Bonjour, Habr! Plus récemment, nous avons
brièvement parlé des interfaces en langage naturel. Eh bien, aujourd'hui, nous ne l'avons pas brièvement. Sous la coupe, vous trouverez une histoire complète sur la création de NL2API pour l'API Web. Nos collègues de Research ont essayé une approche unique de collecte de données de formation pour le framework. Rejoignez-nous maintenant!

Annotation
À mesure qu'Internet évolue vers une architecture orientée services, les interfaces logicielles (API) deviennent de plus en plus importantes pour fournir un accès aux données, aux services et aux appareils. Nous travaillons sur la question de la création d'une interface en langage naturel pour l'API (NL2API), en nous concentrant sur les services Web. Les solutions NL2API présentent de nombreux avantages potentiels, par exemple, en aidant à simplifier l'intégration des services Web dans les assistants virtuels.
Nous proposons la première plateforme complète (framework) qui vous permet de créer NL2API pour une API web spécifique. La tâche principale consiste à collecter des données pour la formation, c'est-à-dire les paires «commande NL - appel API», permettant à NL2API d'étudier la sémantique des deux commandes NL qui n'ont pas de format strictement défini et d'appels API formalisés. Nous proposons notre propre approche unique de collecte de données de formation pour NL2API à l'aide du crowdsourcing - en attirant de nombreux travailleurs à distance pour générer diverses équipes NL. Nous optimisons le processus de crowdsourcing lui-même afin de réduire les coûts.
En particulier, nous proposons un modèle probabiliste hiérarchique fondamentalement nouveau qui nous aidera à répartir le budget du crowdsourcing, principalement entre les appels d'API qui sont de grande valeur pour l'apprentissage de NL2API. Nous appliquons notre cadre à de véritables API et montrons qu'il vous permet de collecter des données de formation de haute qualité à un coût minimal, ainsi que de créer NL2API hautes performances à partir de zéro. Nous démontrons également que notre modèle de crowdsourcing améliore l'efficacité de ce processus, c'est-à-dire que les données de formation collectées dans son cadre fournissent des performances NL2API plus élevées, qui dépassent considérablement la ligne de base.
Présentation
Les interfaces de programmation d'applications (API) jouent un rôle de plus en plus important dans les mondes virtuel et physique, grâce au développement de technologies telles que l'architecture orientée services (SOA), le cloud computing et l'Internet des objets (IoT). Par exemple, les services Web hébergés dans le cloud (météo, sports, finance, etc.) via l'API Web fournissent des données et des services aux utilisateurs finaux, et les appareils IoT permettent à d'autres appareils réseau d'utiliser leurs fonctionnalités.
 Figure 1. Les paires «commande NL (gauche) et appel API (droite)» assemblées
Figure 1. Les paires «commande NL (gauche) et appel API (droite)» assemblées
notre cadre, et comparaison avec IFTTT. GET-Messages et GET-Events sont deux API Web pour rechercher des e-mails et des événements de calendrier, respectivement. L'API peut être appelée avec différents paramètres. Nous nous concentrons sur les appels d'API entièrement paramétrés, tandis que IFTTT est limité aux API avec des paramètres simples.En règle générale, les API sont utilisées dans une variété de logiciels: applications de bureau, sites Web et applications mobiles. Ils servent également les utilisateurs via une interface utilisateur graphique (GUI). L'interface graphique a grandement contribué à la vulgarisation des ordinateurs, mais à mesure que la technologie informatique a évolué, ses nombreuses limites se manifestent de plus en plus. D'une part, à mesure que les appareils deviennent plus petits, plus mobiles et plus intelligents, les exigences d'affichage graphique à l'écran augmentent constamment, par exemple en ce qui concerne les appareils portables ou les appareils connectés à l'IoT.
D'un autre côté, les utilisateurs doivent s'adapter à diverses interfaces graphiques spécialisées pour divers services et appareils. À mesure que le nombre de services et d'appareils disponibles augmente, le coût de la formation et de l'adaptation des utilisateurs augmente également. Les interfaces NLI (Natural Language Interfaces), telles que les assistants virtuels Apple Siri et Microsoft Cortana, également appelées interfaces conversationnelles ou de dialogue (CUI), présentent un potentiel important en tant qu'outil intelligent unique pour une large gamme de services et d'appareils serveur.
Dans cet article, nous considérons le problème de la création d'une interface en langage naturel pour l'API (NL2API). Mais, contrairement aux assistants virtuels, ce ne sont pas des NLI à usage général,
nous développons des approches pour créer des NLI pour des API Web spécifiques, c'est-à-dire des API de services Web comme le service multisports ESPN1. De telles NL2API peuvent résoudre le problème d'évolutivité des NLI à usage général en permettant le développement distribué. L'utilité d'un assistant virtuel dépend en grande partie de l'étendue de ses capacités, c'est-à-dire du nombre de services qu'il prend en charge.
Cependant, l'intégration de services Web dans un assistant virtuel un à la fois est un travail extrêmement laborieux. Si les fournisseurs de services Web individuels avaient un moyen peu coûteux de créer des NLI pour leurs API, les coûts d'intégration seraient considérablement réduits. Un assistant virtuel n'aurait pas à traiter différentes interfaces pour différents services Web. Il lui suffirait d'intégrer simplement des NL2API individuelles, qui atteignent l'uniformité grâce au langage naturel. D'un autre côté, NL2API peut également simplifier la découverte de services Web et de systèmes de recommandation et d'assistance de programmation pour les API, éliminant ainsi la nécessité de se souvenir du grand nombre d'API Web disponibles et de leur syntaxe.
