Il y a quelques mois, la première version de Kepler.gl est sortie - un nouvel outil Open Source pour visualiser et analyser de grands ensembles de géo-données.
Dans cet article, je vous propose de vous familiariser avec les principales fonctionnalités de l'application et de créer à l'aide de celle-ci deux visualisations cartographiques qui nous permettront de découvrir des faits intéressants sur le stationnement payant à Moscou.
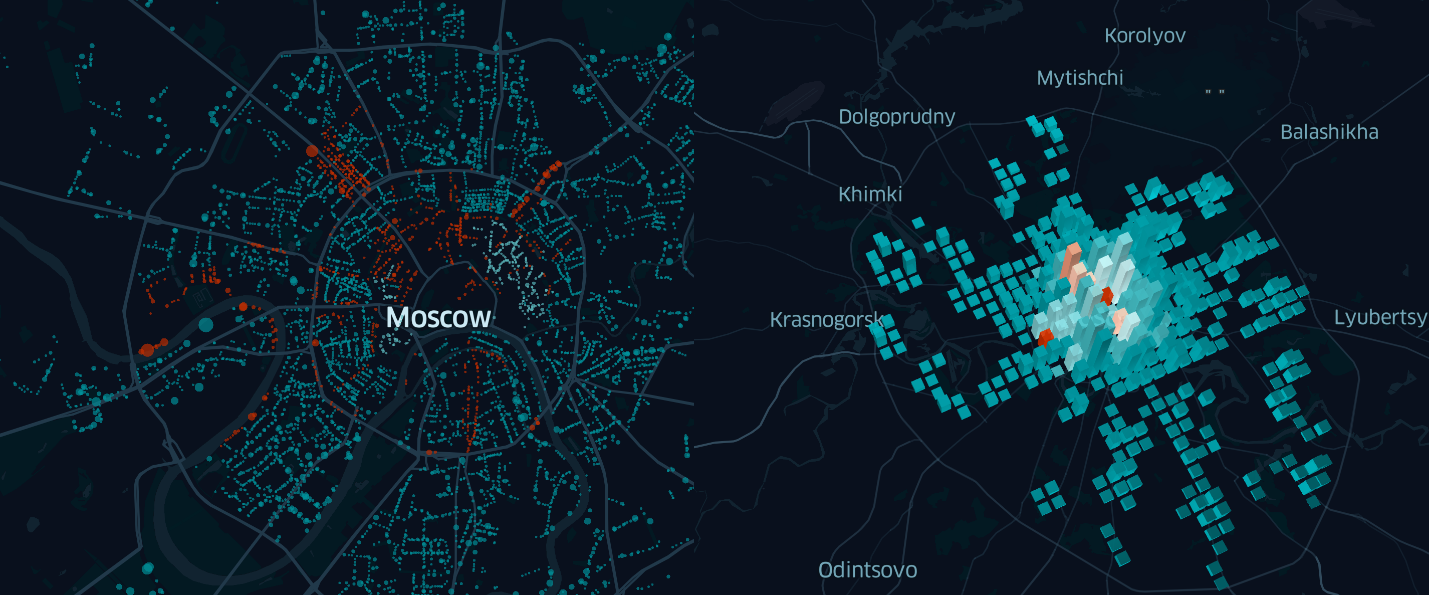
Mais d'abord, quelques mots sur qui et pourquoi a créé Kepler.gl
Initialement, Kepler.Gl a été créé par l'équipe Uber Engineering pour les analystes d'entreprise qui voulaient mieux comprendre «comment la ville se déplace», en utilisant pour cela une énorme quantité de données de trafic de géo-informations collectées quotidiennement par des milliers de «uber» dans diverses villes du monde.
Cependant, en mai de cette année, la société a annoncé un accès ouvert à cette application et a publié tout le code source de Kepler.gl sur GitHub
Principales fonctionnalités de Kepler.gl
Quels que soient les outils d'analyse de données sélectionnés, les services de cartographie ou frameworks utilisés, ainsi que les bibliothèques de création de différentes visualisations, le processus de travail sur ceux-ci est réduit à 4 étapes principales:
- collecte d'informations
- traitement des données
- recherche et analyse des données préparées (pour identifier les dépendances, rechercher les anomalies, etc.)
