Du 19 au 21 avril, s'est tenue à Saint-Pétersbourg la conférence C ++ Russie 2018. D'année en année, l'organisation et la conduite deviennent d'un niveau supérieur, ce qui est une bonne nouvelle. Merci à l'organisateur permanent de C ++ Russie Sergey Platonov pour sa contribution au développement de ce domaine.
Le 19 avril, des master classes étaient prévues, auxquelles nous n'avons malheureusement pas pu assister, et le 20-21 a eu lieu le programme principal de la conférence, à laquelle nous avons participé avec un grand intérêt. Sergey
sermp a fait un excellent travail et a attiré plusieurs conférenciers étrangers remarquables comme conférenciers. Le premier jour de la conférence a été ouvert par Jon Kalb, l'organisateur de CppCon et auteur de C ++ Today: The Beast is Back. La deuxième journée a commencé par une présentation de Daveed Vandevoorde, membre du comité de normalisation, l'un des auteurs de C ++ Templates: The Complete Guide. Andrei Alexandrescu était au centre de l'attention, qui, après son rapport sur les exceptions, a à un moment donné rassemblé une foule de gens qui voulaient obtenir un autographe et prendre une photo commune. Pour la première fois, une conférence Herb Sutter a été diffusée sur Skype à propos de l'opérateur Spaceship pour C ++ 20.
Bien que la conférence ait eu lieu il y a plus de 3 mois, la vidéo (
playlist complète ) y a été publiée tout à l'heure, il est donc temps de vous rafraîchir la mémoire et de vous immerger dans les fonctionnalités incroyables de C ++.
Cette présentation explique pourquoi les ingénieurs à la recherche de performances choisissent C ++. Jon présente une perspective historique du C ++ en se concentrant sur ce qui se passe dans la communauté C ++ en ce moment et où le langage et sa base d'utilisateurs se dirigent. Avec un intérêt renouvelé pour les performances des centres de données et des appareils mobiles, et le succès des bibliothèques de logiciels open source, C ++ est de retour et il fait chaud. Cette présentation explique pourquoi C ++ est le langage de référence de la plupart des ingénieurs logiciels pour les performances. Vous recevrez un croquis historique approximatif qui met le C ++ en perspective et couvre ses hauts et ses bas de popularité.

Les paires d'itérateurs sont omniprésentes dans la bibliothèque C ++. Il est généralement admis que la combinaison d'une telle paire en une seule entité généralement appelée plage fournit un code plus concis et lisible. La définition de la sémantique précise d'un tel concept Range se révèle cependant étonnamment délicate. Les considérations théoriques entrent en conflit avec les considérations pratiques. Certains objectifs de conception sont totalement incompatibles.
Nous savons tous que nous devons connaître les algorithmes STL. Les inclure dans nos conceptions nous permet de rendre notre code plus expressif et plus robuste. Et parfois, de façon spectaculaire.
Mais connaissez-vous vos algorithmes STL?
Dans cet exposé, l'auteur présente 105 algorithmes que la STL possède actuellement, y compris ceux ajoutés en C ++ 11 et C ++ 17. Mais plus qu'une simple liste, l'objectif de cet exposé est de présenter les différents groupes d'algorithmes, les modèles qu'ils forment dans la STL et la façon dont les algorithmes sont liés.
Ce genre de vue d'ensemble est le meilleur moyen de se souvenir de tous, et constitue une boîte à outils remplie de façons de rendre notre code plus expressif et plus robuste.

Vous avez toujours voulu modifier une valeur ou exécuter une instruction pendant que votre programme C ++ fonctionne juste pour tester quelque chose - pas trivial ou possible avec un débogueur? Les langages de script ont un REPL (read-eval-print-loop). La chose la plus proche du C ++ est de s'accrocher (développé par des chercheurs du CERN) mais il est construit au-dessus de LLVM et est très lourd à mettre en place. RCRL (Read-Compile-Run-Loop) est un projet de démonstration présentant une approche innovante pour effectuer la compilation C ++ à l'exécution dans une plate-forme et un compilateur de manière agnostique qui peut être facilement intégrée. Dans cette présentation, il est montré comment l'utiliser, comment il fonctionne et comment il peut être modifié et intégré dans n'importe quelle application et flux de travail.

