Salut% username%!
Vous savez probablement ce que sont les API et combien en dépend dans votre projet. De plus, je crois également que vous connaissez déjà la
première approche de l'
API et que vous savez que
Swagger et son
API ouverte sont parmi les outils les plus populaires pour l'aider à suivre.
Mais dans cet article, je veux d'abord parler de l'approche de la mise en œuvre de l'API, conceptuellement différente de ce que Swagger et Apiary proposent. À la tête de l'idée se trouve le concept de
contrat unique et la possibilité de sa mise en œuvre basée sur RAML 1.0.
Sous la coupe:
- Une brève description des principes de l'API d'abord;
- Contrat unique - introduction d'un concept, conditions préalables à l'apparition, examen de la possibilité de sa mise en œuvre sur la base de l'OEA (Swagger);
- RAML + annotations + superpositions comme base pour le contrat unique , exemples;
- Problèmes RAML, désaccords conceptuels des développeurs;
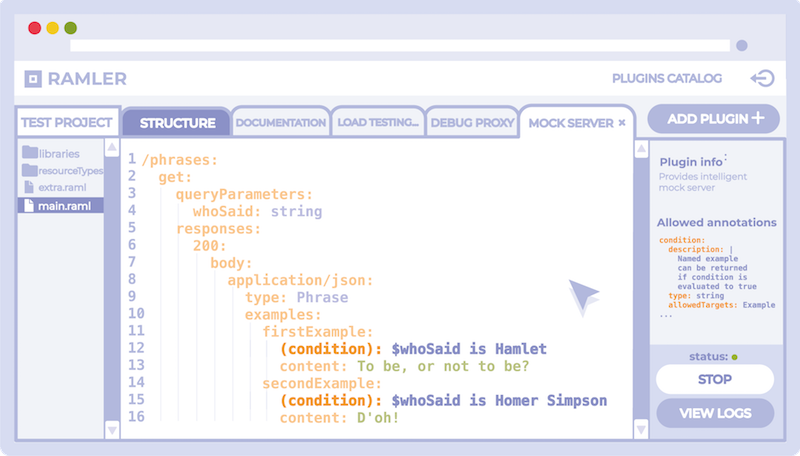
- L'idée d'un service SaaS basé sur l'idée ci-dessus (photo prototype ci-dessus).
De l'API d'abord sur Swagger au contrat unique sur RAML
Lors de la conception de systèmes logiciels modernes, la tâche se pose souvent de coordonner et de développer des interfaces pour l'interaction de leurs composants les uns avec les autres. Au cours de la dernière décennie, le SPA et les applications mobiles épaisses interagissant avec le serveur via des API ont gagné en popularité et en développement. Auparavant, le développement d'un site Web interactif était effectué par une modification étape par étape du code côté serveur pour générer un balisage HTML avec son transfert ultérieur vers le navigateur du client, mais maintenant le développement d'applications Web dynamiques s'est déplacé vers la création d'une API de service unique et le développement parallèle de nombreuses applications (y compris SPA) fonctionnant avec cette API comme source de données principale. Cette approche vous permet de partager plus facilement les tâches, d'organiser des équipes spécialisées uniquement dans des technologies spécifiques (attirer des spécialistes plus spécialisés), d'organiser le développement parallèle aux toutes premières étapes, et vous permet également de créer un point de communication unique - une interface API.
Un tel point de communication unique nécessite une définition formelle et sans ambiguïté, ce document est une spécification API. Pour développer et documenter les spécifications des API aujourd'hui, différentes technologies et langages sont utilisés, par exemple: OAS (Swagger), Apiary et RAML.
Les trois points suivants déterminent la nature de la première approche de l'API:
- L'API devrait être la toute première interface client de l'application développée;
- Tout d'abord, une spécification API est développée, puis la partie logicielle de ses clients;
- Les étapes de vie d'une API doivent coïncider avec les étapes de vie de sa documentation.