- création de visualisation
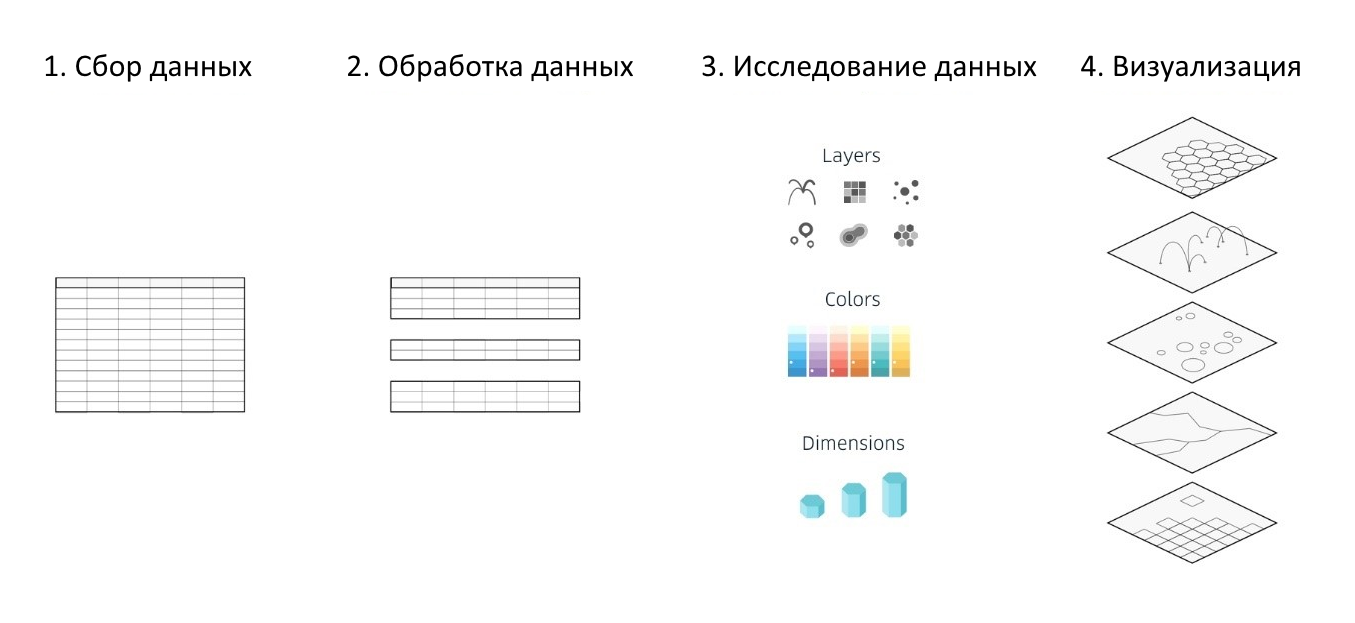 Figure 1. Les étapes de base de la création d'une visualisation
Figure 1. Les étapes de base de la création d'une visualisationKepler.gl automatise et simplifie partiellement 3 des 4 étapes répertoriées, ce qui simplifie considérablement l'ensemble du processus d'analyse et de visualisation de grands ensembles de données et aide à créer une carte informative, et surtout, colorée et interactive basée sur vos propres ensembles de données géographiques en seulement une demi-heure.
Dans le même temps, aucune expérience en programmation ou en conception n'est absolument requise, car le filtrage et l'agrégation de données, le choix d'un moyen d'afficher les données en fonction des différents paramètres des objets étudiés, la superposition d'informations provenant de diverses sources, la commutation entre les modes 2D et 3D, et bien plus est configuré à l'aide du panneau UI.
Comment utiliser Kepler.gl pour l'analyse des données
Le moyen le plus simple est de commencer à vous familiariser avec Kepler.gl en utilisant sa version en ligne, disponible sur
kepler.gl ou, si vous ne faites pas confiance aux serveurs tiers, vous pouvez déployer une version locale pour vous-même, en suivant les instructions sur
GitHub .
Ci-après, j'utiliserai les données sur le «Parking payant à Moscou» fournies par le «Open Data Portal» du gouvernement de Moscou. Cet ensemble contient des informations sur plus de 9 mille objets situés sur le réseau routier, y compris des informations sur le coût et le nombre de places de stationnement.
