Salut Habr, nous voulons parler de l'un des projets de la School of Programmers HeadHunter 2018. Ci-dessous, un article de notre diplômé dans lequel il parlera de l'expérience acquise au cours de la formation.

Bonjour à tous. Cette année, j'ai obtenu mon diplôme de la hh School of Programmers et dans cet article, je parlerai du projet de formation auquel j'ai participé. Pendant l'entraînement à l'école, et surtout sur le projet, il me manquait un exemple d'application de combat (et encore mieux un guide), dans lequel je pouvais voir comment séparer correctement la logique et construire une architecture évolutive. Tous les articles que j'ai trouvés étaient difficiles à comprendre pour un débutant, car soit IoC y était activement utilisé sans explications complètes sur la façon d'ajouter de nouveaux composants ou de modifier d'anciens, soit ils étaient archaïques et contenaient une tonne de configurations xml et un frontend jsp. J'ai essayé de me concentrer sur mon niveau avant l'entraînement, c'est-à-dire presque zéro avec quelques mises en garde, cet article devrait donc être utile aux futurs étudiants de l'école, ainsi qu'aux amateurs autodidactes qui ont décidé de commencer à écrire en java.
Étant donné (énoncé du problème)
Équipe - 5 personnes. La durée est de 3 mois, à la fin de chacun il y a une démo. L'objectif est de créer une application qui aide les RH à accompagner les employés en période d'essai, en automatisant tous les processus qui en découlent. À l'entrée, on nous a dit comment la période de probation (IP) est désormais organisée: dès qu'il est connu qu'un nouvel employé sort, les RH commencent à donner des coups de pied au futur leader pour définir des tâches pour l'IP, et cela doit être fait avant le premier jour ouvrable. Le jour où l'employé se rend au travail, les RH organisent une réunion de bienvenue, parlent de l'infrastructure de l'entreprise et confient les tâches de propriété intellectuelle. Après 1,5 et 3 mois, une réunion intermédiaire et finale des RH, du leader et de l'employé est organisée, au cours de laquelle le succès du passage est discuté et un formulaire de résultats est établi. En cas de succès, après la réunion finale, l'employé reçoit un questionnaire imprimé pour un novice (questions dans le style de "jouir du plaisir de la PI") et obtient une tâche RH pour jira à remettre à l'employé de VHI.
La conception
Nous avons décidé de créer pour chaque employé une page personnelle sur laquelle seront affichées les informations générales (nom, département, responsable, etc.), un champ de commentaires et historique des modifications, des fichiers joints (tâches sur l'IP, questionnaire) et un flux de travail des employés reflétant niveau de passage de la PI. Le workflow a été décidé de se diviser en 8 étapes, à savoir:
- Étape 1 - ajouter un employé: elle se termine immédiatement après l'enregistrement d'un nouvel employé dans le système des RH. Dans le même temps, trois calendriers sont envoyés aux RH pour un puits, une réunion intermédiaire et finale.
- 2ème étape - coordination des tâches sur IP: un formulaire est envoyé au chef d'établissement des tâches sur IP, que les RH recevront après remplissage. Ensuite, HR les imprime, les signe et marque la fin de l'étape de l'interface.
- 3ème étape - réunion d'accueil: HR organise une réunion et appuie sur le bouton «Étape terminée».
- 4ème étape - réunion intérimaire: similaire à la troisième étape
- La 5e étape - les résultats d'une réunion intérimaire: les ressources humaines remplissent les résultats sur la page de l'employé et cliquent sur «Suivant».
- 6ème étape - réunion finale: similaire à la troisième étape
- 7ème étape - résultats de la réunion finale: similaire à la cinquième étape
- 8ème étape - achèvement de la PI: en cas de réussite de la PI, l'employé recevra un lien avec le formulaire du questionnaire par e-mail, et en jira une tâche d'enregistrement de l'assurance médicale volontaire sera automatiquement créée (nous avons obtenu la tâche à la main).
Toutes les étapes ont du temps, après quoi l'étape est considérée comme expirée et est surlignée en rouge, et une notification arrive par la poste. L'heure de fin doit être modifiable, par exemple, dans le cas où la réunion intérimaire tombe un jour férié ou pour une raison quelconque, la réunion doit être reportée.