Si nous considérons le processus basé sur ce qui précède, alors la spécification d'API est au centre du processus de développement, et tous les nœuds qui composent le système et utilisent cette API comme passerelle d'interaction sont des clients de la spécification d'API. Ainsi, la partie serveur du système peut être considérée comme la même API de spécification client, comme tout autre nœud qui utilise l'API pour communiquer avec lui. Les modèles de domaine d'application ne doivent pas nécessairement correspondre aux modèles décrits dans la spécification d'API. Leurs éventuelles coïncidences intentionnelles avec les structures de classe dans le code d'application client ou avec les structures de schéma de base de données sont introduites plutôt pour simplifier le processus de développement, par exemple, lors de l'utilisation d'un générateur de code selon la spécification OAS. Logiquement, ce qui précède peut être résumé sous la définition de
contrat unique .
Contrat unique - de nombreux clients.
Contrat unique. Outils de contrat et bibliothèques
Le terme contrat unique ne revendique aucune participation à la critique de son utilisation dans le texte de l'article. Son application, dans ce contexte, est personnellement mon idée.
L'extension du concept d'
API à un
contrat unique plus général nous permet de considérer la spécification d'API non seulement comme une description formelle de l'interface entre les composants du système, mais également comme un
contrat unique utilisé par un certain nombre de bibliothèques et d'outils externes comme source de configuration. Dans ce cas, ces outils et bibliothèques peuvent être perçus comme des clients sous contrat avec des applications SPA ou mobiles. Exemples de tels clients:
- Générateur de documentation
- API de serveur fictif
- Service de test de résistance
- Bibliothèque de validation des demandes / réponses
- Générateur de code
- Générateur d'interface utilisateur
- etc.
Le contrat unique pour ces clients est un fichier de configuration et une source de données uniques. Les instruments contractuels ne fonctionnent que sur la base des informations obtenues d'un contrat particulier. De toute évidence, pour la fonctionnalité complète de clients hétérogènes tels que l'API du faux serveur, une description d'API ne suffit pas, des méta-informations supplémentaires sont nécessaires, par exemple, une description de la relation entre les paramètres de demande GET (identifiant de ressource) et les données que le serveur doit renvoyer, des indices pointant vers les champs de réponse et paramètres de requête utilisés pour organiser la pagination. De plus, cet exemple sera examiné plus en détail. Des informations spécifiques pour des instruments spécifiques, en même temps, doivent exister et être inextricablement conservées dans le document principal, sinon cela violera le concept d'un contrat unique.
Swagger (OAS) en tant qu'outil de description de contrat unique
Les Swagger (OAS) et Apiary (Blueprint) les plus populaires sur le marché vous permettent de décrire les API HTTP à l'aide de langages spéciaux: API ouverte basée sur YAML ou JSON, Blueprint basée sur Markdown, ce qui facilite la lecture des spécifications. Il existe également de nombreux outils et bibliothèques créés par la grande communauté open source. Swagger est actuellement largement distribué et, pourrait-on dire, est devenu le standard de facto des API en premier. De nombreux systèmes externes prennent en charge l'importation des spécifications Swagger, telles que
SoapUI ,
Readme.io ,
Apigee , etc. De plus, le
hub et le
rucher SaaS
Swagger existants permettent aux utilisateurs de créer des projets, de télécharger ou de créer leurs propres spécifications, d'utiliser les générateurs de documentation et les serveurs fictifs intégrés, ainsi que de publier des liens pour y accéder de l'extérieur.
Swagger avec son OAS 3.0 semble assez confiant et sa fonctionnalité pour décrire l'API (particulièrement simple) est suffisante dans la plupart des cas. Voici une liste des avantages et des inconvénients de Swagger:
Avantages:
- Langage de description clair et facile à lire;
- Grande communauté open source;
- De nombreux éditeurs, générateurs, bibliothèques officiels et open source;
- La présence d'une équipe de développement de base travaillant constamment sur le développement et l'amélioration du format;
- Hub de Shareware pour les spécifications;
- Documentation officielle détaillée;
- Seuil d'entrée bas.
Inconvénients:
- Prise en charge de la modularité faible;
- Manque d'exemples auto-générés de réponses aux requêtes basées sur une description de leurs structures;
- Il y a souvent des problèmes avec la mauvaise stabilité des produits SmartBear (auteurs fanfaronneurs) et la réaction tardive du développeur à cela (l'avis est basé uniquement sur l'expérience personnelle d'utilisation et l'expérience de notre équipe).
