Le sujet d'aujourd'hui - la fiabilité de World of Tanks Server - est plutôt glissant. La fiabilité du jeu est un compromis, donc tout doit être fait rapidement et rapidement dans le développement du jeu. La charge sur les serveurs est importante et les utilisateurs ont tendance à casser quelque chose juste par intérêt. Levon Avakyan de RIT ++ a expliqué ce que Wargaming fait pour garantir la fiabilité.
Habituellement, quand ils parlent de fiabilité, la surveillance, les tests de résistance, etc. sont constamment mentionnés. Il n'y a rien de surnaturel là-dedans, et le rapport a été consacré à des moments spécifiques aux Tanks.

À propos du conférencier: Levon Avakyan travaille pour Wargaming en tant que responsable des services de jeu et de la fiabilité de WoT et s'occupe des problèmes de fiabilité du serveur de tank.
Aujourd'hui, je vais vous expliquer comment nous procédons, y compris en quoi consiste le serveur World Of Tanks, en quoi il consiste, sur quoi il est construit, afin que vous compreniez le sujet de la conversation. De plus, nous examinerons ce qui peut mal tourner à l'intérieur du serveur lui-même et autour de lui, car le jeu est déjà plus que le serveur. Et nous parlerons également un peu des processus, car beaucoup oublient qu'un processus bien établi dans la production fait partie du succès non seulement en termes d'économie de ressources (de nombreuses pratiques proviennent de la production réelle), mais il affecte la qualité et la fiabilité de la solution.

Habituellement, quand ils parlent de fiabilité, la surveillance, les tests de résistance, etc. sont constamment mentionnés. Je ne l'ai pas inclus ici parce que je pense que c'est ennuyeux. Nous n'avons rien découvert de surnaturel là-dedans. Oui, nous avons également un système de surveillance, nous effectuons des tests de résistance avec des tests de résistance afin d'augmenter la fiabilité du système et de savoir où il peut tomber. Mais aujourd'hui, je vais parler de ce qui est plus spécifique pour les chars.
Technologie BigWorld
Il s'agit d'un moteur backend, ainsi que d'une boîte à outils pour créer des MMO.
Ce moteur BigWorld Server assez ancien (né à la fin des années 90 - début des années 2000) est un ensemble de processus différents qui prennent en charge le jeu. Les processus sont lancés sur un cluster, interconnectés dans un réseau de machines. En interagissant les uns avec les autres, les processus montrent à l'utilisateur une sorte de mécanique de jeu.
Le moteur s'appelle BigWorld, car il est très bon d'y faire des jeux, dans lesquels il y a un grand champ (espace), sur lequel se déroulent des opérations militaires (batailles). Pour les réservoirs, cela convient parfaitement.
En termes de fiabilité, les fonctionnalités clés suivantes ont été investies dans BigWorld:
- Équilibrage de charge. Le moteur alloue des ressources, essayant d'atteindre deux objectifs:
- utiliser le moins de machines possible;
- en même temps, ne chargez pas vos applications afin que leur charge dépasse une certaine limite.
- Évolutivité. Nous avons ajouté la voiture au cluster, lancé des processus dessus - ce qui signifie que vous pouvez compter plus de batailles et accepter des joueurs.
- Haute disponibilité. Si, par exemple, une voiture est tombée ou que quelque chose s'est mal passé avec l'un des processus de jeu qui sert le jeu lui-même, il n'y a rien à craindre - le jeu ne le remarquera pas, sera restauré à un autre endroit et fonctionnera.
- Maintenez l'intégrité et la cohérence des données. Il s'agit du deuxième niveau de tolérance aux pannes. S'il y a plusieurs clusters, comme dans Tanks, et qu'il y a eu une sorte de catastrophe dans le centre de données ou sur le canal principal, cela ne signifie pas que nous perdrons complètement les données de jeu auxquelles la personne a joué. Nous allons récupérer, la cohérence sera.
Les processus qui sont dans notre système et leurs fonctions- CellApp est le processus responsable du traitement de l'espace de jeu ou d'une partie de celui-ci.
Comme je l'ai dit, BigWorld fonctionne avec certains espaces que nous divisons en cellules. Chaque cellule spécifique de notre espace de jeu est calculée par une application spécifique.
- CellAppMgr - le processus qui coordonne le travail de CellApp, l'équilibrage de charge.
CellApp peut être nombreux, en conséquence, il doit y avoir un processus qui les contrôle.
- BaseApp gère les entités, isole les clients de travailler avec CellApp.
L'une des choses fondamentales dans BigWorld est le concept d'entité - par exemple, le compte d'un joueur. Tout ce que nous faisons sur le champ de bataille, nous le faisons avec cette entité. CellApps calcule la physique et la mécanique du jeu, comme le tir. BaseApp fonctionne avec des entités. Il sert le compte, le réservoir, etc.
- ServiceApp est une BaseApp spécialisée qui implémente une sorte de service.
Il s'agit d'une version simplifiée de BaseApp, un processus qui effectue diverses tâches de service. Par exemple, quelqu'un devrait pouvoir lire à partir de RabbitMQ. Il ne s'agit pas d'entités de jeu, mais également nécessaires.
- BaseAppMgr gère BaseApp et ServiceApp, car ils sont également nombreux.
- LoginApp crée de nouvelles connexions à partir des clients, ainsi que des utilisateurs mandataires sur BaseApp.
- DBApp implémente une interface d'accès au stockage (bases de données). Nous travaillons avec Percona, mais il peut s'agir d'une autre base de données.
- DBAppMgr coordonne le travail de DBApp.
- InterClusterMgr gère la communication intercluster.
- Reviewer est un inspecteur de processus qui peut redémarrer les processus.
- Bwmachined - un démon qui s'exécute sur chaque machine du cluster pour coordonner son travail. Il permet à tous les gestionnaires BaseApp de communiquer entre eux.
