Notre société SberTech (Sberbank Technologies) utilise actuellement HDFS 2.8.4 car il présente un certain nombre d'avantages, tels que l'écosystème Hadoop, un travail rapide avec de grandes quantités de données, il est bon en analyse et bien plus encore. Mais en décembre 2017, l'Apache Software Foundation a publié une nouvelle version du framework open-source pour le développement et l'exécution de programmes distribués - Hadoop 3.0.0, qui comprend un certain nombre d'améliorations significatives par rapport à la précédente version principale (hadoop-2.x). L'une des mises à jour les plus importantes et intéressantes pour nous est le support des codes de redondance (Erasure Coding). Par conséquent, la tâche a été définie pour comparer ces versions entre elles.
La société SberTech a alloué 10 machines virtuelles de 40 Go chacune pour ce travail de recherche. Étant donné que la politique de codage RS (10.4) nécessite un minimum de 14 machines, elle ne fonctionnera pas pour la tester.
Sur l'une des machines, NameNode sera situé en plus du DataNode. Les tests seront effectués avec les politiques d'encodage suivantes:
- XOR (2.1)
- RS (3.2)
- RS (6,3)
Et aussi, en utilisant la réplication avec un facteur de réplication de 3.
La taille du bloc de données a été choisie égale à 32 Mo.
La recherche
Test de débit de données
Des tests de taux de transfert de données ont été effectués. Les données ont été transférées du système de fichiers local vers le système de fichiers distribué. La taille de fichier utilisée dans ce test est de 292,2 Mo.
Les résultats suivants ont été obtenus:
Un graphique des valeurs groupées reçues du temps de transfert de fichier est également construit:

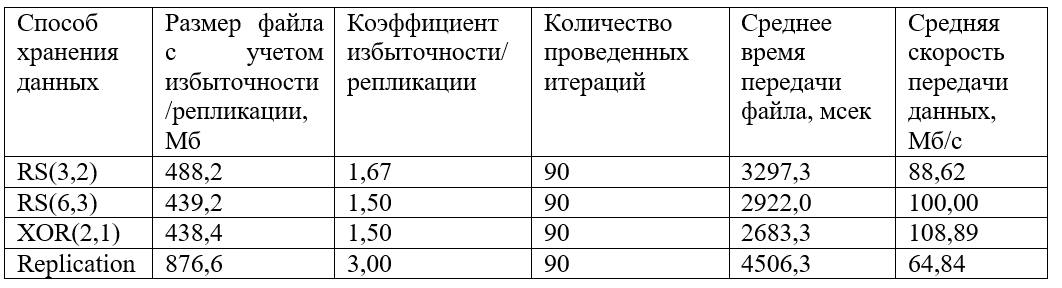
Et aussi, un graphique des débits de données reçus groupés:
Comme le montre le graphique, les données les plus rapides sont transmises codées avec XOR (2,1). Les codages RS (6.3) et RS (3.2) présentent un comportement similaire, bien que la valeur de vitesse moyenne pour RS (6.3) soit légèrement plus élevée. La réplication perd beaucoup en vitesse (environ 1,5 fois moins que XOR et 1,5 fois moins que RS).
Quant à l'efficacité du stockage, XOR (2.1) et RS (6.3) sont les méthodes de stockage les plus rentables, les données redondantes ne sont que de 50%. La réplication, avec un taux de réplication de 3, perd à nouveau, stockant 200% des données redondantes.
Test de performance
Lors du test précédent, l'état des serveurs a été contrôlé à l'aide de l'outil de surveillance Grafana.
