Python est génial. Nous disons «pip install» et très probablement la bibliothèque nécessaire sera livrée. Mais parfois, la réponse sera: «la compilation a échoué», car il existe des modules binaires. Ils souffrent d'une sorte de douleur dans presque tous les langages modernes, car il y a beaucoup d'architectures, quelque chose doit être assemblé pour une machine spécifique, quelque chose doit être lié à d'autres bibliothèques. En général, une question intéressante mais peu étudiée: comment peut-on les faire et quels sont les problèmes? Dmitry Zhiltsov (
zaabjuda ) a tenté de répondre à cette question lors de la MoscowPython Conf l'année dernière.
Sous la coupe se trouve la version texte du rapport de Dmitry. Arrêtons-nous brièvement sur le moment où les modules binaires sont nécessaires, et quand il vaut mieux les abandonner. Discutons des règles à suivre lors de leur rédaction. Envisagez cinq options de mise en œuvre possibles:
- Extension native C / C ++
- Swig
- Cython
- Ctypes
- Rouille
À propos de l'orateur : Dmitry Zhiltsov se développe depuis plus de 10 ans. Il travaille au CIAN en tant qu'architecte système, c'est-à-dire qu'il est responsable des solutions techniques et du contrôle du temps. Dans ma vie, j'ai réussi à essayer l'assembleur, Haskell, C, et depuis 5 ans je programme activement en Python.
À propos de la société
Beaucoup de ceux qui vivent à Moscou et louent un logement connaissent probablement CIAN. CYAN, c'est 7 millions d'acheteurs et de locataires par mois. Tous ces utilisateurs, chaque mois, en utilisant notre service, trouvent un logement.
Environ 75% des Moscovites connaissent notre entreprise, et c'est très cool. À Saint-Pétersbourg et à Moscou, nous sommes pratiquement considérés comme des monopoles. En ce moment, nous essayons d'entrer dans les régions, et le développement a donc augmenté 8 fois au cours des 3 dernières années. Cela signifie que l'équipe a augmenté 8 fois, la vitesse de livraison des valeurs à l'utilisateur a augmenté 8 fois, c'est-à-dire d'une idée de produit à la façon dont la main d'un ingénieur a déployé un build à la production. Nous avons appris dans notre grande équipe à nous développer très rapidement, et à comprendre très rapidement ce qui se passe en ce moment, mais aujourd'hui nous allons parler un peu d'autre chose.
Je vais parler des modules binaires. Maintenant, près de 50% des bibliothèques Python ont une sorte de modules binaires. Et il s'est avéré que beaucoup de gens ne les connaissent pas et croient que c'est quelque chose de transcendantal, quelque chose de sombre et inutile. Et d'autres personnes suggèrent d'écrire un microservice séparé mieux et de ne pas utiliser de modules binaires.
L'article comprendra deux parties.
- Mon expérience: pourquoi ils sont nécessaires, quand ils sont mieux utilisés et quand ils ne le sont pas.
- Outils et technologies avec lesquels vous pouvez implémenter un module binaire pour Python.
Pourquoi des modules binaires sont-ils nécessaires?
Nous savons tous parfaitement que Python est un langage interprété. C'est presque le plus rapide des langages interprétés, mais, malheureusement, sa
vitesse n'est pas toujours suffisante pour les calculs mathématiques lourds. Immédiatement, la pensée surgit que C sera plus rapide.
Mais Python a encore une douleur - c'est
GIL . Un grand nombre d'articles ont été écrits à son sujet et des rapports ont été faits sur la façon de le contourner.
Nous avons également besoin d'extensions binaires pour
réutiliser la logique . Par exemple, nous avons trouvé une bibliothèque qui possède toutes les fonctionnalités dont nous avons besoin, et pourquoi ne pas l'utiliser. Autrement dit, vous n'avez pas besoin de réécrire le code, nous prenons simplement le code fini et le réutilisons.
Beaucoup de gens croient qu'en utilisant des extensions binaires, vous pouvez
masquer le code source . La question est très, très controversée, bien sûr, avec l'aide de certaines perversions sauvages, cela peut être atteint, mais il n'y a pas de garantie à 100%. Le maximum que vous pouvez obtenir est de ne pas laisser le client décompiler et voir ce qui se passe dans le code que vous avez transmis.
