Bonjour à tous, je m'appelle Semyon Levenson, je travaille en tant que chef d'équipe sur le projet Stream du Rambler Group et je veux parler de notre expérience avec Apollo.
Je vais vous expliquer ce qu'est le "Stream". Il s'agit d'un service automatisé pour les entrepreneurs, qui vous permet d'attirer des clients d'Internet vers l'entreprise sans vous impliquer dans la publicité, et de créer rapidement des sites simples sans être un expert en mise en page.
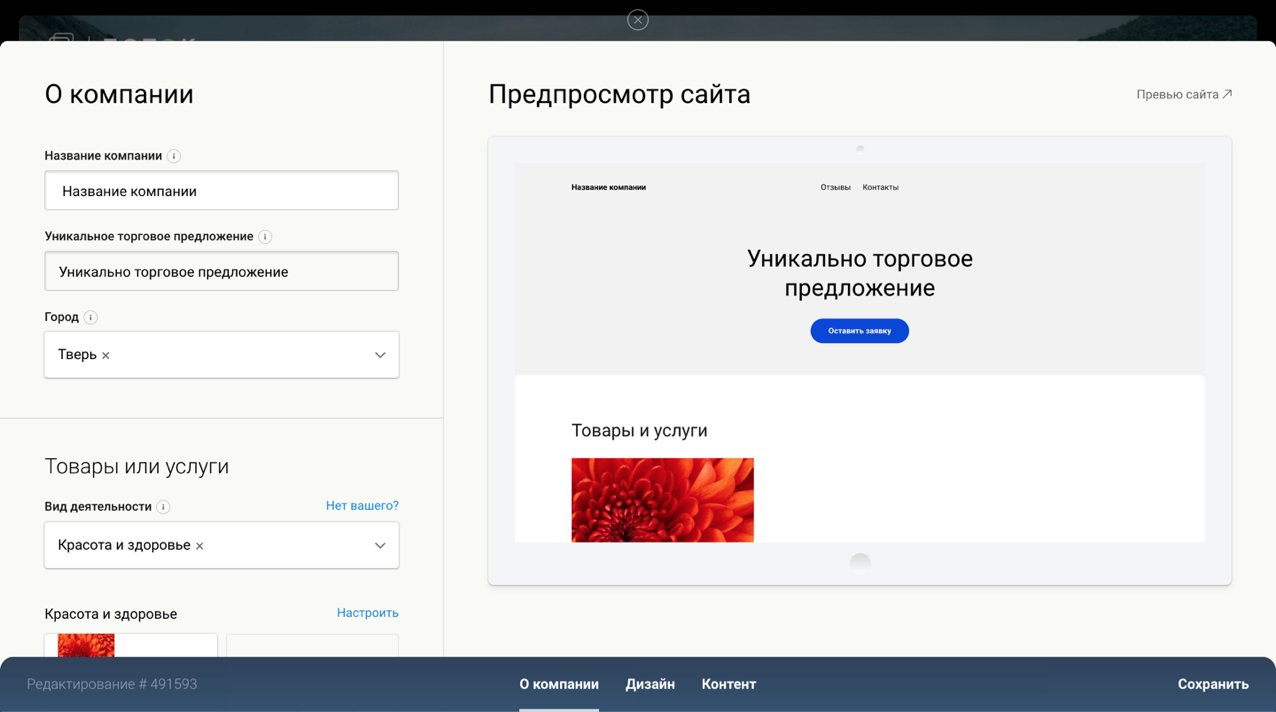
La capture d'écran montre l'une des étapes de la création d'une page de destination.
Quel a été le début?
Et au début, il y avait MVP, beaucoup de Twig, jQuery et des délais très serrés. Mais nous sommes allés d'une manière non standard et avons décidé de faire une refonte. La refonte n'est pas dans le sens de "styles corrigés", mais a décidé de revoir complètement le système. Et ce fut une bonne étape pour nous afin d'assembler le frontend parfait. Après tout, nous, l'équipe de développement, continuons à soutenir cela et à mettre en œuvre d'autres tâches sur la base de cela, à atteindre les nouveaux objectifs fixés par l'équipe produit.
