Le modèle de machine à états finis (FSM) est utilisé pour écrire du code pour une grande variété de plates-formes, y compris Android. Il vous permet de rendre le code moins lourd, s'intègre bien dans le paradigme Model-View-Presenter (MVP) et se prête à des tests simples. Le développeur Vladislav Kuznetsov a expliqué à la Droid Party comment ce modèle aide au développement de l'application Yandex.Disk.
- Tout d'abord, parlons de théorie. Je pense que chacun de vous a entendu parler de MVP et de la machine d'état, mais nous allons le répéter.

Parlons de la motivation, expliquons pourquoi tout cela est nécessaire et comment cela peut nous aider. Passons à ce que nous avons fait, avec un exemple réel, je vais montrer des morceaux de code. Et à la fin, nous parlerons des tests, de la façon dont cette approche a aidé à tout tester facilement.
La machine d'état et MVP, ou quelque chose de similaire - probablement MVI - ont été utilisés par tout le monde.
Il y a beaucoup de machines d'état. Voici la définition la plus simple qui puisse leur être donnée: il s'agit d'une sorte d'abstraction mathématique, présentée sous la forme d'un ensemble fini d'états, d'événements et de transitions de l'état actuel vers un nouvel état en fonction de l'événement.
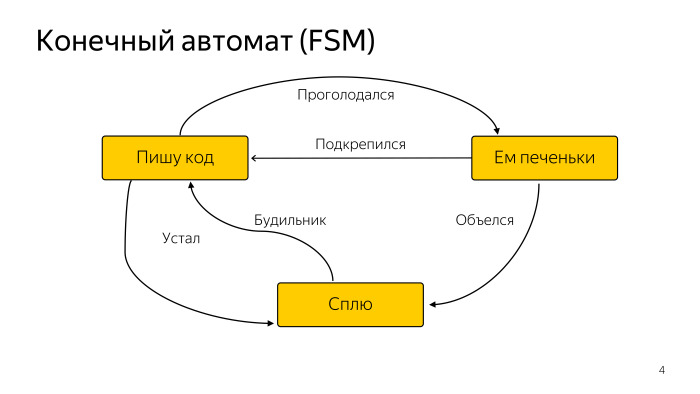
Voici un schéma simple d'un programmeur abstrait qui dort parfois, mange parfois, mais écrit principalement du code. Cela nous suffit. Il existe un grand nombre de variétés de machines à états finis, mais cela nous suffit.

La portée de la machine d'état est assez grande. Pour chaque élément, ils sont utilisés et appliqués avec succès.
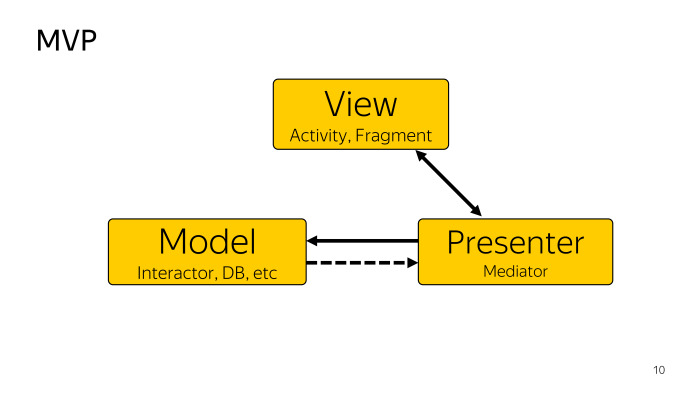
Comme toute approche, MVP divise notre application en plusieurs couches. Vue - le plus souvent une activité ou un fragment, dont la tâche est de transmettre une action à l'utilisateur, pour identifier le présentateur que l'utilisateur a fait quelque chose. Nous considérons Model comme un fournisseur de données. Cela peut être comme une base de données, si nous parlons d'architecture propre ou d'Interactor, tout peut l'être. Et Presenter est un intermédiaire qui connecte la vue et le modèle, tout en pouvant récupérer et mettre à jour la vue à partir du modèle. Cela nous suffit.
Qui peut dire en une phrase ce qu'est un programme? Code exécutable? Trop général, plus détaillé. Un algorithme? Un algorithme est une séquence d'actions.
Il s'agit d'un ensemble de données et d'une sorte de flux de contrôle. Peu importe qui manipule ces données: l'utilisateur ou non. Il s'ensuit que, à tout moment, l'état d'une application est déterminé par la totalité de toutes ses données. Et plus il y a de données dans l'application, plus il est difficile de les gérer, plus une situation imprévisible peut survenir en cas de problème.

