 Pour moi, cela a commencé il y a six ans et demi, lorsque, par la volonté du destin, j'ai été entraîné dans un projet fermé. Dont le projet - ne demandez pas, je ne dirai pas. Je peux seulement dire que son idée était simple comme un râteau: intégrer le front-end de clang dans l'IDE. Eh bien, comme cela a été fait récemment dans QtCreator, dans CLion (dans un sens), etc. Clang était alors une étoile montante, beaucoup se penchaient sur la possibilité d'utiliser enfin le parseur C ++ à part entière presque gratuitement. Et l'idée, pour ainsi dire, était littéralement dans l'air (et l'auto-complétion du code intégré à l'API clang était comme suggéré par Be), il fallait juste le prendre et le faire. Mais, comme l'a dit Boromir, "Vous ne pouvez pas simplement le prendre, et ...". C'est donc arrivé dans ce cas. Pour plus de détails - Bienvenue sous cat.
Pour moi, cela a commencé il y a six ans et demi, lorsque, par la volonté du destin, j'ai été entraîné dans un projet fermé. Dont le projet - ne demandez pas, je ne dirai pas. Je peux seulement dire que son idée était simple comme un râteau: intégrer le front-end de clang dans l'IDE. Eh bien, comme cela a été fait récemment dans QtCreator, dans CLion (dans un sens), etc. Clang était alors une étoile montante, beaucoup se penchaient sur la possibilité d'utiliser enfin le parseur C ++ à part entière presque gratuitement. Et l'idée, pour ainsi dire, était littéralement dans l'air (et l'auto-complétion du code intégré à l'API clang était comme suggéré par Be), il fallait juste le prendre et le faire. Mais, comme l'a dit Boromir, "Vous ne pouvez pas simplement le prendre, et ...". C'est donc arrivé dans ce cas. Pour plus de détails - Bienvenue sous cat.
Tout d'abord bon
Les avantages de l'utilisation de clang en tant qu'analyseur intégré dans l'IDE C ++ sont bien sûr. Au final, les fonctions IDE ne se limitent pas uniquement à l'édition de fichiers. Il s'agit d'une base de données de caractères, de tâches de navigation et de dépendances, et bien plus encore. Et ici, un compilateur à part entière se dirige vers toute sa hauteur, car maîtriser toute la puissance du préprocesseur et des modèles dans un analyseur syntaxique relativement simple est une tâche non triviale. Parce que vous devez généralement faire beaucoup de compromis, ce qui affecte évidemment la qualité de l'analyse du code. Qui s'en soucie - peut regarder, par exemple, l'analyseur intégré de QtCeator ici: Analyseur C ++ Qt Creator
Au même endroit, dans le code source de QtCreator, vous pouvez voir que ce qui précède n'est pas tout ce que l'IDE requiert de l'analyseur. De plus, vous avez besoin d'au moins:
- coloration syntaxique (lexicale et sémantique)
- toutes sortes d'indices "à la volée" avec affichage d'informations sur le symbole
- des conseils sur ce qui ne va pas avec le code et comment le corriger / le compléter
- Achèvement du code dans une grande variété de contextes
- le refactoring le plus divers
Par conséquent, sur les avantages énumérés précédemment (vraiment sérieux!), Les avantages s'arrêtent et la douleur commence. Pour mieux comprendre cette douleur, vous pouvez d'abord voir le rapport d'Anastasia Kazakova ( anastasiak2512 ) sur ce qui est réellement requis de l'analyseur de code intégré à l'IDE:
L'essence du problème
Mais c'est simple, même si cela peut ne pas être évident à première vue. En résumé, alors: clang est un compilateur . Et fait référence au code en tant que compilateur . Et aiguisé par le fait que le code lui est donné déjà complété, et non le talon du fichier qui est maintenant ouvert dans l'éditeur IDE. Les compilateurs n'aiment pas les bits de fichiers, comme les constructions incomplètes, les identifiants mal écrits, le retour au lieu du retour et les autres délices qui peuvent survenir ici et maintenant dans l'éditeur. Bien sûr, avant la compilation, tout cela sera nettoyé, corrigé, aligné. Mais ici et maintenant, dans l'éditeur, c'est ce que c'est. Et c'est sous cette forme que l'analyseur intégré à l'IDE arrive à la table toutes les 5 à 10 secondes. Et si sa version auto-écrite "comprend" parfaitement qu'il s'agit d'un produit semi-fini, alors clang - non. Et très surpris. Ce qui se passe à la suite d'une telle surprise dépend "de", comme on dit.
