Il est temps de reconstituer la tirelire de bons rapports en langue russe sur l'apprentissage automatique! La tirelire elle-même ne sera pas réapprovisionnée!
Cette fois, nous allons
découvrir l’ histoire fascinante d’
Andrei Boyarov sur la reconnaissance des scènes. Andrey est un chercheur en vision par ordinateur engagé dans la vision industrielle chez Mail.Ru Group.
La reconnaissance de scènes est l'un des domaines les plus utilisés de la vision industrielle. Cette tâche est plus compliquée que la reconnaissance étudiée des objets: la scène est un concept plus complexe et moins formalisé, il est plus difficile de distinguer les traits. La reconnaissance des sites découle de la reconnaissance des scènes: vous devez mettre en évidence les endroits connus sur la photo, en garantissant un faible niveau de faux positifs.
Il s'agit de
30 minutes de vidéo de la conférence Smart Data 2017. La vidéo est pratique à regarder à la maison et en déplacement. Pour ceux qui ne sont pas prêts à s'asseoir autant à l'écran, ou qui préfèrent percevoir les informations sous forme de texte, nous appliquons un décryptage de texte intégral, conçu sous la forme d'habrosta.
Je fais de la vision industrielle sur Mail.ru. Aujourd'hui, je vais parler de la façon dont nous utilisons l'apprentissage en profondeur pour reconnaître les images de scènes et d'attractions.
La société a ressenti le besoin de baliser et de rechercher par les images des utilisateurs, et pour cela nous avons décidé de créer notre propre API de vision par ordinateur, dont une partie sera un outil de balisage de scène. Grâce à cet outil, nous voulons obtenir quelque chose comme celui montré dans l'image ci-dessous: l'utilisateur fait une demande, par exemple, "cathédrale", et reçoit toutes ses photos avec des cathédrales.
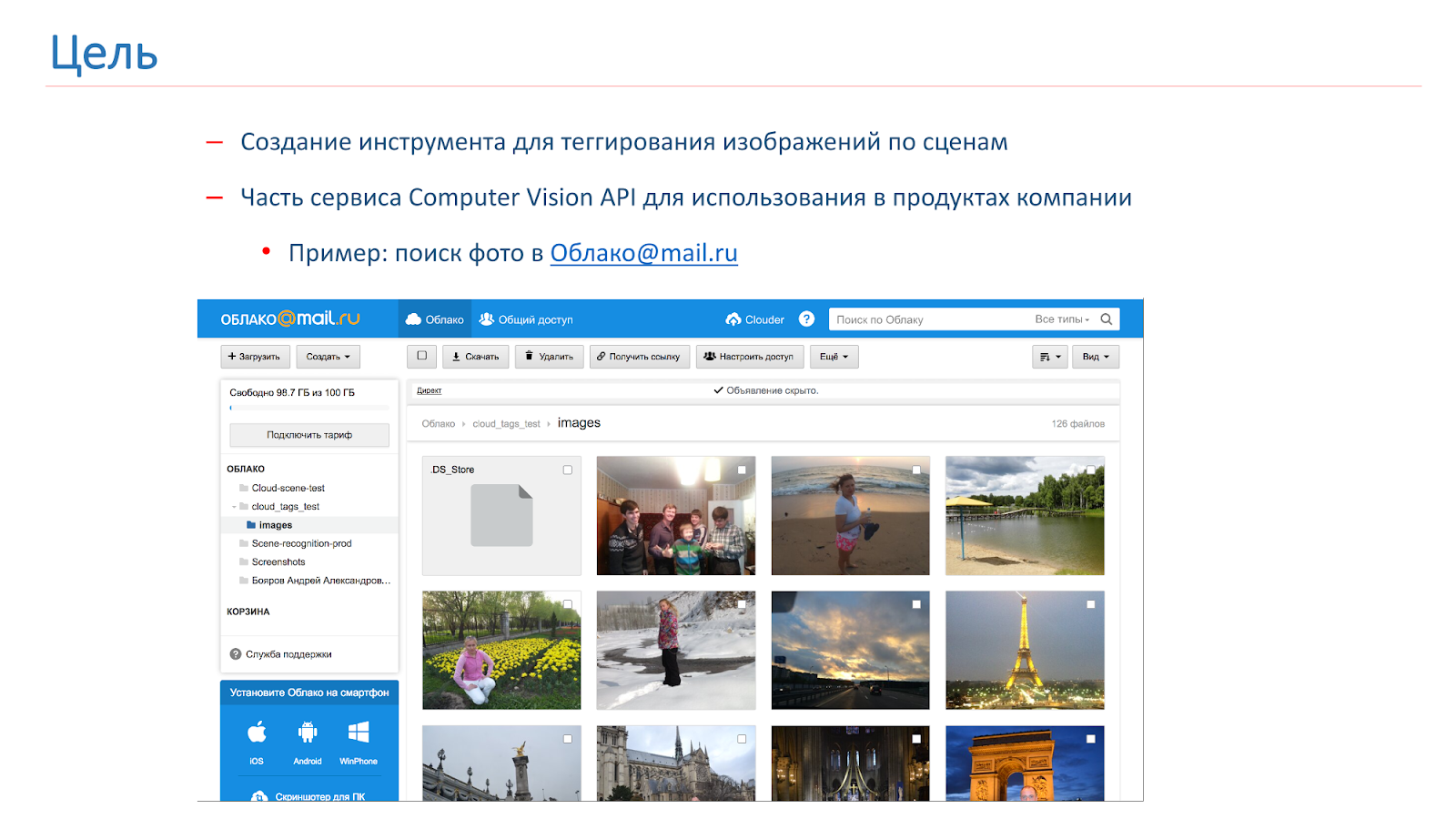
Dans Computer Vision-community, le sujet de la reconnaissance d'objets dans les images a été assez bien étudié. Il existe un
concours ImageNet bien connu qui se déroule depuis plusieurs années et dont la partie principale est la reconnaissance d'objets.
Nous devons essentiellement localiser un objet et le classer. Avec les scènes, la tâche est un peu plus compliquée, car la scène est un objet plus complexe, elle se compose d'un grand nombre d'autres objets et du contexte qui les unit, les tâches sont donc différentes.

