L'idée vous est-elle venue à l'esprit pour réécrire votre application d'entreprise audacieuse à partir de zéro? Si à partir de zéro, alors c'est wow. Au moins deux fois moins de code, non? Mais quelques années passeront, et elles grandiront également, deviendront héritage ... il n'y a pas beaucoup de temps et d'argent pour que la réécriture fonctionne parfaitement.
Calmez-vous, les autorités ne permettront toujours pas de réécrire quoi que ce soit. Reste à refactoriser. Quelle est la meilleure façon de dépenser vos petites ressources? Comment refactoriser où nettoyer?
Le titre de cet article comprend une référence au livre de l’oncle Bob
«Architecture propre» , et il a été fait sur la base d’un merveilleux rapport de Victor Rentea (
twitter ,
site Web ) sur JPoint (sous le chat, il commencera à parler à la première personne, mais pour le moment lisez l’introduction). En lisant des livres intelligents, cet article ne remplace pas, mais pour une description aussi courte est très bien présentée.
L'idée est que les choses populaires comme «l'architecture propre» sont vraiment utiles. Surprise Si vous devez résoudre un problème très spécifique, un code simple et élégant ne nécessite pas d'effort supplémentaire ni de sur-ingénierie. L'architecture pure indique que vous devez protéger votre modèle de domaine contre les effets externes et vous indique exactement comment cela peut être fait. Une approche évolutive pour augmenter le volume des microservices. Des tests qui rendent le refactoring moins effrayant. Vous savez déjà tout ça? Ou vous savez, mais vous avez même peur d'y penser, car c'est une horreur que devrez-vous faire alors?
Qui veut obtenir une pilule magique anti-procrastination qui aidera à arrêter de trembler et à commencer à refactoriser - bienvenue dans le reportage vidéo ou sous cat.
Je m'appelle Victor, je viens de Roumanie. Formellement, je suis consultant, expert technique et architecte principal chez IBM roumain. Mais si on me demandait de donner une définition de mon activité moi-même, alors je suis un évangéliste du code pur. J'adore créer un code beau, propre et pris en charge - en règle générale, j'en parle dans les rapports. Plus encore, je suis inspiré par l'enseignement: former les développeurs dans les domaines de Java EE, Spring, Dojo, Test Driven Development, Java Performance, ainsi que dans le domaine de l'évangélisation mentionné - les principes des modèles de code propre et leur développement.
L'expérience sur laquelle ma théorie est basée est principalement le développement d'applications d'entreprise pour le plus grand client IBM en Roumanie - le secteur bancaire.
Le plan de cet article est le suivant:
- Modélisation des données: les structures de données ne doivent pas devenir nos ennemis;
- Organisation de la logique: le principe de "décomposition du code, qui est trop";
- «Onion» est l'architecture de philosophie Transaction Script la plus pure;
- Les tests comme moyen de gérer les craintes des développeurs.
Mais d'abord, rappelons les grands principes dont nous, développeurs, devons toujours nous souvenir.
Principe de responsabilité exclusive

En d'autres termes, quantité vs qualité. En règle générale, plus votre classe contient de fonctionnalités, pire elle se révèle dans un sens qualitatif. En développant de grandes classes, le programmeur commence à devenir confus, à commettre des erreurs dans la construction des dépendances, et le code volumineux, entre autres, est plus difficile à déboguer. Il est préférable de diviser une telle classe en plusieurs classes plus petites, chacune étant responsable d'une sous-tâche. Mieux vaut avoir quelques modules étroitement couplés qu'un seul - grand et lent. La modularité permet également la réutilisation de la logique.
Liaison de module faible

Le degré de liaison est une mesure de la façon dont vos modules interagissent les uns avec les autres. Il montre à quel point l'effet des modifications que vous apportez à un moment donné du système est en mesure de se propager. Plus la liaison est élevée, plus il est difficile d'apporter des modifications: vous changez quelque chose dans un module, et l'effet s'étend loin et pas toujours de la manière attendue. Par conséquent, l'indicateur de liaison doit être aussi bas que possible - cela fournira plus de contrôle sur le système en cours de modification.
Ne répétez pas

Vos propres implémentations peuvent être bonnes aujourd'hui, mais pas si bonnes demain. Ne vous autorisez pas à copier vos propres bonnes pratiques et donc à les diffuser dans une base de code. Vous pouvez copier à partir de StackOverflow, à partir de livres - à partir de toutes sources faisant autorité qui (comme vous le savez avec certitude) offrent une implémentation idéale (ou proche de cela). L'amélioration de votre propre implémentation, qui se produit plus d'une fois, mais multipliée dans la base de code, peut être très fatigante.
Simplicité et concision

À mon avis, c'est le principe principal qui doit être observé dans l'ingénierie et le développement de logiciels. "L'encapsulation prématurée est la racine du mal", a déclaré Adam Bien. En d'autres termes, la racine du mal réside dans la «réingénierie». L'auteur de la citation, Adam Bien, a été à un moment donné engagé dans des applications héritées et, en réécrivant complètement leur code, a reçu une base de code 2-3 fois plus petite que celle d'origine. D'où vient tant de code supplémentaire? Après tout, cela se pose pour une raison. Ses craintes nous font naître. Il nous semble qu'en empilant un grand nombre de modèles, générant indirects et abstractions, nous assurons à notre code une protection - une protection contre les inconnues de demain et les exigences de demain. Après tout, en fait, aujourd'hui, nous n'avons besoin de rien de tout cela, nous n'inventons tout cela que pour des «besoins futurs». Et il est possible que ces structures de données interfèrent par la suite. Pour être honnête, lorsque certains de mes développeurs viennent vers moi et disent qu'il a trouvé quelque chose d'intéressant qui peut être ajouté au code de production, je réponds toujours de la même manière: "Mon garçon, cela ne vous sera pas utile."
Il ne devrait pas y avoir beaucoup de code, et celui qui est devrait être simple - la seule façon de travailler normalement avec lui. C'est une préoccupation pour vos développeurs. Vous devez vous rappeler qu'ils sont les chiffres clés de votre système. Essayez de réduire leur consommation d'énergie, de réduire les risques avec lesquels ils devront travailler. Cela ne signifie pas que vous devez créer votre propre framework, d'ailleurs, je ne vous conseillerais pas de le faire: il y aura toujours des bugs dans votre framework, tout le monde devra l'étudier, etc. Il vaut mieux utiliser les actifs existants, qui sont aujourd'hui massifs. Ces solutions devraient être simples. Notez les gestionnaires d'erreurs globaux, appliquez la technologie d'aspect, les générateurs de code, les extensions Spring ou CDI, configurez les portées de demande / thread, utilisez la manipulation et la génération de bytecode à la volée, etc. Tout cela sera votre contribution à la chose la plus importante - le confort de votre développeur.
En particulier, je voudrais vous démontrer l'application des zones Requête / Thread. J'ai vu à plusieurs reprises comment cette chose a incroyablement simplifié les applications d'entreprise. L'essentiel est qu'il vous donne la possibilité, en tant qu'utilisateur connecté, d'enregistrer les données RequestContext. Ainsi, RequestContext stockera les données utilisateur sous une forme compacte.

Comme vous pouvez le voir, l'implémentation ne prend que quelques lignes de code. Après avoir écrit la demande dans l'annotation requise (il n'est pas difficile de le faire si vous utilisez Spring ou CDI), vous vous libérerez de la nécessité de passer la connexion utilisateur aux méthodes et autres: les métadonnées de la demande stockées dans le contexte navigueront de manière transparente dans l'application. Un proxy limité vous permettra d'accéder à tout moment aux métadonnées de la demande en cours.
Tests de régression

Les développeurs ont peur des exigences mises à jour car ils ont peur des procédures de refactoring (modifications de code). Et le moyen le plus simple de les aider est de créer une suite de tests fiable pour les tests de régression. Avec lui, le développeur aura la possibilité à tout moment de tester son temps de fonctionnement - pour s'assurer qu'il ne casse pas le système.
Le développeur ne devrait avoir peur de rien casser. Vous devez tout faire pour que le refactoring soit perçu comme quelque chose de bien.
Le refactoring est un aspect essentiel du développement. Rappelez-vous, exactement au moment où vos développeurs ont peur de refactoriser, l'application peut être considérée comme devenue Legacy.
Où implémenter la logique métier?
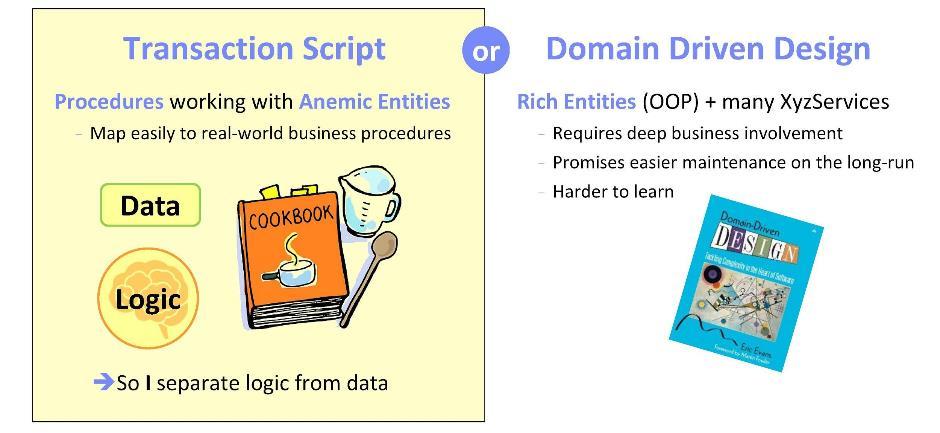
À partir de la mise en œuvre de tout système (ou composants du système), nous nous posons la question: où est-il préférable de mettre en œuvre la logique du domaine, c'est-à-dire les aspects fonctionnels de notre application? Il existe deux approches opposées.
Le premier est basé sur la philosophie
Transaction Script . Ici, la logique est implémentée dans des procédures qui fonctionnent avec des
entités anémiques (c'est-à-dire avec des structures de données). Une telle approche est bonne car au cours de sa mise en œuvre, il est possible de s'appuyer sur les tâches métier formulées. Tout en travaillant sur des applications pour le secteur bancaire, j'ai observé à plusieurs reprises le transfert de procédures métier vers des logiciels. Je peux dire qu'il est vraiment très naturel de corréler des scénarios avec des logiciels.
Une autre approche consiste à utiliser les principes de la
conception pilotée par domaine . Ici, vous devrez mettre en corrélation les spécifications et les exigences avec une méthodologie orientée objet. Il est important de bien considérer les objets et d'assurer une bonne implication commerciale. L'avantage des systèmes ainsi conçus est qu'à l'avenir ils seront facilement entretenus. Cependant, d'après mon expérience, la maîtrise de cette méthodologie est assez difficile: vous vous sentirez plus ou moins courageux au plus tôt après six mois d'études.
Pour mes développements, j'ai toujours choisi la première approche. Je peux vous assurer que dans mon cas, cela a parfaitement fonctionné.
Modélisation des données
Entités
Comment modélisons-nous les données? Dès que l'application prend des tailles plus ou moins décentes,
des données persistantes apparaîtront nécessairement. C'est le type de données que vous devez stocker plus longtemps que les autres - ce sont les
entités de domaine de votre système. Où les stocker - que ce soit dans la base de données, dans un fichier ou en gérant directement la mémoire - n'a pas d'importance. L'important est de
savoir comment les stocker - dans quelles structures de données.