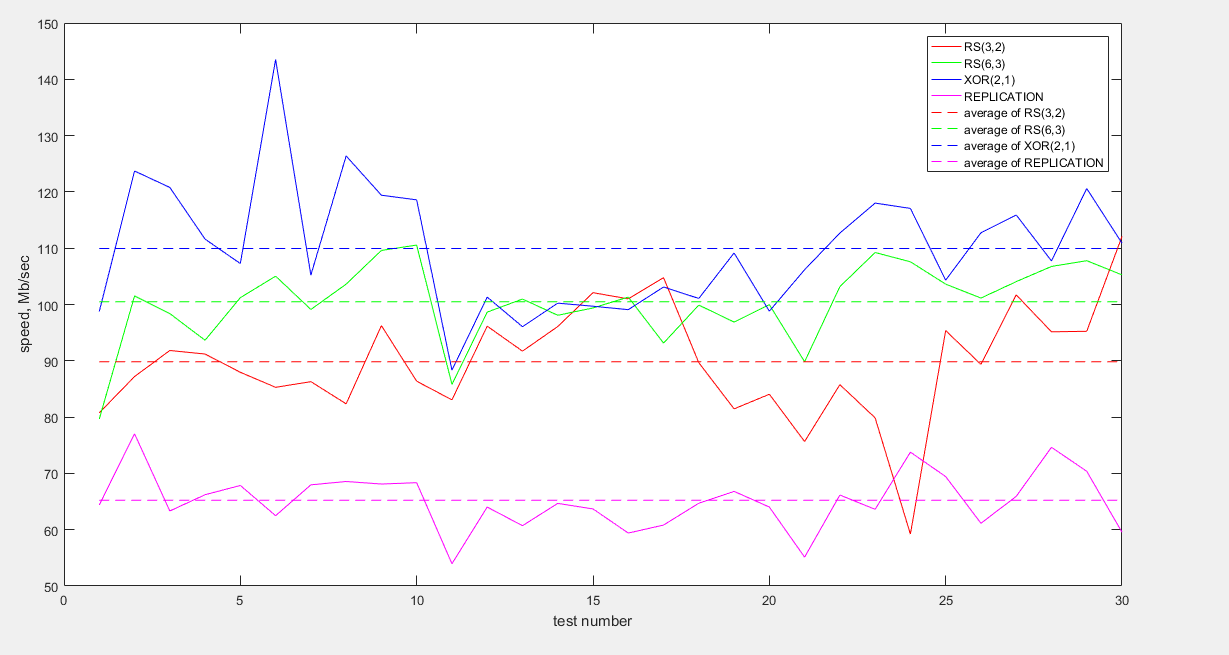
Vous trouverez ci-dessous un graphique montrant la charge du processeur lors des tests de transfert de données:
Comme le montre le graphique, dans ce test également, le codage RS (6.3) consomme le moins de ressources. La réplication montre à nouveau le pire résultat.
Consommation de ressources dans la récupération de données
Pour effectuer ce test, une certaine quantité de données a été téléchargée sur le système de fichiers distribué Hadoop. Ensuite, deux machines avec un DataNode ont été omises.