Imaginez une classe simple avec trois drapeaux booléens. Pour vous assurer de couvrir tous les scénarios de combinaison de ces indicateurs, vous avez besoin de 2³ scénarios. Il est nécessaire de couvrir huit scénarios avec une garantie de dire que je traite toutes les combinaisons d'indicateurs à coup sûr. Si vous ajoutez un autre indicateur, il augmente proportionnellement.
Nous avons fait face à un problème similaire. Cela semblait être une tâche simple, mais au fur et à mesure que nous l'avons développée et travaillée, nous avons commencé à réaliser que quelque chose n'allait pas. Je vais parler des fonctionnalités que nous avons lancées. Cela s'appelle la suppression de photos locales. Le fait est que l'utilisateur télécharge certaines données dans le cloud en mode automatique. Il s'agit très probablement de photos et de vidéos qu'il a prises sur son téléphone. Il s'avère que les fichiers semblent être dans le cloud. Pourquoi occuper un espace précieux sur votre téléphone lorsque vous pouvez supprimer ces photos?

Les concepteurs ont dessiné un tel concept. Cela ressemble à un simple dialogue, il a un en-tête où la quantité d'espace que nous pouvons libérer est dessinée, le texte du message et une coche indiquant qu'il existe deux modes de nettoyage: supprimer toutes les photos que l'utilisateur a téléchargées, ou seulement celles qui ont plus d'un mois.

Nous avons regardé - il ne semble y avoir rien de compliqué. Boîte de dialogue, deux TextViews, case à cocher, boutons. Mais lorsque nous avons commencé à travailler sur ce problème en détail - nous avons réalisé que l'obtention de données sur le nombre de fichiers que nous pouvons supprimer est une tâche à long terme. Par conséquent, nous devons montrer à l'utilisateur une sorte de talon. Ceci est un pseudo code, dans la vraie vie, il semble différent, mais le sens est le même.
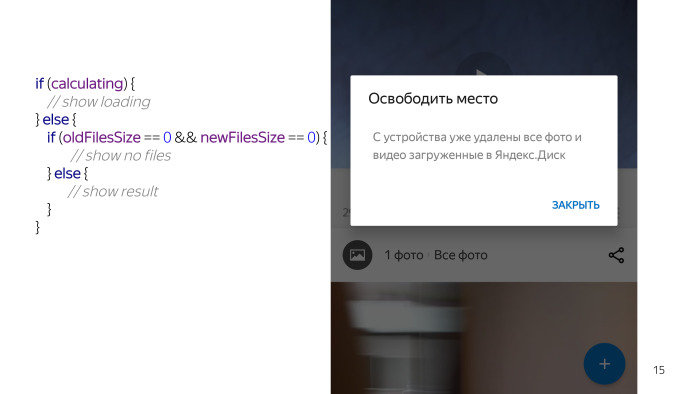
Nous vérifions un état, vérifions que nous calculons et dessinons une prise «Wait».