Exemple 1. La figure 1 illustre deux exemples. L'API peut être appelée avec différents paramètres. Dans le cas de l'API de recherche par e-mail, les utilisateurs peuvent filtrer les e-mails par propriétés spécifiques ou rechercher des e-mails par mots clés. La tâche principale de NL2API est de mapper les commandes NL aux appels API correspondants.
Défi. La collecte de données de formation est l'une des tâches les plus importantes associées à la recherche sur le développement d'interfaces NLI et leur application pratique. Les NLI utilisent des données d'entraînement contrôlées qui, dans le cas de NL2API, sont constituées de paires de "commande NL - appel API" pour étudier la sémantique et mapper sans ambiguïté les commandes NL aux représentations formalisées correspondantes. Le langage naturel est très flexible, de sorte que les utilisateurs peuvent décrire l'appel d'API de différentes manières syntaxiques, c'est-à-dire que la paraphrase a lieu.
Prenons le deuxième exemple de la figure 1. Les utilisateurs peuvent reformuler cette question comme suit: «Où se tiendra la prochaine réunion» ou «Trouver un lieu pour la prochaine réunion». Par conséquent, il est extrêmement important de collecter suffisamment de données de formation pour que le système reconnaisse davantage ces options. Les NLI existants adhèrent généralement au principe du «meilleur possible» dans la collecte de données. Par exemple, l'analogue le plus proche de notre méthodologie de comparaison des commandes NL avec les appels d'API utilise le concept IF-This-Then-That (IFTTT) - «si c'est le cas, alors alors» (figure 1). Les données de formation proviennent directement du site Web de l'IFTTT.
Cependant, si l'API n'est pas prise en charge ou n'est pas entièrement prise en charge, il n'y a aucun moyen de résoudre la situation. De plus, les données d'entraînement collectées de cette manière ne sont pas applicables pour prendre en charge des commandes avancées avec plusieurs paramètres. Par exemple, nous avons analysé les journaux d'appels de l'API Microsoft anonymisés pour rechercher des e-mails pour le mois et avons constaté qu'environ 90% d'entre eux utilisent deux ou trois paramètres (environ le même montant), et ces paramètres sont assez divers. Par conséquent, nous nous efforçons de fournir une prise en charge complète du paramétrage de l'API et d'implémenter des commandes NL avancées. Le problème du déploiement d'un processus actif et personnalisable de collecte de données de formation pour une API spécifique reste actuellement non résolu.
Les problèmes d'utilisation de NLI en combinaison avec d'autres représentations formalisées, telles que les bases de données relationnelles, les bases de connaissances et les tables Web, ont été assez bien résolus, alors que presque aucune attention n'a été accordée au développement de NLI pour les API Web. Nous proposons la première plateforme complète (framework) qui vous permet de créer NL2API pour une API web spécifique à partir de zéro. Dans l'implémentation de l'API web, notre framework comprend trois étapes: (1) Présentation. Le format original de l'API Web HTTP contient de nombreux détails redondants et, par conséquent, distrayants du point de vue de la NLI.
Nous suggérons d'utiliser une représentation sémantique intermédiaire pour l'API web, afin de ne pas surcharger le NLI avec des informations inutiles. (2) Un ensemble de données d'entraînement. Nous proposons une nouvelle approche pour obtenir des données d'entraînement contrôlées basées sur le crowdsourcing. (3) NL2API. Nous proposons également deux modèles NL2API: un modèle d'extraction basé sur le langage et un modèle de réseau de neurones récurrent (Seq2Seq).
L'un des principaux résultats techniques de ce travail est une approche fondamentalement nouvelle de la collecte active des données de formation pour NL2API basée sur le crowdsourcing - nous utilisons des cadres distants pour annoter les appels d'API lors de leur comparaison avec les commandes NL. Cela vous permet d'atteindre trois objectifs de conception en fournissant: (1) la personnalisation. Vous devez pouvoir spécifier les paramètres pour quelle API utiliser et la quantité de données de formation à collecter. (2) Faible coût. Les services des travailleurs du crowdsourcing sont d'un ordre de grandeur moins chers que les services de spécialistes spécialisés, c'est pourquoi ils devraient être embauchés. (3) Haute qualité. La qualité des données de formation ne doit pas être réduite.
Lors de la conception de cette approche, deux problèmes principaux se posent. Tout d'abord, les appels d'API avec paramétrage avancé, comme dans la figure 1, sont incompréhensibles pour l'utilisateur moyen, vous devez donc décider comment formuler le problème d'annotation afin que les employés de crowdsourcing puissent facilement y faire face. Nous commençons par développer une représentation sémantique intermédiaire pour l'API web (voir section 2.2), qui nous permet de générer de manière transparente des appels API avec les paramètres requis.
Ensuite, nous réfléchissons à la grammaire pour convertir automatiquement chaque appel d'API en une commande NL canonique, ce qui peut être assez lourd, mais cela sera clair pour l'employé moyen de crowdsourcing (voir section 3.1). Les interprètes n'auront qu'à reformuler l'équipe canonique pour la rendre plus naturelle. Cette approche vous permet d'éviter de nombreuses erreurs dans la collecte des données de formation, car la tâche de reformulation est beaucoup plus simple et plus compréhensible pour l'employé moyen du crowdsourcing.
