
Les tâches de stockage et d'accès aux données sont un point douloureux pour tout système d'information. Même un système de stockage bien conçu (ci-après dénommé SHD) pendant le fonctionnement révèle des problèmes associés à des performances réduites. Une attention particulière doit être accordée à un ensemble de problèmes de mise à l'échelle lorsque la quantité de ressources impliquées approche des limites établies fixées par les développeurs de stockage.
La raison fondamentale de l'apparition de ces problèmes est l'architecture traditionnelle basée sur une liaison étroite aux caractéristiques matérielles des périphériques de stockage utilisés. La plupart des clients choisissent toujours la méthode de stockage et d'accès aux données, en tenant compte des caractéristiques des interfaces physiques (SAS / SATA / SCSI), et non des besoins réels des applications utilisées.
Il y a une douzaine d'années, c'était une décision logique. Les administrateurs système ont soigneusement sélectionné des périphériques de stockage d'informations avec les spécifications requises, par exemple, SATA / SAS, et comptaient sur l'obtention d'un niveau de performances basé sur les capacités matérielles des contrôleurs de disque. Le combat était pour le volume de caches de contrôleurs RAID et pour les options qui empêchent la perte de données. Or, cette approche pour résoudre le problème n'est pas optimale.
Dans l'environnement actuel, lors du choix des systèmes de stockage, il est logique de commencer non pas à partir des interfaces physiques, mais à partir des performances exprimées en IOPS (le nombre d'opérations d'E / S par seconde). L'utilisation de la virtualisation vous permet d'utiliser de manière flexible les ressources matérielles existantes et de garantir le niveau de performances requis. Pour notre part, nous sommes prêts à fournir des ressources avec les caractéristiques vraiment nécessaires à l'application.
Virtualisation du stockage
Avec le développement des systèmes de virtualisation, il était nécessaire de trouver une solution innovante pour le stockage et l'accès aux données, tout en assurant la tolérance aux pannes. Ce fut le point de départ de la création de SDS (Software-Defined Storage). Pour répondre aux besoins de l'entreprise, ces référentiels ont été conçus avec la séparation des logiciels et du matériel.
L'architecture SDS est fondamentalement différente de l'architecture traditionnelle. La logique de stockage est devenue abstraite au niveau logiciel. L'organisation du stockage est devenue plus aisée grâce à l'unification et la virtualisation de chacun des composants d'un tel système.
Quel est le principal facteur entravant la mise en œuvre de la FDS partout? Ce facteur est le plus souvent une évaluation incorrecte des besoins des applications utilisées et une évaluation incorrecte des risques. Pour une entreprise, le choix de la solution dépend du coût de mise en œuvre, en fonction des ressources actuelles consommées. Peu de gens pensent - que se passera-t-il lorsque la quantité d'informations et les performances requises dépasseront les capacités de l'architecture sélectionnée. Penser sur la base du principe méthodologique «il ne faut pas multiplier l'existant sans nécessité», mieux connu sous le nom de «lame d'Occam», détermine le choix en faveur des solutions traditionnelles.
Seuls quelques-uns comprennent que le besoin d'évolutivité et de fiabilité du stockage des données est plus important qu'il n'y paraît à première vue. L'information est une ressource et, par conséquent, le risque de sa perte doit être assuré. Que se passera-t-il lorsqu'un système de stockage traditionnel tombe en panne? Vous devrez utiliser la garantie ou acheter un nouvel équipement. Et si le système de stockage est interrompu ou s'il a mis fin à la "durée de vie" (le soi-disant EOL - End-of-Life)? Cela peut être un jour noir pour toute organisation qui ne peut pas continuer à utiliser ses propres services familiers.
Il n'y a aucun système qui n'a pas un seul point de défaillance. Mais il existe des systèmes qui peuvent facilement survivre à la défaillance d'un ou de plusieurs composants. Les systèmes de stockage virtuels et traditionnels ont été créés en tenant compte du fait que tôt ou tard une panne se produira. C'est juste la «limite de force» des systèmes de stockage traditionnels définis dans le matériel, mais dans les systèmes de stockage virtuels, elle est déterminée dans la couche logicielle.