Ne serait-ce pas bien si nous avions un type C ++ standard pour représenter les chaînes? Oh, attendez ... nous faisons: std :: string. Ne serait-ce pas bien si nous pouvions utiliser ce type standard dans l'ensemble de notre application / projet? Eh bien ... nous ne pouvons pas! Sauf si nous écrivons une application console ou un service. Mais, si nous écrivons une application avec une interface graphique ou interagissons avec des API de système d'exploitation modernes, il est probable que nous devrons traiter au moins un autre type de chaîne C ++ non standard. Selon la plateforme et le projet, il peut s'agir de CString de MFC ou ATL, Platform :: String de WinRT, QString de Qt, wxString de wxWidgets, etc. Oh, n'oublions pas notre vieil ami const char *, mieux encore const wchar_t * pour la famille d'API C ...
Nous nous sommes donc retrouvés avec deux types de chaînes dans notre base de code. OK, c'est gérable: nous nous en tenons à std :: string pour tout le code indépendant de la plate-forme et convertissons dans les deux sens XString lors de l'interaction avec les API système ou le code GUI. Nous ferons des copies inutiles en traversant ce pont et nous nous retrouverons avec des fonctions amusantes jonglant avec deux types de chaînes; mais c'est du code de colle, de toute façon ... non?
C'est un bon plan ... jusqu'à ce que notre projet se développe et que nous accumulions beaucoup d'utilitaires de chaîne et d'algorithmes. Limitons-nous ces goodies algorithmiques à std :: string? Retournons-nous sur le dénominateur commun const char * et perdons-nous la sécurité de type / mémoire de notre type C ++? C ++ 17 std :: string_view est-il la réponse à tous nos problèmes de chaîne?
L'auteur tente d'explorer les options, ensemble, avec une étude de cas sur une application Windows vieille de 15 ans: Advanced Installer (www.advancedinstaller.com) - un projet C ++ activement développé, modernisé en C ++ 17, grâce à clang-tidy et «Clang Power Tools» (
www.clangpowertools.com) ...
L'écriture de code résistant aux erreurs a toujours été un problème dans toutes les langues. Les exceptions sont le moyen politiquement correct de signaler les erreurs en C ++, mais de nombreuses applications recourent toujours aux codes d'erreur pour des raisons liées à la facilité de compréhension, à la facilité de traitement des erreurs localement et à l'efficacité du code généré.
Cette présentation montre comment une variété d'artefacts théoriques et pratiques peuvent être combinés ensemble pour traiter les codes d'erreur et les exceptions dans un package simple et sain. Le type générique Expected peut être utilisé à la fois pour les manières locales (style code d'erreur) et centralisées (style exception), en tirant parti des points forts de chacune.

Les logiciels dotés d'une logique métier très complexe, tels que les jeux, les systèmes de CAO et les systèmes d'entreprise, doivent souvent composer et modifier des objets au moment de l'exécution, par exemple pour ajouter ou remplacer une méthode dans un objet existant. Le C ++ standard a des types rigides qui sont définis au moment de la compilation et rendent cela difficile. D'un autre côté, les langages avec des types dynamiques comme lua, Python et JavaScript rendent cela très facile. Par conséquent, pour garder le code lisible et maintenable, et accomplir des exigences complexes de logique métier, de nombreux projets utilisent de tels langages aux côtés de C ++. Certains inconvénients de cette approche incluent la complexité supplémentaire d'une couche de liaison de langage, la perte de performances due à l'utilisation d'un langage interprété et la duplication de code inévitable pour de nombreuses fonctionnalités de petit utilitaire.
DynaMix est une bibliothèque qui tente de supprimer, ou du moins de réduire considérablement, la nécessité d'un langage de script distinct en permettant aux utilisateurs de composer et de modifier des objets polymorphes lors de l'exécution en C ++. Cet exposé élabore sur ce problème et présente la bibliothèque et ses fonctionnalités clés aux utilisateurs potentiels ou aux personnes qui pourraient bénéficier de l'approche avec un exemple annoté et une petite démo.