Mais la principale limitation qui ne permet pas d'utiliser l'OEA comme moyen de décrire le
contrat unique est le manque de capacité à joindre des métadonnées personnalisées pour décrire des paramètres supplémentaires des outils / bibliothèques cibles.
Par conséquent, tous les outils qui fonctionnent sur la base des spécifications de Swagger doivent se contenter de l'ensemble d'informations pouvant accueillir le format de base.
Par exemple, la mise en œuvre d'un serveur Smart Mock API nécessite plus d'informations qu'un document de spécification ne peut fournir, c'est pourquoi la Swagger Hub Mock API intégrée est uniquement capable de générer de fausses données basées sur des types / structures de données obtenues à partir d'un document de spécification. Sans aucun doute, cela ne suffit pas et une telle fonctionnalité de faux serveur ne peut être satisfaite que par un simple client API.
Dans notre entreprise, lors du développement d'un des projets (React SPA + API server), la fonctionnalité de faux serveur suivante était requise:
- imitation de la pagination. Le serveur ne doit pas renvoyer des valeurs complètement aléatoires des champs currentPage, nextPage, pagesTotal en réponse aux demandes de liste, mais être capable de simuler le comportement réel du mécanisme de pagination avec la génération des valeurs de ces métapoles en fonction de la valeur de page reçue du client;
- générer des corps de réponse contenant divers ensembles de données en fonction du paramètre spécifique de la demande entrante;
- la possibilité de construire de vraies relations entre de faux objets: le champ foo_id de l'entité Bar doit faire référence à l'entité Foo générée précédemment. Ceci peut être réalisé en ajoutant la prise en charge de l'idempotency au serveur simulé;
- imitation du travail de différentes méthodes d'autorisation: OAuth2, JWT, etc.
Sans tout cela, il est très difficile de développer SPA en parallèle avec le développement de la partie serveur du système. Et, en même temps, un tel serveur factice, en raison de ce qui a été décrit précédemment, est presque impossible à mettre en œuvre sans méta-informations spécifiques supplémentaires qui pourraient être stockées directement dans la spécification API et l'informer du comportement requis lors de la simulation du prochain point de terminaison. Ce problème peut être résolu en ajoutant les paramètres requis sous la forme d'un fichier séparé avec des configurations parallèles à la spécification OAS de base, mais, dans ce cas, vous devez prendre en charge ces deux sources différentes séparément.
S'il y aura plus d'un faux serveur avec des outils fonctionnant dans l'environnement de développement selon ce principe, alors nous aurons un «zoo» d'outils, chacun, ayant sa propre fonctionnalité unique, est obligé d'avoir son propre fichier de configuration unique, logiquement lié à l'API de base -spécifications, mais en réalité situées séparément et vivant «leur propre vie».
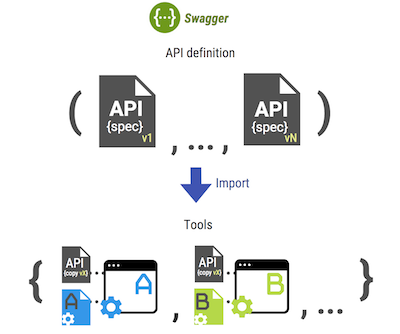
Problème: le développeur sera obligé de maintenir la pertinence de toutes les configurations après avoir changé les versions de la spécification de base, souvent dans des endroits et des formats complètement différents.
Quelques exemples de services qui fonctionnent sur un principe similaire:
- SoapUI est un système pour tester les interfaces REST & SOAP. Prend en charge l'importation d'un projet à partir de la spécification Swagger. Lors de la modification de la spécification Swagger de base, la configuration d'un projet basé sur une liste d'appels API continue d'exister en parallèle et nécessite une synchronisation manuelle;
- Autres produits SmartBear ;
- Apigee est un service de gestion du cycle de vie de l'API. Il utilise les spécifications Swagger comme modèles, à partir desquels il permet d'initialiser ses configurations de services internes. Il n'y a pas non plus de synchronisation automatique;
- Readme.io est un service qui vous permet de créer une belle documentation basée sur la spécification Swagger, et dispose également d'un mécanisme pour suivre les modifications apportées à la spécification de base et résoudre les conflits en mettant à jour la configuration du projet côté service. Cela nécessitait certainement une complexité inutile pour développer ce service.
