Bonjour, Habr. Je m'appelle Vitaliy Kotov, je travaille dans le service d'essais de Badoo. J'écris beaucoup d'autotests d'interface utilisateur, mais je travaille encore plus avec ceux qui l'ont fait il n'y a pas si longtemps et qui n'ont pas encore réussi à marcher sur tous les râteaux.
Donc, après avoir ajouté ma propre expérience et les observations d'autres gars, j'ai décidé de préparer pour vous une collection de "comment écrire des tests ne vaut pas la peine". J'ai pris en charge chaque exemple avec une description détaillée, des exemples de code et des captures d'écran.
L'article sera intéressant pour les auteurs débutants de tests d'interface utilisateur, mais les personnes âgées dans ce sujet apprendront probablement quelque chose de nouveau, ou souriront tout simplement, en se souvenant «dans leur jeunesse». :)
C'est parti!

Table des matières
Localisateurs sans attributs
Commençons par un exemple simple. Puisque nous parlons de tests d'interface utilisateur, les localisateurs y jouent un rôle important. Un localisateur est une ligne composée selon une certaine règle et décrivant un ou plusieurs éléments XML (en particulier HTML).
Il existe plusieurs types de localisateurs. Par exemple, les
localisateurs CSS sont utilisés pour les feuilles de style en cascade.
Les localisateurs XPath sont utilisés pour travailler avec des documents XML. Et ainsi de suite.
Une liste complète des types de localisateurs utilisés par
Selenium peut être trouvée sur
seleniumhq.imtqy.com .
Dans les tests d'interface utilisateur, les localisateurs sont utilisés pour décrire les éléments avec lesquels le pilote doit interagir.
Dans presque n'importe quel inspecteur de navigateur, il est possible de sélectionner l'élément qui nous intéresse et de copier son XPath. Cela ressemble à ceci:
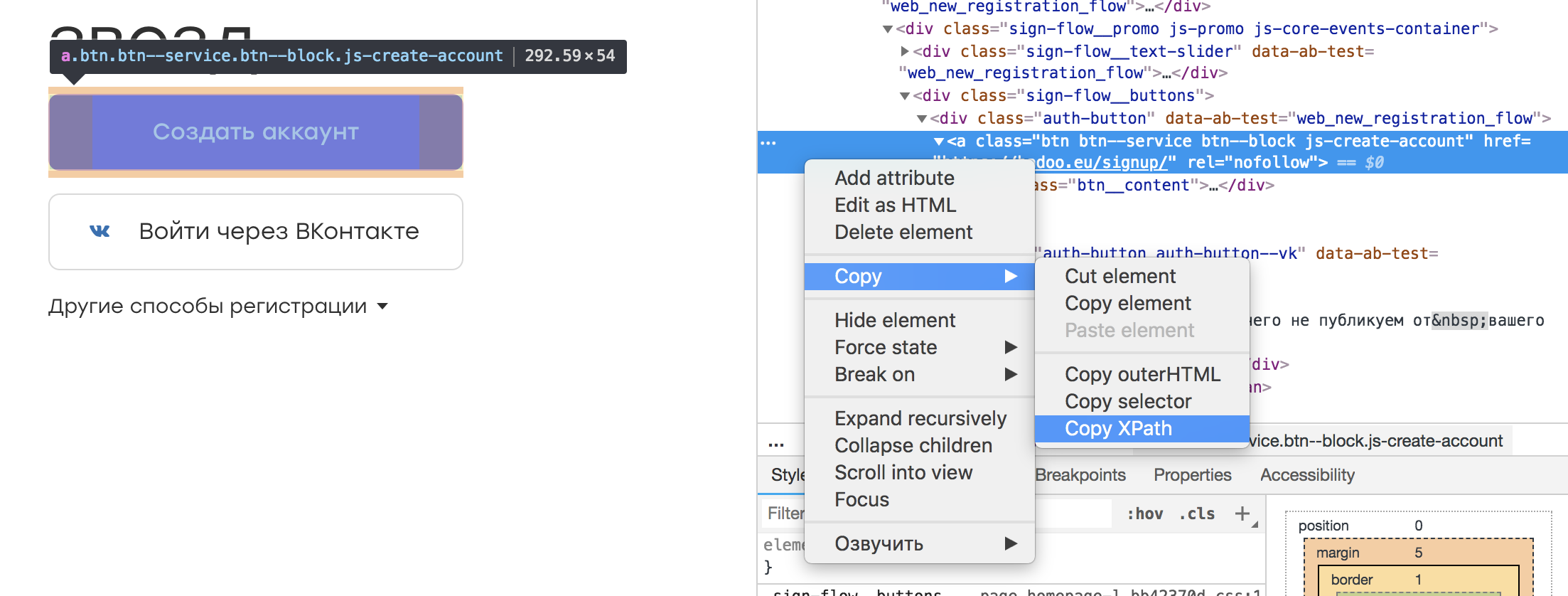
Il s'avère un tel localisateur:
/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a
Il semble qu'il n'y ait rien de mal à un tel localisateur. Après tout, nous pouvons le sauvegarder dans une constante ou un champ de la classe, qui, par son nom, transmettra l'essence de l'élément:
@FindBy(xpath = "/html/body/div[3]/div[1]/div[2]/div/div/div[2]/div[1]/a") public WebElement createAccountButton;
Et enveloppez le texte d'erreur correspondant au cas où l'élément ne serait pas trouvé:
public void waitForCreateAccountButton() { By by = By.xpath(this.createAccountButton); WebDriverWait wait = new WebDriverWait(driver, timeoutInSeconds); wait .withMessage(“Cannot find Create Account button.”) .until( ExpectedConditions.presenceOfElementLocated(by) ); }
Cette approche a un avantage: il n'est pas nécessaire d'apprendre XPath.