En C ++, vous pouvez résoudre une seule tâche de plusieurs manières. L'auteur choisit une tâche réelle dans la production et étudie comment la résoudre avec un certain nombre d'outils fournis par C ++: conteneurs STL, boost.range, plages C ++ 20, coroutines. Il compare également les contraintes API et les performances de différentes solutions, et comment elles peuvent être facilement converties de l'une à l'autre si le code est bien structuré. En cours de route, l'auteur explore également les applications de certaines fonctionnalités C ++ 17 utiles comme constexpr if, les instructions de sélection avec initialiseur, std :: not_fn, etc. Une attention particulière est accordée au thème - algorithmes standard.

La programmation parallèle est un sujet très complexe et profond. Au cours des décennies de recherche, un grand nombre d'approches, de pratiques et d'outils ont été développés, mais nous pouvons difficilement supposer que le langage C ++ a suivi ces tendances. À partir de la norme C ++ 11, des concepts tels que std :: thread, std :: atomic, std :: future, std :: mutex ont été introduits, et à l'avenir, il est prévu que des coroutines, un modèle de calculs asynchrones, seront ajoutées. Eh bien, ce sont toutes des choses intéressantes à étudier, mais le rapport se concentrera sur une idée complètement différente.
La mémoire transactionnelle logicielle (STM) - le concept d'un modèle de données à mutation transactionnelle - existe depuis longtemps et dispose d'un certain nombre d'implémentations pour tous les langages. En utilisant STM, vous exprimez votre modèle de données et le lancez pour changer sur plusieurs threads, de manière compétitive, sans avoir à vous soucier de la synchronisation des threads, de l'état valide des données ou des verrous. La STM fera tout pour vous. Cela semble très bien, mais toutes les bibliothèques STM ne sont pas également utiles. Les STM impératifs traditionnels sont très complexes, sujets à des bogues multithread non triviaux et difficiles à utiliser. D'autre part, dans le monde de la programmation fonctionnelle, le concept de STM combinatoire existe depuis longtemps, les transactions dans lesquelles sont des briques composables, à partir desquelles vous construisez des transactions d'un niveau supérieur. L'approche combinatoire de la STM vous permet d'exprimer un modèle de données compétitif de manière plus flexible, claire et fiable. La programmation parallèle peut également être agréable!
Dans le rapport, l'auteur parlera des caractéristiques de STM combinatoire, comment l'utiliser et comment l'implémenter en C ++ 17.

Tout au long de l'histoire de la programmation, le traitement séquentiel par éléments de divers types de collections a été et reste l'une des tâches pratiques les plus courantes. La représentation interne des collections, ainsi que l'algorithme utilisé pour extraire les éléments suivants, peuvent varier dans une très large gamme: tableau, liste chaînée, arbre, table de hachage, fichier et al. Cependant, derrière la variété des idiomes, des fonctions de bibliothèque standard, des solutions ad hoc, on peut révéler l'essence qui reste invariante pour toute cette classe de tâches. Cet exposé vise à montrer une transition étape par étape des algorithmes basés sur une description explicite des actions sur les éléments individuels vers des outils de traitement déclaratifs de haut niveau qui traitent une collection comme une entité et révèlent de manière adéquate la logique du domaine.
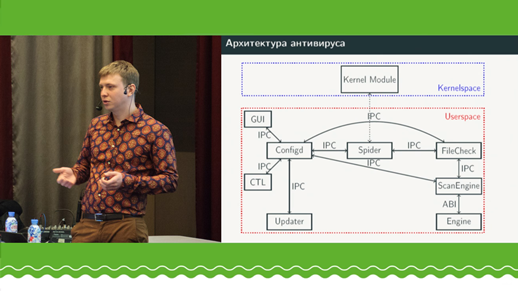
L'auteur racontera son expérience dans le développement d'un moteur antivirus en C ++ sous la forme d'une bibliothèque partagée. Une caractéristique unique est l'absence de toute dépendance externe (runtime C ++ ou C). Tout ce groupe est construit autour de l'utilisation d'une chaîne d'outils personnalisée sur GCC pour une cible spéciale, que libc newlib va utiliser pour la même cible, en plus de laquelle libstdc ++ est construit. Par conséquent, la bibliothèque partagée est assemblée via une chaîne d'outils personnalisée avec libgcc_s, libc, libcstdc ++ personnalisés (modifications uniquement dans l'assembly). Toute interaction avec le runtime se fait via la bibliothèque partagée ABI. Ainsi, la bibliothèque conserve la possibilité d'utiliser C ++ moderne à part entière sans restrictions (RTTI, exceptions, iostream, etc.), qui va à libstdc ++ libc (newlib) | l ibgcc-ABI. Une approche similaire a été testée sur les chaînes d'outils GCC / newlib / libstdc ++ pour Linux et clang / newlib / libc ++ pour MacOS. Le rapport peut intéresser ceux qui souhaitent utiliser C ++ dans des bibliothèques partagées, mais ne peuvent pas se le permettre en raison de dépendances externes.