Intégration
Les changements spectaculaires dans l'infrastructure informatique sont toujours un phénomène indésirable, lourd de temps d'arrêt et de perte de fonds. Seule la bonne mise en œuvre de nouvelles solutions permet d'éviter des conséquences négatives et d'améliorer le travail des services. C'est pourquoi Selectel a conçu et
lancé le cloud basé sur VMware , un leader reconnu sur le marché de la virtualisation. Le service que nous créons permettra à chaque entreprise de résoudre l'ensemble des tâches d'infrastructure, y compris le stockage de données.
Nous vous dirons exactement comment nous avons décidé du choix d'un système de stockage, ainsi que les avantages que ce choix nous a procurés. Bien sûr, les systèmes de stockage traditionnels et les FDS ont été pris en compte. Pour comprendre clairement tous les aspects du fonctionnement et des risques, nous proposons un aperçu plus approfondi du sujet.
Au stade de la conception, les exigences suivantes ont été imposées aux systèmes de stockage:
- tolérance aux pannes;
- performance
- mise à l'échelle
- la capacité de garantir la vitesse;
- fonctionnement correct dans l'écosystème VMware.
L'utilisation de solutions matérielles traditionnelles n'a pas pu fournir le niveau d'évolutivité requis, car il est impossible d'augmenter constamment le volume de stockage en raison des limitations architecturales. La réservation au niveau d'un centre de données entier a également été très difficile. C'est pourquoi nous avons tourné notre attention vers la FDS.
Il existe plusieurs solutions logicielles sur le marché des SDS qui nous conviendraient pour la construction d'un cloud basé sur VMware vSphere. Parmi ces solutions, on peut noter:
- Dell EMC ScaleIO;
- SAN virtuel hyperconvergé Datacore;
- HPE StoreVirtual.
Ces solutions peuvent être utilisées avec VMware vSphere, mais elles ne s'intègrent pas à l'hyperviseur et s'exécutent séparément. Par conséquent, le choix a été fait en faveur de VMware vSAN. Examinons en détail à quoi ressemble l'architecture virtuelle d'une telle solution.
L'architecture
Image tirée de la documentation officielleContrairement aux systèmes de stockage traditionnels, toutes les informations ne sont stockées à aucun moment. Les données de la machine virtuelle sont réparties uniformément entre tous les hôtes et la mise à l'échelle se fait en ajoutant des hôtes ou en y installant des lecteurs de disque supplémentaires. Deux options de configuration sont prises en charge:
- Configuration AllFlash (uniquement les disques SSD, à la fois pour le stockage des données et pour le cache);
- Configuration hybride (stockage magnétique et cache à semi-conducteurs).
La procédure d'ajout d'espace disque ne nécessite pas de paramètres supplémentaires, par exemple, la création d'un LUN (numéro d'unité logique, numéros de disques logiques) et la définition de l'accès à ceux-ci. Dès que l'hôte est ajouté au cluster, son espace disque devient disponible pour toutes les machines virtuelles. Cette approche présente plusieurs avantages importants:
- absence de lien avec le fabricant de l'équipement;
- augmentation de la tolérance aux pannes;
- assurer l'intégrité des données en cas de panne;
- centre de contrôle unique depuis la console vSphere;
- mise à l'échelle horizontale et verticale pratique.
Cependant, cette architecture impose des exigences élevées à l'infrastructure réseau. Pour garantir un débit maximal, dans notre cloud, le réseau est construit sur le modèle Spine-Leaf.
Réseau
Le modèle de réseau traditionnel à trois niveaux (cœur / agrégation / accès) présente un certain nombre d'inconvénients importants. Un exemple frappant est les limitations des protocoles Spanning Tree.
Le modèle Spine-Leaf n'utilise que deux niveaux, ce qui offre les avantages suivants:
- distance prévisible entre les appareils;
- le trafic suit le meilleur itinéraire;
- facilité de mise à l'échelle;
- Exclusion des restrictions du protocole L2.
Une caractéristique clé d'une telle architecture est qu'elle est optimisée pour le passage de trafic "horizontal". Les paquets de données passent par un seul bond, ce qui permet une estimation claire des retards.
