Salut Je m'appelle Denis Kiryanov, je travaille à la Sberbank et je m'occupe des problèmes de traitement du langage naturel (PNL). Une fois, nous devions choisir un analyseur syntaxique pour travailler avec la langue russe. Pour ce faire, nous nous sommes plongés dans la nature sauvage de la morphologie et de la tokenisation, testé différentes options et évalué leur application. Nous partageons notre expérience dans ce post.

Préparation à la sélection
Commençons par les bases: comment ça marche? Nous prenons le texte, effectuons la tokenisation et obtenons un tableau de pseudo-jetons. Les étapes d'une analyse plus approfondie s'inscrivent dans une pyramide:
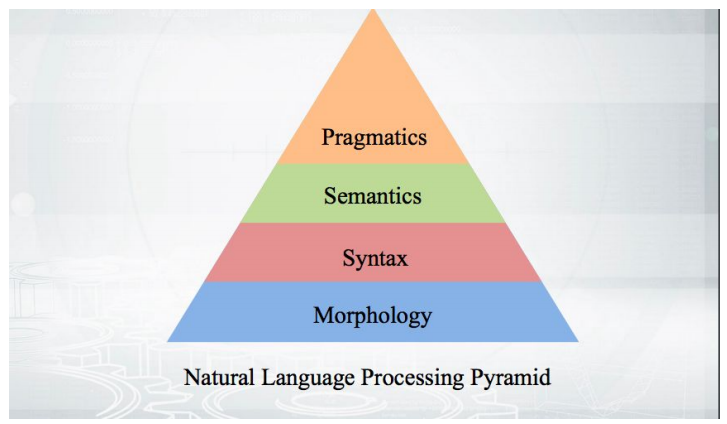
Tout commence par la morphologie - avec une analyse de la forme d'un mot et de ses catégories grammaticales (genre, cas, etc.). La morphologie est basée sur la syntaxe - des relations au-delà des limites d'un mot, entre les mots. Les analyseurs syntaxiques qui seront discutés, analysent le texte et donnent la structure des dépendances des mots les uns des autres.
Grammaire des dépendances et grammaire des composants immédiats
Il existe deux approches principales de l'analyse, qui existent en théorie linguistique sur un pied d'égalité.

Dans la première ligne, la phrase est analysée dans le cadre de la grammaire des dépendances. Cette approche est enseignée à l'école. Chaque mot d'une phrase est en quelque sorte lié aux autres. «Savons» - un prédicat dont dépend le sujet «mère» (ici la grammaire des dépendances diverge de l'école, où le prédicat dépend du sujet). Le sujet a une définition dépendante du «mien». Le prédicat a une "trame" de complément direct dépendante. Et l'ajout direct au "cadre" - la définition de "sale".
Dans la deuxième ligne, l'analyse est conforme à la grammaire des composants eux-mêmes.
Selon elle, la phrase est divisée en groupes de mots (phrases). Les mots d'un même groupe sont plus étroitement liés. Les mots «ma» et «mère» sont plus étroitement liés, «cadre» et «sale» - aussi. Et il y a encore un «savon» distinct.
La deuxième approche pour l'analyse automatique de la langue russe est mal applicable, car en elle, des mots étroitement liés (membres du même groupe) ne se tiennent très souvent pas d'affilée. Il faudrait les combiner avec des parenthèses étranges - en un ou deux mots. Par conséquent, dans l'analyse automatique de la langue russe, il est habituel de travailler sur la base de la grammaire des dépendances. C'est également pratique car tout le monde connaît un tel «cadre» à l'école.
Arbre de dépendance
Nous pouvons traduire un ensemble de dépendances en une structure arborescente. Le sommet est le mot «savon», certains mots dépendent directement de lui, certains dépendent de ses dépendants. Voici la
définition de l'arbre de dépendance du manuel de Martin et Zhurafsky:
L'arbre de dépendance est un graphe orienté qui satisfait les contraintes suivantes:- Il existe un seul nœud racine désigné qui n'a pas d'arcs entrants.
- À l'exception du nœud racine, chaque sommet a exactement un arc entrant.
- Il existe un chemin unique du nœud racine à chaque sommet de V.
Il existe un nœud de niveau supérieur - un prédicat. De là, vous pouvez atteindre n'importe quel mot. Chaque mot dépend d'un autre, mais d'un seul. L'arbre des dépendances ressemble à ceci:

Dans cet arbre, les bords sont signés avec un type particulier de relation syntaxique. Dans la grammaire des dépendances, non seulement le fait de la connexion entre les mots est analysé, mais aussi la nature de cette connexion. Par exemple, «est pris» est presque une forme verbale, «inventaire» est le sujet de «est pris». Par conséquent, nous avons un bord «est» dans un sens et dans l'autre. Ce ne sont pas les mêmes connexions, elles sont de nature différente, il faut donc les distinguer.
Ci-après, nous considérons des cas simples où des membres d'une peine sont présents, non implicites. Il existe des structures et des marques pour gérer les passes. Quelque chose apparaît dans l'arbre qui n'a pas d'expression superficielle - un mot. Mais c'est le sujet d'une autre étude, mais nous devons encore nous concentrer sur la nôtre.
Projet des dépendances universelles
Pour faciliter le choix d'un analyseur, nous avons tourné notre attention vers le projet
Universal Dependencies et le
concours CoNLL Shared Task , qui a récemment eu lieu dans son cadre.