Deuxièmement, vous devez comprendre comment définir et annoter uniquement les appels d'API qui ont une réelle valeur pour l'apprentissage de NL2API. L '«explosion combinatoire» qui survient lors du paramétrage conduit au fait que le nombre d'appels, même pour une API, peut être assez important. Il n'est pas logique d'annoter tous les appels. Nous proposons un modèle probabiliste hiérarchique fondamentalement nouveau pour la mise en œuvre du processus de crowdsourcing (voir section 3.2). Par analogie avec la modélisation de langage dans le but d'obtenir des informations, nous supposons que les commandes NL sont générées sur la base des appels d'API correspondants, donc le modèle de langage doit être utilisé pour chaque appel d'API pour enregistrer ce processus «génératif».
Notre modèle est basé sur la nature compositionnelle des appels API ou des représentations formalisées de la structure sémantique dans son ensemble. Sur un plan intuitif, si un appel API se compose d'appels plus simples (par exemple, "courriels non lus sur un candidat au diplôme en sciences" = "courriels non lus" + "courriels pour un candidat au diplôme en sciences", nous pouvons le créer modèle de langage à partir d'appels d'API simples même sans annotation, par conséquent, en annotant un petit nombre d'appels d'API, nous pouvons calculer le modèle de langage pour tout le monde.
Bien sûr, les modèles de langage calculés sont loin d'être idéaux, sinon nous aurions déjà résolu le problème de la création de NL2API. Néanmoins, une telle extrapolation du modèle de langage aux appels d'API non annotés nous donne une vue holistique de tout l'espace des appels d'API, ainsi que l'interaction du langage naturel et des appels d'API, ce qui nous permet d'optimiser le processus de crowdsourcing. Dans la section 3.3, nous décrivons un algorithme d'annotation sélective des appels d'API pour aider à rendre les appels d'API plus faciles à distinguer, c'est-à-dire pour maximiser l'écart entre leurs modèles de langage.
Nous appliquons notre framework à deux API déployées à partir du package Microsoft Graph API2. Nous démontrons que des données de formation de haute qualité peuvent être collectées à un coût minimal si l'approche proposée est utilisée3. Nous montrons également que notre approche améliore le crowdsourcing. À des coûts similaires, nous collectons de meilleures données d'entraînement, dépassant considérablement la ligne de base. En conséquence, nos solutions NL2API offrent une plus grande précision.
En général, notre principale contribution comprend trois aspects:
- Nous avons été l'un des premiers à étudier les problèmes de NL2API et avons proposé un cadre complet pour créer NL2API à partir de zéro.
- Nous avons proposé une approche unique pour la collecte de données de formation à l'aide du crowdsourcing et un modèle probabiliste hiérarchique fondamentalement nouveau pour optimiser ce processus.
- Nous avons appliqué notre cadre à de véritables API Web et démontré qu'une solution NL2API suffisamment efficace peut être créée à partir de zéro.
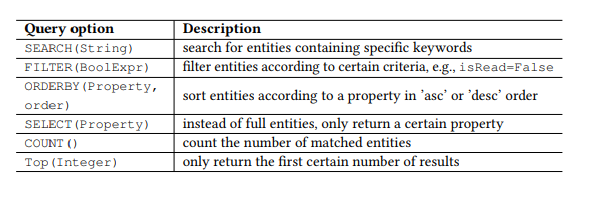 Tableau 1. Paramètres de requête OData.
Tableau 1. Paramètres de requête OData.Préambule
API RESTful
Récemment, les API Web conformes au style architectural REST, c'est-à-dire l'API RESTful, deviennent de plus en plus populaires en raison de leur simplicité. Les API RESTful sont également utilisées sur les smartphones et les appareils IoT. Les API Restful fonctionnent avec des ressources adressées via des URI et fournissent un accès à ces ressources à un large éventail de clients à l'aide de commandes HTTP simples: GET, PUT, POST, etc. Nous travaillerons principalement avec l'API RESTful, mais les méthodes de base peuvent être utilisées et d'autres API.
Par exemple, prenez le populaire Open Data Protocol (OData) pour l'API RESTful et deux API Web du package Microsoft Graph API (Figure 1), qui, respectivement, sont utilisés pour rechercher des e-mails et des événements de calendrier utilisateur. Les ressources dans OData sont des entités, chacune étant associée à une liste de propriétés. Par exemple, l'entité Message - un e-mail - possède des propriétés telles que subject (sujet), from (from), isRead (read), receivedDateTime (date et heure de réception), etc.
De plus, OData définit un ensemble de paramètres de requête, vous permettant d'effectuer des manipulations avancées sur les ressources. Par exemple, le paramètre FILTER vous permet de rechercher des e-mails d'un expéditeur spécifique ou des lettres reçues à une date spécifique. Les paramètres de requête que nous utiliserons sont présentés dans le tableau 1. Nous appelons chaque combinaison de la commande HTTP et de l'entité (ou ensemble d'entités) en tant qu'API, par exemple, GET-Messages - pour rechercher des e-mails. Toute demande paramétrée, par exemple, FILTER (isRead = False), est appelée paramètre, et un appel d'API est une API avec une liste de paramètres.
NL2API
La tâche principale de NLI est de comparer une déclaration (une commande dans un langage naturel) avec une certaine représentation formalisée, par exemple, des formes logiques ou des requêtes SPARQL pour des bases de connaissances ou des API web dans notre cas. Lorsqu'il est nécessaire de se concentrer sur la cartographie sémantique sans être distrait par des détails non pertinents, une représentation sémantique intermédiaire est généralement utilisée afin de ne pas travailler directement avec la cible. Par exemple, la grammaire catégorielle combinatoire est largement utilisée pour créer des NLI pour des bases de données et des bases de connaissances. Une approche similaire de l'abstraction est également très importante pour NL2API. De nombreux détails, notamment les conventions d'URL, les en-têtes HTTP et les codes de réponse, peuvent «distraire» le NL2API de la résolution du problème principal - le mappage sémantique.
