Depuis de nombreuses années, Mail.ru organise des championnats d'apprentissage automatique, chaque fois que la tâche est intéressante à sa manière et complexe à sa manière. C'est ma quatrième participation à des compétitions, j'aime beaucoup la plateforme et l'organisation, et c'est avec les bootcamps que mon chemin vers l'apprentissage automatique compétitif a commencé, mais j'ai réussi à prendre la première place pour la première fois. Dans l'article, je vais vous dire comment montrer un résultat stable sans recyclage soit sur le classement public, soit sur des échantillons retardés, si la partie test est significativement différente de la partie formation des données.
Défi
Le texte intégral de la tâche est disponible sur →
lien . En bref: il y a 10 Go de données, où chaque ligne contient trois types json de "clé: compteur", une certaine catégorie, un certain horodatage et un ID utilisateur. Plusieurs entrées peuvent correspondre à un seul utilisateur. Il est nécessaire de déterminer à quelle classe l'utilisateur appartient, la première ou la seconde. La métrique de qualité pour le modèle est ROC-AUC, elle est bien écrite à ce sujet dans le blog d'Alexander Dyakonov
[1] .
Exemple d'entrée de fichier
00000d2994b6df9239901389031acaac 5 {"809001":2,"848545":2,"565828":1,"490363":1} {"85789":1,"238490":1,"32285":1,"103987":1,"16507":2,"6477":1,"92797":2} {} 39
Solution
La première idée qui émerge d'un scientifique des données qui a réussi à télécharger un ensemble de données est de transformer les colonnes json en une matrice clairsemée. À ce stade, de nombreux participants ont rencontré des problèmes de manque de RAM. Lors du déploiement d'une seule colonne en python, la consommation de mémoire était supérieure à celle disponible sur un ordinateur portable moyen.
Quelques statistiques sèches. Le nombre de clés uniques dans chaque colonne est 2053602, 20275, 1057788. De plus, dans la partie train et dans la partie test, il n'y a que 493866, 20268, 141931. 427994 utilisateurs uniques dans le train et 181024 dans la partie test. Environ 4% de la classe 1 dans la partie formation.
Comme vous pouvez le voir, nous avons beaucoup de signes, les utiliser tous est un moyen évident de s'équiper dans le train, parce que, par exemple, les arbres de décision utilisent des combinaisons de signes, et il existe des combinaisons encore plus uniques d'un si grand nombre de signes et presque tous n'existent que dans la partie formation données ou en test. Cependant, l'un des modèles de base que j'avais était lightgbm avec colsample ~ 0,1 et une régularisation très stricte. Cependant, malgré les énormes paramètres de régularisation, il a montré un résultat instable dans les parties publiques et privées, comme il s'est avéré après la fin de la compétition.
La deuxième pensée de la personne qui a décidé de participer à ce concours serait probablement de collecter le train et de tester, en agrégeant les informations par identifiants. Par exemple, le montant. Ou un maximum. Et ici, il s'avère que deux choses très intéressantes que Mail.ru a imaginées pour nous. Premièrement, le test peut être classé avec une très grande précision. Même selon les statistiques sur le nombre d'entrées pour cuid et le nombre de clés uniques dans json, le test dépasse considérablement le train. Le classificateur de base a donné 0,9+ roc-auc en reconnaissance de test. Deuxièmement, les compteurs n'ont aucun sens, presque tous les modèles sont passés du passage des compteurs aux signes binaires de la forme: il n'y a / pas de clé. Même les arbres, qui en théorie ne devraient pas être pires du fait qu'au lieu d'une unité il y a un certain nombre, semblent être recyclés pour les compteurs.
Les résultats du classement public dépassaient largement ceux de la validation croisée. Cela était apparemment dû au fait qu'il était plus facile pour le modèle de construire le classement de deux records dans le test que dans le train, car un plus grand nombre de panneaux donnait plus de termes pour le classement.