Universal Dependencies est un projet visant à unifier le balisage des corpus syntaxiques (tribanks) dans le cadre de la grammaire des dépendances. En russe, le nombre de types de liens syntaxiques est limité - sujet, prédicat, etc. En anglais pareil, mais l'ensemble est déjà différent. Par exemple, un article y apparaît qui doit également être étiqueté d'une manière ou d'une autre. Si nous voulions écrire un analyseur magique capable de gérer toutes les langues, nous rencontrerions rapidement des problèmes de comparaison de différentes grammaires. Les créateurs héroïques des dépendances universelles ont réussi à s'entendre entre eux et à délimiter tous les bâtiments qui étaient à leur disposition dans un format unique. Peu importe la façon dont ils se sont mis d'accord, l'essentiel est qu'à la sortie, nous avons obtenu un certain format uniforme pour présenter toute cette histoire -
plus de 100 tribanks pour 60 langues .
CoNLL Shared Task est une compétition entre développeurs d'algorithmes d'analyse, organisée dans le cadre du projet Universal Dependencies. Les organisateurs prennent un certain nombre de tribanks et les décomposent en trois parties: formation, validation et test. La première partie est fournie aux participants du concours afin qu'ils y forment leurs modèles. La deuxième partie est également utilisée par les participants pour évaluer le fonctionnement de l'algorithme après la formation. Les participants peuvent répéter la formation et l'évaluation de manière itérative. Ensuite, ils donnent leur meilleur algorithme aux organisateurs, qui l'exécutent sur la partie test, fermée aux participants. Les résultats des modèles sur les pièces d'essai des tribanks sont les résultats de la compétition.
Mesures de qualité
Nous avons des liens entre les mots et leurs types. Nous pouvons évaluer si le mot top est correctement trouvé - la métrique UAS (Unlabeled attachment score). Ou pour évaluer si le sommet et le type de dépendance sont trouvés correctement - la métrique LAS (Labeled attachment score).

Il semblerait qu'une évaluation de l'exactitude s'impose ici - nous considérons combien de fois nous avons obtenu du nombre total de cas. Si nous avons 5 mots et pour 4 nous avons correctement déterminé le sommet, nous obtenons 80%.
Mais en réalité, évaluer l'analyseur dans sa forme pure est problématique. Les développeurs qui résolvent les problèmes de l'analyse automatique prennent souvent du texte brut en entrée qui, conformément à la pyramide d'analyse, passe par les étapes de la tokenisation et de l'analyse morphologique. Les erreurs de ces étapes précédentes peuvent affecter la qualité de l'analyseur. En particulier, cela s'applique à la procédure de tokenisation - attribution de mots. Si nous avons identifié les mauvais mots d'unité, nous ne serons plus en mesure d'évaluer correctement les relations syntaxiques entre eux - après tout, dans notre corps d'origine étiqueté, les unités étaient différentes.
Par conséquent, la formule d'évaluation dans ce cas est la f-mesure, où la précision est la part des hits précis par rapport au nombre total de prédictions, et l'exhaustivité est la part des hits précis par rapport au nombre de liens dans les données balisées.
Lorsque nous donnerons des estimations à l'avenir, nous devons nous rappeler que les métriques utilisées affectent non seulement la syntaxe, mais également la qualité de la tokenisation.
La langue russe aux dépendances universelles
Pour que l'analyseur puisse marquer syntaxiquement des phrases qu'il n'a pas encore vues, il doit alimenter le corpus balisé pour la formation. Pour la langue russe, il existe plusieurs cas de ce type:

La deuxième colonne indique le nombre de jetons - mots. Plus il y a de jetons, plus le corps d'entraînement est grand et meilleur est l'algorithme final (s'il s'agit de bonnes données). De toute évidence, toutes les expériences sont menées sur SynTagRus (développé par IPPI RAS), dans lequel il y a plus d'un million de jetons. Tous les algorithmes y seront entraînés, ce qui sera discuté plus tard.
Analyseurs du russe dans la tâche partagée CoNLL
Selon les résultats du
concours de l'année dernière, les modèles formés sur le même SynTagRus ont atteint les indicateurs LAS suivants:

Les résultats des analyseurs pour le russe sont impressionnants - ils sont meilleurs que ceux des analyseurs pour l'anglais, le français et d'autres langues plus rares. Nous avons eu beaucoup de chance pour deux raisons à la fois. Premièrement, les algorithmes font un bon travail avec la langue russe. Deuxièmement, nous avons SynTagRus - un grand logement marqué.
Soit dit en passant, la compétition de 2018 est déjà passée, mais nous avons mené nos recherches au printemps de cette année, nous nous appuyons donc sur les résultats de la piste de l'année dernière. Pour l'avenir, nous notons que la
nouvelle version d'UDPipe (Future) s'est avérée encore plus élevée cette année.
Syntaxnet, un analyseur Google, n'est pas sur la liste. Qu'est-ce qui ne va pas avec lui? La réponse est simple: Syntaxnet n'a commencé qu'au stade de l'analyse morphologique. Il a pris une tokenisation idéale prête à l'emploi et a déjà construit un traitement par-dessus. Par conséquent, il est injuste de l'évaluer sur un pied d'égalité avec les autres - les autres ont effectué la division en jetons avec leurs propres algorithmes, ce qui pourrait aggraver les résultats à l'étape suivante de la syntaxe. L'échantillon 2017 de Syntaxnet a un meilleur résultat que la liste complète ci-dessus, mais les comparaisons directes ne sont pas justes.
Le tableau a obtenu deux versions de UDPipe, à 12 et 15 places. Les mêmes personnes qui ont participé activement au projet des dépendances universelles développent ce parseur.
Des mises à jour UDPipe apparaissent périodiquement (un peu moins souvent, d'ailleurs, la disposition des cas est également mise à jour). Ainsi, après le concours de l'année dernière, UDPipe a été mis à jour (il s'agissait de validations pour la version 2.0 non encore publiées; à l'avenir, pour plus de simplicité, nous ferons référence à peu près au commit UDPipe 2.0 que nous avons pris, bien que ce ne soit pas le cas à proprement parler); Bien sûr, il n'y a pas de telles mises à jour dans la table de compétition. Le résultat de «notre» engagement est approximativement à la septième place.
