Il y a une semaine ou deux, j'ai vu un
message sur le forum des
utilisateurs de RabbitMQ expliquant comment configurer l'envoi de messages de SQL Server à RabbitMQ. Puisque nous travaillons en étroite collaboration avec
Derivco , j'ai laissé quelques suggestions là-bas et j'ai également dit que j'écrivais un blog sur la façon de procéder. Une partie de mon message n'était pas entièrement vraie - du moins jusqu'à ce moment (désolé, Bro, il était très occupé).
Chose géniale, c'est votre
SQL Server . Son utilisation est très simple pour mettre des informations dans une base de données. La récupération des données d'une base de données à l'aide d'une requête est tout aussi simple. Mais obtenir les données juste mises à jour ou collées est déjà un peu plus difficile. Pensez aux événements en temps réel; un achat est effectué - quelqu'un doit en être informé dès que cela se produit. Peut-être que quelqu'un dira que ces données ne doivent pas être extraites de la base de données, mais ailleurs. Bien sûr, c'est le cas, mais bien souvent, nous n'avons tout simplement pas le choix.
Nous avions une tâche: envoyer des événements de la base de données à l'extérieur pour un traitement ultérieur, et la question était - comment faire cela?
SQL Server et communications externes
Au cours de l'existence de SQL Server, plusieurs tentatives ont été organisées pour organiser les communications en dehors de la base de données;
SQL Server Notification Services (NS), qui est apparu dans SQL Server 2000, et plus tard, dans SQL Server 2005,
SQL Server Service Broker (SSB) est apparu. Je les ai décrits dans mon livre
A First Look at SQL Server 2005 for Developers , avec Bob Boshemen et Dan Sullivan. NS est apparu dans SQL Server 2000, comme je l'ai dit, et a été repensé dans la version bêta de SQL Server 2005. Cependant, NS a été
complètement exclu de la version prête à la vente (RTM) de SQL Server 2005.
Remarque: Si vous lisez le livre, vous y trouverez un certain nombre de fonctionnalités qui n'étaient pas dans la version RTM.
SSB a survécu et Microsoft a introduit
Service Broker External Activator (EA) dans son pack de fonctionnalités SQL Server 2008. Il permet via la SSB d'interagir en dehors de la base de données locale. Théoriquement, cela sonne bien, mais dans la pratique - c'est lourd et déroutant. Nous avons fait quelques tests et avons rapidement réalisé qu'il ne faisait pas ce dont nous avions besoin. De plus, SSB ne nous a pas donné les performances nécessaires, nous avons donc dû inventer autre chose.
SQLCLR
Ce à quoi nous sommes parvenus était basé sur la technologie SQLCLR. SQLCLR est une plate-forme .NET qui est intégrée au noyau SQL Server et peut être utilisée pour exécuter du code .NET à l'intérieur du noyau. Puisque nous exécutons du code .NET, nous pouvons presque tout faire comme dans une application .NET standard.
Remarque: j'ai écrit «presque» ci-dessus, car il y a en fait quelques limitations. Dans ce contexte, ces restrictions n'ont presque aucun effet sur ce que nous allons faire.
Le principe de fonctionnement de SQLCLR est le suivant: le code est compilé dans une bibliothèque dll, puis cette bibliothèque est enregistrée à l'aide des outils SQL Server:
Build Assembly
CREATE ASSEMBLY [RabbitMQ.SqlServer] AUTHORIZATION rmq FROM 'F:\some_path\RabbitMQSqlClr4.dll' WITH PERMISSION_SET = UNSAFE; GO
Extrait de code 1: création d'un assemblage le long d'un chemin absolu
Le code effectue les actions suivantes:
CREATE ASSEMBLY - Crée un assemblage avec le nom donné (quel qu'il soit).AUTHORIZATION - Indique le propriétaire de l'assemblage. Dans ce cas, rmq est un rôle SQL Server prédéfini.FROM - Détermine l'emplacement de l'assemblage d'origine. Dans la FROM , vous pouvez également spécifier le chemin au format binaire ou UNC. Les fichiers d'installation de ce projet utilisent une représentation binaire.WITH PERMISSION_SET - Définit les autorisations. UNSAFE est le moins strict et est requis dans ce cas.
Remarque: indépendamment du rôle ou de la connexion utilisés dans la clause AUTHORIZATION, la classe appdomain doit être créée avec le même nom que lors du chargement de l'assembly dans le domaine. Il est recommandé de séparer les assemblys avec des noms différents de classes de domaine d'application afin que lorsqu'un assemblage échoue, les autres ne tombent pas. Cependant, si les assemblages dépendent les uns des autres, ils ne peuvent pas être divisés en différentes classes.