Une connexion physique est fournie à l'aide de plusieurs liaisons 10 GbE par serveur, dont la bande passante est combinée à l'aide du protocole d'agrégation. Ainsi, chaque hôte physique reçoit un accès haut débit à tous les objets de stockage.
L'échange de données est mis en œuvre à l'aide d'un protocole propriétaire créé par VMware, qui permet un fonctionnement rapide et fiable du réseau de stockage sur le transport Ethernet (à partir de 10 GbE et plus).
Le passage au modèle objet du stockage de données a permis un ajustement flexible de l'utilisation du stockage en fonction des exigences des clients. Toutes les données sont stockées sous forme d'objets qui sont répartis d'une certaine manière entre les hôtes du cluster. Nous clarifions les valeurs de certains paramètres qui peuvent être contrôlés.
Tolérance aux pannes
- FTT (échecs de tolérance). Indique le nombre de pannes d'hôte que le cluster est capable de gérer sans interrompre le fonctionnement normal.
- FTM (Failure Tolerance Method). Méthode permettant d'assurer la tolérance aux pannes au niveau du disque.
a. Miroir
Image tirée du blog VMware.
Représente une duplication complète d'un objet et les répliques sont toujours situées sur différents hôtes physiques. L'analogue le plus proche de cette méthode est RAID-1. Son utilisation permet au cluster de traiter régulièrement jusqu'à trois pannes de n'importe quel composant (disques, hôtes, perte de réseau, etc.). Ce paramètre est configuré en définissant l'option FTT.
Par défaut, cette option a la valeur 1 et 1 réplique est créée pour l'objet (seulement 2 instances sur des hôtes différents). À mesure que la valeur augmente, le nombre de copies sera N + 1. Ainsi, avec une valeur maximale de FTT = 3, 4 instances de l'objet seront sur des hôtes différents.
Cette méthode vous permet d'obtenir des performances maximales au détriment de l'efficacité de l'espace disque. Il peut être utilisé dans les configurations hybrides et AllFlash.
b. Codage d'effacement (analogique de RAID 5/6).
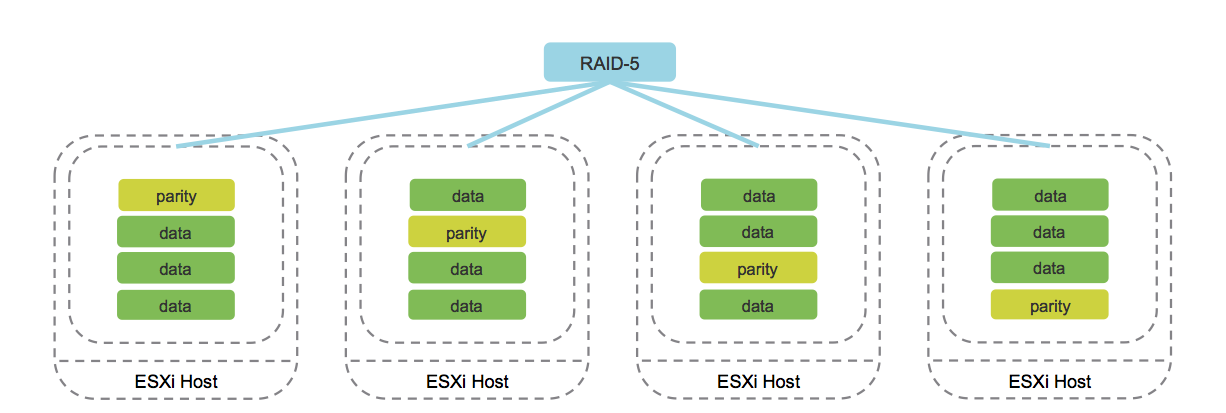
Image tirée du blog cormachogan.com.
Le travail de cette méthode est pris en charge exclusivement sur les configurations AllFlash. Au cours de l'enregistrement de chaque objet, les blocs de parité correspondants sont calculés, ce qui permet de récupérer uniquement les données en cas de panne. Cette approche économise considérablement l'espace disque par rapport à la mise en miroir.