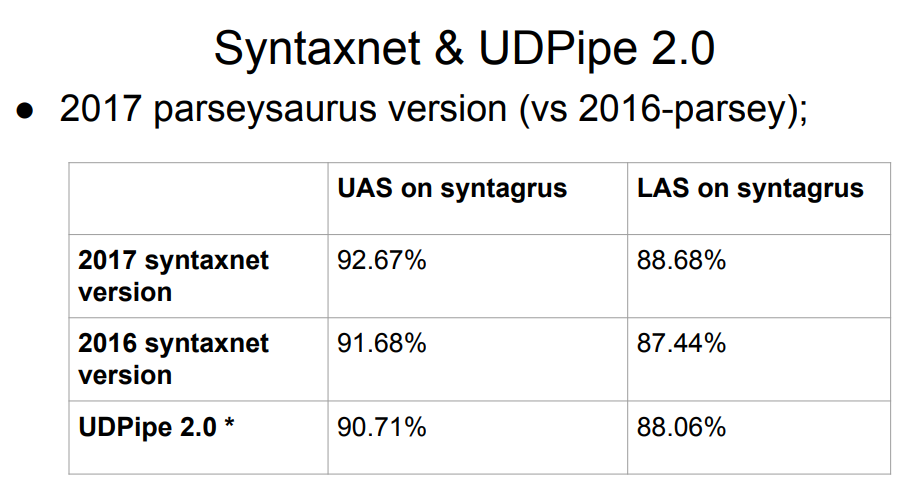
Donc, nous devons choisir un analyseur pour la langue russe. Comme données initiales, nous avons la plaque ci-dessus avec le Syntaxnet leader et avec UDPipe 2.0 quelque part à la 7ème place.
Choisissez un modèle
Nous simplifions les choses: nous commençons par l'analyseur avec les taux les plus élevés. Si quelque chose ne va pas avec lui, allez ci-dessous. Quelque chose ne va peut-être pas selon les critères suivants - peut-être qu'ils ne sont pas parfaits, mais ils nous sont parvenus:
- Vitesse de travail . Notre analyseur devrait fonctionner assez rapidement. La syntaxe, bien sûr, est loin d'être le seul module "sous le capot" d'un système en temps réel, vous ne devez donc pas y consacrer plus d'une dizaine de millisecondes.
- La qualité du travail . Au minimum, l'analyseur lui-même est basé sur des données en russe. L'exigence est évidente. Pour la langue russe, nous avons de très bons analyseurs morphologiques qui peuvent être intégrés dans notre pyramide. Si nous pouvons nous assurer que l'analyseur lui-même fonctionne bien sans morphologie, alors cela nous conviendra - nous glisserons la morphologie plus tard.
- Disponibilité d'un code de formation et de préférence d'un modèle dans le domaine public . Si nous avons un code de formation, nous pourrons répéter les résultats de l'auteur du modèle. Pour ce faire, ils doivent être ouverts. Et, en outre, nous devons surveiller attentivement les conditions de distribution des cas et des modèles - devrons-nous acheter une licence pour les utiliser, si nous les utilisons dans le cadre de nos algorithmes?
- Lancez sans effort supplémentaire . Cet article est très subjectif, mais important. Qu'est-ce que cela signifie? Cela signifie que si nous nous asseyons pendant trois jours et commençons quelque chose, mais que cela ne démarre pas, nous ne pourrons pas sélectionner cet analyseur, même s'il sera de qualité parfaite.
Tout ce qui était supérieur à UDPipe 2.0 sur le graphique de l'analyseur ne nous convenait pas. Nous avons un projet Python, et certains analyseurs de la liste ne sont pas écrits en Python. Pour les implémenter dans le projet Python, il faudrait appliquer les très gros efforts. Dans d'autres cas, nous avons été confrontés à des codes source fermés, des développements académiques et industriels - en général, vous n'allez pas au fond.
Star Syntaxnet mérite une histoire distincte sur la qualité du travail. Ici, il ne nous convenait pas pour la rapidité du travail. Le temps de sa réponse à quelques phrases simples courantes dans les chats est de 100 millisecondes. Si nous dépensons autant en syntaxe, nous n'avons pas assez de temps pour autre chose. Dans le même temps, UDPipe 2.0 effectue une analyse pendant environ 3 ms. En conséquence, le choix s'est porté sur UDPipe 2.0.
UDPipe 2.0
UDPipe est un pipeline qui apprend la tokenisation, la lemmatisation, le marquage morphologique et l'analyse grammaticale des dépendances. Nous pouvons lui apprendre tout cela ou quelque chose séparément. Par exemple, faites avec lui un autre analyseur morphologique pour la langue russe. Ou entraînez-vous et utilisez UDPipe comme tokenizer.
UDPipe 2.0 est documenté en détail. Il y a une
description de l'architecture , un
référentiel avec un code de formation , un
manuel . Le plus intéressant est les
modèles prêts à l'
emploi , y compris pour la langue russe. Téléchargez et exécutez. Également sur cette ressource, les paramètres de formation sélectionnés pour chaque corpus linguistique ont été publiés. Pour chacun de ces modèles, environ 60 paramètres de formation sont nécessaires, et avec leur aide, vous pouvez obtenir indépendamment les mêmes indicateurs de qualité que dans le tableau. Ils ne sont peut-être pas optimaux, mais au moins nous pouvons être sûrs que le pipeline fonctionnera correctement. De plus, la présence d'une telle référence nous permet d'expérimenter sereinement le modèle par nous-mêmes.