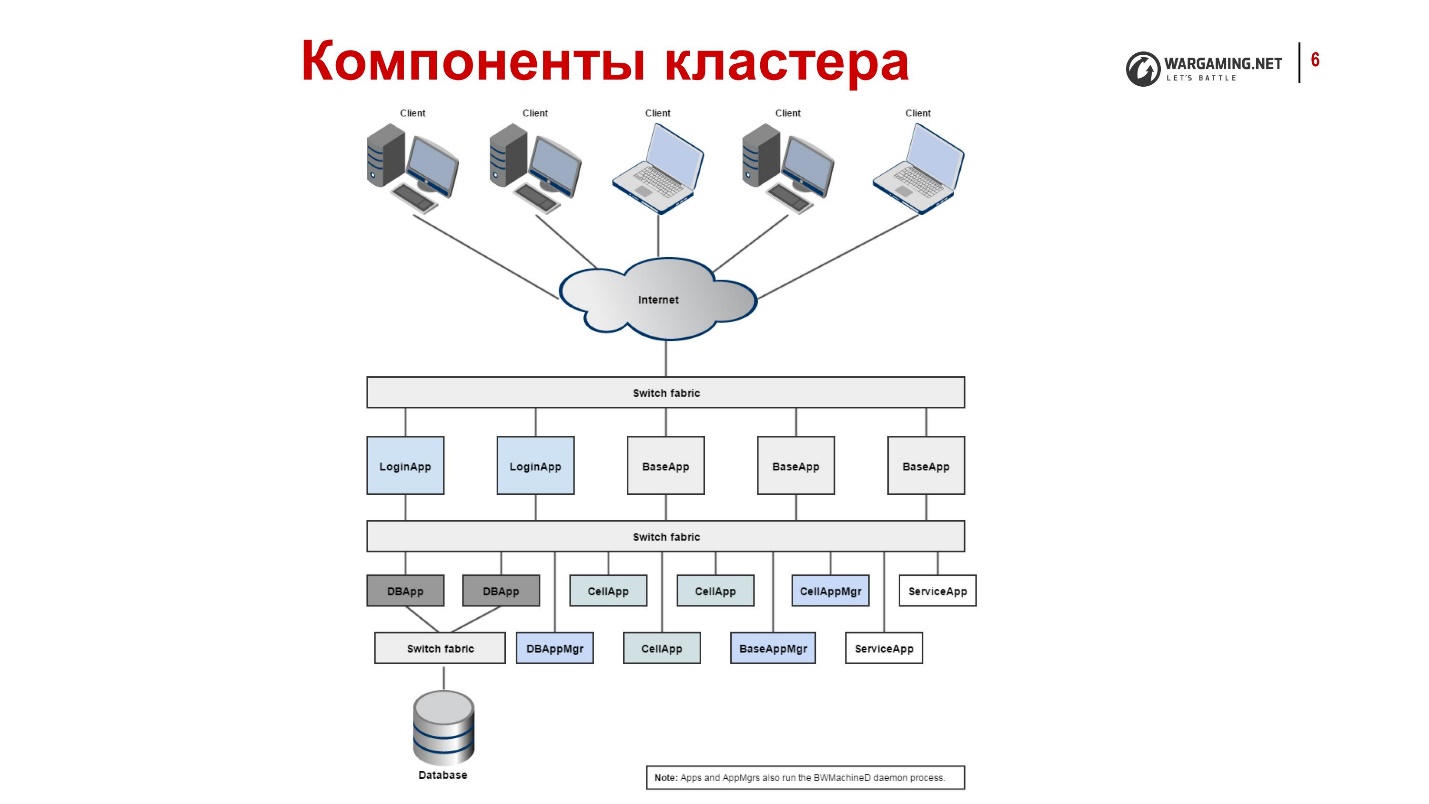
Voici à quoi ressemblent les chars de l'intérieur, si brièvement:
- Les clients se connectent via Internet, accédez à LoginApp.
- LoginApp les autorise à utiliser DBApp et émet une adresse depuis BaseApp.
- D'autres clients y jouent.
Tout cela est dispersé sur de nombreuses machines, chacune ayant un BWMachineD, qui peut gérer tout cela, orchestrer, etc.
Écosystème World of Tanks
Qu'y a-t-il autour? Il semblerait qu'il y ait un serveur de jeu et des joueurs - a choisi un tank, est allé jouer. Mais, malheureusement (ou joyeusement), le jeu se développe, et la mécanique du jeu de «juste tirer» ne suffit plus. En conséquence, le serveur de jeu a commencé à être envahi par divers services, dont certains étaient généralement impossibles à faire à l'intérieur du serveur, tandis que nous avons commencé à en supprimer d'autres spécialement pour augmenter la vitesse de livraison de contenu au joueur. Autrement dit, il est plus rapide d'écrire un petit service en Python qui fait une sorte de mécanique de jeu que de le faire à l'intérieur du serveur sur tous les BaseAPP, les clusters de support, etc.
Certaines choses, par exemple, les systèmes de paiement ont été initialement émis. Nous en subissons d'autres, car Wargaming développe plus d'un jeu, après tout. Il s'agit d'une trilogie: réservoirs, avions, navires, et il y a Blitz et des plans pour de nouveaux jeux. S'ils étaient à l'intérieur de BigWorld, ils ne pourraient pas être utilisés de manière pratique dans d'autres produits.
Tout s'est déroulé assez rapidement et de manière chaotique, ce qui a abouti à certaines technologies de zoo utilisées dans notre écosystème de réservoirs.
Technologies et protocoles clés:
1. Python 2.7, 3.5;
2. Erlang;
3. Scala;
4. JavaScript;
Cadres
5. Django;
6. Falcon;
7. asyncio;
Stockage:
8. Postgres;
9. Percona.
10. Memcached et Redis pour la mise en cache.
Tous ensemble pour le joueur c'est le serveur de tank:
- Point d'autorisation unique;
- Clavarder
- Clans;
- Système de paiement;
- Système de tournoi;
- Méta-jeux (carte globale, zones fortifiées);
- Portail de chars, Portail de clan;
- Gestion de contenu, etc.
Mais si vous regardez, ce sont des choses légèrement différentes écrites sur différentes technologies. Cela provoque des problèmes de fiabilité.