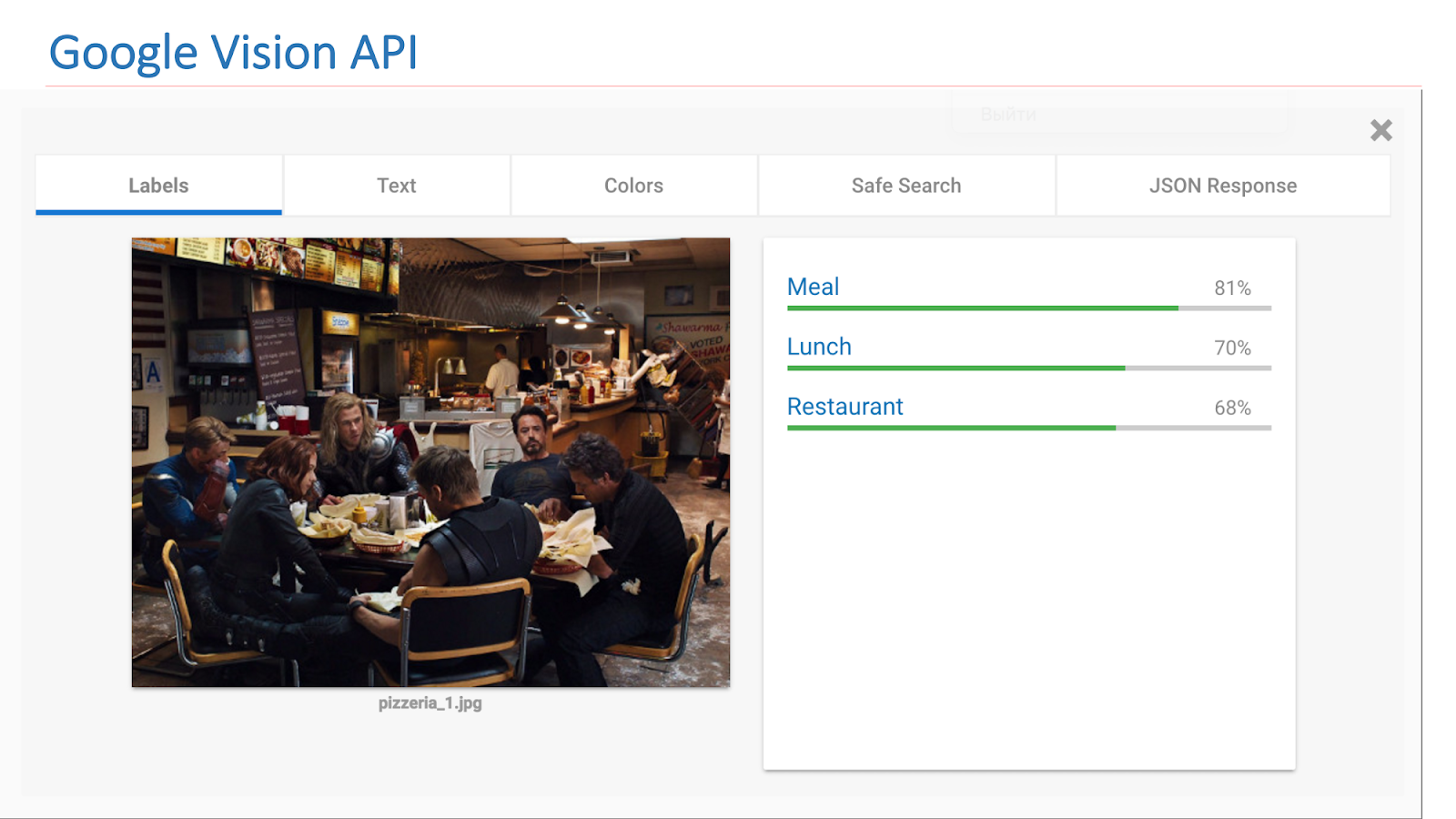
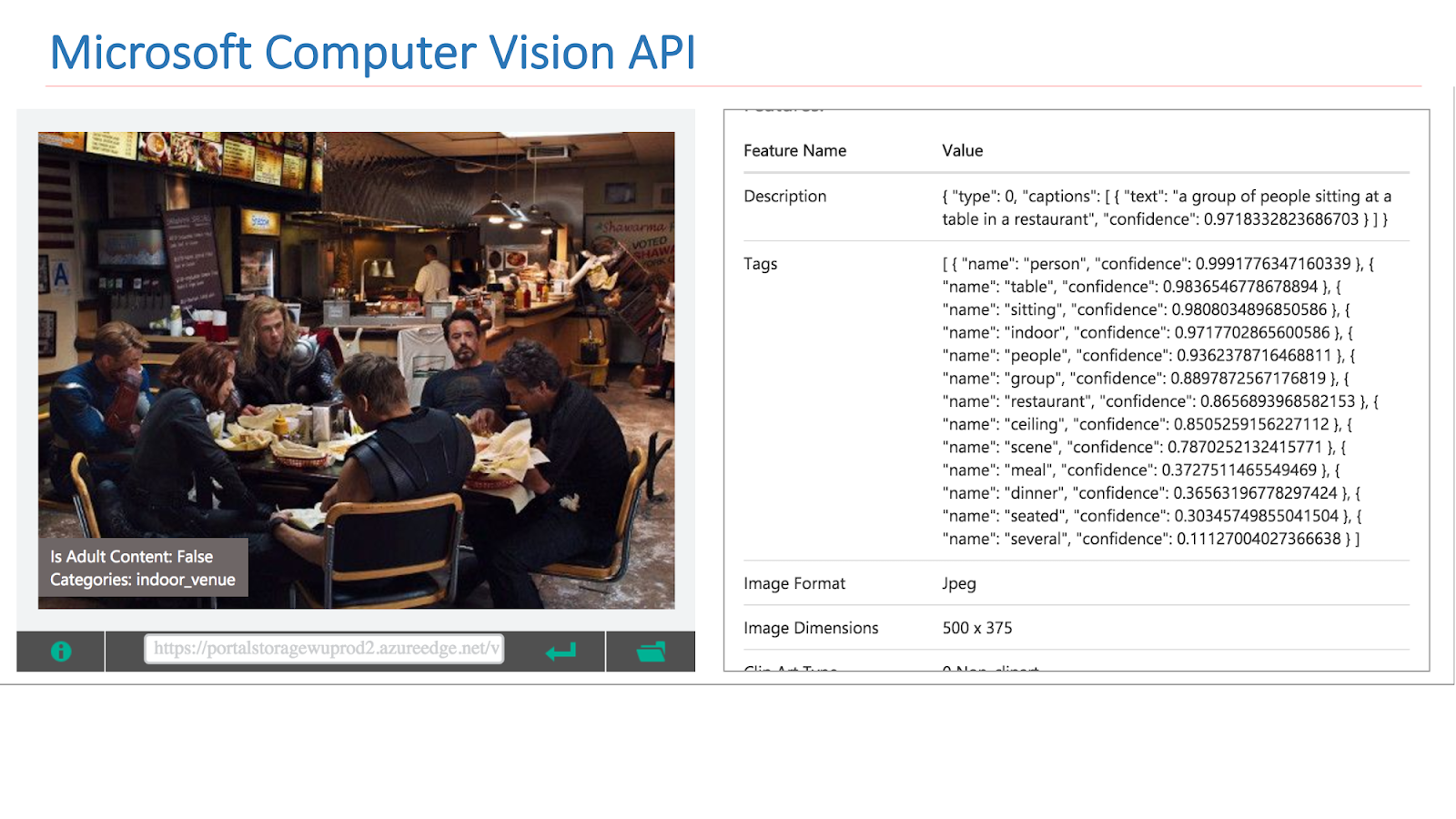
Sur Internet, il existe des services disponibles d'autres sociétés qui mettent en œuvre une telle fonctionnalité. Il s'agit en particulier de l'API Google Vision ou de l'API Microsoft Computer Vision, qui peut trouver des scènes dans des images.
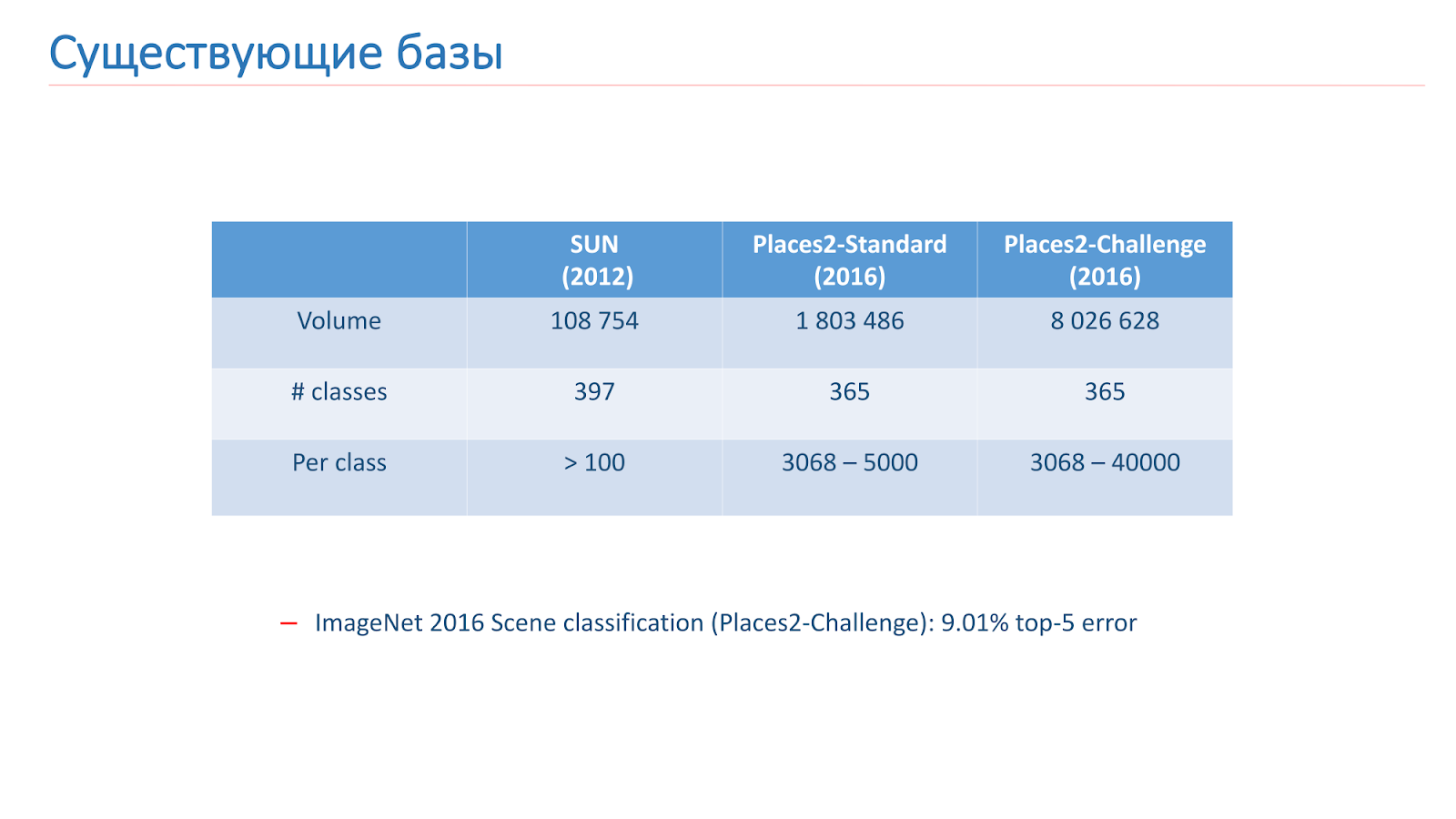
Nous avons résolu ce problème à l'aide de l'apprentissage automatique, nous avons donc besoin de données. Il existe maintenant deux bases principales pour la reconnaissance de scènes en libre accès. Le premier d'entre eux est apparu en 2013 - il s'agit de
la base SUN de l'Université de Princeton. Cette base comprend des centaines de milliers d'images et 397 classes.
La deuxième base sur laquelle nous nous sommes formés est
la base Places2 du MIT. Elle est apparue en 2013 en deux versions. Le premier est Places2-Standart, une base plus équilibrée avec 1,8 million d'images et 365 classes. La deuxième option - Places2-Challenge, contient huit millions d'images et 365 classes, mais le nombre d'images entre les classes n'est pas équilibré. Dans le concours ImageNet 2016, la section Reconnaissance de scène comprenait le Places2-Challenge, et le gagnant a montré le meilleur résultat d'
erreur de classement dans le Top 5 d'environ 9%.
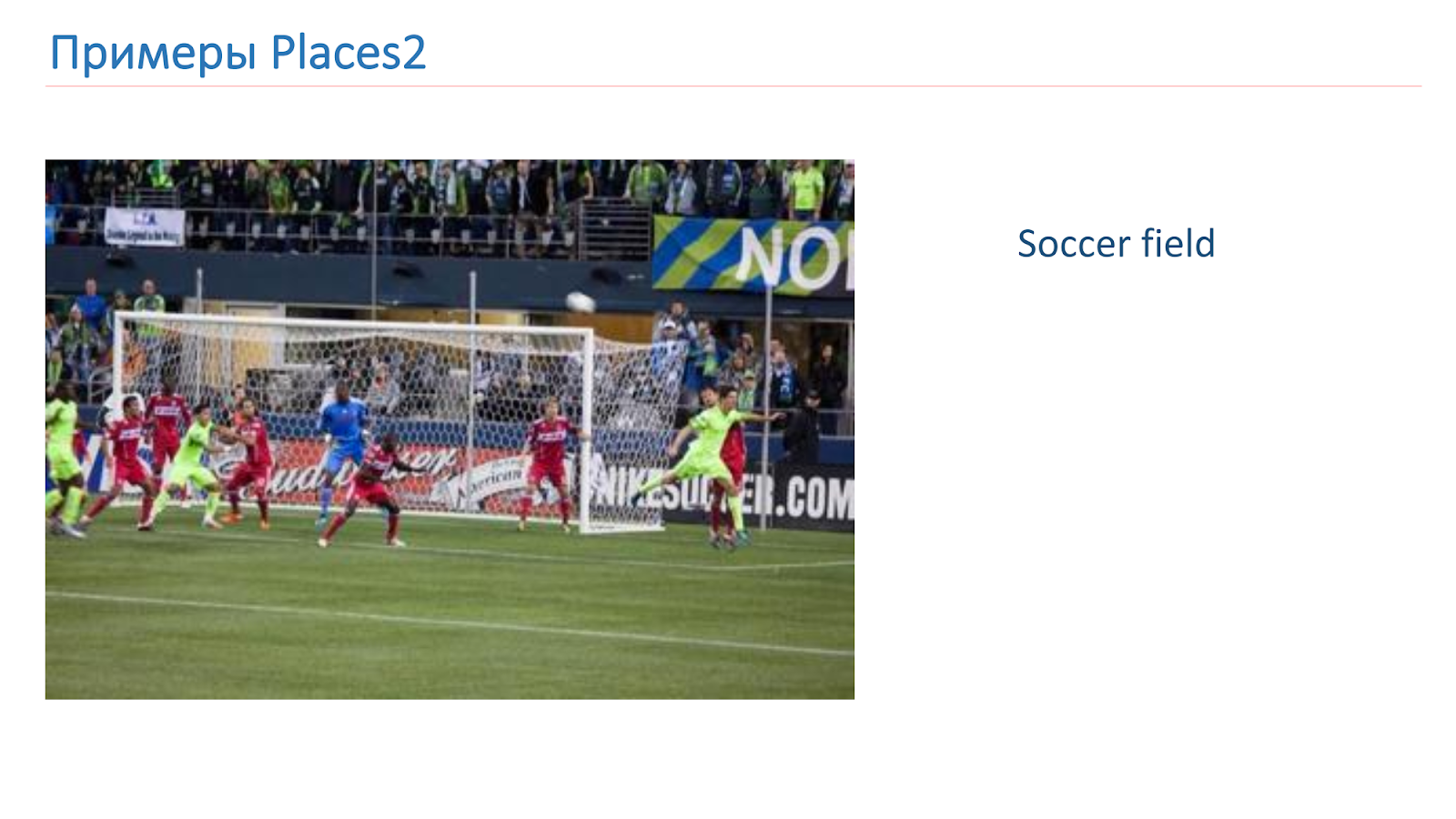
Nous nous sommes entraînés sur la base de Places2. Voici un exemple d'image à partir de là: c'est un canyon, une piste, une cuisine, un terrain de football. Ce sont des objets complexes complètement différents sur lesquels nous devons apprendre à reconnaître.