Une fois les calculs terminés, nous avons plusieurs options pour ce que l’utilisateur doit afficher. Par exemple, le nombre de fichiers que nous pouvons supprimer est zéro. Dans ce cas, nous envoyons un message à l'utilisateur qu'il n'y a rien à supprimer, alors venez la prochaine fois. Ensuite, les concepteurs viennent à nous et disent que nous devons distinguer les situations où l'utilisateur a déjà effacé les fichiers ou n'a rien effacé, rien chargé. Par conséquent, une autre condition apparaît que nous attendons le démarrage et lui dessinons un autre message.
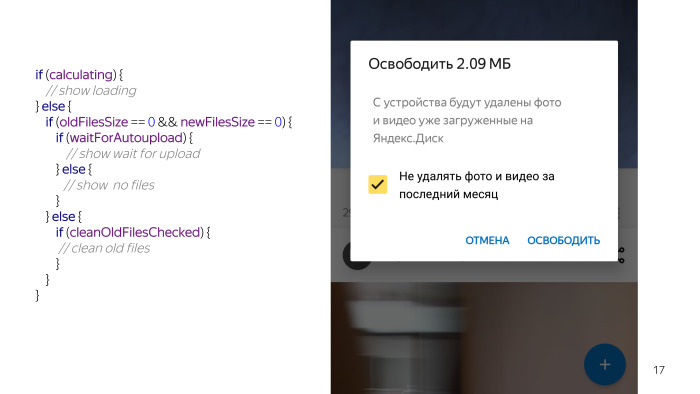
Ensuite, il y a des situations où quelque chose a quand même fonctionné, et par exemple, l'utilisateur a une coche pour ne pas supprimer les nouveaux fichiers. Dans ce cas, il existe également deux options. Soit les fichiers peuvent être nettoyés, soit les fichiers ne peuvent pas être nettoyés, c'est-à-dire qu'ils ont déjà effacé tous les fichiers, nous vous avertissons donc que vous avez déjà supprimé tous les nouveaux fichiers.
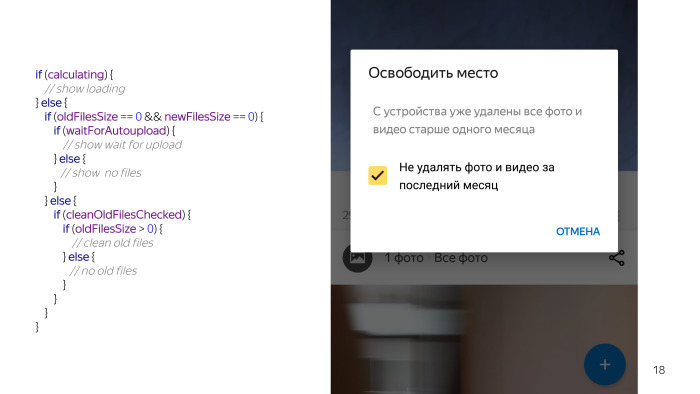
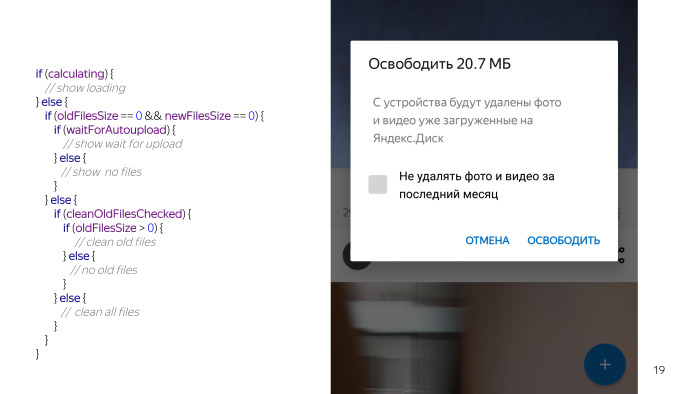
Il y a une autre condition quand nous pouvons vraiment supprimer quelque chose. Décoché, et il y a une option que vous pouvez supprimer quelque chose. Vous regardez ce code et il semble que quelque chose ne va pas. Je n'ai pas encore tout répertorié, nous avons une vérification permanente, car rien ne fonctionne sans eux, nous ne pouvons pas toucher les fichiers sur la carte, et nous devons également vérifier que l'utilisateur a activé le chargement automatique, car les fonctionnalités sont inutiles sans chargement automatique, ce que nous allons nettoyer. Et quelques autres conditions. Et putain, cela semble si simple, et tant de problèmes sont survenus à cause de cela.
Et évidemment, plusieurs problèmes se posent immédiatement. Tout d'abord, ce code est illisible. Ici, un certain pseudo-code est représenté, mais dans un projet réel, il est réparti sur différentes fonctions, morceaux de code, il n'est pas si facile à percevoir à l'œil nu. La prise en charge d'un tel code est également assez compliquée. Surtout quand vous arrivez à un nouveau projet, on vous dit que vous devez faire une telle fonctionnalité, vous ajoutez une condition, vérifiez un scénario positif, tout fonctionne, mais ensuite les testeurs viennent et disent que sous certaines conditions tout s'est cassé. Cela se produit parce que vous n'avez simplement pris en compte aucun scénario.
De plus, il est redondant dans le sens où, comme nous avons une large branche de conditions, nous devons vérifier à l'avance toutes les conditions qui ne nous conviennent pas. Ils sont négatifs à l'avance, mais comme ils sont écrits avec de telles branches, nous devons les vérifier. Le fait est que dans l'exemple, j'ai une sorte de drapeaux booléens, mais en pratique, vous pouvez avoir des appels à des fonctions qui vont quelque part plus profondément dans la base de données. Tout peut être, en raison de la redondance, il y aura des freins supplémentaires.
Et le plus triste est un comportement imprévu qui a été manqué pendant la phase de test, rien ne s'est passé là-bas, et quelque part dans la production, l'utilisateur ne s'est pas produit au mieux, une sorte de courbe d'interface utilisateur, et au pire - il est tombé ou les données ont été perdues . Seule l'application ne s'est pas comportée de manière cohérente.
Comment résoudre ce problème? Par la puissance de la machine d'état.

