Avant de répondre à la question «Comment mesurer le succès?», Vous devez comprendre ce que le «succès» signifie pour vous. Pour Dev et Ops, la définition du succès est différente. Pour Dev, un projet réussi est entièrement testé. Pour le fonctionnement - surveillance. Les tests et la surveillance sont nécessaires, mais les tests ne donnent jamais une couverture à 100% du problème, et une réponse de 200 de HTTP ne suffit pas pour être sûr que le système fonctionne bien. Leon Fayer de RIT ++ a défendu le point de vue selon lequel les DevOps ne paient pas pour s'assurer que toutes les métriques de la surveillance se trouvent dans la zone verte. Ils paient pour rendre les utilisateurs heureux . Si vous n'êtes pas satisfait - l'entreprise perd de l'argent et personne ne se soucie que tout soit vert.
Sous un chat, de nombreux exemples tirés de la pratique prouvent ce point de vue. Voyons pourquoi comprendre l'entreprise, comment surveiller le succès d'un point de vue commercial et pourquoi les développeurs ordinaires en ont besoin.

À propos de l'orateur: Leon Fayer est né dans une république autrefois amie, mais a grandi aux États-Unis. J'ai commencé à programmer il y a de nombreuses années, et pendant ce temps, j'ai travaillé en tant que programmeur, gestionnaire, que je ne travaillais tout simplement pas. Participé à des startups - certains ont eu plus de succès et d'autres pas très bien.
Depuis de nombreuses années, Leon travaille chez OmniTI. Cette entreprise est spécialisée dans le développement de systèmes évolutifs, donc Leon a une opportunité unique de concevoir et de construire des systèmes pour les sites les plus visités au monde - Wikipedia, National Geographic, Maison Blanche, MTV, etc.

Avant de répondre à la question «Comment mesurer le succès?», Vous devez comprendre ce que le «succès» signifie pour vous. Pour chaque personne, la réponse sera différente.
Si vous lisez cet article, vous êtes très probablement impliqué dans DevOps. Êtes-vous plus développeur que opérationnel? Ou, inversement, plus d'Ops que de Dev? Pour Dev et Ops, la définition du succès est un peu différente: pour Dev, bien sûr, c'est tester.
Test
Pour moi, en tant que programmeur, des tests réussis signifient que tout est en ordre, tout va bien, tout fonctionne - vous pouvez l'exécuter en production. Le problème est que je suis aussi un cynique et pas un fan des tests en tant que tels. Non pas parce que c'est difficile, et non pas parce que c'est long - mais parce que les tests ne donnent pas ce que je veux.

Comprenez-moi bien, le test est un processus obligatoire , il devrait être inclus dans tout projet, mais il ne suffit clairement pas de garantir le succès .
Il existe de nombreuses options de test différentes:
- tests de performance;
- tests utilisateurs;
- test automatique ...

Combien de méthodes de test utilisez-vous - 1, 2, 3, 5? Et quoi, vous n'êtes pas éveillé la nuit en alerte? Est-ce que tout fonctionne en production?
Le problème est que les tests donnent l'illusion du succès . C'est prédéterminé: nous savons que le train doit quitter le point A et atteindre le point B, pour cela nous testons. Il y a des options que nous envisageons. Si le train tombe de la roue ou manque de bois, ce ne sera pas une surprise. Mais nous ne testons pas, par exemple, le vol de train. Nous ne pouvons pas tester cela car nous ne savons pas qu'une telle option est possible.
Il y a quelques problèmes en raison desquels les tests ne sont tout simplement pas suffisants. Le premier, bien sûr, est un problème de données . Le fait que la tâche fonctionne localement, mais pour une raison quelconque ne fonctionne pas en production, est un problème standard.
Peu importe à quel point nous essayons. Peu importe le nombre de réplications que nous vivons - le développement et la production ne seront jamais égaux. Y aura-t-il une autre ligne dans la base de données, y aura-t-il une autre demande supplémentaire - il y aura toujours quelque chose en production auquel nous ne nous attendions pas.
Wolfe + 585 - le nom de famille le plus long du monde:
Hubert blaine
Wolfeschlegelsteinhausenbergerdorffwelchevoralternwaren-gewissenhaftschaferswessenschafewarenwohlgepflegeundsorgfaltigkeitbeschutzen-vorangreifendurchihrraubgierigfeindewelchevoralternzwolfhunderttausendjahres-vorandieerscheinenvonderersteerdemenschderraumschiffgenachtmittungsteinund- siebeniridiumelektrischmotorsgebrauchlichtalsseinursprungvonkraftgestartsein-langefahrthinzwischensternartigraumaufdersuchennachbarschaftdersternwelchege-habtbewohnbarplanetenkreisedrehensichundwohinderneuerassevonverstandig-menschlichkeitkonntefortpflanzenundsicherfreuenanlebenslanglichfreudeundruhe-mitnichteinfurchtvorangreifenvorandererintelligentgeschopfsvonhinzwischensternartigraum,
Sr.
Peu de systèmes survivront si quelqu'un entre un tel nom de famille sur le formulaire. Je connais au moins 5 points différents où tout le système peut voler.
Par conséquent, le deuxième problème est le problème avec les utilisateurs .

Ce sont des gens tellement intéressants qui vont tout casser. S'il n'y avait pas d'utilisateurs, tout serait beaucoup plus facile, pour être honnête.
Même s'il y a un bouton dans votre interface utilisateur, ils trouveront toujours une méthode pour briser ce que nous faisons.
Le meilleur exemple est World of Warcraft .

Pour ceux qui ne connaissent pas, c'est un jeu en ligne joué par 10 millions de personnes. À une époque, il y avait des bugs assez légendaires. Un bug de sang corrompu est un parfait exemple de la façon dont les utilisateurs gâchent tout.
Comme pour tout jouet, dans World of Warcraft, de nouveaux contenus, de nouvelles idées, de nouveaux patrons sont constamment apparus. L'un des nouveaux patrons a maudit l'un des 40 joueurs du groupe. Le principe de la malédiction était comme une bombe à retardement - elle a lentement emporté la vie de tout le monde autour. Autrement dit, il fallait fuir sur le côté - il y avait toute une mécanique. Et tout allait bien jusqu'à ce que, à un moment donné, l'un des joueurs décide de se téléporter dans la ville pendant la bataille ...

Dans la ville, il y avait des milliers de personnes de tous niveaux, les plus petites aussi. Non seulement cela, il y avait encore des personnages non-joueurs qui ont également été infectés par une malédiction. Pendant la journée, les serveurs étaient vides. Il était impossible d'aller nulle part, où il y avait d'autres joueurs. C'est devenu un fléau de jeu dans le vrai sens du terme. J'ai dû faire un redémarrage rond de tous les serveurs afin de supprimer la malédiction et de changer la mécanique. Et tout cela à cause d'un seul testeur - je ne sais même pas comment l'appeler.
Le troisième problème principal est celui de la dépendance externe . Nous sommes tous tombés sur ceci: l'API dont vous dépendez cesse soudainement de fonctionner; ou vous arrêtez de contrôler l'API.
Mais cela pose un plus gros problème. La dépendance externe peut être non seulement directe, mais aussi indirecte. Nous utilisons tous OpenSource maintenant. Chaque produit OpenSource dépend de certaines bibliothèques, qui sont également OpenSource et qui sont prises en charge par quelqu'un d'autre. Quand quelque chose casse, il casse non seulement dans ce petit module, mais dans tout ce qui en dépend.
L'exemple le plus idéal a probablement été récemment, il y a environ un an - c'est le bloc gauche . Il s'agit d'un module npm sur node.js qui expose les espaces avant la chaîne (au début d'une ligne). Nous ne discuterons pas pourquoi ce module a été créé. Mais il s'avère qu'il était inclus dans de nombreux modules populaires. À un moment donné, l'auteur a décidé qu'il en avait assez, a supprimé ce module de npm et 70% du code écrit dans node.js a volé.
Si vous pensez qu'il s'agit d'un cas isolé, vous vous trompez.
Il y a aussi le module is-odd, qui est maintenant dans npm. Ce module définit un nombre pair ou non.
