«L'équipe @Cloudflare vient d'apporter des modifications qui ont considérablement amélioré les performances de notre réseau, en particulier pour les demandes les plus lentes. Combien plus rapide? Nous estimons que nous économisons sur Internet environ 54 ans de temps par jour qui auraient autrement été consacrés à attendre le chargement des sites .
» - Matthew Prince
tweet , 28 juin 2018
10 millions de sites, applications et API utilisent Cloudflare pour accélérer les téléchargements de contenu pour les utilisateurs. Au plus fort, nous traitons plus de 10 millions de demandes par seconde dans 151 centres de données. Au fil des ans, nous avons apporté de nombreux changements à notre version de Nginx pour faire face à la croissance. Cet article concerne l'un de ces changements.
Comment fonctionne Nginx
Nginx est l'un des programmes qui utilise des boucles de traitement d'événements pour résoudre
le problème C10K . Chaque fois qu'un événement réseau arrive (nouvelle connexion, demande ou notification pour envoyer une plus grande quantité de données, etc.), Nginx se réveille, traite l'événement, puis revient à un autre travail (il peut s'agir de traiter d'autres événements). Lorsqu'un événement arrive, les données le concernant sont prêtes, ce qui vous permet de traiter efficacement de nombreuses demandes simultanées sans interruption.
num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ // handle event[1]: send out response to GET http://cloudflare.com/
Par exemple, voici à quoi pourrait ressembler un morceau de code pour lire les données d'un descripteur de fichier:
// we got a read event on fd while (buf_len > 0) { ssize_t n = read(fd, buf, buf_len); if (n < 0) { if (errno == EWOULDBLOCK || errno == EAGAIN) { // try later when we get a read event again } if (errno == EINTR) { continue; } return total; } buf_len -= n; buf += n; total += n; }
Si fd est une socket réseau, les octets déjà reçus seront retournés. Le dernier appel renverra
EWOULDBLOCK . Cela signifie que le tampon de lecture local est terminé et que vous ne devez plus lire à partir de ce socket jusqu'à ce que les données apparaissent.
Les E / S de disque sont différentes du réseau
Si fd est un fichier normal sous Linux, alors
EWOULDBLOCK et
EAGAIN n'apparaissent jamais, et l'opération de lecture attend toujours de lire la totalité du tampon, même si le fichier est ouvert à l'aide de
O_NONBLOCK . Comme écrit dans le manuel
open (2) :
Veuillez noter que cet indicateur n'est pas valide pour les fichiers normaux et les périphériques bloqués.
En d'autres termes, le code ci-dessus est essentiellement réduit à ceci:
if (read(fd, buf, buf_len) > 0) { return buf_len; }
Si le gestionnaire doit lire à partir du disque, il bloque la boucle d'événements jusqu'à la fin de la lecture et les gestionnaires d'événements suivants attendent.
Ceci est normal pour la plupart des tâches, car la lecture à partir d'un disque est généralement assez rapide et beaucoup plus prévisible que l'attente d'un paquet du réseau. Surtout maintenant que tout le monde a un SSD et que tous nos caches sont sur des SSD. Dans les SSD modernes, un très petit retard, généralement en dizaines de microsecondes. En outre, vous pouvez exécuter Nginx avec plusieurs flux de travail afin qu'un gestionnaire d'événements lent ne bloque pas les demandes dans d'autres processus. La plupart du temps, vous pouvez compter sur Nginx pour traiter rapidement et efficacement les demandes.
Performances SSD: pas toujours comme promis
Comme vous l'avez peut-être deviné, ces hypothèses roses ne sont pas toujours vraies. Si chaque lecture prend toujours 50 μs, la lecture de 0,19 Mo en blocs de 4 Ko (et nous lisons en blocs encore plus grands) ne prendra que 2 ms. Mais les tests ont montré que le délai jusqu'au premier octet est parfois bien pire, en particulier dans les 99e et 999e centiles. En d'autres termes, la lecture la plus lente sur 100 (ou 1000) lectures prend souvent beaucoup plus de temps.
Les disques SSD sont très rapides, mais connus pour leur complexité. Ils ont des ordinateurs à l'intérieur de cette file d'attente et réordonnent les E / S, et effectuent également diverses tâches d'arrière-plan, telles que la récupération de place et la défragmentation. De temps en temps, les demandes ralentissent sensiblement. Mon collègue
Ivan Bobrov a lancé plusieurs
tests de performances d' E / S et enregistré des retards de lecture pouvant aller jusqu'à 1 seconde. De plus, certains de nos SSD ont plus de pics de performances que d'autres. À l'avenir, nous allons tenir compte de cet indicateur lors de l'achat d'un SSD, mais nous devons maintenant développer une solution pour les équipements existants.