Étape 1. Chargement des données
À ce jour, Kepler.gl prend en charge 3 formats de données source: geojson, json et csv. Après avoir enregistré les données dans l'un des formats indiqués (dans cet exemple, j'utilise .csv), nous les chargeons simplement dans l'application. À propos, ici, dans la boîte de dialogue de téléchargement, pour vous familiariser avec l'application, vous pouvez également utiliser l'une des dizaines de jeux de données de test prédéfinis.
Remarque Pour Chrome, la taille maximale du fichier de téléchargement ne doit pas dépasser 250 Mo. Les créateurs de Kepler.gl suggèrent d'utiliser Safari si vous devez télécharger un fichier plus volumineux. Cependant, dans tous les cas, vous devez vous rappeler que les performances de l'application dépendent du périphérique sur lequel elle s'exécute. Après tout, toutes les manipulations associées à l'agrégation, au filtrage et à l'affichage des données se produisent sur le client.
Étape 2. Affichage des données sur une carte
L'application prend en charge 9 types de couches de visualisation (couche de visualisation de données), qui diffèrent les uns des autres par un ensemble de paramètres personnalisables:
- couche de points
- couche d'arcs (Arc)
- couche de lignes (Ligne)
- grille (grille)
- grille hexagonale (Hexbin)
- polygones de couche (Poligon)
- couche de cluster (Claster)
- couche d'icônes (icône)
- heatmap (Heatmap)
De plus, même les couches du même type, affichant le même ensemble de données, peuvent différer considérablement en fonction de la configuration sélectionnée.

Figure 2. Cartes créées dans kepler.gl en utilisant différents types de couches
Kepler.gl ne limite pas le nombre de couches utilisées lors de l'affichage de l'ensemble de données de test. Les couches sont dessinées sur la carte dans le même ordre dans lequel elles se trouvent dans la liste des couches du panneau latéral. Cette séquence peut facilement être modifiée en faisant simplement glisser les calques correspondants les uns par rapport aux autres sur l'onglet Calques.
Lorsque vous utilisez plusieurs calques, faites attention au paramètre «Layer Blending», qui est responsable de la façon dont les calques se chevauchent. Il est uniforme tout au long de la visualisation, ce qui rend impossible l'utilisation de différents types de mélange pour différentes couches.
Actuellement, trois valeurs pour ce paramètre sont disponibles:
- Normal
Dans ce cas, les couches inférieures n'affectent pas la couleur des points (ou d'autres éléments) des couches supérieures.
- Additif
Avec ce type de superposition, les valeurs de couleur des éléments correspondants s'additionnent. Il est pratique pour identifier les zones de haute densité, qui dans ce cas seront plus lumineuses. - Soustractif
Contrairement à l'additif, il n'ajoute pas, mais soustrait la signification des couleurs dans les zones d'intersection. C'est pratique lorsque vous n'utilisez pas une carte sombre, mais une carte claire.
Ainsi, pour voir nos données sur la carte, il est nécessaire de créer au moins une couche en les utilisant. Il convient de noter qu'après avoir téléchargé le fichier, Kepler.gl essaiera d'identifier les champs contenant des informations de géolocalisation et de les afficher instantanément, créant automatiquement des couches des types correspondants (généralement des points ou des polygones).
Cependant, dans notre cas, en raison de la différence entre les formats de données attendus et utilisés, vous devrez spécifier vous-même la source des coordonnées. Pour ce faire, supprimez d'abord les couches de polygones créées par Kepler.gl, puis ajoutez manuellement une nouvelle couche de type Point. Comme source de coordonnées, nous utilisons les champs Latitude_WGS84 et Longitude_WGS84 au lieu du champ Coordonnées automatiquement sélectionné par l'application pour le rendu des données sur la carte.