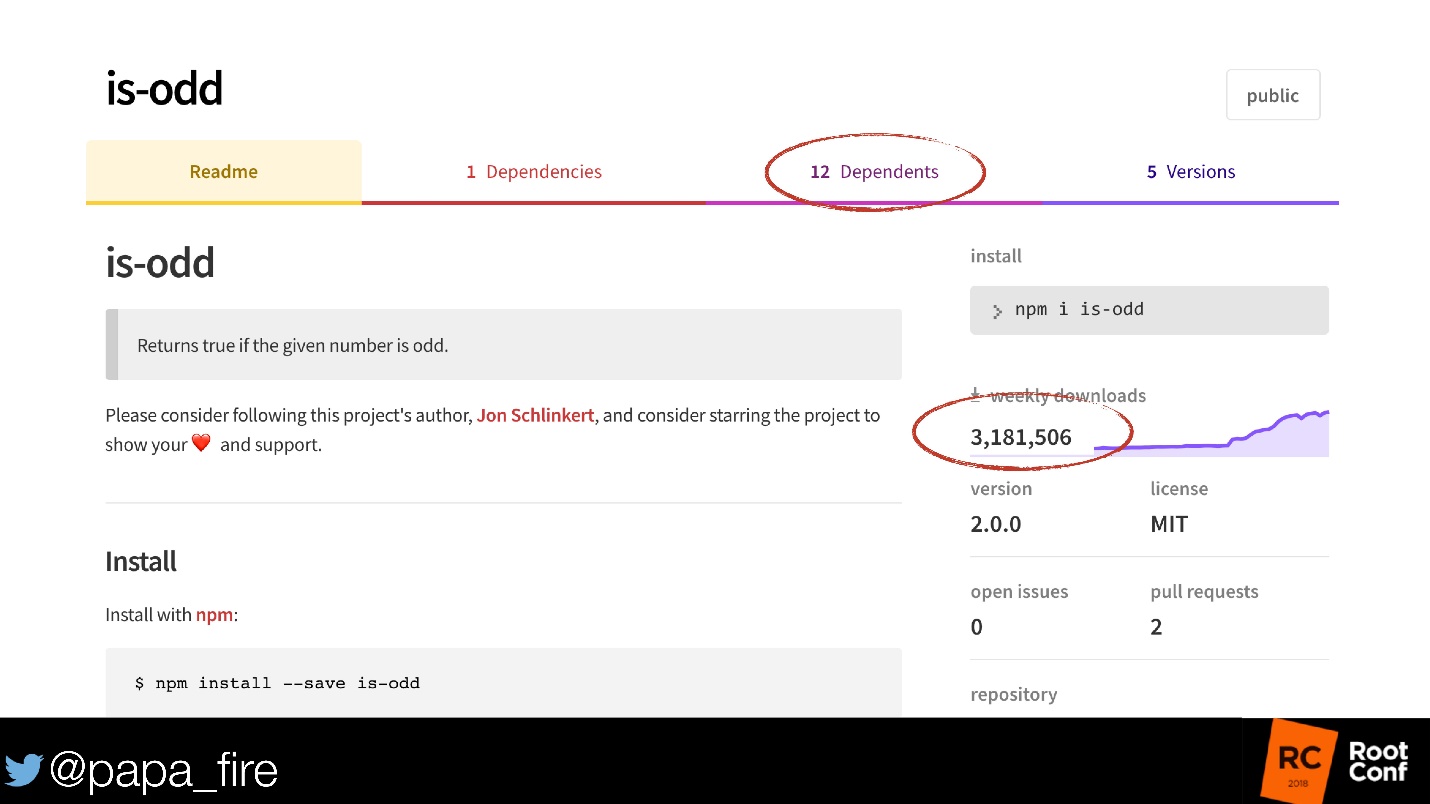
Nous ne discuterons pas du fait que 3 millions de personnes ne savent pas comment vérifier la parité / bizarrerie. Mais il y a 12 autres modules qui l'utilisent! Et on ne sait pas combien de ces modules utilisent encore les modules. S'il vous semble qu'il n'y a rien à casser - il existe 5 versions!
Revenons à nos moutons - il y a beaucoup plus d'options:
- Myopie - nous ne savons pas ce qui se passera à l'avenir. Y2K en est un parfait exemple. Personne ne pensait qu'en 2000 tout ce qui était écrit en Kobol volerait.
- Nombre d'options de test .
Il y a encore un bon exemple avec World of Warcraft - ils ont beaucoup de bons exemples à ce sujet.
Six mois après la sortie du jeu, des appels ont commencé à soutenir que certains joueurs ne pouvaient pas entrer dans une grotte. Il s'est avéré qu'une seule version de la race et du sexe ne pouvait pas entrer dans cette grotte - il s'agissait de taurens femelles.
Pourquoi at-il fallu 6 mois pour trouver cette erreur - après tout, des millions de personnes jouent? Parce que le tauren est une race fictive, un mélange d'homme et de taureau. La femme Tauren est une vache parlante. Personne ne voulait jouer à une vache, donc pendant 6 mois, aucune personne n'a atteint le niveau maximum pour entrer dans la grotte et trouver ce bug. En conséquence, personne ne l'a testé.
- Modification des données source. Nous ne savons vraiment pas ce qui se passera demain.
En tout cas, il y a peu de tests. Mais les tests ne donnent pas une couverture à 100%. Par conséquent, les tests ne garantissent pas le succès. Cela nous amène progressivement à la deuxième partie - Ops. Pour l'exploitation, le succès est le suivi .
Suivi
Il existe de nombreuses raisons pour lesquelles la surveillance est nécessaire:
- le code parfait n'existe pas;
- les systèmes deviennent plus complexes;
- dépendance extérieure croissante;
- anticipation -> réponse;
- ...
La surveillance est nécessaire car tout change. C'est la raison principale. De plus, il est en production, tout y change constamment, et nous devons le détecter.
Que devrait couvrir le suivi? - C'est ça! C'est une réponse courte, mais elle devrait tout couvrir.

Tout cela est un peu abstrait. En fait, nous avons tous une liste de contrôle que nous surveillons:
- infrastructure
- Bases de données
- Les applications
- points d'intégration;
- demander le temps de traitement;
- charge;
- ...
Il peut y avoir un million de choses. Beaucoup collectent des centaines, des milliers et des dizaines de milliers de métriques sur leurs systèmes.
Nous collecterons beaucoup de métriques pour cela:
Bien sûr, j'exagère, mais tout ce dont nous avons besoin du point de vue d'Ops est que HTTP renvoie 200 . Cela signifie que tout va bien avec le site. Une fois qu'un site fonctionne, cela signifie que les bases de données fonctionnent, les applications fonctionnent - tout est en ordre. Du point de vue Ops, le succès est exactement cela: tous les graphismes sont dans la zone verte, tout fonctionne correctement - tout va bien!

Tout le monde sait ce qu'est Twitter. Ils traitent 500 millions de tweets par jour - un nombre fou.

Mais ils sont également connus pour leurs erreurs. Les erreurs sont légendaires dans leur complexité ou leur facilité - de quel côté regarder.
Ils ont fait une erreur: le site fonctionnait, le client pouvait écrire un tweet, cliquer sur un bouton, ils ont dit merci, le tweet a été envoyé - et c'est tout! Il n'est apparu nulle part et a simplement disparu, et la surveillance a montré que tout était en ordre. Le site renvoie une demande de 200 - l'API fonctionne. Mais il n'y a pas de tweets!
J'ai une citation préférée d'un client. J'ai réparé des problèmes sur trois écrans pendant une heure, et il a crié pourquoi rien ne fonctionnait. Lorsque j'ai essayé d'expliquer les problèmes que je résolvais, une personne qui a tapé avec deux doigts et n'a pas compris comment utiliser un ordinateur m'a dit:
"Tant que je continue à gagner de l’argent, c’est pour moi que les serveurs sont allumés."
À certains égards, c'est très correct, et l'exemple de Twitter le confirme: toutes les mesures ont montré que tout était en ordre du point de vue des développeurs, mais du point de vue du travail de l'entreprise, ce n'était pas du tout en ordre.
Pour être honnête, nous sommes tous à blâmer. Bien sûr, les entreprises qui fabriquent des produits de surveillance sont principalement à blâmer. Mais nous aussi, car traditionnellement, nous collectons des métriques système. Nous sommes habitués à travailler avec de petits systèmes - un, peut-être deux serveurs. S'ils fonctionnent, alors tout est en ordre.
Nous avons maintenant un peu plus de serveurs que deux, voire 10, et il ne suffit pas de mesurer la santé du système ou la santé du programme. Nous devons suivre le travail d'autre chose.
Pour en revenir au devis, je ne suis pas payé pour que tout soit vert. Je suis payé pour que mes utilisateurs ou mes managers soient satisfaits - quelqu'un devrait être satisfait du résultat . Si tous les utilisateurs sont mécontents, personne ne se soucie que tout soit vert.
Suivi des affaires
Nous avons dit que la surveillance est nécessaire parce que tout change. Mais quand tout change, les changements affectent l'entreprise: quelque chose a cassé - l'argent a cessé d'entrer, quelque chose a été réparé - l'argent a recommencé à couler - une corrélation directe. Ou bien ils ne l’influencent pas - mais si nous ne surveillons pas l’entreprise, nous ne le savons pas.
