Dans un article précédent, nous avons examiné les modèles et les topologies utilisés dans RabbitMQ. Dans cette partie, nous allons nous tourner vers Kafka et le comparer avec RabbitMQ pour avoir quelques idées sur leurs différences. Il convient de garder à l'esprit que les architectures d'applications orientées événements seront comparées plutôt que les pipelines de traitement de données, bien que la frontière entre ces deux concepts soit plutôt floue dans ce cas. En général, il s'agit plus d'un spectre que d'une séparation claire. Notre comparaison se concentrera simplement sur la partie de ce spectre liée aux applications événementielles.

La première différence qui vient à l'esprit est que les mécanismes de nouvelle tentative de message et de rappel d'alarme utilisés par RabbitMQ pour travailler avec des messages de lettres mortes dans Kafka n'ont aucun sens. Dans RabbitMQ, les messages sont temporaires, ils sont transmis et disparaissent. Par conséquent, les rajouter est un cas d'utilisation absolument réel. Et à Kafka, le magazine occupe une place centrale. Résoudre les problèmes de remise en renvoyant un message à la file d'attente n'a pas de sens et ne fait que nuire au journal. L'un des avantages est la distribution claire et garantie des messages à travers les partitions du journal, les messages répétés confondent un schéma bien organisé. Dans RabbitMQ, vous pouvez déjà envoyer des messages à la file d'attente avec laquelle un destinataire travaille, et sur la plateforme Kafka il y a un journal pour tous les destinataires. Les retards de livraison et les problèmes de livraison des messages ne nuisent pas beaucoup au fonctionnement du journal, mais Kafka ne contient pas de mécanismes de retard intégrés.
La manière de remettre des messages sur la plate-forme Kafka sera discutée dans la section sur les schémas de messagerie.
La deuxième grande différence qui affecte les schémas de messagerie possibles est que RabbitMQ stocke beaucoup moins les messages que Kafka. Lorsqu'un message a déjà été remis au destinataire dans RabbitMQ, il est supprimé sans laisser de trace de son existence. Dans Kafka, chaque message est conservé dans un journal jusqu'à ce qu'il soit effacé. La fréquence de nettoyage dépend de la quantité de données disponibles, de la quantité d'espace disque que vous prévoyez de leur allouer et des schémas de messagerie que vous souhaitez garantir. Vous pouvez utiliser la fenêtre de temps pendant laquelle nous stockons les messages pendant une période donnée: les derniers jours / semaines / mois.
De cette façon, Kafka permet au destinataire de revoir ou de récupérer les messages précédents. Cela ressemble à une technologie pour envoyer des messages, bien qu'elle ne fonctionne pas de la même manière que dans RabbitMQ.
Si RabbitMQ déplace des messages et fournit des éléments puissants pour créer des schémas de routage complexes, Kafka enregistre l'état actuel et précédent du système. Cette plate-forme peut être utilisée comme source de données historiques fiables, contrairement à RabbitMQ.
Exemple de schéma de messagerie sur la plate-forme Kafka
L'exemple le plus simple d'utilisation de RabbitMQ et de Kafka est la diffusion d'informations selon le schéma «éditeur-abonné». Un ou plusieurs éditeurs ajoutent des messages au journal partitionné, et ces messages sont reçus par l'abonné d'un ou plusieurs groupes d'abonnés.

Figure 1. Plusieurs éditeurs envoient des messages au journal partitionné et plusieurs groupes de destinataires les reçoivent.
Si vous n'entrez pas dans les détails sur la façon dont l'éditeur envoie des messages aux sections nécessaires de la revue et sur la façon dont les groupes de destinataires sont coordonnés entre eux, ce schéma ne diffère pas de la topologie de fanout (échange fourchu) utilisée dans RabbitMQ.
Dans un article précédent, tous les schémas et topologies de messagerie RabbitMQ ont été discutés. Peut-être qu'à un moment donné, vous pensiez "Je n'ai pas besoin de toutes ces difficultés, je veux juste envoyer et recevoir des messages dans la file d'attente", et le fait que vous puissiez rembobiner le magazine à des positions précédentes a parlé des avantages évidents de Kafka.
Pour les personnes habituées aux fonctionnalités traditionnelles des systèmes de files d'attente, le fait de la possibilité de reculer l'horloge et de rembobiner le journal des événements dans le passé est incroyable. Cette propriété (disponible en utilisant le journal au lieu de la file d'attente) est très utile pour récupérer des échecs. J'ai (l'auteur de l'article en anglais) commencé à travailler pour mon client actuel il y a 4 ans en tant que responsable technique du groupe de support du système serveur. Nous avions plus de 50 applications qui recevaient des informations en temps réel sur les événements commerciaux via MSMQ, et la chose habituelle était que lorsqu'une erreur se produisait dans l'application, le système ne la détectait que le lendemain. Malheureusement, souvent les messages disparaissaient en conséquence, mais en général, nous pouvions obtenir les données initiales d'un système tiers et transmettre les messages uniquement à «l'abonné» qui avait le problème. Cela nous a obligés à créer une infrastructure de messagerie pour les destinataires. Et si nous avions la plateforme Kafka, il ne serait pas plus difficile de faire un tel travail que de changer le lien vers l'emplacement du dernier message reçu pour l'application dans laquelle l'erreur s'est produite.
Intégration de données dans des applications et des systèmes orientés événements
Ce schéma est à bien des égards un moyen de générer des événements, bien qu'il ne soit pas lié à une seule application. Il existe deux niveaux de génération d'événements: le logiciel et le système. Le schéma actuel est associé à ce dernier.
Génération d'événements au niveau du programme
L'application gère son propre état via une séquence immuable d'événements de modification qui sont stockés dans le magasin d'événements. Afin d'obtenir l'état actuel de l'application, vous devez lire ou combiner ses événements dans la séquence correcte. Habituellement, dans un tel modèle, le modèle CQRS Kafka peut être utilisé comme système.
Interaction entre les applications au niveau du système.
Les applications ou services peuvent gérer leur état de la manière que leur développeur souhaite gérer, par exemple, dans une base de données relationnelle régulière.
Mais les applications ont souvent besoin de données les unes sur les autres, ce qui conduit à des architectures sous-optimales, par exemple, des bases de données communes, un flou des limites des entités ou des API REST peu pratiques.
J'ai (l'auteur de l'article en anglais) écouté le podcast « Software Engineering Daily », qui décrit un scénario événementiel pour les profils de service sur les réseaux sociaux. Il existe un certain nombre de services connexes dans le système, tels que la recherche, un système de graphiques sociaux, un moteur de recommandation, etc., tous doivent être informés d'un changement de statut d'un profil utilisateur. Lorsque j'ai (l'auteur de l'article en anglais) travaillé en tant qu'architecte de l'architecture d'un système lié au transport aérien, nous avions deux grands systèmes logiciels avec une myriade de petits services connexes. Les services d'assistance ont requis les données de commande et de vol. Chaque fois qu'une commande était créée ou modifiée, lorsqu'un vol était retardé ou annulé, ces services devaient être activés.
Il fallait une technique pour générer des événements. Mais d'abord, examinons certains problèmes courants qui surviennent dans les grands systèmes logiciels et voyons comment la génération d'événements peut les résoudre.
Un grand système d'entreprise intégré se développe généralement de manière organique; des migrations vers de nouvelles technologies et de nouvelles architectures sont effectuées, ce qui peut ne pas affecter 100% du système. Les données sont distribuées dans différentes parties de l'institution, les applications divulguent des bases de données à l'usage du public afin que l'intégration se fasse le plus rapidement possible, et personne ne peut prédire avec certitude comment tous les éléments du système interagiront.
Distribution aléatoire des données
Les données sont distribuées à différents endroits et gérées à différents endroits, il est donc difficile de comprendre:
- comment les données se déplacent dans les processus métier;
- comment les changements dans une partie du système peuvent affecter d'autres parties;
- que faire des conflits de données qui surviennent du fait qu'il existe de nombreuses copies de données qui se propagent lentement.
S'il n'y a pas de limites claires des entités de domaine, les modifications seront coûteuses et risquées, car elles affectent de nombreux systèmes à la fois.
Base de données distribuée centralisée
Une base de données ouverte au public peut provoquer plusieurs problèmes:
- Elle n'est pas suffisamment optimisée pour chaque application séparément. Très probablement, cette base de données contient un ensemble de données excessivement complet pour l'application, de plus, elle est normalisée de telle sorte que les applications devront exécuter des requêtes très complexes pour les recevoir.
- En utilisant une base de données commune, les applications peuvent affecter le travail de l'autre.