Heureusement, clang tolère assez bien les erreurs de code. Néanmoins, il peut y avoir des surprises - rétro-éclairage disparaissant soudainement, courbe auto-complétée, diagnostics étranges. Vous devez être préparé à tout cela. De plus, le clang n'est pas omnivore. Il a le droit de ne rien accepter dans les en-têtes du compilateur, qui sont utilisés ici et maintenant pour construire le projet. Intrinsèques délicates, extensions non standard et autres, euh ..., fonctionnalités - tout cela peut conduire à des erreurs d'analyse dans les endroits les plus inattendus. Et, bien sûr, la performance. Modifier un fichier de grammaire sur Boost.Spirit ou travailler sur un projet basé sur llvm sera un plaisir. Mais, à propos de tout plus en détail.
Code préfabriqué
Supposons donc que vous ayez commencé un nouveau projet. Votre environnement a généré un espace par défaut pour main.cpp, et vous y avez écrit:
#include <iostream> int main() { foo(10) }
Du point de vue du C ++, franchement, le code n'est pas valide. Il n'y a pas de définition de la fonction foo (...) dans le fichier, la ligne n'est pas terminée, etc. Mais ... Vous venez de commencer. Ce code a droit à ce type. Comment ce code perçoit-il un IDE avec un analyseur automatique (dans ce cas CLion)?
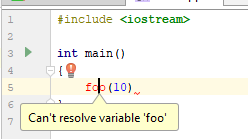
Et si vous cliquez sur l'ampoule, vous pouvez voir ceci:
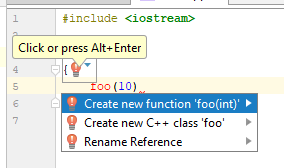
Un tel IDE, sachant quelque chose, euh, plus sur ce qui se passe, offre l'option très attendue: créer une fonction à partir du contexte d'utilisation. Super offre, je pense. Comment se comporte l'IDE basé sur les clangs (dans ce cas, Qt Creator 4.7)?
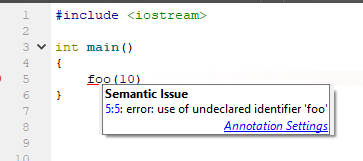
Et qu'est-ce qui est proposé pour rectifier la situation? Mais rien! Seul renommage standard!
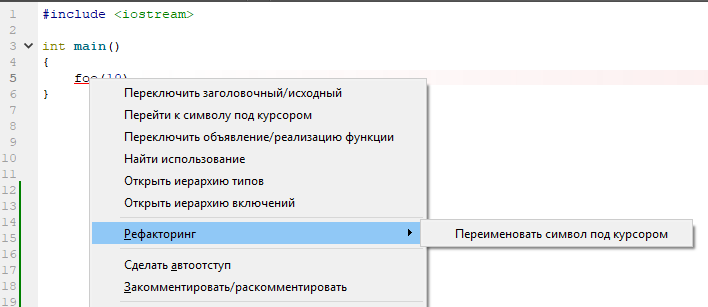
La raison de ce comportement est très simple: pour clang, ce texte est complet (et il ne peut rien y avoir d'autre). Et il construit l'AST sur la base de cette hypothèse. Et puis tout est simple: clang voit un identifiant non défini auparavant. Il s'agit de texte en C ++ (pas en C). Aucune hypothèse n'est faite sur la nature de l'identifiant - il n'est pas défini, donc un morceau de code n'est pas valide. Et dans AST pour cette ligne, rien n'apparaît. Elle n'est tout simplement pas là. Et ce qui n'est pas dans AST est impossible à analyser. C'est dommage, ennuyeux, d'accord.