Malheureusement, les prototypes dessinés sur un morceau de papier / carton n'ont pas été conservés, mais à la fin il y aura des captures d'écran de l'application terminée.
Fonctionnement
L'un des objectifs de l'école est de préparer les élèves à travailler dans de grands projets, donc le processus de libération des tâches nous convenait.
À la fin du travail sur la tâche, nous le donnons pour révision_1 à un autre étudiant de l'équipe afin de corriger des erreurs évidentes / échanger des expériences. Vient ensuite review_2 - la tâche est vérifiée par deux mentors qui s'assurent que nous ne libérons pas le govnokod en paire avec le reviewer_1. Des tests supplémentaires étaient supposés, mais cette étape n'est pas très appropriée, étant donné l'ampleur du projet d'école. Donc, après avoir passé en revue la revue, nous pensions que la tâche était prête à être publiée.
Maintenant, quelques mots sur le déploiement. L'application doit être disponible à tout moment sur le réseau depuis n'importe quel ordinateur. Pour ce faire, nous avons acheté une machine virtuelle bon marché (pour 100 roubles / mois), mais, comme je l'ai découvert plus tard, tout pouvait être organisé gratuitement et de manière à la mode dans le docker AWS . Pour une intégration continue, nous avons choisi Travis. Si quelqu'un ne le sait pas (je n'ai personnellement jamais entendu parler de l'intégration continue avant l'école), c'est une chose tellement cool que votre github surveillera et lorsqu'un nouveau commit apparaît (comment configurer) recueillez le code dans le bocal, envoyez-le au serveur et redémarrez l'application automatiquement. Comment le construire est décrit dans le Travis Jam à la racine du projet, il est assez similaire à bash, donc je pense qu'aucun commentaire n'est requis. Nous avons également acheté le domaine www.adaptation.host afin de ne pas enregistrer une adresse IP laide dans la barre d'adresse de la démo. Nous avons également configuré postfix (pour l'envoi de courrier), apache (pas nginx, car apache était prêt à l'emploi) et le serveur jira (version d'essai). Le frontend et le backend ont été créés par deux services distincts qui communiqueront via http (# 2k18, # microservices). Cette partie de l'article «à la HeadHunter School of Programmers» se termine en douceur, et nous passons au service de repos java.
Backend
0. Introduction
Nous avons utilisé les technologies suivantes:
- JDK 1.8;
- Maven 3.5.2;
- Postgres 9,6;
- Hibernate 5.2.10;
- Jetée 9.4.8;
- Maillot 2.27.
En tant que framework, nous avons pris NaB 3.5.0 de hh. Premièrement, il est utilisé dans HeadHunter, et deuxièmement, il contient des jetons, jersey, hibernate, postgres intégrés hors de la boîte, qui est écrit sur le github. Je vais clarifier brièvement pour les débutants: jetty est un serveur Web qui identifie les clients et organise des sessions pour chacun d’eux; jersey - un cadre qui aide à créer facilement un service RESTful; hibernate - ORM pour simplifier le travail avec la base de données; maven est un collectionneur de projets java.
Je vais montrer un exemple simple de la façon de travailler avec cela. J'ai créé un petit référentiel de test , dans lequel j'ai ajouté deux entités: un utilisateur et un CV, ainsi que des ressources pour les créer et les recevoir avec le lien OneToMany / ManyToOne. Pour commencer, clonez simplement le référentiel et exécutez mvn clean install exec: java à la racine du projet. Avant de commenter le code, je vais vous parler de la structure de notre service. Cela ressemble à ceci:
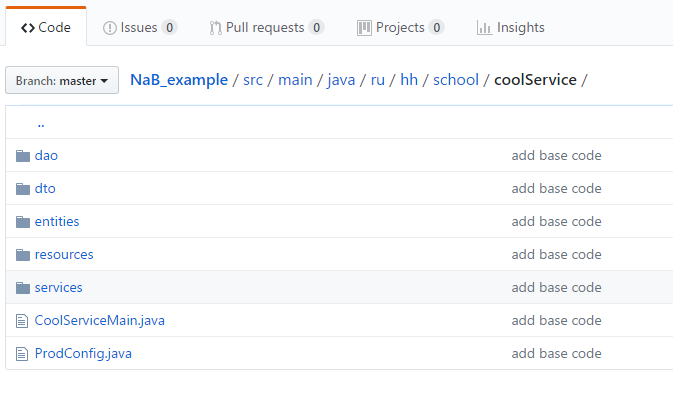
Répertoires principaux:
- Services - le répertoire principal de l'application, toute la logique métier est stockée ici. Dans d'autres endroits, travailler avec des données sans raison valable ne devrait pas l'être.
