 Ceci est la deuxième partie de l'histoire du portage du moteur de modèle Jinja2 vers C ++. Vous pouvez lire le premier ici: les modèles de troisième ordre, ou comment j'ai porté Jinja2 en C ++ . Il se concentrera sur le processus de rendu des modèles. Ou, en d'autres termes, d'écrire à partir de zéro un interprète d'un langage de type python.
Ceci est la deuxième partie de l'histoire du portage du moteur de modèle Jinja2 vers C ++. Vous pouvez lire le premier ici: les modèles de troisième ordre, ou comment j'ai porté Jinja2 en C ++ . Il se concentrera sur le processus de rendu des modèles. Ou, en d'autres termes, d'écrire à partir de zéro un interprète d'un langage de type python.
Rendu en tant que tel
Après l'analyse, le modèle se transforme en une arborescence contenant des nœuds de trois types: texte brut , expressions calculées et structures de contrôle . Par conséquent, pendant le processus de rendu, le texte brut doit être placé sans aucune modification dans le flux de sortie, les expressions doivent être calculées, converties en texte, qui sera placé dans le flux, et les structures de contrôle doivent être exécutées. À première vue, il n'y avait rien de difficile à implémenter le processus de rendu: il suffit de faire le tour de tous les nœuds de l'arbre, de tout calculer, de tout exécuter et de générer du texte. Tout est simple. Exactement tant que deux conditions sont remplies: a) tout le travail est effectué avec des chaînes d'un seul type (chaîne ou chaîne de caractères); b) seules des expressions très simples et de base sont utilisées. En fait, c'est avec de telles restrictions que inja et Jinja2CppLight sont implémentés. Dans le cas de mon Jinja2Cpp, les deux conditions ne fonctionnent pas. Tout d'abord, j'ai initialement prévu un support transparent pour les deux types de chaînes. Deuxièmement, tout le développement a été lancé juste pour prendre en charge la spécification Jinja2 presque entièrement, et c'est essentiellement un langage de script à part entière. Par conséquent, j'ai dû approfondir le rendu plutôt que l'analyse.
Évaluation de l'expression
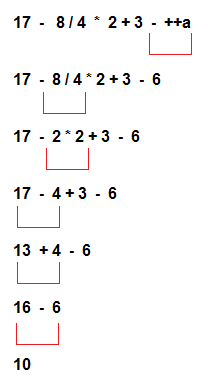 Un modèle ne serait pas un modèle s'il ne pouvait pas être paramétré. En principe, Jinja2 permet l'option de modèles "en soi" - toutes les variables nécessaires peuvent être définies à l'intérieur du modèle lui-même, puis le rendre. Mais travailler dans un modèle avec des paramètres obtenus "à l'extérieur" reste le cas principal. Ainsi, le résultat de l'évaluation d'une expression dépend des variables (paramètres) avec lesquelles les valeurs sont visibles aux points de calcul. Et le hic, c'est que dans Jinja2, il n'y a pas seulement une portée (qui peut être imbriquée), mais aussi des règles compliquées de «transparence». Par exemple, voici un modèle:
Un modèle ne serait pas un modèle s'il ne pouvait pas être paramétré. En principe, Jinja2 permet l'option de modèles "en soi" - toutes les variables nécessaires peuvent être définies à l'intérieur du modèle lui-même, puis le rendre. Mais travailler dans un modèle avec des paramètres obtenus "à l'extérieur" reste le cas principal. Ainsi, le résultat de l'évaluation d'une expression dépend des variables (paramètres) avec lesquelles les valeurs sont visibles aux points de calcul. Et le hic, c'est que dans Jinja2, il n'y a pas seulement une portée (qui peut être imbriquée), mais aussi des règles compliquées de «transparence». Par exemple, voici un modèle:
{% set param1=10 %} {{ param1 }}
À la suite de son rendu, le texte 10 sera reçu
L'option est un peu plus compliquée:
{% set param1=10 %} {{ param1 }} {% for param1 in range(10) %}-{{ param1 }}-{% endfor %} {{ param1 }}
10-0--1--2--3--4--5--6--7--8--9-10 dès 10-0--1--2--3--4--5--6--7--8--9-10
Le cycle génère une nouvelle étendue dans laquelle vous pouvez définir vos propres paramètres variables, et ces paramètres ne seront pas visibles en dehors de l'étendue, tout comme ils n'affecteront pas les valeurs des mêmes paramètres dans celle externe. Encore plus délicat avec les constructions extend / block, mais il est préférable de lire à ce sujet dans la documentation Jinja2.