Vous pouvez ajouter de nombreux autres services à cette liste qui fournissent la fonction d'intégration avec la spécification Swagger. L'intégration pour la plupart d'entre eux signifie la copie habituelle de la structure de base de la spécification Swagger et l'auto-complétion ultérieure des champs de configuration locale sans prise en charge de la synchronisation avec les modifications de la spécification de base.
RAML, annotations, superpositions
Le désir de trouver un outil qui exclut la restriction OAS mentionnée précédemment, nous permettant de considérer la spécification comme un contrat unique pour tous les outils clients, nous a conduit à nous familiariser avec le langage RAML. Il y a suffisamment d'écrit sur RAML, vous pouvez le lire, par exemple, ici
https://www.infoq.com/articles/power-of-raml . Les développeurs de RAML ont essayé de placer le support du langage pour la modularité au niveau de son concept. Désormais, chaque entreprise ou développeur individuel peut créer ses propres dictionnaires publics prêts à l'emploi lors de la conception de l'API, redéfinir et hériter des modèles de données prêts à l'emploi. À partir de la version 1.0, RAML prend en charge 5 types de modules externes différents:
inclure, bibliothèque, extension, trait, superposition , ce qui permet d'utiliser chacun de manière aussi flexible que possible en fonction de la tâche.
Le moment est venu de discuter de la principale possibilité de RAML, qui, pour des raisons qui ne sont pas complètement comprises, n'a pas d'analogues dans l'OEA et Blueprint - Annotations.
Les annotations dans RAML permettent d'attacher des métadonnées personnalisées aux structures de langage sous-jacentes.
C'est cette fonction RAML qui est devenue la raison de la rédaction de cet article.
Un exemple:
#%RAML 1.0 title: Example API mediaType: application/json # Annotation types block may be placed into external file annotationTypes: validation-rules: description: | Describes strict validation rules for the model properties. Can be used by validation library allowedTargets: [ TypeDeclaration ] type: string[] info-tip: description: | Can be used by Documentation generator for showing tips allowedTargets: [ Method, DocumentationItem, TypeDeclaration ] type: string condition: description: | Named example can be returned if condition is evaluated to true. Can be used by Intelligent mock server allowedTargets: [ Example ] type: string types: Article: type: object properties: id: type: integer title: string paragraphs: Paragraph[] createdAt: type: string (validation-rules): ["regex:/\d{4}-[01]\d-[0-3]\dT[0-2]\d:[0-5]\d:[0-5]\d(?:\.\d+)?Z?/"] Paragraph: type: object properties: order: type: integer (validation-rules): ["min:0"] content: string (validation-rules): ["max-length:1024"] /articles/{articleId}: get: (info-tip): This endpoint is deprecated description: Returns Article object by ID responses: 200: body: application/json: type: Article
Les structures d'annotation utilisateur elles-mêmes doivent avoir des descriptions claires en RAML. Pour cela, une section spéciale
annotationTypes est utilisée, dont les définitions peuvent également être extraites du module externe. Ainsi, il devient possible de définir des paramètres spéciaux d'un outil externe sous forme d'annotations attachées à la définition de base de l'API RAML. Afin d'éviter d'encombrer la spécification de base avec un grand nombre d'annotations pour divers outils externes, il est possible de les transférer dans des fichiers séparés - des
superpositions (et également des
extensions ), avec une classification par portée. Voici ce qui est dit sur les superpositions dans la documentation RAML (
https://github.com/raml-org/raml-spec/blob/master/versions/raml-10/raml-10.md#overlays ):
Une superposition ajoute ou remplace les nœuds d'une définition d'API RAML tout en préservant ses aspects comportementaux et fonctionnels. Certains nœuds d'une définition d'API RAML spécifient le comportement d'une API: ses ressources, méthodes, paramètres, corps, réponses, etc. Ces nœuds ne peuvent pas être modifiés en appliquant une superposition. En revanche, d'autres nœuds, tels que les descriptions ou les annotations, répondent à des préoccupations au-delà de l'interface fonctionnelle, telles que la documentation descriptive à caractère humain dans un certain langage, ou les informations de mise en œuvre ou de vérification à utiliser dans les outils automatisés. Ces nœuds peuvent être modifiés en appliquant une superposition.