Par conséquent, nous créons une vue intermédiaire pour les API RESTful (figure 2) avec le nom API frame; cette vue reflète la sémantique du cadre. Le cadre API se compose de cinq parties. Le verbe HTTP (commande HTTP) et la ressource sont les éléments de base d'une API RESTful. Le type de retour vous permet de créer des API composites, c'est-à-dire de combiner plusieurs appels d'API pour effectuer une opération plus complexe. Les paramètres obligatoires sont le plus souvent utilisés dans les appels PUT ou POST dans l'API, par exemple, l'adresse, l'en-tête et le corps du message sont des paramètres requis pour l'envoi d'e-mails. Les paramètres facultatifs sont souvent présents dans les appels GET dans l'API, ils aident à affiner la demande d'informations.
Si les paramètres requis sont manquants, nous sérialisons la trame API, par exemple: GET-messages {FILTER (isRead = False), SEARCH ("PhD application"), COUNT ()}. Une trame API peut être déterministe et convertie en un véritable appel API. Au cours du processus de conversion, les données contextuelles nécessaires seront ajoutées, y compris l'ID utilisateur, l'emplacement, la date et l'heure. Dans le deuxième exemple (figure 1), la valeur now dans le paramètre FILTER sera remplacée par la date et l'heure d'exécution de la commande correspondante lors de la conversion de la trame API en un véritable appel API. De plus, les concepts de trame API et d'appel API seront utilisés de manière interchangeable.
 Figure 2. Le cadre API. Ci-dessus: équipe de langage naturel. Au milieu: API Frame. En bas: appel API.
Figure 2. Le cadre API. Ci-dessus: équipe de langage naturel. Au milieu: API Frame. En bas: appel API.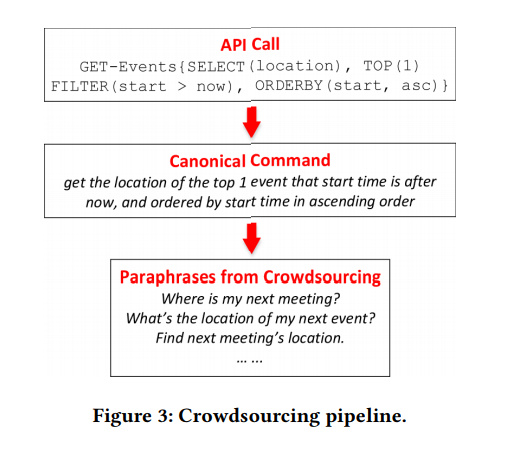 3. .
3. .NL2API . API , ( 3.1), ( 3). API, ( 3.2), ( 3.3).
 4. . : . : .
4. . : . : .API
API API. , , API, API . , Boolean, (True/False).
, Datetime, , today this_week receivedDateTime. , API (, ) API API.
, API . . , TOP, ORDERBY. , Boolean, isRead, ORDERBY . « » API API.
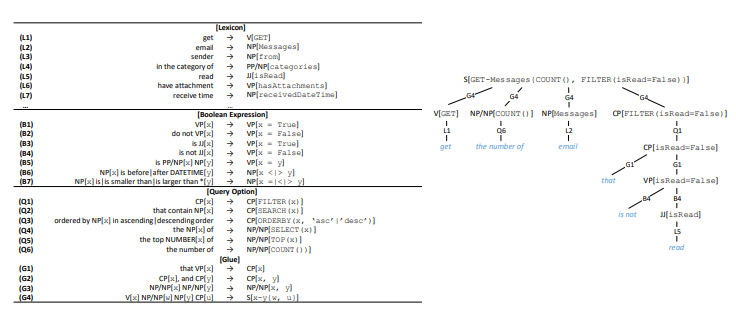
API. API . API API ( 4). ( HTTP, , ). , ⟨sender → NP[from]⟩ , from «sender», — (NP), .
(V), (VP), (JJ), - (CP), , (NP/NP), (PP/NP), (S) . .
, API , RESTful API OData — « » . 17 4 API, ( 5).
, API. ⟨t1, t2, ..., tn → c[z]⟩,
, z API, cz — . 4. API , S, G4, API . C , , - «that is not read».
, . , VP[x = False] B2, B4, x. x VP, B2 (, x is hasAttachments → «do not have attachment»); JJ, B4 (, x is isRead → «is not read»). («do not read» or «is not have attachment») .
Nous pouvons générer un grand nombre d'appels d'API en utilisant l'approche ci-dessus, mais annoter tous en utilisant le crowdsourcing n'est pas économiquement faisable. Par conséquent, nous proposons un modèle probabiliste hiérarchique pour le crowdsourcing qui vous aide à décider quels appels API doivent être annotés. À notre connaissance, il s'agit du premier modèle probabiliste d'utilisation du crowdsourcing pour créer des interfaces NLI, ce qui nous permet de résoudre la tâche unique et intrigante de modéliser l'interaction entre les représentations du langage naturel et les représentations de structure sémantique formalisées. Les représentations formalisées de la structure sémantique en général et les appels API en particulier sont de nature compositionnelle. Par exemple, z12 = GET-Messages {COUNT (), FILTER (isRead = False)} se compose de z1 = GET-Messages {FILTER (isRead = False)} et z2 = GET-Messages {COUNT ()} (ces exemples sont plus détaillés discuter davantage).
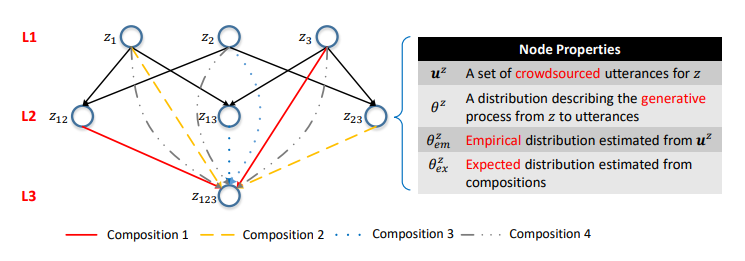 Figure 5. Le réseau sémantique. La ième couche se compose d'appels API avec i paramètres. Les côtes sont des compositions. Les distributions de probabilité aux sommets caractérisent les modèles de langage correspondants.
Figure 5. Le réseau sémantique. La ième couche se compose d'appels API avec i paramètres. Les côtes sont des compositions. Les distributions de probabilité aux sommets caractérisent les modèles de langage correspondants.L'un des principaux résultats de notre étude a été la confirmation qu'une telle compositionnalité peut être utilisée pour modéliser le processus de crowdsourcing.
Tout d'abord, nous définissons la composition en fonction d'un ensemble de paramètres d'appel API.
Définition 3.1 (composition). Prendre une API et un ensemble d'appels d'API
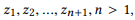
si nous définissons r (z) comme un ensemble de paramètres pour z, alors
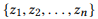
est une composition
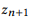
si et seulement si
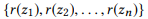
fait partie
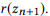
En fonction des relations de composition des appels d'API, vous pouvez organiser tous les appels d'API dans une seule structure hiérarchique. Les appels d'API avec le même nombre de paramètres sont représentés comme les sommets d'une couche et les compositions sont représentées comme
côtes dirigées entre les couches. Nous appelons cette structure un réseau sémantique (ou SeMesh).
Par analogie avec l'approche basée sur la modélisation du langage dans la recherche d'informations, nous supposons que les déclarations correspondant à un appel API z sont générées à l'aide d'un processus stochastique caractérisé par un modèle de langage
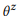
. Afin de simplifier, nous nous concentrons sur les probabilités des mots, donc