L'analyseur intégré à l'IDE provient de quelques autres hypothèses. Il sait que le code n'est pas terminé. Que le programmeur est en train de précipiter la pensée et que les doigts derrière elle n'ont pas le temps. Par conséquent, tous les identificateurs ne peuvent pas être définis. Un tel code, bien sûr, est incorrect du point de vue des normes élevées de qualité du compilateur, mais l'analyseur sait ce qui peut être fait avec un tel code et propose des options. Options tout à fait raisonnables.
Au moins jusqu'à la version 3.7 (incluse), des problèmes similaires se sont produits dans ce code:
#include <iostream> class Temp { public: int i; }; template<typename T> class Foo { public: int Bar(Temp tmp) { Tpl(tmp); } private: template<typename U> void Tpl(U val) { Foo<U> tmp(val); tmp. } int member; }; int main() { return 0; }
À l'intérieur des méthodes de classe de modèle, la saisie semi-automatique basée sur les clangs ne fonctionnait pas. Pour autant que j'ai réussi à le découvrir, la raison en était l'analyse en deux passes des modèles. La saisie semi-automatique dans clang est déclenchée lors de la première passe, lorsque les informations sur les types réellement utilisés peuvent ne pas être suffisantes. Dans clang 5.0 (à en juger par les notes de publication), cela a été corrigé.
D'une manière ou d'une autre, des situations dans lesquelles le compilateur n'est pas en mesure de créer le bon AST (ou de tirer les bonnes conclusions à partir du contexte) dans le code édité peuvent bien être. Et dans ce cas, l'IDE ne "verra" tout simplement pas les sections de texte correspondantes et ne pourra en aucun cas aider le programmeur. Ce qui, bien sûr, n'est pas génial. La capacité de travailler efficacement avec un code incorrect est ce dont l'analyseur a besoin dans l'IDE et ce dont le compilateur normal n'a pas du tout besoin. Par conséquent, l'analyseur dans l'EDI peut utiliser de nombreuses heuristiques, qui pour le compilateur peuvent être non seulement inutiles, mais également nuisibles. Et pour y implémenter deux modes de fonctionnement - eh bien, vous devez encore convaincre les développeurs.
"Ce rôle est abusif!"
L'IDE du programmeur est généralement un (enfin, deux), mais il existe de nombreux projets et chaînes d'outils. Et, bien sûr, je ne veux pas faire de gestes supplémentaires pour passer d'une chaîne d'outils à une chaîne d'outils, d'un projet à l'autre. Un ou deux clics, et la configuration de build passe de Debug à Release, et le compilateur de MSVC à MinGW. Mais l'analyseur de code dans l'IDE reste le même. Et il doit, avec le système de build, passer d'une configuration à une autre, d'une chaîne d'outils à une autre. Une chaîne d'outils peut être une sorte d'exotique ou de croix. Et la tâche de l'analyseur ici est de continuer à analyser correctement le code. Si possible avec un minimum d'erreurs.