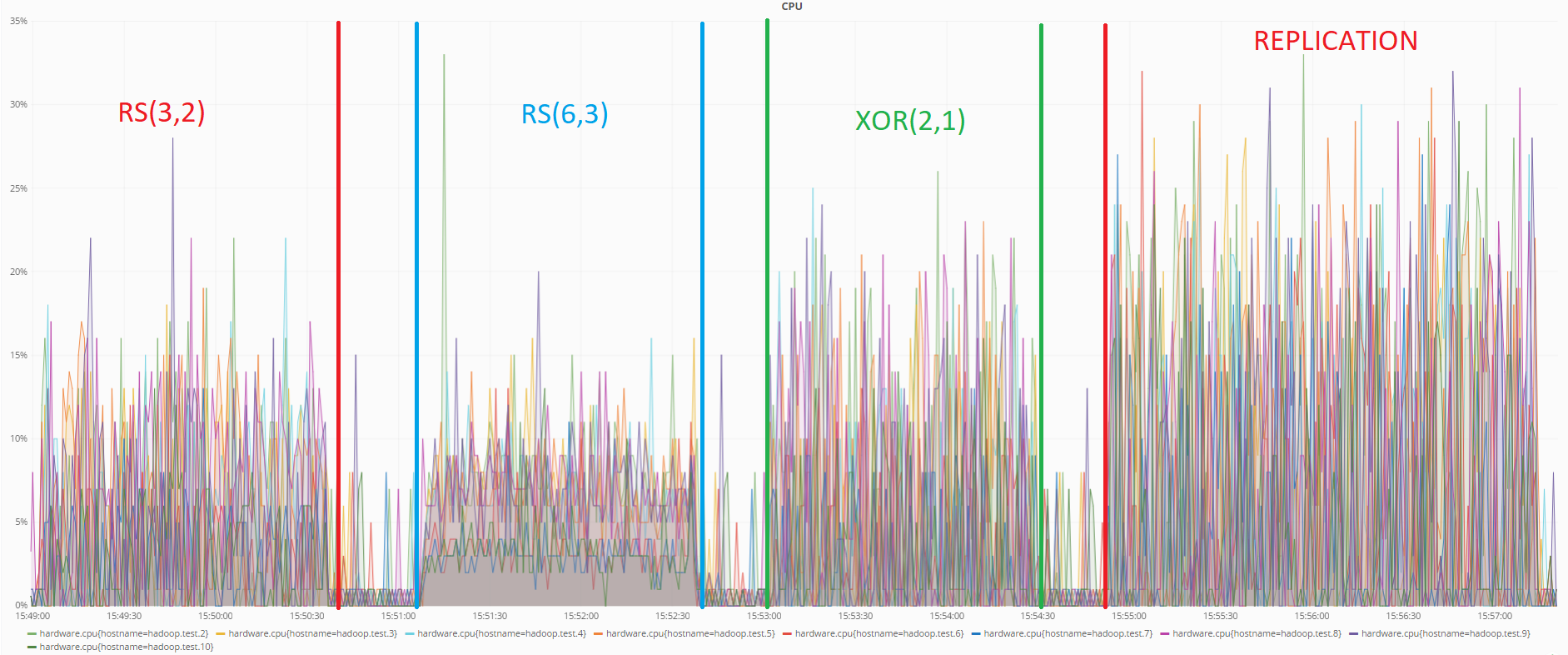
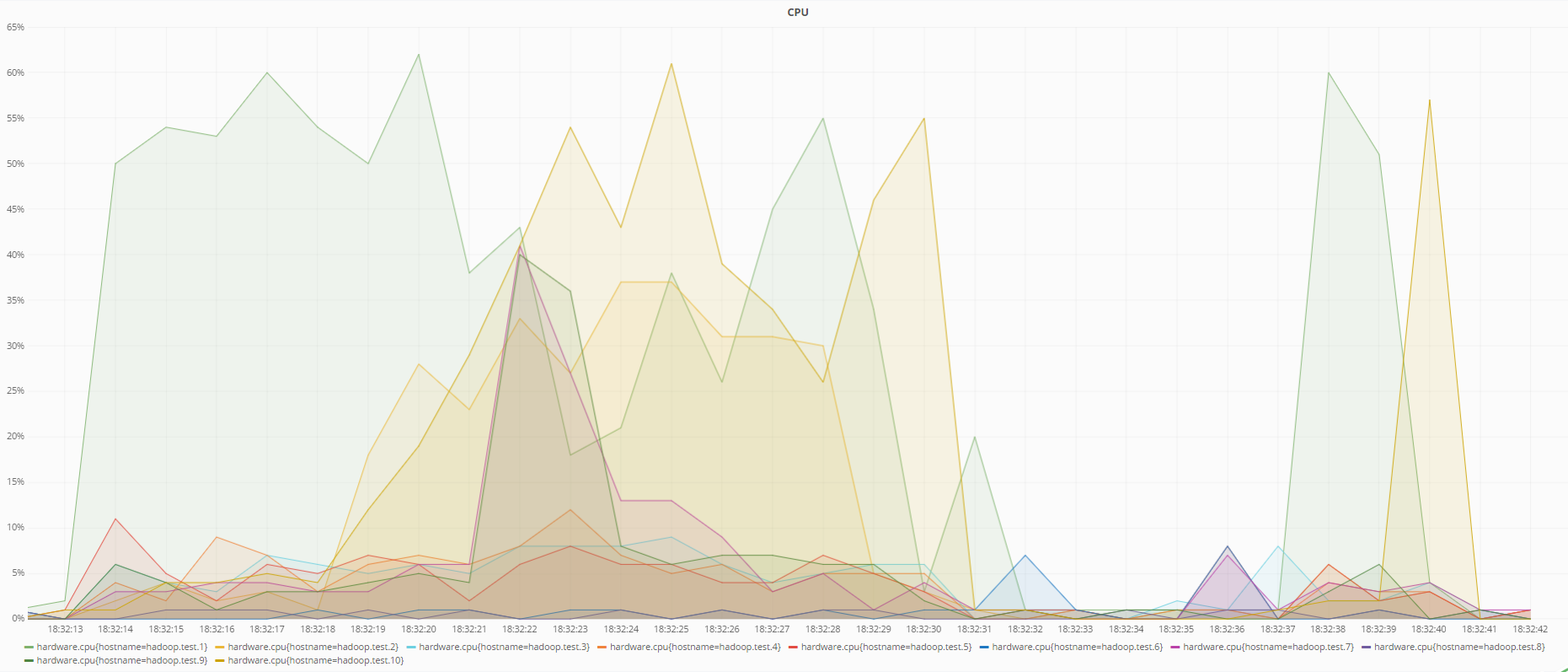
Vous trouverez ci-dessous des graphiques de l'état des machines au moment de la récupération des données avec l'encodage RS (6.3) et lors de l'utilisation de la réplication:
État du processeur pendant la récupération des données à l'aide du codage RS (6.3)

État du processeur pendant la récupération de données à l'aide de la réplication
Comme le montrent les graphiques, le codage RS (6.3) charge le processeur plus que la réplication pendant la récupération des données, ce qui est logique, car pour récupérer les données perdues à l'aide de codes redondants, il est nécessaire de calculer la matrice de redondance inverse, qui consomme plus de ressources que la simple réécriture les données d'autres DataNode en cas de réplication.
Résultats des tests:
- Pour les taux de transfert de données, il est préférable d'utiliser le codage XOR (2.1) ou RS (6.3)
- Lors de la transmission de données, le processeur charge le moins l'encodage RS (6.3) et RS (3.2)
- Lors de la restauration des données, le processeur est le moins lourd
- Le moyen le plus compact de stocker des données est le codage RS (6.3) et XOR (2.1)
La méthode de stockage la plus fiable est le codage RS (6.3), car il vous permet de perdre jusqu'à trois machines sans perte de données, et la réplication avec un coefficient de réplication de 3 prend en charge la défaillance de jusqu'à 2 machines. XOR (2, 1) est le moyen le plus fiable de stocker des données car il vous permet de perdre un maximum d'une machine.
Conclusion
Les principaux objectifs de l'utilisation du système de fichiers distribué dans SberTech sont les suivants:
- Haute fiabilité
- Minimiser le coût de maintenance des serveurs pour le stockage des données
- Fournir des outils d'analyse de données
Sur la base des résultats de l'analyse, les conclusions suivantes sont tirées:
- HDFS 3 surpasse la fiabilité par rapport à HDFS 2.
- HDFS 3 gagne en minimisant les coûts de maintenance du serveur car il stocke les données de manière plus compacte.
- HDFS 3 a le même ensemble d'outils d'analyse de données que HDFS 2.
À cet égard, il a été conclu que HDFS 3 est un remplacement rationnel de HDFS 2.
Sources utilisées: