Il s'agit d'une histoire sur le portage de JavaScript sur la plate-forme Elbrus domestique, réalisée par des gars d'UniPro. L'article fournit une brève analyse comparative des plateformes, des détails des processus et des pièges.

L'article est basé sur un rapport de Dmitry (
dbezheckov ) Bezhetskov et Vladimir (
volodyabo ) Anufrienko avec HolyJS 2018 Piter. Sous la coupe, vous trouverez la vidéo et la transcription textuelle du rapport.
Partie 1. Elbrus, originaire de Russie
Tout d'abord, nous comprendrons ce qu'est Elbrus. Voici quelques fonctionnalités clés de cette plate-forme par rapport à x86.
Architecture VLIW
Une solution architecturale complètement différente de l'architecture superscalaire, qui est plus courante sur le marché aujourd'hui. VLIW vous permet d'exprimer plus finement les intentions dans le code en raison du contrôle explicite de tous les dispositifs arithmétiques et logiques indépendants (ALU), dont Elbrus a, en passant, 4. Cela n'exclut pas la possibilité d'indisponibilité de certaines ALU, mais augmente néanmoins les performances théoriques d'un cycle d'horloge le processeur.
Regroupement d'équipe
Les commandes de processeur prêtes sont combinées en bundles (Bundles). Un bundle est une grosse instruction qui s'exécute par horloge conditionnelle. Il possède de nombreuses instructions atomiques qui sont exécutées indépendamment et immédiatement dans l'architecture Elbrus.

Dans l'image de droite, les rectangles gris indiquent les faisceaux obtenus en traitant le code JS à gauche. Si tout est à peu près clair avec les instructions ldd, fmuld, faddd, fsqrts, alors avec la déclaration de retour au tout début du premier paquet, il est surprenant pour les personnes qui ne connaissent pas l'assembleur d'Elbrus. Cette instruction charge à l'avance l'adresse de retour de la fonction floatMath actuelle dans le registre ctpr3, afin que le processeur parvienne à télécharger les instructions nécessaires. Ensuite, dans le dernier bundle, nous faisons déjà la transition vers l'adresse préchargée dans ctpr3.
Il convient également de noter qu'Elbrus a beaucoup plus de registres 192 + 32 + 32 contre 16 + 16 +8 pour x86.
Explicit spéculative versus implicite
Elbrus prend en charge la spéculation explicite au niveau de la commande. Par conséquent, nous pouvons appeler et charger a.bar à partir de la mémoire avant même de vérifier qu'il n'est pas nul, comme le montre le code à droite. Si la lecture logique à la fin s'avère non valide, la valeur en b sera simplement marquée matériel comme incorrecte et il ne sera pas possible d'y accéder.

Prise en charge de l'exécution conditionnelle
Elbrus prend également en charge l'exécution conditionnelle. Considérez ceci dans l'exemple suivant.

Comme nous pouvons le voir, le code de l'exemple précédent sur la spéculation est également réduit en raison de l'utilisation de la convolution de l'expression conditionnelle en dépendance, non par contrôle, mais par données. Le matériel Elbrus prend en charge les registres de prédicats, dans lesquels vous ne pouvez stocker que deux valeurs vraies ou fausses. Leur principale caractéristique est que vous pouvez marquer des instructions avec un tel prédicat et en fonction de sa valeur au moment de l'exécution, l'instruction sera exécutée ou non. Dans cet exemple, l'instruction cmpeq effectue la comparaison et place son résultat logique dans le prédicat P1, qui est ensuite utilisé comme marqueur pour charger la valeur de b dans le résultat. Par conséquent, si le prédicat était égal à vrai, la valeur 0 restait dans le résultat.
Cette approche vous permet de transformer un graphique de contrôle de programme assez complexe en exécution de prédicat et, en conséquence, augmente la plénitude du bundle. Nous pouvons maintenant générer plus d'équipes indépendantes sous différents prédicats et les remplir de bundles. Elbrus prend en charge 32 registres de prédicats, ce qui vous permet d'encoder 65 flux de contrôle (plus un pour l'absence de prédicat sur la commande).
Trois piles matérielles par rapport à une dans Intel
Deux d'entre eux sont protégés contre toute modification par le programmeur. L'une - la pile de chaînes - est chargée de stocker les adresses pour les retours de fonctions, l'autre - la pile de registres - contient les paramètres par lesquels elles sont transmises. La troisième - pile d'utilisateurs - stocke les variables et les données utilisateur. En intel, tout est stocké sur une seule pile, ce qui donne lieu à des vulnérabilités, puisque toutes les adresses de transitions, les paramètres sont en un seul endroit qui n'est pas protégé par les modifications de l'utilisateur.
Pas de prédicteur de branche dynamique
Au lieu de cela, un schéma avec if-conversion et préparations de transition est utilisé afin que le pipeline d'exécution ne s'arrête pas.
Alors pourquoi avons-nous besoin de JS sur Elbrus?
- Substitution d'importation.
- Introduction d'Elbrus sur le marché des ordinateurs personnels, où Javascript est déjà requis pour le même navigateur.
- Elbrus est déjà nécessaire dans l'industrie, par exemple avec Node.js. Par conséquent, vous devez porter Node sur cette architecture.
- Le développement de l'architecture d'Elbrus, ainsi que des spécialistes dans ce domaine.
S'il n'y a pas d'interprète, deux compilateurs viennent
La mise en œuvre précédente de la v8 de Google a été prise comme base. Cela fonctionne comme ceci: une arborescence de syntaxe abstraite est créée à partir du code source, puis selon que le code a été exécuté ou non, en utilisant l'un des deux compilateurs (Crankshaft ou FullCodegen), respectivement, du code binaire optimisé ou non optimisé est créé. Il n'y a pas d'interprète.

Comment fonctionne FullCodegen?
Les nœuds de l'arbre de syntaxe sont traduits en code binaire, après quoi tout est «collé» ensemble. Un nœud représente environ 300 lignes de code dans un assembleur de macros. Cela, d'une part, donne un large horizon d'optimisations, et, d'autre part, il n'y a pas de transitions de bytecode, comme dans l'interpréteur. C'est simple, mais en même temps, il y a un problème - pendant le portage, vous devrez réécrire beaucoup de code dans l'assembleur de macros.
Néanmoins, tout cela a été fait, et le résultat a été une version de compilateur FullCodegen 1.0 pour Elbrus. Tout a été fait via C ++ runtime v8, ils n'ont rien optimisé, le code assembleur a été simplement réécrit de x86 à l'architecture Elbrus.
Codegen 1.1
En conséquence, le résultat n'était pas tout à fait le même que prévu, et il a été décidé de publier FullCodegen 1.1:
- Réduit le temps d'exécution, écrit sur un assembleur de macros;
- Ajout de conversions if manuelles (dans la figure, à titre d'exemple, la variable js est vérifiée pour vrai ou faux);

Notez que la vérification de NaN, non défini, null se fait à la fois, sans utiliser if, ce qui serait requis dans l'architecture Intel.
- Le code n'a pas seulement été réécrit avec Intel, mais a implémenté la spéculation dans les talons et a également implémenté le raccourci via MAsm (macro assembleur).
Des tests ont été effectués dans Google Octane. Machines d'essai:
- Elbrus: E2S 750 MHz, 24 Go
- Intel: core i7 3,4 GHz, 16 Go
Autres résultats:

Sur l'histogramme est le rapport des résultats, c'est-à-dire combien de fois Elbrus est-il pire qu'Intel. Sur deux tests, Crypto et zlib, les résultats sont nettement pires du fait qu'Elbrus ne dispose pas encore d'instructions matérielles pour travailler avec le cryptage. En général, étant donné la différence de fréquences, cela s'est plutôt bien passé.
Ce qui suit est un test en comparaison avec l'interpréteur js de firefox, qui fait partie de la distribution Elbrus standard. Plus c'est mieux.
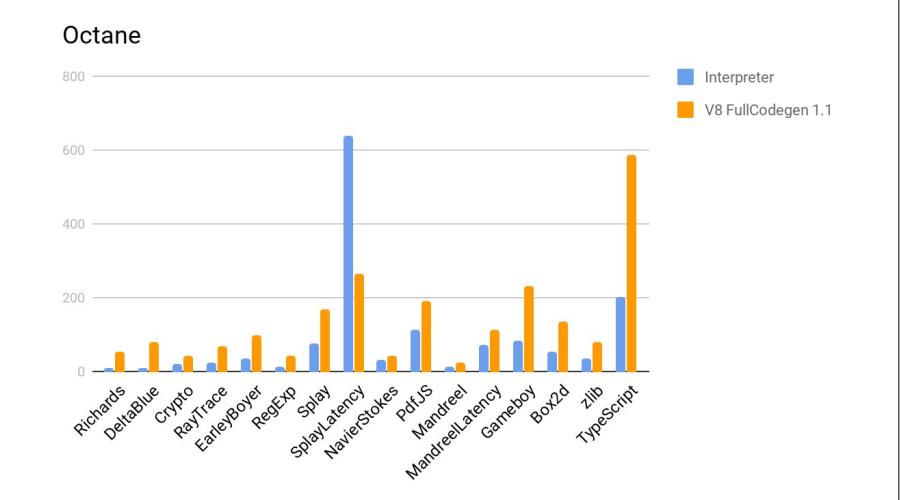
Verdict - le compilateur a de nouveau fait du bon travail.
Résultats de développement
- Le nouveau moteur JS a passé les tests test262. Cela lui donne le droit d'être appelé un environnement d'exécution à part entière ECMAScript 262.
- La productivité a augmenté en moyenne cinq fois par rapport au moteur précédent - l'interprète.
- Node.js 6.10 a également été porté comme exemple d'utilisation de V8, car ce n'était pas difficile.
- Cependant, il est encore sept fois pire que le Core i7 sur FullCodegen.
Rien ne semblait présager
Tout irait bien, mais ici, Google a annoncé qu'il ne prend plus en charge FullCodegen et Crankshaft et ils seront supprimés. Après quoi, l'équipe a reçu une commande de développement pour le navigateur Firefox, et plus à ce sujet plus tard.

Partie 2. Firefox et son singe araignée
Il s'agit du moteur de navigateur Firefox - SpiderMonkey. Sur la figure, les différences entre ce moteur et le nouveau V8.
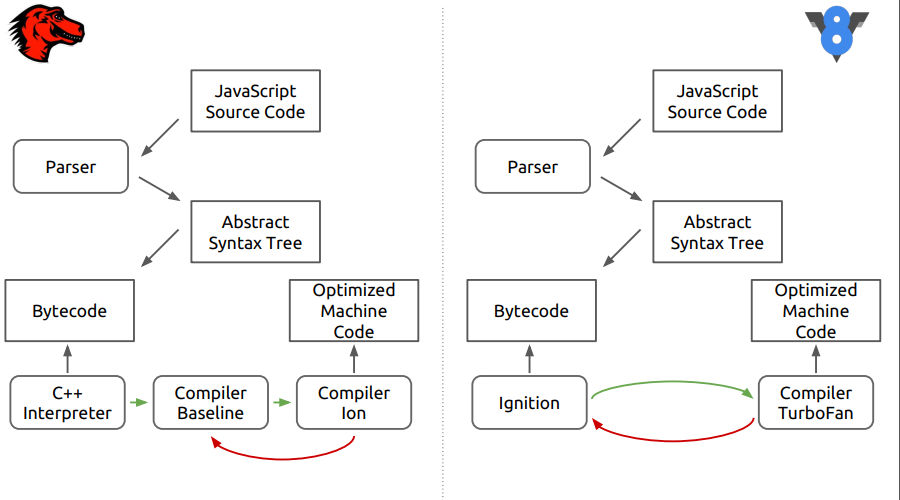
On peut voir qu'à la première étape, tout ressemble au code source qui est analysé dans une arborescence de syntaxe abstraite, puis dans du code d'octets, puis les différences commencent.
Dans SpiderMonkey, le bytecode est interprété par l'interpréteur C ++, qui ressemble essentiellement à un grand commutateur, à l'intérieur duquel des sauts de bytecode sont effectués. De plus, le code interprété entre dans la ligne de base du compilateur néotimisant. Ensuite, au stade final, le compilateur d'optimisation Ion est inclus dans le boîtier. Dans le moteur V8, le bytecode est traité par l'interpréteur Ingnition, puis par le compilateur TurboFan.
Baseline, je te choisis!
Le portage a commencé avec le compilateur Baseline. Il s'agit essentiellement d'une machine empilée. Autrement dit, il existe une certaine pile à partir de laquelle les cellules, il prend des variables, se souvient d'eux, effectue certaines actions avec elles, après quoi il renvoie à la fois les variables et les résultats des actions aux cellules de la pile. Ci-dessous dans quelques images ce mécanisme est montré étape par étape par rapport à la fonction simple foo:
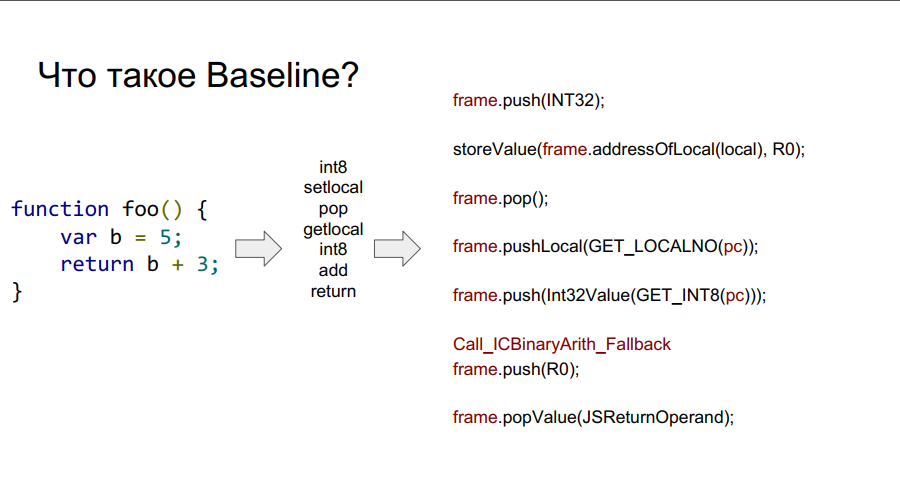