Ainsi, le contexte des calculs apparaît. Ou plutôt, le rendu en général:
class RenderContext { public: RenderContext(const InternalValueMap& extValues, IRendererCallback* rendererCallback); InternalValueMap& EnterScope(); void ExitScope(); auto FindValue(const std::string& val, bool& found) const { for (auto p = m_scopes.rbegin(); p != m_scopes.rend(); ++ p) { auto valP = p->find(val); if (valP != p->end()) { found = true; return valP; } } auto valP = m_externalScope->find(val); if (valP != m_externalScope->end()) { found = true; return valP; } found = false; return m_externalScope->end(); } auto& GetCurrentScope() const; auto& GetCurrentScope(); auto& GetGlobalScope(); auto GetRendererCallback(); RenderContext Clone(bool includeCurrentContext) const; private: InternalValueMap* m_currentScope; const InternalValueMap* m_externalScope; std::list<InternalValueMap> m_scopes; IRendererCallback* m_rendererCallback; };
D'ici .
Le contexte contient un pointeur vers une collection de valeurs obtenues lors de l'appel de la fonction de rendu, une liste (pile) de portées, la portée active actuelle et un pointeur vers une interface de rappel, avec diverses fonctions utiles pour le rendu. Mais à propos de lui un peu plus tard. La fonction de recherche de paramètres remonte séquentiellement la liste des contextes jusqu'à l'externe jusqu'à ce qu'elle trouve le paramètre nécessaire.
Maintenant, un peu sur les paramètres eux-mêmes. Du point de vue de l'interface externe (et de ses utilisateurs), Jinja2 prend en charge la liste suivante de types valides:
- Nombres (int, double)
- Cordes (étroites, larges)
- bool
- Tableaux (plus comme des tuples sans dimension)
- Dictionnaires
- Structures C ++ réfléchies
Tout cela est décrit par un type de données spécial créé sur la base de boost :: variant:
using ValueData = boost::variant<EmptyValue, bool, std::string, std::wstring, int64_t, double, boost::recursive_wrapper<ValuesList>, boost::recursive_wrapper<ValuesMap>, GenericList, GenericMap>; class Value { public: Value() = default; template<typename T> Value(T&& val, typename std::enable_if<!std::is_same<std::decay_t<T>, Value>::value>::type* = nullptr) : m_data(std::forward<T>(val)) { } Value(const char* val) : m_data(std::string(val)) { } template<size_t N> Value(char (&val)[N]) : m_data(std::string(val)) { } Value(int val) : m_data(static_cast<int64_t>(val)) { } const ValueData& data() const {return m_data;} ValueData& data() {return m_data;} private: ValueData m_data; };
D'ici .
Bien sûr, les éléments des tableaux et des dictionnaires peuvent être l'un des types répertoriés. Mais le problème est que pour un usage interne, cet ensemble de types est trop étroit. Pour simplifier la mise en œuvre, un support était nécessaire pour les types supplémentaires suivants:
- Chaîne au format cible. Il peut être étroit ou large selon le type de modèle rendu.
- type appelable
- Assemblage d'arbres AST
- Paire valeur-clé
Grâce à cette expansion, il est devenu possible de transférer des données de service à travers le contexte de rendu, qui autrement devrait être "affiché" dans les en-têtes publics, ainsi que pour généraliser plus efficacement certains algorithmes qui fonctionnent avec des tableaux et des dictionnaires.