Fonctionnement d'UDPipe 2.0
Tout d'abord, le texte est divisé en phrases et les phrases en mots. UDPipe fait tout cela à la fois à l'aide d'un module commun - un réseau de neurones (GRU double couche monocouche), qui pour chaque caractère prédit s'il est le dernier d'une phrase ou d'un mot.
Ensuite, le tagueur commence à travailler - une chose qui prédit les propriétés morphologiques du jeton: dans ce cas, le mot est, dans quel numéro. Sur la base des quatre derniers caractères de chaque mot, un tagueur génère des hypothèses concernant une partie de la parole et des balises morphologiques de ce mot, puis à l'aide d'un perceptron sélectionne la meilleure option.
UDPipe dispose également d'un lemmatiseur qui sélectionne la forme initiale des mots. Il apprend le même principe par lequel un locuteur non natif pourrait essayer de déterminer le lemme d'un mot inconnu. Nous coupons le préfixe et la fin du mot, ajoutons du «t», qui est présent dans la forme initiale du verbe, etc. Ainsi, les candidats sont générés, à partir desquels le meilleur perceptron choisit.
Le schéma de marquage morphologique (détermination du nombre, du cas et de tout le reste) et les prédictions des lemmes sont très similaires. Ils peuvent être prédits ensemble, mais mieux séparément - la morphologie de la langue russe est trop riche. Vous pouvez également connecter votre liste de lemmes.
Passons à la partie la plus intéressante - l'analyseur. Il existe plusieurs architectures d'analyseur de dépendance. UDPipe est une architecture basée sur la transition: elle fonctionne rapidement, en traversant tous les jetons une fois dans un temps linéaire.
L'analyse syntaxique dans une telle architecture commence par une pile (où au début il n'y a que root) et une configuration vide. Il existe trois méthodes par défaut pour le modifier:
- LeftArc - applicable si le deuxième élément de la pile n'est pas root. Il conserve la relation entre le jeton en haut de la pile et le deuxième jeton, et éjecte également le second de la pile.
- RightArc est le même, mais la dépendance est construite dans l'autre sens et la pointe est ignorée.
- Shift - transfère le mot suivant du tampon vers la pile.
Voici un exemple de l'analyseur (
source ). Nous avons la phrase «réservez-moi le vol du matin» et nous nous y reconnectons:

Voici le résultat:

L'analyseur classique basé sur la transition a les trois opérations énumérées ci-dessus: flèche unidirectionnelle, flèche unidirectionnelle et décalage. Il existe également une opération Swap, dans les architectures de base basées sur la transition, elle n'est pas utilisée, mais elle est incluse dans UDPipe. Swap renvoie le deuxième élément de la pile dans le tampon pour prendre le suivant dans le tampon (s'ils sont espacés). Cela permet de sauter quelques mots et de rétablir la connexion correcte.
Il y a un bon article du
lien de la personne qui a proposé l'opération de swap. Nous allons souligner un point: malgré le fait que nous passions plusieurs fois par le tampon de jeton initial (c'est-à-dire que notre temps n'est plus linéaire), ces opérations peuvent être optimisées de sorte que le temps soit retourné très près de linéaire. Autrement dit, devant nous n'est pas seulement une opération significative du point de vue de la langue, mais aussi un outil qui ne ralentit pas beaucoup le travail de l'analyseur.
En utilisant l'exemple ci-dessus, nous avons montré les opérations, à la suite desquelles nous obtenons une configuration - le tampon de jeton et les connexions entre eux. Nous donnons cette configuration à l'étape actuelle à l'analyseur basé sur la transition, et avec lui, il devrait prédire la configuration à l'étape suivante. En comparant les vecteurs d'entrée et les configurations à chaque étape, le modèle est formé.
Nous avons donc sélectionné un analyseur qui correspond à tous nos critères et avons même compris comment cela fonctionne. Nous procédons aux expériences.
Problèmes UDPipe
Demandons une petite phrase: "Transférer cent roubles à maman". Le résultat vous fait saisir la tête.
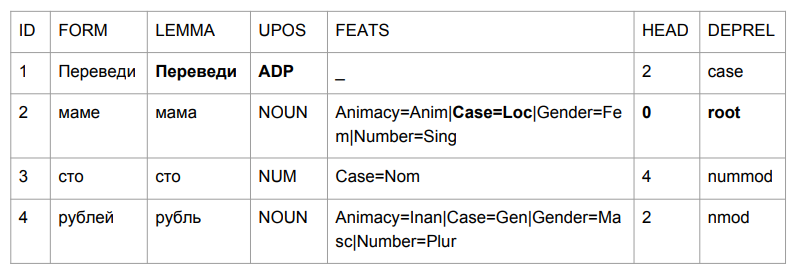
«Traduire» s'est avéré être une excuse, mais c'est tout à fait logique. Nous déterminons la grammaire de la forme verbale par les quatre derniers caractères. "Plomb" est quelque chose comme "au milieu", donc le choix est relativement logique. C'est plus intéressant avec "maman": "maman" était dans le cas prépositionnel et est devenu le summum de cette phrase.
Si nous essayons d'interpréter tout sur la base des résultats de l'analyse, nous obtiendrions quelque chose comme "au milieu d'une maman (dont la maman? Qui est cette maman?) Des centaines de roubles." Pas tout à fait ce que c'était au début. Nous devons en quelque sorte faire face à cela. Et nous avons trouvé comment.