Les superpositions sont particulièrement importantes pour séparer l'interface de l'implémentation. Les superpositions permettent des cycles de vie distincts pour les aspects comportementaux de l'API qui doivent être étroitement contrôlés, comme un contrat entre le fournisseur d'API et ses consommateurs, par rapport à ceux qui nécessitent peu de contrôle, tels que les aspects orientés vers l'humain ou la mise en œuvre qui peuvent évoluer à allures différentes. Par exemple, l'ajout de crochets pour les outils de test et de surveillance, l'ajout de métadonnées pertinentes à un registre d'API ou la fourniture d'une documentation humaine mise à jour ou traduite peuvent être réalisés sans modifier aucun aspect des aspects comportementaux de l'API. Ces choses peuvent être contrôlées via une version rigoureuse et un processus de gestion des changements.
En d'autres termes, cette fonctionnalité vous permet de «séparer le grain de l'ivraie», par exemple, la description principale de la spécification API, des méta-informations supplémentaires spécifiques à un outil particulier l'utilisant pour le travail. Les méta-informations de chaque superposition distincte sont «accrochées» sur divers blocs de la spécification sous forme d'annotations.
Un exemple de structure de base:
#%RAML 1.0 title: Phrases API mediaType: application/json types: Phrase: type: object properties: content: string /phrases: get: queryParameters: whoSaid: string responses: 200: body: application/json: type: Phrase
Superposition:
#%RAML 1.0 Overlay usage: Applies annotations for Intelligent mock server extends: example_for_article_2_1.raml annotationTypes: condition: description: | Named example can be returned if condition is evaluated to true type: string allowedTargets: Example /phrases: get: responses: 200: body: application/json: examples: firstExample: (condition): $whoSaid is Hamlet content: "To be, or not to be?" secondExample: (condition): $whoSaid is Homer Simpson content: "D'oh!"
En conséquence, il devient possible de mettre en œuvre un contrat unique: toutes les informations fonctionnelles, comportementales et méta sont stockées et versionnées en un seul endroit, et les outils de contrat - les clients du contrat, doivent prendre en charge les annotations utilisées dans cette spécification. D'un autre côté, ce sont les outils eux-mêmes qui peuvent présenter leurs propres exigences en matière d'annotations, qui doivent être «accrochées» à la spécification - cela offrira un plus large éventail de possibilités lors du développement d'outils contractuels.
Le concept ci-dessus est illustré dans la figure ci-dessous:
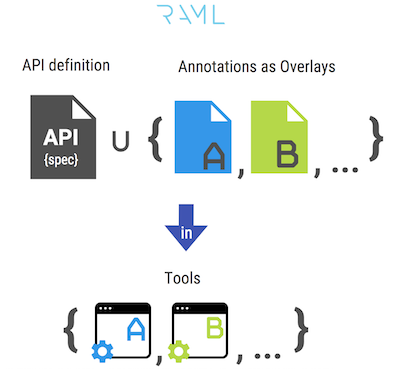
Parmi les inconvénients de cette approche, on peut distinguer la grande complexité de la synchronisation manuelle du fichier de spécification de base et de chacun des superpositions: lors de la mise à jour de la structure de la spécification de base, vous devez appliquer les changements requis dans les structures des superpositions. Ce problème devient plus grave lorsque plusieurs superpositions apparaissent.
Une solution possible et la plus évidente serait de développer un éditeur spécial ou un module complémentaire pour l'éditeur RAML en ligne existant
https://github.com/mulesoft/api-designer . La zone d'édition reste inchangée, mais il devient possible de créer des onglets: chaque nouvel onglet est une fenêtre d'édition de la superposition qui lui est affectée. Lors de la modification de la structure de base de la spécification dans la fenêtre principale, les structures de tous les onglets créés changent également et lorsqu'une incompatibilité de la nouvelle structure avec les annotations existantes situées dans les superpositions d'onglets est détectée, un avertissement apparaît. Un examen plus détaillé d'un tel éditeur est un sujet distinct et mérite un examen sérieux.