Notre département a déjà accumulé suffisamment d'expertise dans l'utilisation de React. Je ne voulais pas passer 2 semaines à configurer le webpack, j'ai donc décidé d'utiliser CRA (Create React App). Pour les styles, les composants stylisés ont été pris, et où sans taper - ils ont pris Flow . Ils ont pris Redux pour la gestion de l'État, mais il s'est avéré que nous n'en avons pas besoin du tout, mais plus à ce sujet plus tard.
Nous avons mis en place notre interface parfaite et réalisé que nous avions oublié quelque chose. Il s'est avéré que nous avons oublié le backend, ou plutôt l'interaction avec lui. Lorsque vous avez réfléchi à ce que nous pouvons utiliser pour organiser cette interaction, la première chose qui m'est venue à l'esprit - bien sûr, c'est le repos. Non, nous ne sommes pas allés nous reposer (sourire), mais nous avons commencé à parler de l'API RESTful. En principe, l'histoire est familière, s'étire depuis longtemps, mais nous connaissons aussi les problèmes avec elle. Nous en parlerons.
Le premier problème est la documentation. RESTful, bien sûr, ne dit pas comment organiser la documentation. Ici, il y a une option pour utiliser le même swagger, mais en fait c'est l'introduction d'une entité supplémentaire et la complication des processus.
Le deuxième problème est de savoir comment organiser la prise en charge de la gestion des versions de l'API.
Le troisième problème important est un grand nombre de requêtes ou de points de terminaison personnalisés que nous pouvons récompenser. Supposons que nous devions demander des articles, pour ces articles - des commentaires et plus d'auteurs de ces commentaires. Dans le Rest classique, nous devons faire au moins 3 requêtes. Oui, nous pouvons récompenser les points de terminaison personnalisés, et tout cela peut être réduit à 1 demande, mais c'est déjà une complication.
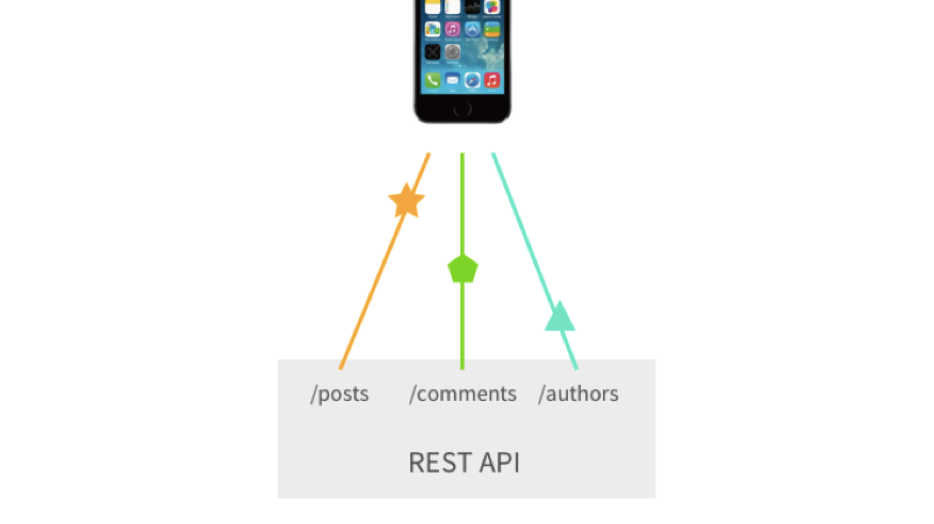
Merci Sashko Stubailo pour l'illustration .
Solution
Et en ce moment, Facebook vient à notre aide avec GraphQL. Qu'est-ce que GraphQL? Il s'agit d'une plate-forme, mais aujourd'hui, nous allons examiner l'une de ses parties - c'est le langage de requête pour votre API, juste un langage et assez primitif. Et cela fonctionne aussi simplement que possible - comme nous demandons une sorte d'entité, nous l'obtenons également.
Demande:
{ me { id isAcceptedFreeOffer balance } }
La réponse est:
{ "me": { "id": 1, "isAcceptedFreeOffer": false, "balance": 100000 } }
Mais GraphQL ne concerne pas seulement la lecture, il s'agit également de modifier les données. Pour ce faire, il existe des mutations dans GraphQL. Les mutations sont remarquables en ce que nous pouvons déclarer la réponse souhaitée du backend, avec un changement réussi. Cependant, il y a quelques nuances. Par exemple, si notre mutation affecte des données en dehors des limites du graphique.