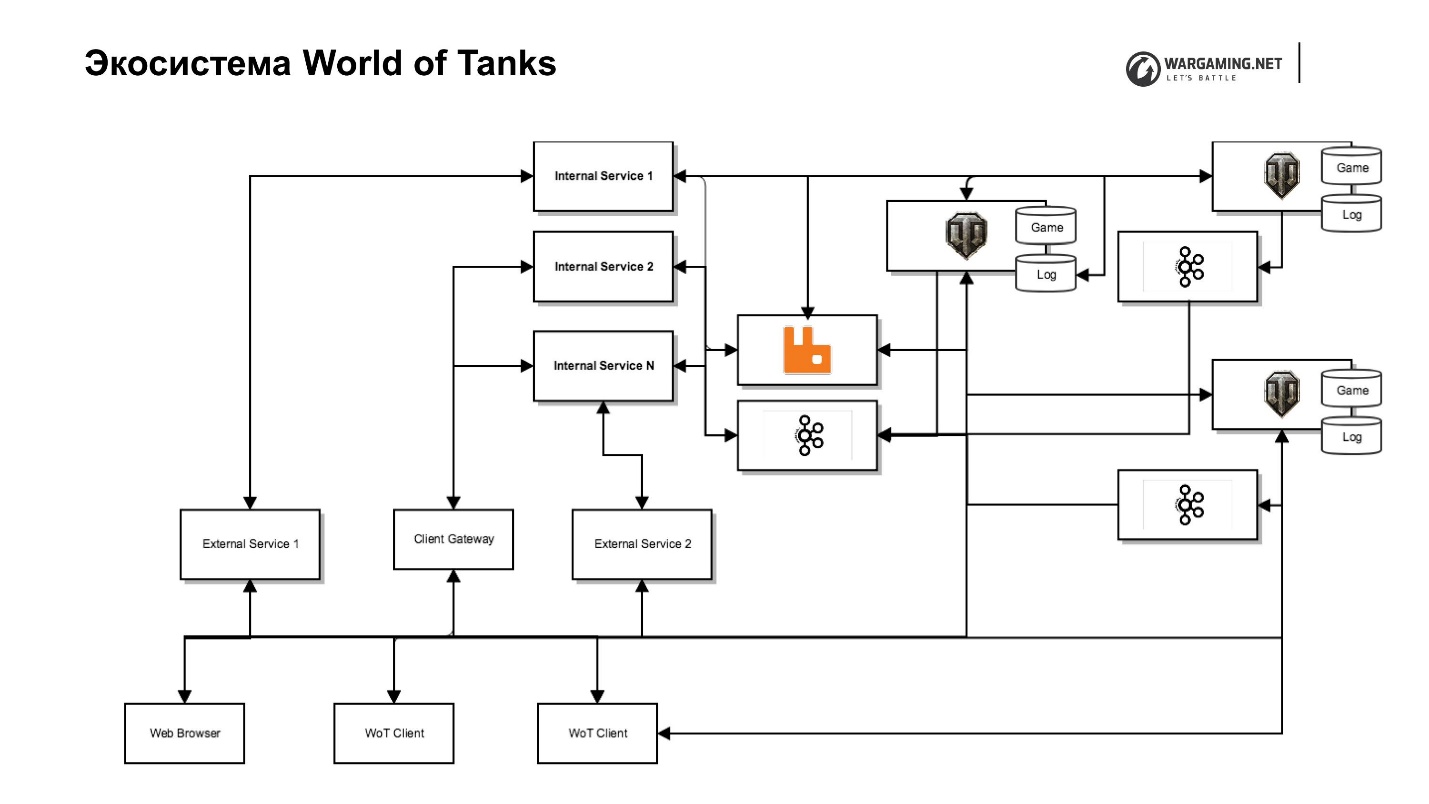
Le diagramme montre notre serveur de réservoir avec son écosystème. Il y a un serveur de jeu, des services Web (internes et externes), y compris des services complètement spéciaux qui sont situés dans le réseau principal et exécutent des fonctions de service et un service pour eux, qui implémentent réellement les interfaces. Par exemple, il existe un service de clan avec son propre portail de clan, qui vous permet de gérer ce clan, il y a un portail du jeu lui-même, etc.
Cette séparation nous permet de moins nous soucier de la sécurité, car personne n'a accès au réseau interne - moins de problèmes. Mais cela entraîne des efforts supplémentaires, car nous avons besoin de procurations qui donneront accès si nous devons les pousser à l'extérieur.
J'ai déjà dit que nous avions décidé de supprimer une partie de la logique du jeu et d'autres choses du serveur. Il y avait une tâche pour inclure en quelque sorte tout dans le client. Nous avons une merveilleuse passerelle client qui permet à un client de réservoir d'accéder directement à un serveur à partir de certaines des API de ces services internes - les mêmes clans ou API de nos méta-jeux.
De plus, nous avons poussé le Chromium Embedded Framework (CEF) à l'intérieur du client du réservoir. Nous avons maintenant le même navigateur. Le joueur ne le distingue pas de la fenêtre de jeu. Cela vous permet de travailler avec l'ensemble de l'infrastructure, en contournant le travail avec le serveur de jeu.
Nous avons de nombreux clusters - il en est ainsi - je vais vous dire pourquoi. Voilà à quoi ressemble la région de la CEI.
