comme un type de test A / B effectué avec le même niveau de rigueur en ce qui concerne les mesures) .
Journaux, événements, indicateurs et traçage
Vous
pouvez en savoir plus sur les soi-disant «trois baleines observables» - journaux, indicateurs et suivi distribué
ici .
Profilage
Dans certains cas, pour diagnostiquer les problèmes de performances, il est nécessaire d'utiliser le profilage d'application en production. Selon les langues et les temps d'exécution pris en charge, le profilage peut être une procédure assez simple, qui consiste à ajouter une seule ligne de code à l'application (
import _ "net/http/pprof" dans le cas de Go). D'autre part, cela peut nécessiter l'utilisation de nombreux outils ou tester le processus par la méthode de la boîte noire et vérifier les résultats à l'aide d'outils tels que des
graphiques à
flamme .
Test de départ
Beaucoup de gens considèrent ces tests comme quelque chose comme la duplication fantôme des données, car dans les deux cas, le trafic de l'environnement de production est envoyé vers des clusters ou des processus hors production. À mon avis, la différence est que l'utilisation du trafic à
des fins de
test est quelque peu différente de son utilisation à
des fins de
débogage .
Etsy a écrit sur son blog à propos de l'utilisation des tee-tests comme outil de vérification (cet exemple ressemble vraiment à la duplication fantôme des données).
«Ici, tee peut être compris comme la commande tee sur la ligne de commande. Nous avons écrit une règle iRule basée sur un équilibreur de charge F5 existant pour cloner le trafic HTTP dirigé vers l'un des pools et le rediriger vers un autre pool. Ainsi, nous avons pu utiliser le trafic de l'environnement de production dirigé vers notre cluster API et en envoyer une copie au cluster HHVM expérimental, ainsi qu'à un cluster PHP isolé pour comparaison.
Cette technique s'est avérée très efficace. Il nous a permis de comparer les performances des deux configurations en utilisant des profils de trafic identiques. »Cependant, parfois un test de départ basé sur le trafic de l'environnement de production dans un système autonome est requis pour le
débogage . Dans de tels cas, le système autonome peut être modifié pour configurer la sortie d'informations de diagnostic supplémentaires ou une autre procédure de compilation (par exemple, en utilisant l'outil de nettoyage de flux), ce qui simplifie considérablement le processus de dépannage. Dans de tels cas, les tests en té devraient être considérés, plutôt que
des outils de débogage , plutôt qu'une
vérification .
Auparavant, de tels types de débogage étaient relativement rares dans
imgix , mais ils étaient toujours utilisés, en particulier lorsqu'il s'agissait de problèmes avec des applications de débogage sensibles au délai.
Par exemple, voici une description analytique de l'un de ces incidents survenus en 2015. L'erreur 400 s'est produite si rarement qu'elle n'a presque pas été vue lors de la tentative de reproduction du problème. Elle est apparue dans quelques cas sur un milliard. Il y en avait très peu pendant la journée. En conséquence, il s'est avéré qu'il était tout simplement impossible de reproduire le problème de manière fiable, il était donc nécessaire d'effectuer un débogage à l'aide du trafic de travail afin d'avoir une chance de suivre l'occurrence de cette erreur. Voici ce que mon ancien collègue a écrit à ce sujet:
«J'ai choisi une bibliothèque qui était censée être interne, mais j'ai finalement dû créer la mienne en fonction de la bibliothèque fournie par le système. Dans la version fournie par le système, une erreur se produisait périodiquement qui n'apparaissait en aucune façon alors que la quantité de trafic était faible. Cependant, le nom tronqué dans le titre était le vrai problème.
Au cours des deux jours suivants, j'ai étudié en détail le problème lié à l'augmentation de la fréquence des fausses erreurs 400. L'erreur s'est manifestée dans un très petit nombre de demandes, et les problèmes de ce type sont difficiles à diagnostiquer. Tout cela ressemblait à l'aiguille notoire d'une botte de foin: le problème était rencontré dans un cas par milliard.