Ce choix vous est donné en tant que développeur et ne dépend que de vous que ces structures de données fonctionneront pour vous ou contre vous lors de la mise en œuvre des exigences fonctionnelles à l'avenir. Pour que tout soit bon, vous devez implémenter des entités en y déposant des grains de
logique de domaine réutilisée . Comment spécifiquement? Je vais démontrer plusieurs méthodes en utilisant un exemple.

Voyons ce que j'ai fourni à l'entité Client. Tout d'abord, j'ai implémenté un
getFullName() synthétique getFullName() qui me renverra la concaténation de firstName et lastName. J'ai également implémenté la méthode
activate() - pour surveiller l'état de mon entité, l'encapsulant ainsi. Dans cette méthode, j'ai placé, d'une part, une
opération de validation , et, d'autre part, en
attribuant des valeurs aux champs status et enabledBy, il n'y a donc pas besoin de setters pour eux. J'ai également ajouté à l'entité Client les
isActive() et
canPlaceOrders() , qui implémentent la validation lambda en moi. C'est ce qu'on appelle l'encapsulation des prédicats. Ces prédicats sont utiles si vous utilisez des filtres Java 8: vous pouvez les passer comme arguments aux filtres. Je vous conseille d'utiliser ces aides.
Peut-être que vous utilisez une sorte d'ORM comme Hibernate. Supposons que vous ayez deux entités avec une communication bidirectionnelle. L'initialisation doit être effectuée des deux côtés, sinon, comme vous le comprenez, vous aurez des problèmes lors de l'accès à ces données à l'avenir. Mais les développeurs oublient souvent d'initialiser un objet de l'une des parties. Lors du développement de ces entités, vous pouvez fournir des méthodes spéciales qui garantissent une initialisation bidirectionnelle. Jetez un œil à
addAddress() .

Comme vous pouvez le voir, c'est une entité très ordinaire. Mais à l'intérieur se trouve la logique du domaine. Ces entités ne doivent pas être maigres et superficielles, mais ne doivent pas être submergées de logique. Le débordement de logique se produit plus souvent: si vous décidez d'implémenter toute la logique du domaine, alors pour chaque cas d'utilisation, il sera tentant d'implémenter une méthode spécifique. En règle générale, il existe de nombreux cas d'utilisation. Vous ne recevrez pas une entité, mais une grande pile de toutes sortes de logiques. Essayez d'observer la mesure ici: seule la
logique réutilisée est placée dans le domaine et seulement
en petite quantité.
Objets de valeur
En plus des entités, vous aurez probablement aussi besoin de valeurs d'objet. Ce n'est rien d'autre qu'un moyen de regrouper les données de domaine afin de pouvoir les déplacer ultérieurement dans le système ensemble.
L'objet valeur doit être:
- Petit . Pas de
float pour les variables monétaires! Soyez prudent lors du choix des types de données. Plus votre objet est compact, plus il est facile pour un nouveau développeur de le comprendre. C'est la base d'une vie confortable.
- Inchangeable . Si l'objet est vraiment immuable, alors le développeur peut être calme que votre objet ne changera pas sa valeur et ne se cassera pas après la création. Cela jette les bases d'un travail calme et confiant.

Et si vous ajoutez un appel de méthode
validate() au constructeur, le développeur sera en mesure de se calmer pour la validité de l'entité créée (lors du passage, disons, d'une devise inexistante ou d'une somme d'argent négative, le constructeur ne fonctionnera pas).
La différence entre une entité et un objet de valeur
Les objets de valeur diffèrent des entités en ce qu'ils n'ont pas d'ID fixe. Les entités auront toujours des champs associés à la clé étrangère d'une table (ou d'un autre stockage). Les objets de valeur n'ont pas de tels champs. La question se pose: les procédures de vérification de l'égalité de deux objets valeur et de deux entités sont-elles différentes? Étant donné que les objets de valeur n'ont pas de champ ID, pour conclure que deux de ces objets sont égaux, vous devez comparer les valeurs de tous leurs champs par paires (c'est-à-dire examiner tout le contenu). Lors de la comparaison d'entités, il suffit de faire une seule comparaison - par ID de champ. C'est dans la procédure de comparaison que réside la principale différence entre les entités et les objets de valeur.
Objets de transfert de données (DTO)

Quelle est l'interaction avec l'interface utilisateur (UI)? Vous devez lui transmettre les
données à afficher . Aurez-vous vraiment besoin d'une autre structure? Il en est ainsi. Et tout cela parce que l'interface utilisateur n'est pas du tout votre ami. Il a ses propres demandes: il a besoin que les données soient stockées selon leur mode d'affichage. C'est tellement merveilleux - que ce sont parfois les interfaces utilisateur et leurs développeurs qui nous demandent. Ensuite, ils doivent obtenir des données pour cinq lignes; il leur vient alors à l'esprit de créer un
isDeletable booléen
isDeletable pour l'objet (l'objet peut-il avoir un tel champ en principe?) afin de savoir si le bouton Supprimer est actif ou non. Mais il n'y a rien à s'indigner. Les interfaces utilisateur ont simplement des exigences différentes.
La question est de savoir si nos entités peuvent leur être confiées pour utilisation? Très probablement, ils vont les changer, et de la manière la plus indésirable pour nous. Par conséquent, nous leur fournirons autre chose -
Data Transfer Objects (DTO). Ils seront spécialement adaptés aux exigences externes et à une logique différente de la nôtre. Voici quelques exemples de structures DTO: Form / Request (provenant de l'interface utilisateur), View / Response (envoyé à l'interface utilisateur), SearchCriteria / SearchResult, etc. Vous pouvez, dans un sens, appeler cela un modèle d'API.
Premier principe important: le DTO doit contenir un minimum de logique.
Voici un exemple d'implémentation de
CustomerDto .
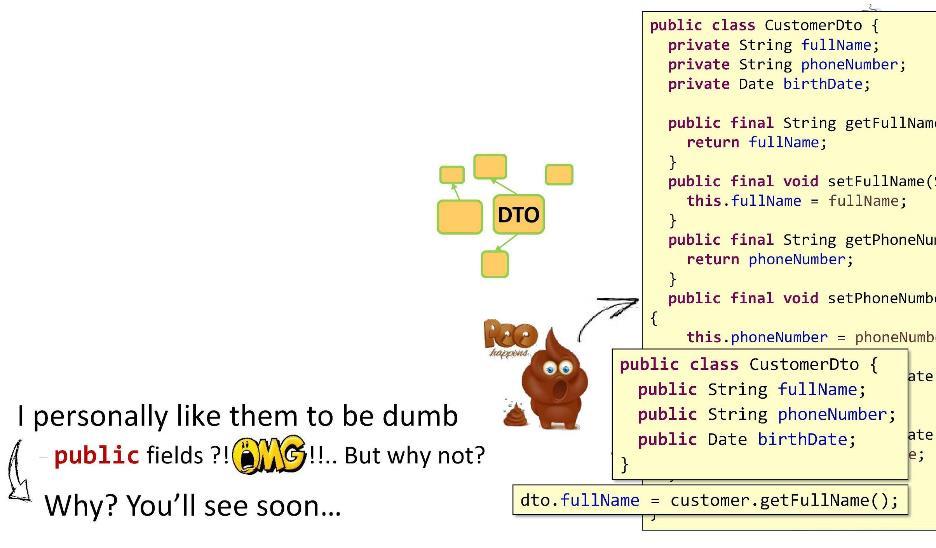
Contenu: champs
privés , getters
publics et setters pour eux. Tout semble super. OOP dans toute sa splendeur. Mais une chose est mauvaise: sous la forme de getters et setters, j'ai mis en œuvre trop de méthodes. Dans DTO, il devrait y avoir aussi peu de logique que possible. Et puis quelle est ma sortie? Je rend les champs publics! Vous direz que cela fonctionne mal avec les références de méthode de Java 8, qu'il y aura des limitations, etc. Mais croyez-le ou non, j'ai fait tous mes projets (10-11 pièces) avec de tels DTO. Le frère est vivant. Maintenant, comme mes champs sont publics, je peux facilement définir la valeur sur
dto.fullName en mettant simplement un signe égal. Quoi de plus beau et de plus simple?
Organisation logique
Cartographie
Donc, nous avons une tâche: nous devons transformer nos entités en DTO. Nous mettons en œuvre la transformation comme suit:
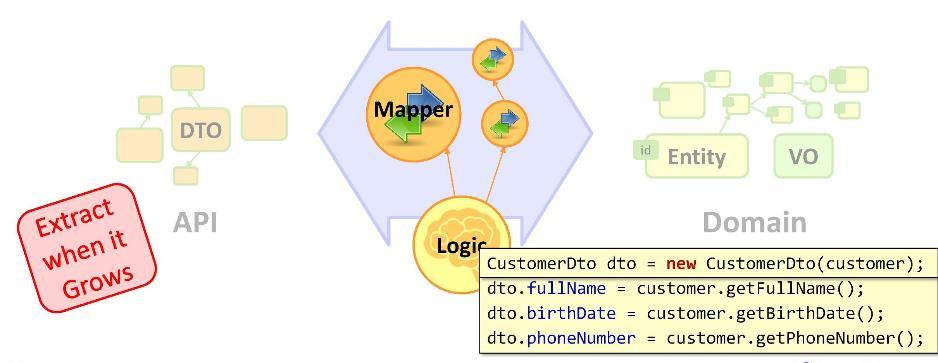
Comme vous pouvez le voir, en déclarant un DTO, nous passons aux opérations de mappage (attribution de valeur). Dois-je être un développeur senior pour écrire des affectations régulières dans de tels nombres? Pour certains, c'est tellement inhabituel qu'ils commencent à changer de chaussures en cours de route: par exemple, copier des données en utilisant une sorte de cadre de cartographie en utilisant la réflexion. Mais ils manquent l'essentiel - que tôt ou tard, l'interface utilisateur interagira avec le DTO, à la suite de quoi l'entité et le DTO divergent dans leurs significations.
On pourrait, par exemple, mettre des opérations de mappage dans le constructeur. Mais cela n'est possible pour aucune cartographie; en particulier, le concepteur ne peut pas accéder à la base de données.
Ainsi, nous sommes obligés de laisser les opérations de mappage dans la logique métier. Et s'ils ont une apparence compacte, il n'y a rien à craindre. Si le mappage ne prend pas quelques lignes, mais plus, il est préférable de le placer dans le soi-disant
mappeur . Un mappeur est une classe spécialement conçue pour copier des données. Ceci, en général, est chose antédiluvienne et passe-partout. Mais derrière eux, vous pouvez masquer nos nombreuses tâches - pour rendre le code plus propre et plus mince.
N'oubliez pas: un
code devenu trop volumineux doit être déplacé vers une structure distincte . Dans notre cas, les opérations de mappage étaient vraiment un peu nombreuses, nous les avons donc déplacées vers une classe distincte - le mappeur.
Les mappeurs doivent-ils autoriser l'accès à la base de données? Vous pouvez l'activer par défaut - cela est souvent fait pour des raisons de simplicité et de pragmatisme. Mais cela vous expose à certains risques.
Je vais illustrer avec un exemple. Sur la base du DTO existant, nous créons l'entité
Customer .
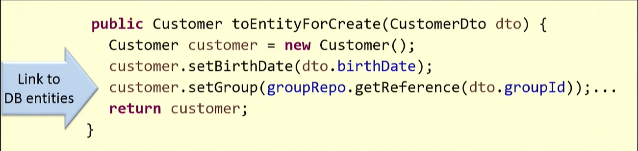
Pour la cartographie, nous devons obtenir un lien vers le groupe du client à partir de la base de données.
getReference() méthode
getReference() , et elle me renvoie une entité. La demande ira très probablement à la base de données (dans certains cas, cela ne se produit pas et la fonction de remplacement fonctionne).
Mais le problème ne nous attend pas ici, mais dans la méthode qui effectue l'opération inverse - transformer l'entité en DTO.