Lorsque l'assembly est créé, nous y faisons des wrappers de méthodes .NET:
CREATE PROCEDURE rmq.pr_clr_PostRabbitMsg @EndpointID int, @Message nvarchar(max) AS EXTERNAL NAME [RabbitMQ.SqlServer].[RabbitMQSqlClr.RabbitMQSqlServer].[pr_clr_PostRabbitMsg]; GO
Extrait de code 2: wrapper de méthode .NET
Le code effectue les actions suivantes:
- Crée une procédure stockée T-SQL nommée
rmq.pr_clr_PostRabbitMsg qui prend deux paramètres; @EndpointID et @Message . - Au lieu du corps de la procédure, une source externe est utilisée, qui se compose de:
- Un assembly nommé
RabbitMQ.SqlServer , c'est-à-dire l'agrégat que nous avons créé ci-dessus dans l' extrait de code 1 . - Type complet (espace de noms et classe):
RabbitMQSqlClr.RabbitMQSqlServer - La méthode de l'espace de noms et de la classe ci-dessus est:
pr_clr_PostRabbitMsg .
Lorsque
rmq.pr_clr_PostRabbitMsg , la méthode
pr_clr_PostRabbitMsg sera appelée.
Remarque: lors de la création d'une procédure, le nom de l'assembly n'est pas sensible à la casse, contrairement au nom complet du type et de la méthode. Il n'est pas nécessaire que le nom de la procédure en cours de création corresponde au nom de la méthode. Cependant, les types de données finaux pour les paramètres doivent correspondre.
Comme je l'ai dit plus tôt, chez Derivco, nous devons envoyer des données en dehors de SQL Server, nous utilisons donc SQLCLR et
RabbitMQ (RMQ).
Rabbitmq
RMQ est un courtier de messages open source qui implémente le protocole AMQP (Advanced Message Queuing Protocol) et est écrit en Erlang.
Étant donné que RMQ est un courtier de messages, les bibliothèques clientes AMQP sont requises pour s'y connecter. L'application fait référence aux bibliothèques clientes et, avec leur aide, ouvre une connexion et envoie des messages - comme, par exemple, il y a un appel via ADO.NET à SQL Server. Mais contrairement à ADO.NET, où, très probablement, la connexion s'ouvre à chaque fois que vous accédez à la base de données, ici, la connexion reste ouverte pour toute la période de l'application.
Ainsi, afin de pouvoir interagir à partir de la base de données avec RabbitMQ, nous avons besoin de l'application et de la bibliothèque cliente .NET pour RabbitMQ.
Remarque: dans la prochaine partie de cet article, des fragments de code RabbitMQ seront trouvés, mais sans explication détaillée de ce qu'ils font. Si vous débutez avec RabbitMQ, je vous suggère de consulter les différents didacticiels RabbitMQ pour comprendre le but du code. Le tutoriel Hello World C # est un bon début. L'une des différences entre les manuels et les exemples de code est que les échangeurs ne sont pas déclarés dans les exemples. Ils sont censés être prédéfinis.
RabbitMQ.SqlServer
RabbitMQ.SqlServer est un assemblage utilisant la bibliothèque cliente .NET pour RabbitMQ et offre la possibilité d'envoyer des messages de la base de données à un ou plusieurs points de terminaison RabbitMQ (VHosts et échangeurs). Le code peut être téléchargé / forké depuis mon référentiel
RabbitMQ-SqlServer sur GitHub. Il contient les sources d'assemblage et les fichiers d'installation (c'est-à-dire que vous n'avez pas à les compiler vous-même).
Remarque: ce n'est qu'un exemple pour montrer comment SQL Server peut interagir avec RabbitMQ. Ce n'est PAS un produit fini ou même une partie de celui-ci. Si ce code vous brise le cerveau - ne me blâmez pas, car ce n'est qu'un exemple.