- Ressources - gestionnaires d'url, une couche entre les services et le frontend. La validation des données entrantes et la conversion des données sortantes, mais pas la logique métier, sont autorisées ici.
- Dao (Data Access Object) - une couche entre la base de données et les services. Tao ne doit contenir que des opérations de base fondamentales: ajouter, compter, mettre à jour, supprimer une / toutes.
- Entité - objets qu'ORM échange avec la base de données. En règle générale, ils correspondent directement aux tables et doivent contenir tous les champs en tant qu'entité dans la base de données avec les types correspondants.
- Dto (Data Transfer Object) - un analogue de l'entité, uniquement pour les ressources (avant), aide à former json à partir des données que nous voulons envoyer / recevoir.
1. Base
Dans le bon sens, vous devriez utiliser les postgres installés à proximité, comme dans l'application principale, mais je voulais que le cas de test soit simple et exécuté avec une seule commande, j'ai donc pris le HSQLDB intégré. La connexion de la base de données à notre infrastructure se fait en ajoutant une DataSource à ProdConfig (n'oubliez pas non plus de dire à hibernate la base de données que vous utilisez):
@Bean(destroyMethod = "shutdown") DataSource dataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.HSQL) .addScript("db/sql/create-db.sql") .build(); }
J'ai créé le script de création de table dans le fichier create-db.sql. Vous pouvez ajouter d'autres scripts qui initialisent la base de données. Dans notre exemple léger in_memory, nous pourrions nous passer de scripts. Si vous spécifiez hibernate.hbm2ddl.auto=create dans les paramètres hibernate.properties, hibernate lui-même créera des tables par entité au démarrage de l'application. Mais si vous avez besoin de quelque chose dans la base de données que l'entité ne possède pas, vous ne pouvez pas vous passer d'un fichier. Personnellement, j'ai l'habitude de partager la base de données et l'application, donc je n'ai généralement pas confiance en hibernation pour faire de telles choses.
db/sql/create-db.sql :
CREATE TABLE employee ( id INTEGER IDENTITY PRIMARY KEY, first_name VARCHAR(256) NOT NULL, last_name VARCHAR(256) NOT NULL, email VARCHAR(128) NOT NULL ); CREATE TABLE resume ( id INTEGER IDENTITY PRIMARY KEY, employee_id INTEGER NOT NULL, position VARCHAR(128) NOT NULL, about VARCHAR(256) NOT NULL, FOREIGN KEY (employee_id) REFERENCES employee(id) );
2. Entité
entities/employee :
@Entity @Table(name = "employee") public class Employee { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id", nullable = false) private Integer id; @Column(name = "first_name", nullable = false) private String firstName; @Column(name = "last_name", nullable = false) private String lastName; @Column(name = "email", nullable = false) private String email; @OneToMany(mappedBy = "employee") @OrderBy("id") private List<Resume> resumes;
entities/resume :
@Entity @Table(name = "resume") public class Resume { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "employee_id") private Employee employee; @Column(name = "position", nullable = false) private String position; @Column(name = "about") private String about;
Les entités ne se réfèrent pas les unes aux autres avec le champ de classe, mais avec l'objet parent / enfant entier. Ainsi, nous pouvons obtenir une récursivité lorsque nous essayons de prendre à partir de la base de données des employés, pour laquelle des CV sont dessinés, pour lesquels ... Pour éviter que cela ne se produise, nous avons indiqué les annotations @OneToMany(mappedBy = "employee") et @ManyToOne(fetch = FetchType.LAZY) . Ils seront pris en compte dans le service lors de l'exécution d'une transaction d'écriture / lecture à partir de la base de données. La configuration de FetchType.LAZY est facultative, mais l'utilisation d'une communication paresseuse facilite la transaction. Donc, si dans une transaction, nous obtenons un CV de la base de données et ne contactons pas son propriétaire, l'entité employé ne sera pas chargée. Vous pouvez le vérifier vous-même: supprimez FetchType.LAZY et voyez dans le débogage qu'il revient du service avec le CV. Mais vous devez être prudent - si nous n'avons pas chargé d'employé dans la transaction, l'accès aux champs d'employé en dehors de la transaction peut provoquer une LazyInitializationException .