Dans la pyramide d'analyse, la syntaxe est construite au-dessus de la morphologie, basée sur des balises morphologiques. Voici un exemple de manuel d'un linguiste L.V. Shcherby à cet égard:
"Gloky cuzdra shteko budlanula bokra et petit garçon aux cheveux bouclés."L'analyse de cette proposition ne pose pas de problème. Pourquoi? Parce que nous, en tant que tagueur UDPipe, regardons la fin d'un mot et comprenons à quelle partie du discours il fait référence et de quelle forme il s'agit. L'histoire avec «traduire» comme excuse contredit complètement notre intuition, mais elle s'avère logique au moment où nous essayons de faire de même avec des mots inconnus. Une personne pourrait penser de la même façon.
Nous évaluerons le tagueur UDPipe séparément. Si cela ne nous convient pas, nous prendrons un autre tagueur - puis pour construire l'analyse syntaxique sur un autre balisage morphologique.
Balisage à partir de texte brut (score CoNLL17 F1)- formes d'or: 301639 ,
- upostag: 98,15% ,
- xpostag: 99,89% ,
- exploits: 93,97% ,
- alltags: 93,44% ,
- lemmes: 96,68%
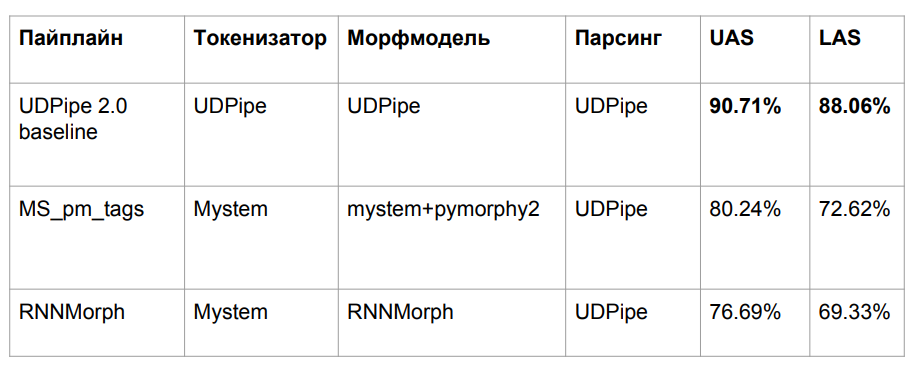
La qualité morphologique de UDPipe 2.0 n'est pas mauvaise. Mais pour la langue russe, c'est mieux. L'analyseur Mystem (le
développement de Yandex ) obtient de meilleurs résultats dans la détermination des parties de la parole que UDPipe. De plus, d'autres analyseurs sont plus difficiles à implémenter dans un projet python, et ils fonctionnent plus lentement avec une qualité comparable à Mystem. ,
.
UDPipe. . , Mystem . , « » «» — «», «». . , «», (), , . :
- « » —
- « » — ..
- « - » — (- )
Dans de tels cas, Mystem donne honnêtement à toute la chaîne:
m.analyze(" ")
[{'analysis': [{'lex': '', 'gr': 'PART='}], 'text': ''},
{'text': ' '},
{'analysis': [{'lex': '', 'gr': 'S,,=(,|,|,)'}],
'text': ''},
{'text': '\n'}]
Mais nous ne pouvons pas envoyer toute la chaîne de tuyaux à UDPipe, mais nous devons spécifier une meilleure balise. Comment le choisir? Si vous ne touchez à rien, je veux prendre le premier, ça marchera peut-être. Mais les balises sont triées alphabétiquement en fonction des noms anglais, donc notre choix sera proche de l'aléatoire, et certaines analyses perdent presque la chance d'être les premières.
Il y a un analyseur qui peut donner la meilleure option - Pymorphy2. Mais avec une analyse de la morphologie, il est pire. De plus, il donne le meilleur mot hors contexte. Pymorphy2 ne donnera qu'une seule analyse pour "pas de réalisateur", "voir réalisateur" et "réalisateur". Ce ne sera pas aléatoire, mais vraiment le meilleur en probabilité, qui en pymorphie2 était considéré sur un corps séparé de textes. Mais un certain pourcentage d’analyses incorrectes des textes de combat sera garanti, tout simplement parce qu’elles peuvent contenir des phrases aux formes réelles différentes: «Je vois le réalisateur» et «les réalisateurs sont venus à la réunion» et «il n’y a pas de réalisateur». Une probabilité d'analyse contextuelle ne nous convient pas.
Comment obtenir contextuellement le meilleur ensemble de balises? Utilisation de l'analyseur
RNNMorph . Peu de gens ont entendu parler de lui, mais l'année dernière, il a remporté le concours des analyseurs morphologiques, organisé dans le cadre de la conférence Dialogue.
RNNMorph a son propre problème: il n'a pas de tokenisation. Si Mystem peut symboliser du texte brut, alors RNNMorph requiert une liste de jetons à l'entrée. Pour arriver à la syntaxe, vous devrez d'abord utiliser un tokenizer externe, puis donner le résultat à RNNMorph et ensuite seulement nourrir la morphologie résultante à l'analyseur syntaxique.
Voici les options que nous avons. Nous ne refuserons pas pour l'instant l'analyse sans contexte de pymorphy2 sur des cas discutables dans le Mystème - du coup, elle ne sera pas loin derrière RNNMorph. Bien que si nous les comparons uniquement au niveau de la qualité du balisage morphologique (données de
MorphoRuEval-2017 ), la perte est importante - environ 15%, si nous prenons la précision selon les mots.
Ensuite, nous devons convertir la sortie de Mystem au format que UDPipe comprend - conllu. Et encore une fois, c'est un problème, même jusqu'à deux. Purement technique - les lignes ne correspondent pas. Et conceptuel - il n'est pas toujours clair de savoir comment les comparer. Face à deux balises différentes de données de langage, vous rencontrerez très certainement le problème de la correspondance des balises, voir les exemples ci-dessous. Les réponses à la question «quelle balise se trouve ici» peuvent être différentes, et probablement la bonne réponse dépend de la tâche. En raison de cette incohérence, l'appariement des systèmes de balisage n'est pas une tâche facile en soi.