La tâche principale prise en charge par la machine d'état consiste à prendre une grande tâche complexe et à la diviser en petits états discrets plus faciles à interagir et à gérer. Après s'être assis, avoir réfléchi, puisque nous essayons de faire quelque chose de MVP, comment lier notre état à tout cela? Nous sommes arrivés à peu près à un tel schéma. Quiconque lit le livre GOF est un modèle d'état classique, juste ce qu'on appelle le contexte, je l'ai appelé un état-oner, et en fait c'est un présentateur. Le présentateur a cet état, sait comment les changer et peut toujours fournir des données à nos états s'il veut savoir quelque chose, par exemple, la taille du fichier ou s'il souhaite demander une demande asynchrone, sélectionnez.

Il n'y a rien de super-duper ici, la diapositive suivante est plus importante.
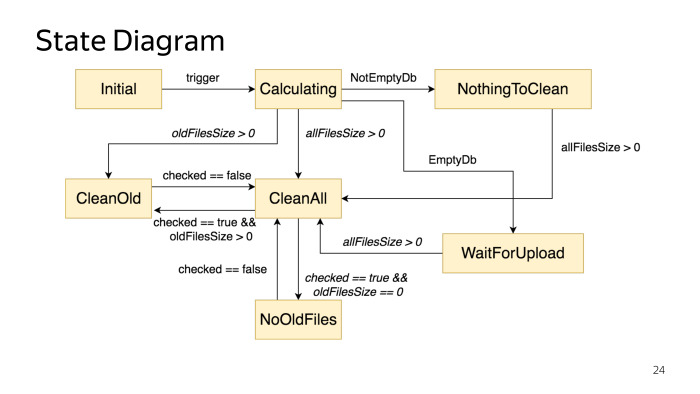
Avec cela, vous devez démarrer le développement lorsque vous commencez à créer une machine d'état. Vous êtes assis à votre ordinateur ou quelque part autour de la table, et sur un morceau de papier ou dans des outils spéciaux, dessinez un diagramme d'état. Il n'y a également rien de compliqué, mais cette étape présente de nombreux avantages. Premièrement, à un stade précoce, vous pouvez immédiatement détecter certaines incohérences dans la logique métier. Vos produits peuvent venir, exprimer leur désir, tout va bien, mais lorsque vous commencez à écrire du code, vous comprenez que quelque chose ne va pas ensemble. Je pense que tout le monde a eu une telle situation. Mais lorsque vous créez un diagramme, vous pouvez voir à un stade précoce que quelque chose n'est pas ancré. Il est dessiné tout simplement, il existe des outils spéciaux tels que PlantUML, dans lesquels vous n'avez même pas besoin de pouvoir dessiner, vous devez être capable d'écrire du pseudocode, et il génère lui-même des graphiques.
Notre graphique ressemble à ceci, qui décrit l'état de cette boîte de dialogue. Il y a plusieurs états et la logique de la transition entre eux.