Cependant, il existe un certain nombre d'inconvénients. Premièrement, lorsque vous changez la disposition, rien ne garantit que l'élément sur un tel localisateur restera le même. Il est possible qu'un autre prenne sa place, ce qui entraînera des circonstances imprévues. Deuxièmement, la tâche des autotests est de rechercher les bogues et non de surveiller les changements de disposition. Par conséquent, l'ajout d'un wrapper ou d'autres éléments plus haut dans l'arborescence ne devrait pas affecter nos tests. Sinon, il nous faudra beaucoup de temps pour mettre à jour les localisateurs.
Conclusion: vous devez créer des localisateurs qui décrivent correctement l'élément et résistent aux changements de disposition en dehors de la partie testée de notre application. Par exemple, vous pouvez vous lier à un ou plusieurs attributs d'un élément:
//a[@rel=”createAccount”]
Un tel localisateur est plus facile à percevoir dans le code, et il ne se cassera que si "rel" disparaît.
Un autre avantage d'un tel localisateur est la possibilité de rechercher dans le référentiel de modèles avec l'attribut spécifié. Mais que rechercher si le localisateur ressemble à l'exemple d'origine? :)
Si initialement dans l'application, les éléments n'ont pas d'attributs ou s'ils sont définis automatiquement (par exemple, en raison de l'
obscurcissement des classes), cela vaut la peine d'être discuté avec les développeurs. Ils ne devraient pas moins s'intéresser à l'automatisation des tests de produits et vous rencontreront sûrement et vous proposeront une solution.
Vérifier l'élément manquant
Chaque utilisateur Badoo a son propre profil. Il contient des informations sur l'utilisateur: (nom, âge, photos) et des informations sur qui l'utilisateur souhaite discuter. De plus, il est possible d'indiquer vos intérêts.
Supposons que nous ayons eu une fois un bug (bien que, bien sûr, ce ne soit pas le cas :)). L'utilisateur de son profil a choisi ses centres d'intérêt. Ne trouvant pas d'intérêt approprié dans la liste, il a décidé de cliquer sur «Plus» pour mettre à jour la liste.
Comportement attendu: les anciens intérêts devraient disparaître, de nouveaux devraient apparaître. Mais à la place, une «erreur inattendue» est apparue:
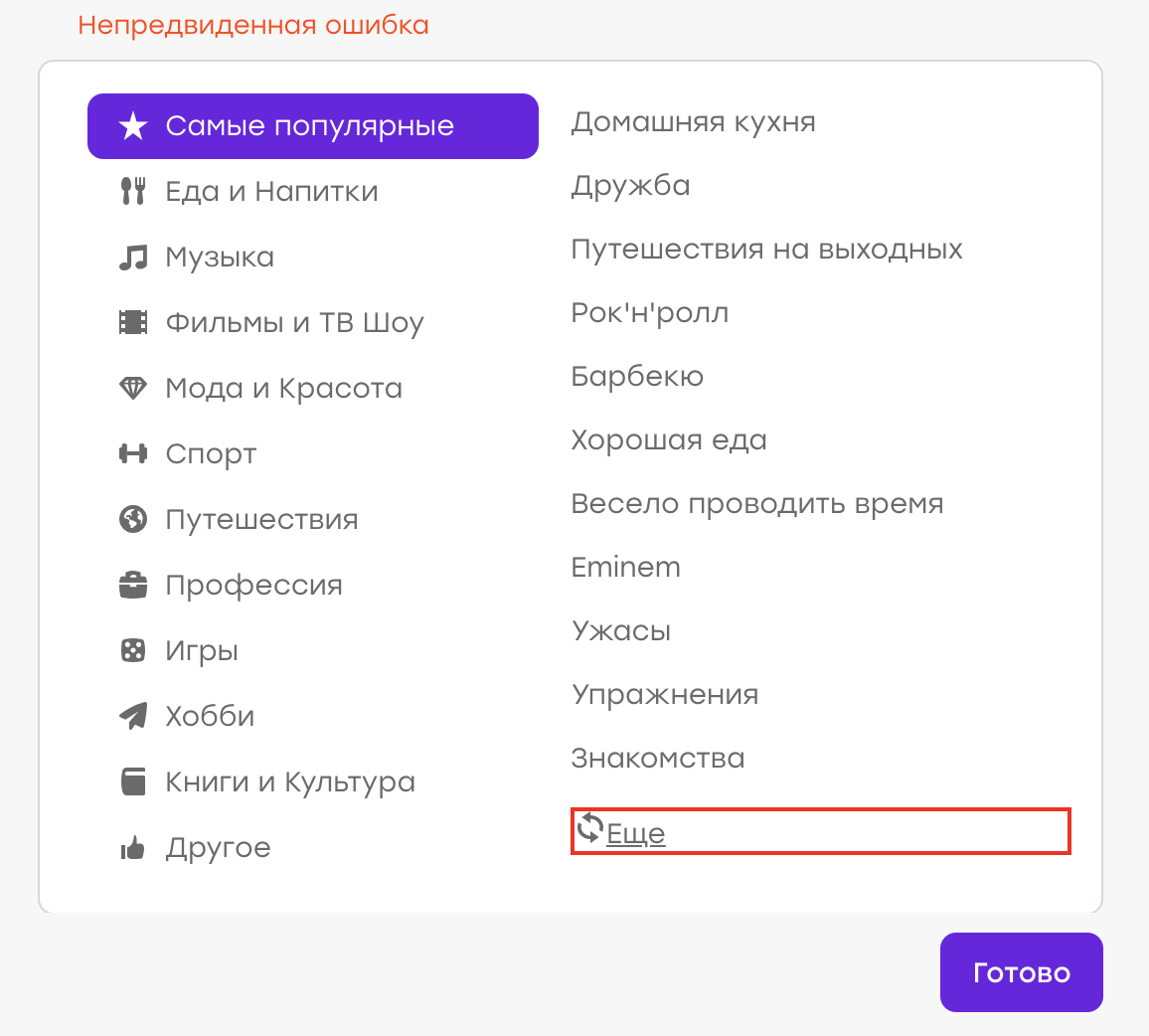
Il s'est avéré qu'il y avait un problème côté serveur, la réponse n'était pas la même et le client a traité ce problème en affichant une notification.