Au cours de la dernière année et demie, l'auteur a dirigé la création de la spécialisation Coursera en C ++ moderne. La spécialisation comprendra cinq cours, dont deux sont déjà en cours et un autre est presque prêt.
Le rapport dira:
- quels problèmes peuvent être rencontrés en travaillant sur des cours (par exemple, après 3 mois de travail, les développeurs ont jeté tout le matériel et ont recommencé)
- comment le programme est formé et pourquoi exactement (par exemple, pourquoi le mot "pointeur" ne sonnait pas une seule fois dans les deux premiers cours)
De plus, au cours des travaux de spécialisation, un ensemble de principes a été développé et applicables au quotidien:
- dans le processus d'intégration d'un nouvel employé dans le projet
- lors de la révision du code
- lors de l'embauche
Par conséquent, l'auteur veut non seulement dire comment ils se spécialisent, mais il tentera également de transférer l'expérience acquise aux tâches quotidiennes.
Ce n'est un secret pour personne que le développement en C / C ++ a des exigences de qualité du code beaucoup plus élevées que le développement en Java. La probabilité de faire une erreur fatale est beaucoup plus élevée. Dans le même temps, la collecte d'informations sur ces erreurs est une tâche non triviale, même pour les programmeurs expérimentés.
Dans la première partie du rapport, nous passerons brièvement en revue les développements existants: comment fonctionne le débogueur Android intégré, quelles solutions existent déjà. La deuxième partie est consacrée à l'histoire de son fonctionnement "sous le capot": comment obtenir l'état du processeur au moment de l'erreur, comment dérouler la pile d'appels, comment trouver les numéros de ligne dans le code source. Un aperçu des bibliothèques de promotion de pile telles que libcorkscrew, libunwind, libunwindstack sera donné.
Le rapport intéressera à la fois les développeurs Android, dont les applications utilisent NDK, et tout le monde pour élargir leurs horizons.
int * ptr = new int;
* ptr = 42;
supprimer ptr;
Que se passe-t-il réellement lorsque ces 3 lignes de code sont exécutées? Nous allons regarder à l'intérieur de l'allocateur de mémoire, du système d'exploitation et du matériel moderne pour donner une réponse exhaustive à cette question.
En 2017, la question du choix d'un allocateur en C ++ ne perd pas de pertinence. Ils ont ajouté une nouvelle façon à la norme de choisir un allocateur local pour les conteneurs (std :: pmr), tcmalloc global et jemalloc continuent d'évoluer, ainsi que les interfaces du noyau sur lesquelles ils s'appuient. Ce rapport est consacré au "plancher inférieur" de cette conception: les fonctionnalités de mmap et madvise dans le noyau Linux et l'impact de ces fonctionnalités sur les performances des allocateurs.

Le nouveau vaisseau spatial a récemment été adopté comme fonctionnalité de langage pour C ++ 20. Dans cette présentation, le concepteur et auteur de la proposition de vaisseau spatial donne un aperçu de la fonctionnalité, discute de sa motivation et de sa conception, et passe en revue des exemples d'utilisation. Il met particulièrement l'accent sur la façon dont la fonctionnalité rend le code C ++ plus propre à écrire et à lire, plus rapidement en évitant les travaux redondants et plus robuste en évitant plusieurs écueils importants mais subtils dans le code plus fragile que nous avions auparavant à écrire à la main sans cette fonctionnalité.