où
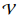
désigne un dictionnaire.
Pour des raisons qui apparaîtront un peu plus tard, au lieu du modèle unigramme de langage standard, nous suggérons d'utiliser un ensemble de distributions de Bernoulli (Bag of Bernoulli, BoB). Chaque distribution de Bernoulli correspond à une variable aléatoire W, déterminant si le mot w apparaît dans la phrase générée sur la base de z, et la distribution BoB est un ensemble de distributions de Bernoulli pour tous les mots

. Nous utiliserons
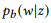
comme une courte notation pour
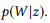
.
Supposons que nous avons formé un (multi) ensemble d'instructions

pour z,
l'estimation du maximum de vraisemblance (MLE) pour la distribution BoB vous permet de sélectionner des instructions contenant w:
 Exemple 2.
Exemple 2. Concernant l'appel API ci-dessus z1, supposons que nous ayons deux instructions u1 = "trouver les e-mails non lus" et u2 = "e-mails qui ne sont pas lus", puis u = {u1, u2}. pb ("emails" | z) = 1.0, car "emails" est présent dans les deux instructions. De même, pb ("non lu" | z) = 0,5 et pb ("meeting" | z) = 0,0.
Dans le réseau sémantique, il existe trois opérations de base au niveau du sommet:
Annotation, mise en page et interpolation.
ANNOTER (annoter) signifie collecter des relevés
pour paraphraser la commande canonique du sommet z en utilisant le crowdsourcing et évaluer la distribution empirique
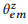
méthode du maximum de vraisemblance.
COMPOSE (compose) essaie de dériver un modèle de langage basé sur des compositions pour calculer la distribution attendue
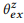
. Comme nous le montrons expérimentalement,
Est une composition pour z. Si nous partons de l'hypothèse que les énoncés correspondants sont caractérisés par la même connexion de composition, alors
devrait être présenté sur

:

où f est une fonction de composition. Pour la distribution BoB, la fonction de composition ressemblera à ceci:
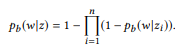
En d'autres termes, si ui est une instruction zi, u est une instruction
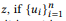
forme u, alors le mot w n'appartient pas à u. Si et seulement si elle n'appartient à aucune interface utilisateur. Lorsque z a de nombreuses compositions, θe x est calculé séparément puis moyenné. Le modèle unigramme de langage standard ne conduit pas à une fonction de composition naturelle. Dans le processus de normalisation des probabilités de mots, la longueur des phrases est impliquée, ce qui, à son tour, prend en compte la complexité des appels API, violant la décomposition dans l'équation (2). C'est pourquoi nous proposons la distribution BoB.
Exemple 3. Supposons que nous ayons préparé une annotation pour les appels d'API mentionnés précédemment z1 et z2, chacun ayant deux instructions:
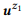
= {"Rechercher les e-mails non lus", "les e-mails non lus"} et
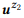
= {"Combien d'e-mails ai-je", "trouver le nombre d'e-mails"}. Nous avons évalué les modèles linguistiques
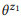
et
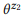
. L'opération de composition tente d'évaluer
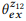
sans demander
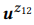
. Par exemple, pour le mot «emails», pb («emails» | z1) = 1.0 et pb («emails» | z2) = 1.0, il résulte donc de l'équation (3) que pb («emails» | z12) = 1.0, c'est-à-dire que nous pensons que ce mot sera inclus dans toute déclaration de z12. De même, pb ("find" | z1) = 0,5 et pb ("find" | z2) = 0,5, donc pb ("find" | z12) = 0,75. Un mot a de bonnes chances d'être généré à partir de n'importe quel z1 ou z2, donc sa probabilité pour z12 devrait être plus élevée.
Bien sûr, les déclarations ne sont pas toujours combinées de façon compositionnelle. Par exemple, plusieurs éléments d'une représentation formalisée d'une structure sémantique peuvent être véhiculés en un seul mot ou une phrase dans un langage naturel, ce phénomène est appelé compositionnalité sublexique. Un tel exemple est illustré à la figure 3, où les trois paramètres - TOP (1), FILTER (début> maintenant) et ORDERBY (début, asc) - sont représentés par le seul mot «suivant». Cependant, il est impossible d'obtenir de telles informations sans annoter l'appel API, donc le problème lui-même ressemble au problème du poulet et des œufs. En l'absence de telles informations, il est raisonnable d'adhérer à l'hypothèse par défaut selon laquelle les instructions sont caractérisées par la même relation de composition que les appels d'API.
Il s'agit d'une hypothèse plausible. Il convient de noter que cette hypothèse n'est utilisée que pour modéliser le processus de crowdsourcing dans le but de collecter des données. Au stade des tests, les déclarations d'utilisateurs réels peuvent ne pas correspondre à cette hypothèse. L'interface en langage naturel sera en mesure de faire face à de telles situations non compositionnelles si elles sont couvertes par les données de formation collectées.
INTERPOLER (interpolation) combine toutes les informations disponibles sur z, c'est-à-dire les énoncés annotés z et les informations obtenues à partir des compositions, et obtient une estimation plus précise
par interpolation
et
.
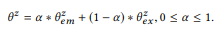
Le paramètre d'équilibre α contrôle les compromis entre les annotations
les pics actuels qui sont précis mais suffisants, et les informations obtenues à partir des compositions basées sur l'hypothèse de composition peuvent ne pas être aussi précises, mais elles offrent une couverture plus large. Dans un sens,
sert le même objectif que l'anti-aliasing dans la modélisation du langage, ce qui permet une meilleure estimation de la distribution de probabilité avec des données insuffisantes (annotations). Plus que
plus il y a de poids
. Pour un sommet racine sans composition,
=
. Pour un haut non annoté
=
.
Ensuite, nous décrivons l'algorithme de mise à jour du réseau sémantique, c'est-à-dire les calculs
pour tout z (algorithme 1), même si seule une petite partie des sommets a été annotée. Nous supposons que la valeur
Déjà mis à jour pour tous les sites annotés. En descendant de haut en bas, nous calculons séquentiellement
et
pour chaque sommet z. Vous devez d'abord mettre à jour les couches supérieures afin de pouvoir calculer la distribution attendue des sommets du niveau inférieur. Nous avons annoté tous les sommets racine, afin de pouvoir calculer
pour tous les sommets.
Algorithme 1. Mettre à jour les distributions de nœuds du maillage sémantique
3.3 Optimisation du crowdsourcing
Le réseau sémantique forme une vue holistique de tout l'espace des appels API, ainsi que de l'interaction des déclarations et des appels. Sur la base de cette vue, nous pouvons annoter de manière sélective uniquement un sous-ensemble d'appels d'API de grande valeur. Dans cette section, nous décrivons notre stratégie de distribution différentielle pour optimiser le crowdsourcing.
Considérons un réseau sémantique avec plusieurs sommets Z. Notre tâche est de déterminer un sous-ensemble de sommets dans le processus itératif
à annoter par les travailleurs du crowdsourcing. Les sommets annotés précédemment seront appelés l'état d'état,
alors nous devons trouver la politique politique

pour évaluer chaque sommet non annoté en fonction de l'état actuel.
Avant de plonger dans la discussion des approches de calcul des politiques efficaces, supposons que nous en ayons déjà une et donnons une description de haut niveau de notre algorithme de crowdsourcing (algorithme 2) pour décrire les méthodes d'accompagnement. Plus précisément, nous annotons d'abord tous les sommets racine afin d'évaluer la distribution de tous les sommets en Z (ligne 3). À chaque itération, nous mettons à jour la distribution des sommets (ligne 5), calculons
une politique basée sur l'état actuel du réseau sémantique (ligne 6), sélectionnez le sommet non annoté avec la note maximale (ligne 7), et annotez le sommet et le résultat dans le nouvel état (ligne 8). En termes pratiques, vous pouvez annoter plusieurs sommets dans le cadre d'une itération pour augmenter l'efficacité.
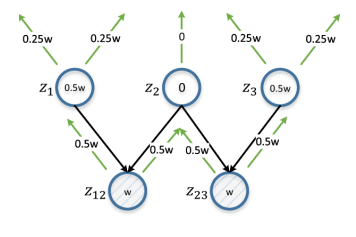 Figure 6. Distribution différentielle. z12 et z23 représentent la paire de sommets étudiés. w est une estimation calculée sur la base de d (z12, z23), et se propage de façon itérative de bas en haut, doublée à chaque itération. L'estimation pour le sommet sera la différence absolue de ses estimations de z12 et z23 (donc différentielle). z2 obtient un score de 0 car il s'agit de l'entité parente commune pour z12 et z23; dans ce cas, l'annotation sera de peu d'utilité pour garantir la distinction entre z12 et z23.
Figure 6. Distribution différentielle. z12 et z23 représentent la paire de sommets étudiés. w est une estimation calculée sur la base de d (z12, z23), et se propage de façon itérative de bas en haut, doublée à chaque itération. L'estimation pour le sommet sera la différence absolue de ses estimations de z12 et z23 (donc différentielle). z2 obtient un score de 0 car il s'agit de l'entité parente commune pour z12 et z23; dans ce cas, l'annotation sera de peu d'utilité pour garantir la distinction entre z12 et z23.Dans un sens large, les tâches que nous résolvons peuvent être attribuées au problème de l'apprentissage actif, nous nous sommes fixé pour objectif d'identifier un sous-ensemble d'exemples d'annotation afin d'obtenir un ensemble de formation pouvant améliorer les résultats d'apprentissage. Cependant, plusieurs différences clés ne permettent pas l'application directe de méthodes classiques d'enseignement actif, telles que «l'incertitude d'échantillonnage». Habituellement, dans le processus d'apprentissage actif, l'étudiant, qui dans notre cas serait l'interface NLI, essaie d'étudier le mappage f: X → Y, où X est l'échantillon d'espace d'entrée, composé d'un petit ensemble d'échantillons marqués et d'un grand nombre d'échantillons non marqués, et Y est généralement un ensemble de marqueurs classe.
L'élève évalue la valeur informative des exemples non étiquetés et sélectionne le plus informatif pour obtenir une note Y de la part des travailleurs du crowdsourcing. Mais dans le cadre du problème que nous résolvons, le problème d'annotation se pose différemment. Nous devons sélectionner une instance dans Y, un grand espace d'appel API, et demander aux travailleurs du crowdsourcing de l'étiqueter en spécifiant des modèles dans X, l'espace de la phrase. De plus, nous ne sommes pas liés à un stagiaire particulier. Ainsi, nous proposons une nouvelle solution au problème en question. Nous nous inspirons de nombreuses sources sur l'apprentissage actif.
Tout d'abord, nous déterminons l'objectif, sur la base duquel le contenu informationnel des nœuds sera évalué. De toute évidence, nous voulons que les différents appels d'API puissent être distingués. Dans le réseau sémantique, cela signifie que la distribution
différents pics ont des différences évidentes. Pour commencer, nous présentons chaque distribution
comme un vecteur à n dimensions