Quand les extensions binaires sont-elles vraiment nécessaires?
À propos de la vitesse et de Python, il est clair - lorsque certaines fonctions fonctionnent très lentement et occupent 80% du temps d'exécution de tout le code, nous commençons à penser à écrire une extension binaire. Mais pour prendre de telles décisions, vous devez commencer, comme l'a dit un orateur célèbre, à penser avec votre cerveau.
Pour écrire des extensions d'extensions, il faut tenir compte du fait que cela sera tout d'abord long. Vous devez d'abord "lécher" vos algorithmes, c'est-à-dire voir s'il y a des jambages.
Dans 90% des cas, après une vérification approfondie de l'algorithme, la nécessité d'écrire quelques extensions disparaît.
Le deuxième cas où des extensions binaires sont vraiment nécessaires est l'
utilisation du multi-threading pour des opérations simples . Maintenant, ce n'est pas si pertinent, mais cela reste dans l'entreprise sanglante, dans certains intégrateurs de systèmes, où Python 2.6 est toujours écrit. Il n'y a pas d'asynchronie, et même pour des choses simples, par exemple, le téléchargement d'un tas d'images, le multi-threading augmente. Il semble qu'au départ, cela n'entraîne pas de frais de réseau, mais lorsque nous téléchargeons l'image dans la mémoire tampon, le malheureux GIL arrive et une sorte de frein commence. Comme le montre la pratique, de telles choses sont mieux résolues en utilisant des bibliothèques dont Python ne sait rien.
Si vous devez implémenter un protocole spécifique, il peut être pratique de créer du code C / C ++ simple et de vous débarrasser de beaucoup de douleur. Je l'ai fait à mon époque dans un opérateur de télécommunications, car il n'y avait pas de bibliothèque toute faite - je devais l'écrire moi-même. Mais je le répète, maintenant ce n'est pas très pertinent, car il y a asyncio, et pour la plupart des tâches c'est suffisant.
A propos d'
opérations manifestement
difficiles, je l'ai déjà dit à l'avance. Lorsque vous avez des plantages, de grandes matrices et autres, il est logique que vous ayez besoin de faire une extension en C / C ++. Je veux noter que certaines personnes pensent que nous n'avons pas besoin d'extensions binaires ici, il est préférable de créer un microservice dans un «
langage ultra-rapide » et de transférer d'énormes matrices sur le réseau. Non, il vaut mieux ne pas faire ça.
Un autre bon exemple quand ils peuvent et doivent même être pris est quand vous avez une
logique établie du module . Si vous avez une sorte de module Python dans votre entreprise ou qu'une bibliothèque existe déjà depuis 3 ans, il y a des changements une fois par an puis 2 lignes, alors pourquoi ne pas en faire une bibliothèque C normale s'il y a des ressources et du temps libres. Obtenez au minimum une augmentation de la productivité. Et il y aura également une compréhension que si certains changements cardinaux sont nécessaires dans la bibliothèque, alors ce n'est pas si simple et, peut-être, cela vaut la peine de réfléchir à nouveau avec le cerveau et d'utiliser cette bibliothèque d'une manière différente.
5 règles d'or
J'ai dérivé ces règles dans ma pratique. Ils concernent non seulement Python, mais aussi d'autres langages pour lesquels vous pouvez utiliser des extensions binaires. Vous pouvez discuter avec eux, mais vous pouvez également penser et apporter les vôtres.
- Fonctions d'exportation uniquement . Construire des classes en Python dans des bibliothèques binaires prend beaucoup de temps: vous devez décrire un grand nombre d'interfaces, vous devez revoir beaucoup d'intégrité de référence dans le module lui-même. Il est plus facile d'écrire une petite interface pour la fonction.
- Utilisez des classes wrapper . Certains aiment beaucoup la POO et veulent vraiment des cours. Dans tous les cas, même si ce ne sont pas des classes, il est préférable d'écrire simplement un wrapper Python: créer une classe, définir une méthode de classe ou une méthode régulière, appeler des fonctions natives C / C ++. Au minimum, cela permet de maintenir l'intégrité de l'architecture des données. Si vous utilisez une sorte d'extension tierce C / C ++ que vous ne pouvez pas corriger, alors dans l'encapsuleur, vous pouvez la pirater pour que tout fonctionne.