À l'aide d'une boucle, nous parcourons toutes les adresses associées au client existant et les traduisons en adresses DTO. Si vous utilisez ORM, alors, probablement, lorsque vous appelez la méthode
getAddresses() , un chargement
getAddresses() sera effectué. Si vous n'utilisez pas ORM, ce sera une demande ouverte à tous les enfants de ce parent. Et là, vous courez le risque de plonger dans le «problème N + 1». Pourquoi?
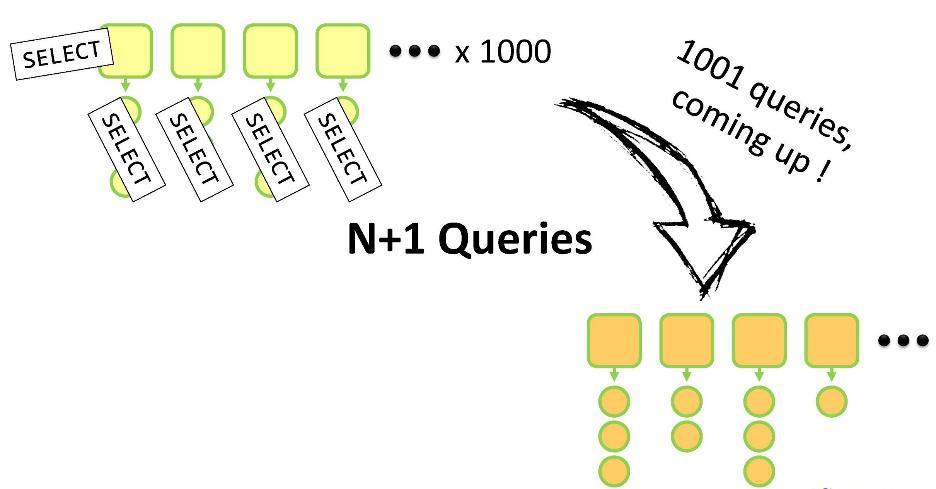
Vous avez un ensemble de parents dont chacun a des enfants. Pour tout cela, vous devez créer vos propres analogues à l'intérieur du DTO. Vous devrez effectuer une requête
SELECT pour parcourir N entités parentes puis N requêtes
SELECT pour contourner les enfants de chacune d'entre elles. Total N + 1 demande. Pour 1000 entités
Customer mères, une telle opération prendra 5 à 10 secondes, ce qui, bien sûr, prend beaucoup de temps.
Supposons que, néanmoins, notre méthode
CustomerDto() soit appelée à l'intérieur de la boucle, convertissant la liste des objets Customer en liste CustomerDto.
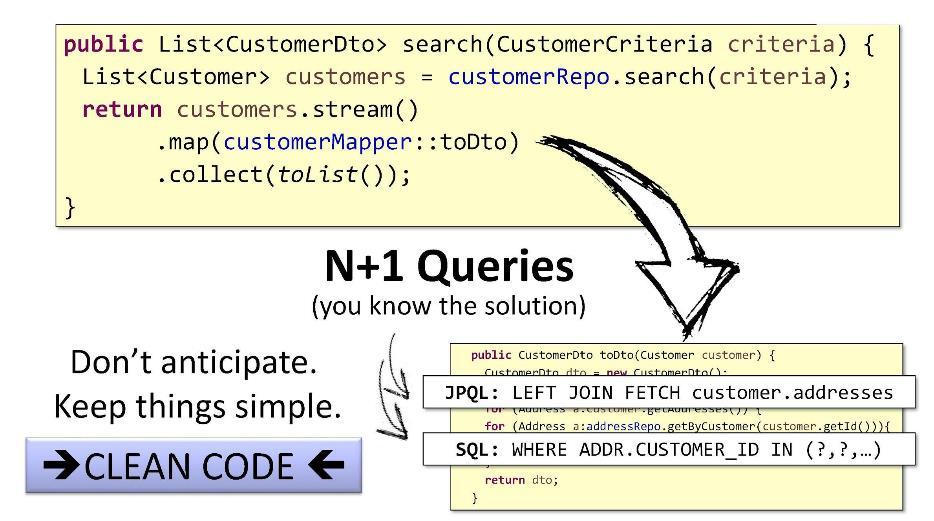
Le problème avec les requêtes N + 1 a des solutions standard simples: dans
JPQL, vous pouvez utiliser
FETCH by customer.addresses pour récupérer des enfants, puis les connecter à l'aide de
JOIN , et dans SQL, vous pouvez utiliser le contournement
IN et la
WHERE .
Mais je le ferais différemment. Vous pouvez savoir quelle est la longueur maximale de la liste des enfants (cela peut être fait, par exemple, sur la base d'une recherche avec pagination). Si la liste ne contient que 15 entités, nous n'avons besoin que de 16 requêtes. Au lieu de 5 ms, nous passerons à tout, disons 15 ms - l'utilisateur ne remarquera pas la différence.
À propos de l'optimisation
Je ne vous conseillerais pas de revenir sur les performances du système au stade initial de développement. Comme l'a dit Donald Knud: «L'optimisation prématurée est la racine du mal.» Vous ne pouvez pas optimiser dès le départ. C'est exactement ce qui doit être laissé pour plus tard. Et ce qui est particulièrement important:
pas d'hypothèses - uniquement des mesures et l'évaluation des mesures!Etes-vous sûr que vous êtes compétent que vous êtes un vrai expert? Soyez humble en vous évaluant. Ne pensez pas que vous comprenez la JVM avant d'avoir lu au moins quelques livres sur la compilation JIT. Il arrive que les meilleurs programmeurs de notre équipe viennent me voir et disent
qu'ils pensent avoir trouvé une implémentation plus efficace. Il s'avère qu'ils ont à nouveau inventé quelque chose qui ne fait que compliquer le code. Alors je réponds encore et encore: YAGNI. Nous n'en avons pas besoin.
Souvent, pour les applications d'entreprise, aucune optimisation des algorithmes n'est nécessaire. Le goulot d'étranglement pour eux, en règle générale, n'est pas la compilation et pas en ce qui concerne le processeur, mais toutes sortes d'opérations d'entrée-sortie. Par exemple, en lisant un million de lignes d'une base de données, des écritures volumineuses dans un fichier, une interaction avec des sockets.
Au fil du temps, vous commencez à comprendre quels goulots d'étranglement le système contient et, en renforçant le tout avec des mesures, vous commencerez à optimiser progressivement. Pour l'instant, gardez le code aussi propre que possible. Vous constaterez qu'un tel code est beaucoup plus facile à optimiser davantage.
Préfère la composition à l'héritage
Retour à notre DTO. Supposons que nous définissions un DTO comme ceci:

Nous pouvons en avoir besoin dans de nombreux workflows. Mais ces flux sont différents et, très probablement, chaque cas d'utilisation supposera un degré différent de remplissage sur le terrain. Par exemple, nous devrons évidemment créer un DTO plus tôt que lorsque nous disposons d'informations complètes sur l'utilisateur. Vous pouvez temporairement laisser les champs vides. Mais plus vous ignorerez de champs, plus vous voudrez créer un nouveau DTO plus strict pour ce cas d'utilisation.
Vous pouvez également créer des copies d'un DTO trop volumineux (dans le nombre de cas d'utilisation disponibles), puis en supprimer des champs supplémentaires pour chaque copie. Mais pour de nombreux programmeurs, en raison de leur intelligence et de leur alphabétisation, cela fait vraiment mal d'appuyer sur Ctrl + V. L'axiome dit que le copier-coller est mauvais.
Vous pouvez recourir au principe d'
héritage connu dans la théorie de la POO: il suffit de définir un DTO de base et de créer un héritier pour chaque cas d'utilisation.
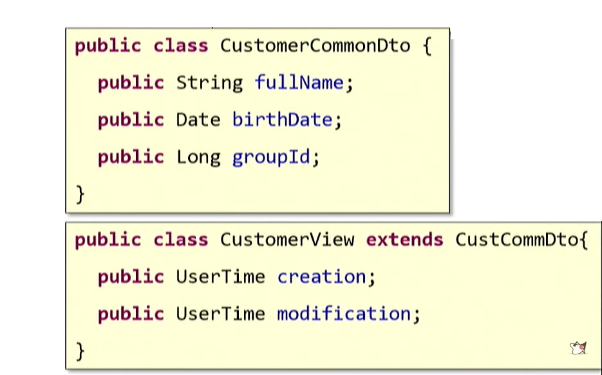
Un principe bien connu est: «Préférez la composition à l'héritage». Lisez ce qu'il dit:
«s'étend» . Il semble que nous aurions dû «élargir» la classe source. Mais si vous y réfléchissez, alors ce que nous avons fait n'est pas du tout «l'expansion». C'est la vraie «répétition» - le même copier-coller, vue latérale. Par conséquent, nous n'utiliserons pas d'héritage.
Mais que devons-nous donc être? Comment aller à la composition? Faisons-le de cette façon: écrivez un champ dans CustomerView qui pointera vers l'objet du DTO sous-jacent.
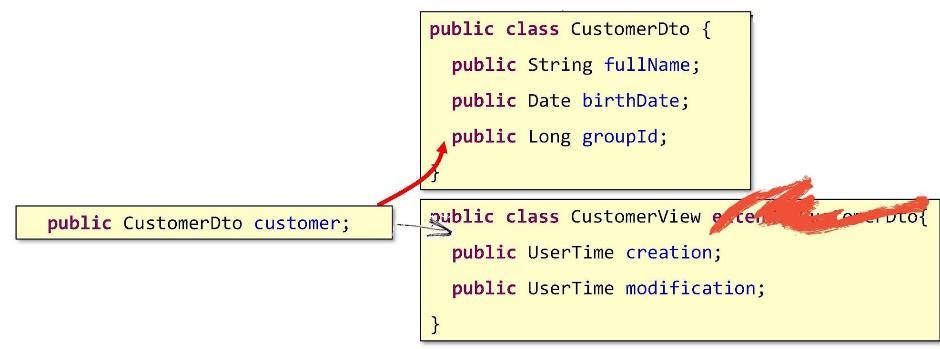
Ainsi, notre structure de base sera imbriquée à l'intérieur. C'est ainsi que la vraie composition sort.
Que nous utilisions l'héritage ou résolvions le problème par composition - ce sont toutes des particularités, des subtilités qui ont surgi profondément au cours de notre mise en œuvre. Ils sont très
fragiles . Que signifie fragile? Jetez un œil à ce code:

La plupart des développeurs à qui j'ai montré cela ont immédiatement laissé entendre que le nombre "2" était répété, il fallait donc le supprimer comme une constante. Ils n'ont pas remarqué que le diable dans les trois cas a une signification complètement différente (ou «valeur commerciale») et que sa répétition n'est rien de plus qu'une coïncidence. Tirer un deux dans une constante est une décision légitime, mais très fragile. Essayez de ne pas autoriser une logique fragile dans le domaine. Ne travaillez jamais avec des structures de données externes, en particulier avec DTO.
Alors, pourquoi le travail d'élimination de l'héritage et d'introduction de la composition est-il inutile? Précisément parce que nous créons du DTO non pas pour nous, mais pour un client externe. Et comment l'application client analysera le DTO reçu de vous - vous ne pouvez que deviner. Mais évidemment, cela n'aura pas grand-chose à voir avec votre implémentation. Les développeurs, d'autre part, peuvent ne pas faire de distinction pour les DTO de base et non de base que vous avez soigneusement réfléchis; ils utilisent probablement l'héritage, et peut-être bêtement copier-coller c'est tout.
Façades

Revenons à l'image globale de l'application. Je vous conseille d'implémenter la logique du domaine via le
modèle de façade , en étendant les façades avec des
services de domaine si nécessaire. Un service de domaine est créé lorsque trop de logique s'accumule dans la façade, et il est plus pratique de le placer dans une classe distincte.
Vos services de domaine doivent nécessairement parler la langue de votre modèle de domaine (ses entités et objets de valeur). Ils ne doivent en aucun cas travailler avec DTO, car les DTO, comme vous vous en souvenez, sont des structures en constante évolution côté client, trop fragiles pour un domaine.
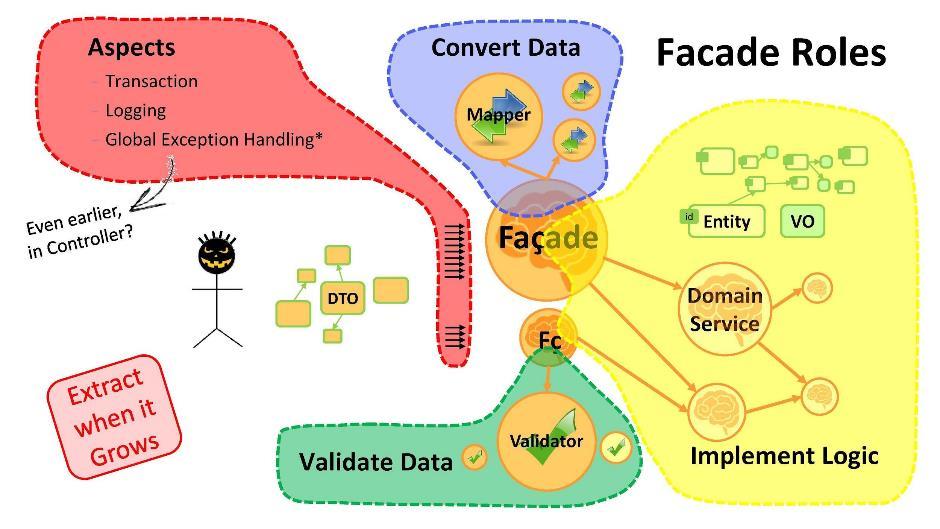
À quoi sert la façade?
- Conversion de données. Si nous avons des entités d'un côté et des DTO de l'autre, il faut effectuer des transformations de l'un à l'autre. Et c'est la première chose à laquelle les façades sont destinées. Si la procédure de conversion a augmenté en volume - utilisez les classes de mappage.
- L'implémentation de la logique. Dans la façade, vous commencerez à écrire la logique principale de l'application. Dès que cela devient beaucoup - apportez des pièces au service de domaine.
- Validation des données. N'oubliez pas que toutes les données reçues de l'utilisateur sont, par définition, incorrectes (contenant des erreurs). La façade a la capacité de valider les données. Ces procédures, lorsque le volume est dépassé, sont généralement transmises aux valideurs .
- Aspects Vous pouvez aller plus loin et faire passer chaque cas d'utilisation par sa façade. Ensuite, il s'avérera ajouter des choses telles que les transactions, la journalisation, les gestionnaires d'exceptions globales aux méthodes de façade. Je note qu'il est très important d'avoir des gestionnaires d'exceptions globales dans toute application qui détectent toutes les erreurs non détectées par d'autres gestionnaires. Ils aideront grandement vos programmeurs - ils leur donneront la tranquillité d'esprit et la liberté d'action.
Décomposition de beaucoup de code
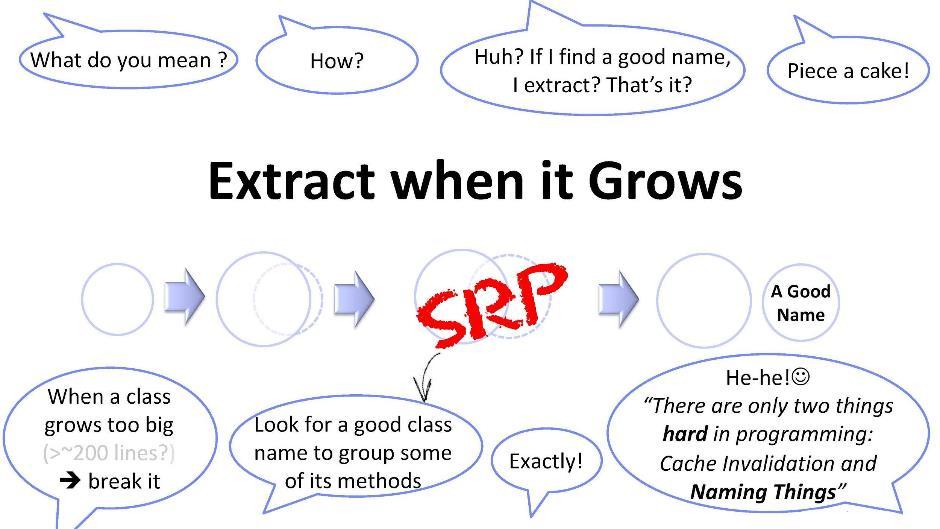
Encore quelques mots sur ce principe. Si la classe a atteint une taille qui ne me convient pas (disons, 200 lignes), je devrais essayer de la diviser en morceaux. Mais isoler une nouvelle classe d'une classe existante n'est pas toujours facile. Nous devons trouver des moyens universels. L'une de ces méthodes consiste à rechercher des noms: vous essayez de trouver un nom pour un sous-ensemble des méthodes de votre classe. Dès que vous parvenez à trouver un nom, n'hésitez pas à créer une nouvelle classe. Mais ce n'est pas si simple. En programmation, comme vous le savez, il n'y a que deux choses complexes: cela invalide le cache et invente des noms. Dans ce cas, inventer un nom implique d'identifier une sous-tâche - se cacher et donc pas préalablement identifié par quiconque.
Un exemple:
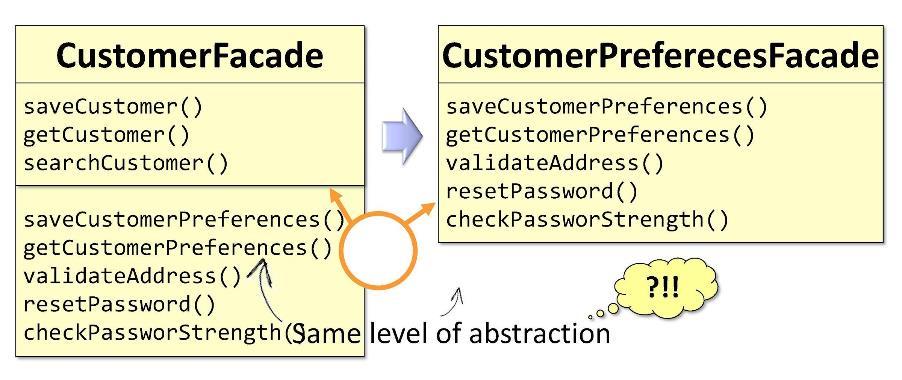
Dans la façade d'origine de
CustomerFacade certaines des méthodes sont directement liées au client, et certaines sont liées aux préférences du client. Sur cette base, je pourrai diviser la classe en deux lorsqu'elle atteindra des tailles critiques. J'obtiens deux façades:
CustomerFacade et
CustomerPreferencesFacade . La seule mauvaise chose est que ces deux façades appartiennent au même niveau d'abstraction. La séparation par niveaux d'abstraction implique quelque chose de différent.
Un autre exemple:

Supposons qu'il existe une classe
OrderService dans notre système dans laquelle nous avons implémenté un mécanisme de notification par e-mail. Nous créons maintenant un
DeliveryService et souhaitons utiliser le même mécanisme de notification ici. Le copier-coller est exclu. Faisons-le de cette façon: extrayez la fonctionnalité de notification dans la nouvelle classe
AlertService et écrivez-la en tant que dépendance pour les
OrderService DeliveryService et
OrderService . Ici, contrairement à l'exemple précédent, la séparation s'est produite précisément aux niveaux d'abstraction.
DeliveryServiceplus abstrait que AlertService, car il l'utilise dans le cadre de son flux de travail.La séparation par niveaux d'abstraction suppose toujours que la classe extraite devient une dépendance et l' extraction est effectuée pour être réutilisée .La tâche d'extraction n'est pas toujours facile. Elle peut également entraîner certaines difficultés et nécessiter une refactorisation des tests unitaires. Néanmoins, selon mes observations, il est encore plus difficile pour les développeurs de rechercher des fonctionnalités dans l'énorme base de code monolithique de l'application.Programmation par paire
 De nombreux consultants parleront de la programmation en binôme, du fait qu'il s'agit d'une solution universelle à tous les problèmes de développement informatique d'aujourd'hui. Pendant ce temps, les programmeurs développent leurs compétences techniques et leurs connaissances fonctionnelles. De plus, le processus lui-même est intéressant, il rassemble l'équipe.Ne parlant pas en tant que consultants, mais humainement, la chose la plus importante est la suivante: la programmation par paires améliore le «facteur bus». L’essence du «facteur bus» est qu’il devrait y avoir autant de personnes qui connaissent la structure du système que possible . Perdre ces personnes signifie perdre les derniers indices de cette connaissance.Le refactoring de la programmation en binôme est un art qui nécessite de l'expérience et de la formation. Il est utile, par exemple, la pratique du refactoring agressif, de la réalisation de hackathons, de coupures, de codage de dojos, etc.La programmation par paire fonctionne bien dans les cas où vous devez résoudre des problèmes de grande complexité. Le processus de collaboration n'est pas toujours simple. Mais cela vous garantit que vous éviterez la "réingénierie" - au contraire, vous obtiendrez une implémentation qui répond aux exigences définies avec une complexité minimale.
De nombreux consultants parleront de la programmation en binôme, du fait qu'il s'agit d'une solution universelle à tous les problèmes de développement informatique d'aujourd'hui. Pendant ce temps, les programmeurs développent leurs compétences techniques et leurs connaissances fonctionnelles. De plus, le processus lui-même est intéressant, il rassemble l'équipe.Ne parlant pas en tant que consultants, mais humainement, la chose la plus importante est la suivante: la programmation par paires améliore le «facteur bus». L’essence du «facteur bus» est qu’il devrait y avoir autant de personnes qui connaissent la structure du système que possible . Perdre ces personnes signifie perdre les derniers indices de cette connaissance.Le refactoring de la programmation en binôme est un art qui nécessite de l'expérience et de la formation. Il est utile, par exemple, la pratique du refactoring agressif, de la réalisation de hackathons, de coupures, de codage de dojos, etc.La programmation par paire fonctionne bien dans les cas où vous devez résoudre des problèmes de grande complexité. Le processus de collaboration n'est pas toujours simple. Mais cela vous garantit que vous éviterez la "réingénierie" - au contraire, vous obtiendrez une implémentation qui répond aux exigences définies avec une complexité minimale. L'organisation d'un format de travail pratique est l'une de vos principales responsabilités envers l'équipe. Vous devez constamment prendre soin des conditions de travail du développeur - leur fournir un confort complet et une liberté de créativité, surtout si elles sont nécessaires pour augmenter l'architecture de conception et sa complexité.
L'organisation d'un format de travail pratique est l'une de vos principales responsabilités envers l'équipe. Vous devez constamment prendre soin des conditions de travail du développeur - leur fournir un confort complet et une liberté de créativité, surtout si elles sont nécessaires pour augmenter l'architecture de conception et sa complexité.«Je suis architecte. Par définition, j'ai toujours raison. »
Cette stupidité s'exprime périodiquement publiquement ou en coulisses. Dans la pratique d'aujourd'hui, les architectes en tant que tels se retrouvent de moins en moins. Avec l'avènement d'Agile, ce rôle est progressivement passé aux développeurs seniors, car généralement tout le travail, d'une manière ou d'une autre, est construit autour d'eux. La taille de l'implémentation augmente progressivement, et avec cela il y a un besoin de refactoring et de nouvelles fonctionnalités sont en cours de développement.Architecture de l'oignon
Oignon est la philosophie de script de transaction la plus pure. En le construisant, nous sommes guidés par l'objectif de protéger le code que nous considérons comme critique, et pour cela nous le déplaçons vers le module de domaine. Dans notre application, les plus importants sont les services de domaine: ils mettent en œuvre les flux les plus critiques. Déplacez-les vers le module de domaine. Bien sûr, il vaut également la peine de déplacer tous vos objets de domaine ici - entités et objets de valeur. Tout le reste que nous avons compilé aujourd'hui - DTO, mappeurs, validateurs, etc. - devient, pour ainsi dire, la première ligne de défense de l'utilisateur. Parce que l'utilisateur, hélas, n'est pas notre ami, et il est nécessaire de protéger le système contre lui.Attention à cette dépendance:
Dans notre application, les plus importants sont les services de domaine: ils mettent en œuvre les flux les plus critiques. Déplacez-les vers le module de domaine. Bien sûr, il vaut également la peine de déplacer tous vos objets de domaine ici - entités et objets de valeur. Tout le reste que nous avons compilé aujourd'hui - DTO, mappeurs, validateurs, etc. - devient, pour ainsi dire, la première ligne de défense de l'utilisateur. Parce que l'utilisateur, hélas, n'est pas notre ami, et il est nécessaire de protéger le système contre lui.Attention à cette dépendance: Le module d'application dépendra du module de domaine, c'est-à-dire pas l'inverse. En enregistrant une telle connexion, nous garantissons que le DTO ne pénètrera jamais dans le territoire sacré du module de domaine: ils ne sont tout simplement pas visibles et inaccessibles depuis le module de domaine. Il s'avère que dans un sens, nous avons clôturé le territoire du domaine - nous avons restreint l'accès à celui-ci par des étrangers.Cependant, le domaine peut avoir besoin d'interagir avec certains services externes. Avec des moyens extérieurs peu amicaux, car il est équipé de son DTO. Quelles sont nos options?Premièrement: évitez l'ennemi à l'intérieur du module.
Le module d'application dépendra du module de domaine, c'est-à-dire pas l'inverse. En enregistrant une telle connexion, nous garantissons que le DTO ne pénètrera jamais dans le territoire sacré du module de domaine: ils ne sont tout simplement pas visibles et inaccessibles depuis le module de domaine. Il s'avère que dans un sens, nous avons clôturé le territoire du domaine - nous avons restreint l'accès à celui-ci par des étrangers.Cependant, le domaine peut avoir besoin d'interagir avec certains services externes. Avec des moyens extérieurs peu amicaux, car il est équipé de son DTO. Quelles sont nos options?Premièrement: évitez l'ennemi à l'intérieur du module.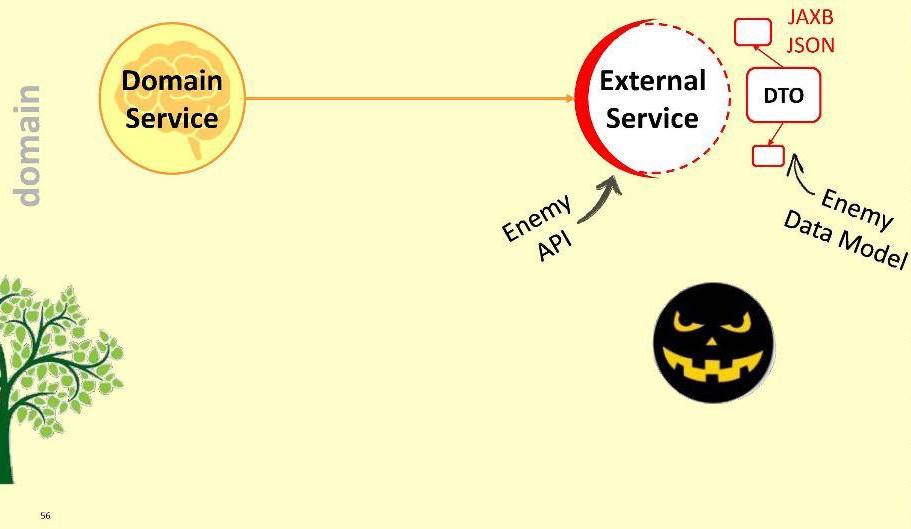 Évidemment, c'est une mauvaise option: il est possible que demain le service externe ne passe pas à la version 2.0, et nous devrons redessiner notre domaine. Ne laissez pas l'ennemi à l'intérieur du domaine!Je propose une approche différente: nous allons créer un adaptateur spécial pour l'interaction .