Un exemple de mutation dans laquelle nous utilisons une offre gratuite:
mutation { acceptOffer (_type: FREE) { id isAcceptedFreeOffer } }
En réponse, nous obtenons la même structure que celle demandée
{ "acceptOffer": { "id": 1, "isAcceptedFreeOffer": true } }
L'interaction avec le backend GraphQL peut être effectuée en utilisant la récupération régulière.
fetch('/graphql', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ query: '{me { id balance } }' }) });
Quels sont les avantages de GraphQL?
Le premier avantage très cool qui peut être apprécié lorsque vous commencez à travailler avec lui est que cette langue est fortement typée et auto-documentée. En concevant le schéma GraphQL sur le serveur, nous pouvons immédiatement décrire les types et les attributs directement dans le code.

Comme mentionné ci-dessus, RESTful a un problème de version. GraphQL a implémenté une solution très élégante pour cela - obsolète.
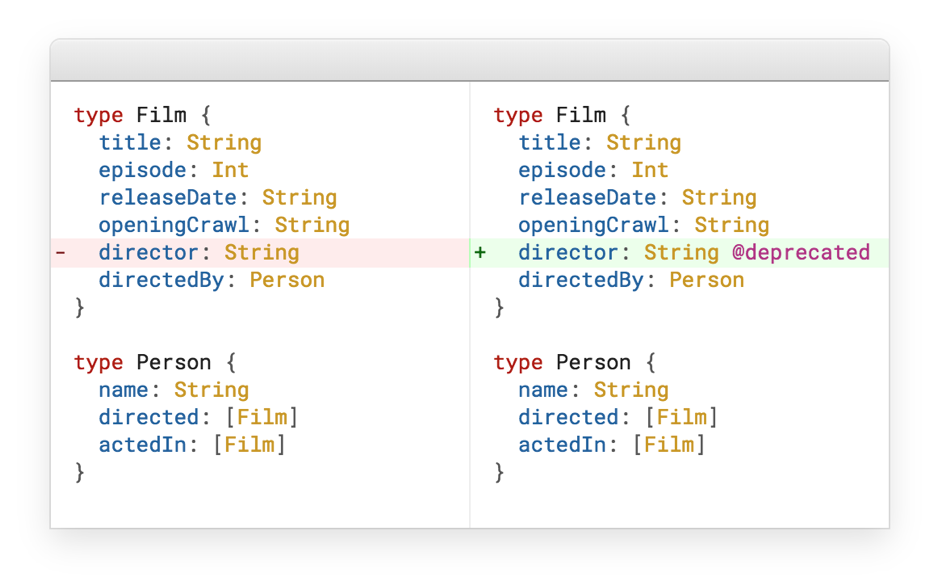
Supposons que nous ayons un film, nous le développons, nous avons donc un réalisateur. Et à un moment donné, nous faisons simplement du réalisateur un type distinct. La question est, que faire du dernier champ de réalisateur? Il y a deux réponses: soit nous supprimons ce champ, soit nous le marquons obsolète, et il disparaît automatiquement de la documentation.
Nous décidons indépendamment de ce dont nous avons besoin.
Nous rappelons l'image précédente, où tout s'est passé avec REST, mais ici tout est combiné en une seule demande et ne nécessite aucune personnalisation du développement backend. Une fois qu'ils l'ont tous décrit, et nous nous tordons, nous tordons, jonglons.