À titre d'exemple vivant, le graphique de lecture du cache est familier à tout le monde.
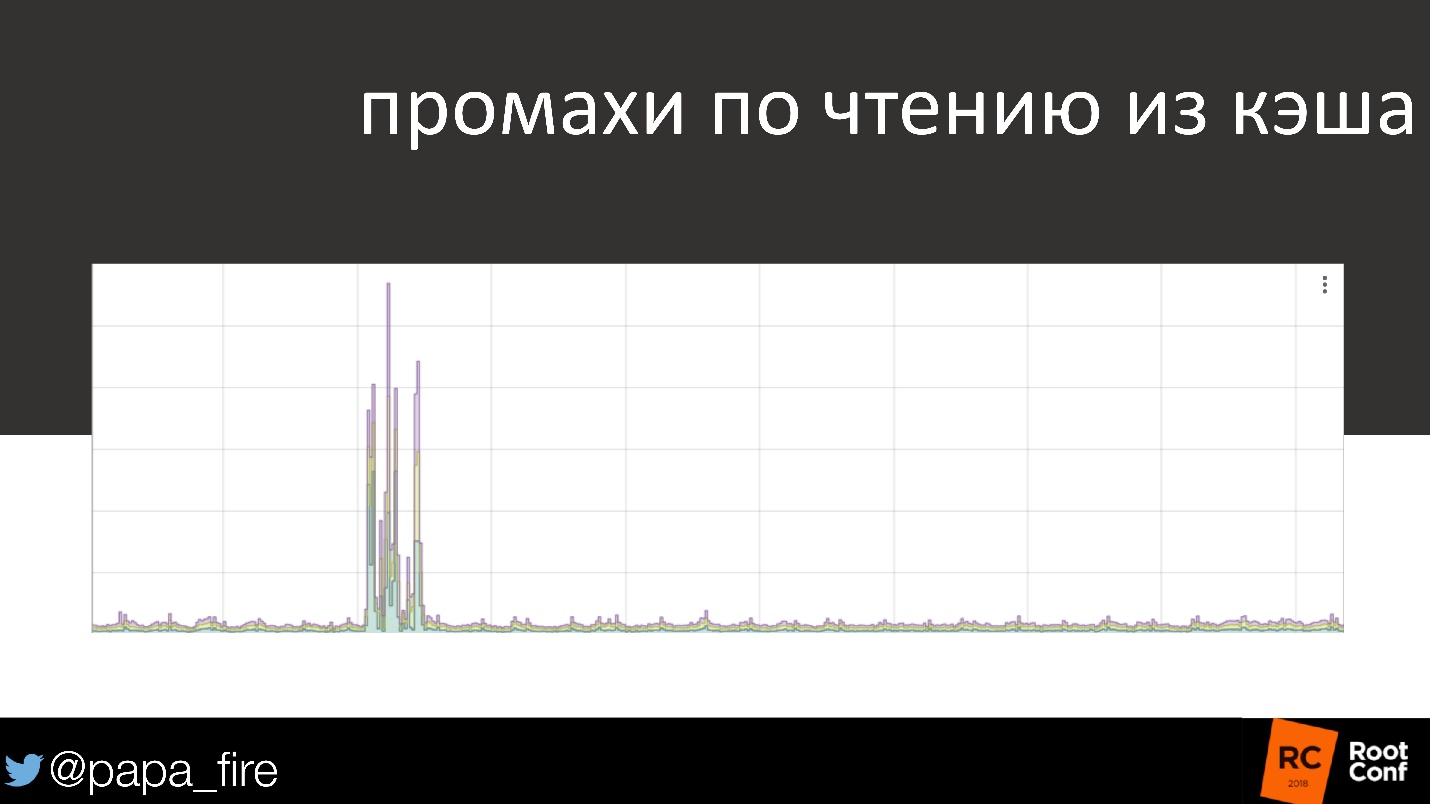
90% du temps, tout est en ordre, presque toutes les requêtes vont dans le cache. Et soudain, quelque chose s'est produit - et très grave. C'est un problème qui devrait se réveiller à 3 heures du matin, quelqu'un qui le résoudra. Mais, si la vitesse de téléchargement pour les utilisateurs ne change pas, est-ce vraiment un problème?
En anglais, il existe le terme observabilité - observabilité. Ce sont: la surveillance, la journalisation, les alertes. Par conséquent, le terme surveillance est un peu. Nous voulons tout observer - collecter les métriques du système sur chaque nœud, si nécessaire. Mais nous voulons surveiller l'activité, car cela excite tout le monde. Ceci est un indicateur de réussite.
Pour ce faire, nous devons:
1. Comprendre le problème - que devons-nous exactement surveiller.
2. Déterminez la ligne de base, c'est-à-dire qu'il suffit que la vitesse de téléchargement de l'utilisateur ne change pas pour que personne ne se réveille au milieu de la nuit lorsque la lecture à partir du cache a cessé de fonctionner.
3. La corrélation des données est l'un des facteurs les plus importants. Si le marketing collecte des données sur les revenus et que vous collectez des données sur des serveurs et que vous ne pouvez pas comparer ces deux observations, alors elles ont très peu de sens.
Je donne généralement beaucoup d'exemples. Peu importe à quel point ils sembleraient absurdes, ils sont tous de ma vie, et je leur ai consacré beaucoup de nerfs.
Exemple: j'avais un client avec 100 millions d'utilisateurs. C'était une entreprise de marketing Internet qui a envoyé beaucoup d'e-mails et utilisé des tests A / B. Pour eux, nous avons collecté 6 000 métriques.
Tout, comme toujours, a commencé par un appel. Le téléphone sonne - cela signifie que quelque chose s'est produit.
" Nous avons un problème." Quelque chose ne fonctionne pas.
- OK, qu'est-ce qui ne fonctionne pas exactement? En quoi cela s'exprime-t-il?
- Nous avons commencé à recevoir moins de revenus.
- Et?
- Quelque chose ne fonctionne pas dans le système.
- Je ne comprends pas. Si moins de revenus, parlez-en à votre équipe de vente. Pourquoi m'appelles-tu?
- Non, je suis sûr que quelque chose dans le système ne fonctionne pas!
- D'accord, voyons.
Dieu merci, nous avions une mesure des revenus, afin que nous puissions voir. Le graphique montre vraiment qu'à un moment donné, leur revenu a chuté de 15%. Compte tenu du nombre d'utilisateurs, c'est assez important.
D'accord, je dois regarder. Tout d'abord, je vérifie la vitesse de téléchargement - normale.
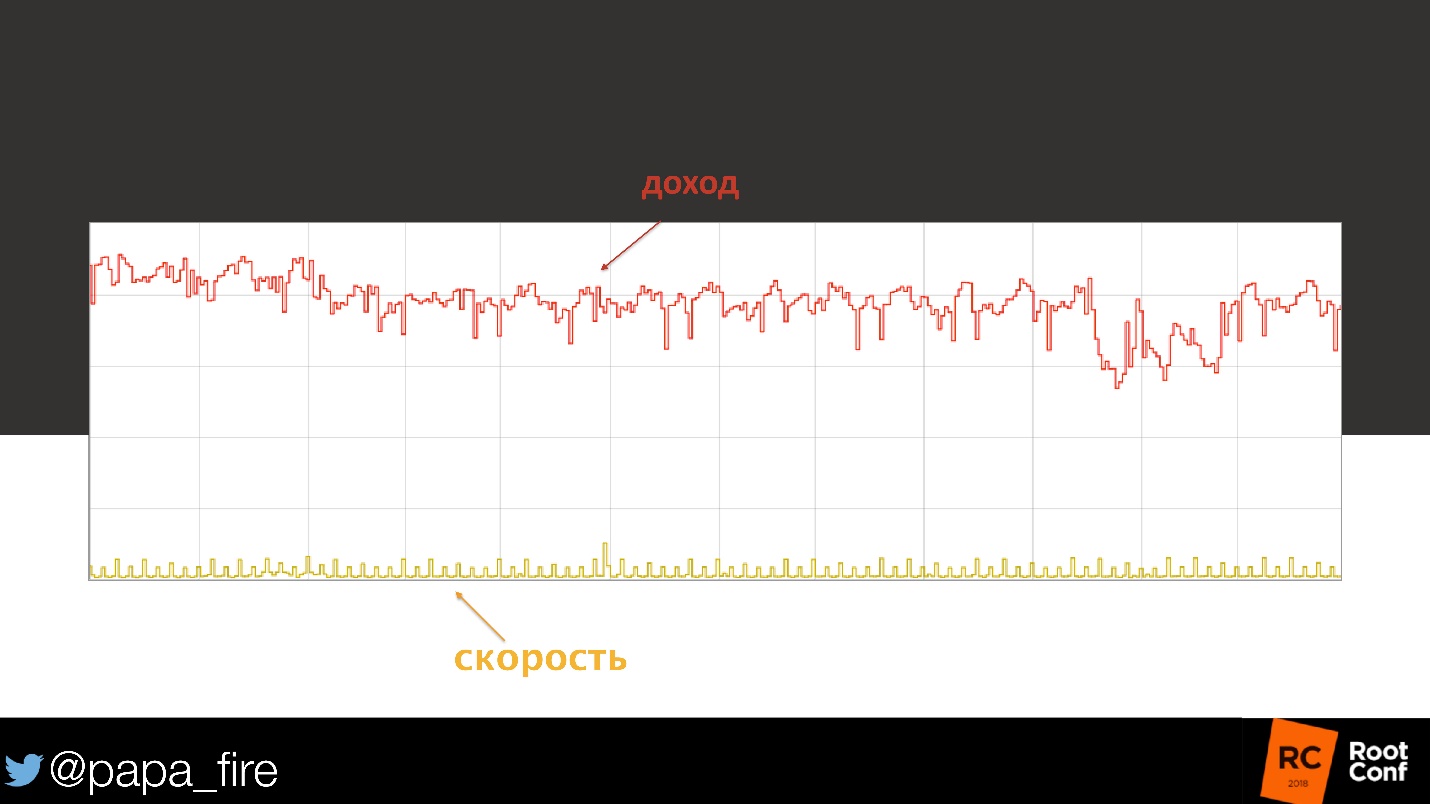
Nous avons examiné la charge de la base de données - tout est dans des limites raisonnables, il semble que rien n'a changé. Ensuite, nous avons commencé à examiner la charge du processeur, les nœuds individuels, les caches.