Comment convertir? Il existe
russian_tagsets _
package - un package pour Python qui peut convertir différents formats. Il n'y a pas de traduction du format d'émission de Mystem vers Conllu, qui est accepté dans les dépendances universelles, mais il y a une traduction vers conllu, par exemple, du format de balisage du corpus national de la langue russe (et vice versa). L'auteur du paquet (d'ailleurs, il est l'auteur de pymorphy2) a écrit une chose merveilleuse directement dans la documentation: "Si vous ne pouvez pas utiliser ce paquet, ne l'utilisez pas." Il ne l'a pas fait parce que le programmeur krivorukov (c'est un excellent programmeur!), Mais parce que si vous avez besoin de vous convertir l'un à l'autre, vous risquez de rencontrer des problèmes en raison de l'incohérence linguistique des conventions de balisage.
Voici un exemple. L'école a appris la "catégorie de condition" (froid, nécessaire). Certains disent que c'est un adverbe, d'autres disent un adjectif. Vous devez convertir cela, et vous ajoutez quelques règles, mais ne réalisez toujours pas une correspondance sans ambiguïté entre un format et un autre.
Un autre exemple: un engagement (soit quelqu'un a fait quelque chose ou a fait quelque chose avec quelqu'un). "Petya a tué quelqu'un" ou "Petya a été tué". «Vasya prend des photos» - «Vasya prend des photos» (c'est-à-dire, en fait, «Vasya est photographiée»). Il y a aussi une garantie médiale dans SynTagRus - nous ne creuserons même pas ce que c'est et pourquoi. Mais dans Mystem, ce n'est pas le cas. Si vous devez en quelque sorte amener un format à un autre, c'est une impasse.
Nous avons plus ou moins honnêtement suivi l'avis de l'auteur du paquet russian_tagsets - n'avons pas utilisé son développement, car nous n'avons pas trouvé la paire requise dans la liste des formats de correspondance. En conséquence, nous avons écrit notre convertisseur personnalisé de Mystem en Conllu et avons continué.
Nous connectons le tagueur tiers et l'analyseur UDPipe
Après toutes les aventures, nous avons pris trois algorithmes, décrits ci-dessus:
- UDPipe de base
- Mym avec désambiguïsation d'étiquette de pymorphy2
- RNNMorph
Nous avons perdu de la qualité pour une raison assez évidente. Nous avons pris le modèle UDPipe formé sur une morphologie, mais avons glissé une autre morphologie sur une entrée. Le problème classique de l'inadéquation des données entre le train et le test est le résultat d'une baisse de qualité.
Nous avons essayé d'aligner nos outils de marquage morphologique automatique avec le balisage SynTagRus, qui a été marqué manuellement. Nous n'avons pas réussi, donc, dans le cas de la formation SynTagRus, nous remplacerons tous les marquages morphologiques manuels par ceux obtenus à partir de Mystem et de pymorphy2 dans un cas et de RNNMorph dans un autre. Dans un cas validé balisé à la main, nous sommes obligés de changer le marquage manuel en automatique, car «au combat» nous n'obtiendrons jamais de marquage manuel.
En conséquence, nous avons formé l'analyseur UDPipe (uniquement l'analyseur) avec les mêmes hyperparamètres que la ligne de base. Ce qui était responsable de la syntaxe - l'ID de sommet, dont dépend le type de connexion - nous sommes partis, nous avons tout changé.
Résultats
De plus, je vais nous comparer avec Syntaxnet et d'autres algorithmes. Les organisateurs de la tâche partagée CoNLL ont dévoilé la partition SynTagRus (train / dev / test 80/10/10). Nous en avons initialement pris un autre (train / test 70/30), donc les données ne coïncident pas toujours avec nous, bien qu'elles aient été reçues sur le même cas. De plus, nous avons pris la dernière version (de février à mars) du référentiel SynTagRus - cette version est légèrement différente de celle de la compétition. Les données pour ce qui n'a pas décollé sont données dans des articles où la répartition était la même que dans la compétition - ces algorithmes sont marqués d'un astérisque dans le tableau.
Voici les résultats finaux:
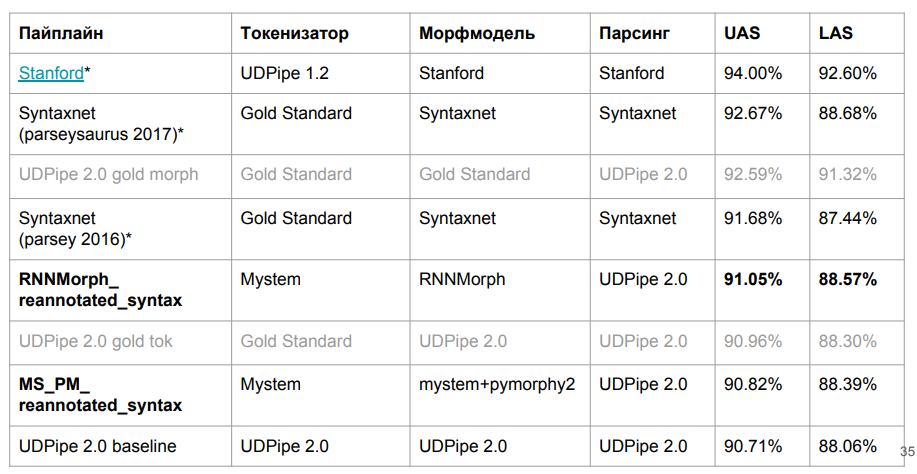
RNNMorph s'est avéré vraiment meilleur - non pas dans le sens absolu, mais dans le rôle d'un outil auxiliaire pour obtenir une métrique commune en fonction des résultats de l'analyse (par rapport à Mystem + pymorphy2). Autrement dit, meilleure est la morphologie, meilleure est la syntaxe, mais la séparation "syntaxique" est beaucoup moins importante que la séparation morphologique. Notez également que nous ne sommes pas allés très loin du modèle de référence, ce qui signifie qu'en morphologie, il n'y en avait vraiment pas autant que prévu.