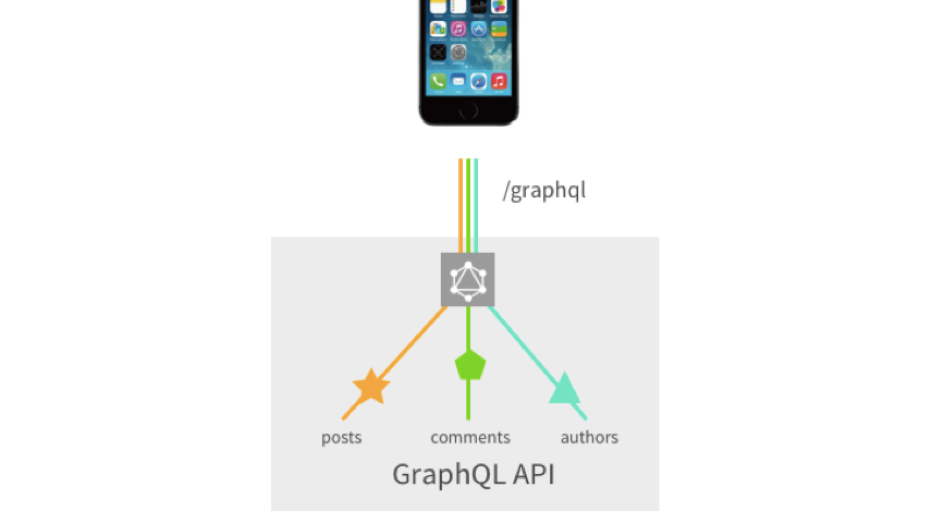
Mais pas sans une mouche dans la pommade. En principe, il n'y a pas autant d'inconvénients à GraphQL sur le frontend, car il a été développé à l'origine pour résoudre les problèmes du frontend. Mais le backend ne va pas si bien ... Ils ont un problème comme N + 1. Prenons l'exemple de la requête:
{ landings(_page: 0, limit: 20) { nodes { id title } totalCount } }
Une simple demande, nous demandons 20 sites et le nombre de sites que nous avons. Et dans le backend, cela peut se transformer en 21 requêtes de base de données. Ce problème est connu, résolu. Pour Node JS, il existe un package de chargeur de données de Facebook. Pour les autres langues, vous pouvez trouver vos propres solutions.
Il y a aussi le problème de la nidification profonde. Par exemple, nous avons des albums, ces albums ont des chansons, et grâce à la chanson, nous pouvons également obtenir des albums. Pour ce faire, effectuez les requêtes suivantes:
{ album(id: 42) { songs { title artists } } }
{ song(id: 1337) { title album { title } } }
Ainsi, nous obtenons une requête récursive, qui nous établit également élémentairement une base.
query evil { album(id: 42) { songs { album { songs { album {
Ce problème est également connu, la solution pour Node JS est la limite de profondeur GraphQL, pour d'autres langages il existe également des solutions.
Ainsi, nous avons opté pour GraphQL. Il est temps de choisir une bibliothèque qui fonctionnera avec l'API GraphQL. L'exemple de quelques lignes avec fetch, illustré ci-dessus, n'est qu'un transport. Mais grâce au schéma et à la déclarativité, nous pouvons également mettre en cache les requêtes à l'avant et travailler avec de meilleures performances avec le backend GraphQL.
Nous avons donc deux acteurs principaux - Relay et Apollo.
Relais
Relay est un développement Facebook, ils l'utilisent eux-mêmes. Comme Oculus, Circle CI, Arsti et Friday.
Quels sont les avantages du relais?
L'avantage immédiat est que le développeur est Facebook. React, Flow et GraphQL sont des développements Facebook, qui sont tous des puzzles adaptés les uns aux autres. Où en sommes-nous sans étoiles sur Github, Relay en a presque 11 000, Apollo en a 7600. La chose sympa que Relay a est Relay-compiler, un outil qui optimise et analyse vos requêtes GraphQL au niveau de la construction de votre projet . Nous pouvons supposer que ce n'est uglify que pour GraphQL:
# Relay-compiler foo { # type FooType id ... on FooType { # matches the parent type, so this is extraneous id } } # foo { id }
Quels sont les inconvénients du relais?
Le premier inconvénient * est le manque de SSR prêt à l'emploi. Github a toujours un problème ouvert. Pourquoi sous l'astérisque - car il existe déjà des solutions, mais elles sont tierces, et en plus, assez ambiguës.
Encore une fois, Relay est une spécification. Le fait est que GraphQL est déjà une spécification, et Relay est une spécification sur une spécification.
Par exemple, la pagination de relais est implémentée différemment, des curseurs apparaissent ici.
{ friends(first: 10, after: "opaqueCursor") { edges { cursor node { id name } } pageInfo { hasNextPage } } }
Nous n'utilisons plus les décalages et limites habituels. Pour les flux dans le flux, c'est un excellent sujet, mais lorsque nous commençons à faire toutes sortes de grilles, il y a de la douleur.