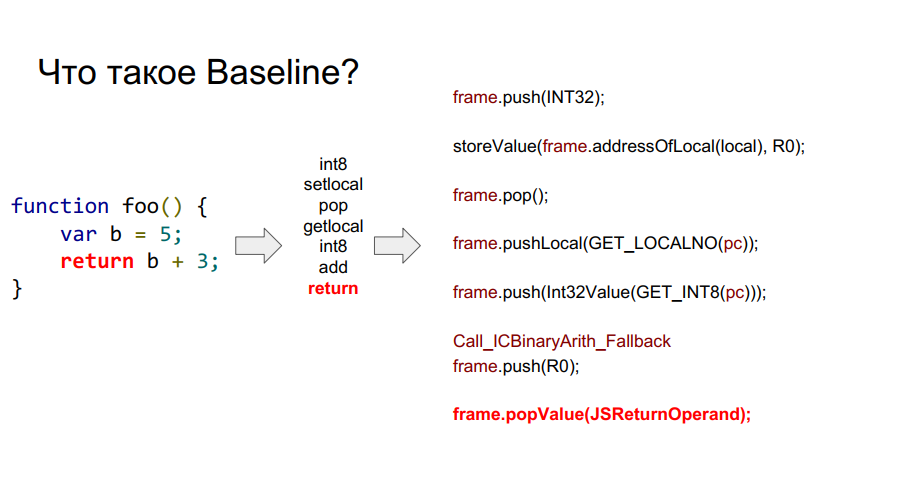
Qu'est-ce qu'un cadre?
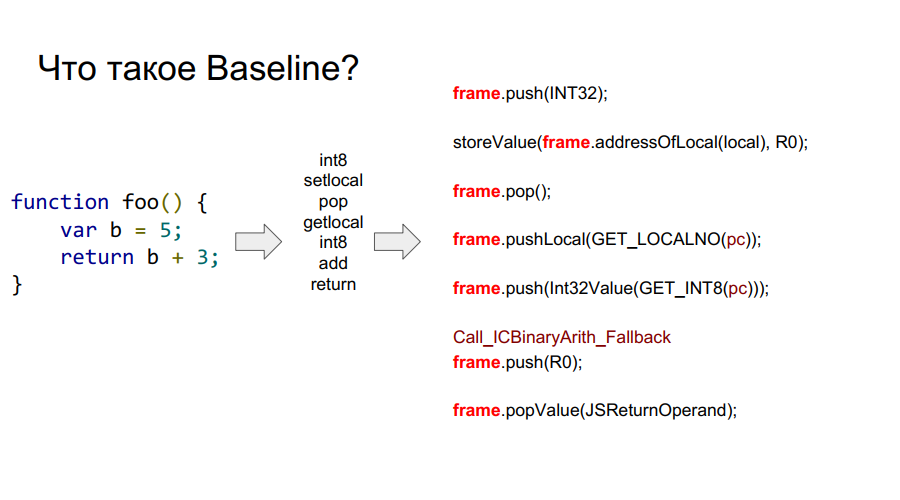
Dans les images ci-dessus, vous pouvez voir le cadre de mots. En gros, il s'agit d'un contexte Javascript sur le matériel, c'est-à-dire un ensemble de données sur la pile qui décrit l'une de vos fonctions. Dans l'image ci-dessous, la fonction est foo, et à droite se trouve à quoi elle ressemble sur la pile: arguments, description de la fonction, adresse de retour, référence au cadre précédent, car la fonction a été appelée de quelque part et afin de retourner correctement à l'endroit de l'appel, ces informations doivent être stockées dans pile, puis les variables locales elles-mêmes fonctions et opérandes pour les calculs.