- Vous ne pouvez pas passer d'arguments de Python à une extension - ce n'est même pas une règle, mais plutôt une exigence. Dans certains cas, cela peut fonctionner, mais c'est généralement une mauvaise idée. Par conséquent, dans votre code, vous devez d'abord créer un gestionnaire qui convertit le type Python en type C. Et seulement après cet appel, toute fonction native qui fonctionne déjà avec le type s. Le même gestionnaire reçoit une réponse d'une fonction exécutable, la transforme en types de données Python et la jette en code Python.
- Tenez compte de la collecte des ordures . Python a un GC bien connu, et vous ne devriez pas l'oublier. Par exemple, nous passons un grand morceau de texte par référence et essayons de trouver un mot dans la bibliothèque. Nous voulons paralléliser cela, nous passons le lien vers cette zone mémoire et au lancement de plusieurs threads. À ce moment, le GC prend simplement et décide que rien d'autre ne fait référence à cet objet et le supprime de la zone de mémoire. Dans le même code, nous obtenons juste une référence nulle, et c'est généralement une erreur de segmentation. Nous ne devons pas oublier une telle fonctionnalité du garbage collector et passer les types de données les plus simples aux bibliothèques de caractères: char, integer, etc.
D'un autre côté, la langue dans laquelle l'extension est écrite peut avoir son propre garbage collector. La combinaison de Python et de la bibliothèque C # est pénible dans ce sens.
- Définissez explicitement les arguments de la fonction exportée . Par cela, je veux dire que ces fonctions devront être annotées qualitativement. Si nous acceptons la fonction PyObject, et dans tous les cas nous l'accepterons dans notre bibliothèque, alors nous devrons indiquer explicitement quels arguments appartiennent à quels types. Ceci est utile car si nous transmettons le mauvais type de données, nous obtiendrons une erreur dans la bibliothèque. Autrement dit, vous en avez besoin pour votre commodité.
Architecture d'extension binaire

En fait, il n'y a rien de compliqué dans l'architecture des extensions binaires. Il y a Python, il y a une fonction d'appel qui atterrit sur un wrapper qui appelle nativement le code. Cet appel atterrit à son tour sur une fonction qui est exportée vers Python et qu'il peut appeler directement. C'est dans cette fonction que vous devez convertir des types de données en types de données de votre langue. Et seulement après que cette fonction nous a tout traduit, nous appelons la fonction native, qui fait la logique principale, renvoie le résultat dans la direction opposée et le jette en Python, traduisant les types de données en arrière.
Technologie et outils
La façon la plus connue d'écrire des extensions binaires est l'extension Native C / C ++. Tout simplement parce qu'il s'agit de la technologie Python standard.
Extension native C / C ++
Python lui-même est implémenté en C, et les méthodes et structures de python.h sont utilisées pour écrire des extensions. Soit dit en passant, cette chose est également bonne car elle est très facile à implémenter dans un projet existant. Il suffit de spécifier xt_modules dans setup.py et de dire que pour construire le projet, vous devez compiler de telles sources avec de tels drapeaux de compilation. Voici un exemple.
name = 'DateTime.mxDateTime.mxDateTime' src = 'mxDateTime/mxDateTime.c' extra_compile_args=['-g3', '-o0', '-DDEBUG=2', '-UNDEBUG', '-std=c++11', '-Wall', '-Wextra'] setup ( ... ext_modules = [(name, { 'sources': [src], 'include_dirs': ['mxDateTime'] , extra_compile_args: extra_compile_args } )] )
Avantages de l'extension native C / C ++
- Technologie native.
- Il s'intègre facilement dans le montage du projet.
- La plus grande quantité de documentation.
- Vous permet de créer vos propres types de données.
Inconvénients de l'extension native C / C ++
- Seuil d'entrée élevé.
- La connaissance de C. est requise.
- Boost.Python.
- Erreur de segmentation.
- Difficultés de débogage.
Selon cette technologie, une énorme quantité de documentation est écrite, à la fois des articles standard et des articles de blog. Un énorme avantage est que nous pouvons créer nos propres types de données Python et construire nos classes.