Je me demande combien de mensonges sur la morphologie? Est-il possible d'obtenir une amélioration fondamentale de l'analyseur syntaxique grâce à une morphologie idéale? Pour répondre à cette question, nous avons conduit UDPipe 2.0 sur la tokenisation et la morphologie qui étaient parfaitement calibrées (en utilisant la norme de balisage manuel standard). Nous avons obtenu une certaine marge (voir la ligne sur Gold Morph dans le tableau; il s'avère que + 1,54% de RNNMorph_reannotated_syntax) de ce que nous avions, y compris du point de vue de déterminer correctement le type de connexion. Si quelqu'un écrit un analyseur morphologique absolument parfait de la langue russe, il est probable que les résultats que nous obtenons en utilisant un analyseur syntaxique abstrait augmenteront également. Et nous comprenons approximativement le plafond (au moins le plafond de cette architecture et de la combinaison de paramètres que nous avons utilisés pour UDPipe - il est indiqué dans la troisième ligne du tableau ci-dessus).
Fait intéressant, nous avons presque atteint la version Syntaxnet dans la métrique LAS. Il est clair que nous avons des données légèrement différentes, mais en principe, elles sont toujours comparables. La tokenisation Syntaxnet est "or", et pour nous - de Mystem. Nous avons écrit le wrapper susmentionné dans Mystem, mais l'analyse se fait toujours automatiquement; Mystem se trompe probablement aussi quelque part. À partir de la ligne du tableau «Jeton d'or UDPipe 2.0», on peut voir que si vous prenez le jeton UDPipe et or par défaut, il perd encore un peu Syntaxnet-2017. Mais cela fonctionne beaucoup plus rapidement.
Ce que personne n'a atteint, c'est
l'analyseur de Stanford . Il est conçu de la même manière que Syntaxnet, il fonctionne donc longtemps. Dans UDPipe, nous suivons simplement la pile. L'architecture de l'analyseur Stanford et de Syntaxnet a un concept différent: ils génèrent d'abord un graphe orienté complet, puis l'algorithme fonctionne pour laisser le squelette (arbre couvrant minimal) qui sera le plus probable. Pour ce faire, il passe par des combinaisons, et cette recherche n'est plus linéaire, car vous vous tournerez vers un mot plus d'une fois. Malgré le fait que depuis longtemps, du point de vue de la science pure, au moins pour la langue russe, c'est une architecture plus efficace. Nous avons essayé de soulever ce développement académique pendant deux jours - hélas, cela n'a pas fonctionné. Mais sur la base de son architecture, il est clair qu'il ne fonctionne pas rapidement.
Quant à notre approche - bien que nous n'ayons pratiquement pas augmenté de manière métrique, maintenant tout va bien avec la «mère».
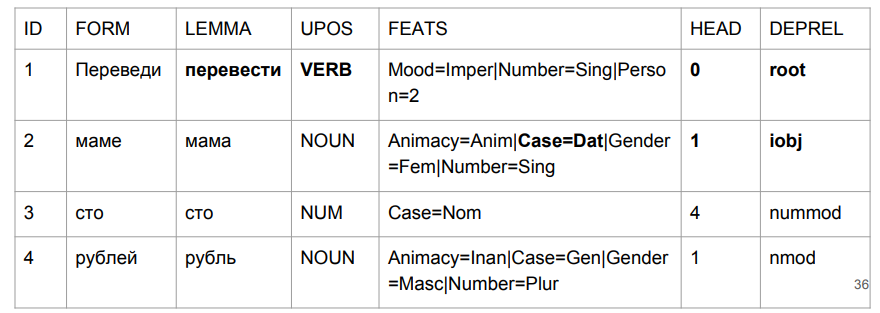
Dans la phrase «traduire cent roubles à maman», «traduire» est vraiment un verbe d'humeur impérative. "Maman" a obtenu son étui datif. Et la chose la plus importante pour nous est notre étiquette (iobj), un objet indirect (destination). Bien que la croissance en nombre soit négligeable, nous avons bien géré le problème avec lequel la tâche a commencé.
Bonus track: ponctuation
Si nous revenons aux données réelles, il s'avère que la syntaxe dépend de la ponctuation. Prenez la phrase «vous ne pouvez pas faire miséricorde». Ce qui ne peut pas être fait exactement - «exécuter» ou «avoir pitié» - dépend de la position de la virgule. Même si nous mettons le linguiste pour baliser les données, il aura besoin de la ponctuation comme d'une sorte d'outil auxiliaire. Il ne pouvait pas se passer d'elle.
Prenons les phrases «Peter bonjour» et «Peter bonjour» et regardons leur analyse par le modèle de base-UDPipe. On laisse de côté les problèmes qui, selon ce modèle, alors:
1) "Petya" est un nom féminin;
2) "Petya" est (à en juger par l'ensemble de balises) la forme initiale, mais en même temps, son lemme n'est pas censé être "Petya".
C'est ainsi que le résultat change en raison de la virgule, avec son aide, nous obtenons quelque chose de similaire à la vérité.