Bien entendu, le fonctionnement de cette méthode augmente les frais généraux, ce qui se traduit par une diminution de la productivité. Néanmoins, étant donné les performances de la configuration AllFlash, cet inconvénient est nivelé, ce qui rend l'utilisation du codage d'effacement une option acceptable pour la plupart des tâches.
En outre, VMware vSAN introduit le concept de «domaines de défaillance», qui sont un regroupement logique de racks de serveurs ou de paniers de disques. Dès que les éléments nécessaires sont regroupés, cela conduit à la répartition des données entre les différents nœuds en tenant compte des domaines de défaillance. Cela permet au cluster de survivre à la perte d'un domaine entier, car toutes les répliques correspondantes des objets seront situées sur d'autres hôtes dans un domaine de défaillance différent.
Le plus petit domaine d'échec est un groupe de disques, qui est un lecteur de disque connecté de manière logique. Chaque groupe de disques contient deux types de supports: le cache et la capacité. En tant que média de cache, le système permet d'utiliser uniquement des disques SSD, et les disques magnétiques et SSD peuvent servir de supports de capacité. La mise en cache des supports permet d'accélérer les disques magnétiques et de réduire la latence lors de l'accès aux données.
Implémentation
Parlons des limitations qui existent dans l'architecture VMware vSAN et pourquoi elles sont nécessaires. Quelle que soit la plate-forme matérielle utilisée, l'architecture prévoit les restrictions suivantes:
- pas plus de 5 groupes de disques par hôte;
- pas plus de 7 supports de capacité dans un groupe de disques;
- pas plus d'un cache-transporteur dans un groupe de disques;
- pas plus de 35 transporteurs de capacité par hôte;
- pas plus de 9 000 composants par hôte (y compris les composants témoins);
- pas plus de 64 hôtes dans un cluster;
- pas plus d'une banque de données vSAN par cluster.
Pourquoi est-ce nécessaire? Jusqu'à ce que les limites spécifiées soient dépassées, le système fonctionnera avec la capacité déclarée, en maintenant un équilibre entre les performances et la capacité de stockage. Cela vous permet de garantir le bon fonctionnement de l'ensemble du système de stockage virtuel dans son ensemble.
En plus de ces limitations, vous devez vous souvenir d'une caractéristique importante. Il n'est pas recommandé de remplir plus de 70% du volume de stockage total. Le fait est que lorsque 80% est atteint, le mécanisme de rééquilibrage démarre automatiquement et le système de stockage commence à redistribuer les données sur tous les hôtes du cluster. La procédure est assez gourmande en ressources et peut sérieusement affecter les performances du sous-système de disque.
Pour répondre aux besoins d'une grande variété de clients, nous avons mis en œuvre trois pools de stockage pour une facilité d'utilisation dans divers scénarios. Regardons chacun d'eux dans l'ordre.
Pool de disques rapide
La priorité pour la création de ce pool était d'obtenir un stockage offrant des performances maximales pour l'hébergement de systèmes très chargés. Les serveurs de ce pool utilisent une paire d'Intel P4600 comme cache et 10 Intel P3520 pour le stockage des données. Le cache de ce pool est utilisé pour que les données soient lues directement à partir du support et que les opérations d'écriture se produisent via le cache.
Pour augmenter la capacité utile et garantir la tolérance aux pannes, un modèle de stockage de données appelé Erasure Coding est utilisé. Ce modèle est similaire à une matrice RAID 5/6 standard, mais au niveau du stockage d'objets. Pour éliminer la probabilité de corruption des données, vSAN utilise un mécanisme de calcul de somme de contrôle pour chaque bloc de données 4K.
La validation est effectuée en arrière-plan lors des opérations de lecture / écriture, ainsi que pour les données «froides» dont l'accès n'a pas été demandé dans l'année. Lorsqu'une incompatibilité de somme de contrôle est détectée, et donc une corruption de données est détectée, vSAN récupère automatiquement les fichiers par écrasement.