Fonctionnalité
Lorsque l'assembly est chargé, ou lorsque son initialisation est explicitement appelée, ou lorsqu'elle est appelée indirectement, au moment de l'appel de la procédure wrapper, l'assembly charge la chaîne de connexion dans la base de données locale dans laquelle il a été installé, ainsi que les points de terminaison RabbitMQ auxquels il se connecte:
Connexion
internal bool InternalConnect() { try { connFactory = new ConnectionFactory(); connFactory.Uri = connString; connFactory.AutomaticRecoveryEnabled = true; connFactory.TopologyRecoveryEnabled = true; RabbitConn = connFactory.CreateConnection(); for (int x = 0; x < channels; x++) { var ch = RabbitConn.CreateModel(); rabbitChannels.Push(ch); } return true; } catch(Exception ex) { return false; } }
Extrait de code 3: connexion au point de terminaison
Dans le même temps, une partie de la connexion au point de terminaison crée également des IModels sur la connexion, et ils sont utilisés lors de l'envoi (ajout à la file d'attente) de messages:
Envoi de message
internal bool Post(string exchange, byte[] msg, string topic) { IModel value = null; int channelTryCount = 0; try { while ((!rabbitChannels.TryPop(out value)) && channelTryCount < 100) { channelTryCount += 1; Thread.Sleep(50); } if (channelTryCount == 100) { var errMsg = $"Channel pool blocked when trying to post message to Exchange: {exchange}."; throw new ApplicationException(errMsg); } value.BasicPublish(exchange, topic, false, null, msg); rabbitChannels.Push(value); return true; } catch (Exception ex) { if (value != null) { _rabbitChannels.Push(value); } throw; } }
La méthode
Post est appelée à partir de la méthode
pr_clr_PostRabbitMsg(int endPointId, string msgToPost) , qui a été présentée comme une procédure utilisant la clause
CREATE PROCEDURE dans le fragment de code 2:
Méthode post-appel
public static void pr_clr_PostRabbitMsg(int endPointId, string msgToPost) { try { if(endPointId == 0) { throw new ApplicationException("EndpointId cannot be 0"); } if (!isInitialised) { pr_clr_InitialiseRabbitMq(); } var msg = Encoding.UTF8.GetBytes(msgToPost); if (endPointId == -1) { foreach (var rep in remoteEndpoints) { var exch = rep.Value.Exchange; var topic = rep.Value.RoutingKey; foreach (var pub in rabbitPublishers.Values) { pub.Post(exch, msg, topic); } } } else { RabbitPublisher pub; if (rabbitPublishers.TryGetValue(endPointId, out pub)) { pub.Post(remoteEndpoints[endPointId].Exchange, msg, remoteEndpoints[endPointId].RoutingKey); } else { throw new ApplicationException($"EndpointId: {endPointId}, does not exist"); } } } catch { throw; } }
Extrait de code 5: représentation d'une méthode en tant que procédure
Lorsque la méthode est exécutée, il est supposé que l'appelant envoie l'identifiant du point d'extrémité auquel le message doit être transmis, et, en fait, le message lui-même. Si la valeur -1 est transmise comme identifiant du point de terminaison, nous itérons sur tous les points et envoyons un message à chacun d'eux. Le message se présente sous la forme d'une chaîne à partir de laquelle nous obtenons des octets à l'aide d'
Encoding.UTF8.GetBytes . Dans un environnement de production, l'appel
Encoding.UTF8.GetBytes doit être remplacé par la sérialisation.
L'installation
Pour installer et exécuter l'exemple, vous avez besoin de tous les fichiers du dossier
src\SQL . Pour installer, procédez comme suit:
- Exécutez le script
01.create_database_and_role.sql . Il créera:
- Base de données de test
RabbitMQTest où l'assembly sera créé. - rôle
rmq à affecter en tant que propriétaire de l'assembly - , qui sera également appelé
rmq . Dans ce diagramme, divers objets de base de données sont créés.
- Exécutez le fichier
02.create_database_objects.sql . Il créera:
- la table
rmq.tb_RabbitSetting , qui stockera la chaîne de connexion dans la base de données locale. - La table
rmq.tb_RabbitEndpoint , dans laquelle un ou plusieurs points de terminaison RabbitMQ seront stockés.
- Dans le fichier
03.create_localhost_connstring.sql remplacez la valeur de la variable @connString par la chaîne de connexion correcte pour la base de données RabbitMQTest créée à l'étape 1 et exécutez le script.