Avant d'étudier, nous avons adapté les bases que nous devons adapter à nos besoins. Il existe une astuce pour la reconnaissance d'objets lorsque vous expérimentez avec des modèles sur de petites bases CIFAR-10 et CIFAR-100 au lieu d'ImageNet, et ce n'est qu'alors que les meilleurs s'entraînent sur ImageNet.
Nous avons décidé de suivre le même chemin, avons pris la base de données SUN, l'avons réduite, obtenu 89 classes, 50 000 images dans le train et 10 000 images lors de la validation. En conséquence, avant de nous entraîner sur Places2, nous avons mis en place des expériences et testé nos modèles basés sur SUN. La formation ne prend que 6 à 10 heures, contrairement à plusieurs jours sur Places2, ce qui a permis de mener beaucoup plus d'expériences et de le rendre plus efficace.
Nous avons également examiné la base de données Places2 elle-même et réalisé que nous n'avions pas besoin de certaines classes. Soit pour des raisons de production, soit parce qu'il y a trop peu de données à leur sujet, nous supprimons des classes comme, par exemple, un aqueduc, une cabane dans les arbres, une porte de grange.

En conséquence, après toutes les manipulations, nous avons obtenu la base de données Places2, qui contient 314 classes et un demi-million d'images (dans sa version standard), dans la version Challenge environ 7,5 millions d'images. Nous avons construit la formation sur ces bases.
De plus, lors de la visualisation des classes restantes, nous avons découvert qu'il y en avait trop pour la production, elles sont trop détaillées. Et pour cela, nous avons appliqué le mécanisme de mappage de scène lorsque certaines classes sont combinées en une seule. Par exemple, nous avons connecté tout ce qui est lié aux forêts à une forêt, tout ce qui est lié aux hôpitaux - à un hôpital, aux hôtels - à un hôtel.
Nous utilisons le mappage de scène uniquement pour les tests et pour l'utilisateur final, car c'est plus pratique. En formation, nous utilisons toutes les classes standard 314. Nous avons appelé la base résultante Places Sift.
Approches, solutions
Considérez maintenant les approches que nous avons utilisées pour résoudre ce problème. En fait, ces tâches sont liées à l'approche classique - les réseaux de neurones convolutionnels profonds.
L'image ci-dessous montre l'un des premiers réseaux classiques, mais il contient déjà les principaux blocs de construction utilisés dans les réseaux modernes.

Ce sont des couches convolutives, ce sont des couches de traction, des couches entièrement connectées. Afin de déterminer l'architecture, nous avons vérifié les sommets des concours ImageNet et Places2.

On peut dire que les principales architectures principales peuvent être divisées en deux familles: Inception et la famille ResNet (réseau résiduel). Au cours des expériences, nous avons découvert que la famille ResNet est mieux adaptée à notre tâche et nous avons mené la prochaine expérience sur cette famille.

ResNet est un réseau profond qui se compose d'un grand nombre de blocs résiduels. C'est son bloc de construction principal, qui se compose de plusieurs couches avec des poids et une connexion de raccourci. Grâce à cette conception, cet appareil apprend à quel point le signal d'entrée x diffère de la sortie f (x). En conséquence, nous pouvons construire des réseaux de tels blocs, et pendant l'entraînement, le réseau dans les dernières couches peut faire des poids proches de zéro.
Ainsi, nous pouvons dire que le réseau lui-même décide de la profondeur qu'il doit avoir pour résoudre certaines tâches. Grâce à cette architecture, il est possible de construire des réseaux de très grande profondeur avec un très grand nombre de couches. Le gagnant d'ImageNet 2014 ne contenait que 22 couches, ResNet a dépassé ce résultat et contenait déjà 152 couches.
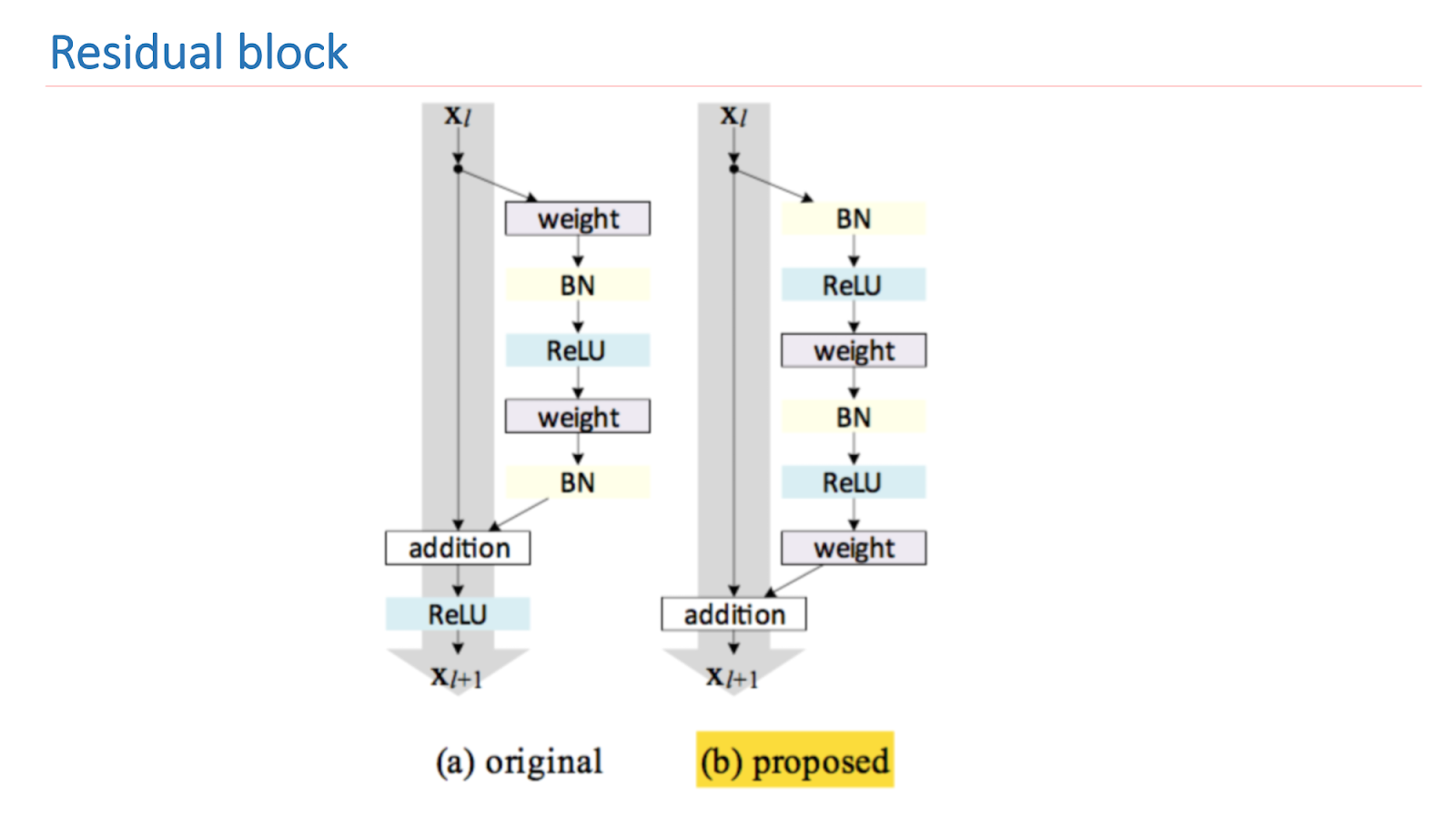
La recherche principale de ResNet est d'améliorer et de construire correctement un bloc résiduel. L'image ci-dessous montre une version empiriquement et mathématiquement saine qui donne le meilleur résultat. Une telle construction du bloc vous permet de traiter l'un des problèmes fondamentaux de l'apprentissage en profondeur - un gradient de décoloration.
Pour former nos réseaux, nous avons utilisé le framework Torch écrit en Lua en raison de sa flexibilité et de sa vitesse, et pour ResNet nous avons bifurqué l'
implémentation de ResNet à partir de Facebook . Pour valider la qualité du réseau, nous avons utilisé trois tests.
Le premier test Places val est la validation de nombreux sets Places Sift. Le deuxième test est le criblage des lieux utilisant la cartographie des scènes, et le troisième est le test Cloud le plus proche de la situation de combat. Images d'employés prises depuis le cloud et étiquetées manuellement. Dans l'image ci-dessous, il y a deux exemples de telles images.