Pool de lecteurs hybrides
Dans le cas de ce pool, sa tâche principale est de fournir une grande quantité de données, tout en assurant un bon niveau de tolérance aux pannes. Pour de nombreuses tâches, la vitesse d'accès aux données n'est pas une priorité, le volume et le coût de stockage sont beaucoup plus importants. L'utilisation de disques SSD en tant que stockage de ce type coûtera excessivement cher.
Ce facteur a été à l'origine de la création du pool, qui est un hybride de mise en cache des disques SSD (comme dans les autres pools, c'est Intel P4600) et des disques durs de niveau entreprise développés par HGST. Un flux de travail hybride accélère l'accès aux données fréquemment demandées en mettant en cache les opérations de lecture et d'écriture.
Au niveau logique, les données sont mises en miroir pour éliminer les pertes en cas de panne matérielle. Chaque objet est divisé en composants identiques et le système les distribue à différents hôtes.
Pool avec reprise après sinistre

La tâche principale du pool est d'atteindre le niveau maximum de tolérance aux pannes et de performances. L'utilisation de la technologie
vSAN Stretched nous a permis de
répartir le stockage entre les centres de données Tsvetochnaya-2 à Saint-Pétersbourg et Dubrovka-3 dans la région de Leningrad. Chaque serveur de ce pool est équipé d'une paire de disques Intel P4600 à grande capacité et à grande vitesse pour le fonctionnement du cache et de 6 disques Intel P3520 pour le stockage des données. Au niveau logique, il s'agit de 2 groupes de disques par hôte.
La configuration AllFlash n'a pas d'inconvénient sérieux - une forte baisse des IOPS et une augmentation de la file d'attente des demandes de disque avec un volume accru d'accès aléatoire aux données. Tout comme dans un pool avec des disques rapides, les opérations d'écriture passent par le cache et la lecture se fait directement.
Maintenant sur la principale différence avec le reste des piscines. Les données de chaque machine virtuelle sont mises en miroir dans un centre de données et en même temps répliquées de manière synchrone dans un autre centre de données qui nous appartient. Ainsi, même un accident grave, comme une interruption complète de la connectivité entre les centres de données, ne sera pas un problème. Même une perte complète du centre de données n'affectera pas les données.
Un accident avec une défaillance complète du site - la situation est assez rare, mais vSAN peut y survivre avec honneur sans perdre de données. Les invités de notre événement
SelectelTechDay 2018 ont pu voir par eux-mêmes comment le cluster vSAN étiré a connu une défaillance complète du site. Les machines virtuelles sont devenues disponibles juste une minute après que tous les serveurs d'un des sites ont été mis hors tension. Tous les mécanismes ont fonctionné exactement comme prévu, mais les données sont restées intactes.
L'abandon de l'architecture de stockage familière entraîne de nombreux changements. L'un de ces changements a été l'émergence de nouvelles «entités» virtuelles, qui incluent l'appliance témoin. Le sens de cette solution est de suivre le processus d'enregistrement des répliques de données et de déterminer laquelle est pertinente. Dans le même temps, les données elles-mêmes ne sont pas stockées sur des composants témoins, mais uniquement des métadonnées sur le processus d'enregistrement.
Ce mécanisme prend effet en cas d'accident lorsqu'une défaillance se produit pendant le processus de réplication, ce qui entraîne la désynchronisation des répliques.
Pour déterminer laquelle contient les informations pertinentes, un mécanisme de détermination du quorum est utilisé. Chaque composante a un «droit de vote» et se voit attribuer un certain nombre de votes (1 ou plus). Le même «droit de vote» comporte des éléments témoins qui jouent le rôle d'arbitres en cas de situation controversée.
Un quorum n'est atteint que lorsqu'une réplique complète est disponible pour un objet et que le nombre de «votes» en cours est supérieur à 50%.
Conclusion
Le choix de VMware vSAN comme système de stockage est devenu une décision importante pour nous. Cette option a passé les tests de résistance et les tests de tolérance aux pannes avant d'être incluse dans notre projet cloud basé sur VMware.
D'après les résultats des tests, il est devenu clair que la fonctionnalité déclarée fonctionne comme prévu et répond à toutes les exigences de notre infrastructure cloud.
Vous avez quelque chose à dire sur la base de votre propre expérience avec vSAN? Bienvenue dans les commentaires.