Avant de continuer, vous devez avoir une instance en cours d'exécution du courtier RabbitMQ et de VHost (par défaut, VHost est représenté par /). En règle générale, nous avons plusieurs VHost, juste pour l'isolement. Cet hôte a également besoin d'un échangeur, dans l'exemple que nous utilisons
amq.topic . Lorsque votre courtier RabbitMQ est prêt, modifiez les
rmq.pr_UpsertRabbitEndpoint procédure
rmq.pr_UpsertRabbitEndpoint , qui se trouve dans le fichier
04.upsert_rabbit_endpoint.sql :
Endpoint RabbitMQ
EXEC rmq.pr_UpsertRabbitEndpoint @Alias = 'rabbitEp1', @ServerName = 'RabbitServer', @Port = 5672, @VHost = 'testHost', @LoginName = 'rabbitAdmin', @LoginPassword = 'some_secret_password', @Exchange = 'amq.topic', @RoutingKey = '#', @ConnectionChannels = 5, @IsEnabled = 1
Extrait de code 6: création d'un point de terminaison dans RabbitMQ
À ce stade, il est temps de déployer des assemblys. Il existe des différences dans les options de déploiement pour les versions de SQL Server antérieures à SQL Server 2014 (2005, 2008, 2008R2, 2012) et pour 2014 et ultérieur. La différence réside dans la version prise en charge du CLR. Avant SQL Server 2014, la plate-forme .NET fonctionnait dans la version 2 du CLR et dans SQL Server 2014 et versions ultérieures, la version 4 était utilisée.
SQL Server 2005 - 2012
Commençons par les versions de SQL Server qui s'exécutent sur CLR 2, car elles ont leurs propres caractéristiques. Nous devons déployer l'assembly créé et déployer en même temps la bibliothèque .NET du client
RabbitMQ.Client (
RabbitMQ.Client ). De notre assemblage, nous ferons référence à la bibliothèque client RabbitMQ. Parce que Puisque nous prévoyons d'utiliser CLR 2, notre assemblage et
RabbitMQ.Client devraient être compilés sur la base de .NET 3.5. Il y a des problèmes.
Toutes les dernières versions de la bibliothèque
RabbitMQ.Client sont compilées pour l'environnement CLR 4, elles ne peuvent donc pas être utilisées dans notre assemblage. La dernière version des bibliothèques clientes pour CLR 2 est compilée sur .NET 3.4.3. Mais même si nous essayons de déployer cet assembly, nous obtenons un message d'erreur:
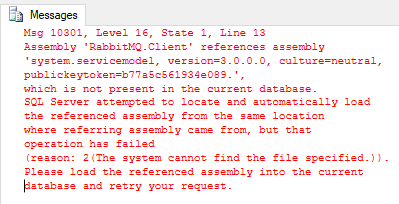 Figure 1: assemblage System.ServiceModel manquant
Figure 1: assemblage System.ServiceModel manquantCette version de
RabbitMQ.Client fait référence à un assembly qui ne fait pas partie du CLR SQL Server. Il s'agit d'un assembly WCF, et c'est l'une des limitations de SQLCLR que j'ai mentionnées ci-dessus: cet assembly particulier est destiné aux types de tâches qui ne peuvent pas être exécutées dans SQL Server. Les versions récentes de
RabbitMQ.Client n'ont pas ces dépendances, elles peuvent donc être utilisées sans aucun problème, à l'exception des exigences gênantes du CLR 4. Que dois-je faire?
Comme vous le savez, RabbitMQ est open source, mais nous sommes des développeurs, non? ;) Alors recompilons! Dans la version antérieure aux dernières versions (c'est-à-dire la version <3.5.0) de
RabbitMQ.Client j'ai supprimé les liens vers
System.ServiceModel et recompilé. J'ai dû modifier quelques lignes de code à l'aide de la fonctionnalité
System.ServiceModel , mais il s'agissait de modifications mineures.
Dans cet exemple, je n'ai pas utilisé la version client 3.4.3, mais j'ai pris la
version stable 3.6.6 et recompilé à l'aide de .NET 3.5 (CLR 2). Cela a presque fonctionné :), sauf que les versions ultérieures de
RabbitMQ.Client utilisent
Task 'et qui ne font pas partie à l'origine de .NET 3.5.
Heureusement, il existe une version de
System.Threading.dll pour .NET 3.5 qui inclut la
Task . Je l'ai téléchargé, mis en place les liens et tout s'est passé! Ici, l'astuce principale est que
System.Threading.dll doit être installé avec l'assembly.
Remarque: la source de RabbitMQ.Client , à partir de laquelle j'ai compilé une version de .NET 3.5, se trouve dans mon référentiel sur GitHub RabbitMQ Client 3.6.6 .NET 3.5 . Le fichier binaire DLL avec System.Threading.dll pour .NET 3.5 se trouve également dans le lib\NET3.5 référentiel (RabbitMQ-SqlServer) .