Nous avons commencé à mesurer et à former des réseaux, à les comparer les uns aux autres. Le premier est le benchmark ResNet-152, qui vient avec Places2, le second est ResNet-50, que nous avons formé sur ImageNet et formé sur notre base, le résultat était déjà meilleur. Ensuite, ils ont pris ResNet-200, également formé sur ImageNet, et cela a finalement donné le meilleur résultat.

Voici des exemples de travaux. Il s'agit d'une référence ResNet-152. Les prédictions sont les étiquettes originales que le réseau distribue. Les étiquettes mappées sont les étiquettes qui sont apparues après le mappage de scène. On peut voir que le résultat n'est pas très bon. Autrement dit, elle semble donner quelque chose sur l'affaire, mais pas très bien.

L'exemple suivant est le fonctionnement de ResNet-200. Déjà très adéquat.

Amélioration ResNet
Nous avons décidé d'essayer d'améliorer notre réseau, et au début, nous avons juste essayé d'augmenter la profondeur du réseau, mais après cela, il est devenu beaucoup plus difficile à former. C'est un problème connu, l'année dernière plusieurs articles ont été publiés sur ce sujet, qui disent que ResNet, en fait, est un ensemble d'un grand nombre de réseaux ordinaires de différentes profondeurs.
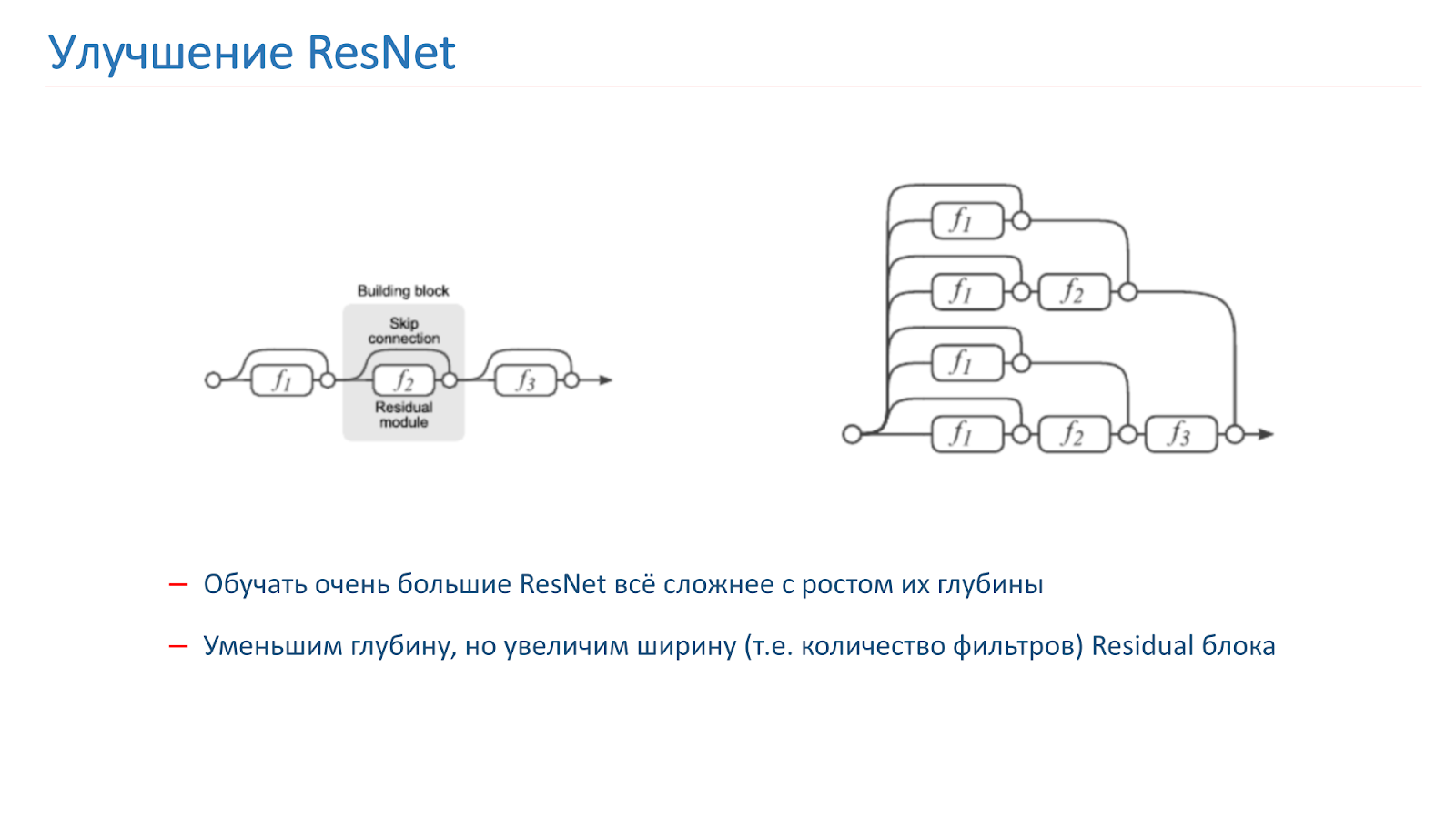
Les res-blocs, qui sont à la fin de la grille, contribuent peu à la formation du résultat final. Il semble plus prometteur d'augmenter non pas la profondeur du réseau, mais sa largeur, c'est-à-dire le nombre de filtres à l'intérieur du bloc Res.
Cette idée est mise en œuvre par le Wide Residual Network, qui est apparu en 2016. Nous avons fini par utiliser WRN-50-2, qui est le ResNet-50 habituel avec deux fois le nombre de filtres dans la convolution 3x3 du goulot d'étranglement interne.

Le réseau affiche sur ImageNet des résultats similaires avec le ResNet-200, que nous avons déjà utilisé, mais, surtout, il est presque deux fois plus rapide. Voici deux implémentations du bloc résiduel sur Torch; le paramètre qui est doublé est mis en surbrillance. Il s'agit du nombre de filtres dans la convolution interne.