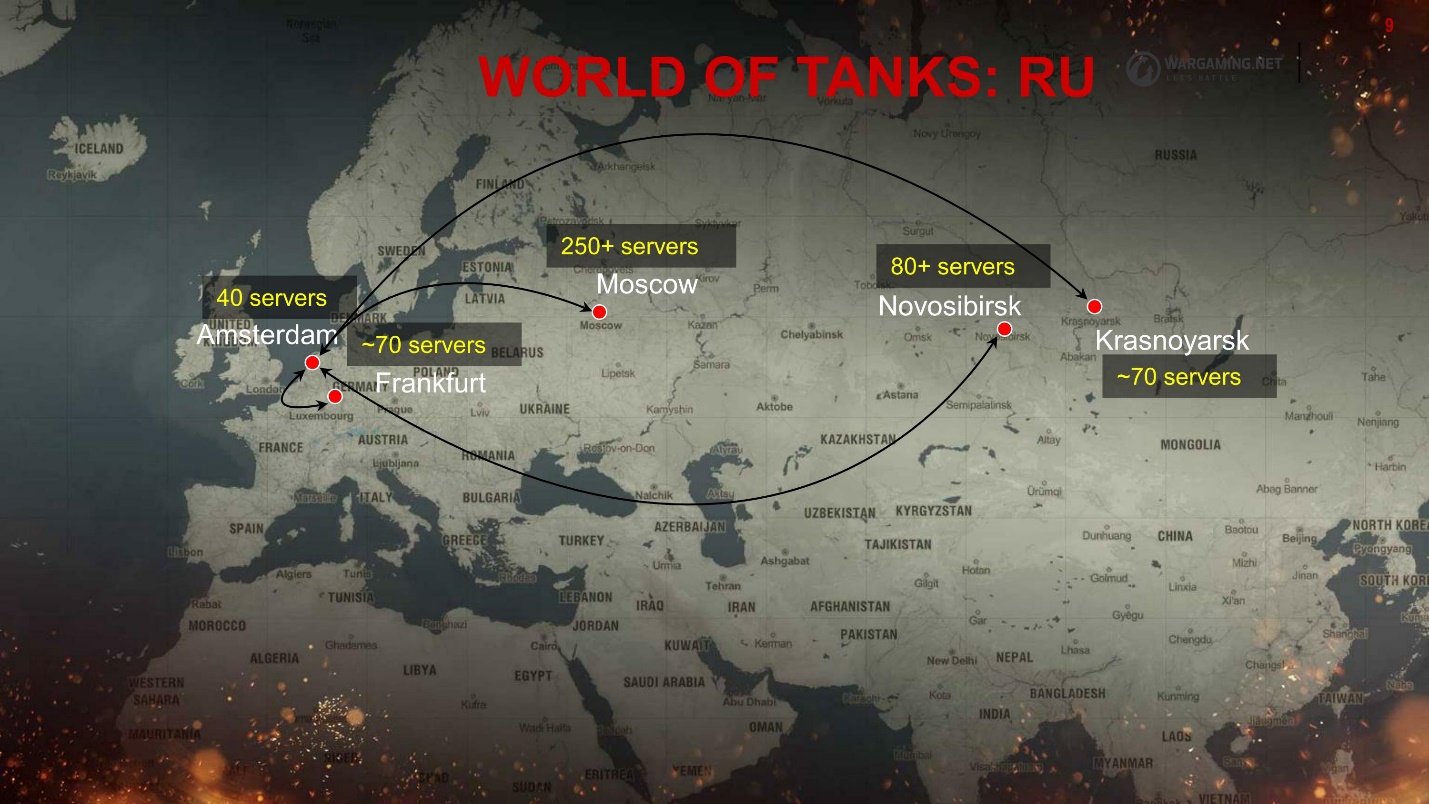
Tout est dispersé dans les centres de données. Les joueurs, selon l'endroit où le ping est le meilleur, se connectent à l'emplacement. Mais l'ensemble de l'écosystème ne se modifie pas de cette façon, c'est principalement en Europe et à Moscou, ce qui nous ajoute également quelques problèmes de fiabilité - latence supplémentaire et redirection.
Voilà à quoi ressemble l'écosystème de World of Tanks.
Qu'est-ce qui peut mal tourner avec toute cette économie? Tout ce que vous voulez! Et va J. Mais démontons-le.
Points de défaillance clés au sein d'un cluster
Défaillance d'une seule machine ou d'un seul processus
L'option la plus simple que nous pouvons prévoir est la défaillance d'une machine ou d'un processus au sein d'un cluster. Nous avons des groupes de 10 à 100 voitures - quelque chose peut s'envoler. Comme je l'ai dit, BigWorld lui-même fournit des mécanismes prêts à l'emploi qui nous permettent d'être plus fiables.
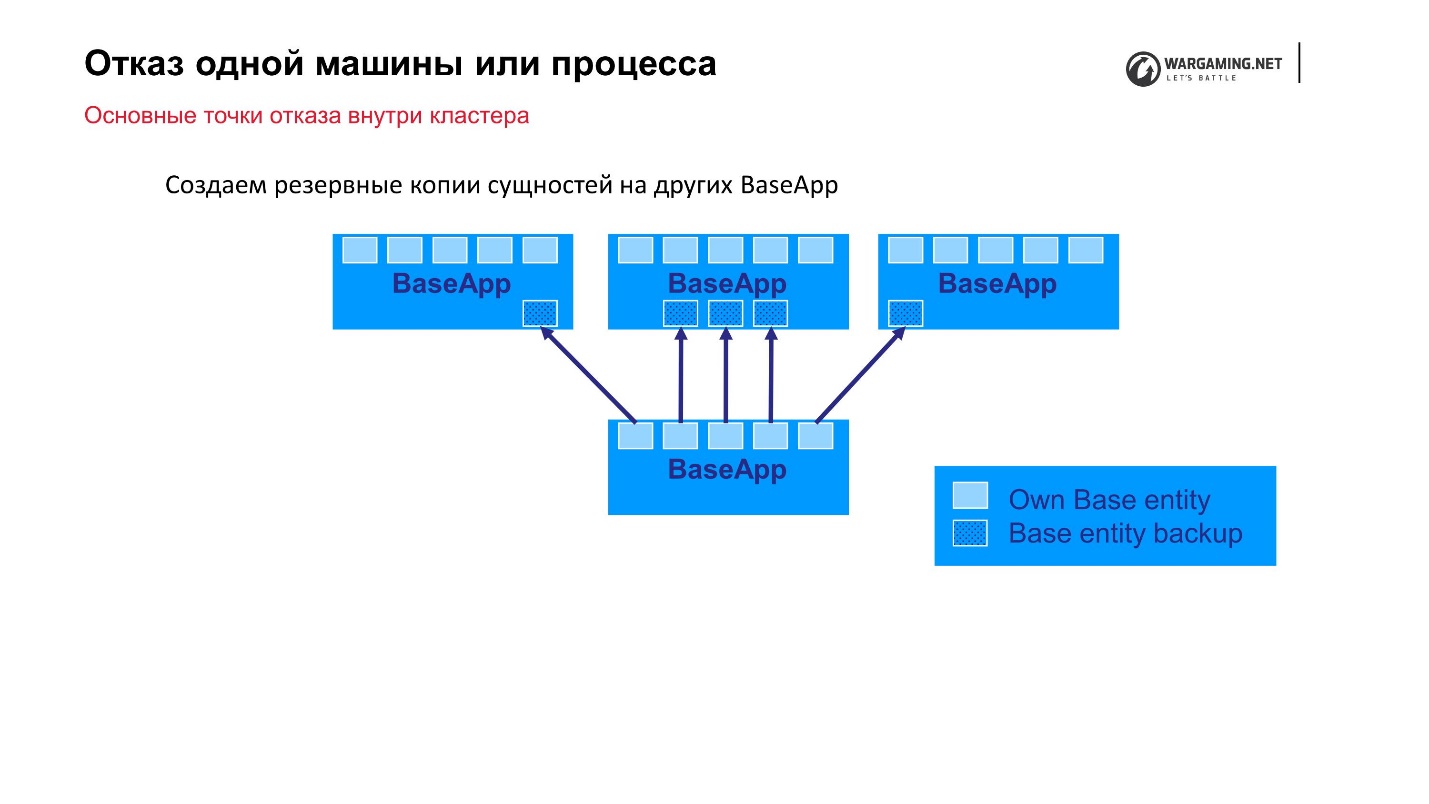
Schéma standard: il existe des BaseApps réparties sur différentes machines. Sur ces BaseApp, il existe des entités qui contiennent des entités d'état. Chaque BaseApp se sauvegarde avec Round Robin sur les autres.