Notre tâche est d'écrire un autotest qui vérifiera ce cas.
Nous écrivons approximativement le script suivant:
- Ouvrir le profil
- Ouvrir la liste des intérêts
- Cliquez sur le bouton "Plus"
- Assurez-vous que l'erreur ne s'est pas produite (par exemple, il n'y a pas d'élément div.error)
Nous effectuons un tel test. Cependant, ce qui suit se produit: après quelques jours / mois / années, le bogue réapparaît, bien que le test ne détecte rien. Pourquoi?
Tout est assez simple: lors de la réussite du test, le localisateur de l'élément par lequel nous avons recherché le texte d'erreur a changé. Il y a eu une refactorisation des modèles et au lieu de la classe "error" nous avons eu la classe "error_new".
Pendant le refactoring, le test a continué de fonctionner comme prévu. L'élément div.error n'apparaissait pas; il n'y avait aucune raison de la chute. Mais maintenant, l'élément "div.error" n'existe plus du tout - par conséquent, le test n'échouera jamais, quoi qu'il arrive dans l'application.
Conclusion: il vaut mieux tester l'opérabilité de l'interface avec des contrôles positifs. Dans notre exemple, nous devons nous attendre à ce que la liste des intérêts ait changé.
Dans certains cas, un test négatif ne peut pas être remplacé par un test positif. Par exemple, lors de l'interaction avec un élément, rien ne se passe dans une «bonne» situation et une erreur apparaît dans une «mauvaise» situation. Dans ce cas, vous devriez trouver un moyen de simuler un «mauvais» scénario et d'y écrire également un autotest. Ainsi, nous vérifions que l'élément d'erreur apparaît dans le cas négatif et surveillons ainsi la pertinence du localisateur.
Rechercher un article
Comment s'assurer que l'interaction de test avec l'interface a réussi et que tout fonctionne? Cela se voit le plus souvent dans les changements survenus dans cette interface.
Prenons un exemple. Vous devez vous assurer que lors de l'envoi d'un message, il apparaît dans le chat:
Le script ressemble à ceci:
- Ouvrir le profil utilisateur
- Ouvrez le chat avec lui
- Rédiger un message
- Soumettre
- Attendez que le message apparaisse.
Nous décrivons un tel scénario dans notre test. Supposons qu'un message de discussion correspond à un localisateur:
p.message_text
Voici comment nous vérifions que l'élément apparaît:
this.waitForPresence(By.css('p.message_text'), "Cannot find sent message.");
Si notre attente fonctionne, alors tout est en ordre: les messages de chat sont dessinés.
Comme vous l'avez peut-être deviné, après un certain temps, l'envoi de messages de discussion est interrompu, mais notre test continue de fonctionner sans interruption. Faisons les choses correctement.
Il s'avère que la veille un nouvel élément est apparu dans le chat: du texte qui invite l'utilisateur à mettre en évidence le message s'il passe soudainement inaperçu:
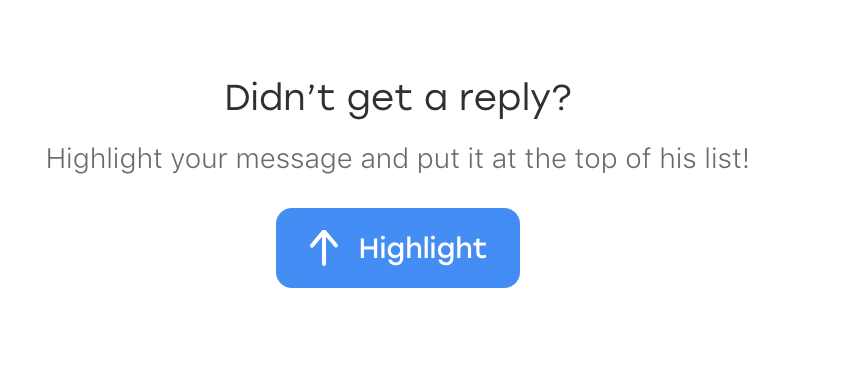
Et, le plus drôle, il relève également de notre localisateur. Seulement, il a une classe supplémentaire qui le distingue des messages envoyés:
p.message_text.highlight
Notre test n'a pas cassé lorsque ce bloc est apparu, mais la case «attendre que le message apparaisse» a cessé d'être pertinente. L'élément qui était un indicateur d'un événement réussi est maintenant toujours là.
Conclusion: si la logique du test est basée sur la vérification de l'apparence d'un élément, il est nécessaire de vérifier qu'il n'y en a pas avant notre interaction avec l'interface utilisateur.
- Ouvrir le profil utilisateur
- Ouvrez le chat avec lui
- Assurez-vous qu'aucun message n'a été envoyé
- Rédiger un message
- Soumettre
- Attendez que le message apparaisse.