À ce stade, il est devenu tout à fait clair que la validation dans ce concours n'est pas une chose simple et ni les informations publiques ni les CV des autres participants, qui pourraient être trompés en leurre dans le chat officiel
[2] . Pourquoi est-ce arrivé? Il semble que le train et le test soient séparés par le temps, ce qui a ensuite été confirmé par les organisateurs.
Tout membre expérimenté de kaggle avisera immédiatement la validation contradictoire
[3] , mais ce n'est pas si simple. Malgré le fait que la précision du classificateur pour le train et le test soit proche de 1 par le métrique roc-auc, il n'y a pas beaucoup d'entrées similaires dans le train. J'ai essayé de résumer des échantillons agrégés en cuid avec la même cible pour augmenter le nombre d'enregistrements avec un grand nombre de clés uniques dans json, mais cela a causé des inconvénients à la fois en validation croisée et en public, et j'avais peur d'utiliser de tels modèles.
Il y a deux façons: rechercher des valeurs éternelles avec un apprentissage non supervisé ou essayer de prendre des fonctionnalités plus importantes pour le test. Je suis allé dans les deux sens, en utilisant TruncatedSVD pour non supervisé et en sélectionnant les fonctionnalités par fréquence dans le test.
La première étape, cependant, j'ai fait un auto-encodeur profond, mais je me suis trompé, en prenant deux fois la même matrice, je n'ai pas pu corriger l'erreur et utiliser l'ensemble complet des signes: le tenseur d'entrée ne s'adaptait pas à la mémoire du GPU à aucune taille de couche dense. J'ai trouvé une erreur et plus tard, je n'ai pas essayé de coder les fonctionnalités.
J'ai généré SVD de toutes les manières imaginatives: sur le jeu de données d'origine avec cat_feature et la sommation suivante par cuid. Pour chaque colonne séparément. Par tf-idf sur json comme sac de mots
[4] (n'a pas aidé).