Évidemment, c'est une mauvaise option: il est possible que demain le service externe ne passe pas à la version 2.0, et nous devrons redessiner notre domaine. Ne laissez pas l'ennemi à l'intérieur du domaine!Je propose une approche différente: nous allons créer un adaptateur spécial pour l'interaction .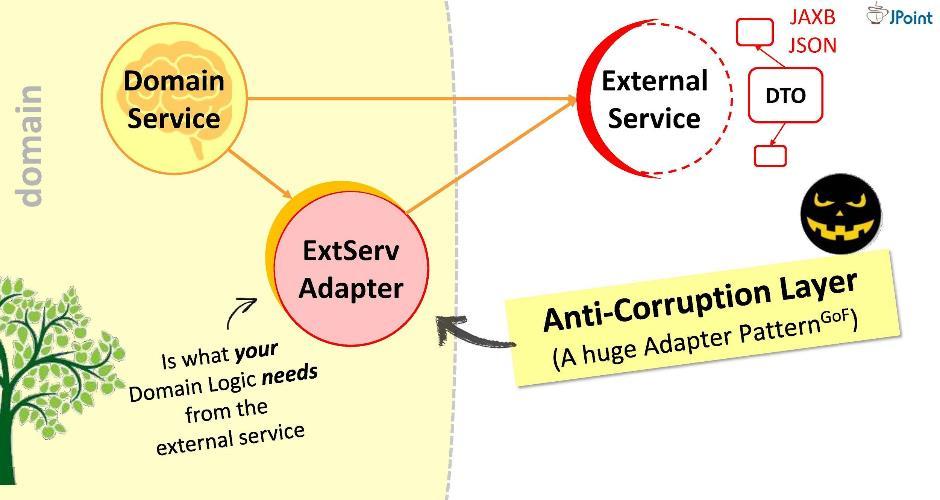 L'adaptateur recevra les données d'un service externe, extraira les données dont notre domaine a besoin et les convertira en types de structures requis. Dans ce cas, tout ce qui nous est demandé pendant le développement est de corréler les appels vers le système externe avec les exigences du domaine. Considérez-le comme un énorme adaptateur comme celui-ci . J'appelle cette couche «anti-corruption».Par exemple, nous pouvons avoir besoin d'exécuter des requêtes LDAP à partir d'un domaine. Pour ce faire, nous mettons en œuvre le «module anti-corruption»
L'adaptateur recevra les données d'un service externe, extraira les données dont notre domaine a besoin et les convertira en types de structures requis. Dans ce cas, tout ce qui nous est demandé pendant le développement est de corréler les appels vers le système externe avec les exigences du domaine. Considérez-le comme un énorme adaptateur comme celui-ci . J'appelle cette couche «anti-corruption».Par exemple, nous pouvons avoir besoin d'exécuter des requêtes LDAP à partir d'un domaine. Pour ce faire, nous mettons en œuvre le «module anti-corruption» LDAPUserServiceAdapter. Dans l'adaptateur, nous pouvons:
Dans l'adaptateur, nous pouvons:- Masquer les appels d'API laids (dans notre cas, masquer la méthode qui prend le tableau Object);
- Pack d'exceptions dans nos propres implémentations;
- Convertir les structures de données des autres en leurs propres (dans nos objets de domaine);
- Vérifiez la validité des données entrantes.
C'est le but de l'adaptateur. Bon, à l'interface avec chaque système externe avec lequel vous devez interagir, votre adaptateur doit être installé. Ainsi, le domaine ne dirigera pas l'appel vers un service externe, mais vers l'adaptateur. Pour ce faire, la dépendance correspondante doit être enregistrée dans le domaine (depuis l'adaptateur ou depuis le module d'infrastructure dans lequel elle se trouve). Mais cette dépendance est-elle sûre? Si vous l'installez comme ceci, un DTO de service externe peut entrer dans notre domaine. Nous ne devons pas permettre cela. Par conséquent, je vous suggère une autre façon de modéliser les dépendances.
Ainsi, le domaine ne dirigera pas l'appel vers un service externe, mais vers l'adaptateur. Pour ce faire, la dépendance correspondante doit être enregistrée dans le domaine (depuis l'adaptateur ou depuis le module d'infrastructure dans lequel elle se trouve). Mais cette dépendance est-elle sûre? Si vous l'installez comme ceci, un DTO de service externe peut entrer dans notre domaine. Nous ne devons pas permettre cela. Par conséquent, je vous suggère une autre façon de modéliser les dépendances.Principe d'inversion de dépendance
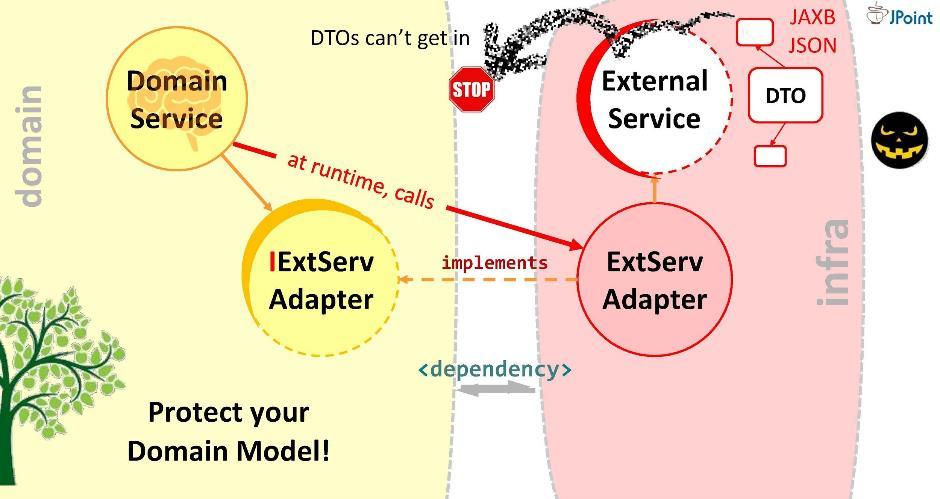 Créons une interface, écrivons-y la signature des méthodes nécessaires et plaçons-la dans notre domaine. La tâche de l'adaptateur est d'implémenter cette interface. Il s'avère que l'interface est à l'intérieur du domaine, et l'adaptateur est à l'extérieur, dans le module d'infrastructure qui importe l'interface. Ainsi, nous avons tourné la direction de la dépendance dans la direction opposée. Au moment de l'exécution, le système de domaine appellera n'importe quelle classe via des interfaces.Comme vous pouvez le voir, rien qu'en introduisant des interfaces dans l'architecture, nous avons pu déployer des dépendances et ainsi sécuriser notre domaine contre les structures étrangères et les API qui y tombent. Cette approche est appelée inversion de dépendance .
Créons une interface, écrivons-y la signature des méthodes nécessaires et plaçons-la dans notre domaine. La tâche de l'adaptateur est d'implémenter cette interface. Il s'avère que l'interface est à l'intérieur du domaine, et l'adaptateur est à l'extérieur, dans le module d'infrastructure qui importe l'interface. Ainsi, nous avons tourné la direction de la dépendance dans la direction opposée. Au moment de l'exécution, le système de domaine appellera n'importe quelle classe via des interfaces.Comme vous pouvez le voir, rien qu'en introduisant des interfaces dans l'architecture, nous avons pu déployer des dépendances et ainsi sécuriser notre domaine contre les structures étrangères et les API qui y tombent. Cette approche est appelée inversion de dépendance .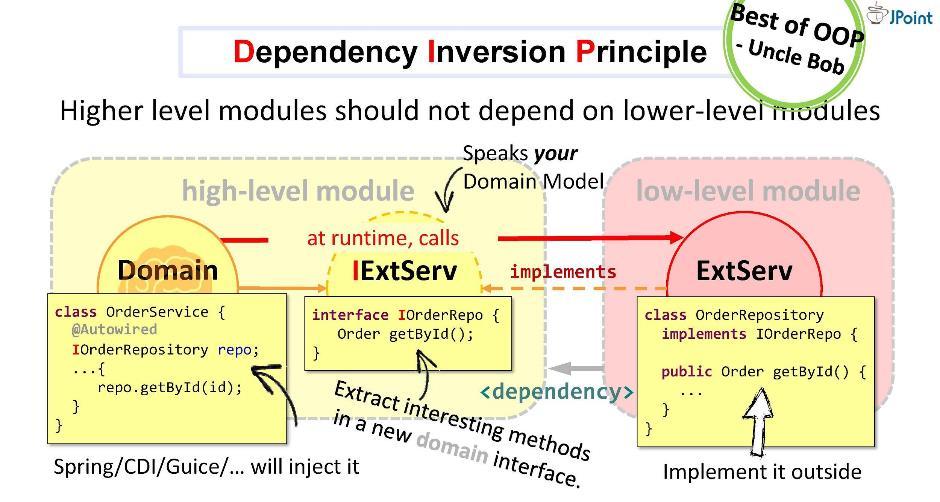 En général, l'inversion de dépendance suppose que vous placez les méthodes qui vous intéressent dans l'interface à l'intérieur de votre module de haut niveau (dans le domaine), et implémentez cette interface de l'extérieur - dans l'un ou l'autre module laid de bas niveau (infrastructure).L'interface implémentée à l'intérieur du module de domaine doit parler la langue du domaine, c'est-à-dire qu'elle fonctionnera sur ses entités, ses paramètres et ses types de retour. Au moment de l'exécution, le domaine appellera n'importe quelle classe via un appel polymorphe à l'interface. Les frameworks d'injection de dépendances (comme Spring et CDI) nous fournissent une instance concrète de la classe directement à l'exécution.Mais l'essentiel est que pendant la compilation, le module de domaine ne verra pas le contenu du module externe. Voilà ce dont nous avons besoin. Aucune entité externe ne doit tomber dans le domaine.Selon l' oncle Bob , le principe de l'inversion de contrôle (ou, comme il l'appelle, «architecture plug-in») est peut-être le meilleur que le paradigme OOP offre en général.
En général, l'inversion de dépendance suppose que vous placez les méthodes qui vous intéressent dans l'interface à l'intérieur de votre module de haut niveau (dans le domaine), et implémentez cette interface de l'extérieur - dans l'un ou l'autre module laid de bas niveau (infrastructure).L'interface implémentée à l'intérieur du module de domaine doit parler la langue du domaine, c'est-à-dire qu'elle fonctionnera sur ses entités, ses paramètres et ses types de retour. Au moment de l'exécution, le domaine appellera n'importe quelle classe via un appel polymorphe à l'interface. Les frameworks d'injection de dépendances (comme Spring et CDI) nous fournissent une instance concrète de la classe directement à l'exécution.Mais l'essentiel est que pendant la compilation, le module de domaine ne verra pas le contenu du module externe. Voilà ce dont nous avons besoin. Aucune entité externe ne doit tomber dans le domaine.Selon l' oncle Bob , le principe de l'inversion de contrôle (ou, comme il l'appelle, «architecture plug-in») est peut-être le meilleur que le paradigme OOP offre en général.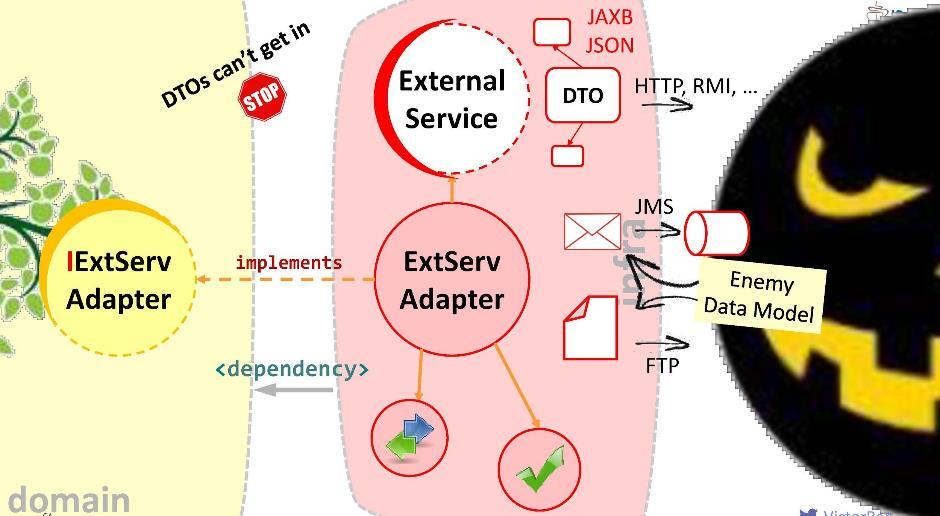 Cette stratégie peut être utilisée pour l'intégration avec tous les systèmes, pour les appels et messages synchrones et asynchrones, pour l'envoi de fichiers, etc.
Cette stratégie peut être utilisée pour l'intégration avec tous les systèmes, pour les appels et messages synchrones et asynchrones, pour l'envoi de fichiers, etc.Présentation de l'ampoule