Boost :: variant n'a pas été choisi par hasard. Ses riches capacités sont utilisées pour travailler avec des paramètres de types spécifiques. Jinja2CppLight utilise des classes polymorphes dans le même but, tandis qu'inja utilise le système de type de bibliothèque nlohmann json. Hélas, ces deux alternatives ne me convenaient pas. Raison: la possibilité de répartition n-aire pour boost :: variant (et maintenant - std :: variant). Pour un type de variante, vous pouvez créer un visiteur statique qui accepte deux types stockés spécifiques et le définir par rapport à une paire de valeurs. Et tout fonctionnera comme il se doit! Dans le cas de classes polymorphes ou d'unions simples, cette commodité ne fonctionnera pas:
struct StringJoiner : BaseVisitor<> { using BaseVisitor::operator (); InternalValue operator() (EmptyValue, const std::string& str) const { return str; } InternalValue operator() (const std::string& left, const std::string& right) const { return left + right; } };
D'ici .
Un tel visiteur est appelé très simplement:
InternalValue delimiter = m_args["d"]->Evaluate(context); for (const InternalValue& val : values) { if (isFirst) isFirst = false; else result = Apply2<visitors::StringJoiner>(result, delimiter); result = Apply2<visitors::StringJoiner>(result, val); }
Apply2 ici est un wrapper sur boost::apply_visitor , qui applique le visiteur du type spécifié par le paramètre de modèle à une paire de valeurs de variante, effectuant auparavant quelques conversions si nécessaire. Si le concepteur du visiteur a besoin de paramètres, ils sont transmis après les objets auxquels le visiteur s'applique:
comparator = [](const KeyValuePair& left, const KeyValuePair& right) { return ConvertToBool(Apply2<visitors::BinaryMathOperation>(left.value, right.value, BinaryExpression::LogicalLt, BinaryExpression::CaseSensitive)); };
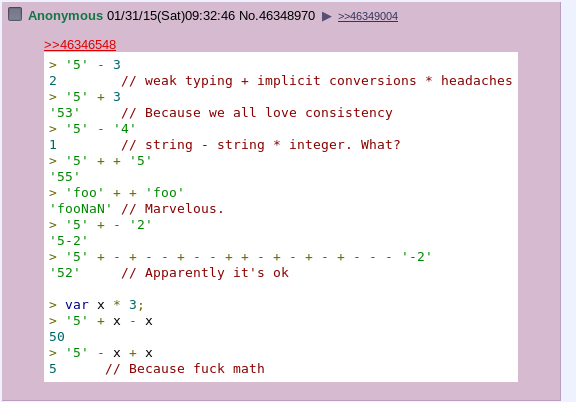 Ainsi, la logique des opérations avec des paramètres se présente comme suit: variante (s) -> décompression à l'aide de visiteur -> exécution de l'action souhaitée sur des valeurs spécifiques de types spécifiques -> reconditionnement du résultat dans la variante. Et un minimum de magie secrète. Il serait possible de tout implémenter comme dans js: effectuer des opérations (par exemple, des ajouts) dans tous les cas, choisir un certain système de conversion de chaînes en nombres, de nombres en chaînes, de chaînes en listes, etc. Et d'obtenir des résultats étranges et inattendus. J'ai choisi une manière plus simple et plus prévisible: si une opération sur une valeur (ou une paire de valeurs) est impossible ou illogique, alors un résultat vide est retourné. Par conséquent, lorsque vous ajoutez un nombre à une chaîne, vous ne pouvez obtenir une chaîne comme résultat que si l'opération de concaténation ('~') est utilisée. Sinon, le résultat sera une valeur vide. La priorité des opérations est déterminée par la grammaire, par conséquent, aucune vérification supplémentaire n'est requise pendant le traitement AST.