Pour une plus grande variété, j'ai essayé de sélectionner un petit nombre de caractéristiques dans le train, en utilisant A-NOVA pour la partie train de chaque pli en validation croisée.
Les modèles
Les principaux modèles de base: lightgbm, vowpal wabbit, xgboost, SGD. De plus, j'ai utilisé plusieurs architectures de réseaux de neurones. Dmitry Nikitko, qui était à la première place du classement public, a conseillé d'utiliser
HashEmbeddings , ce modèle après une sélection de paramètres a montré un bon résultat et amélioré l'ensemble.
Un autre modèle de réseau neuronal avec recherche d'interactions (style machine de factorisation) entre 3-4-5 colonnes de données (trois entrées de gauche), statistiques numériques (4 entrées), matrice SVD (5 entrées).
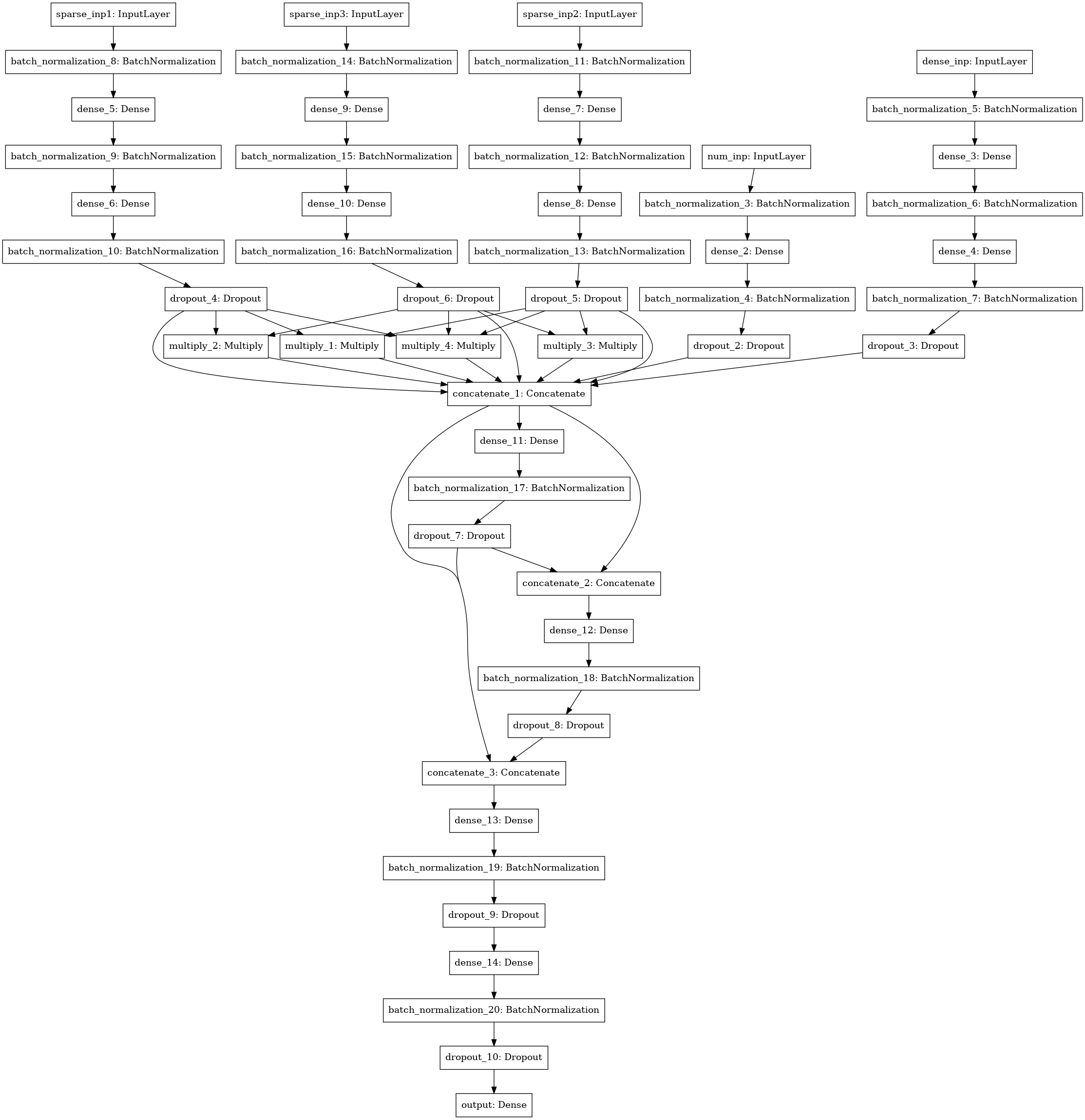
Ensemble
J'ai compté tous les modèles par pli, en faisant la moyenne des prévisions de test à partir de modèles formés sur divers plis. Les prévisions de train ont été utilisées pour l'empilement. Le meilleur résultat a été montré par la pile de niveau 1 utilisant xgboost sur les prédictions des modèles de base et 250 attributs de chaque colonne json, sélectionnés en fonction de la fréquence à laquelle l'attribut se rencontrait dans le test.
J'ai passé environ 30 heures de mon temps sur la solution, en comptant sur un serveur avec 4 cœurs core-i7, 64 gigaoctets de RAM et un GTX 1080. En conséquence, ma solution s'est révélée assez stable et je suis passé de la troisième place du classement public au premier privé.
Une partie substantielle du code est disponible sur un bitbucket sous forme d'ordinateurs portables
[5] .
Je tiens à remercier Mail.ru pour les concours intéressants et les autres participants pour la communication intéressante dans le groupe!
[1]
ROC-AUC sur le blog d'Aleksandrov Dyakonov[2]
Officiel Chat ML BootCamp officiel[3]
Validation contradictoire[4]
sac de mots[5]
code source pour la plupart des modèles