clang est assez omnivore. Il peut être forcé d'accepter les extensions de compilateur de Microsoft, le compilateur gcc. Il peut être passé des options au format de ces compilateurs, et clang les comprendra même. Mais tout cela ne garantit pas que clang acceptera n'importe quel cap des abats collectés dans le réservoir gcc. Tout __builtin_intrinsic_xxx peut devenir une pierre d'achoppement pour lui. Ou les constructions de langage que la version actuelle de clang dans l'EDI ne prend tout simplement pas en charge. Très probablement, cela n'affectera pas la qualité de la construction AST pour le fichier actuellement édité. Mais la création d'une base de caractères globale ou la sauvegarde d'en-têtes précompilés peut se casser. Et cela peut être un grave problème. Un problème similaire pourrait se révéler être un code similaire non pas dans les en-têtes des chaînes d'outils ou des tiers, mais dans les en-têtes ou les codes source du projet. Soit dit en passant, tout cela est une raison suffisamment importante pour dire explicitement au système de construction (et à l'IDE) quels fichiers d'en-tête pour votre projet sont "étrangers". Cela peut vous faciliter la vie.
Encore une fois, l'IDE a été initialement conçu pour être utilisé avec différents compilateurs, paramètres, chaînes d'outils et plus encore. Conçu pour traiter du code dont certains éléments ne sont pas pris en charge. Le cycle de sortie de l'IDE (pas tous :)) est plus court que celui des compilateurs, par conséquent, il est possible de récupérer plus rapidement de nouvelles fonctionnalités et de répondre aux problèmes détectés. Dans le monde des compilateurs, tout est un peu différent: le cycle de sortie est d'au moins un an, les problèmes de compatibilité entre compilateurs sont résolus par compilation conditionnelle et transmis aux épaules du développeur. Le compilateur n'a pas besoin d'être universel et omnivore - sa complexité est déjà élevée. clang ne fait pas exception.
Le combat pour la vitesse
Cette partie du temps passé à l'IDE, lorsque le programmeur n'est pas assis dans le débogueur, il édite le texte. Et son désir naturel ici est de le rendre confortable (sinon pourquoi un IDE? Puis-je me débrouiller avec un bloc-notes!) Le confort, en particulier, implique la vitesse de réaction élevée de l'éditeur aux changements de texte et la pression sur les touches de raccourci. Comme Anastasia l'a correctement noté dans son rapport, si cinq secondes après avoir appuyé sur Ctrl + Espace, l'environnement n'a pas répondu avec l'apparition d'un menu ou d'une liste de saisie semi-automatique, c'est terrible (sérieusement, essayez-le vous-même). En chiffres, cela signifie que l'analyseur intégré à l'IDE a environ une seconde pour évaluer les modifications dans le fichier et reconstruire l'AST, et un autre et demi ou deux pour offrir au développeur un choix contextuel. Deuxièmement. Eh bien, peut-être deux. En outre, le comportement attendu est que si le développeur a modifié le .h-nickname, puis est passé au .cpp-shnik, les modifications apportées seront "visibles". Les fichiers, les voici, ouverts dans les fenêtres voisines. Et maintenant, un calcul simple. Si clang, lancé à partir de la ligne de commande, peut faire face au code source en environ dix à vingt secondes, alors quelle est la raison de croire que lorsqu'il est lancé à partir de l'IDE, il va faire face au code source beaucoup plus rapidement et s'intégrer dans cette seconde ou deux? Autrement dit, cela fonctionnera un ordre de grandeur plus rapidement? En général, cela pourrait être terminé, mais je ne le ferai pas.
Environ dix à vingt secondes à la source, bien sûr, j'exagère. Bien que, si une API lourde est incluse ou, par exemple, boost.spirit avec Hana prêt, et que tout cela soit activement utilisé dans le texte, 10 à 20 secondes sont toujours de bonnes valeurs. Mais même si l'AST est prêt quelques secondes après trois ou quatre après le lancement de l'analyseur intégré - c'est déjà long. À condition que ces lancements soient aussi réguliers (pour maintenir le modèle de code et l'index dans un état cohérent, surligné, rapide, etc.), ainsi qu'à la demande - l'achèvement du code est également le lancement du compilateur. Est-il possible de réduire ce temps d'une manière ou d'une autre? Malheureusement, dans le cas de l'utilisation de clang comme analyseur, il n'y a pas beaucoup de possibilités. Raison: il s'agit d'un outil tiers dans lequel ( idéalement ) des modifications ne peuvent pas être apportées. Autrement dit, creuser dans le code clang avec perftool, optimiser, simplifier certaines branches - ces fonctionnalités ne sont pas disponibles et vous devez faire avec ce que l'API externe fournit (dans le cas de l'utilisation de libclang, il est également assez étroit).