Cette approche présente de gros inconvénients. Premièrement, c'est le seuil d'entrée - tout le monde ne connaît pas suffisamment le C pour coder pour la production. Vous devez comprendre que pour cela, il ne suffit pas de lire le livre et d'exécuter des extensions natives. Si vous voulez faire cela, alors: d'abord, apprenez C; puis commencez à écrire des utilitaires de commande; ce n'est qu'après cela que vous pourrez écrire des extensions.
Boost.Python est très bon pour C ++, il vous permet d'abstraire presque complètement de tous ces wrappers que nous utilisons en Python. Mais le moins, je pense, c'est que vous devez beaucoup transpirer pour en prendre une partie et l'importer dans le projet sans télécharger l'intégralité de Boost.
Énumérant les difficultés de débogage dans les inconvénients, je veux dire que maintenant tout le monde est habitué à utiliser un débogueur graphique, et avec les modules binaires, une telle chose ne fonctionnera pas. Vous devez probablement installer GDB avec un plugin pour Python.
Regardons un exemple de la façon dont nous créons cela.
#include <Python.h> static PyObject*addList_add(Pyobject* self, Pyobject* args){ PyObject * listObj; if (! PyARg_Parsetuple( args, "", &listObj)) return NULL; long length = PyList_Size(listObj) int i, sum =0; // return Py_BuildValue("i", sum); }
Pour commencer, nous incluons les fichiers d'en-tête Python. Après cela, nous décrivons la fonction addList_add que Python utilisera. La chose la plus importante est de nommer la fonction correctement, dans ce cas addList est le nom du module, _add est le nom de la fonction qui sera utilisée en Python. Nous passons le module PyObject lui-même et passons également les arguments en utilisant PyObject. Après cela, nous effectuons des vérifications standard. Dans ce cas, nous essayons d'analyser l'argument tuple et de dire qu'il s'agit d'un objet - le "O" littéral doit être explicitement spécifié. Après cela, nous savons que nous avons passé listObj en tant qu'objet, et nous essayons de découvrir sa longueur en utilisant des méthodes Python standard: PyList_Size. Remarque, ici, nous ne pouvons toujours pas utiliser les appels pour connaître la longueur de ce vecteur, mais utiliser la fonctionnalité Python. Nous omettons l'implémentation, après quoi il est nécessaire de retourner toutes les valeurs à Python. Pour ce faire, appelez Py_BuildValue, spécifiez le type de données que nous renvoyons, dans ce cas «i» est un entier et la variable somme elle-même.
Dans ce cas, tout le monde comprend - on retrouve la somme de tous les éléments de la liste. Allons un peu plus loin.
for(i = 0; i< length; i++){
C'est la même chose; pour le moment, listObj est un objet Python. Et dans ce cas, nous essayons de prendre les éléments de la liste. Python.h a tout ce dont vous avez besoin pour cela.
Après avoir obtenu la température, nous essayons de la lancer trop longtemps. Et seulement après cela, vous pouvez faire quelque chose en C.
Après avoir implémenté la fonction entière, il est nécessaire d'écrire de la documentation.
La documentation est toujours bonne , et cette boîte à outils a tout pour une maintenance pratique. En suivant la convention de dénomination, nous nommons le module addList_docs et y enregistrons la description. Vous devez maintenant enregistrer le module, pour cela, il existe une structure PyMethodDef spéciale. En décrivant les propriétés, nous disons que la fonction est exportée vers Python sous le nom «add», que cette fonction appelle PyCFunction. METH_VARARGS signifie qu'une fonction peut potentiellement prendre n'importe quel nombre de variables. Nous avons également noté des lignes supplémentaires et décrit une vérification standard, au cas où nous venions d'importer le module, mais n'avons utilisé aucune méthode pour qu'il ne tombe pas.
Après avoir annoncé tout cela, nous essayons de créer un module. Nous créons un moduledef et y mettons tout ce que nous avons fait.
static struct PyModuleDef moduledef = { PyModuleDef_HEAD_INIT, "addList example module", -1, adList_funcs, NULL, NULL, NULL, NULL };
PyModuleDef_HEAD_INIT est une constante Python standard que vous devez toujours utiliser. -1 indique qu'aucune mémoire supplémentaire n'a besoin d'être allouée au stade de l'importation.