Pour installer les assemblys nécessaires (
System.Threading ,
RabbitMQ.Client et
RabbitMQ.SqlServer ), exécutez les scripts d'installation à partir du répertoire
src\sql dans l'ordre suivant:
05.51.System.Threading.sql2k5-12.sql - System.Threading05.52.RabbitMQ.Client.sql2k5-12.sql - RabbitMQ.Client05.53.RabbitMQ.SqlServer.sql2k5-12.sql - RabbitMQ.SqlServer
SQL Server 2014+
Dans SQL Server 2014 et versions ultérieures, l'assembly se compile sous .NET 4.XX (mon exemple est sur 4.5.2), et vous pouvez référencer n'importe laquelle des dernières versions de
RabbitMQ.Client , qui peuvent être obtenues à l'aide de
NuGet . Dans mon exemple, j'utilise 4.1.1.
RabbitMQ.Client , qui se trouve également dans le
lib\NET4 référentiel (RabbitMQ-SqlServer) .
Pour installer, exécutez les scripts à partir du répertoire
src\sql dans l'ordre suivant:
05.141.RabbitMQ.Client.sql2k14+.sql - RabbitMQ.Client05.142.RabbitMQ.SqlServer.sql2k14+.sql - RabbitMQ.SqlServer
Wrappers de méthode SQL
Pour créer des procédures qui seront utilisées à partir de notre assembly (3.5 ou 4), exécutez le script
06.create_sqlclr_procedures.sql . Il créera des procédures T-SQL pour trois méthodes .NET:
rmq.pr_clr_InitialiseRabbitMq appelle pr_clr_InitialiseRabbitMq . Utilisé pour charger et initialiser l'assembly RabbitMQ.SqlServer.rmq.pr_clr_ReloadRabbitEndpoints appelle pr_clr_ReloadRabbitEndpoints . Charge différents points de terminaison RabbitMQ.rmq.pr_clr_PostRabbitMsg appelle pr_clr_PostRabbitMsg . Utilisé pour envoyer des messages à RabbitMQ.
Le script crée également une procédure T-SQL simple -
rmq.pr_PostRabbitMsg , qui s'applique à
rmq.pr_clr_PostRabbitMsg . Il s'agit d'une procédure d'encapsulation qui sait quoi faire avec les données, gère les exceptions, etc. Dans un environnement de production, nous avons plusieurs procédures similaires qui traitent différents types de messages. En savoir plus à ce sujet ci-dessous.
Utiliser
De tout ce qui précède, il est clair que pour envoyer des messages à RabbitMQ, nous appelons
rmq.pr_PostRabbitMsg ou
rmq.pr_clr_PostRabbitMsg , en transmettant dans les paramètres l'identifiant du point de terminaison et le message lui-même sous forme de chaîne. Tout cela, bien sûr, est cool, mais j'aimerais voir comment cela fonctionnera en réalité.
Ce que nous faisons dans les environnements de production, c'est que dans les procédures stockées qui traitent les données qui doivent être envoyées à RabbitMQ, nous collectons les données à envoyer et dans le bloc de connexion, nous appelons une procédure comme
rmq.pr_PostRabbitMsg . Voici un exemple très simplifié d'une telle procédure:
Procédure de traitement des données
ALTER PROCEDURE dbo.pr_SomeProcessingStuff @id int AS BEGIN SET NOCOUNT ON; BEGIN TRY
Dans le
fragment de code 7, nous voyons comment les données nécessaires sont capturées et traitées dans la procédure et envoyées après le traitement. Pour utiliser cette procédure, exécutez le script
07.create_processing_procedure.sql partir du répertoire
src\SQL .
Courons tout
À ce stade, vous devez être prêt à envoyer des messages. Avant de tester, assurez-vous que des files d'attente dans RabbitMQ sont attachées à l'échangeur de noeud final dans
rmq.tb_RabbitEndpoint .
Donc, pour commencer, vous devez faire ce qui suit:
Ouvrez le fichier
99.test_send_message.sql .
Exécuter
EXEC rmq.pr_clr_InitialiseRabbitMq;
pour initialiser l'assemblage et charger les points de terminaison RabbitMQ. Cela n'est pas obligatoire, mais il est recommandé de précharger l'assemblage après sa création ou sa modification.
Exécuter
EXEC dbo.pr_SomeProcessingStuff @id = 101
(vous pouvez utiliser tout autre identifiant que vous aimez).
Si tout a fonctionné sans erreur, un message devrait apparaître dans la file d'attente RabbitMQ! Vous avez donc utilisé SQLCLR pour envoyer un message à RabbitMQ.
Félicitations!