Facebook a résolu son problème en écrivant une bibliothèque pour React. Il existe des solutions pour d'autres bibliothèques, pour vue.js, par exemple - vue-relay . Mais si nous prêtons attention au nombre d'étoiles et d'engagements, ici aussi, tout n'est pas si fluide et peut être instable. Par exemple, la création de l'application React à partir de la zone CRA vous empêche d'utiliser le compilateur de relais. Mais vous pouvez contourner cette limitation avec react-app-rewired .
Apollo
Notre deuxième candidat est Apollo . Développé par son équipe Meteor . Apollo utilise des commandes bien connues telles que: AirBnB, ticketmaster, Opentable, etc.
Quels sont les avantages d'Apollo?
Le premier avantage significatif est qu'Apollo a été développé comme une bibliothèque agnostique de framework. Par exemple, si nous voulons maintenant tout réécrire sur Angular, ce ne sera pas un problème, Apollo fonctionne avec cela. Et vous pouvez même tout écrire en vanille.
Apollo a une documentation intéressante, il existe des solutions toutes faites aux problèmes courants.

Un autre plus Apollo - une puissante API. En principe, ceux qui ont travaillé avec Redux trouveront ici des approches communes: il y a ApolloProvider (comme Provux pour Redux), et au lieu de stocker pour Apollo, cela s'appelle client:
import { ApolloProvider } from 'react-apollo'; import { ApolloClient } from './ApolloClient'; const App = () => ( <ApolloProvider client={ApolloClient}> ... </ApolloProvider> );
Au niveau du composant lui-même, nous avons graphql HOC fourni comme connect. Et nous écrivons la requête GraphQL déjà à l'intérieur, comme MapStateToProps dans Redux.
import { graphql } from 'react-apollo'; import gql from 'graphql-tag'; import { Landing } from './Landing'; graphql(gql` { landing(id: 1) { id title } } `)(Landing);
Mais quand nous faisons MapStateToProps dans Redux, nous récupérons les données locales. S'il n'y a pas de données locales, Apollo va lui-même au serveur. Des accessoires très pratiques tombent dans le composant lui-même.
function Landing({ data, loading, error, refetch, ...other }) { ... }
C’est:
• données;
• état du téléchargement;
• une erreur si elle s'est produite;
des fonctions d'assistance comme refetch pour recharger les données ou fetchMore pour paginer. Il y a aussi un énorme avantage pour Apollo et Relay, qui est l'interface utilisateur optimiste. Il vous permet de valider annuler / rétablir au niveau de la demande:
this.props.setNotificationStatusMutation({ variables: { … }, optimisticResponse: { … } });
Par exemple, l'utilisateur a cliqué sur le bouton «J'aime», et «J'aime» a immédiatement compté. Dans ce cas, une demande au serveur sera envoyée en arrière-plan. Si une erreur se produit pendant le processus d'envoi, les données mutables reviendront à leur état d'origine par elles-mêmes.
Le rendu côté serveur est bien implémenté, nous avons défini un indicateur sur le client et tout est prêt.
new ApolloClient({ ssrMode: true, ... });
Mais ici, je voudrais parler de l'état initial. Quand Apollo le cuisine pour lui-même, tout fonctionne bien.
<script> window.__APOLLO_STATE__ = client.extract(); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link });
Mais nous n'avons pas de rendu côté serveur, et le backend pousse une requête GraphQL spécifique dans la variable globale. Ici, vous avez besoin d'une petite béquille, vous devez écrire une fonction de transformation que la réponse GraphQL du backend deviendra déjà au format nécessaire pour Apollo.
<script> window.__APOLLO_STATE__ = transform({…}); </script> const client = new ApolloClient({ cache: new InMemoryCache().restore(window.__APOLLO_STATE__), link });
Un autre avantage d'Apollo est qu'il est bien personnalisable. Nous nous souvenons tous du middleware de Redux, tout est pareil ici, seulement cela s'appelle un lien.

Je voudrais noter séparément deux liens: apollo-link-state , qui est nécessaire pour stocker l'état local en l'absence de Redux, et apollo-link-rest , si nous voulons écrire des requêtes GraphQL dans l'API Rest. Cependant, avec ce dernier, vous devez être extrêmement prudent, car certains problèmes peuvent survenir.