La première solution, évidente et, en fait, la seule consiste à utiliser des en-têtes précompilés générés dynamiquement. Avec une mise en œuvre adéquate, la solution est mortelle. Augmente parfois la vitesse de compilation au moins. Son essence est simple: l'environnement collecte tous les en-têtes tiers (ou en-têtes en dehors de la racine du projet) dans un seul fichier .h, crée pch à partir de ce fichier, puis inclut implicitement ce pch dans chaque source. Bien sûr, un effet secondaire évident apparaît: dans le code source ( au stade de l'édition ), on peut voir des symboles qui n'y sont pas inclus. Mais c'est une charge pour la vitesse. Je dois choisir. Et tout irait bien, sinon pour un petit problème: clang est toujours un compilateur. Et, étant un compilateur, il n'aime pas les erreurs de code. Et si tout à coup (tout à coup! - voir la section précédente) il y a des erreurs dans les en-têtes, alors le fichier .pch n'est pas créé. Au moins, c'était jusqu'à la version 3.7. Depuis, quelque chose a-t-il changé à cet égard? Je ne sais pas, on soupçonne que non. Hélas, il n'y a plus aucune possibilité de vérifier.
Hélas, les options alternatives ne sont pas disponibles pour la même raison: clang est un compilateur et une chose «en soi». Intervenir activement dans le processus de génération AST, en quelque sorte faire fusionner AST à partir de différentes pièces, maintenir des bases de symboles externes et te et te te - hélas, toutes ces fonctionnalités ne sont pas disponibles. Seulement API externe, uniquement hardcore et paramètres disponibles via les options de compilation. Et puis analyse de l'AST résultant. Si vous vous asseyez sur la version C ++ de l'API, alors un peu plus d'opportunités deviennent disponibles. Par exemple, vous pouvez jouer avec des FrontendActions personnalisées, effectuer des réglages plus fins pour les options de compilation, etc. Mais dans ce cas, le point principal ne changera pas - le texte édité (ou indexé) sera compilé indépendamment des autres et complètement. C’est tout. Le point.
Peut-être (peut-être!) Un jour, il y aura une fourchette de clang en amont spécialement conçue pour être utilisée dans le cadre de l'IDE. C'est possible. Mais pour l'instant, tout est comme ça. Supposons que l'intégration de l'équipe de Qt Creator (à l'étape "finale") avec libclang ait pris sept ans. J'ai essayé QtC 4.7 avec un moteur basé sur libclang - j'avoue que j'aime personnellement l'ancienne version (sur l'auto-écrite) plus simplement parce qu'elle fonctionne mieux sur mes cas: elle invite et met en évidence, et tout le reste. Je ne m'engagerai pas à estimer combien d'heures humaines ils ont consacrées à cette intégration, mais j'ose suggérer que pendant ce temps, il serait possible de terminer mon propre analyseur. Pour autant que je sache (par des indications indirectes), l'équipe travaillant sur CLion envisage avec prudence l'intégration avec libclang / clang ++. Mais ce sont des hypothèses purement personnelles. L'intégration au niveau du protocole du serveur de langues est une option intéressante, mais spécifiquement pour le cas C ++, j'ai tendance à considérer cela plus comme un palliatif pour les raisons énumérées ci-dessus. Il transfère simplement les problèmes d'un niveau d'abstraction à un autre. Mais je me trompe peut-être pour le LSP - l'avenir. Voyons voir. Mais de toute façon, la vie des développeurs d'IDE modernes pour C ++ est pleine d'aventures - avec clang comme backend, ou sans.