Données aléatoires
Très souvent, les tests d'interface utilisateur fonctionnent avec des formulaires dans lesquels ils saisissent des données. Par exemple, nous avons un formulaire d'inscription:
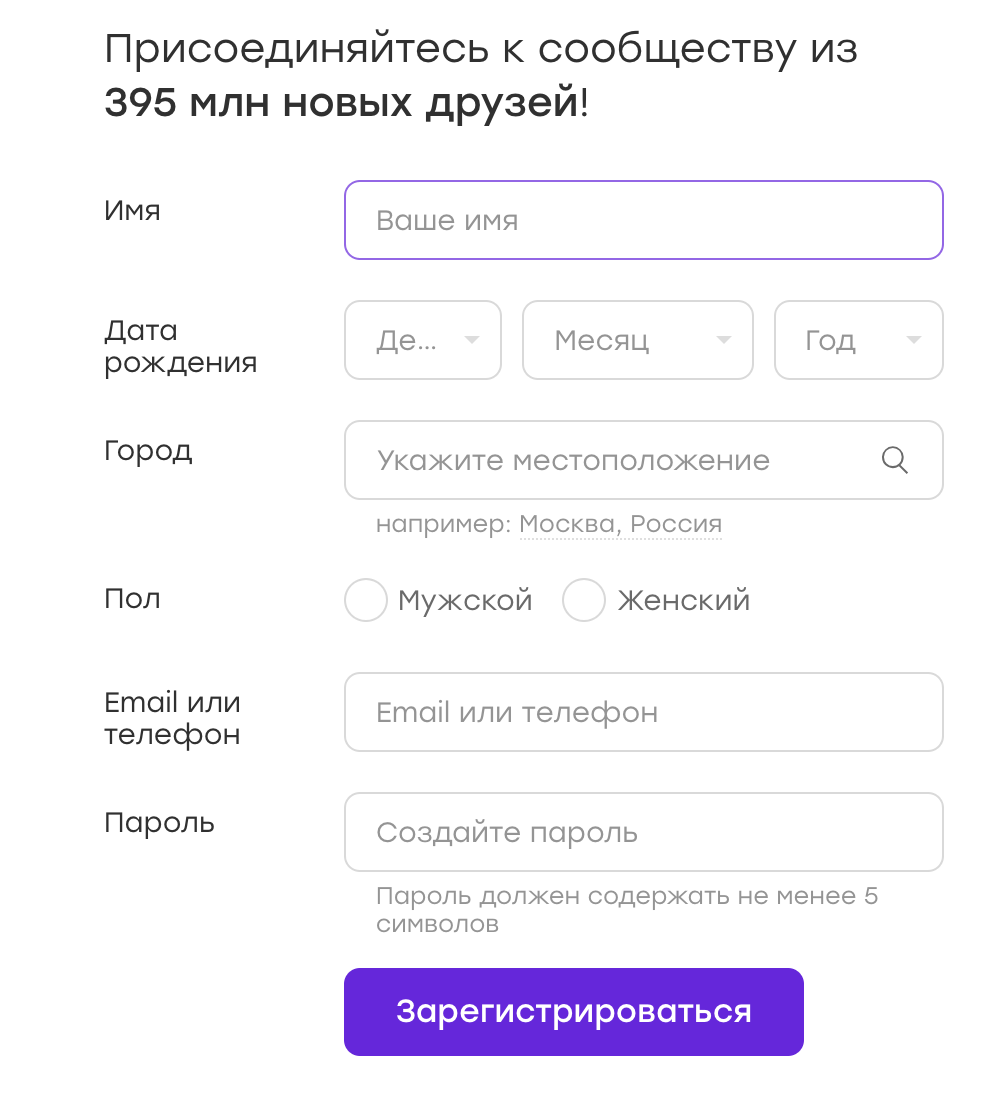
Les données de ces tests peuvent être stockées dans des configurations ou codées en dur dans un test. Mais parfois, la pensée vient à l'esprit: pourquoi ne pas randomiser les données? C'est bien, nous couvrirons plus de cas!
Mon conseil: non. Et maintenant je vais vous dire pourquoi.
Supposons que notre test soit enregistré sur Badoo. Nous décidons de choisir au hasard le sexe de l'utilisateur. Au moment de la rédaction du test, le flux d'inscription pour la fille et pour le garçon n'est pas différent, donc notre test réussit.
Imaginez maintenant qu'après un certain temps, le flux d'enregistrement devient différent. Par exemple, nous donnons à la fille des bonus gratuits immédiatement après l'inscription, à propos desquels nous lui notifions une superposition spéciale.
Dans le test, il n'y a pas de logique pour fermer la superposition, mais cela, à son tour, interfère avec toutes les autres actions prescrites dans le test. Nous obtenons un test qui tombe dans 50% des cas. Tout outil d'automatisation confirmera que les tests d'interface utilisateur ne sont pas intrinsèquement stables par nature. Et c'est normal, il faut vivre avec, en plaçant constamment entre une logique redondante "pour toutes les occasions" (qui gâche sensiblement la lisibilité du code et complique son support) et cette instabilité elle-même.
La prochaine fois, lorsque le test échouera, nous n'aurons peut-être pas le temps de le gérer. Nous venons de le redémarrer et voyons qu'il est passé. Nous décidons que dans notre application tout fonctionne comme il se doit et la chose est un test instable. Et calme-toi.
Passons maintenant. Et si cette superposition se brise? Le test continuera de réussir dans 50% des cas, ce qui retarde considérablement la recherche du problème.