Répartition uniforme de la charge avec SO_REUSEPORT
Il est difficile d'éviter une réponse lente pour 1000 requêtes, mais ce que nous ne voulons vraiment pas, c'est bloquer les 1000 requêtes restantes pendant une seconde entière. Conceptuellement, Nginx est capable de traiter de nombreuses demandes en parallèle, mais il ne démarre qu'un seul gestionnaire d'événements à la fois. J'ai donc ajouté une métrique spéciale:
gettimeofday(&start, NULL); num_events = epoll_wait(epfd, events, events_len, -1); // events is list of active events // handle event[0]: incoming request GET http://example.com/ gettimeofday(&event_start_handle, NULL); // handle event[1]: send out response to GET http://cloudflare.com/ timersub(&event_start_handle, &start, &event_loop_blocked);
Le 99e centile (p99)
event_loop_blocked dépassait 50% de notre TTFB. En d'autres termes, la moitié du temps lors du traitement d'une demande est le résultat du blocage du cycle de traitement des événements par d'autres demandes.
event_loop_blocked ne mesure que la moitié du verrou (car les appels en attente à
epoll_wait() ne
epoll_wait() pas mesurés), donc le rapport réel du temps bloqué est beaucoup plus élevé.
Chacune de nos machines exécute Nginx avec 15 workflows, c'est-à-dire qu'une E / S lente ne bloquera pas plus de 6% des demandes. Mais les événements ne sont pas également répartis: le travailleur principal reçoit 11% des demandes.
SO_REUSEPORT peut résoudre le problème de la distribution inégale. Marek Maikovsky a écrit plus tôt sur l'
inconvénient de cette approche dans le contexte d'autres instances de Nginx, mais ici vous pouvez principalement l'ignorer: les connexions en amont dans le cache sont durables, vous pouvez donc négliger une légère augmentation du délai lors de l'ouverture de la connexion. Ce changement de configuration à lui seul avec l'activation de
SO_REUSEPORT amélioré le pic p99 de 33%.
Déplacer read () vers un pool de threads: pas une solution miracle
La solution est de rendre read () non bloquant. En fait, cette fonction est
implémentée dans Nginx normal ! En utilisant la configuration suivante, read () et write () sont exécutées dans le pool de threads et ne bloquent pas la boucle d'événements:
aio threads; aio_write on;
Mais nous avons testé cette configuration et au lieu d'améliorer le temps de réponse de 33 fois, nous n'avons remarqué qu'un petit changement dans p99, la différence est dans la marge d'erreur. Le résultat a été très décourageant, nous avons donc temporairement reporté cette option.
Il y a plusieurs raisons pour lesquelles nous n'avons pas apporté d'améliorations significatives, comme les développeurs Nginx. Dans le test, ils ont utilisé 200 connexions simultanées pour demander des fichiers de 4 Mo sur le disque dur. Les Winchesters ont beaucoup plus de latence d'E / S, donc l'optimisation a un effet plus important.
De plus, nous sommes principalement préoccupés par les performances de p99 (et p999). L'optimisation du retard moyen ne résout pas nécessairement le problème des pics d'émission.
Enfin, dans notre environnement, les tailles de fichiers typiques sont beaucoup plus petites. 90% de nos hits de cache sont inférieurs à 60 Ko. Plus les fichiers sont petits, moins il y a de cas de blocage (généralement nous lisons le fichier entier en deux lectures).
Regardons les E / S disque lorsqu'elles sont touchées dans le cache:
// https://example.com 0xCAFEBEEF fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY); // 32 // , "aio threads" read(fd, buf, 32*1024);
32K ne sont pas toujours lus. Si les en-têtes sont petits, vous devez lire seulement 4 Ko (nous n'utilisons pas directement les E / S, donc le noyau arrondit à 4 Ko).
open() semble inoffensif, mais il prend en fait des ressources. Au minimum, le noyau doit vérifier si le fichier existe et si le processus appelant a l'autorisation de l'ouvrir. Il doit trouver l'inode pour
/cache/prefix/dir/EF/BE/CAFEBEEF , et pour cela il devra chercher
CAFEBEEF dans
/cache/prefix/dir/EF/BE/ . En bref, dans le pire des cas, le noyau effectue cette recherche:
/cache /cache/prefix /cache/prefix/dir /cache/prefix/dir/EF /cache/prefix/dir/EF/BE /cache/prefix/dir/EF/BE/CAFEBEEF
Ce sont 6 lectures distinctes que
open() produit, contre 1
read() ! Heureusement, dans la plupart des cas, la recherche tombe dans le
cache de la
dentisterie et n'atteint pas le SSD. Mais il est clair que le traitement de
read() dans un pool de threads ne représente que la moitié de l'image.