Développements existants
Dans la recherche de solutions existantes qui sont près de réaliser l'idée d'utiliser des annotations comme moyen de décrire les méta-informations, les solutions suivantes ont été trouvées:
- https://github.com/raml-org/raml-annotations référentiel contenant des annotations officielles approuvées par la communauté des développeurs RAML. Dans la version actuelle, seules les annotations OAuth2 sont disponibles. Ils peuvent être utilisés par des outils externes pour obtenir des méta-informations décrivant les aspects de l'implémentation OAuth2 pour la spécification API développée;
- https://github.com/petrochenko-pavel-a/raml-annotations bibliothèque d'annotations utilisateur @ petrochenko-pavel-a avec un regroupement logique par domaine d'application. Le projet est plus expérimental, mais illustre parfaitement l'idée d'utiliser des annotations. Les groupes d'annotations les plus intéressants:
- additionalValidation.raml - annotations pour décrire des règles supplémentaires pour la validation des modèles de spécification. Ils peuvent être utilisés, par exemple, par la bibliothèque du serveur pour valider les requêtes selon la spécification RAML;
- mock.raml - annotations pour décrire les détails du serveur simulé sur la base de la spécification RAML;
- semanticContexts.raml - annotations pointant vers le contexte sémantique des blocs structurels déclarés individuels de la spécification RAML;
- structural.raml - annotations clarifiant le rôle d'une entité RAML distincte dans la structure globale du modèle de domaine décrit;
- uiCore.raml - un exemple d'annotations pouvant être utilisées par les outils de génération d'interface utilisateur basés sur la spécification RAML;
Le référentiel contient également des bibliothèques de types d'utilitaires pouvant être utilisées comme primitives dans la description des structures de données de la spécification RAML.
Problèmes RAML
Malgré la fonctionnalité, la progressivité de l'idée de base et l'attention des grands fabricants de logiciels (cisco, spotify, vmware, etc.), RAML a aujourd'hui de graves problèmes qui peuvent devenir fatals en ce qui concerne son succès:
- Petite communauté open source fragmentée;
- Une stratégie incompréhensible du principal développeur RAML est mulesoft . La société développe des produits qui ne sont qu'une copie des solutions basées sur l'OEA existantes (incluses dans la plate-forme Anypoint ), au lieu de créer des services qui mettent l'accent sur les avantages de RAML par rapport à Swagger;
- La conséquence du premier paragraphe: un petit nombre de bibliothèques / outils open-source;
- Seuil d'entrée plus élevé que l'OEA (c'est étrange, mais beaucoup de gens le pensent);
- En raison du grand nombre de bogues et de problèmes avec UX / UI, le principal service totalement inadapté et repoussant les utilisateurs est le point d'entrée de RAML - https://anypoint.mulesoft.com/ .
Désaccord conceptuel. Première conclusion
Il existe des contradictions au sein de la communauté concernant le concept de base. Quelqu'un pense que RAML est un
langage de définition de modèle , et quelqu'un pense que c'est un
langage de définition d'API comme OAS ou Blueprint (les gars qui s'appellent eux-mêmes développeurs RAML le mentionnent souvent dans divers commentaires). Le concept de
langage de définition de
modèle permettrait à l'intérieur de la spécification RAML de décrire le modèle de domaine du domaine sans liaison stricte avec le contexte de la description de la ressource API, élargissant les horizons des options d'utilisation de la spécification avec des outils externes (en fait, créant la base de l'existence de ce
contrat unique !) Voici une définition du concept d'une ressource qui peut être vue sur les documents de lecture du site Web (
http://restful-api-design.readthedocs.io/en/latest/resources.html , d'ailleurs, je recommande à tout le monde de lire ce merveilleux guide sur la conception d'API):
Nous appelons les informations qui décrivent les types de ressources disponibles, leur comportement et leurs relations le modèle de ressource d'une API . Le modèle de ressource peut être considéré comme le mappage RESTful du modèle de données d'application .