Et c'est bien quand, en raison de la randomisation des données, nous créons une situation "50 par 50". Mais cela se passe différemment. Par exemple, avant de vous inscrire, un mot de passe était considéré comme acceptable sur au moins trois caractères. Nous écrivons du code qui propose un mot de passe aléatoire d'au moins trois caractères (parfois trois caractères et parfois plus). Et puis la règle change - et le mot de passe doit déjà contenir au moins quatre caractères. Quelle est la probabilité d'une chute dans ce cas? Et, si notre test détecte un vrai bug, à quelle vitesse le découvrirons-nous?
Il est particulièrement difficile de travailler avec des tests où de nombreuses données aléatoires sont entrées: nom, sexe, mot de passe, etc. Dans ce cas, il existe également de nombreuses combinaisons différentes, et si une erreur se produit dans l'une d'entre elles, il est généralement difficile de la remarquer.
Conclusion Comme je l'ai écrit ci-dessus, la randomisation des données est mauvaise. Il vaut mieux couvrir plus de cas aux dépens des fournisseurs de données, sans oublier bien sûr les
classes d'équivalence . La réussite des tests prendra plus de temps, mais vous pouvez le combattre. Mais nous serons sûrs que s'il y a un problème, il sera détecté.
Atomicité des tests (partie 1)
Regardons l'exemple suivant. Nous écrivons un test qui vérifie le compteur d'utilisateurs dans le pied de page.

Le scénario est simple:
- Ouvrir l'application
- Trouver le compteur de pied de page
- Assurez-vous qu'il est visible
Nous appelons un tel test testFooterCounter et l'exécutons. Il devient alors nécessaire de vérifier que le compteur n'affiche pas zéro. Nous ajoutons ce test à un test existant, pourquoi pas?
Mais alors il devient nécessaire de vérifier que dans le pied de page il y a un lien vers la description du projet (le lien "A propos de nous"). Ecrire un nouveau test ou ajouter à un test existant? Dans le cas d'un nouveau test, nous devrons relancer l'application, préparer l'utilisateur (si nous vérifions le pied de page sur la page autorisée), se connecter - en général, passer un temps précieux. Dans une telle situation, renommer le test en testFooterCounterAndLinks semble être une bonne idée.
D'une part, cette approche présente des avantages: gain de temps, stockage de tous les chèques d'une partie de notre application (en l'occurrence, le pied de page) en un seul endroit.
Mais il y a un inconvénient notable. Si le test échoue lors du premier test, nous ne vérifierons pas le reste du composant. Supposons qu'un test se bloque dans une branche, non pas à cause de l'instabilité, mais à cause d'un bogue. Que faire Renvoyer une tâche décrivant uniquement ce problème? Ensuite, nous courons le risque d'obtenir une tâche avec un correctif de ce bogue uniquement, exécutons un test et découvrons que le composant est également cassé plus loin, dans un autre endroit. Et il peut y avoir de nombreuses itérations de ce type. Dans ce cas, donner un coup de pied dans les deux sens prendra beaucoup de temps et sera inefficace.
Conclusion: si possible, atomisez les chèques. Dans ce cas, même en cas de problème dans un cas, nous vérifierons tous les autres. Et, si vous devez retourner le billet, nous pouvons immédiatement décrire tous les problèmes.
Atomicité des tests (partie 2)
Prenons un autre exemple. Nous écrivons un test de chat qui vérifie la logique suivante. Si les utilisateurs ont une sympathie mutuelle, le promoblock suivant apparaît dans le chat:

Le scénario est le suivant:
- Voter par l'utilisateur A pour l'utilisateur B
- Voter par l'utilisateur B pour l'utilisateur A
- Utilisateur A chat ouvert avec l'utilisateur B
- Confirmez que l'unité est en place
Pendant un certain temps, le test fonctionne avec succès, mais ensuite ce qui se passe ... Non, cette fois, le test ne manque aucun bug. :)
Après un certain temps, nous découvrons qu'il existe un autre bug non lié à notre test: si vous ouvrez un chat, fermez-le immédiatement et rouvrez-le, le bloc disparaît. Ce n'est pas le cas le plus évident, et dans le test, nous ne l'avons bien sûr pas prévu. Mais nous décidons que nous devons également le couvrir.
La même question se pose: écrire un autre test ou insérer un test dans un test existant? En écrire un nouveau semble inapproprié, car dans 99% des cas, il fera de même que l'existant. Et nous décidons d'ajouter le test au test qui existe déjà:
- Voter par l'utilisateur A pour l'utilisateur B
- Voter par l'utilisateur B pour l'utilisateur A
- Utilisateur A chat ouvert avec l'utilisateur B
- Confirmez que l'unité est en place
- Fermer le chat
- Ouvrir le chat
- Confirmez que l'unité est en place
Un problème peut survenir lorsque, par exemple, nous refactorisons un test après une longue période. Par exemple, une refonte se produira sur un projet - et vous devrez réécrire de nombreux tests.
Nous allons ouvrir le test et essayer de nous souvenir de ce qu'il vérifie. Par exemple, un test est appelé testPromoAfterMutualAttraction. Comprenons-nous pourquoi l'ouverture et la fermeture du chat sont écrites à la fin? Probablement pas. Surtout si ce test n'a pas été écrit par nous. Allons-nous laisser cette pièce? Peut-être que oui, mais s'il y a des problèmes avec lui, il est probable que nous le supprimerons simplement. Et la vérification sera perdue simplement parce que sa signification ne sera pas évidente.
Je vois deux solutions ici. Premièrement: faites toujours le deuxième test et appelez-le testCheckBlockPresentAfterOpenAndCloseChat. Avec un tel nom, il sera clair que nous ne faisons pas seulement un certain ensemble d'actions, mais faisons un contrôle très conscient, car il y a eu une expérience négative. La deuxième solution consiste à écrire un commentaire détaillé dans le code expliquant pourquoi nous effectuons ce test dans ce test particulier. Il est également conseillé d'indiquer le numéro de bug dans le commentaire.