Accord final: open () non bloquant dans les pools de threads
Par conséquent, nous avons apporté une modification à Nginx afin que
open() soit principalement exécuté à l'intérieur du pool de threads et ne bloque pas la boucle d'événements. Et voici le résultat de non-bloquant open () et read () en même temps:
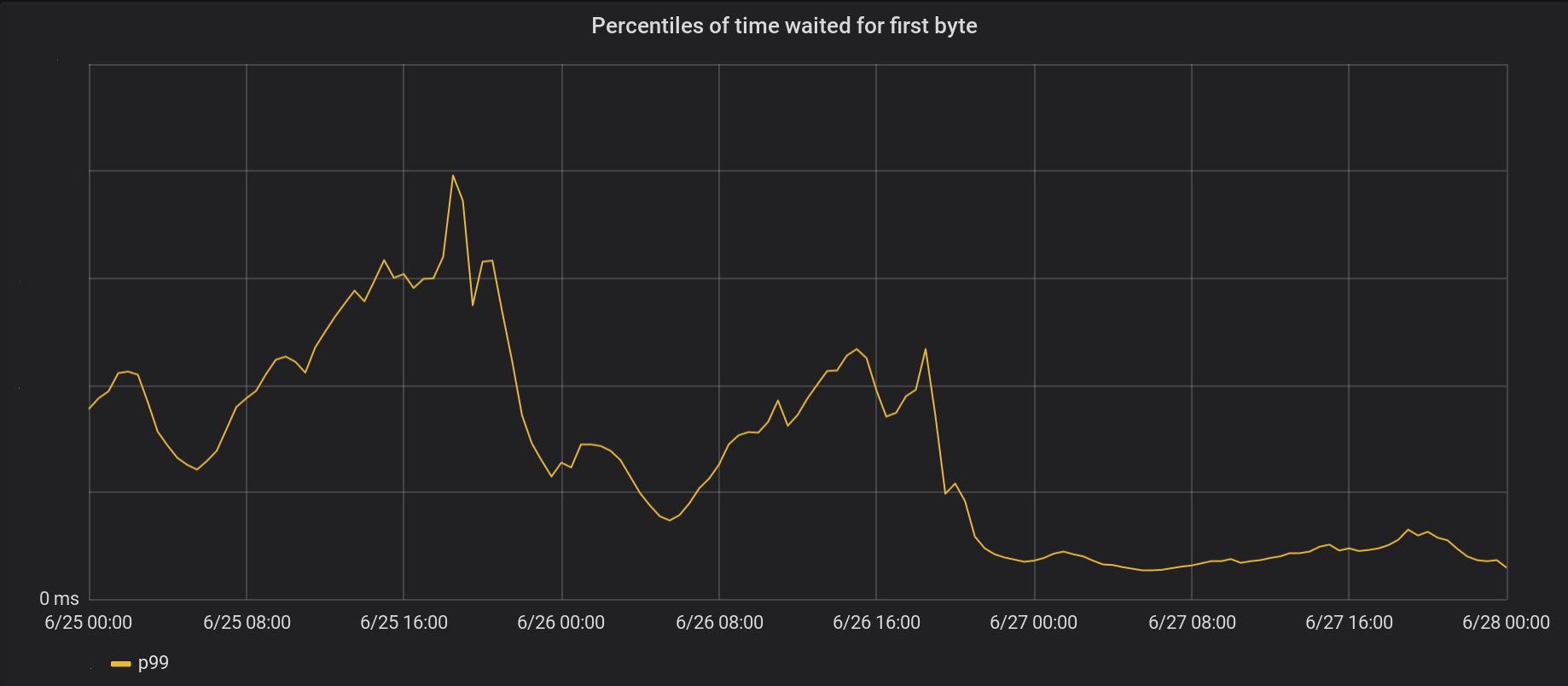
Le 26 juin, nous avons apporté les modifications aux 5 centres de données les plus occupés et le lendemain, à tous les 146 autres centres de données du monde. Le pic total p99 TTFB a diminué de 6 fois. En fait, si nous résumons constamment le traitement de 8 millions de demandes par seconde, nous économisons à Internet 54 ans d'attente chaque jour.
Notre série d'événements ne s'est pas encore complètement débarrassée des serrures. En particulier, le blocage se produit toujours la première fois que le fichier est mis en cache (à la fois
open(O_CREAT) et
rename() ) ou lors de la mise à jour de la revalidation. Mais de tels cas sont rares par rapport aux accès au cache. À l'avenir, nous envisagerons la possibilité de déplacer ces éléments en dehors de la boucle de traitement d'événements pour améliorer encore le facteur de retard p99.
Conclusion
Nginx est une plate-forme puissante, mais la mise à l'échelle de charges d'E / S Linux extrêmement élevées peut être une tâche ardue. Les décharges Nginx standard lisent dans des threads séparés, mais à notre échelle, nous devons souvent aller plus loin.