- Les changements dans la structure logique de la base de données nécessitent une coordination à grande échelle et des travaux sur la migration des données, et le développement de services individuels sera arrêté pendant toute la durée de ce processus.
- Personne ne veut changer la structure de stockage. Les changements que tout le monde attend sont trop douloureux.
Utilisation de l'API REST peu pratique
Obtenir des données à partir d'autres systèmes via l'API REST, d'une part, ajoute la commodité et l'isolement, mais peut ne pas toujours réussir. Chacune de ces interfaces peut avoir son propre style spécial et ses propres conventions. Obtenir les données nécessaires peut nécessiter beaucoup de requêtes HTTP et être assez compliqué.
Nous nous dirigeons de plus en plus vers une approche centrée sur les API, et de telles architectures offrent de nombreux avantages, en particulier lorsque les services eux-mêmes sont hors de notre contrôle. Il existe tellement de façons pratiques de créer une API pour le moment que nous n'avons pas besoin d'écrire autant de code que nécessaire auparavant. Néanmoins, ce n'est pas le seul outil disponible, et il existe des alternatives pour l'architecture interne du système.
Kafka comme référentiel d'événements
Nous donnons un exemple. Il existe un système qui gère les réservations dans une base de données relationnelle. Le système utilise toutes les garanties d'atomicité, de cohérence, d'isolement et de durabilité offertes par la base de données afin de gérer efficacement leurs caractéristiques et tout le monde est content. La répartition des responsabilités en équipes et demandes, la génération d'événements, les microservices sont absents, en général, d'un monolithe de construction traditionnelle. Mais il existe une multitude de services d'assistance (éventuellement des microservices) liés aux réservations: notifications push, distribution d'e-mails, système anti-fraude, programme de fidélité, facturation, système d'annulation, etc. La liste s'allonge encore et encore. Tous ces services nécessitent des détails de réservation, et il existe de nombreuses façons de les obtenir. Ces services produisent eux-mêmes des données qui peuvent être utiles à d'autres applications.

Figure 2. Différents types d'intégration de données.
Architecture alternative basée sur Kafka. Chaque fois que vous effectuez une nouvelle réservation ou modifiez une réservation précédente, le système envoie des données complètes sur l'état actuel de cette réservation à Kafka. En consolidant le journal, vous pouvez raccourcir les messages afin que seules les informations sur le dernier statut de réservation y soient laissées. Dans ce cas, la taille du journal sera sous contrôle.
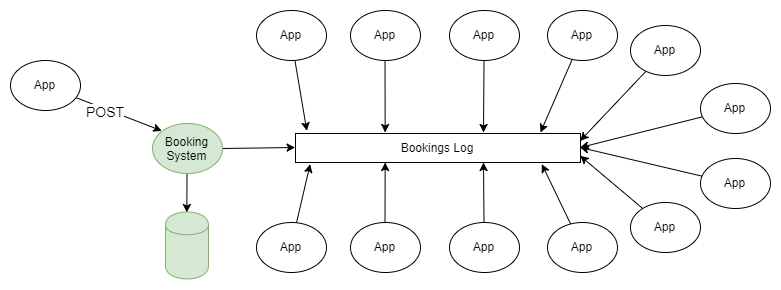
Figure 3. Intégration des données basée sur Kafka comme base pour la génération d'événements
Pour toutes les applications pour lesquelles cela est nécessaire, ces informations sont la source de vérité et la seule source de données. Du coup, nous passons d'un réseau intégré de dépendances et de technologies à l'envoi et la réception de données vers / depuis les sujets Kafka.
Kafka comme référentiel d'événements:
- S'il n'y a pas de problème d'espace disque, Kafka peut stocker tout l'historique des événements, c'est-à-dire qu'une nouvelle application peut être déployée et télécharger toutes les informations nécessaires depuis le journal. Les enregistrements d'événements qui reflètent pleinement les caractéristiques des objets peuvent être compressés en compilant le journal, ce qui rendra cette approche plus justifiée pour de nombreux scénarios.
- Que faire si les événements doivent être joués dans le bon ordre? Tant que les enregistrements d'événements sont correctement distribués, vous pouvez définir l'ordre de leur lecture et appliquer des filtres, des outils de conversion, etc., afin que la lecture des données se termine toujours sur les informations nécessaires. Selon la possibilité de distribution des données, il est possible d'assurer leur traitement hautement parallélisé dans le bon ordre.