 Nous avons donc décidé de protéger le module de domaine. À l'intérieur, il y a un service de domaine, des entités, des objets de valeur, et maintenant des interfaces pour les services externes, ainsi que des interfaces pour le référentiel (pour interagir avec la base de données).La structure ressemble à ceci:
Nous avons donc décidé de protéger le module de domaine. À l'intérieur, il y a un service de domaine, des entités, des objets de valeur, et maintenant des interfaces pour les services externes, ainsi que des interfaces pour le référentiel (pour interagir avec la base de données).La structure ressemble à ceci: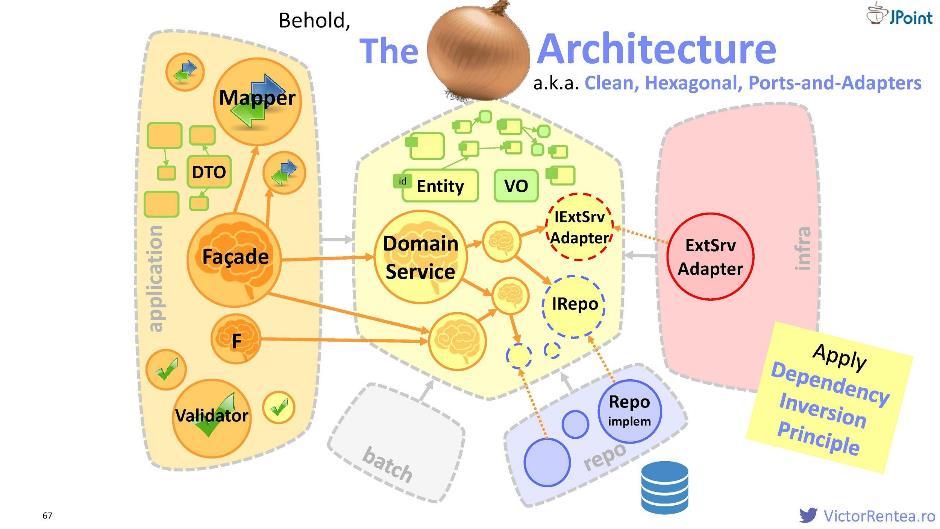 le module d'application, le module d'infrastructure (via l'inversion de dépendance), le module de référentiel (nous considérons également la base de données comme un système externe), le module batch et éventuellement certains autres modules sont des dépendances déclarées pour le domaine. Cette architecture est appelée «oignon» ; il est également appelé «propre», «hexagonal» et «ports et adaptateurs».
le module d'application, le module d'infrastructure (via l'inversion de dépendance), le module de référentiel (nous considérons également la base de données comme un système externe), le module batch et éventuellement certains autres modules sont des dépendances déclarées pour le domaine. Cette architecture est appelée «oignon» ; il est également appelé «propre», «hexagonal» et «ports et adaptateurs».Module de référentiel
Je vais parler brièvement du module de référentiel. Que ce soit pour le retirer du domaine est une question. La tâche du référentiel est de rendre la logique plus propre, en nous cachant l'horreur de travailler avec des données persistantes. L'option pour les gars de la vieille école est d'utiliser JDBC pour interagir avec la base de données: Vous pouvez également utiliser Spring et son JdbcTemplate:
Vous pouvez également utiliser Spring et son JdbcTemplate: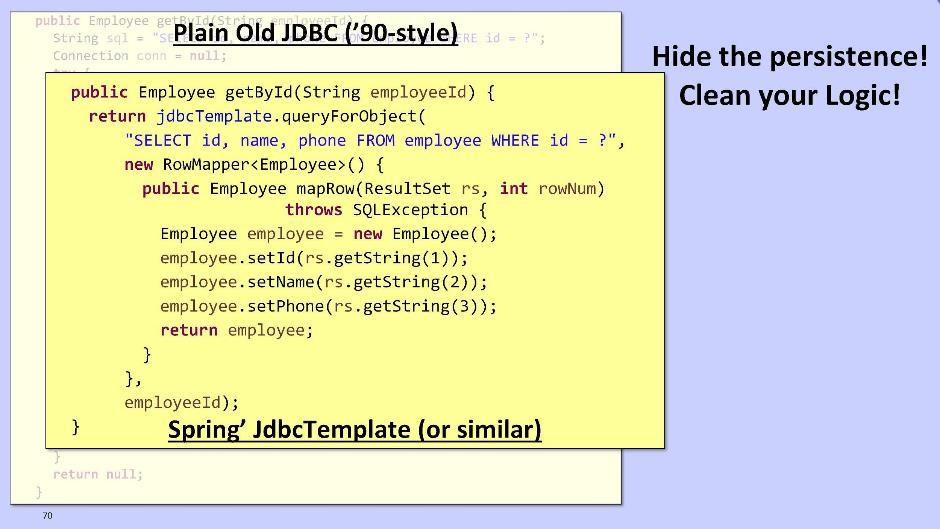 Ou MyBatis DataMapper:
Ou MyBatis DataMapper: Mais c'est tellement compliqué et laid que cela décourage tout désir de faire quoi que ce soit d'autre. Par conséquent, je suggère d'utiliser JPA / Hibernate ou Spring Data JPA. Ils nous donneront la possibilité d'envoyer des requêtes construites non pas sur le schéma de la base de données, mais directement sur la base du modèle de nos entités.Implémentation pour JPA / Hibernate:
Mais c'est tellement compliqué et laid que cela décourage tout désir de faire quoi que ce soit d'autre. Par conséquent, je suggère d'utiliser JPA / Hibernate ou Spring Data JPA. Ils nous donneront la possibilité d'envoyer des requêtes construites non pas sur le schéma de la base de données, mais directement sur la base du modèle de nos entités.Implémentation pour JPA / Hibernate: Dans le cas de Spring Data JPA:
Dans le cas de Spring Data JPA: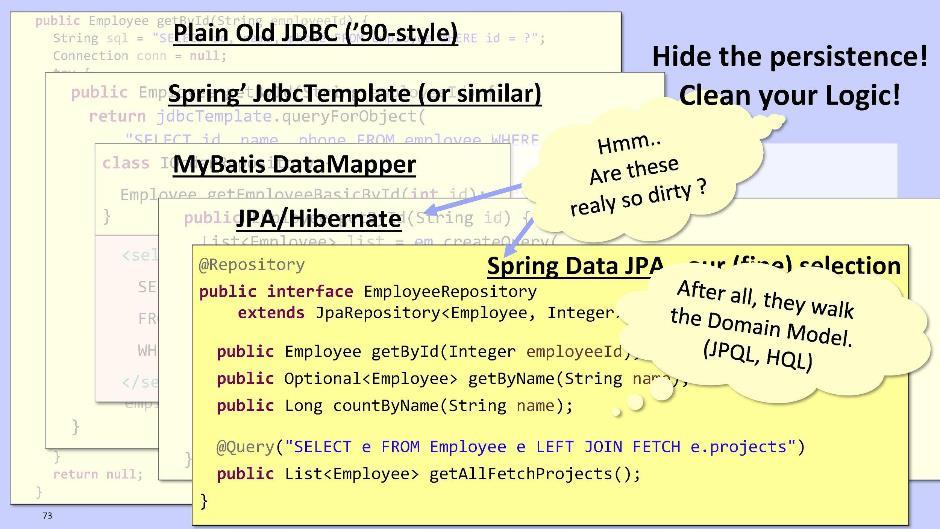 Spring Data JPA peut générer automatiquement des méthodes au moment de l'exécution, telles que, par exemple, getById (), getByName (). Il vous permet également d'exécuter des requêtes JPQL si nécessaire - et non vers la base de données, mais vers votre propre modèle d'entité.Le code Hibernate JPA et Spring Data JPA est vraiment très bon. Avons-nous besoin de l'extraire du domaine? À mon avis, ce n'est pas ainsi et nécessaire. Très probablement, le code sera encore plus propre si vous laissez ce fragment à l'intérieur du domaine. Alors agissez sur la situation.
Spring Data JPA peut générer automatiquement des méthodes au moment de l'exécution, telles que, par exemple, getById (), getByName (). Il vous permet également d'exécuter des requêtes JPQL si nécessaire - et non vers la base de données, mais vers votre propre modèle d'entité.Le code Hibernate JPA et Spring Data JPA est vraiment très bon. Avons-nous besoin de l'extraire du domaine? À mon avis, ce n'est pas ainsi et nécessaire. Très probablement, le code sera encore plus propre si vous laissez ce fragment à l'intérieur du domaine. Alors agissez sur la situation. Si vous créez néanmoins un module de référentiel, alors pour l'organisation des dépendances il vaut mieux utiliser le principe de l'inversion de contrôle de la même manière. Pour ce faire, placez l'interface dans le domaine et implémentez-la dans le module de référentiel. Quant à la logique du référentiel, il est préférable de la transférer vers le domaine. Cela rend le test pratique, car vous pouvez utiliser des objets Mock dans le domaine. Ils vous permettront de tester la logique rapidement et à plusieurs reprises.Traditionnellement, une seule entité est créée pour un référentiel dans un domaine. Ils ne le cassent en morceaux que lorsqu'il devient trop volumineux. N'oubliez pas que les classes doivent être compactes.
Si vous créez néanmoins un module de référentiel, alors pour l'organisation des dépendances il vaut mieux utiliser le principe de l'inversion de contrôle de la même manière. Pour ce faire, placez l'interface dans le domaine et implémentez-la dans le module de référentiel. Quant à la logique du référentiel, il est préférable de la transférer vers le domaine. Cela rend le test pratique, car vous pouvez utiliser des objets Mock dans le domaine. Ils vous permettront de tester la logique rapidement et à plusieurs reprises.Traditionnellement, une seule entité est créée pour un référentiel dans un domaine. Ils ne le cassent en morceaux que lorsqu'il devient trop volumineux. N'oubliez pas que les classes doivent être compactes.API
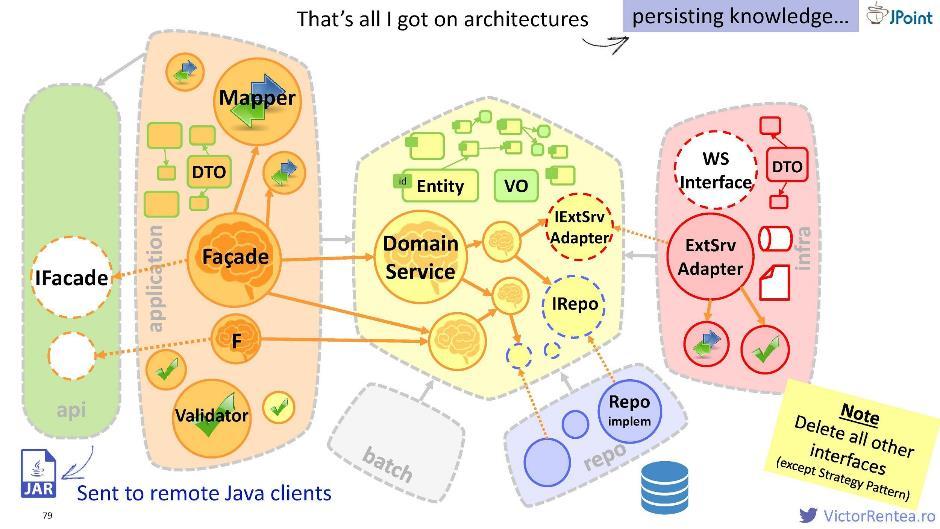 Vous pouvez créer un module séparé, placer l'interface extraite de la façade et les DTO qui en dépendent, puis l'emballer dans un JAR et le transférer vers vos clients Java sous cette forme. Ayant ce dossier, ils pourront envoyer des demandes aux façades.
Vous pouvez créer un module séparé, placer l'interface extraite de la façade et les DTO qui en dépendent, puis l'emballer dans un JAR et le transférer vers vos clients Java sous cette forme. Ayant ce dossier, ils pourront envoyer des demandes aux façades.Ampoule pragmatique
En plus de ceux de nos «ennemis» à qui nous livrons des fonctionnalités, c'est-à-dire des clients, nous avons également des ennemis et, d'autre part, les modules dont nous dépendons nous-mêmes. Nous devons également nous protéger de ces modules. Et pour cela, je vous propose un «oignon» légèrement modifié - en lui toute l'infrastructure est combinée en un module.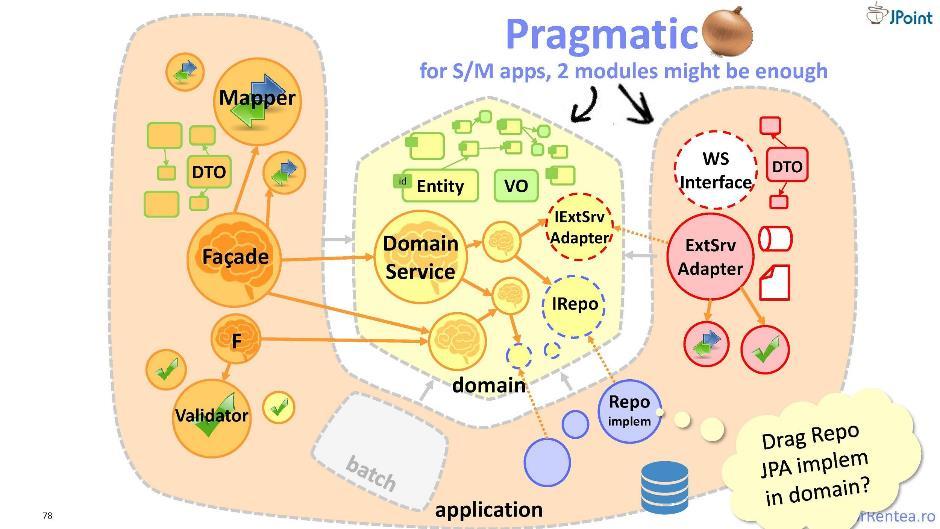 J'appelle cette architecture une «ampoule pragmatique». Ici, la séparation des composants s'effectue selon le principe du «mien» et du «intégrable»: séparément, cela concerne mon domaine, et séparément, cela fait référence à l'intégration avec des collaborateurs externes. Ainsi, seuls deux modules sont obtenus: le domaine et l'application. Une telle architecture est très bonne, mais uniquement lorsque le module d'application est petit. Sinon, vous feriez mieux de revenir à l'oignon traditionnel.
J'appelle cette architecture une «ampoule pragmatique». Ici, la séparation des composants s'effectue selon le principe du «mien» et du «intégrable»: séparément, cela concerne mon domaine, et séparément, cela fait référence à l'intégration avec des collaborateurs externes. Ainsi, seuls deux modules sont obtenus: le domaine et l'application. Une telle architecture est très bonne, mais uniquement lorsque le module d'application est petit. Sinon, vous feriez mieux de revenir à l'oignon traditionnel.Les tests