Lorsque nous avons créé le module lui-même, nous devons l'initialiser. Python recherche toujours init, alors créez un PyInit_addList pour addList. Maintenant, à partir de la structure assemblée, vous pouvez appeler PyModule_Create et enfin créer le module lui-même. Ensuite, ajoutez les méta-informations et renvoyez le module lui-même.
PyInit_addList(void){ PyObject *module = PyModule_Create(&mdef); If (module == NULL) return NULL; PyModule_AddStringConstant(module, "__author__", "Bruse Lee<brus@kf.ch>:"); PyModule_addStringConstant (Module, "__version__", "1.0.0"); return module; }
Comme vous l'avez déjà remarqué, il y a beaucoup de choses à transformer. Vous devez toujours vous souvenir de Python lorsque nous écrivons en C / C ++.
C'est pourquoi, pour faciliter la vie d'un programmeur mortel ordinaire, il y a environ 15 ans, la technologie SWIG est apparue.
Swig
Cet outil vous permet d'abstraire des liaisons Python et d'écrire du code natif. Il présente les mêmes avantages et inconvénients que Native C / C ++, mais il existe des exceptions.
SWIG Pros:
- Technologie stable.
- Une grande quantité de documentation.
- Résumés de la liaison à Python.
Inconvénients de SWIG:
- Configuration longue.
- Connaissances C.
- Erreur de segmentation.
- Difficultés de débogage.
- La complexité de l'intégration dans l'assemblage du projet.
Le premier inconvénient est que
pendant que vous l'installez, vous perdrez la tête . Quand je l'ai installé pour la première fois, j'ai passé un jour et demi à le lancer. Alors, bien sûr, c'est plus facile. SWIG 3.x est devenu plus facile.
Afin de ne plus entrer dans le code, considérons le schéma général de SWIG.
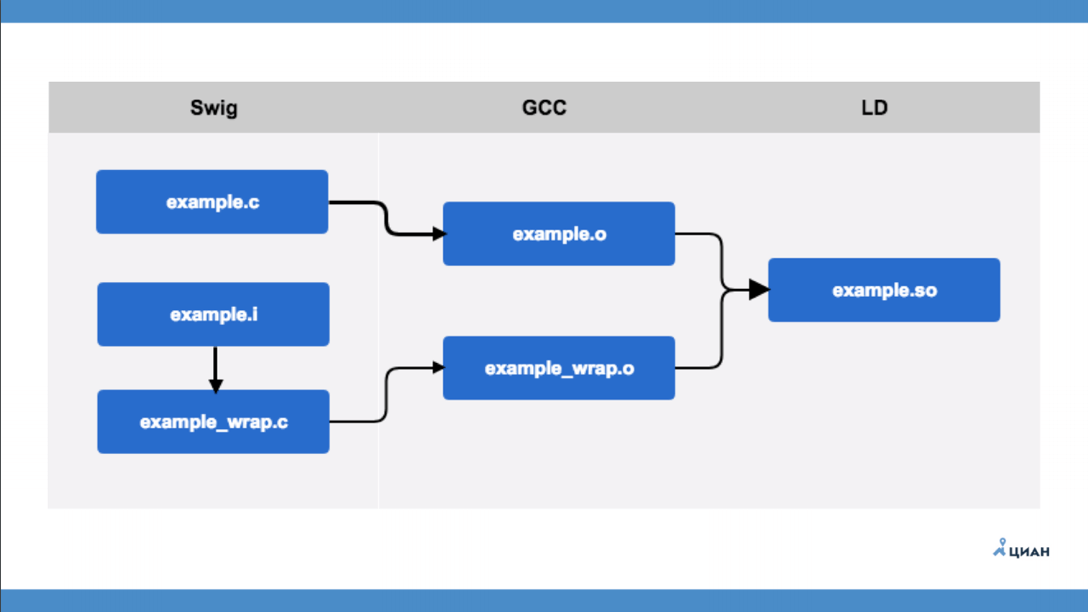
example.c est un module C qui ne sait rien du tout sur Python. Il existe un fichier d'interface example.i, qui est décrit au format SWIG. Après cela, exécutez l'utilitaire SWIG, qui crée example_wrap.c à partir du fichier d'interface - c'est le même wrapper que nous avions l'habitude de faire avec nos mains. Autrement dit, SWIG crée simplement un wrapper de fichier pour nous, le soi-disant pont. Après cela, en utilisant GCC, nous compilons deux fichiers et obtenons deux fichiers objets (example.o et example_wrap.o) et seulement ensuite nous créons notre bibliothèque. Tout est simple et clair.