Ainsi, les
avantages de Baseline :
- Ressemble à FullCodegen, son expérience de portage est donc très utile;
- Portez l'assembleur, obtenez un compilateur fonctionnel;
- Il est pratique de déboguer;
- Tout talon peut être réécrit.
Mais il y a aussi des
inconvénients :
- Du code linéaire, jusqu'à ce que vous exécutiez un code d'octet, vous ne pourrez pas exécuter ce qui suit, ce qui n'est pas très bon pour l'architecture avec le calcul parallèle;
- Puisqu'il fonctionne avec le bytecode, vous n'optimisez pas vraiment.
Il ne restait plus qu'à implémenter l'assembleur de macros et à obtenir un compilateur prêt à l'emploi. Le débogage n'augurait pas bien, il suffisait de regarder la pile sur l'architecture x86, puis celle obtenue lors du portage pour trouver le problème.
En conséquence, lors des tests avec le nouveau compilateur, la productivité a triplé:

Cependant, Octane ne prend pas en charge les exceptions. Et leur mise en œuvre est très importante.
Travail exceptionnel
Voyons d'abord comment fonctionnent les exceptions sur x86. Pendant l'exécution du programme, les adresses de retour des fonctions sont écrites dans la pile. À un moment donné, une exception se produit. Nous passons au gestionnaire d'exceptions d'exécution, qui utilise les trames dont nous avons parlé ci-dessus. Nous trouvons où exactement l'exception s'est produite, après quoi nous devons rembobiner la pile à l'état souhaité, puis l'adresse de retour change en celle où l'exception sera traitée.
Le problème est qu'en raison d'un autre périphérique de pile sur l'architecture Elbrus, cela ne fonctionnera pas. Il sera nécessaire de calculer par appels système combien vous devez rembobiner dans la pile de chaînes. Ensuite, nous faisons un appel système pour obtenir la pile d'appels. Ensuite, dans l'adresse de la pile Chaîne, nous remplaçons l'adresse faisant le retour.
Vous trouverez ci-dessous une illustration de la séquence de ces étapes.

Ce n'est pas le moyen le plus rapide, cependant, l'exception est gérée. Mais encore, sur Intel, cela semble un peu plus simple:

Avec Elbrus, il y aura plus de sauts vers le gestionnaire:

C'est pourquoi vous ne devez pas baser la logique du programme sur des exceptions, en particulier sur Elbrus.
Optimisez-le!
Ainsi, la gestion des exceptions est implémentée. Nous allons maintenant vous expliquer comment nous avons fait tout cela un peu plus vite:
- Réécriture des caches en ligne;
- Faire un arrangement manuel (puis automatique) des retards;
- Ils ont préparé les transitions (plus haut dans le code): plus la transition est préparée tôt, mieux c'est;
- Ramasse-miettes incrémentiel pris en charge
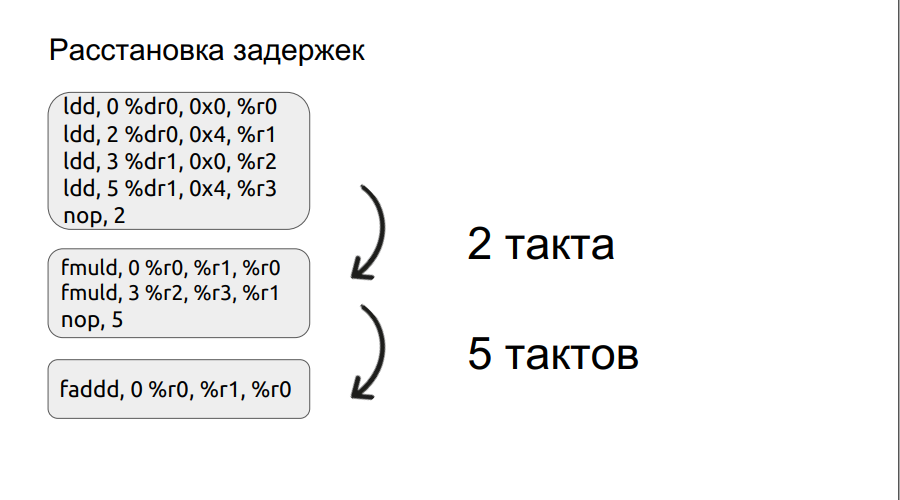
Le deuxième paragraphe s'attardera un peu plus en détail. Nous avons déjà examiné un petit exemple de travail avec des bundles, et nous allons y passer.

Toute opération, par exemple le chargement, ne se fait pas en un cycle, dans ce cas, elle se fait en trois cycles. Ainsi, si nous voulons multiplier deux nombres, nous sommes entrés dans l'opération de multiplication, mais les opérandes eux-mêmes n'ont pas encore été chargés, le processeur ne peut qu'attendre leur chargement. Et il attendra un certain nombre de mesures, un multiple de quatre. Mais si vous définissez manuellement le retard, le temps d'attente peut être réduit, améliorant ainsi les performances. De plus, le processus d'organisation des retards a été automatisé.
Résultats de l'optimisation BaseLine v1.0 vs Baseline v1.1. Bien sûr, le moteur est devenu plus rapide.

Comment les programmeurs ne peuvent-ils pas fabriquer un canon à ions?
Sur la vague de succès de la mise en œuvre de Baseline v1.1, il a été décidé de porter le compilateur d'optimisation Ion.