Apollo a aussi des inconvénients
Regardons un exemple. Un problème de performance inattendu s'est produit: 2 000 éléments ont été demandés sur le frontend (c'était un répertoire) et des problèmes de performances ont commencé. Après l'avoir vu dans le débogueur, il s'est avéré qu'Apollo ronge beaucoup de ressources en lisant, le problème est fondamentalement clos, maintenant tout va bien, mais il y avait un tel péché.
De plus, le refetch s'est avéré très peu évident ...
function Landing({ loading, refetch, ...other }) { ... }
Il semblerait que lorsque nous effectuons une nouvelle demande de données, en outre, si la demande précédente se terminait par une erreur, le chargement devrait devenir vrai. Mais non!
Pour que cela se produise, vous devez spécifier notifyOnNetworkStatusChange: true dans le graphql HOC ou stocker l'état de refetch localement.
Apollo contre Relais
Ainsi, nous avons eu une telle table, nous avons tous pesé, compté, et nous avions 76% de retard sur Apollo.
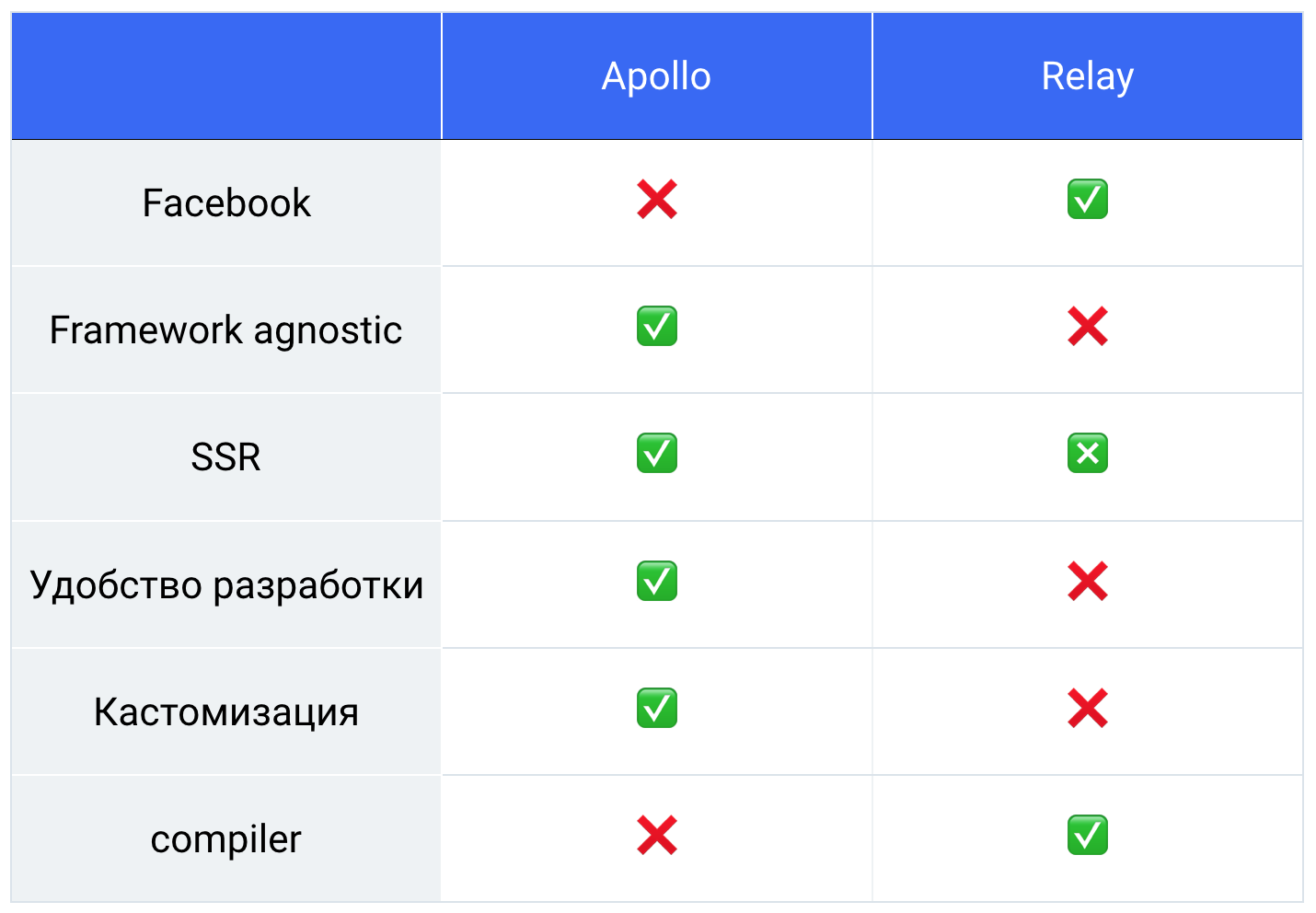
Nous avons donc choisi la bibliothèque et nous sommes allés travailler.