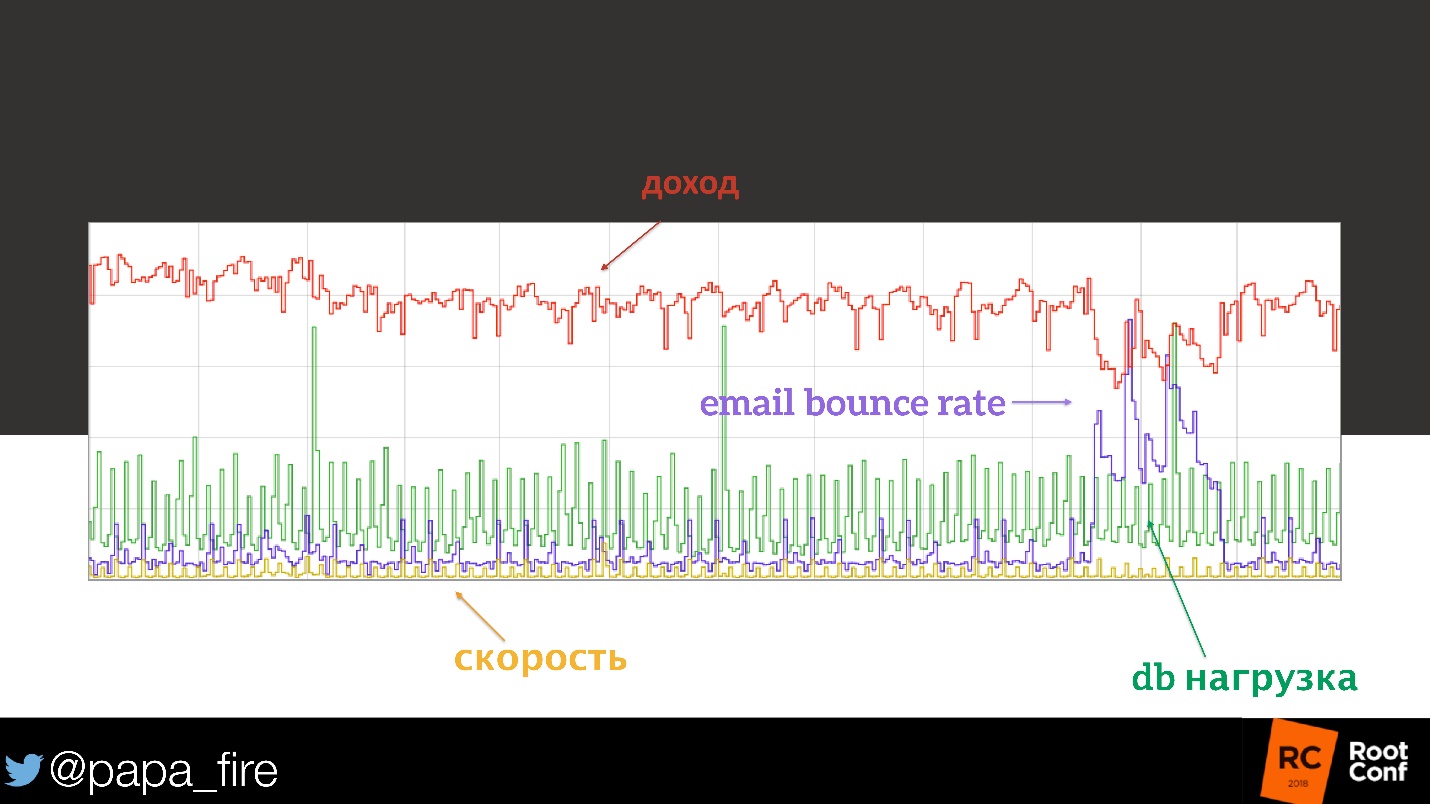
Tout était en ordre jusqu'à ce que nous arrivions aux paramètres de la newsletter par e-mail. L'un des grands fournisseurs a accidentellement mis son domaine sur la liste noire. Le pourcentage de leur marketing par e-mail a cessé d'atteindre les utilisateurs, ce qui signifie que moins de personnes: ont reçu des lettres, cliqué sur le bouton, se sont rendues sur le site et ont acheté quelque chose.
Voici une telle corrélation!
Nous avons la chance d'avoir ces mesures. Si nous ne les avions pas, nous les ajouterions - c'est une réponse très simple.
La plus grande erreur que les gens commettent est de croire que le suivi peut être mis à la fin du projet. C’est comme une fonctionnalité: créer son propre projet, mettre en place un suivi - et c’est tout, nous sommes prêts!
L'instrumentation ne peut jamais être terminée. Il y a toujours des problèmes inconnus dès le début. Comme pour les tests, vous ne pouvez pas écrire des tests et tout couvrir, car vous ne savez pas ce que «tout» est. Nous ne savons pas prédire l'avenir et nous ne savons pas prédire une entreprise, nous ne savons donc pas ce que «tout» est.
Un exemple absolument identique à ce dont je parle. C'est le PDG, qui s'est réveillé le matin à une conférence à Paris, a bu du café, a regardé son courrier et son compte de résultat, et m'a appelé avec le même problème: le revenu a chuté.
Je m'en souviens bien, car il avait 9 heures du matin, et j'avais 6 heures plus tôt, également samedi. Je viens d'être ramené chez moi après une fête d'anniversaire - mais cela n'a pas d'importance. Donc, à 3 heures du matin, je m'assois devant l'ordinateur et nous commençons à suivre les mêmes étapes. Autrement dit, nous examinons la charge sur le système, le numéro d'enregistrement, du tout.
Le seul écart par rapport à la norme que nous avons constaté est un pourcentage inférieur d'autorisations réussies. Autrement dit, le montant est le même, mais le pourcentage est légèrement inférieur. Je sais que cela pourrait être du spam, etc. Mais toutes les autres mesures techniques sont absolument normales. Et nous sommes arrivés au point où nous marchions presque le long des lignes de la base de données et essayions de vérifier s'il y avait quelque chose qui pouvait être attiré par l'œil. Absolument rien!
Nous nous sommes assis une demi-dimanche, nous avons continué lundi aussi, mais nous étions déjà sûrs que le problème n'était pas technique. Laissez-les décider eux-mêmes. Et ici lundi, je m'assois au travail et un employé de leur service de comptabilité m'appelle:
- Écoutez, pouvez-vous m'aider rapidement?
- De quoi as-tu besoin?
- Pouvez-vous retirer le badge American Express du site?
- Bien sûr que je peux! Pourquoi tout d'un coup?
- Vous savez, nous discutons avec eux ici, et jusqu'à ce que nous acceptions l'américain
Exprimez en général.
"Je m'excuse de demander, quand avez-vous cessé de les prendre?"
- Avant le week-end, à mon avis - le vendredi ou le samedi .
Personne sensé ne mettrait jamais une collection métrique sur le pourcentage d'autorisations d'un certain type de carte de crédit! Après cet incident, bien sûr, nous nous sommes mis.