Cython
Andrey Svetlov a fait un excellent
rapport à MoscowPython Conf, donc je vais juste dire que c'est une technologie populaire avec une bonne documentation.
Avantages de Cython:
- Technologie populaire.
- Assez stable.
- Il s'intègre facilement dans le montage du projet.
- Bonne documentation.
Inconvénients de Cython:
- Propre syntaxe.
- Connaissances C.
- Erreur de segmentation.
- Difficultés de débogage.
Les inconvénients, comme toujours, le sont. Le principal est sa propre syntaxe, qui est similaire à C / C ++, et très similaire à Python.
Mais je tiens à souligner que le code Python peut être accéléré à l'aide de Cython en écrivant du code natif.

Comme vous pouvez le voir, il y a beaucoup de décorateurs, et ce n'est pas très bon. Si vous souhaitez utiliser Cython - reportez-vous au rapport d'Andrei Svetlov.
CTypes
CTypes est la bibliothèque Python standard qui fonctionne avec l'interface de fonction étrangère. FFI est une bibliothèque de bas niveau. Il s'agit d'une technologie native, elle est terriblement souvent utilisée dans le code, avec son aide, elle est facile à implémenter multi-plateforme.
Mais FFI supporte beaucoup de frais généraux car tous les ponts, tous les gestionnaires en runtime sont créés dynamiquement. Autrement dit, nous avons chargé la bibliothèque dynamique et Python à ce moment ne sait pas ce qu'est la bibliothèque. Ce n'est que lorsqu'une bibliothèque est appelée en mémoire que ces ponts sont construits dynamiquement.
Avantages des CTypes:
- Technologie native.
- Facile à utiliser dans le code.
- Multiplateforme facile à mettre en œuvre.
- Vous pouvez utiliser presque toutes les langues.
Contre CTypes:
- Transporte les frais généraux.
- Difficultés de débogage.
from ctypes import *
Ils ont pris adder.so et l'ont appelé lors de l'exécution. On peut même passer en types natifs Python.
Après tout cela, la question est: "C'est en quelque sorte compliqué, partout C, que faire?".
Rouille
À un moment donné, je n'ai pas accordé une attention appropriée à la langue, mais maintenant je m'y tourne pratiquement.
Avantages de Rust:
- Langage sûr.
- Puissantes garanties statiques de comportement correct.
- S'intègre facilement dans les builds de projet ( PyO3 ).
Inconvénients de la rouille:
- Seuil d'entrée élevé.
- Configuration longue.
- Difficultés de débogage.
- Il y a peu de documentation.
- Dans certains cas, les frais généraux.
La rouille est une langue sûre avec preuve de travail automatique. La syntaxe elle-même et le préprocesseur de langage lui-même ne permettent pas une erreur explicite. Dans le même temps, il se concentre sur la variabilité, c'est-à-dire qu'il doit traiter tout résultat de l'exécution de la branche de code.
Grâce à l'équipe PyO3, il existe de bons classeurs Python pour Rust et des outils pour s'intégrer dans le projet.
À la baisse, je suppose que pour un programmeur non préparé, il faut beaucoup de temps pour le configurer. Peu de documentation, mais au lieu des inconvénients, nous n'avons pas de défaut de segmentation. Dans Rust, dans le bon sens, dans 99% des cas, un programmeur ne peut obtenir un défaut de segmentation que s'il a explicitement indiqué déballer et simplement le marquer.
Un petit exemple de code, le même module que nous avons examiné auparavant.