Lorsque vous regardez les modèles, la réflexion, la génération de code au stade de la compilation, les métaclasses, vous avez l'impression que C ++ s'est donné pour tâche de «cacher» le code final au développeur autant que possible. Une utilisation non triviale du préprocesseur (et de nombreuses branches) peut rendre la séquence du programme très peu évidente. Bien sûr, ces approches sauvent les développeurs du copier-coller sans fin et de la répétition de parties similaires de la base de code, mais nécessitent une prise en charge plus avancée dans les outils de développement.
Est-il possible de déboguer du code sans le redémarrer en continu, sans débogueur et même sans une simple compilation de la base de code entière? Est-il possible de trouver des erreurs dans le code qui ne peuvent pas être assemblées ou exécutées sur la machine locale? Voilà! Les environnements de développement intégré (IDE) ont une connaissance et une compréhension approfondies du code personnalisé, et ce sont eux qui peuvent fournir les outils appropriés.
Ce rapport montrera comment on pourrait «déboguer» des substitutions de macros imbriquées par typedef, comprendre les types de variables (qui dans le C ++ moderne sont souvent «cachés»), déboguer différentes branches du préprocesseur ou la surcharge de l'opérateur, et bien plus encore à l'aide d'un outil vraiment intelligent IDE Certaines fonctionnalités sont déjà disponibles dans CLion et ReSharper C ++, et certaines ne sont que des idées intéressantes pour l'avenir, qui seraient intéressantes à discuter avec le public.

L'assemblage d'un projet C ++ peut être déplacé à l'intérieur du conteneur Docker, tandis qu'au lieu d'installer les bibliothèques et les dépendances nécessaires dans le système hôte, ils peuvent être installés directement dans l'image Docker (par exemple, Cuda), ou installés à l'aide du gestionnaire C ++ de la bibliothèque Conan (par exemple, Boost). Il en résulte un environnement contrôlé isolé (et à chaque fois le même) pour l'assembly, dans lequel vous pouvez connecter le cache Conan, de sorte que différents projets utilisant les mêmes bibliothèques utiliseront les mêmes assemblys. De plus, la construction ne dépend plus de la distribution Linux où le projet est en cours de construction, l'essentiel est que vous pouvez exécuter Docker sur cette distribution.

Au cours du rapport, nous écrirons une petite bibliothèque de travail avec std :: tuple. En utilisant cette bibliothèque, nous compilons le temps de compilation dans une table de hachage hétérogène. De plus - sur sa base, nous écrirons un petit cadre RPC, en utilisant le fait que nous n'avons pas d'effacement de type.
Il y aura de nombreux calculs constexpr, des modèles et de nouvelles fonctionnalités dans C ++ 17 (en particulier, si constexpr).
La réflexion est souvent nécessaire pour généraliser les algorithmes de sérialisation. Implémentation de différents protocoles, travail avec des bases de données. Pour résoudre ces problèmes, nous avons écrit un compilateur IDL homebrew pour générer des structures C ++ et une bibliothèque pour interagir avec le résultat. Protobuf avec pédales et si cela en valait la peine.
Il y a quelque temps, le comité de normalisation C ++ a créé un sous-groupe "SG-7" pour explorer comment ajouter des capacités de réflexion au langage. Plus récemment, ce groupe a ajouté la «métaprogrammation» à son assiette et a pris des décisions importantes concernant la forme de la solution éventuelle. Dans cet exposé, l'auteur se penche sur le passé qui nous a amenés ici et examine un chemin possible pour le support de première classe de C ++ de la "métaprogrammation réfléchissante".
Avec l'ajout de concepts à la prochaine révision de C ++, il est prévu que de nouveaux concepts soient définis. Chaque concept définit un ensemble d'opérations utilisées par du code générique. Une telle utilisation pourrait être un test générique vérifiant que toutes les parties d'un concept sont définies et vérifiant les interactions génériques entre les opérations d'un concept. Idéalement, un tel test fonctionne même avec des classes ne modélisant que partiellement un concept pour guider la mise en œuvre des classes.
Cette présentation n'utilise pas les extensions de concept réelles mais montre comment les tests génériques peuvent être créés à l'aide des fonctionnalités de C ++ 17. Pour les tests génériques, l'idiome de détection et constexpr if sont utilisés pour déterminer la disponibilité des opérations requises et gérer avec élégance l'absence des opérations. Les tests génériques devraient pouvoir couvrir les bases des classes modélisant un concept. De toute évidence, un comportement spécifique pour les classes nécessitera toujours des tests correspondants.