3. Dao
Dans notre cas, EmployeeDao et ResumeDao sont presque identiques, donc je ne donnerai ici qu'un seul d'entre eux
EmployeeDao :
public class EmployeeDao { private final SessionFactory sessionFactory; @Inject public EmployeeDao(SessionFactory sessionFactory) { this.sessionFactory = sessionFactory; } public void save(Employee employee) { sessionFactory.getCurrentSession().save(employee); } public Employee getById(Integer id) { return sessionFactory.getCurrentSession().get(Employee.class, id); } }
L' @Inject signifie que dans le constructeur de notre dao, l'injection de dépendance est utilisée. Dans ma vie passée, un physicien qui a morcelé des fichiers, construit des graphiques basés sur les résultats des nombres et, à tout le moins, compris OOP, dans les guides java, de telles constructions semblaient quelque peu folles. Et à l'école, peut-être, ce sujet est le plus évident, à mon humble avis. Heureusement, il y a beaucoup de matériel sur DI sur Internet. Si vous êtes trop paresseux pour lire, alors le premier mois, vous pouvez suivre la règle: enregistrer de nouvelles ressources / services / Tao dans notre configuration de contexte , ajouter des entités au mappage . Si vous devez utiliser certains services / tao dans d'autres, vous devez les ajouter dans le constructeur avec l'injection d'annotation, comme indiqué ci-dessus, et le ressort initialise tout pour vous. Mais alors vous devez toujours faire face à DI.
4. Dto
Dto, comme dao, sont presque identiques pour l'employé et le curriculum vitae. Nous considérons uniquement employeeDto ici. Nous aurons besoin de deux classes: EmployeeCreateDto , nécessaire lors de la création d'un employé; EmployeeDto utilisé à la réception (contient des champs supplémentaires id et resumes ). Le champ id est ajouté afin qu'à l'avenir, à la demande de l'extérieur, nous puissions travailler avec l'employé sans effectuer une recherche préliminaire de l'entité par email . Le champ resumes pour recevoir un employé avec tous ses CV en une seule demande. Il serait possible de gérer avec un dto pour toutes les opérations, mais pour la liste de tous les CV d'un employé particulier, nous devions créer une ressource supplémentaire, comme getResumesByEmployeeEmail, polluer le code avec des requêtes de base de données personnalisées et biffer toutes les commodités fournies par ORM.
EmployeeCreateDto :
public class EmployeeCreateDto { public String firstName; public String lastName; public String email; }
EmployeeDto :
public class EmployeeDto { public Integer id; public String firstName; public String lastName; public String email; public List<ResumeDto> resumes; public EmployeeDto(){ } public EmployeeDto(Employee employee){ id = employee.getId(); firstName = employee.getFirstName(); lastName = employee.getLastName(); email = employee.getEmail(); if (employee.getResumes() != null) { resumes = employee.getResumes().stream().map(ResumeDto::new).collect(Collectors.toList()); } } }
Encore une fois, j'attire l'attention sur le fait que l'écriture de la logique en dto est si indécente que tous les champs sont désignés comme public , afin de ne pas utiliser les getters et les setters.