Pourquoi je te dis ça? Vous devez d'abord regarder l'entreprise, car tous ces problèmes systémiques étaient tout simplement invisibles. Ils n'ont réveillé personne au milieu de la nuit, nous n'avons pas vu qu'il s'agissait de problèmes. Il est facile de remarquer une baisse de revenu, et tout le reste doit être suivi pour que vous puissiez corréler ces données avec les données de l'entreprise.
Succès pour les entreprises
Pour une entreprise, le succès peut être différent, cela dépend des objectifs. Plus important encore, comment mesurer cela? Traditionnellement, nous mesurons les performances du système, parfois en tant qu'ingénieurs, oubliant que vous pouvez mesurer n'importe quoi.
Par exemple, vous pouvez mesurer votre propre alcoolisme. Au fait, je ne plaisante pas. Dans notre bureau, il y a une bière pression avec quatre robinets. Puisque nous sommes tous ingénieurs, mon collègue a décidé de mettre des capteurs Raspberry Pi pour voir combien de bière nous buvons et laquelle.

Cela ressemble à une simple blague, mais en fait, c'est pratique, car nous voyons quand la bière arrive à son terme et nous devons remplacer le baril. En général, nous pouvons voir quand les gens boivent, quelle bière ils préfèrent - sombre, claire, etc. Au fait, le sommet est mon anniversaire.
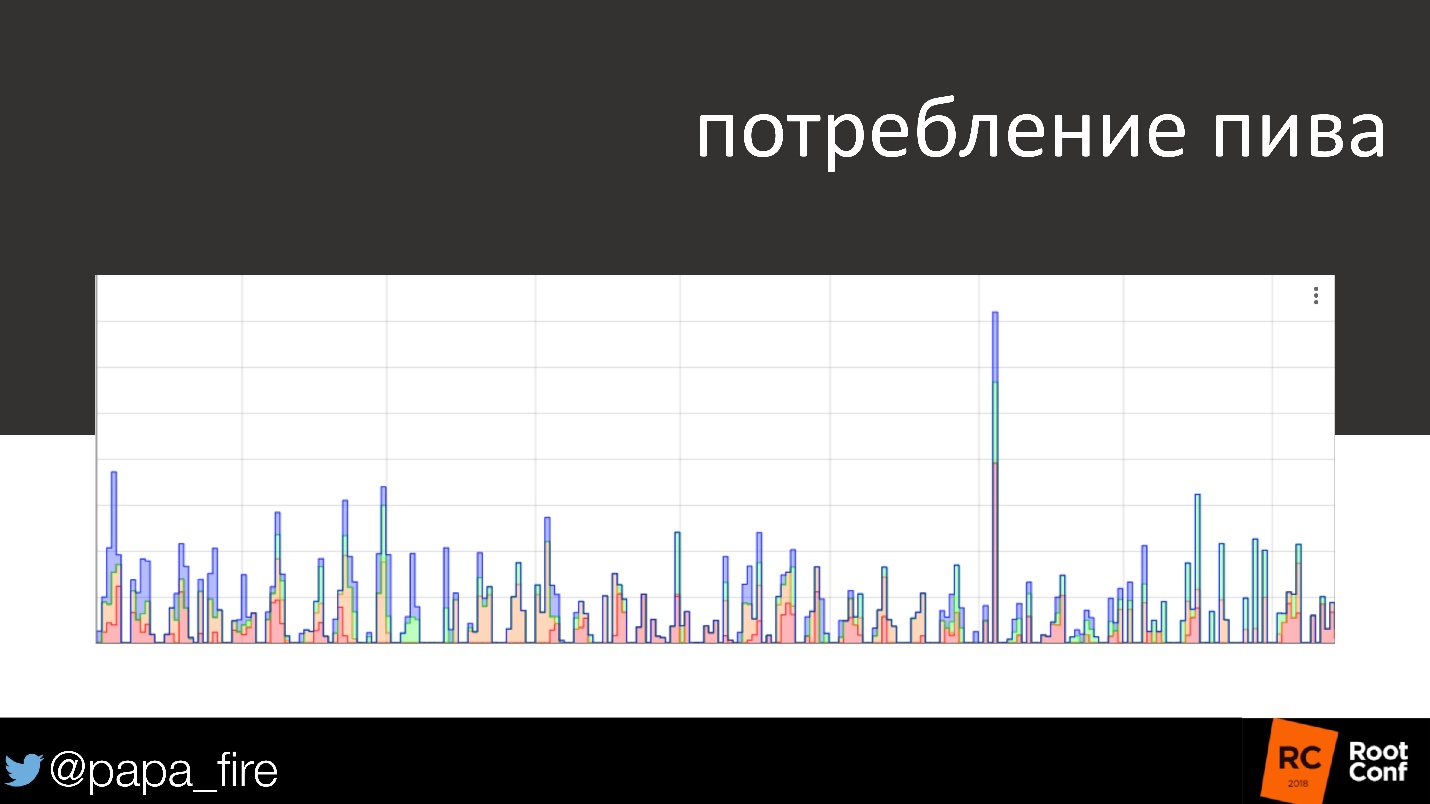
Absolument par hasard, nous avons trouvé une autre application pour cela.
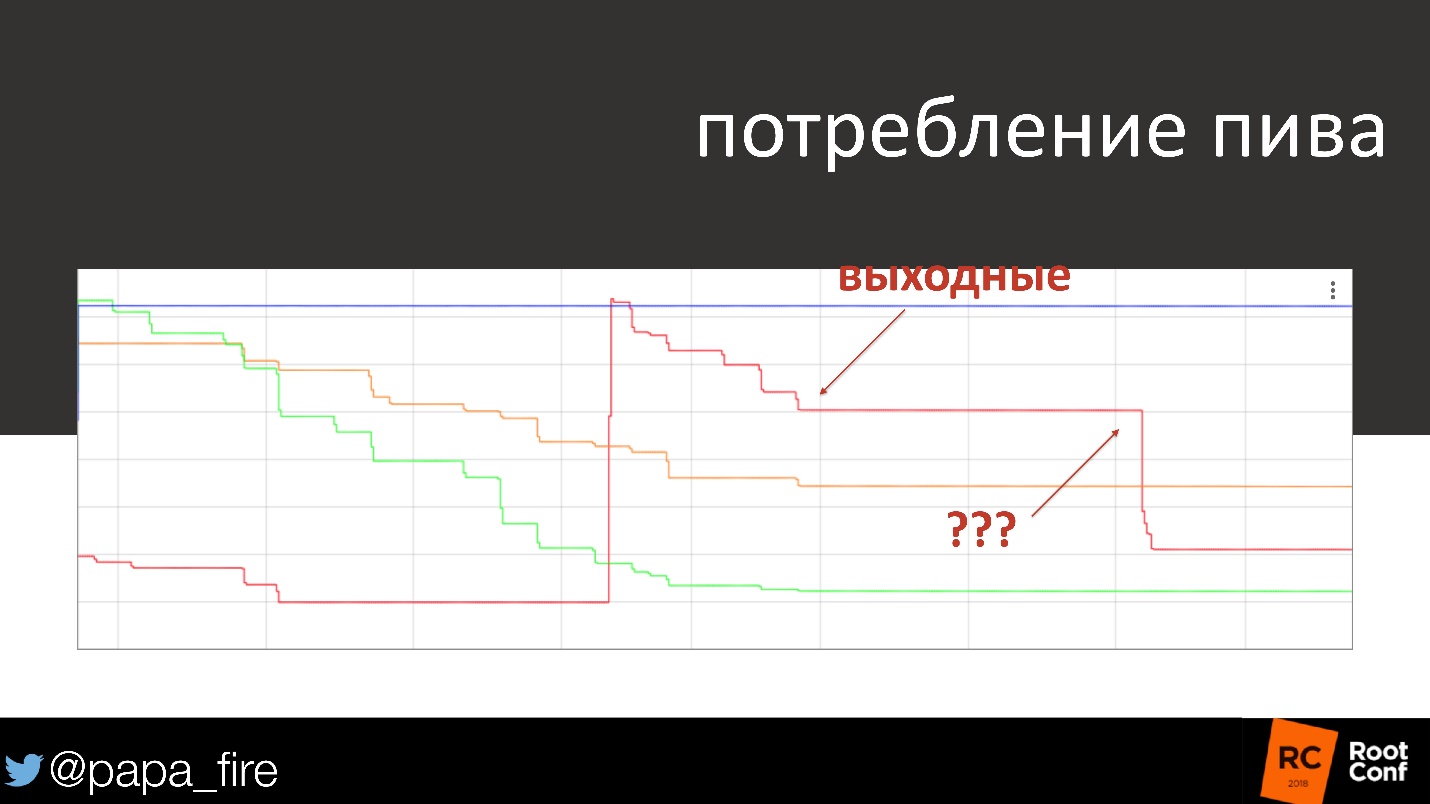
Le graphique montre la consommation de bière sur plusieurs jours et week-ends. Le week-end, la consommation d'alcool diminue généralement, disparaît presque. Un jour, nous arrivons lundi, regardons l'horaire et voyons que quelqu'un samedi a bu un quart de baril de bière. Le graphique montre l'heure exacte dans une demi-heure. Il s'est avéré que les nettoyeurs qui étaient venus samedi devaient gueule de bois, donc ils étaient gueule de bois.