Erreur en cliquant sur un élément existant
L'exemple suivant
m'a lancé
bbidox , pour lequel il est un gros plus en karma!
Il y a une situation très intéressante où le code de test devient déjà ... un framework. Supposons que nous ayons une méthode comme celle-ci:
public void clickSomeButton() { WebElement button_element = this.waitForButtonToAppear(); button_element.click(); }
À un moment donné, quelque chose d'étrange commence à arriver à cette méthode: le test se bloque lorsque vous essayez de cliquer sur un bouton. Nous ouvrons la capture d'écran prise au moment où le test s'est écrasé, et nous voyons qu'il y a un bouton dans la capture d'écran et que la méthode waitForButtonToAppear a fonctionné avec succès. Question: quel est le problème avec le clic?
Le plus dur dans cette situation est que le test peut parfois réussir. :)
Faisons les choses correctement. Supposons que le bouton considéré dans l'exemple se trouve sur une telle superposition:
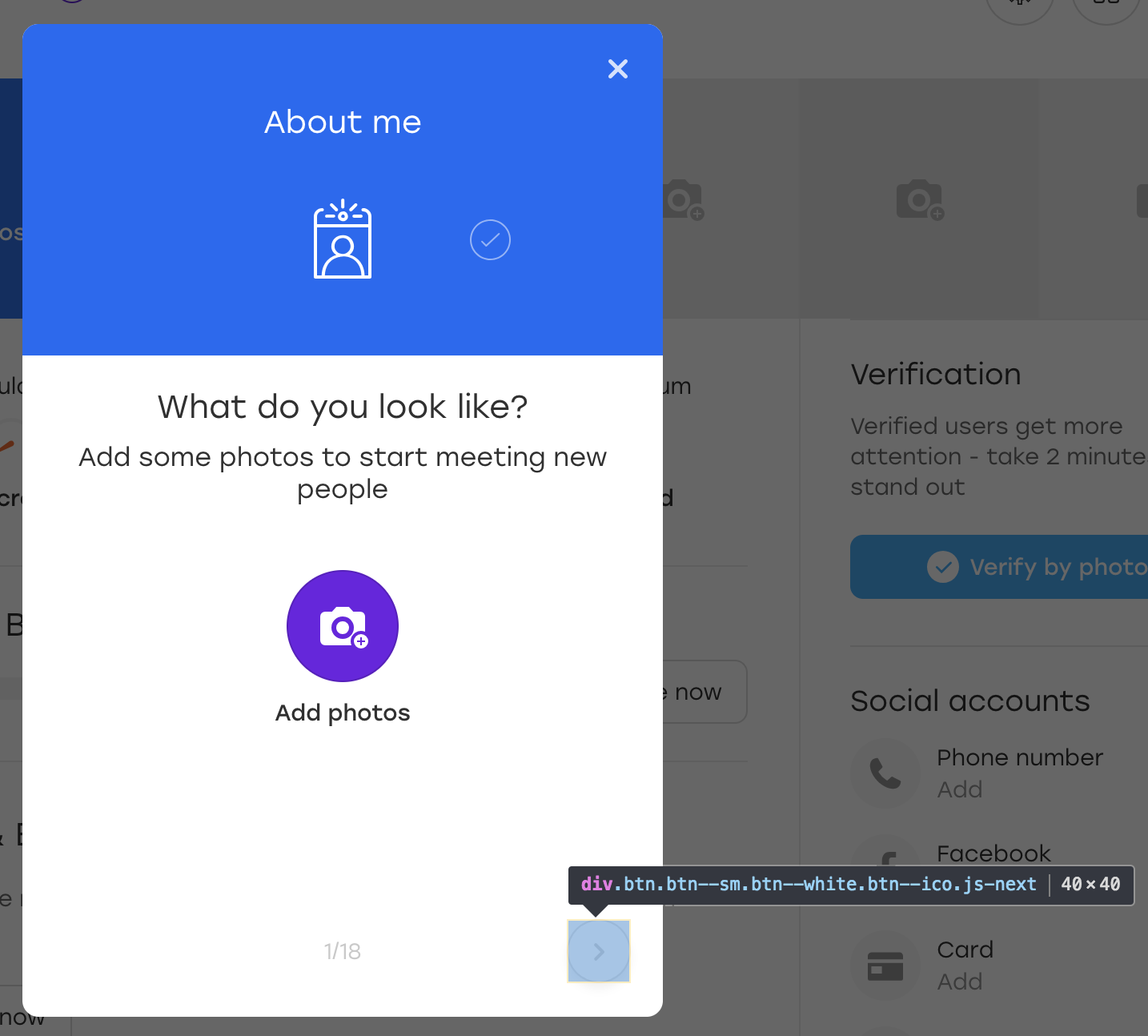
Il s'agit d'une superposition spéciale à travers laquelle un utilisateur de notre site Web peut remplir des informations sur lui-même. Lorsque vous cliquez sur le bouton de superposition en surbrillance, le bloc suivant apparaît à remplir.