Passons au code. Indiquez lui-même, il n'y a rien d'important, l'essentiel est qu'il dispose de trois méthodes: onEnter, qui, lors de la saisie, appelle d'abord invalidateView. Pourquoi est-ce fait? De sorte que dès que nous entrons dans l'état, l'interface utilisateur est mise à jour. De plus, il y a la méthode invalidateView, que nous surchargeons si nous devons faire quelque chose avec l'interface utilisateur, et la méthode onExit, dans laquelle nous pouvons faire quelque chose si nous quittons l'état.

StateOwner. Une interface qui offre la possibilité de cliquer sur l'état. Comme nous l'avons découvert, ce sera un futur présentateur. Et ce sont des méthodes qui fournissent un accès supplémentaire aux données. Si des données sont fouillées entre les états, nous pouvons les conserver dans le présentateur et les transmettre via cette interface. Dans ce cas, nous pouvons donner la taille des fichiers que nous pouvons nettoyer et donner la possibilité de faire une sorte de demande. Nous sommes dans un état, nous voulons demander quelque chose et via StateOwner nous pouvons appeler une méthode.
Une autre utilité de ce type est que lui aussi peut renvoyer un lien vers la vue. Ceci est fait de sorte que si vous avez un état et que certaines données arrivent, vous ne voulez pas passer à un nouvel état, c'est juste redondant, vous pouvez directement mettre à jour la vue, le texte. Nous l'utilisons afin de mettre à jour le nombre de chiffres que l'utilisateur voit lorsqu'il regarde le dialogue. Nous sommes en train de télécharger des fichiers à l'exécution, il regarde le dialogue et les chiffres sont mis à jour. Nous ne passons pas à un nouvel état, nous mettons simplement à jour la vue actuelle.

Voici le MVP standard, tout devrait être extrêmement simple, pas de logique, des méthodes simples qui dessinent quelque chose. J'adhère à ce concept. Il ne devrait y avoir aucune logique, au moins une sorte d'action. Nous prenons proprement une vue texte, changez-la, pas plus.

Présentateur Il y a des choses plus intéressantes. Tout d'abord, nous pouvons fouiller les données à travers elle pour certains états, nous avons deux variables marquées avec l'annotation State. Qui a utilisé Icepick le connaît. Nous n'écrivons pas la sérialisation avec nos mains en Partible, nous utilisons une bibliothèque prête à l'emploi.
Voici l'état initial. Il est toujours utile de définir l'état initial, même s'il ne fait rien. L'utilité est que vous n'avez pas besoin de faire de vérifications nulles, mais si nous disons que cela peut faire quelque chose. Par exemple, vous devez faire quelque chose une fois pour le cycle de vie de votre application, lorsque nous démarrons, vous devez exécuter la procédure une fois et ne plus jamais la refaire. Lorsque nous quittons l'état initial, nous pouvons toujours faire quelque chose comme ça, et nous ne revenons jamais à cet état. Tapez pour que le diagramme d'état soit dessiné. Bien que qui sache qui va dessiner, vous pouvez peut-être revenir.
Je suis en faveur de minimiser les contrôles pour Null et ainsi de suite, donc ici je garde un lien vers une implémentation de vue simple. Nous n'avons pas besoin de synchroniser quoi que ce soit, juste à un moment où le détachement se produit, nous remplaçons la vue par une vue vide, et le présentateur peut basculer quelque part dans les états, penser qu'il y a une vue, la mettre à jour, mais en fait cela fonctionne avec une implémentation vide.
Il existe plusieurs autres méthodes pour enregistrer l'état, mais nous voulons faire l'expérience du bouleversement de l'activité, dans ce cas, tout se fait via le constructeur. Tout est un peu plus compliqué, voici un exemple exagéré.

Il est nécessaire de transmettre saveState, si quelqu'un a travaillé avec des bibliothèques similaires, tout est assez trivial. Vous pouvez écrire avec vos mains. Et deux méthodes sont très importantes: attacher, appelé onStart, et détacher, appelé onStop.