Une blague, mais au final ils ont eu de sérieux problèmes, car il est généralement mauvais de boire au travail, et même de la bière de quelqu'un d'autre!
En fin de compte, toutes les mesures peuvent être utiles. Même cette métrique, que nous avons collectée uniquement pour notre propre fan, s'est avérée importante dans autre chose. Mais fondamentalement, les mesures vraiment nécessaires se résument à de l'argent. L'argent est le plus important pour les entreprises.
En règle générale, les critères de réussite d'une entreprise impliquent en fin de compte de l'argent:
- profit;
- revenu
- les coûts
- efficacité.
Mesures commerciales:
- Inscription
- les achats;
- vues des annonces
- conversions;
- pourcentage de retour;
- quantité de bière bue
Tout cela a un équivalent monétaire.Soit dit en passant, très probablement, toutes ces mesures sont déjà collectées dans votre entreprise - soit par les ventes, soit par le marketing. Vous n'avez donc pas besoin d'inventer une roue, vous pouvez simplement prendre les mesures existantes dans votre propre système.
Tout doit être considéré dans le contexte des affaires. Nous avons parlé de mesures spéciales pour les entreprises. D'autres, à savoir les métriques techniques, peuvent également être envisagées dans ce contexte.
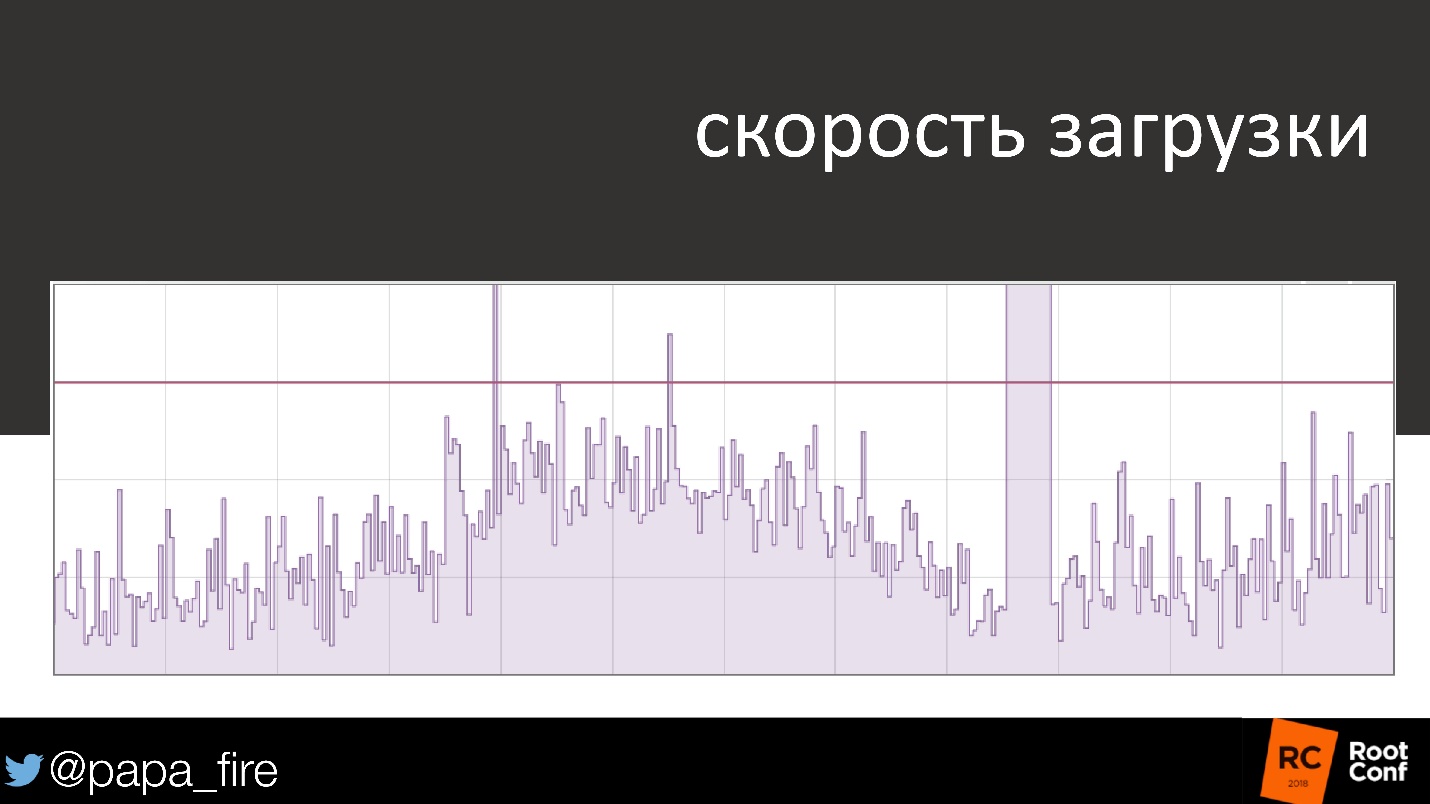
Par exemple, la vitesse de téléchargement est un programme assez standard. Au début, tout est en ordre, cela monte - descend, monte - descend, et soudain, un problème clair. Il a été réparé et le calendrier est revenu à sa forme standard - le 99e centile est inférieur au seuil, le SLA n'est pas violé.
Si vous prenez le même calendrier et regardez le nombre d'utilisateurs qui ont été affectés, le problème est immédiatement différent.
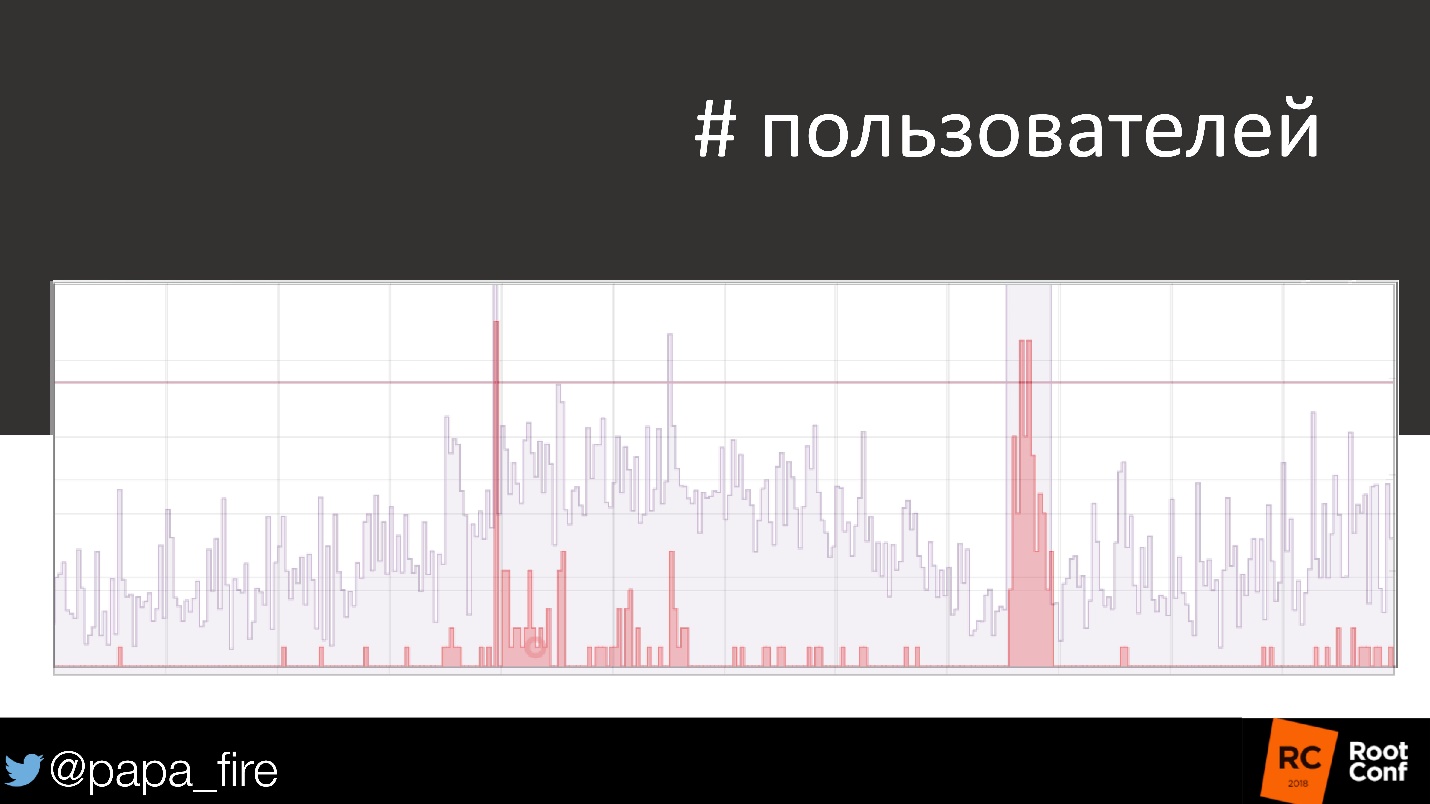
, . , , , . , .