Pour le plaisir, ajoutons une classe OLOLO supplémentaire pour ce bouton:
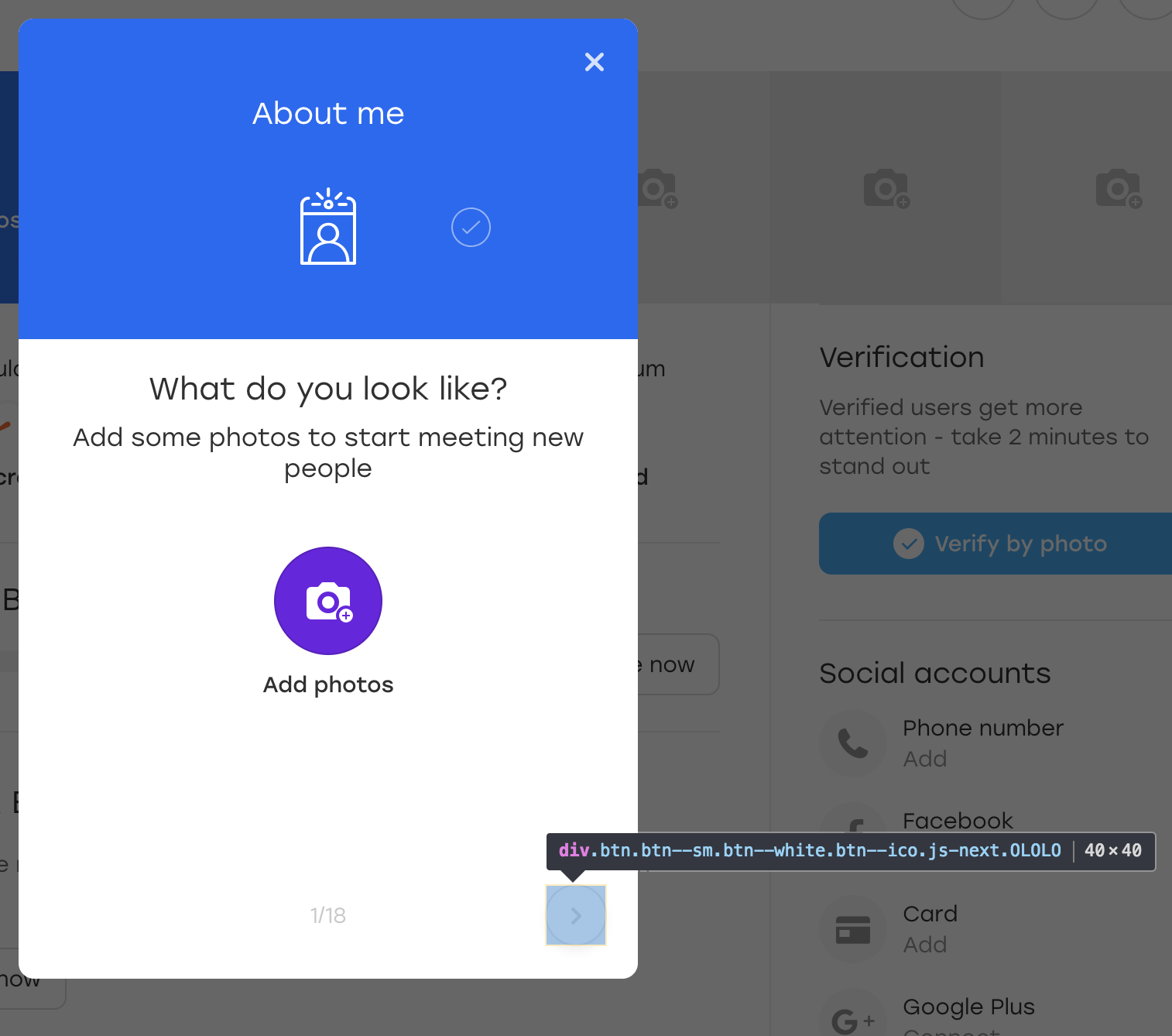
Après quoi, nous cliquons sur ce bouton. Visuellement, rien n'a changé, mais le bouton lui-même est resté en place:
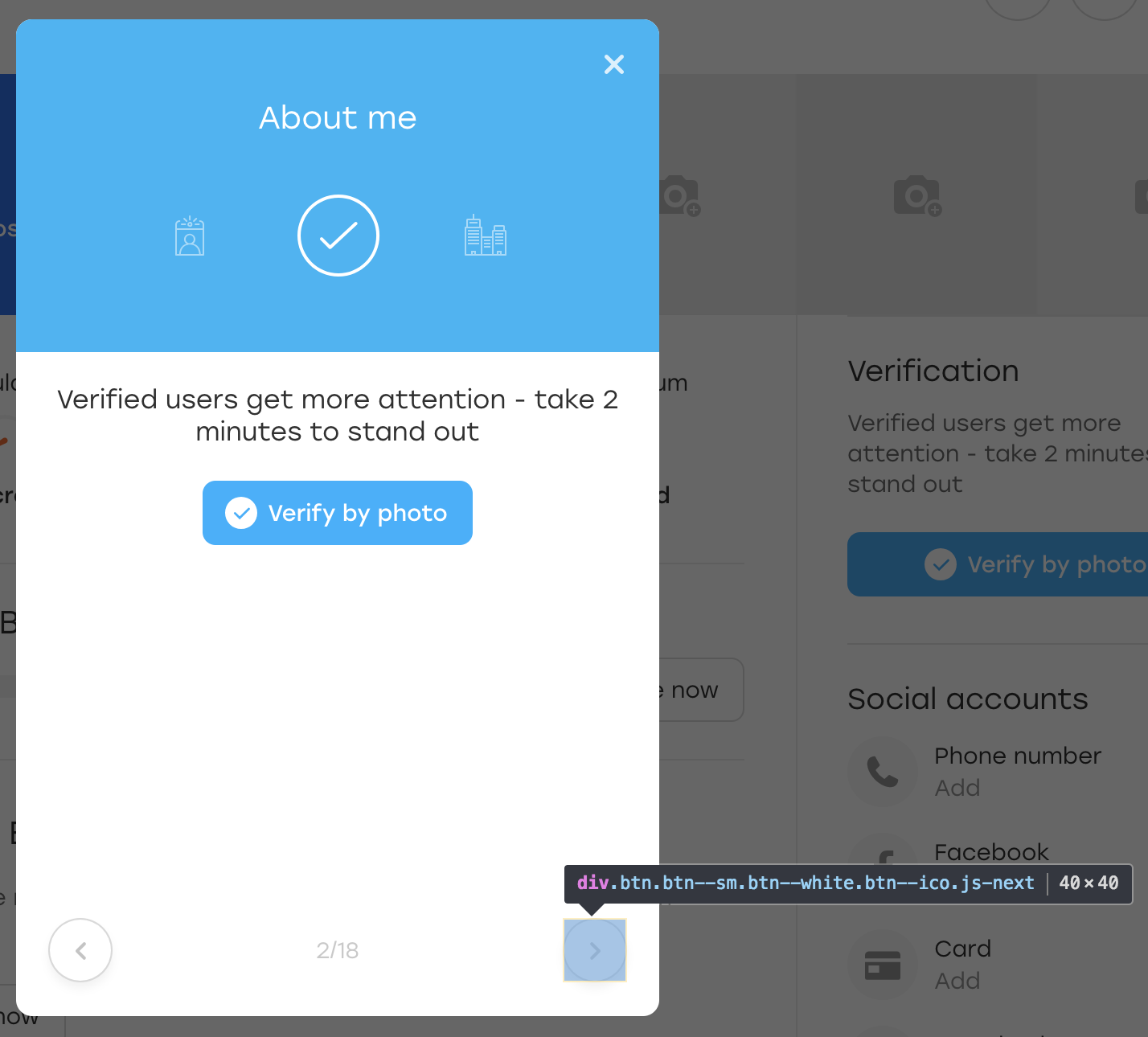
Que s'est-il passé? En fait, lorsque JS a redessiné le bloc pour nous, il a également redessiné le bouton. Il est toujours disponible sur le même localisateur, mais c'est un autre bouton. Cela est démontré par le manque de la classe OLOLO que nous avons ajoutée.
Dans le code ci-dessus, nous stockons l'élément dans la variable $ element. Si un élément est régénéré pendant ce temps, il peut ne pas être visible visuellement, mais vous ne pouvez plus cliquer dessus - la méthode click () échouera.
Il existe plusieurs solutions:
- Wrap click dans le bloc try et dans l'élément catch rebuild
- Ajouter un bouton à un attribut pour signaler qu'il a changé
Texte d'erreur
Enfin, un point simple, mais non moins important.
Cet exemple s'applique non seulement aux tests d'interface utilisateur, mais se produit également très souvent dans ceux-ci. Habituellement, lorsque vous écrivez un test, vous êtes dans le contexte de ce qui se passe: vous décrivez la vérification après la vérification et comprenez leur signification. Et vous écrivez des textes d'erreur dans le même contexte:
WebElement element = this.waitForPresence(By.css("a.link"), "Cannot find button");
Qu'est-ce qui pourrait être incompréhensible dans ce code? Le test s'attend à l'apparition d'un bouton et, s'il n'est pas là, tombe naturellement.
Imaginez maintenant que l'auteur du test soit en arrêt maladie et que son collègue s'occupe des tests. Et puis il abandonne le test testQuestionsOnProfile et écrit ce message: «Bouton introuvable». Un collègue doit comprendre ce qui se passe le plus rapidement possible, car la sortie arrive bientôt.
Que devra-t-il faire?