La première étape pour localiser la source des erreurs a été d'obtenir toutes les données brutes de requête HTTP qui ont abouti à une réponse incorrecte. Pour effectuer un test de départ du trafic entrant lorsqu'il est connecté à un socket, j'ai ajouté le point de terminaison de socket de domaine Unix au serveur de rendu. L'idée était de nous permettre d'activer et de désactiver rapidement et facilement le flux de trafic sombre et d'effectuer des tests directement sur l'ordinateur du développeur. Pour éviter les problèmes de production, il était nécessaire de rompre la connexion en cas de problème de contre-pression. C'est-à-dire si le doublon ne pouvait pas faire face à la tâche, il était déconnecté. Cette socket a été très utile dans certains cas lors du développement. Cette fois, cependant, nous l'avons utilisé pour collecter le trafic entrant sur les serveurs sélectionnés, en espérant obtenir suffisamment de requêtes pour révéler le modèle qui a conduit à l'apparition de fausses erreurs 400. En utilisant dsh et netcat, j'ai pu générer relativement facilement le trafic entrant dans un fichier local .
La majeure partie de l'environnement a été consacrée à la collecte de ces données. Dès que nous avions suffisamment de données, j'ai pu utiliser netcat pour les lire sur le système local, dont la configuration a été modifiée pour afficher une grande quantité d'informations de débogage. Et tout s'est parfaitement déroulé. L'étape suivante consiste à lire les données à la vitesse la plus élevée possible. Dans ce cas, la boucle avec le contrôle de condition a envoyé les requêtes brutes une à la fois. Après environ deux heures, j'ai réussi à obtenir le résultat souhaité. Les données dans les journaux ont montré l'absence d'un en-tête!
J'utilise du bois rouge-noir pour transmettre les en-têtes. De telles structures considèrent la comparabilité comme une identité, ce qui en soi est très utile lorsqu'il existe des exigences particulières pour les clés: dans notre cas, les en-têtes HTTP n'étaient pas sensibles à la casse. Au début, nous pensions que le problème était dans le nœud feuille de la bibliothèque utilisée. L'ordre d'addition affecte vraiment l'ordre de construction de l'arbre de base, et l'équilibrage de l'arbre rouge-noir est un processus assez compliqué. Et bien que cette situation était peu probable, elle n'était pas impossible. Je suis passé à une autre implémentation en ébène rouge. Il a été corrigé il y a plusieurs années, j'ai donc décidé de l'intégrer directement dans la source pour obtenir exactement la version requise. Néanmoins, l'assemblage a choisi une version différente, et comme je comptais sur une version plus récente, j'ai finalement eu un comportement incorrect.
Pour cette raison, le système de visualisation a généré 500 erreurs, ce qui a entraîné l'interruption du cycle. C'est pourquoi l'erreur ne s'est produite qu'avec le temps. Après le traitement cyclique de plusieurs assemblys, le trafic provenant d'eux a été redirigé vers une route différente, ce qui a accru l'ampleur du problème sur ce serveur. Mon hypothèse selon laquelle le problème était dans la bibliothèque s'est avérée incorrecte et le commutateur inversé a résolu 500 erreurs.
Je suis revenu à 400 erreurs: il y avait toujours un problème avec l'erreur, qui a pris environ deux heures à détecter. Changer la bibliothèque, évidemment, n'a pas résolu le problème, mais j'étais sûr que la bibliothèque sélectionnée était suffisamment fiable. Ne réalisant pas l'erreur du choix, je n'ai rien changé. Après avoir étudié la situation plus en détail, je me suis rendu compte que la valeur correcte était stockée dans un en-tête à un seul caractère (par exemple, «h: 12345»). J'ai finalement compris que h était le caractère de fin de l'en-tête Content-Length. En regardant à nouveau les données, j'ai réalisé que l'en-tête Content-Length était vide.