Ainsi, la logique des opérations avec des paramètres se présente comme suit: variante (s) -> décompression à l'aide de visiteur -> exécution de l'action souhaitée sur des valeurs spécifiques de types spécifiques -> reconditionnement du résultat dans la variante. Et un minimum de magie secrète. Il serait possible de tout implémenter comme dans js: effectuer des opérations (par exemple, des ajouts) dans tous les cas, choisir un certain système de conversion de chaînes en nombres, de nombres en chaînes, de chaînes en listes, etc. Et d'obtenir des résultats étranges et inattendus. J'ai choisi une manière plus simple et plus prévisible: si une opération sur une valeur (ou une paire de valeurs) est impossible ou illogique, alors un résultat vide est retourné. Par conséquent, lorsque vous ajoutez un nombre à une chaîne, vous ne pouvez obtenir une chaîne comme résultat que si l'opération de concaténation ('~') est utilisée. Sinon, le résultat sera une valeur vide. La priorité des opérations est déterminée par la grammaire, par conséquent, aucune vérification supplémentaire n'est requise pendant le traitement AST.
Filtres et tests
 Ce que les autres langues appellent la "bibliothèque standard" dans Jinja2 est appelé "filtres". En substance, un filtre est une sorte d'opération complexe sur une valeur à gauche du signe «|», dont le résultat sera une nouvelle valeur. Les filtres peuvent être organisés en chaîne en organisant un pipeline:
Ce que les autres langues appellent la "bibliothèque standard" dans Jinja2 est appelé "filtres". En substance, un filtre est une sorte d'opération complexe sur une valeur à gauche du signe «|», dont le résultat sera une nouvelle valeur. Les filtres peuvent être organisés en chaîne en organisant un pipeline:
{{ menuItems | selectattr('visible') | map(attribute='title') | map('upper') | join(' -> ') }}
Ici, seuls les éléments dont l'attribut visible est défini sur true seront sélectionnés dans le tableau menuItems, puis l'attribut title sera extrait de ces éléments, converti en majuscules, et la liste de lignes résultante sera collée avec le séparateur `` -> '' sur une seule ligne. Ou, disons, comme exemple de la vie:
{% macro MethodsDecl(class, access) %} {% for method in class.methods | rejectattr('isImplicit') | selectattr('accessType', 'in', access) %} {{ method.fullPrototype }}; {% endfor %} {% endmacro %}
D'ici .
Option alternative {% macro MethodsDecl(class, access) %} {{ for method in class.methods | rejectattr('isImplicit') | selectattr('accessType', 'in', access) | map(attribute='fullPrototype') | join(';\n') }}; {% endmacro %}
Cette macro parcourt toutes les méthodes de la classe donnée, ignore celles pour lesquelles l'attribut isImplicit est défini sur true, sélectionne les autres pour lesquelles la valeur de l'attribut accessType correspond à l'une des données données et affiche leurs prototypes. Relativement clair. Et tout cela est plus facile que les cycles de trois étages et si c'est pour clôturer. Soit dit en passant, quelque chose de similaire en C ++ peut être fait dans la spécification de gamme v.3 .
En fait, le principal manquement dans le temps était lié à la mise en place d'une quarantaine de filtres, que j'ai inclus dans l'ensemble de base. Pour une raison quelconque, j'ai pensé que je pourrais le gérer en une semaine ou deux. C'était trop optimiste. Et bien que l'implémentation typique du filtre soit assez simple: prendre une valeur et lui appliquer un foncteur, il y en avait trop et j'ai dû bricoler.