. , . . . , 3 , .
— . , , , , .
.
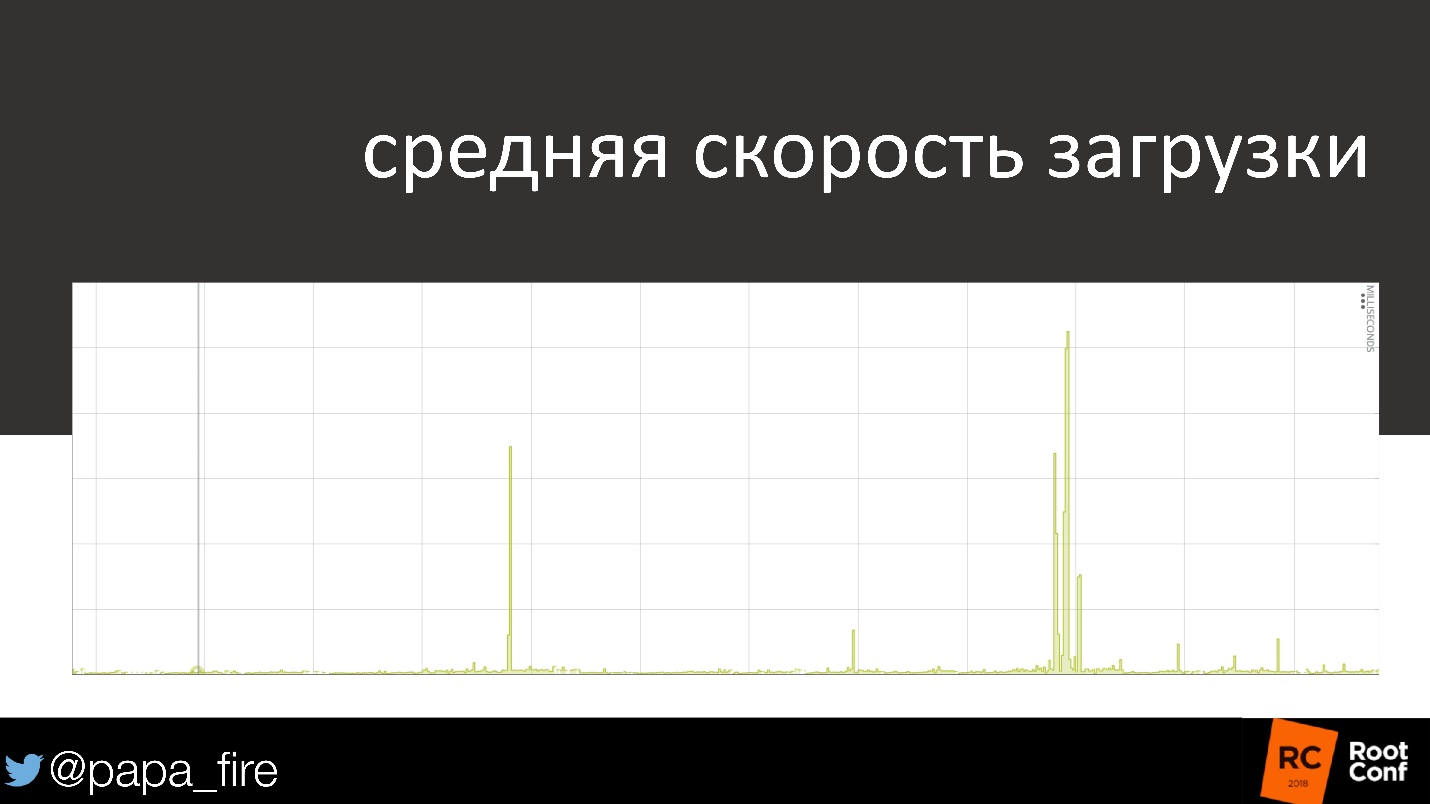
: , , , - .
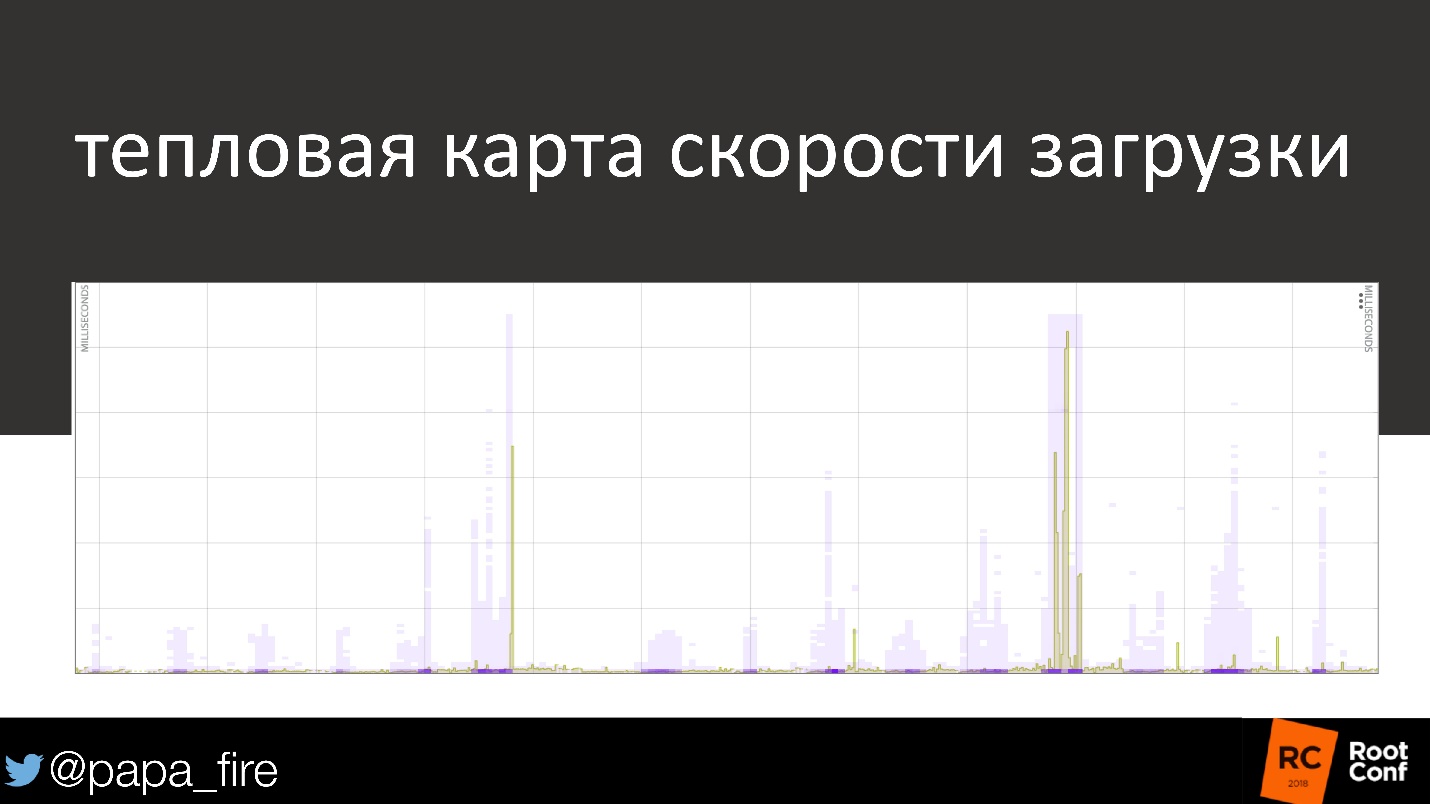
, . , , , 50 % « », , .