Mais je voudrais en dire plus sur la chaîne d'outils.
Tout est très bien ici, il existe différents modules complémentaires pour les éditeurs, quelque part mieux, quelque part pire. Il existe également apollo-codegen, qui génère des fichiers utiles, par exemple, des types de flux, et extrait essentiellement le schéma de l'API GraphQL.
La rubrique "Crazy Hands" ou ce que nous faisions à la maison
La première chose que nous avons rencontrée est que nous devons essentiellement demander des données.
graphql(BalanceQuery)(BalanceItem)
Nous avons des conditions communes: chargement, gestion des erreurs. Nous avons écrit notre propre faucon (asyncCard), qui est connecté via la composition de graqhql et asyncCard.
compose( graphql(BalanceQuery), AsyncCard )(BalanceItem)
Je voudrais également parler des fragments. Il existe un composant LandingItem et il sait de quelles données il a besoin à partir de l'API GraphQL. Nous définissons la propriété de fragment, où nous avons spécifié les champs de l'entité Landing.
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... } `;
Maintenant, au niveau de l'utilisation du composant, nous utilisons son fragment dans la requête finale.
query LandingsDashboard { landings(...) { nodes { ...LandingItem } totalCount } ${LandingItem.Fragment} }
Et disons qu'une tâche vole pour ajouter du statut à cette page de destination - ce n'est pas un problème. Nous ajoutons une propriété au rendu et au fragment. Et tout est prêt. Principe de responsabilité unique dans toute sa splendeur.
const LandingItem = ({ content }: Props) => ( <LandingItemStyle> … <LandingItemStatus … /> </LandingItemStyle> ); LandingItem.fragment = gql` fragment LandingItem on Landing { ... status } `;
Quel autre problème avions-nous?
Nous avons un certain nombre de widgets sur notre site qui ont fait leurs demandes individuelles.
Lors des tests, il s'est avéré que tout cela ralentit. Nous avons de très longs contrôles de sécurité et chaque demande coûte très cher. Cela s'est également avéré ne poser aucun problème, il y a Apollo-link-batch-http
new BatchHttpLink({ batchMax: 10, batchInterval: 10 });
Il est configuré comme suit: nous transmettons le nombre de requêtes que nous pouvons combiner et combien de temps ce lien attendra après l'apparition de la première requête.
Et cela s'est avéré comme ceci: en même temps tout se charge, et en même temps tout vient. Il convient de noter que si au cours de cette fusion, l'une des sous-requêtes revient avec une erreur, l'erreur ne sera que pour lui, et non pour la demande entière.
Je voudrais dire séparément que l'automne dernier, il y a eu une mise à jour du premier Apollo au second
Au début était Apollo et Redux
'react-apollo' 'redux'
Puis Apollo est devenu plus modulaire et extensible, ces modules peuvent être développés indépendamment. La même apollo-cache-inmemory.
'react-apollo' 'apollo-client' 'apollo-link-batch-http' 'apollo-cache-inmemory' 'graphql-tag'
Il convient de noter que Redux ne l'est pas, et il s'est avéré que, en principe, il n'est pas nécessaire.
Conclusions:
- Le délai de livraison des fonctionnalités a diminué, nous ne perdons pas de temps à décrire l'action, à réduire dans Redux et à moins toucher au backend
- L'antifragilité est apparue parce que L'analyse statique de l'API vous permet d'annuler les problèmes lorsque le frontend attend une chose et que le backend en retourne une complètement différente.
- Si vous commencez à travailler avec GraphQL - essayez Apollo, ne soyez pas déçu.
PS Vous pouvez également regarder une vidéo de ma présentation sur Rambler Front & Meet up # 4