où n = |
| - la taille du dictionnaire. Par une certaine métrique de la distance vectorielle d (dans nos expériences, nous utilisons la distance entre les vecteurs pL1), nous entendons

c'est-à-dire que la distance entre deux sommets est égale à la distance entre leurs distributions.
L'objectif évident est de maximiser la distance totale entre toutes les paires de sommets. Cependant, l'optimisation de toutes les distances par paires peut être trop compliquée pour les calculs, et même cela n'est pas nécessaire. Une paire de pics distants a déjà suffisamment de différences, donc une nouvelle augmentation de la distance n'a pas de sens. Au lieu de cela, nous pouvons nous concentrer sur les paires de sommets qui causent le plus de confusion, c'est-à-dire que la distance entre eux est la plus petite.
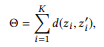
où
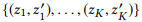
pointe vers les K premières paires de sommets si nous classons toutes les paires de nœuds par distance dans l'ordre croissant.
Algorithme 2. Annoter itérativement un maillage sémantique avec une politique Algorithme 3. Politique de calcul basée sur la propagation diférentielle
Algorithme 3. Politique de calcul basée sur la propagation diférentielle Algorithme 4. Propagation récursive d'un score d'un nœud source à tous ses nœuds parents
Algorithme 4. Propagation récursive d'un score d'un nœud source à tous ses nœuds parents
Les sommets avec un contenu d'informations plus élevé après l'annotation augmentent potentiellement la valeur de Θ. Pour la quantification dans ce cas, nous proposons d'utiliser une stratégie de distribution différentielle. Si la distance entre une paire de sommets est petite, nous examinons tous leurs sommets parents: si le sommet parent est commun pour une paire de sommets, il devrait obtenir une note faible, car l'annotation entraînera des changements similaires pour les deux sommets.
Sinon, le sommet doit être hautement coté, et plus la paire de sommets est proche, plus la cote est élevée. Par exemple, si la distance entre les sommets des «e-mails non lus sur l'application PhD» et «combien d'e-mails concernent l'application PhD» est petite, l'annotation de leur sommet parent «e-mails sur l'application PhD» n'a pas beaucoup de sens du point de vue de la distinction de ces sommets. Il est plus conseillé d'annoter les nœuds parents qui ne leur seront pas communs: «emails non lus» et «combien d'emails».
Un exemple d'une telle situation est illustré à la figure 6, et son algorithme est l'algorithme 3. Comme estimation, nous prenons l'inverse de la distance du nœud délimitée par une constante (ligne 6), de sorte que les paires de sommets les plus proches ont le plus grand impact. Lorsque nous travaillons avec une paire de sommets, nous attribuons simultanément une évaluation de chaque sommet à tous ses sommets parents (ligne 9, 10 et algorithme 4). Une estimation d'un sommet non annoté est la différence absolue dans les estimations de la paire de sommets correspondante avec sommation sur toutes les paires de sommets (ligne 12).
Interface en langage naturel
Pour évaluer le cadre proposé, il est nécessaire de former les modèles NL2API à l'aide des données collectées. Pour le moment, le modèle NL2API fini n'est pas disponible, mais nous adaptons deux modèles NLI testés dans d'autres domaines afin de les appliquer à l'API.
Modèle d'extraction du modèle de langage
Sur la base des développements récents dans le domaine du NLI pour les bases de connaissances, nous pouvons envisager la création du NL2API dans le contexte du problème de l'extraction d'informations afin d'adapter le modèle d'extraction basé sur le modèle de langage (LM) à nos conditions.
Pour dire u, vous devez trouver un appel API z dans le réseau sémantique avec la meilleure correspondance pour u. Nous transformons d'abord la distribution de BoB

chaque appel de l'API z au modèle unigramme de langage:
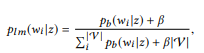
où nous utilisons le lissage additif, et 0 ≤ β ≤ 1 est le paramètre de lissage. Valeur plus élevée
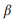
, plus le poids des mots qui n'ont pas encore été analysés est important. Les appels API peuvent être classés par leur probabilité logarithmique:
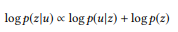
(soumis à une distribution de probabilité a priori uniforme)
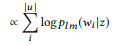
L'appel d'API le mieux noté est utilisé comme résultat de simulation.
Module de reformulation Seq2Seq
Les réseaux de neurones sont de plus en plus répandus en tant que modèles pour NLI, tandis que le modèle Seq2Seq est meilleur que les autres à cet effet, car il vous permet de traiter naturellement les séquences d'entrée et de sortie de longueurs variables. Nous adaptons ce modèle pour NL2API.
Pour la séquence d'entrée e