1 ?
1-2 . . 10 000 , . , 10 000 , - .
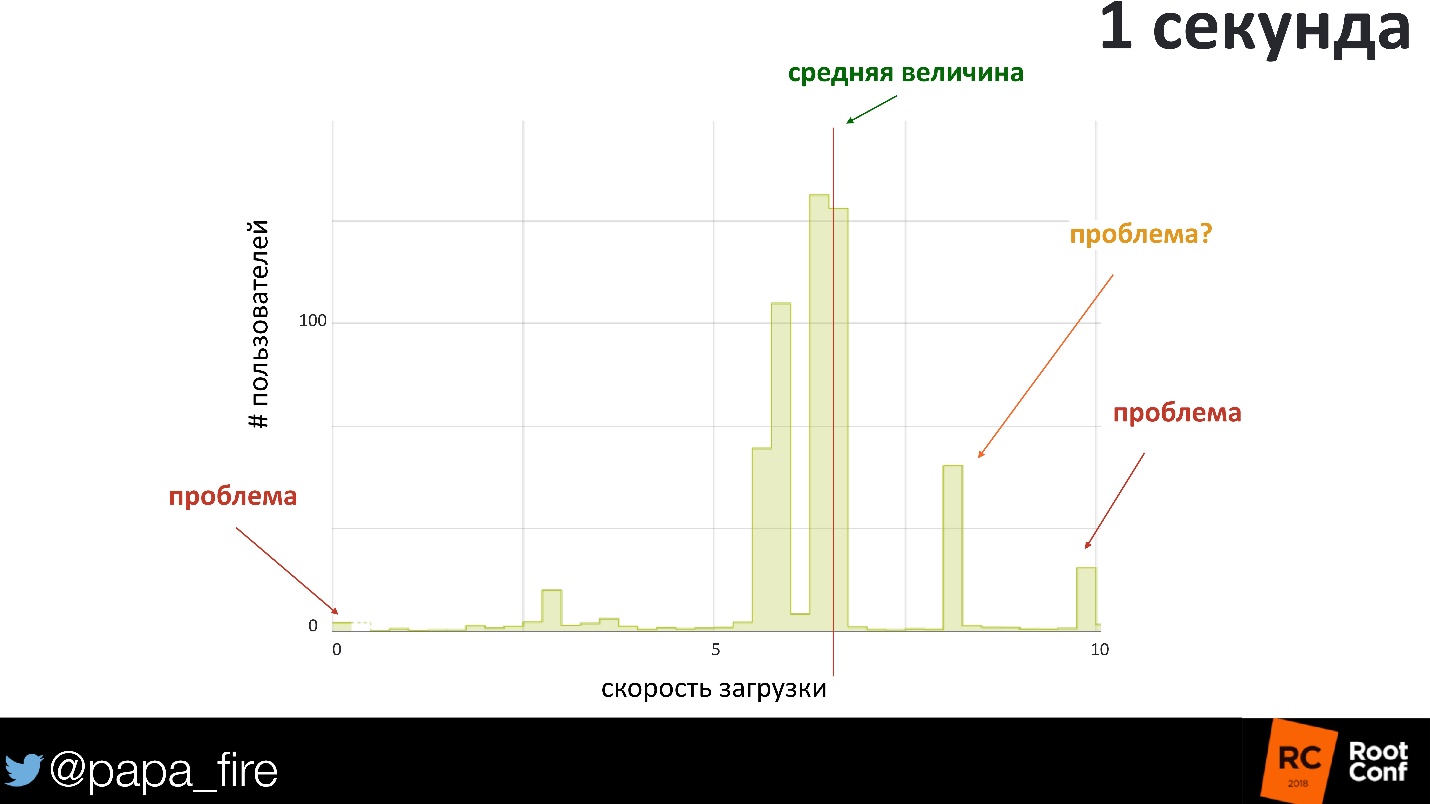
1 . 600-700 . , 600 — , . , , . 800 , , — .
, , . 0 , - , ! .
, - . — , .
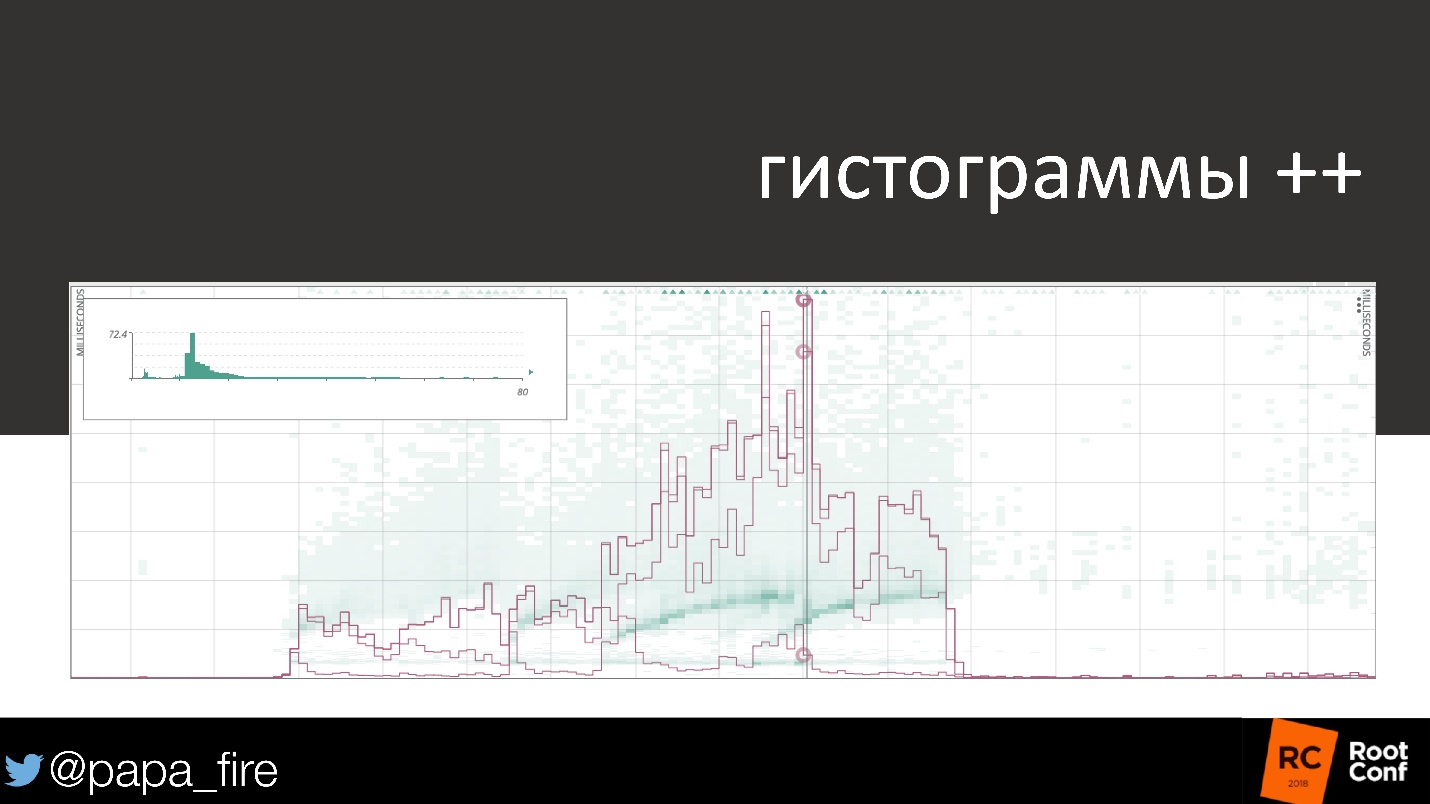
99- 50- , . , .
, — , DevOps — .
, , .
Value stream mapping — . , . , , , , , . , , .
:
- MTTD (mean time to discovery) — , .
- MTTR (mean time to recovery) — , .
- , .
- / .
, , , , . : « — . , , ».
, , . , .
. , — , , . , . .
— , , . , , , . — .
Les 1er et 2 octobre, une conférence professionnelle sur l'intégration des processus de développement, de test et d'exploitation de DevOpsConf Russie se tiendra à Moscou .
Si vous commencez tout juste à travailler sur les principes de DevOps, ce sera une excellente occasion de regarder de vrais exemples de travail depuis le début jusqu'à une mise en œuvre réussie, et de vous inspirer d'idées telles que le rapport de Leon. Pour les professionnels avancés, il y aura des rapports avec une immersion profonde dans le sujet et des détails importants, et des discussions sur de nouveaux produits.
Venez voir comment le développement, les tests et le fonctionnement peuvent être indissociables .