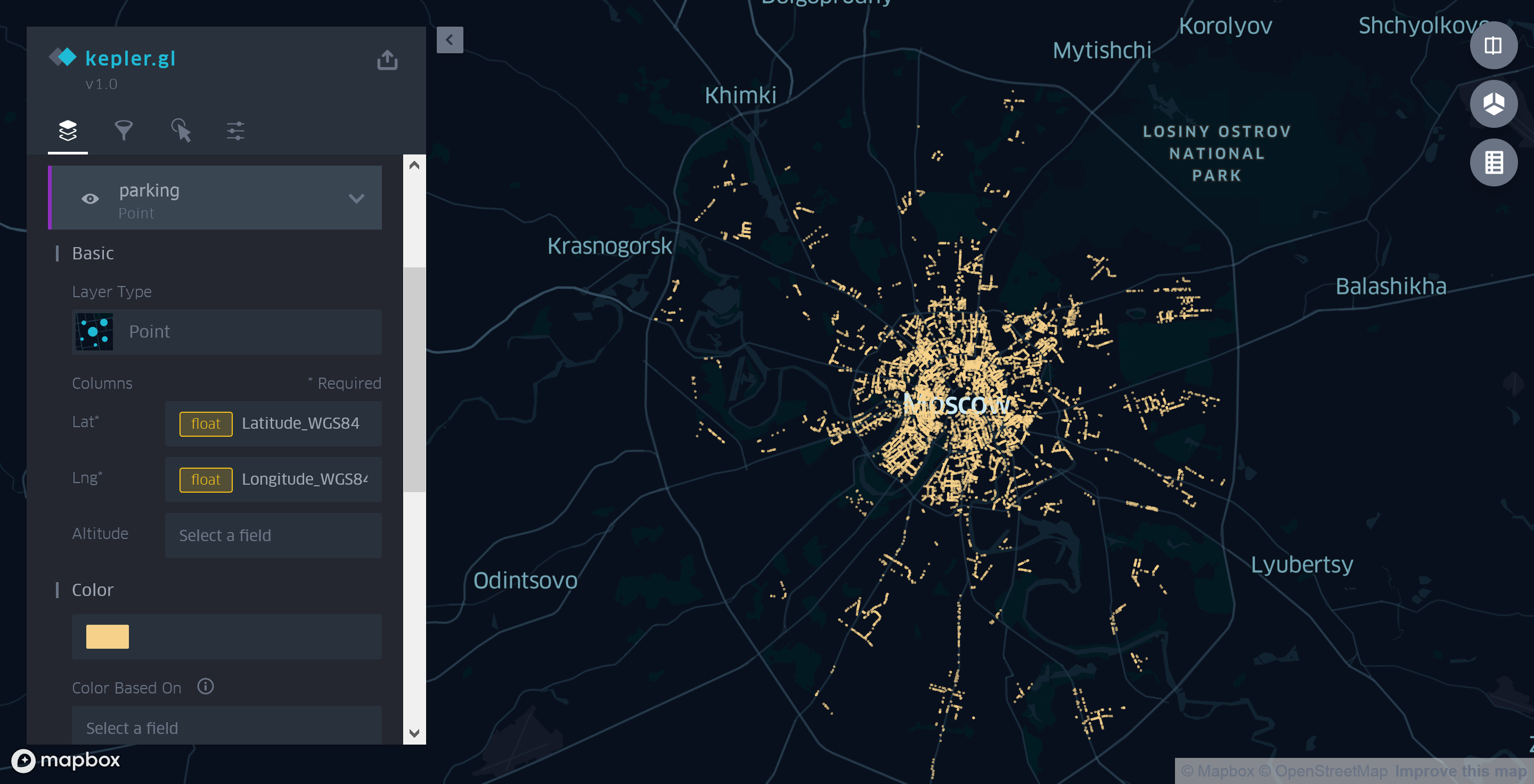
Figure 3. Utilisation de la couche spot Kepler.gl pour afficher les parkings de Moscou
Dans ce mode de réalisation, la carte n'est pas très informative. La seule chose que l'on puisse dire, en la regardant, c'est qu'il y a plus de parkings au centre qu'en périphérie.
Il est donc temps d'utiliser d'autres informations sur les objets étudiés pour une analyse plus détaillée et rechercher des faits et / ou des modèles intéressants.
Étape 3. Modification de l'apparence de la carte sur la base des données associées sur les objets affichés
L'ensemble téléchargé sur le portail Open Data contient de nombreuses informations sur chacun des parkings, cependant, deux paramètres me paraissent les plus intéressants - le coût d'une heure de parking et le nombre de places disponibles.
Quels sont les parkings les plus chers de Moscou? Existe-t-il une relation entre la taille du parking et sa distance par rapport au cent? Quelle est la différence dans le coût d'une heure de stationnement à l'intérieur et à l'extérieur du Garden Ring? Pour répondre à ces questions, il nous suffit de modifier légèrement les paramètres d'affichage de la couche de points précédemment créée et de regarder à nouveau la carte.