Ce sont des mesures sur les tests ResNet-200 ImageNet. Au début, nous avons pris le WRN-22-6, le résultat a été pire. Ensuite, ils ont pris WRN-50-2-ImageNet, l'ont formé, ont pris WRN-50-2, formé sur ImageNet et l'ont formé sur Places2-challenge, et il a montré le meilleur résultat.
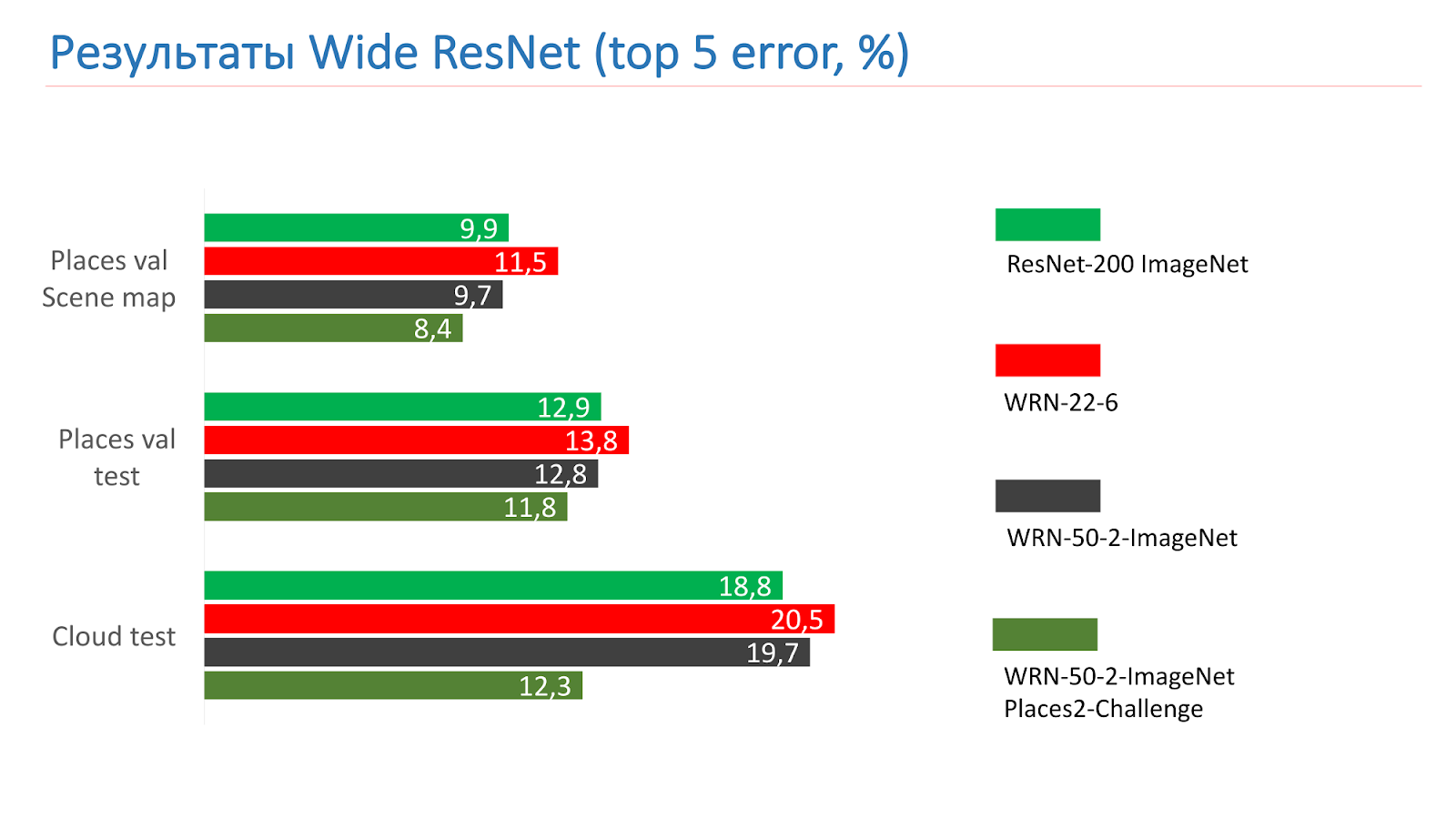
Voici un exemple du WRN-50-2 - un résultat tout à fait adéquat dans nos photos que vous avez déjà vues.

Et ceci est un exemple de travail sur des photographies de combat, également avec succès.

Il y a, bien sûr, des œuvres pas très réussies. Le pont d'Alexandre III à Paris n'était pas reconnu comme un pont.

Amélioration du modèle
Nous avons réfléchi à la manière d'améliorer ce modèle. La famille ResNet continue de s'améliorer, avec de nouveaux articles à paraître. En particulier, en 2016, un article intéressant PyramidNet a été publié, qui a montré des résultats prometteurs sur CIFAR-10/100 et ImageNet.
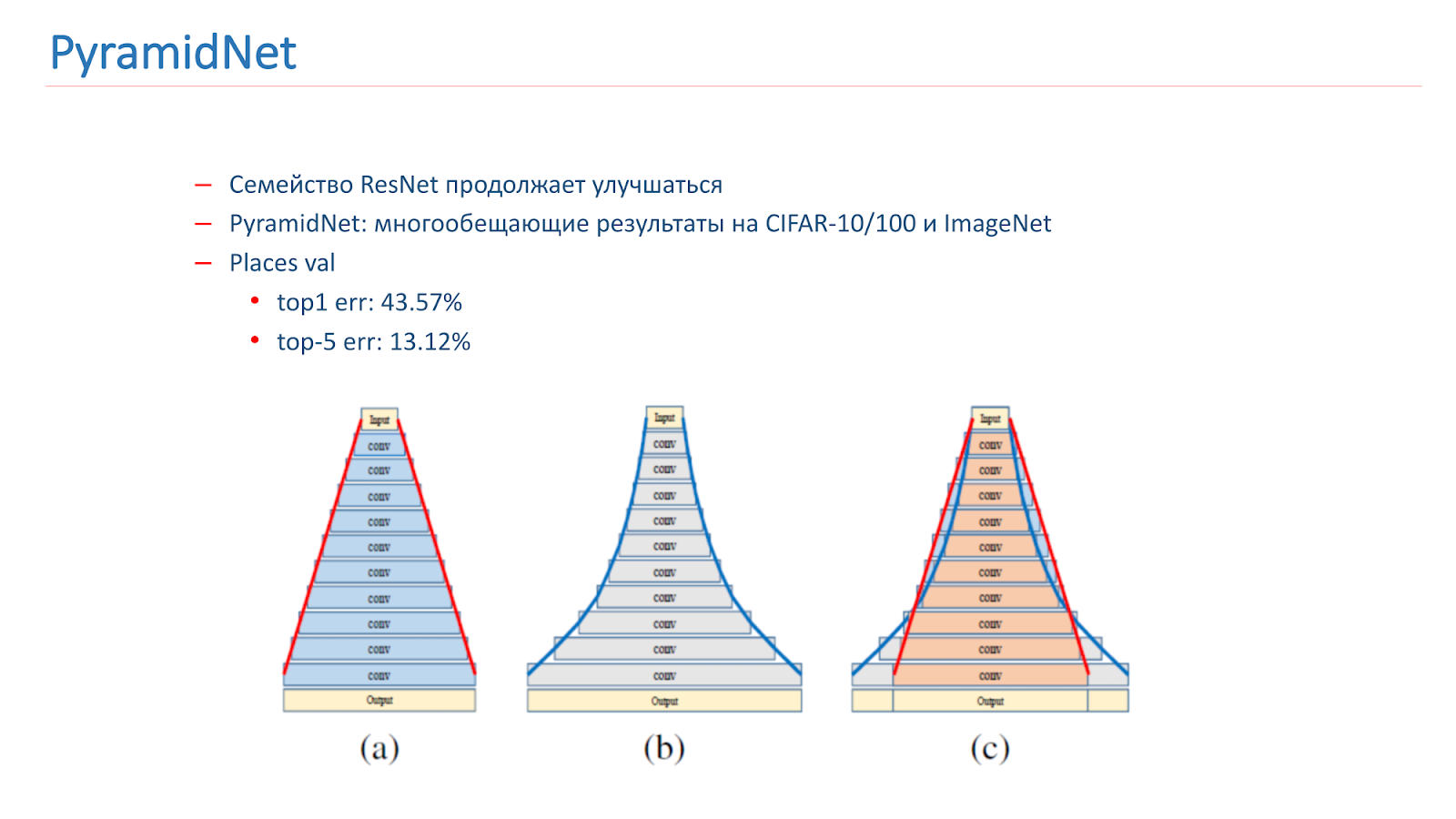
L'idée n'est pas d'augmenter fortement la largeur du bloc résiduel, mais de le faire progressivement. Nous avons formé plusieurs options pour ce réseau, mais, malheureusement, il a donné des résultats légèrement pires que notre modèle de combat.
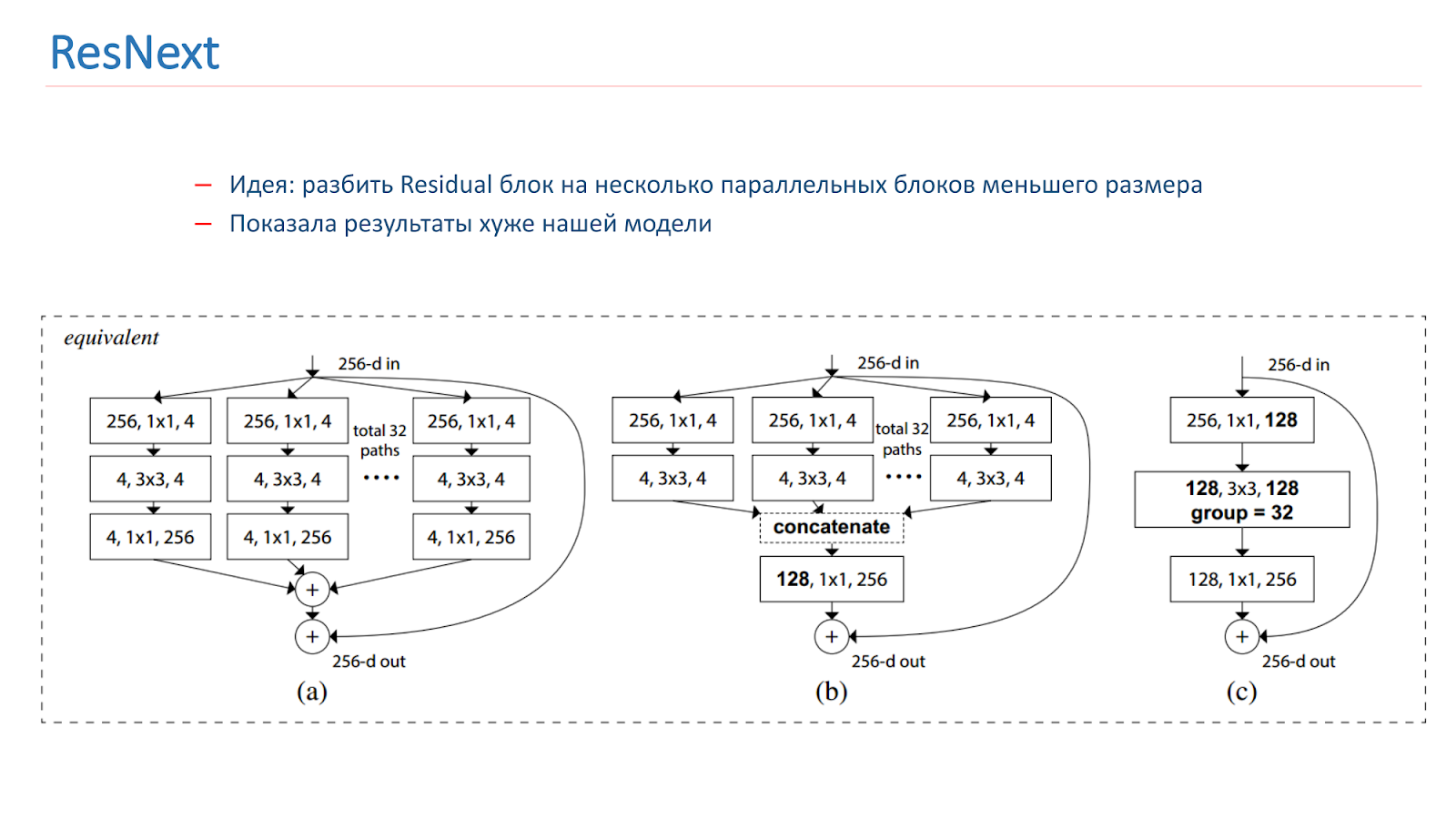
Au printemps 2018, le modèle ResNext est sorti, également une idée prometteuse: diviser le bloc résiduel en plusieurs blocs parallèles de plus petite taille, de plus petite largeur. Ceci est similaire à l'idée d'Inception, nous l'avons également expérimentée. Mais, malheureusement, elle a montré des résultats pires que notre modèle.
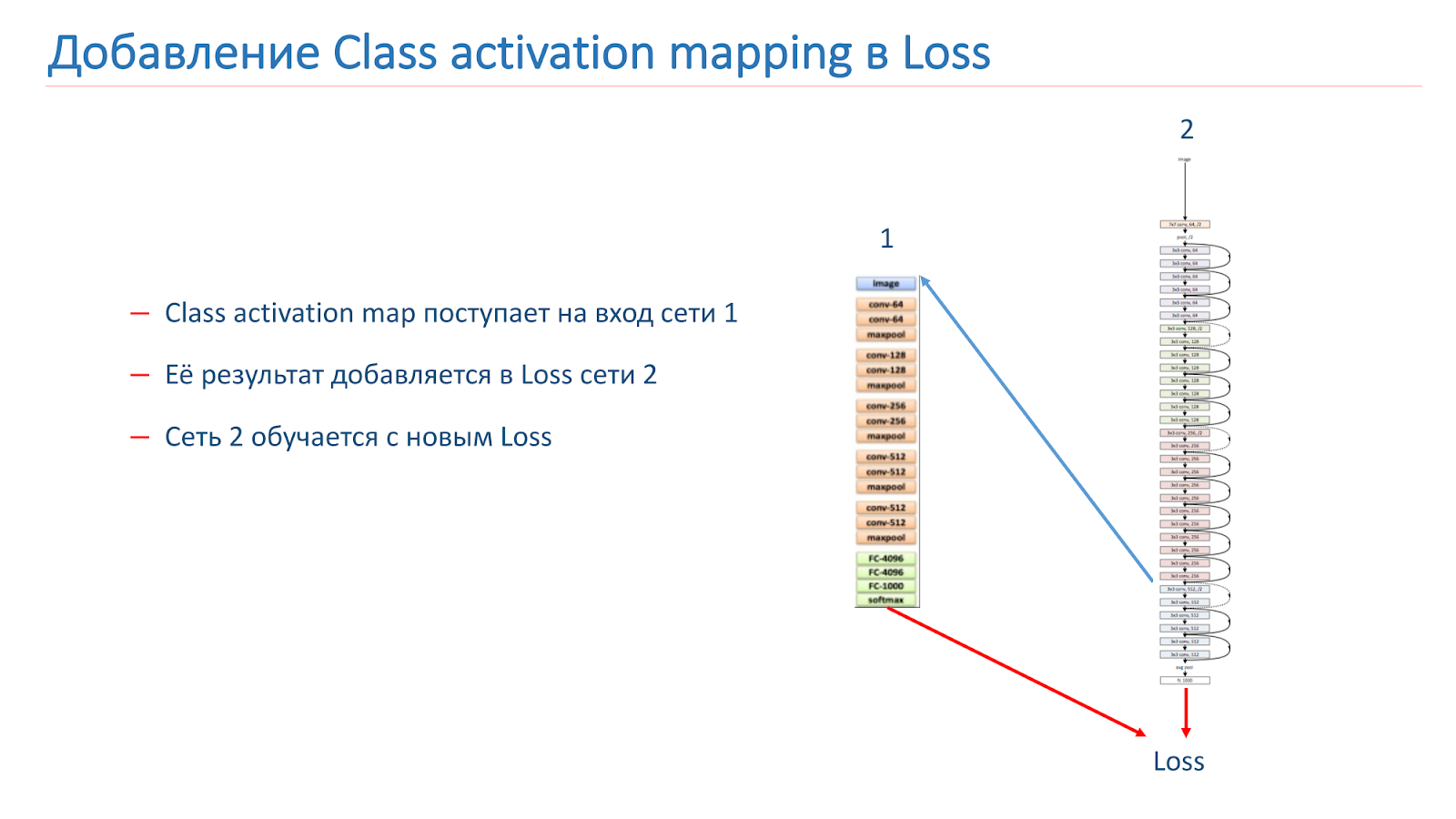
Nous avons également expérimenté différentes approches «créatives» pour améliorer nos modèles. En particulier, nous avons essayé d'utiliser le mappage d'activation de classe (CAM), c'est-à-dire que ce sont les objets que le réseau examine lorsqu'il classe l'image.