Supposons que nous ayons un fichier et que certains BaseApp soient morts, ou que la machine entière soit morte - ça va! Les BaseApp restantes ont quitté ces entités, elles seront restaurées et le gameplay du joueur n'en souffrira pas.
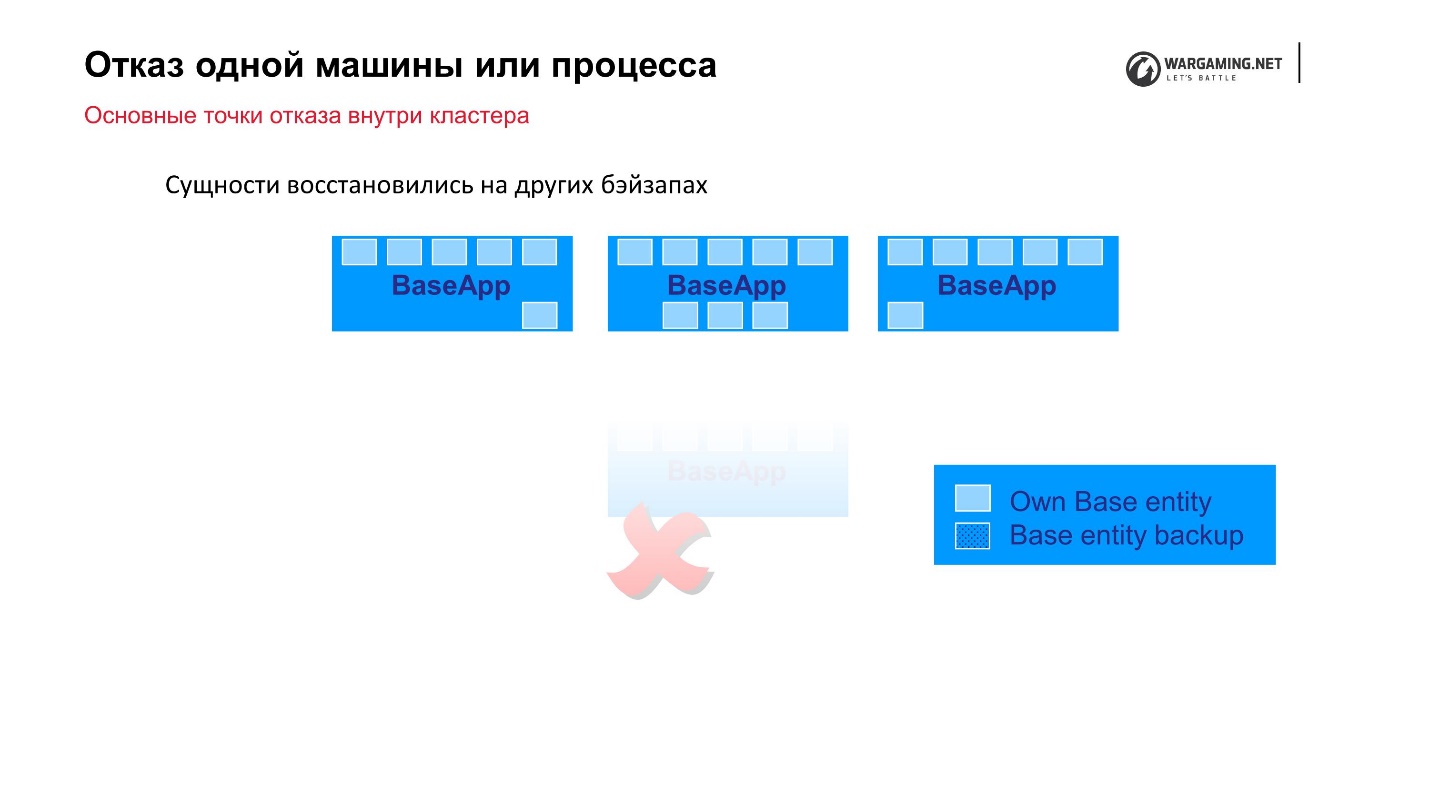
Les CellAPP font exactement la même chose, la seule chose est qu'ils stockent également leurs états sur BaseApps, et non sur d'autres CellAPP.
Cela semble être un mécanisme fiable, mais ...
Vous devez tout payer
Au fil du temps, nous avons commencé à observer ce qui suit.
• La création de copies de sauvegarde d'entités commence à consommer de plus en plus de ressources système et de trafic réseau.
En fait, le processus de sauvegarde lui-même commence à affecter la stabilité du système lorsque, à l'intérieur du cluster, la plupart du réseau est occupé à transmettre des copies à Round Robins.
• La taille des entités augmente avec le temps, à mesure que de nouveaux attributs et mécanismes de jeu sont ajoutés.
Mais le plus désagréable est que la taille de ces entités croît comme une avalanche. Par exemple, un joueur effectue une action (achète une propriété de jeu) et cette opération a commencé à ralentir. Nous ne l'avons pas encore terminé, mais nous avons enregistré les modifications apportées à ces attributs. Autrement dit, le système est si mauvais, et nous commençons toujours à augmenter la taille de la sauvegarde qui doit être effectuée. Il y a un effet boule de neige.
• La stabilité du système diminue globalement
En raison du fait que nous essayons d'échapper à la chute d'une machine ou d'un processus, nous abandonnons la stabilité de l'ensemble du système.