Comme je l'ai dit plus tôt, si tout le monde a peur de votre candidature, considérez qu'elle a reconstitué les rangs de Legacy.  Mais les tests sont bons. Ils nous donnent un sentiment de confiance qui nous permet de continuer le refactoring. Mais malheureusement, cette confiance peut facilement se révéler injustifiée. Je vais vous expliquer pourquoi. TDD (développement par le biais de tests) suppose que vous êtes à la fois l'auteur du code et l'auteur des cas de test: vous lisez les spécifications, implémentez la fonctionnalité et écrivez immédiatement une suite de tests. Les tests, par exemple, réussiront. Mais que faire si vous avez mal compris les exigences du cahier des charges? Ensuite, les tests ne vérifieront pas ce qui est nécessaire. Votre confiance est donc sans valeur. Et tout cela parce que vous avez écrit du code et des tests seuls.Mais essayez de fermer les yeux sur cela. Des tests sont encore nécessaires, et en tout cas ils nous donnent confiance. Surtout, bien sûr, nous aimons les tests fonctionnels: ils n'impliquent aucun effet secondaire, aucune dépendance - uniquement des données d'entrée et de sortie. Pour tester un domaine, vous devez utiliser des objets fantômes: ils vous permettront de tester des classes isolément.Quant aux requêtes de base de données, les tester est désagréable. Ces tests sont fragiles, ils nécessitent que vous ajoutiez d'abord des données de test à la base de données - et seulement après cela, vous pouvez procéder au test de la fonctionnalité. Mais comme vous le comprenez, ces tests sont également nécessaires, même si vous utilisez JPA.
Mais les tests sont bons. Ils nous donnent un sentiment de confiance qui nous permet de continuer le refactoring. Mais malheureusement, cette confiance peut facilement se révéler injustifiée. Je vais vous expliquer pourquoi. TDD (développement par le biais de tests) suppose que vous êtes à la fois l'auteur du code et l'auteur des cas de test: vous lisez les spécifications, implémentez la fonctionnalité et écrivez immédiatement une suite de tests. Les tests, par exemple, réussiront. Mais que faire si vous avez mal compris les exigences du cahier des charges? Ensuite, les tests ne vérifieront pas ce qui est nécessaire. Votre confiance est donc sans valeur. Et tout cela parce que vous avez écrit du code et des tests seuls.Mais essayez de fermer les yeux sur cela. Des tests sont encore nécessaires, et en tout cas ils nous donnent confiance. Surtout, bien sûr, nous aimons les tests fonctionnels: ils n'impliquent aucun effet secondaire, aucune dépendance - uniquement des données d'entrée et de sortie. Pour tester un domaine, vous devez utiliser des objets fantômes: ils vous permettront de tester des classes isolément.Quant aux requêtes de base de données, les tester est désagréable. Ces tests sont fragiles, ils nécessitent que vous ajoutiez d'abord des données de test à la base de données - et seulement après cela, vous pouvez procéder au test de la fonctionnalité. Mais comme vous le comprenez, ces tests sont également nécessaires, même si vous utilisez JPA.Tests unitaires
 Je dirais que la puissance des tests unitaires n'est pas dans la possibilité de les exécuter, mais dans ce que le processus de leur écriture englobe. Pendant que vous écrivez un test, vous repensez et travaillez sur le code - réduisez la connectivité, divisez-le en classes - en un mot, effectuez le prochain refactoring. Le code testé est du code pur; c'est plus simple, la connectivité y est réduite; en général, il est également documenté (un test unitaire bien écrit décrit parfaitement le fonctionnement de la classe). Il n'est pas surprenant que l'écriture des tests unitaires soit difficile, en particulier les premières pièces.
Je dirais que la puissance des tests unitaires n'est pas dans la possibilité de les exécuter, mais dans ce que le processus de leur écriture englobe. Pendant que vous écrivez un test, vous repensez et travaillez sur le code - réduisez la connectivité, divisez-le en classes - en un mot, effectuez le prochain refactoring. Le code testé est du code pur; c'est plus simple, la connectivité y est réduite; en général, il est également documenté (un test unitaire bien écrit décrit parfaitement le fonctionnement de la classe). Il n'est pas surprenant que l'écriture des tests unitaires soit difficile, en particulier les premières pièces.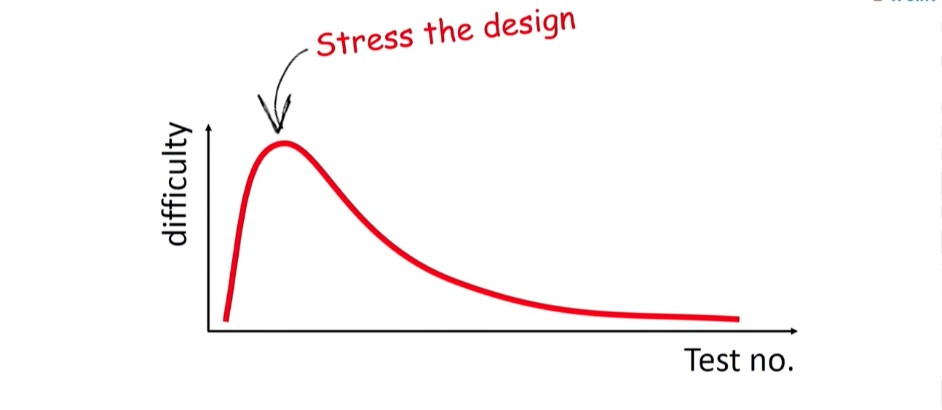 Au stade des premiers tests unitaires, beaucoup de gens ont vraiment peur des perspectives qu'ils doivent vraiment tester quelque chose. Pourquoi sont-ils si durs?Parce que ces tests sont le premier fardeau pour votre classe. Il s'agit du premier coup porté au système, qui montrera peut-être qu'il est fragile et fragile. Mais vous devez comprendre que ces quelques tests sont les plus importants pour votre développement. Ils sont, par essence, vos meilleurs amis, car ils diront tout car il s'agit de la qualité de votre code. Si vous avez peur de cette étape, vous n'irez pas loin. Vous devez exécuter des tests pour votre système. Après cela, la complexité diminuera, les tests seront écrits plus rapidement. En les ajoutant un par un, vous créerez une base de test de régression fiable pour votre système. Et cela est extrêmement important pour le travail futur de vos développeurs. Il leur sera plus facile de refactoriser; Ils comprendront que le système peut être testé en régression à tout moment, c'est pourquoi travailler avec la base de code est sûr. Et, je vous assure, ils s'engageront beaucoup plus volontiers dans la refactorisation.
Au stade des premiers tests unitaires, beaucoup de gens ont vraiment peur des perspectives qu'ils doivent vraiment tester quelque chose. Pourquoi sont-ils si durs?Parce que ces tests sont le premier fardeau pour votre classe. Il s'agit du premier coup porté au système, qui montrera peut-être qu'il est fragile et fragile. Mais vous devez comprendre que ces quelques tests sont les plus importants pour votre développement. Ils sont, par essence, vos meilleurs amis, car ils diront tout car il s'agit de la qualité de votre code. Si vous avez peur de cette étape, vous n'irez pas loin. Vous devez exécuter des tests pour votre système. Après cela, la complexité diminuera, les tests seront écrits plus rapidement. En les ajoutant un par un, vous créerez une base de test de régression fiable pour votre système. Et cela est extrêmement important pour le travail futur de vos développeurs. Il leur sera plus facile de refactoriser; Ils comprendront que le système peut être testé en régression à tout moment, c'est pourquoi travailler avec la base de code est sûr. Et, je vous assure, ils s'engageront beaucoup plus volontiers dans la refactorisation. Mon conseil: si vous sentez que vous avez beaucoup de force et d'énergie aujourd'hui, consacrez-vous à la rédaction de tests unitaires. Et assurez-vous que chacun est propre, rapide, a son propre poids et ne répète pas les autres.
Mon conseil: si vous sentez que vous avez beaucoup de force et d'énergie aujourd'hui, consacrez-vous à la rédaction de tests unitaires. Et assurez-vous que chacun est propre, rapide, a son propre poids et ne répète pas les autres.Astuces
Résumant tout ce qui a été dit aujourd'hui, je voudrais vous avertir avec les conseils suivants:- Restez simple aussi longtemps que possible (et quel qu'en soit le coût) : évitez la «réingénierie» et l'optimisation tardive, ne surchargez pas l'application;
- , , ;
- «» — ;
- , — : ;
- «», , — ;
- N'ayez pas peur des tests : donnez-leur la possibilité de faire tomber votre système, ressentez tous leurs avantages - au final, ce sont vos amis car ils sont capables de signaler honnêtement les problèmes.
En faisant ces choses, vous aiderez votre équipe et vous-même. Et puis, le jour de la livraison du produit, vous serez prêt.Que lire

. JPoint — , 19-20 - Joker 2018 — Java-. . .