Comment fonctionne le compilateur d'optimisation? Le code source est interprété, la compilation est lancée. Au cours de l'exécution du bytecode, Ion collecte des données sur les types utilisés dans le programme et l'analyse des «fonctions chaudes» - celles qui sont effectuées plus souvent que d'autres. Après cela, la décision est prise de mieux les compiler, de les optimiser. Ensuite, une représentation de haut niveau du compilateur, un graphe d'opération, est construite. Le graphique est optimisé (opt 1, opt 2, opt ...), une représentation de bas niveau est créée, composée d'instructions machine, des registres sont réservés, un code binaire directement optimisé est généré.
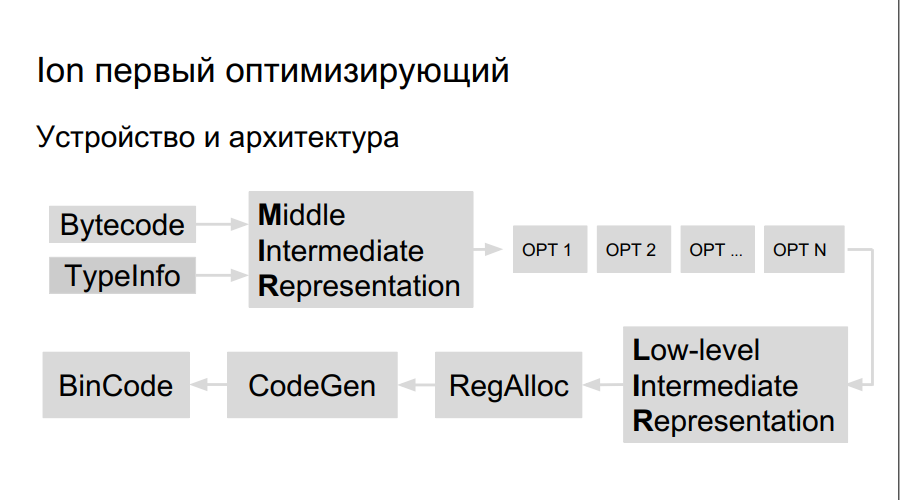
Il y a plus de registres sur Elbrus et les équipes elles-mêmes sont grandes, nous avons donc besoin de:
- Planificateur d'équipe
- Propre allocateur de registre;
- Propre LIR (représentation intermédiaire de bas niveau);
- Propre générateur de code.
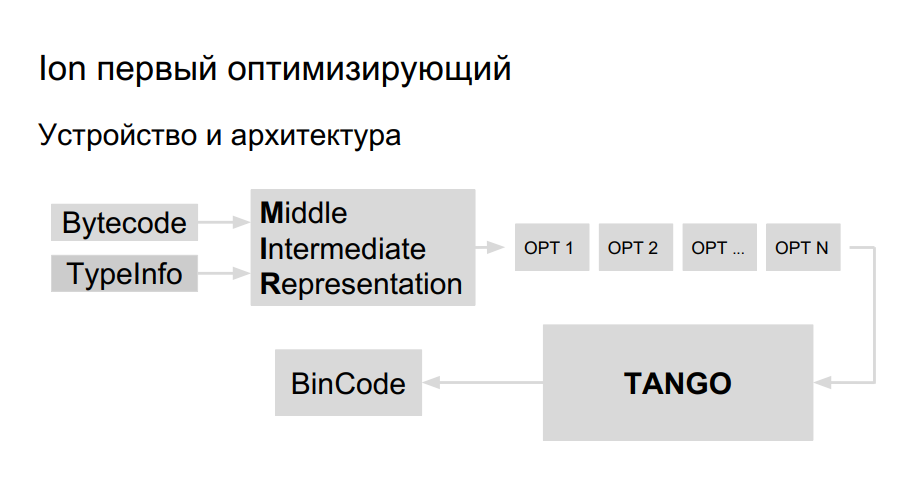
L'équipe avait déjà l'expérience du portage de Java vers Elbrus, ils ont décidé d'utiliser la même bibliothèque pour la génération de code pour le portage d'Ion. Elle s'appelle TANGO. Il a:
- Planificateur d'équipe
- Propre allocateur de registre;
- Optimisations de bas niveau.
Reste à introduire une représentation de haut niveau dans TANGO, à faire un sélecteur. Le problème est que la vue de bas niveau dans TANGO est comme l'assembleur, qui est difficile à maintenir et à déboguer. À quoi devrait ressembler le compilateur à l'intérieur? Pour une meilleure compréhension, Mozilla a créé son propre compilateur HolyJit; il existe également une option pour écrire votre propre mini-langage pour la traduction entre une représentation de haut niveau et de bas niveau.
Le développement est toujours en cours. Eh bien et plus loin sur la façon de ne pas en faire trop avec l'optimisation.
Partie 3. Le meilleur est l'ennemi du bien
Compilation telle qu'elle est
Le processus d'optimisation dans Ion, lorsque le code s'échauffe, puis compile et optimise, est gourmand, cela peut être vu dans l'exemple suivant.
function foo(a, b) {
return a + b;
}
function doSomeStuff(obj) {
for (let i = 0; i < 1100; ++i) {
print(foo(obj,obj));
}
}
doSomeStuff("HollyJS");
doSomeStuff({n:10});
JS Shell ( ), Mozilla, :