, le modèle estime la distribution de probabilité conditionnelle p (y | x) pour toutes les séquences de sortie possibles
. Les longueurs T et T 'peuvent varier et prendre n'importe quelle valeur. Dans NL2API, x est l'instruction de sortie. y peut être un appel d'API sérialisé ou sa commande canonique. Nous utiliserons des commandes canoniques comme séquences de sortie cibles, ce qui transforme en fait notre problème en un problème de reformulation.
Un codeur implémenté comme un réseau de neurones récurrents (RNN) avec des unités de récurrence contrôlée (GRU) représente d'abord x comme un vecteur de taille fixe,

où RN N est une brève représentation pour appliquer GRU à la séquence d'entrée entière, marqueur par marqueur, suivi de la sortie du dernier état caché.
Le décodeur, qui est également un RNN avec GRU, prend h0 comme état initial et traite la séquence de sortie y, marqueur par marqueur, pour générer une séquence d'états,

La couche de sortie prend chaque état du décodeur comme valeur d'entrée et génère une distribution de dictionnaire
comme valeur de sortie. Nous utilisons simplement la transformation affine suivie de la fonction logistique multi-variable softmax:
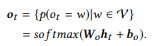
La probabilité conditionnelle finale, qui nous permet d'évaluer dans quelle mesure la commande canonique y reformule l'instruction d'entrée x, est

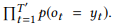
. Les appels API sont ensuite classés en fonction de la probabilité conditionnelle de leur commande canonique. Nous vous recommandons de vous familiariser avec la source, où le processus d'apprentissage du modèle est décrit plus en détail.
Expériences
Expérimentalement, nous étudions les sujets de recherche suivants: [PI1]: pouvons-nous utiliser le cadre proposé pour collecter des données de formation de haute qualité à un prix raisonnable? [PI2]: Le réseau sémantique fournit-il une évaluation plus précise des modèles de langage que l'évaluation du maximum de vraisemblance? [PI3]: Une stratégie de distribution différentielle améliore-t-elle l'efficacité du crowdsourcing?
Crowdsourcing
-API Microsoft — GET-Events GET-Messages — . API, API ( 3.1) . API 2. , Amazon Mechanical Turk. , API .
. API 10 , 10 . 201 , . 44 , 82 , 8,2 , , , . , 400 , 17,4 %.
(, ORDERBY a COUNT parameter) (, , ). . NLI. , , [1] . .
, , , , API (. 3). API . , . 61 API 157 GET-Messages, 77 API 190 GET-Events. , , API (, ) , , .
 2. API.
2. API. 3. : ().
3. : ()., , . , α = 0,3, LM β = 0,001. K, , 100 000. , , Seq2Seq — 500. ( ).
NLI, . .
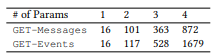
. , , . LM: , . , . ROOT — . TOP2 = ROOT + 2; TOP3 = TOP2 + 3. .
4. LM (MLE) ,
, . , , , MLE .
MLE,

,

- , . API . 16 API (ROOT) LM SeMesh Seq2Seq API (TOP2) , 500 API (TOP3).
, , , , ( 3.2) . , GET-Events , GET-Messages. , GET-Events
, , , .
 4. . LM, Seq2Seq, . , .
4. . LM, Seq2Seq, . , .LM + , ,
θem with
.
et
, , ROOT,
et
. , , . MLE. , , [2] .
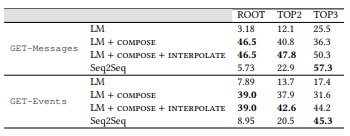
0,45 0,6: , NLI . , API. API (. 7) , RNN , . .
. : |u | α. - LM ( 7). , |u | < 10, 10 . GET-Events, GET-Messages .
, , , . , , . , α, ([0.1, 0.7]). α , , .
(DP) . API . 50 API, , NL2API .
, . LM, . . , ( 5.1), API .
7. .
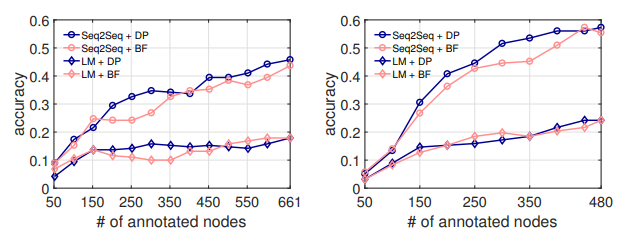
8. . : GET-Events. : GET-Messages
breadth first (BF), . . . API , API .
8. NL2API API DP . 300 API, Seq2Seq, DP 7 % API. , . , DP API, NL2API. , , [3] .
- . - (NLI) . NLI . , , . .
NLI , -, API . NL2API : API , - , . . API REST .
NLI. NLI « ». , Google Suggest API, API IFTTT. NLI, . , .
NLI, . NLI , . , , .
API . , -API. .
-API. , -API. , -API API, -API . NL2API , , API.
- -API (NL2API) NL2API . NL2API . : (1) . , , ? (2) .
? (3) NL2API. , API. (4) API. API? (5) : NL2API ?