En conséquence, le tout était une erreur de biais de un lors de la lecture des en-têtes. L'analyseur HTTP nginx / joyent crée des données partielles, et chaque fois que le champ d'en-tête partiel s'est avéré être un caractère plus court que nécessaire, j'ai envoyé l'en-tête sans valeur et j'ai ensuite reçu un champ d'en-tête à un caractère contenant la valeur correcte. C'est une combinaison assez rare, donc son fonctionnement prend tellement de temps. J'ai donc augmenté la quantité de collecte de données chaque fois qu'un en-tête à un caractère est apparu, j'ai appliqué le correctif proposé et j'ai réussi à exécuter le script pendant plusieurs heures.
Bien sûr, d'autres pièges avec le dysfonctionnement de la bibliothèque mentionné ont pu être détectés, mais les deux erreurs ont été corrigées. »
Les ingénieurs impliqués dans le développement d'applications sensibles aux retards doivent pouvoir déboguer à l'aide du trafic dynamique capturé, car des erreurs se produisent souvent qui ne peuvent pas être reproduites pendant les tests unitaires ou détectées à l'aide d'un outil de surveillance (en particulier s'il y a un retard important dans la journalisation).
Approche de l'ingénierie du chaos
Chaos Engineering est une approche basée sur des expériences sur un système distribué afin de confirmer sa capacité à résister aux conditions chaotiques de l'environnement de production.La méthode Chaos Engineering, d'abord rendue célèbre par
Chaos Monkey de Netflix, est maintenant devenue une discipline indépendante. Le terme Chaos Engineering est apparu récemment, mais le test de panne est une pratique de longue date.
Le terme «tests chaotiques» fait référence aux techniques suivantes:
- désactiver les nœuds arbitraires pour déterminer la résistance du système aux défaillances;
- introduire des erreurs (par exemple, augmenter le retard) afin de confirmer que le système les traite correctement;
- violation forcée du réseau afin de déterminer la réponse du service.
La plupart des entreprises utilisent un environnement d'exploitation insuffisamment complexe et hiérarchisé pour effectuer efficacement des tests chaotiques. Il est important de souligner que l'introduction de défauts dans le système se fait mieux après avoir défini les fonctions de base de la tolérance aux défauts.
Ce livre blanc de Gremlin fournit une description assez complète des principes des tests chaotiques, ainsi que des instructions pour la préparation de cette procédure.
«Le fait que Chaos Engineering soit considéré comme une discipline scientifique est particulièrement important. Dans cette discipline, des processus d'ingénierie de haute précision sont appliqués.
La tâche de Chaos Engineering est de dire aux utilisateurs quelque chose de nouveau sur les vulnérabilités du système en effectuant des expériences sur celui-ci. Il est nécessaire d'identifier tous les problèmes cachés qui pourraient survenir dans la production, avant même qu'ils ne provoquent une panne massive. Ce n'est qu'après cela que vous pourrez éliminer efficacement toutes les faiblesses du système et le rendre vraiment tolérant aux pannes. »Conclusion
Le but des tests en production n'est pas d'
éliminer complètement toutes les défaillances possibles du système.
John Allspaw dit:
« Nous constatons que les systèmes deviennent de plus en plus tolérants aux pannes - et c'est formidable. Mais nous devons admettre: «de plus en plus» n'est pas égal à «absolument». Dans tout système complexe, une défaillance peut se produire (et se produira) de la manière la plus imprévisible. »
Les tests en production à première vue peuvent sembler une tâche assez compliquée, allant bien au-delà des compétences de la plupart des sociétés d'ingénierie. Et bien que de tels tests
ne soient
pas une tâche
facile , associée à certains risques, si vous les suivez par toutes les règles, ils aideront à atteindre la fiabilité des systèmes distribués complexes que l'on trouve partout aujourd'hui.