Quelle est leur importance? Initialement, nous avions prévu d'attacher et de détacher dans onCreateView, onDestroyView, mais ce n'était pas tout à fait suffisant. Si vous avez une vue, votre texte peut être mis à jour ou un fragment de boîte de dialogue peut apparaître. Et si vous ne vous retrouvez pas sur onStop, puis essayez d'afficher le fragment, vous interceptez l'exception bien connue selon laquelle vous ne pouvez pas valider une transaction lorsque nous avons encore l'état. Soit utiliser commit state loss, soit ne pas le faire. Par conséquent, nous sommes détaillés dans onStop, tandis que le présentateur continuera à travailler là-bas, changer d'état, intercepter des événements. Et au moment où le démarrage se produit, nous déclencherons l'événement attaché à la vue, et le présentateur mettra à jour l'interface utilisateur pour correspondre à l'état actuel.


Il existe une méthode de libération, elle est généralement appelée dans onDestroy, vous effectuez un détachement et libérez également des ressources.

Une autre méthode setState importante. Puisque nous prévoyons de changer l'interface utilisateur dans onEnter et onExit, il y a une vérification pour le thread principal. Cela crée une restriction pour nous que nous ne faisons rien de lourd ici, toutes les demandes doivent être adressées à l'interface utilisateur ou doivent être asynchrones. L'avantage de cet endroit est qu'ici nous pouvons réserver l'entrée et la sortie de l'état, c'est très utile lors du débogage, par exemple, quand quelque chose ne va pas, vous pouvez voir comment le système a cliqué et comprendre ce qui n'allait pas.
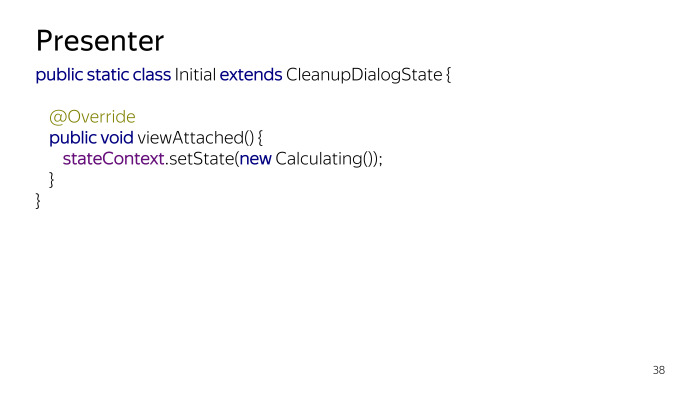
Quelques exemples de conditions. Il existe un état initial, il déclenche simplement le calcul de l'espace dont vous avez besoin pour libérer au moment où la vue est devenue disponible. Cela se produira après onStart. Dès que onStart se produit, nous entrons dans un nouvel état et le système commence à demander des données.

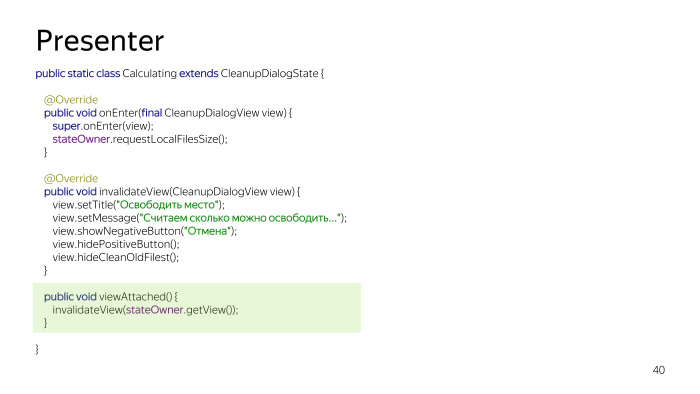
Un exemple de l'état est Calcul, nous indiquerons la taille des fichiers avec stateOwner, il rampe en quelque sorte dans la base de données, puis il y a toujours un inValidateView, nous mettons à jour l'interface utilisateur actuelle. Et viewAttached est appelé si la vue est rattachée. Si nous étions en arrière-plan, le calcul était en arrière-plan, nous retournons à nouveau à notre activité, cette méthode est appelée et met à jour toutes les données.