- Un changement de modèle de données peut être nécessaire. Lors de la création d'une nouvelle fonction de filtrage / transformation, il peut être nécessaire de lire les enregistrements de tous les événements ou événements de la semaine dernière.
Les messages peuvent provenir de Kafka non seulement à partir des applications de votre organisation qui envoient des messages sur toutes les modifications de leurs caractéristiques (ou les résultats de ces modifications), mais aussi à partir de services tiers intégrés à votre système. Cela se produit de la manière suivante:
- Exportation, transfert, importation périodique des données reçues de services tiers et leur téléchargement vers Kafka.
- Téléchargement de données à partir de services tiers à Kafka.
- Les données de CSV et d'autres formats téléchargés à partir de services tiers sont téléchargées sur Kafka.
Revenons aux questions que nous avons examinées précédemment. L'architecture basée sur Kafka simplifie la distribution des données. Nous savons où se trouve la source de la vérité, nous savons où se trouvent ses sources de données et toutes les applications cibles fonctionnent avec des copies dérivées de ces données. Les données vont de l'expéditeur aux destinataires. Les données source n'appartiennent qu'à l'expéditeur, mais d'autres sont libres de travailler avec leurs projections. Ils peuvent les filtrer, les transformer, les compléter avec des données provenant d'autres sources, les enregistrer dans leurs propres bases de données.
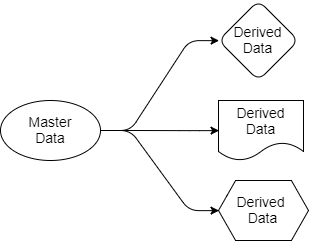
Fig 4. Données source et sortie
Chaque application qui a besoin de données de réservation et de vol les recevra pour elle-même, car elle est «abonnée» aux sections de Kafka qui contiennent ces données. Pour cette application, ils peuvent utiliser SQL, Cypher, JSON ou tout autre langage de requête. Une application peut ensuite enregistrer les données dans son système comme bon lui semble. Le schéma de distribution des données peut être modifié sans affecter le fonctionnement d'autres applications.
La question peut se poser: pourquoi tout cela ne peut pas être fait en utilisant RabbitMQ? La réponse est que RabbitMQ peut être utilisé pour traiter des événements en temps réel, mais pas comme base pour générer des événements. RabbitMQ est une solution complète uniquement pour répondre aux événements qui se produisent actuellement. Lorsqu'une nouvelle application est ajoutée qui a besoin de sa propre partie des données de réservation présentées dans un format optimisé pour les tâches de cette application, RabbitMQ ne pourra pas vous aider. Avec RabbitMQ, nous revenons aux bases de données partagées ou à l'API REST.
Deuxièmement, l'ordre dans lequel les événements sont traités est important. Si vous travaillez avec RabbitMQ, lorsque vous ajoutez un deuxième destinataire à la file d'attente, la garantie de conformité avec la commande est perdue. Ainsi, l'ordre correct d'envoi des messages n'est observé que pour un seul destinataire, mais cela, bien sûr, n'est pas suffisant.
Kafka, en revanche, peut fournir toutes les données dont cette application a besoin pour créer sa propre copie des données et maintenir les données à jour, tandis que Kafka suit l'ordre dans lequel les messages sont envoyés.
Revenons maintenant aux architectures centrées sur l'API. Ces interfaces seront-elles toujours le meilleur choix? Lorsque vous souhaitez ouvrir l'accès aux données en lecture seule, je préfère une architecture émettrice d'événements. Il empêchera les défaillances en cascade et raccourcira la durée de vie associée à une augmentation du nombre de dépendances sur d'autres services. Il y aura plus d'opportunités pour une organisation créative et efficace des données au sein des systèmes. Mais parfois, vous devez modifier les données de manière synchrone dans votre système et dans un autre système, et dans une telle situation, des systèmes centrés sur l'API seront utiles. Beaucoup les préfèrent à d'autres méthodes asynchrones. Je pense que c'est une question de goût.
Applications sensibles au trafic élevé et au traitement des événements.
Il n'y a pas si longtemps, un problème est survenu avec l'un des récepteurs de RabbitMQ, qui a reçu des fichiers en file d'attente d'un service tiers. La taille totale du fichier était importante et l'application était spécifiquement configurée pour recevoir un tel volume de données. Le problème était que les données arrivaient de manière incohérente, ce qui a créé beaucoup de problèmes.