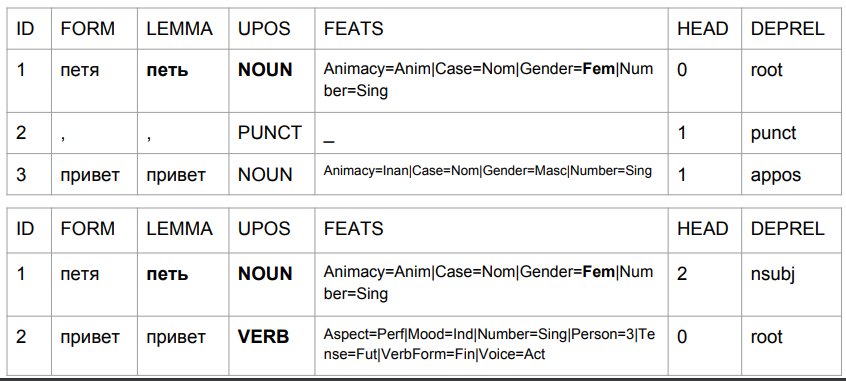
Dans le second cas, «Petya» est un sujet et «bonjour» est un verbe. Revenons à prédire la forme d'un mot en fonction des quatre derniers caractères. Dans l'interprétation de l'algorithme, il ne s'agit pas de «salutations Petya», mais de «salutations Petya». Tapez "Petya chante" ou "Petya viendra". L'analyse est tout à fait compréhensible: en russe, il ne peut pas y avoir de virgule entre le sujet et le prédicat. Par conséquent, si la virgule est, c'est le mot "bonjour", et s'il n'y a pas de virgule, cela pourrait bien être quelque chose comme "Petya Privet".
Nous le rencontrerons assez souvent en production, car les correcteurs orthographiques corrigeront l'orthographe, mais pas la ponctuation. Pour aggraver les choses, l'utilisateur peut définir des virgules de manière incorrecte, et notre algorithme en tiendra compte pour comprendre le langage naturel. Quelles sont les solutions possibles ici? Nous voyons deux options.
La première option consiste à faire comme ils le font parfois lors de la traduction de la parole en texte. Initialement, il n'y a pas de ponctuation dans un tel texte, il est donc restauré via le modèle. La sortie est un matériau relativement compétent en termes de règles de la langue russe, ce qui aide l'analyseur syntaxique à fonctionner correctement.
La deuxième idée est quelque peu plus audacieuse et contredit les leçons scolaires de la langue russe. Il s'agit de travailler sans ponctuation: si tout à coup l'entrée est ponctuée, on la supprimera de là. Nous supprimerons également absolument toute ponctuation du corps d'entraînement. Nous supposons que la langue russe existe sans ponctuation. Seuls les points pour la division en phrases.
Techniquement, c'est assez simple, car nous ne modifions pas les nœuds finaux dans l'arbre de syntaxe. Nous ne pouvons pas avoir tel que le signe de ponctuation soit le haut. Il s'agit toujours d'un nœud d'extrémité, à l'exception du signe%, qui pour une raison quelconque dans SynTagRus est le sommet du chiffre précédent (50% dans SynTagRus est marqué comme% - sommet et 50 - dépendant).
Testons en utilisant le modèle Mystem (+ pymorphy 2).

Il est extrêmement important pour nous de ne pas donner le modèle de texte de ponctuation sans ponctuation. Mais si nous donnons toujours le texte sans ponctuation, alors nous serons en première ligne et obtiendrons au moins des résultats acceptables. Si le texte sans ponctuation et le modèle fonctionnent sans ponctuation, alors en ce qui concerne la ponctuation idéale et le modèle de ponctuation, la baisse ne sera que d'environ 3%.
Que faire à ce sujet? Nous pouvons nous attarder sur ces chiffres - obtenus en utilisant le modèle sans ponctuation et la purification de la ponctuation. Ou trouvez une sorte de classificateur pour restaurer la ponctuation. Nous n'atteindrons pas les nombres idéaux (ceux avec ponctuation sur le modèle de ponctuation), parce que l'algorithme de récupération de ponctuation fonctionne avec une certaine erreur, et les nombres «idéaux» ont été calculés sur SynTagRus absolument pur. Mais si nous allons écrire un modèle qui rétablit la ponctuation, les progrès nous rembourseront-ils? La réponse n'est pas encore évidente.
Nous pouvons réfléchir longtemps à l'architecture de l'analyseur, mais nous devons nous rappeler qu'en fait il n'y a pas de grand corpus syntaxiquement marqué de textes web. Son existence permettrait de mieux résoudre les problèmes réels. Jusqu'à présent, nous étudions le corps de textes édités absolument alphabétisés - et nous perdons de la qualité en obtenant des textes personnalisés au combat, qui sont souvent écrits analphabètes.
Conclusion
Nous avons examiné l'utilisation de divers algorithmes d'analyse syntaxique basés sur la grammaire des dépendances, appliqués à la langue russe. Il s'est avéré qu'en termes de rapidité, de commodité et de qualité de travail, UDPipe s'est avéré être le meilleur outil. Son modèle de référence peut être amélioré si les étapes de la tokenisation et de l'analyse morphologique sont attribuées à d'autres analyseurs tiers: cette astuce permet de corriger le comportement incorrect du tagueur et, par conséquent, de l'analyseur dans les cas importants pour l'analyse.
Nous avons également analysé le problème de la relation entre la ponctuation et l'analyse et sommes parvenus à la conclusion que dans notre cas, la ponctuation avant l'analyse syntaxique est préférable de supprimer.
Nous espérons que les points d'application abordés dans notre article vous aideront à utiliser l'analyse syntaxique pour résoudre vos problèmes aussi efficacement que possible.
L'auteur remercie Nikita Kuznetsova et Natalya Filippova pour leur aide dans la préparation de l'article; pour l'assistance dans l'étude - Anton Alekseev, Nikita Kuznetsov, Andrei Kutuzov, Boris Orekhov et Mikhail Popov.