La programmation parallèle peut être utilisée pour tirer parti des architectures multicœurs et hétérogènes et peut augmenter considérablement les performances des logiciels. Le C ++ moderne a grandement contribué à rendre la programmation parallèle plus facile et plus accessible; fournissant des abstractions de haut niveau et de bas niveau. C ++ 17 va plus loin en fournissant des algorithmes parallèles de haut niveau, et beaucoup plus est attendu en C ++ 20. Cette présentation donne un aperçu des utilitaires de parallélisme actuels disponibles et examine l'avenir de la façon dont les GPU et les systèmes hétérogènes peuvent être pris en charge par le biais de nouvelles fonctionnalités de bibliothèque standard et d'autres normes comme SYCL.
Le langage C ++ et l'infrastructure qui l'entoure continuent d'évoluer, ce qui fait de ce langage l'un des outils les plus efficaces à l'heure actuelle. Je voudrais souligner trois facteurs qui rendent le langage C ++ si attrayant.
- Premièrement: des innovations dans la norme de langage, vous permettant d'écrire du code efficace.
- Deuxièmement: la maturité des outils de développement et une augmentation de la vitesse de montage des projets.
- Troisièmement: des outils de support matures qui vous permettent de contrôler la qualité du code et d'autres aspects du cycle de vie du projet.
Ce rapport est une ode au langage de programmation C ++!

Dans le domaine du développement d'applications multithread ou distribuées hautement chargées, on peut de plus en plus entendre des conversations sur le code asynchrone, y compris des spéculations sur la nécessité (manque de besoin) de prendre en compte l'asynchronie dans le code, sur la compréhensibilité (incompréhensibilité) du code asynchrone et son efficacité (inefficacité). Dans ce rapport, nous tenterons d'approfondir le sujet: nous analyserons ce qu'est l'asynchronie; quand il se pose; comment cela affecte le code que nous écrivons et le langage de programmation que nous utilisons. Nous allons essayer de comprendre ce que l'avenir et les promesses ont à voir avec cela, parlons un peu des coroutines et des acteurs. Nous affectons JavaScript et les systèmes d'exploitation. L'objectif du rapport est de rendre plus explicites les compromis qui surviennent avec l'une ou l'autre approche du développement de logiciels multithread ou distribués.