Une autre tâche intéressante dans le processus de mise en œuvre était la logique de traitement des arguments. Dans Jinja2, comme dans python, les arguments passés à l'appel peuvent être nommés ou positionnels. Et les paramètres de la déclaration de filtre peuvent être obligatoires ou facultatifs (avec des valeurs par défaut). De plus, contrairement à C ++, les paramètres facultatifs peuvent être situés n'importe où dans l'annonce. Il a fallu trouver un algorithme pour combiner ces deux listes en tenant compte des cas différents. Ici, disons, il y a une fonction range: range([start, ]stop[, step]) . Il peut être appelé des manières suivantes:
range(10) // -> range(start = 0, stop = 10, step = 1) range(1, 10) // -> range(start = 1, stop = 10, step = 1) range(1, 10, 3) // -> range(start = 1, stop = 10, step = 3) range(step=2, 10) // -> range(start = 0, stop = 10, step = 2) range(2, step=2, 10) // -> range(start = 2, stop = 10, step = 2)
Et ainsi de suite. Et j'aimerais beaucoup que dans le code d'implémentation de la fonction de filtrage, il ne soit pas nécessaire de prendre en compte tous ces cas. En conséquence, il s'est contenté du fait que dans le code de filtre, le testeur ou le code de fonction, les paramètres sont obtenus strictement par leur nom. Et une fonction distincte compare la liste réelle des arguments avec la liste attendue des paramètres en cours de route en vérifiant que tous les paramètres requis sont donnés d'une manière ou d'une autre:
Gros morceau de code ParsedArguments ParseCallParams(const std::initializer_list<ArgumentInfo>& args, const CallParams& params, bool& isSucceeded) { struct ArgInfo { ArgState state = NotFound; int prevNotFound = -1; int nextNotFound = -1; const ArgumentInfo* info = nullptr; }; boost::container::small_vector<ArgInfo, 8> argsInfo(args.size()); boost::container::small_vector<ParamState, 8> posParamsInfo(params.posParams.size()); isSucceeded = true; ParsedArguments result; int argIdx = 0; int firstMandatoryIdx = -1; int prevNotFound = -1; int foundKwArgs = 0;
D'ici .
On l'appelle ainsi (pour, disons, range ):
bool isArgsParsed = true; auto args = helpers::ParseCallParams({{"start"}, {"stop", true}, {"step"}}, m_params, isArgsParsed); if (!isArgsParsed) return InternalValue();
et renvoie la structure suivante:
struct ParsedArguments { std::unordered_map<std::string, ExpressionEvaluatorPtr<>> args; std::unordered_map<std::string, ExpressionEvaluatorPtr<>> extraKwArgs; std::vector<ExpressionEvaluatorPtr<>> extraPosArgs; ExpressionEvaluatorPtr<> operator[](std::string name) const { auto p = args.find(name); if (p == args.end()) return ExpressionEvaluatorPtr<>(); return p->second; } };
l'argument nécessaire dont il est tiré simplement par son nom:
auto startExpr = args["start"]; auto stopExpr = args["stop"]; auto stepExpr = args["step"]; InternalValue startVal = startExpr ? startExpr->Evaluate(values) : InternalValue(); InternalValue stopVal = stopExpr ? stopExpr->Evaluate(values) : InternalValue(); InternalValue stepVal = stepExpr ? stepExpr->Evaluate(values) : InternalValue();
Un mécanisme similaire est utilisé lorsque vous travaillez avec des macros et des testeurs. Et bien qu'il ne semble y avoir rien de compliqué à décrire les arguments de chaque filtre et test, il n'y a pas (comment l'implémenter), mais même l'ensemble «de base», qui comprend une cinquantaine d'entre eux et d'autres, s'est avéré assez volumineux pour la mise en œuvre. Et cela à condition qu'il n'inclue pas toutes sortes de choses délicates, comme le formatage de chaînes pour HTML (ou C ++), la sortie de valeurs dans des formats comme xml ou json, etc.
Dans la partie suivante, nous nous concentrerons sur la mise en œuvre de travaux avec plusieurs modèles (exportation, inclusion, macros), ainsi que sur des aventures fascinantes avec la mise en œuvre de la gestion des erreurs et le travail avec des chaînes de différentes largeurs.
Traditionnellement, les liens:
Spécifications Jinja2
Implémentation de Jinja2Cpp