Qu'avons-nous fait pour y faire face ? Nous avons décidé pour chaque entité de mettre en évidence ce qui doit vraiment être sauvegardé. Nous avons divisé les attributs en mutables et immuables, et nous ne copions pas l'entité entière, mais nous sauvegardons uniquement ses attributs mutables. De cette façon, nous avons simplement réduit la quantité d'informations qui doivent vraiment être conservées. Maintenant, lors de l'ajout d'un nouvel attribut, celui qui le fait devrait voir plus clairement où l'attribuer. Mais en général, cela nous a sauvé la situation.
Pour être complètement franc, ce mécanisme a été défini dans BigWorld, mais dans Tanks à un moment donné, il n'était plus pris en charge jusqu'à la fin, et toutes les entités ne peuvent pas récupérer de leur sauvegarde. Dans Ships, par exemple, les gars le soutiennent. Là, vous pouvez éteindre les machines en toute sécurité - les informations seront simplement restaurées sur d'autres machines, et le client ne remarquera rien. Malheureusement, ce n'est pas toujours le cas dans Tanks, mais nous obtiendrons le retour de toutes ces fonctionnalités pour qu'elles fonctionnent comme il se doit.
Échec du centre de données. Multi-cluster
Si soudainement pas 1-2 voitures sont tombées et que nous avons commencé à perdre tout le centre de données, c'est-à-dire le cluster complètement, quelles propriétés le système devrait-il avoir pour que le jeu ne tombe pas dans une telle situation?
- Chaque cluster doit être indépendant, c'est-à-dire:
- doit avoir sa propre base de données;
- le cluster ne traite que ses espaces (arènes de combat).
Ainsi, si certaines arènes frappent, d'autres fonctionnent toujours. - Les clusters doivent communiquer entre eux pour que l'on puisse dire au second: «Je suis tombé!» Lorsqu'il augmente, les données seront restaurées à partir des copies enregistrées.
- Il est également souhaitable que vous puissiez transférer l'utilisateur d'un cluster à l'autre.
Pour le moment, le schéma de notre multi-cluster ressemble à ceci.
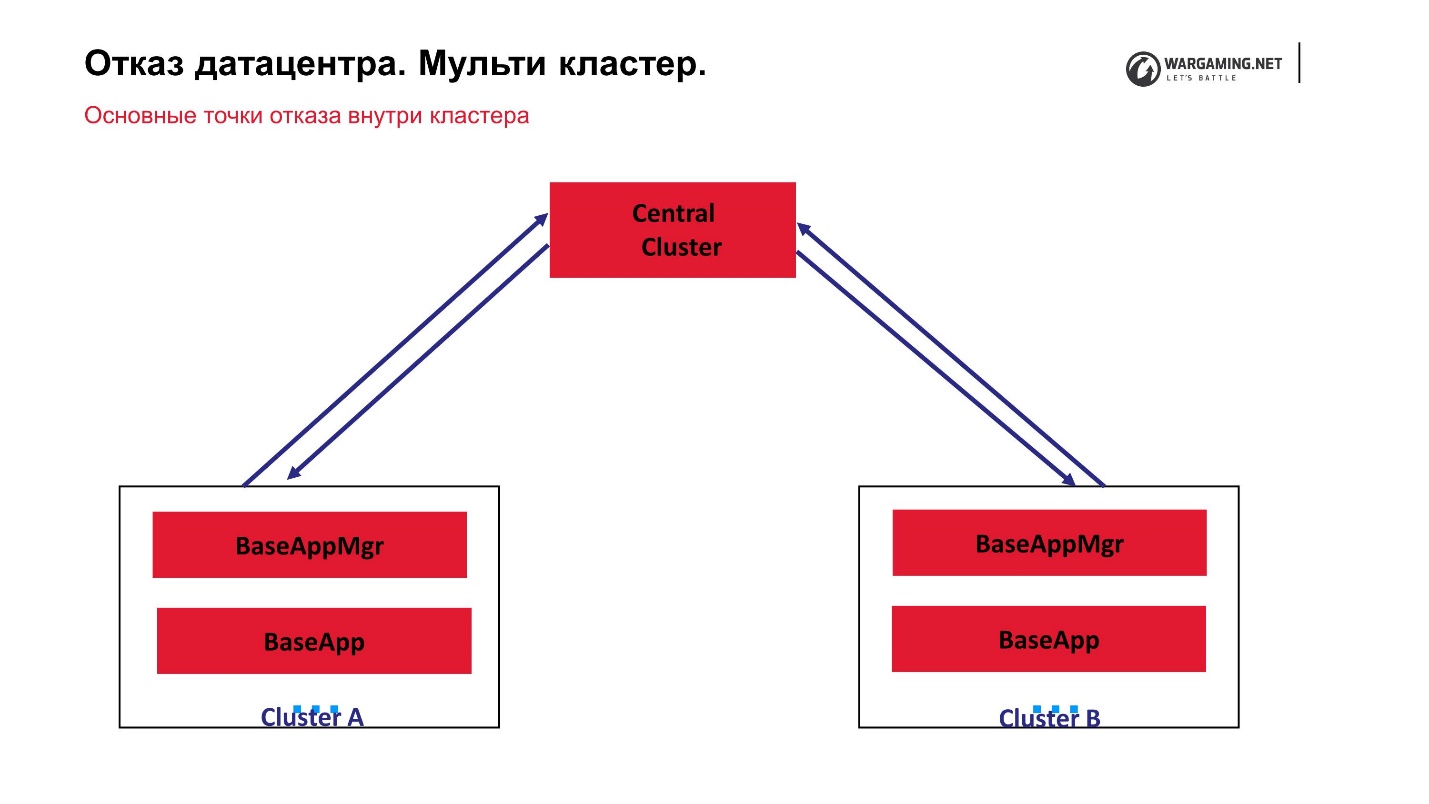
Nous avons un cluster central et ce que nous appelons des périphériques sur lesquels les batailles réelles sont menées. CellApp ne fonctionne pas sur le cluster central, sinon c'est exactement la même chose que tout le monde. C'est le point central du traitement des comptes: ils y montent, sont envoyés en périphérie, et en périphérie une personne joue déjà. Autrement dit, l'échec de l'un des clusters ne conduit pas à une perte d'opérabilité de l'ensemble du jeu. Même l'échec du cluster central ne permet tout simplement pas aux nouveaux joueurs de se connecter, mais ceux qui jouent déjà en périphérie peuvent continuer la partie.