Il est inutile d'ouvrir la page sur laquelle le test est tombé et de vérifier le localisateur "a.link" - il n'y a aucun élément. Par conséquent, vous devez étudier attentivement le test et déterminer ce qu'il vérifie.
Ce serait beaucoup plus simple avec un texte d'erreur plus détaillé: «Impossible de trouver le bouton d'envoi sur la superposition de questions». Avec une telle erreur, vous pouvez immédiatement ouvrir la superposition et voir où le bouton est allé.
Sortie deux. Tout d'abord, il vaut la peine de transmettre le texte d'erreur à n'importe quelle méthode de votre framework de test, en plus, un paramètre obligatoire pour qu'il n'y ait pas de tentation de l'oublier. Deuxièmement, le texte d'erreur doit être détaillé. Cela ne signifie pas toujours que cela devrait être long, il suffit de préciser ce qui a mal tourné dans le test.
Comment comprendre que le texte d'erreur est bien écrit? Très simple. Imaginez que votre application soit en panne et que vous deviez aller voir les développeurs et expliquer quoi et où s'est cassé. Si vous leur dites seulement ce qui est écrit dans le texte d'erreur, comprendront-ils?
Résumé
La rédaction d'un script de test est souvent une activité intéressante. Dans le même temps, nous poursuivons de nombreux objectifs. Nos tests doivent:
- couvrir autant de cas que possible
- travailler aussi vite que possible
- être compris
- élargir
- facile à entretenir
- commander une pizza
- et ainsi de suite ...
Il est particulièrement intéressant de travailler avec des tests dans un projet en constante évolution, où ils doivent être constamment mis à jour: ajouter quelque chose et couper quelque chose. C'est pourquoi il vaut la peine de réfléchir à l'avance sur certains points et de ne pas toujours se précipiter avec les décisions. :)
J'espère que mes conseils vous aideront à éviter certains problèmes et vous rendront plus réfléchi dans les études de cas. Si le public aime l'article, je vais essayer de collecter des exemples plus ennuyeux. En attendant - au revoir!