Dans le
modèle de données d'application RAML
, ce sont des types déclarés dans le bloc
types , et le
modèle de ressource d'une API est ce qui est décrit dans le bloc RAML de
ressources . Par conséquent, vous devez avoir la capacité de décrire ce
mappage . Mais l'implémentation actuelle de RAML ne permet d'effectuer ce
mappage que de 1 à 1, c'est-à-dire d'utiliser des types «tels quels» dans la déclaration de l'API de ressource.
Je pense que c'est le principal problème du langage, dont la solution permettra à RAML d'aller au-delà du
langage de définition d'API et de devenir un
langage de définition de modèle à part entière: un langage plus général (plutôt que OAS ou Blueprint) utilisé pour décrire les contrats uniques de systèmes, qui sont par essence le noyau formel bon nombre de leurs composants.
Ce qui précède fait de RAML un joueur faible qui est actuellement incapable de gagner la compétition contre Swagger. C'est peut-être pourquoi, en conséquence, le principal développeur de RAML a pris des mesures drastiques
https://blogs.mulesoft.com/dev/api-dev/open-api-raml-better-together/L'idée du Single Contract RAML SaaS
Basée sur le concept de
contrat unique , à partir de l'idée d'héberger une API de spécifications Swagger basée sur l'OEA, ainsi que sur la possibilité pour RAML de déclarer des méta-informations et de partager les spécifications de base à l'aide de superpositions, l'idée d'une solution SaaS alternative pour l'hébergement et la gestion des spécifications basées sur le langage RAML suggère Surpassez le Swagger Hub et le rucher dans le volume et la qualité des fonctionnalités possibles.
Le nouveau service, par analogie avec le hub Swagger, sera l'hébergement de contrats utilisateur avec la mise à disposition d'un éditeur en ligne et la possibilité de visualiser les aperçus de la documentation avec des mises à jour en temps réel. La principale différence devrait être la présence d'un catalogue de plug-ins contractuels intégrés au service, dont l'utilisateur pourra installer les spécifications API dans son projet actuel. Pour l'installation, il sera nécessaire d'implémenter les annotations RAML requises spécifiées dans la documentation du plugin. Après avoir ajouté un nouveau plug-in au projet, un nouvel onglet sera ajouté dans la fenêtre de l'éditeur de