Tout d'abord, changez la couleur des points en fonction du coût d'une heure de stationnement à cet endroit. Pour ce faire, dans la liste déroulante «Couleur basée sur», comme base de choix d'une couleur, nous indiquons le paramètre «Prix» de l'ensemble de données d'origine.

Figure 4. Utilisation de la couleur pour afficher les informations de coût par heure de stationnement
Déjà à ce stade, plusieurs observations intéressantes peuvent être faites. Par exemple, ce n'est pas tout le centre qui est aussi cher pour les automobilistes, mais à Tverskaya, il vaut mieux être un piéton
Voyons maintenant la capacité des parkings. Pour cela, nous utiliserons le champ «CarCapacity» comme paramètre de base pour déterminer le rayon d'un point (l'attribut «Radius Based On» d'une couche de points). Définissez la plage de rayon de 0 à 30 pixels.

Figure 5. Personnalisation de la taille des points en fonction du nombre de places de parking
Ainsi, en quelques minutes, notre plan de stationnement est devenu nettement plus informatif. Maintenant, même un coup d'œil rapide permet non seulement de comparer la politique de prix des différents quartiers de la ville, mais aussi d'évaluer grossièrement vos chances de trouver un espace libre compte tenu non seulement du nombre de parkings à proximité, mais aussi de leur espace.
Étape 4. Agrégation de données avec Kepler.gl
L'utilisation d'une couche de points pour afficher chacun de plus de 9000 parkings nous a déjà permis de faire quelques observations intéressantes, mais la carte ne nous permet pas de répondre facilement à des questions telles que "Où sont les plus de parkings par unité de surface?". Pour y répondre, nous devons utiliser l'une des couches d'agrégation.
Actuellement, Kepler.Gl prend en charge 4 types de telles couches: grille (Grille), grille hexagonale (Hexbin), heatmap (Heatmap) et cluster (Cluster). Les deux derniers types (Cluster et Heatmap) sont pratiques lorsque vous devez agréger des données par un seul paramètre. La grille et la grille hexagonale permettent d'analyser les valeurs agrégées par plusieurs paramètres simultanément.
Pour répondre à la question posée précédemment, nous allons changer le type de la couche de points que nous avons précédemment créée en «grille» (Grille), cela permettra non seulement d'évaluer le nombre total de places de stationnement par unité de surface, mais également d'économiser des informations sur le coût moyen d'une heure de stationnement à cet endroit.
Réglez la taille de la grille sur 1 km2 (le minimum disponible dans Kepler.gl). La valeur du paramètre Coverage est réduite de 1 à 0,7 afin qu'un petit espace apparaisse entre les cellules, ce qui améliore la lisibilité de la carte finale.
Remarque La liste des options disponibles pour la personnalisation varie en fonction du type de couche sélectionné. Vous pouvez trouver plus de détails sur les attributs pris en charge par chacun d'eux dans la documentation officielle de Kepler.gl.
La couleur de chaque cellule dans la nouvelle visualisation, comme précédemment, dépendra du coût d'une heure de stationnement. Cependant, maintenant, en plus du nom du champ dans l'ensemble de données utilisé, nous devons également indiquer comment Kepler.gl agrégera ces informations. Les méthodes d'agrégation dépendent du type de champ sélectionné. Dans notre cas, «Prix» est de type numérique (int) et l'application propose l'une des 5 options:
- valeur la plus élevée (minimum)
- plus petite valeur (maximum)
- montant (somme)
- valeur moyenne (moyenne)
- médiane
La hauteur de chacune des colonnes de la grille reflétera le nombre total de places de stationnement dans cette zone. Pour ce faire, passez en mode 3D de visualisation de la carte. Ensuite, dans l'onglet "Couches" du panneau latéral , sélectionnez "Activer la hauteur" pour notre couche d'agrégation, et sélectionnez le champ "CarCapacity" comme paramètre de base.