Le rapport discutera de l'état actuel de WebAssembly par rapport aux produits réels. Nous parlerons de notre expérience de portage de l'application, des problèmes survenus et de la manière dont nous les avons résolus.
Les sujets traités comprennent:
- Prise en charge de la norme sur différentes plates-formes et navigateurs.
- Performances et taille de construction par rapport à asm.js.
- Interactions avec le navigateur.
- Créez des plantages de l'utilisateur.
- Fonctionnalités VM.
Le système de construction CMake devient progressivement la norme de facto pour la programmation C ++ multiplateforme. Cependant, il est souvent critiqué équitablement, notamment pour le langage de script peu pratique, la documentation obsolète et le fait que les mêmes tâches peuvent être exécutées de différentes manières, et il peut être assez difficile de comprendre laquelle est la plus correcte dans une situation particulière. . L'auteur racontera:- fréquents anti-modèles populaires et pourquoi ils sont mauvais,
- à quels niveaux d'abstraction CMake fonctionne-t-il et quand «fuit-il»,
- qu'est-ce que «Modern CMake» et quels sont ses avantages,
- comment localiser et déboguer les problèmes dans les scripts CMake (y compris certains plutôt exotiques).
L'architecture épurée du projet, des abstractions simples sur chaque couche est le rêve de toute équipe. Pour réaliser ce rêve, de nombreuses techniques orientées objet ont été inventées. Emportés par OOP, les développeurs oublient de surveiller la propreté du code à la jonction de C et C ++. C'est ici que le style procédural aidera à rétablir l'ordre, à construire des abstractions pratiques et sûres qui s'intègrent facilement dans le code orienté objet du projet. Nous découvrirons:- pourquoi avez-vous besoin d'isoler l'API C (comme winapi, POSIX, SQLite, OpenGL, OpenSSL)
- pourquoi la POO fonctionne-t-elle mal dans cette entreprise
- comment écrire une couche d'abstraction au-dessus de l'API de style C
- comment gérer les rappels, la gestion des erreurs et la gestion des ressources pour rendre le code traditionnellement complexe et déroutant compréhensible même pour un junior
Ses intérêts professionnels sont la sémantique des langages de programmation, la conception et l'implémentation de compilateurs de YaP et d'autres outils orientés langages. Parmi les réalisations les plus importantes figurent la participation à des projets tels que la création d'un compilateur de la norme complète du langage C ++ (Interstron, Moscou, 2000), la mise en œuvre du compilateur de langage Zonnon pour .NET (ETH Zurich, 2005) et la mise en œuvre du prototype de compilateur Swift pour la plate-forme Tizen ( Samsung Research Institute, Moscou, 2015).C ++ a toujours eu un puissant sous-langage de méta-programmation qui a permis aux développeurs de bibliothèques d'effectuer des exploits magiques comme l'introspection statique pour réaliser une exécution polymorhpique sans héritage. Le problème était que la syntaxe était maladroite et inutilement verbeuse, ce qui rendait l'apprentissage de la méta-programmation une tâche intimidante.Avec les améliorations récentes apportées à la norme et avec les fonctionnalités prévues pour C ++ 20, la méta-programmation est devenue beaucoup plus facile, et les méta-programmes sont devenus plus faciles à comprendre et à raisonner.Dans cet exposé, l'auteur présente quelques techniques modernes de méta-programmation, avec un accent principal sur la méta-fonction magique void_t.L'auteur du rapport est responsable du développement du framework SObjectizer Open-Source depuis 16 ans. C'est l'un des rares frameworks d'acteurs multiplates-formes en direct et en développement pour C ++. Le développement de SObjectizer a commencé en 2002, lorsque C ++ était parmi les langages de programmation les plus populaires et les plus courants. Au cours du passé, le C ++ a beaucoup changé et l'attitude envers le C ++ a encore changé. Le rapport discutera de la façon dont ces changements ont affecté le développement d'un outil avec une histoire de 16 ans et de la simplicité et de la commodité de la création d'un tel outil pour le langage C ++. Et s'il était nécessaire de faire un tel outil pour C ++ en général.
- Entraînez-vous à utiliser le modèle Model-View-Presenter
- Gestion du cycle de vie des documents
- Stockage de fichiers Smart Pointers
Des informations sur la prochaine vulnérabilité trouvée régulièrement apparaissent ici et là. Les pertes collatérales de $, en règle générale, sont énormes. Par conséquent, au lieu de corriger les vulnérabilités, elles ne devraient pas être autorisées à apparaître.
Une façon de traiter les erreurs de code consiste à utiliser l'analyse statique. Mais dans quelle mesure est-il approprié de rechercher des vulnérabilités? Et y a-t-il vraiment une grande différence entre de simples bugs et des vulnérabilités de code?
Nous discuterons de ces questions au cours du rapport et, en même temps, nous parlerons de la manière d'utiliser l'analyse statique afin d'en tirer le meilleur parti.
PSPour ma part, je veux attirer votre attention sur la mini-intrigue autour de
std :: string liée aux rapports de mon collègue Andrei Karpov. Donc, dans l'ordre:
- Un fragment du rapport d'Andrei (C ++ Russia 2016) «Contes privés de développeurs d'analyseurs de code» de 30:05 - lien .
- Trolling facile de personnes comme nous par Anton Polukhin (C ++ Russia 2017) dans le rapport «Comment ne pas le faire: la construction de vélos C ++ pour les professionnels» à partir de 2h00 - lien .
- L'histoire d'Andrey lors de la conférence C ++ Russia 2018 selon laquelle nous ne sommes pas des dinosaures et apprenons une nouvelle chose: "C ++ efficace" à partir de 12:21 - lien .
C’est tout! Profitez de vos rapports.