5. Service
EmployeeService :
public class EmployeeService { private EmployeeDao employeeDao; private ResumeDao resumeDao; @Inject public EmployeeService(EmployeeDao employeeDao, ResumeDao resumeDao) { this.employeeDao = employeeDao; this.resumeDao = resumeDao; } @Transactional public EmployeeDto createEmployee(EmployeeCreateDto employeeCreateDto) { Employee employee = new Employee(); employee.setFirstName(employeeCreateDto.firstName); employee.setLastName(employeeCreateDto.lastName); employee.setEmail(employeeCreateDto.email); employeeDao.save(employee); return new EmployeeDto(employee); } @Transactional public ResumeDto createResume(ResumeCreateDto resumeCreateDto) { Resume resume = new Resume(); resume.setEmployee(employeeDao.getById(resumeCreateDto.employeeId)); resume.setPosition(resumeCreateDto.position); resume.setAbout(resumeCreateDto.about); resumeDao.save(resume); return new ResumeDto(resume); } @Transactional(readOnly = true) public EmployeeDto getEmployeeById(Integer id) { return new EmployeeDto(employeeDao.getById(id)); } @Transactional(readOnly = true) public ResumeDto getResumeById(Integer id) { return new ResumeDto(resumeDao.getById(id)); } }
Ces transactions qui nous protègent de LazyInitializationException (et pas seulement). Pour comprendre les transactions en veille prolongée, je recommande un excellent travail sur le hub (en savoir plus ... ), ce qui m'a beaucoup aidé en temps voulu.
6. Ressources
Enfin, ajoutez les ressources pour créer et obtenir nos entités:
EmployeeResource :
@Path("/") @Singleton public class EmployeeResource { private final EmployeeService employeeService; public EmployeeResource(EmployeeService employeeService) { this.employeeService = employeeService; } @GET @Produces("application/json") @Path("/employee/{id}") @ResponseBody public Response getEmployee(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getEmployeeById(id)) .build(); } @POST @Produces("application/json") @Path("/employee/create") @ResponseBody public Response createEmployee(@RequestBody EmployeeCreateDto employeeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createEmployee(employeeCreateDto)) .build(); } @GET @Produces("application/json") @Path("/resume/{id}") @ResponseBody public Response getResume(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getResumeById(id)) .build(); } @POST @Produces("application/json") @Path("/resume/create") @ResponseBody public Response createResume(@RequestBody ResumeCreateDto resumeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createResume(resumeCreateDto)) .build(); } }
Produces(“application/json”) nécessaires pour que json et dto soient correctement convertis l'un à l'autre. Il nécessite une dépendance pom.xml:
<dependency> <groupId>org.glassfish.jersey.media</groupId> <artifactId>jersey-media-json-jackson</artifactId> <version>${jersey.version}</version> </dependency>
D'autres convertisseurs json exposent pour une raison quelconque MediaType non valide.
7. Résultat
Exécutez et vérifiez ce que nous avons ( mvn clean install exec:java à la racine du projet). Le port sur lequel l'application s'exécute est spécifié dans service.properties . Créez un utilisateur et reprenez. Je le fais avec curl, mais vous pouvez utiliser postman si vous méprisez la console.
curl --header "Content-Type: application/json" \ --request POST \ --data '{"firstName": "Jason", "lastName": "Statham", "email": "jasonst@t.ham"}' \ http://localhost:9999/employee/create curl --header "Content-Type: application/json" \ --request POST \ --data '{"employeeId": 0, "position": "Voditel", "about": "Opyt raboty perevozchikom 15 let"}' \ http://localhost:9999/resume/create curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0 curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0
Tout fonctionne bien. Nous avons donc un backend qui fournit une API. Vous pouvez maintenant démarrer le service avec l'interface et dessiner les formulaires correspondants. Il s'agit d'une bonne base pour une application que vous pouvez utiliser pour démarrer la vôtre en configurant divers composants au fur et à mesure du développement du projet.
Conclusion
Le code de l' application principale est maintenu en état de marche sur le github avec des instructions pour démarrer dans l'onglet wiki.