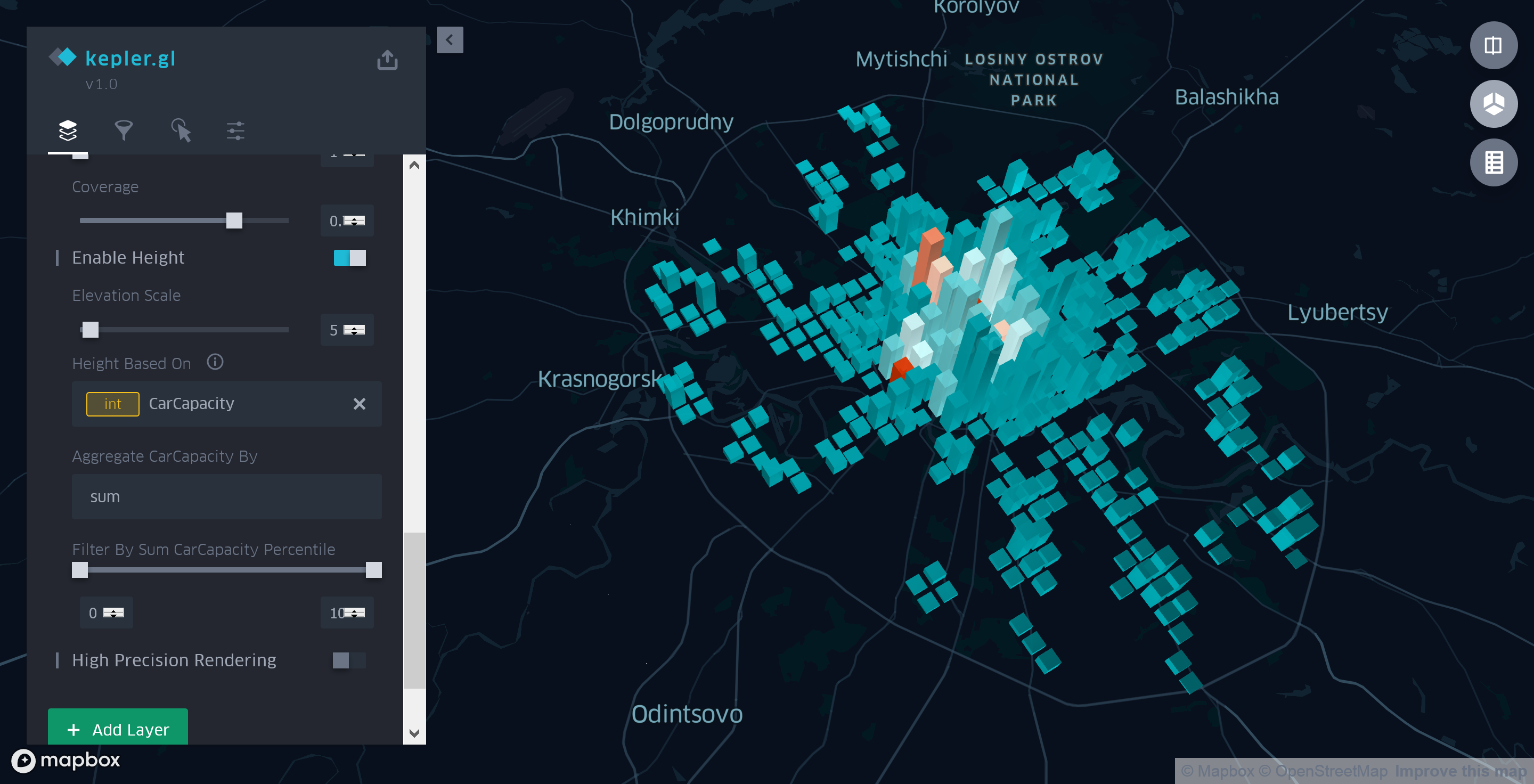
Figure 6. Informations généralisées sur le coût et la capacité de stationnement
Ainsi, après avoir passé quelques minutes de plus à mettre en place la couche d'agrégation, nous pouvons affirmer avec certitude qu'à l'intérieur du Garden Ring, non seulement le nombre de parkings, mais aussi le nombre réel de places de parking est beaucoup plus grand qu'à l'extérieur.
Conclusion
Dans cet article, en utilisant un exemple spécifique, seule une partie des capacités de Kepler.gl a été considérée comme un outil moderne de visualisation et d'analyse de base de diverses géo-données. Si vous êtes intéressé par cette application, je vous recommande également de vous familiariser avec les articles et les didacticiels ci-dessous, ainsi que de tester vous-même le filtrage des données, de configurer les info-bulles et les styles de carte, ainsi que d'autres fonctionnalités de cette application.
Et dans le prochain article, je vous expliquerai comment partager les visualisations et les cartes que vous avez créées, ainsi que l'utilisation de Kepler.gl comme composant React pour votre application Web.
Liens utiles