#![feature(proc_macro)] #[macro_use] extern crate pyo3; Use pyo3::prelude::*;
Le code a une syntaxe spécifique, mais on s'y habitue très rapidement. En fait, tout est pareil ici. En utilisant des macros, nous créons modinit, qui pour nous fait tout le travail supplémentaire de génération de toutes sortes de classeurs pour Python. N'oubliez pas que j'ai dit, vous devez faire un wrapper de gestionnaire, ici c'est la même chose. run_py convertit les types, puis nous appelons le code natif.
Comme vous pouvez le voir, pour exporter une fonction, il y a du sucre syntaxique. Nous disons simplement que nous avons besoin de la fonction add et ne décrivons aucune interface. Nous acceptons list, qui est exactement py_list, pas Object, car Rust lui-même configurera les classeurs nécessaires au moment de la compilation. Si nous transmettons le mauvais type de données, comme dans les extensions d'extension, une TypeError se produira. Après avoir obtenu la liste, nous commençons à la traiter.
Voyons plus en détail ce qu'il commence à faire.
#[pyfn(m, "add", py_list="*")] fn add(_py: Python, py_list: &PyList) -> PyResult<i32> { match py_list.len() { 0 =>Err(EmptyListError::new("List is empty")), _ => { let mut sum : i32 = 0; for item in py_list.iter() { let temp:i32 = match item.extract() { Ok(v) => v, Err(_) => { let err_msg: String = format!("List item {} is not int", item); return Err(ItemListError::new(err_msg)) } }; sum += temp; } Ok(sum) } } }
Le même code qui était en C / C ++ / Ctypes, mais seulement en Rust. Là, j'ai essayé de lancer PyObject sur une sorte de long. Que se passerait-il si nous devions lister, à l'exception des nombres, aurions-nous une chaîne? Oui, nous obtiendrions un SystemEerror. Dans ce cas, via
let mut sum
: i32 = 0; nous essayons également d'obtenir une valeur de la liste et de la convertir en i32. Autrement dit, nous ne serons pas en mesure d'écrire ce code sans item.extract (), inconsciemment et converti en le type souhaité. Lorsque nous avons écrit i32, dans le cas d'une erreur Rust, au stade de la compilation, il est dit: «Traitez le cas lorsque ce n'est pas i32». Dans ce cas, si nous avons i32, nous retournons une valeur, si c'est une erreur, nous lançons une exception.
Que choisir
Après cette courte tournée, nous penserons à quoi choisir à la fin?
La réponse est vraiment à votre goût et à votre couleur.
Je ne ferai la promotion d'aucune technologie spécifique.

Résumez simplement ce qui a été dit:
- Dans le cas de SWIG et C / C ++, vous devez très bien connaître C / C ++, comprendre que le développement de ce module entraînera des frais supplémentaires. Mais un minimum d'outils sera utilisé, et nous travaillerons dans la technologie native Python, qui est prise en charge par les développeurs.
- Dans le cas de Cython, nous avons un petit seuil d'entrée, nous avons une vitesse de développement élevée, et c'est aussi un générateur de code ordinaire.
- Au détriment des CTypes, je veux vous mettre en garde contre les frais généraux relativement importants. Le chargement dynamique de bibliothèque, lorsque nous ne savons pas de quel type de bibliothèque il s'agit, peut entraîner de nombreux problèmes.
- Je conseillerais à Rust de prendre quelqu'un qui ne connaît pas bien le C / C ++. La rouille en production pose vraiment le moins de problèmes.
Appel à communications
Nous acceptons les candidatures pour Moscou Python Conf ++ jusqu'au 7 septembre - écrivez sous cette forme simple que vous connaissez Python que vous avez vraiment besoin de partager avec la communauté.
Pour ceux qui sont plus intéressés par l'écoute, je peux parler de reportages sympas.
- Donald Whyte aime parler de l'accélération des mathématiques en Python et prépare une nouvelle histoire pour nous: comment rendre les mathématiques 10 fois plus rapides en utilisant des bibliothèques populaires, des astuces et de l'insidiosité, et le code est compréhensible et pris en charge.
- Artyom Malyshev a rassemblé toutes ses nombreuses années d'expérience dans le développement de Django et présente un rapport-guide sur le framework! Tout ce qui se passe entre la réception d'une requête HTTP et l'envoi d'une page Web terminée: exposer la magie, une carte des mécanismes internes du framework, et de nombreux conseils utiles pour vos projets.