Le fait que tout fonctionne pour nous via le cluster central s'est avéré parce qu'en général, la technologie BigWorld elle-même suppose qu'il existe un processus de gestion spécial entre les gestionnaires de clusters. En fait, ces gestionnaires inter-claster peuvent être quelque peu relevés.
Historiquement, Tanks avait besoin d'un multi-cluster, car il commençait à se développer en avalanche en ligne. Lorsque nous avons atteint le pic de 200 000 joueurs, le trafic entrant d'eux a simplement cessé d'être placé dans le centre de données sur le réseau. Nous avons dû littéralement agenouiller une sorte de solution pour que les joueurs puissent être lancés dans plusieurs centres de données.
En fait, nous n'avons gagné que parce que nous avons maintenant un multi-cluster. Il est également devenu utile pour les joueurs, car le ping, c'est-à-dire l'accessibilité sur le réseau, affecte considérablement le gameplay. Si le retard est supérieur à 50-70 ms, cela commence déjà à affecter la qualité du jeu lui-même, car dans Tanks, tout est calculé sur le serveur. Il n'y a aucun calcul sur le client. Par conséquent, gardez à l'esprit qu'il n'y a pratiquement rien à faire. Bien sûr, certains mods y sont fabriqués, mais ils n'affectent pas le processus lui-même. Vous pouvez essayer de deviner ce qui se passera, mais affecter les mécanismes de jeu eux-mêmes - non.
Grâce à cette approche, notre
cluster central est devenu un point d'échec . Tout était fermé sur lui. Nous avons décidé - puisque ces machines et une grande base de repaire de jeu se tiennent là, que nos périphériques s'occupent exclusivement des combats. Ensuite, il n'est vraiment pas nécessaire de stocker de grandes quantités d'informations - les batailles sont jouées et sont jouées - verrouillons tout là-bas.
Pour réécrire absolument tout pour s'éloigner du concept de cluster central, il n'y a plus de temps, ni de désir particulier. Mais nous avons d'abord décidé d'enseigner aux clusters périphériques à communiquer entre eux. Ensuite, nous avons creusé un trou en eux afin qu'il soit possible de les influencer en utilisant des services tiers.
Par exemple, afin de créer une bataille plus tôt, il était nécessaire de dire au cluster central qu'il était nécessaire de créer une bataille sur une partie de la périphérie. De plus, par des mécanismes internes, les entités se déplaçaient, l'essence de l'arène était créée, etc.
Il est désormais possible de contacter directement la périphérie, en contournant le cluster central. Nous lui retirons donc le travail supplémentaire. Mais jusqu'à présent, il n'y a aucun désir de basculer complètement vers un schéma dans lequel tous les clusters sont presque peer-to-peer, et tout cela est contrôlé par certains processus, mais pas le cluster.
Je vous rappelle qu'en plus du cluster de jeux avec ses BaseApps, CellApps et autres, nous avons un écosystème.
Nous essayons de nous assurer que les performances de l'écosystème n'affectent pas le gameplay. Dans le pire des cas, par exemple, le système de tournoi ne fonctionne pas, mais vous pouvez jouer au hasard - de toute façon, la plupart des gens jouent au hasard. Oui, nous avons abaissé la qualité, mais en général, vous pouvez survivre plusieurs heures sans tournois.
Cela n'arrive pas toujours. Premièrement, il existe déjà de tels services Web qui sont profondément intégrés dans le jeu. Par exemple, un point d'autorisation unique est un service qui vous permet de vous connecter sur le Web ou quelque part en un seul endroit, et d'être connecté à l'ensemble de l'univers Wargaming.
Le deuxième exemple est un service qui sert les achats et les transactions de jeux. Il a également dû être introduit dans le jeu uniquement parce que nous avions besoin d'une trace des achats du joueur. Le fait est que dans certaines régions, nous sommes obligés d'afficher des informations au client sur la propriété du jeu achetée pour de l'argent réel et celle pour l'argent du jeu. Au départ, le système ne le supposait pas, personne ne l'a exposé il y a 5 ans, mais la
loi est sévère: vous devez le faire - le faire .
Points de défaillance de l'écosystème de World of Tanks
Problème numéro 1. Charge accrue
Nous avons un multi-cluster dans lequel 10 clusters avec un grand nombre de machines. Les joueurs les jouent et le web est petit. Personne n'achète cinq machines supplémentaires dans chaque centre de données. Mais en même temps, nous fournissons toutes les mêmes fonctionnalités et tout ce qui est nécessaire directement à l'intérieur du client. C'est le principal problème.
L'interactivité et la réactivité de l'interface sont la principale source d'augmentation de la charge de l'écosystème.
Je vais donner deux exemples du service de clan:
- Vous souhaitez inviter un autre joueur dans le clan. Bien sûr, je souhaite que l'invité reçoive immédiatement une notification, et il pourra vous rejoindre. Pour implémenter cela, il est nécessaire de faire en sorte que le service de clan informe le client d'une manière ou d'une autre, ou de laisser le client demander au service Web de temps en temps: «Est-ce que quelque chose a changé? Ai-je de nouvelles invitations? " Il s'agit de la première option d'où peut provenir la charge supplémentaire.
- Les chars ont un régime fortifié. Supposons qu'il soit joué non par une seule personne, mais par plusieurs. Tous les joueurs ont une fenêtre ouverte avec des zones fortifiées. Le commandant a construit le bâtiment. Il est conseillé que pour tous ceux qui ont cette fenêtre ouverte, le bâtiment apparaisse immédiatement.
La décision sur le front avec l'enquête n'est pas très bonne. En fait, cela fonctionne, c'est juste que vous devez allouer autant de capacités pour cela que cette fonctionnalité n'apportera aucun profit à l'entreprise. Et si la fonctionnalité n'apporte pas de profit, vous n'avez pas besoin de le faire.
Mon conseil personnel sur la façon de gérer cela: la meilleure façon de rendre le système plus fiable sous charge est généralement de réduire la charge de manière logique.
Vous ne devriez pas vous asseoir avec le fer, trouver des systèmes nouveaux, optimiser quelque chose - de toute façon, plus la charge est élevée, plus il y aura d'artefacts que vous ne pourrez pas échapper. De plus, des artefacts se produiront même à des niveaux d'abstraction de plus en plus bas - d'abord avec des applications, puis avec différents services Web, puis vous accéderez au réseau (Cisco, etc.). À un certain niveau, vous ne pouvez tout simplement pas résoudre les problèmes.