De plus, il y avait parfois un problème dans le fait que parfois deux fichiers étaient destinés à la même destination, et leur heure d'arrivée différait de plusieurs secondes. Ils ont tous deux subi un traitement et ont dû être téléchargés sur un serveur. Et après que le deuxième message a été enregistré sur le serveur, le premier message qui le suit écrase le second. Ainsi, tout s'est terminé par la sauvegarde de données invalides. RabbitMQ a rempli son rôle et envoyé des messages dans le bon ordre, mais tout de même, tout s'est terminé dans le mauvais ordre dans l'application elle-même.
Ce problème a été résolu en lisant l'horodatage à partir des enregistrements existants et l'absence de réponse si le message était ancien. De plus, un hachage cohérent a été appliqué lors de l'échange de données et la file d'attente a été divisée, comme avec le même partitionnement sur la plate-forme Kafka.
Dans le cadre de la partition, Kafka stocke les messages dans l'ordre dans lequel ils leur ont été envoyés. L'ordre des messages n'existe que dans la partition. Dans l'exemple ci-dessus, en utilisant Kafka, nous avons dû appliquer la fonction de hachage à l'id de la destination pour sélectionner la partition souhaitée. Nous avons dû créer un ensemble de partitions, il devrait y en avoir plus que le client n'en avait besoin. L'ordre de traitement des messages aurait dû être atteint car chaque partition est destinée à un seul destinataire. Simple et efficace.
Kafka, par rapport à RabbitMQ, présente certains avantages associés au fractionnement des messages à l'aide du hachage. Il n'y a rien sur la plate-forme RabbitMQ qui empêcherait les conflits de destinataires au sein de la même file d'attente générée dans le cadre de l'échange de données à l'aide d'un hachage cohérent. RabbitMQ n'aide pas à coordonner les destinataires afin qu'un seul destinataire de la file d'attente entière utilise le message. Kafka fournit tout cela grâce à l'utilisation de groupes de destinataires et d'un nœud de coordination. Cela vous permet de vous assurer qu'un seul destinataire dans la section est garanti pour utiliser le message et que l'ordre de traitement des données est garanti.
Localité de données
À l'aide d'une fonction de hachage pour distribuer les données sur les partitions, Kafka fournit la localité des données. Par exemple, les messages de l'utilisateur avec l'ID 1001 doivent toujours aller au destinataire 3. Comme les événements de l'utilisateur 1001 vont toujours au destinataire 3, le destinataire 3 peut effectivement effectuer certaines opérations qui seraient beaucoup plus difficiles si un accès régulier à une base de données externe ou à d'autres systèmes était nécessaire pour recevoir. les données. Nous pouvons lire des données, effectuer des agrégations, etc. directement avec des informations dans la mémoire du destinataire. C'est l'endroit où les applications orientées événements et le streaming de données commencent à se combiner.
Comment Kafka fournit-elle la localisation des données? Pour commencer, il est important de noter que Kafka ne permet pas d'augmenter et de diminuer élastiquement le nombre de partitions. Tout d'abord, vous ne pouvez pas du tout réduire le nombre de partitions: s'il y en a 10, vous ne pouvez pas réduire le nombre à 9. Mais, d'autre part, cela n'est pas obligatoire. Chaque destinataire peut utiliser 1 ou plusieurs partitions, il n'est donc pas nécessaire de réduire leur nombre. La création de partitions supplémentaires sur Kafka entraîne un retard au moment du rééquilibrage, nous essayons donc de faire évoluer le nombre de partitions en tenant compte des pics de charges.
Mais si nous devons encore augmenter le nombre de partitions et de destinataires pour évoluer, nous n'aurons besoin que de coûts indirects ponctuels si un rééquilibrage est nécessaire. Il convient de noter que lors de la mise à l'échelle, les anciennes données restent dans les mêmes partitions où elles se trouvaient. Mais les nouveaux messages entrants seront déjà acheminés différemment et les nouvelles partitions commenceront à recevoir de nouveaux messages. Les messages de l'utilisateur 1001 peuvent désormais aller au destinataire 4 (car les données sur l'utilisateur 1001 sont désormais divisées en deux sections).
De plus, nous comparerons et comparerons la sémantique de livraison des messages de livraison dans les deux systèmes. Le sujet du rééquilibrage et du partitionnement mérite un article séparé, dont nous discuterons dans la partie suivante.