. , , - bailout (). , . foo object, , , . , :
function doSomeStuff(obj) {
for (let i=0; i < 1100; ++i) {
if (!(obj instanceof String))
print(foo_only_str(obj, obj));
}
}
, .
. , , DCE.
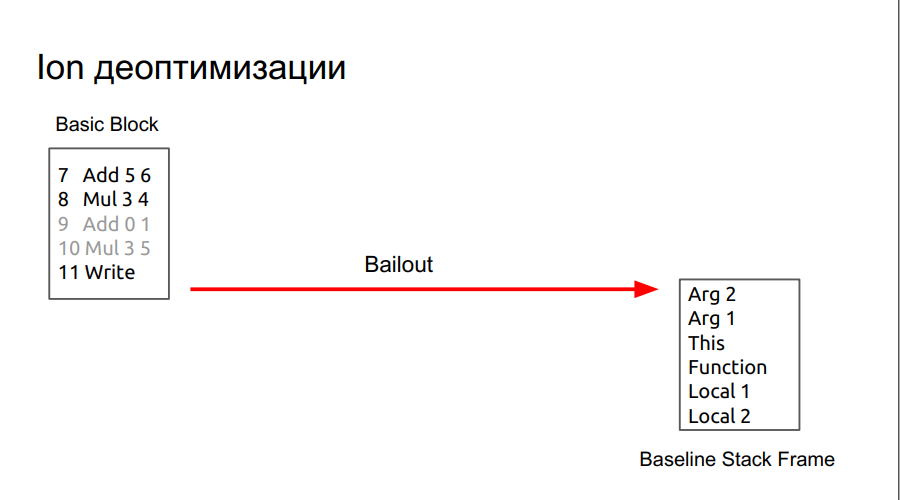
, , , .
, , , SpiderMonkey Resume Point. - , . , baseline . , runtime , . lowering, regAlloc, (snapshot), , . baseline .
:

runtime x86 : , . . , , , , , . , , Type . :
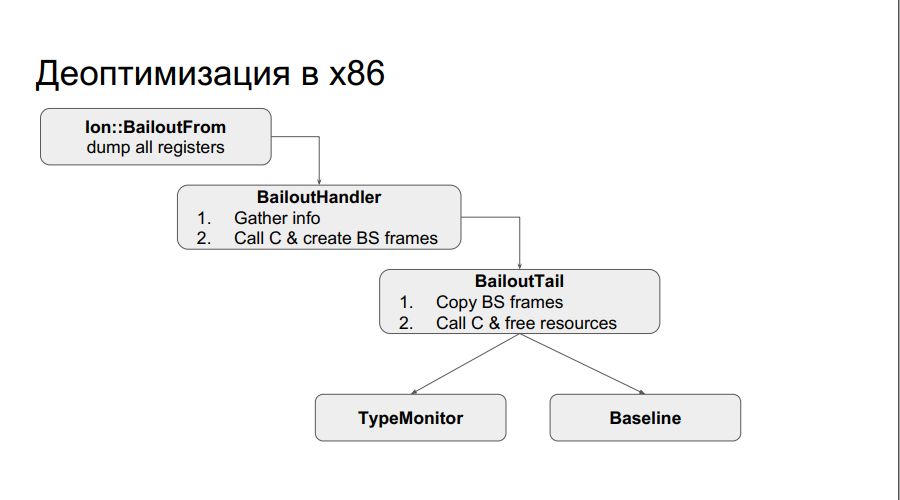
, , chain . , , .
: , chain-, N , , baseline, .
, .
:

Ion 4- baseline. :
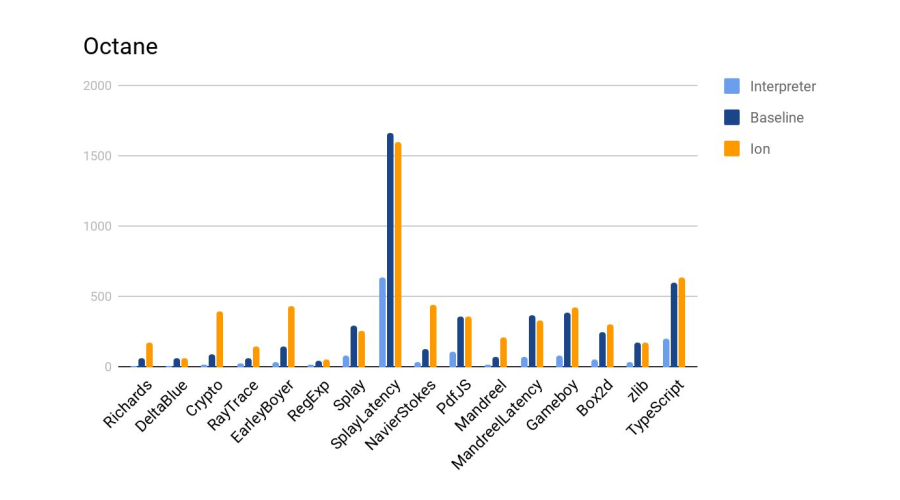
, , SpiderMonkey, V8 Node. — . .
. , , chain-.
, : 24-25 HolyJS, . — , .