code lorsque vous y basculerez, l'édition des annotations du plug-in installé deviendra disponible. La structure de la spécification de base doit être automatiquement dupliquée dans tous les onglets correspondant aux plugins. Si des conflits surviennent entre la structure de base et les annotations déjà existantes, un mécanisme spécial devrait offrir des options pour sa solution, ou la résoudre automatiquement.
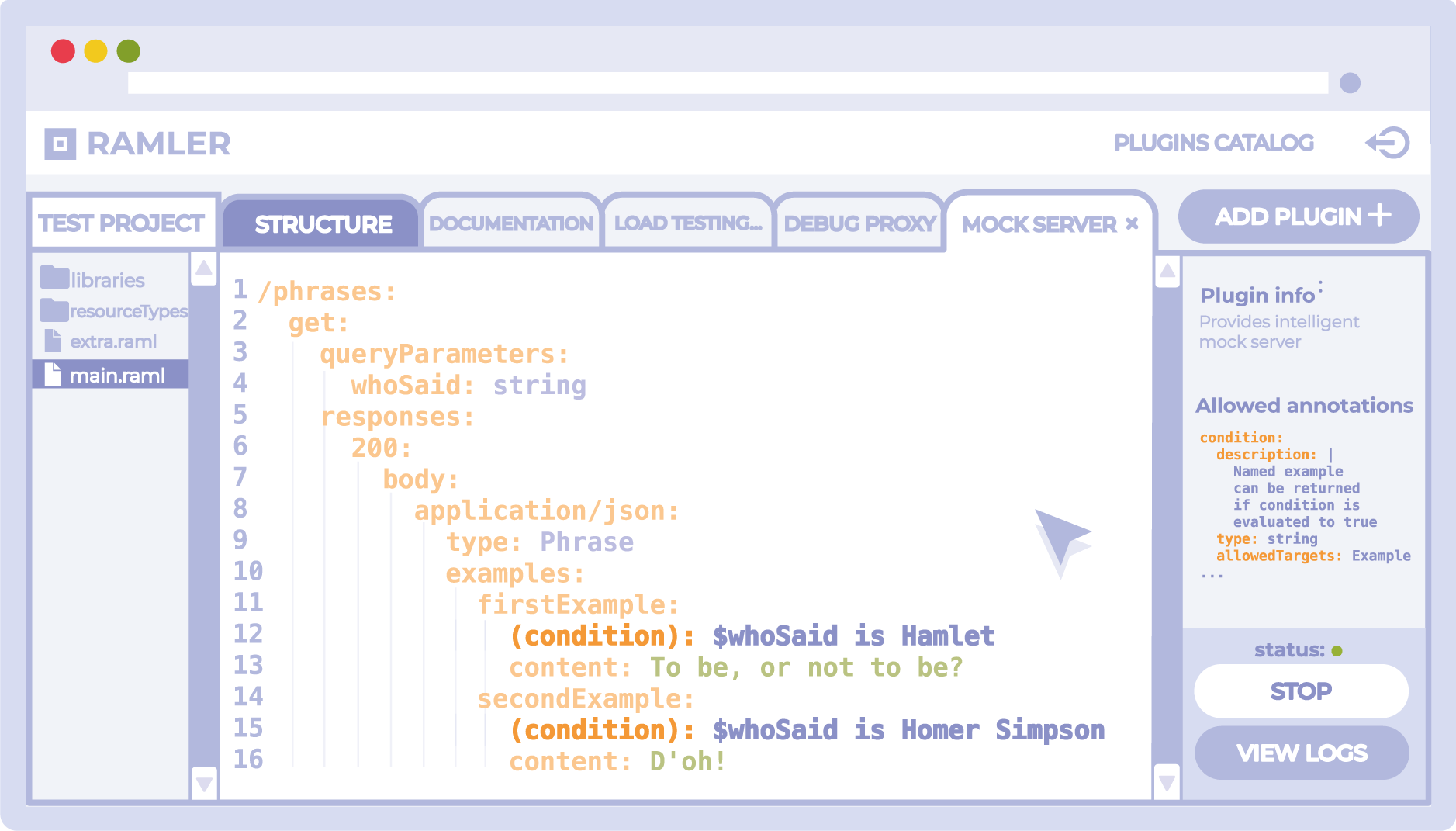
Techniquement, chaque onglet sera une abstraction de la superposition RAML contenant des annotations de chaque plugin spécifique. Cela garantit que la spécification est compatible avec tout outil prenant en charge RAML 1.0.
Le répertoire du plugin doit être ouvert pour expansion par la communauté open source. Il est également possible d'implémenter des plug-ins payants, ce qui peut servir d'incitation au développement de nouveaux.
Plugins possibles: documentation API avec prise en charge d'un grand nombre d'annotations pour un paramétrage flexible de son rendu, serveur factice «intelligent» (de l'exemple ci-dessus), bibliothèques téléchargeables pour valider les requêtes ou la génération de code, outils de débogage pour les requêtes API sortantes pour les applications mobiles (proxy de mise en cache), tests de charge avec la mise en place de tests de flux à travers des annotations, divers plugins pour l'intégration avec des services externes.
Cette idée du service présente des avantages évidents par rapport aux services existants pour la gestion des spécifications de l'API, et sa mise en œuvre ouvre la voie à un changement possible dans l'approche de la mise en œuvre de tout système externe qui est en quelque sorte lié à l'API.
Deuxième conclusion
Le but de cet article n'est pas de critiquer Swagger, Apiary ou d'autres outils standard de facto pour développer des API, mais plutôt d'examiner la différence conceptuelle avec l'approche des spécifications de conception promue par RAML, d'essayer d'abord d'introduire le concept de
contrat et d'envisager la possibilité de sa mise en œuvre basée sur RAML. Un autre objectif était le désir d'attirer l'attention bien méritée des développeurs sur RAML pour le développement ultérieur possible de sa communauté.
Site officiel RAMLCanal détenduSpécificationMerci de votre attention.