Un exemple d'événement, nous avons demandé à stateOwner combien de fichiers peuvent être libérés, et il appelle la méthode filesSizeUpdated. Ici, j'étais trop paresseux, il était possible d'écrire trois méthodes distinctes, telles que mises à jour, il y a autant d'anciens fichiers que de séparer différents événements. Mais vous devez comprendre, une fois que ce sera difficile pour vous, une fois que ce sera beaucoup plus simple. Il n'est pas nécessaire de tomber dans une ingénierie excessive pour que chaque événement soit une méthode distincte. Vous pouvez vous en tirer avec un simple si, je ne vois rien de mal à cela.

Je vois plusieurs améliorations potentielles. Je n'aime pas que nous soyons obligés de jeter nos mains autour de ces méthodes, telles que onStart, on Stop, onCreate, onSave, et plus encore. Vous pouvez vous attacher à Lifecycle, mais on ne sait pas quoi faire avec saveState. Il y a une idée, par exemple, pour faire un fragment de présentateur. Pourquoi pas? Un fragment sans interface utilisateur qui rattrape le cycle de vie, et en général alors nous n'aurons besoin de rien, tout volera jusqu'à nous par lui-même.
Un autre point intéressant: ce présentateur est recréé à chaque fois, et si vous avez des données volumineuses stockées dans le présentateur, vous êtes allé à la base de données, maintenez un énorme curseur, alors il est inacceptable de demander chaque fois que vous faites pivoter l'écran. Par conséquent, vous pouvez mettre en cache le présentateur, comme c'est le cas, par exemple, ViewModule à partir des composants d'architecture, créer un fragment qui contiendra le cache des présentateurs et les retourner pour chaque vue.
Vous pouvez utiliser la méthode tabulaire pour spécifier les machines à états, car le modèle d'état que nous utilisons présente un inconvénient important: dès que vous devez ajouter une méthode à un nouvel événement, vous devez ajouter l'implémentation à tous les descendants. Au moins vide. Ou faites-le dans un état de base. Ce n'est pas très pratique. Ainsi, la manière tabulaire de spécifier les machines à états est utilisée dans toutes les bibliothèques - si vous recherchez sur GitHub le mot FSM, vous trouverez un grand nombre de bibliothèques qui vous fournissent une sorte de générateur dans lequel vous définissez l'état initial, l'événement et l'état final. L'expansion et la maintenance d'une telle machine d'état sont beaucoup plus faciles.
Un autre point intéressant: si vous utilisez le modèle d'état, si votre machine d'état commence à se développer, vous devrez très probablement gérer certains événements de la même manière afin que le code ne se copie pas, vous créez un état de base. Plus il y a d'événements, plus les conditions de base commencent à apparaître, la hiérarchie se développe et quelque chose tourne mal.
Comme nous le savons, l'héritage doit être remplacé par la délégation, et les machines à états hiérarchiques aident à résoudre ce problème. Vous avez des états qui ne dépendent pas du niveau d'héritage - créez simplement un arbre d'états qui passe le gestionnaire ci-dessus. Vous pouvez également lire séparément, une chose très utile. Dans Android, par exemple, les machines à états hiérarchiques sont utilisées dans WatchDog Wi-Fi, qui surveille l'état du réseau, elles sont là, directement dans la source Android.

Dernier point mais non le moindre. Comment cela peut-il être testé? Tout d'abord, les états déterministes peuvent être testés. Il y a un état séparé, nous créons une instance, tirons la méthode onEnter et voyons que les valeurs correspondantes sont appelées dans la vue. Ainsi, nous validons que notre état met correctement à jour la vue. Si votre vue ne fait rien de grave, vous couvrirez très probablement un grand nombre de scénarios.

Vous pouvez verrouiller certaines méthodes avec une fonction qui renvoie la taille, appeler un autre événement après onEnter et voir comment un état particulier répond à des événements spécifiques. Dans ce cas, lorsque l'événement filesSizeUpdated se produit et lorsque AllFilesSize est supérieur à zéro, nous devons passer au nouvel état CleanAllFiles. Avec l'aide de la mise en page, nous vérifions tout cela.

Et le dernier - nous pouvons tester l'ensemble du système. Nous construisons l'état, lui envoyons un événement et vérifions le comportement du système. Nous avons trois étapes de test. , UI, , , , .
, 70%. 80% . , .

, ? — . - .
. . - , , - , — , .
- , , , . , , . , , . - , , . , , . lock . - , .
— . , , , , . , - , , -, , . , . , .