Notre idée était que les instances de la même scène devraient avoir les mêmes objets ou des objets similaires à une classe CAM. Nous avons essayé d'utiliser cette approche. Au début, ils ont pris deux réseaux. L'un est formé par ImageNet, le second est notre modèle, que nous voulons améliorer.

Nous prenons l'image, parcourons le réseau 2, ajoutons le CAM pour la couche, puis la transmettons à l'entrée du réseau 1. Parcourez le réseau 1, ajoutez les résultats à la fonction de perte du réseau 2, continuez avec les nouvelles fonctions de perte.
La deuxième option consiste à exécuter l'image via le réseau 2, à prendre le CAM, à l'alimenter à l'entrée du réseau 1, puis à partir de ces données, nous formons simplement le réseau 1 et utilisons l'ensemble à partir des résultats du réseau 1 et du réseau 2.
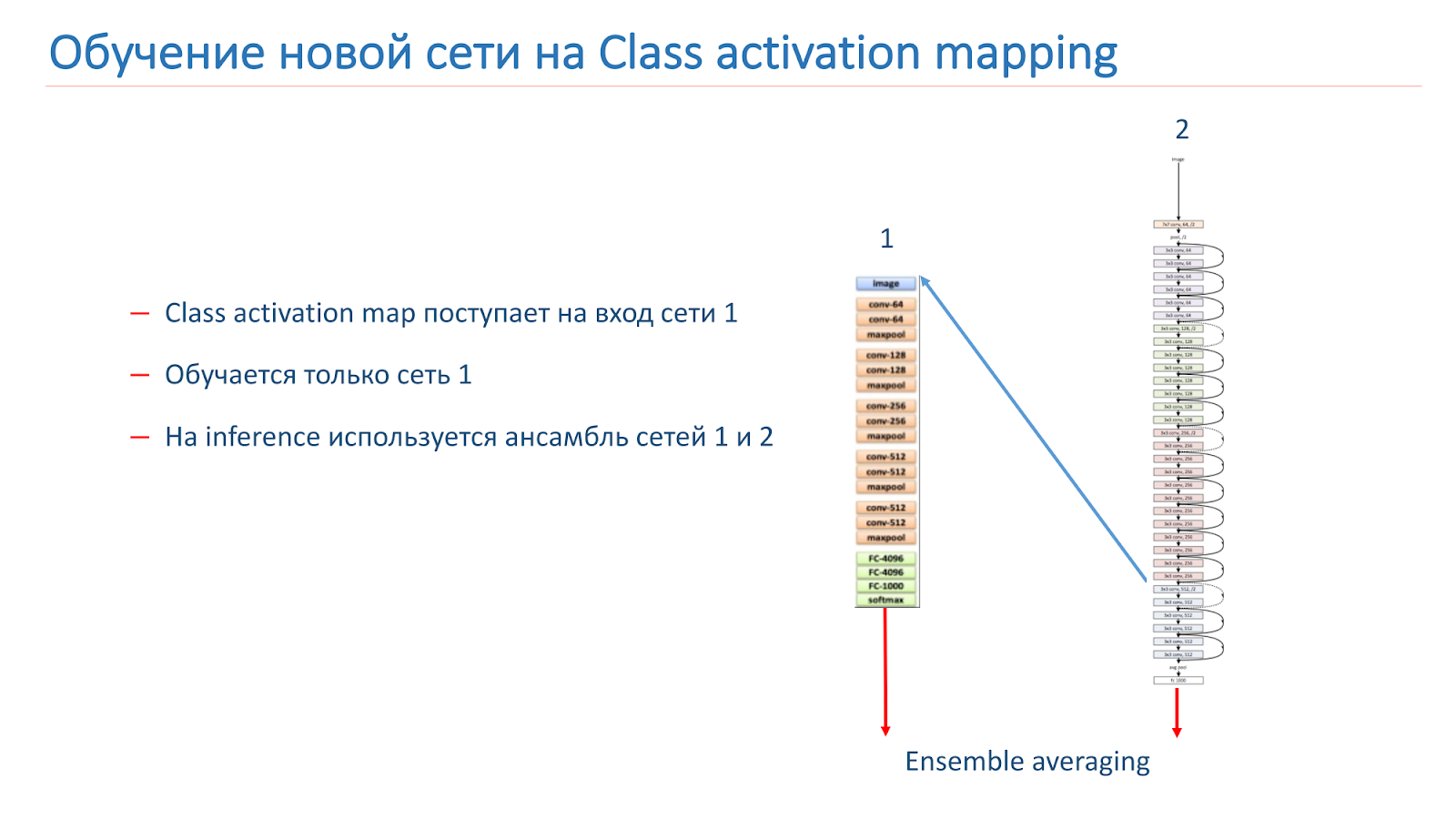
Nous avons recyclé notre modèle sur WRN-50-2, en tant que réseau 1, nous avons utilisé ResNet-50 ImageNet, mais il n'a pas été possible d'augmenter de manière significative la qualité de notre modèle.
Mais nous poursuivons nos recherches pour améliorer nos résultats: nous formons de nouvelles architectures CNN, en particulier la famille ResNet. Nous essayons d'expérimenter avec la FAO et considérons différentes approches avec un traitement plus intelligent des patchs d'images - il nous semble que cette approche est assez prometteuse.
Reconnaissance historique