Si vous réfléchissez bien, ils peuvent simplement être évités.
La première chose que nous avons faite a été d'
apprendre à notifier les clients via un serveur de jeux en utilisant son infrastructure. Par exemple, lorsqu'une invitation arrive au clan, nous disons au serveur: «Nous avons invité telle ou telle personne», puis le cluster cluster lui-même trouve celui à qui la notification doit être envoyée, d'autant plus qu'ils ont une connexion. Autrement dit, nous poussons du service, et personne ne nous déverse constamment. , , . , , .
—
Web-sockets (nginx-pushstream) . , Web-sockets. , Chromium Embedded Framework — , , Web-sockets Nginx. pushstream, Web-sockets .
№ 2.
, , ,
— . , , — .
, , .
? : - , - , , . - , , . .
.

,
120 Game Play . . , , . , . .
3 , :
- HTTP API;
- RabbitMQ — ;
- Apache Kafka .
, , , , , . , - — , . , .
1. HTTP— HTTP. , , -, . :
, , . , , , Django, 100 200 , API, . , , - 30-40 , , . , — .
, , HTTP, — . . — — . ,
, , , .
. . - , - API — API, .
— , . , , . , 10 , - 100 500. , HTTP . nginx' , — .
, HTTP , .
2. RabbitMQRabbitMQ BigWord .
— - , , , .
: . , API: « N — ». , , , , — . , .
«», «», — .
RabbitMQ , , , , , , , .
— RabbitMQ .
3. Kafka, , — Kafka. , RabbitMQ - .
, , , . , , . . Kafka. , — , .
, . , , - — .
Kafka , , , - , . .
— .

:
- . , - , ..
- — , , , .
- — , . , , .
. , , , entity. . , , .
DLC
, DLC (Development Lifecycle) — , , .
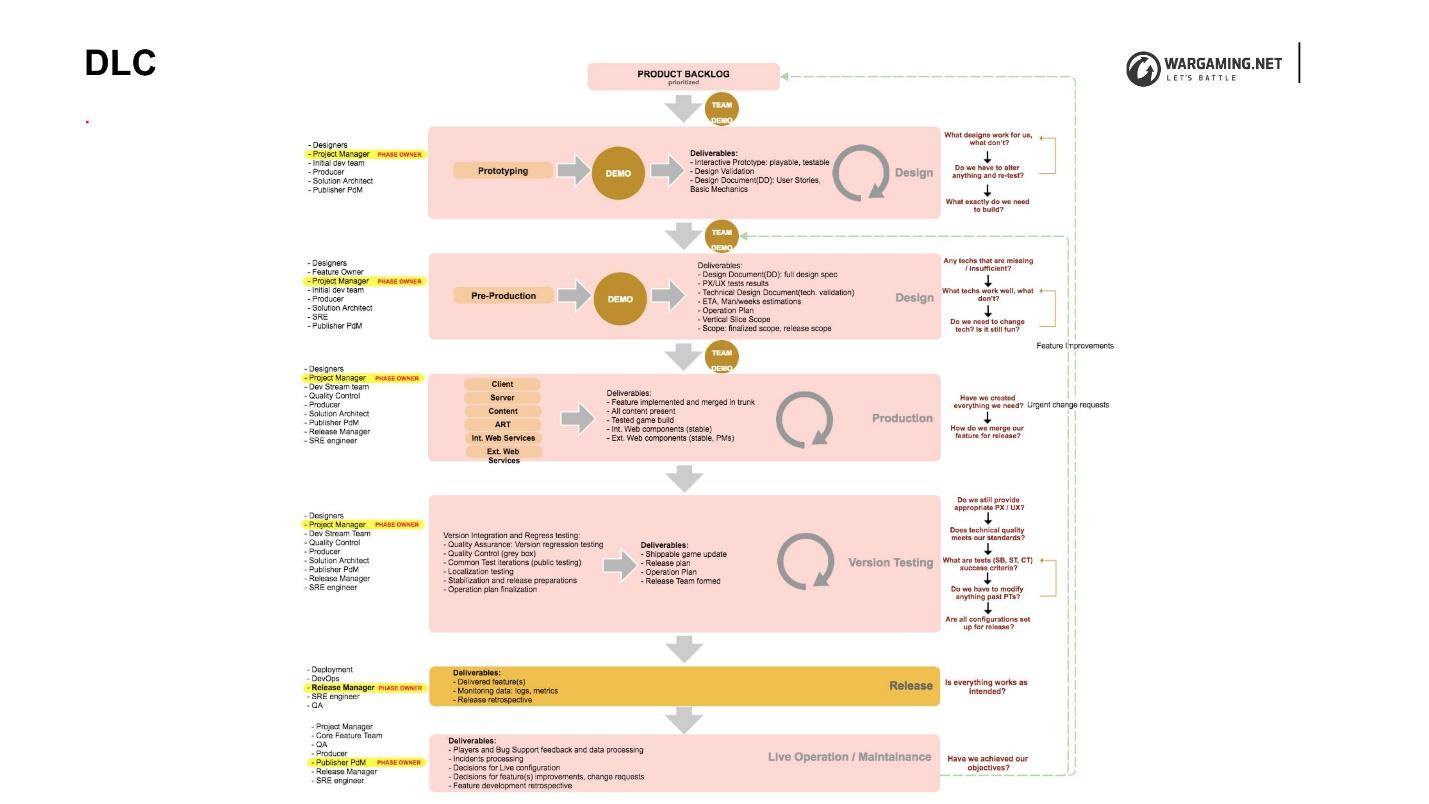
, , . DLC , , . , . , , , .
DLC, . , , , .
DLC, , :
•
( )., , «- , », . , , , , .
• : SRE.
, solution-, technical-owner, reability- — , - , game- . , , , . - , , , , . , .
•
SRE .— - . , . , SRE -. SRE , : « , , , — !» , .
QA , , - , , — .
BigWorld Technology «» . , . . « », .
« » , , . — «» (, ) — . , . , - .
: ++. , 40 , . , .RootConf — DevOpsConf Russia . DevOps 1 2 , . , . , — !