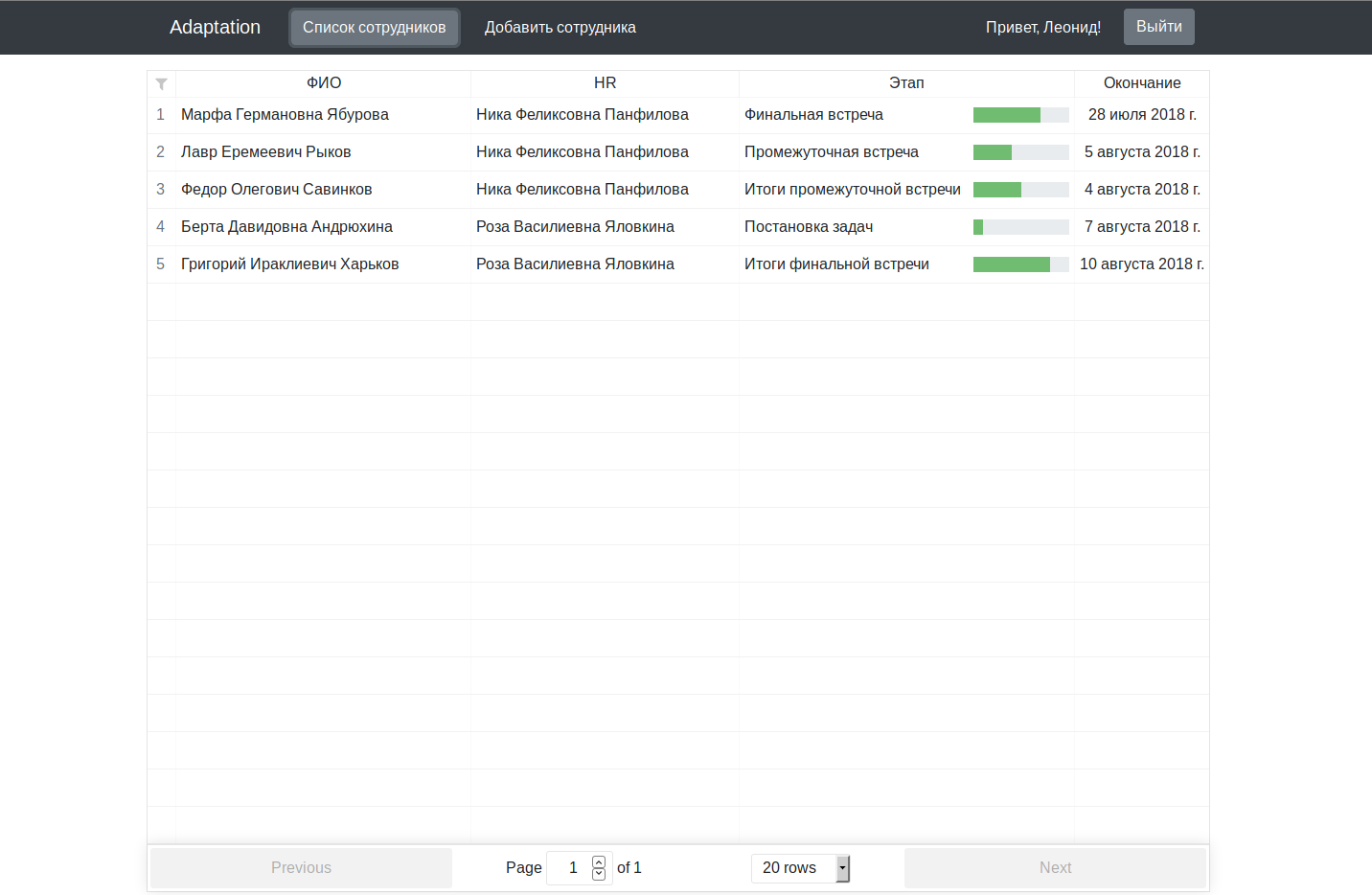
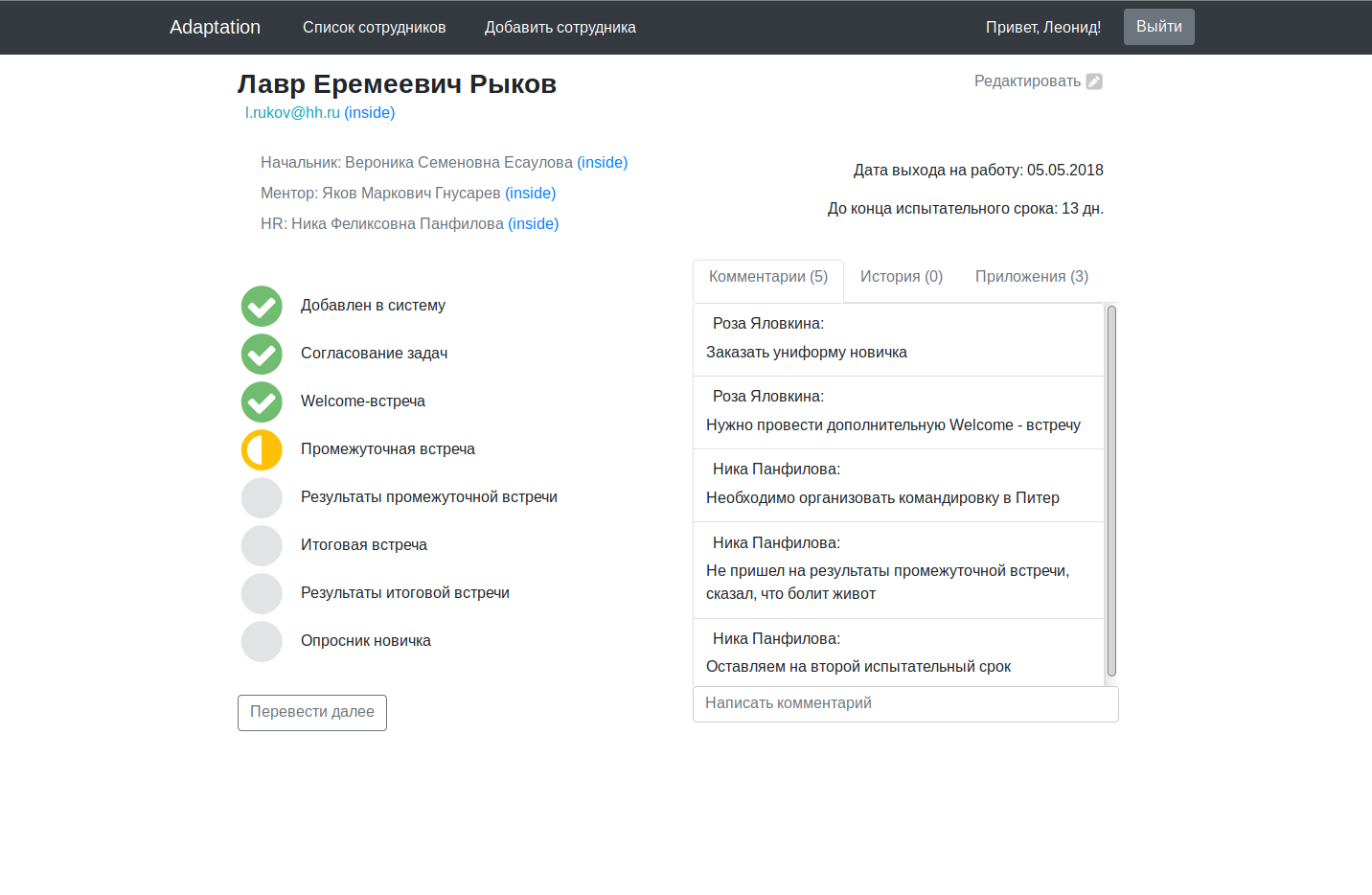
Pour un projet de plusieurs millions de dollars, ça a l'air un peu humide, bien sûr, mais comme excuse, je vous rappelle que nous y avons travaillé le soir, après le travail / les études.
Si le nombre de personnes intéressées dépasse le nombre de pantoufles, je pourrai à l'avenir en faire une série d'articles où je parlerai du front, de la dockérisation et des nuances que nous avons rencontrées lorsque nous travaillions avec des fichiers mail / fat / dock.
PS Après un certain temps après avoir survécu au choc de l'école, le reste de l'équipe s'est réunie et, après avoir analysé les vols, a décidé de faire l'adaptation 2.0, en tenant compte de toutes les erreurs. L'objectif principal du projet est le même: apprendre à créer des applications sérieuses, à construire une architecture réfléchie et à être recherché par les spécialistes du marché. Vous pouvez suivre le travail dans le même référentiel. Les demandes de piscine sont les bienvenues. Merci de votre attention et bonne chance!
petits pains
conférence vidéo hoc du CIO