Nous avons un bon modèle pour reconnaître les scènes, mais maintenant nous voulons découvrir des endroits emblématiques, c'est-à-dire des sites. De plus, les utilisateurs les prennent souvent en photo ou prennent des photos sur leur arrière-plan.
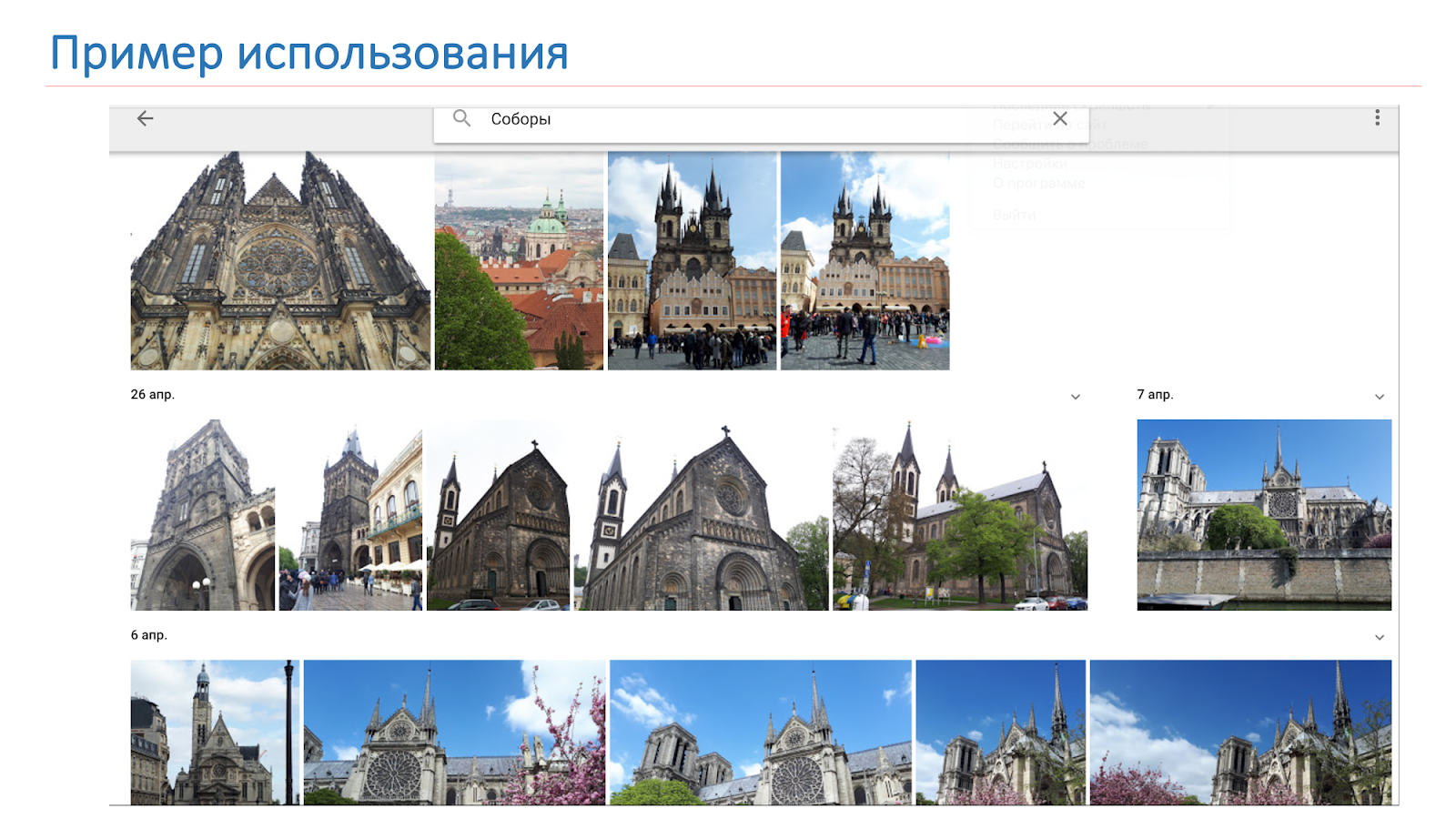
Nous voulons que le résultat ne soit pas seulement les cathédrales, comme dans l'image sur la diapositive, mais le système pour dire: "Il y a Notre Dame de Paris et les cathédrales à Prague."
Lorsque nous avons résolu ce problème, nous avons rencontré quelques difficultés.
- Il n'y a pratiquement aucune étude sur ce sujet et il n'y a pas de données toutes faites dans le domaine public.
- Un petit nombre d'images "propres" dans le domaine public pour chaque attraction.
- On ne sait pas exactement ce qu'est un point de repère dans les bâtiments. Par exemple, une maison avec des tours sur Sq. Leo Tolstoy à Petersburg, TripAdvisor ne considère pas les attractions, mais Google le considère.
Nous avons commencé par collecter une base de données, compilé une liste de 100 villes, puis utilisé l'API Google Places pour télécharger des données JSON pour les points d'intérêt de ces villes.
Les données ont été filtrées et analysées, et selon la liste, nous avons téléchargé 20 images de la recherche Google pour chaque attraction. Le nombre 20 est tiré de considérations empiriques. En conséquence, nous avons obtenu une base de 2827 attractions et environ 56 000 images. C'est sur cette base que nous avons formé notre modèle. Pour valider notre modèle, nous avons utilisé deux tests.
Test cloud - ce sont des images de nos employés, étiquetées manuellement. Il contient 200 photos dans 15 villes et 10 mille images sans attractions. Le second est le test de recherche. Il a été construit en utilisant la recherche Mail.ru, qui contient de 3 à 10 images pour chaque attraction, mais, malheureusement, ce test est sale.
Nous avons formé les premiers modèles, mais ils ont montré de mauvais résultats sur le test Cloud dans les photos de combat.
Voici un exemple de l'image sur laquelle nous avons été formés, et un exemple de photographie de combat. Le problème chez les gens, c'est qu'ils sont souvent photographiés sur fond de vues. Dans ces images que nous avons obtenues de la recherche, il n'y avait personne.
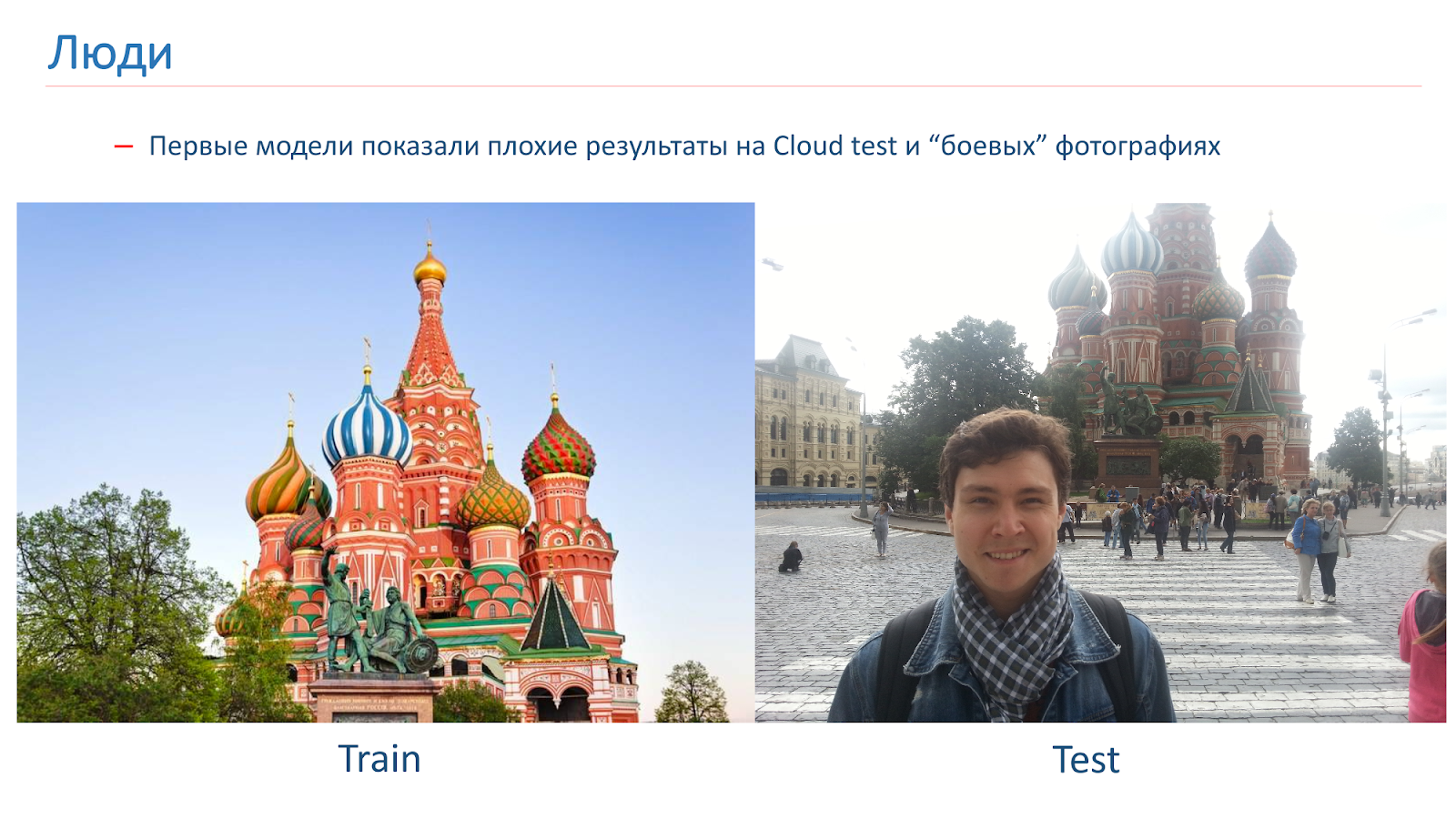
Pour lutter contre cela, nous avons ajouté une augmentation «humaine» pendant l'entraînement. Autrement dit, nous avons utilisé des approches standard: rotations aléatoires, découpe aléatoire d'une partie de l'image, etc. Mais également dans le processus d'apprentissage, nous avons ajouté des personnes au hasard à certaines images.

Cette approche nous a aidés à résoudre le problème avec les gens et à obtenir un modèle de qualité acceptable.
Modèles de scène de réglage fin
Comment nous avons formé le modèle: il existe une base de formation, mais elle est assez petite. Mais nous savons qu'une attraction touristique est un cas particulier de la scène. Et nous avons un assez bon modèle de scène. Nous avons décidé de la former pour les sites touristiques. Pour ce faire, nous avons ajouté plusieurs couches entièrement connectées et BN au-dessus du réseau, les avons formées ainsi que les trois premiers blocs résiduels. Le reste du réseau était gelé.

De plus, pour la formation, nous utilisons la fonction de perte centrale non standard. Pendant la formation, Center Loss essaie de «séparer» les représentants de différentes classes en différents groupes, comme le montre l'image.

Lors de la formation, nous avons ajouté une autre classe «pas une attraction touristique». Et la perte centrale n'a pas été appliquée à cette classe. Sur une telle fonction de perte mixte, une formation a été dispensée.
Après avoir formé le réseau, nous en coupons la dernière couche de classification, et lorsque l'image passe à travers le réseau, elle se transforme en un vecteur numérique appelé intégration.
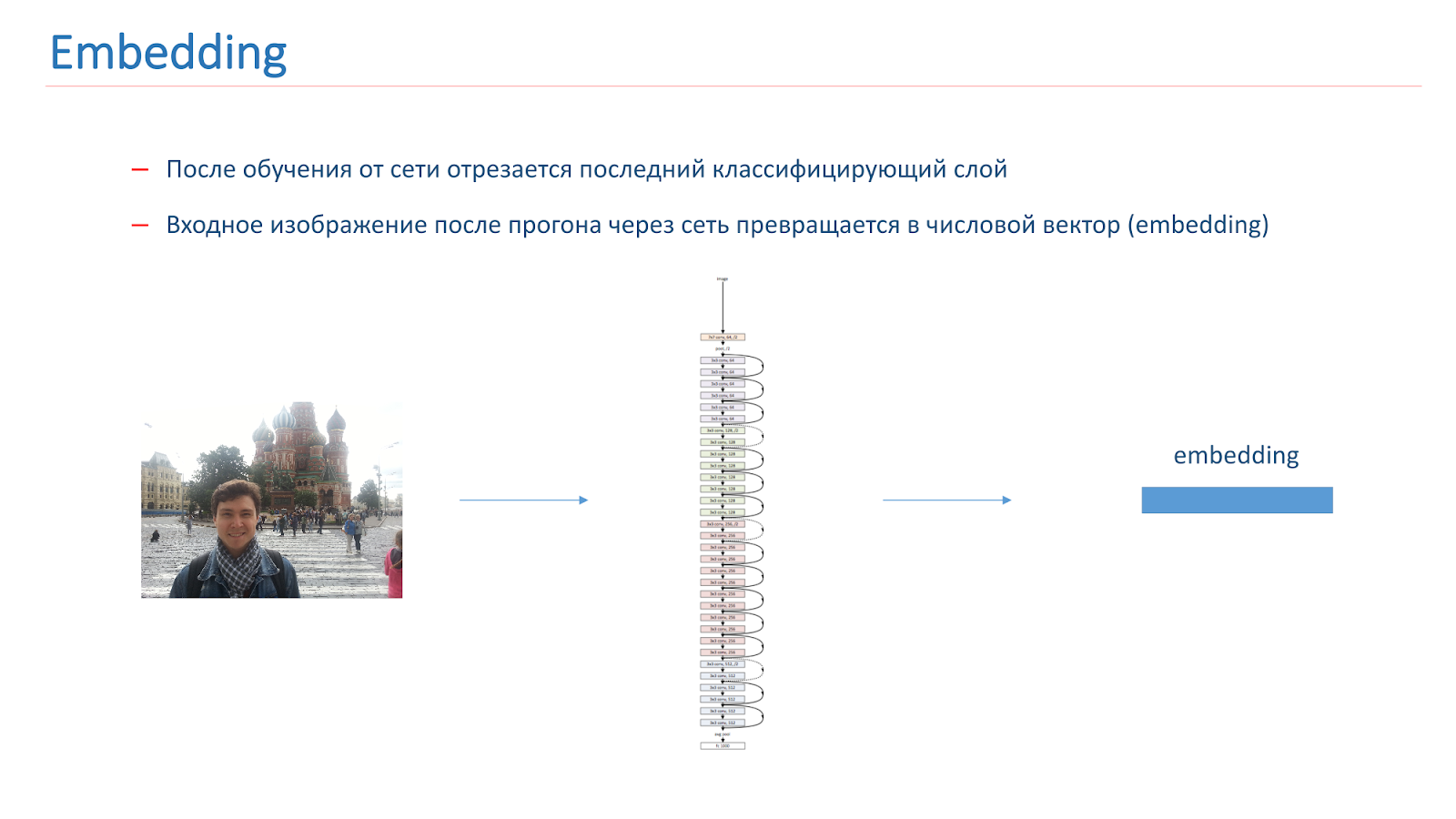
Pour continuer à construire un système de reconnaissance historique, nous avons construit des vecteurs de référence pour chaque classe. Nous avons pris chaque classe d'attractions de la multitude et parcouru les images à travers le réseau. Ils ont obtenu des plongements et ont pris leur vecteur du milieu, qui était appelé le vecteur de référence de classe.

Pour déterminer les sites sur la photo, nous exécutons l'image d'entrée via le réseau et son intégration est comparée au vecteur de référence de chaque classe. Si le résultat de la comparaison est inférieur au seuil, alors nous pensons que l'image n'a pas d'attrait. Sinon, nous prenons la classe avec la valeur de comparaison la plus élevée.
Résultats des tests
- Lors du test sur les nuages, la précision des vues était de 0,616, pas des vues - 0,981
- La précision moyenne de 0,669 a été obtenue lors du test de recherche et la complétude moyenne était de 0,576.
Sur Search, ils n'ont pas obtenu de très bons résultats, mais cela s'explique par le fait que le premier est assez "sale" et le second a des caractéristiques - parmi les attractions, il y a différents jardins botaniques qui sont similaires dans toutes les villes.
Il y avait une idée de reconnaissance de scène pour former d'abord le réseau, qui déterminera le masque de scène, c'est-à-dire en supprimera les objets du premier plan, puis l'introduira dans le modèle lui-même, qui reconnaît les scènes d'image sans ces zones, où l'arrière-plan est obstrué. Mais il n'est pas très clair ce qui doit être retiré de la couche avant, quel masque est nécessaire.
Ce sera quelque chose d'assez compliqué et intelligent, car tout le monde ne comprend pas quels objets appartiennent à la scène et lesquels sont superflus. Par exemple, des personnes dans un restaurant peuvent être nécessaires. C'est une décision non triviale, nous avons essayé de faire quelque chose de similaire, mais cela n'a pas donné de bons résultats.
Voici un exemple de travail dans les photographies de combat.
Exemples de travail réussi:


Mais le travail a échoué: aucune vue n'a été trouvée. Le principal problème de notre modèle pour le moment n'est pas que le réseau confond les vues, mais qu'il ne les trouve pas sur la photo.

À l'avenir, nous prévoyons de collecter une base pour un nombre encore plus grand de villes, de trouver de nouvelles méthodes pour former le réseau à cette tâche et de déterminer les possibilités d'augmenter le nombre de classes sans recycler le réseau.
Conclusions
Aujourd'hui, nous:
- Nous avons examiné les ensembles de données disponibles pour la reconnaissance de scène;
- Nous avons vu que le Wide Residual Network est le meilleur modèle;
- A discuté d'autres possibilités d'améliorer la qualité de ce modèle;
- Nous avons examiné la tâche de reconnaître les vues, les difficultés qui surgissent;
- Nous avons décrit l'algorithme de collecte de la base et les méthodes d'enseignement du modèle pour reconnaître les attractions.
Je peux dire que les tâches sont intéressantes, mais peu étudiées dans la communauté. Il est intéressant de les traiter, car vous pouvez appliquer des approches non standard qui ne sont pas appliquées dans la reconnaissance habituelle d'objets.Minute de publicité. Si vous avez aimé ce rapport de la conférence SmartData, veuillez noter que SmartData 2018 se tiendra à Saint-Pétersbourg le 15 octobre, une conférence pour ceux qui sont plongés dans le monde de l'apprentissage automatique, de l'analyse et du traitement des données. Le programme aura beaucoup de choses intéressantes, le site a déjà ses premiers intervenants et rapports.