Contrairement à la croyance populaire, l'apprentissage automatique n'est pas une invention du 21e siècle. Au cours des vingt dernières années, seules des plates-formes matérielles suffisamment productives sont apparues pour qu'il soit conseillé d'utiliser des réseaux de neurones et d'autres modèles d'apprentissage automatique pour résoudre tous les problèmes appliqués au quotidien. Les implémentations logicielles d'algorithmes et de modèles ont également été renforcées.
La tentation de faire en sorte que les machines assurent elles-mêmes notre sécurité et protègent les personnes (plutôt paresseuses, mais intelligentes) est devenue trop grande. Selon
CB Insights, près de 90 startups (dont 2 avec une estimation de plus d'un milliard de dollars américains) tentent d'automatiser au moins une partie des tâches routinières et monotones. Avec un succès variable.

Le principal problème de
l'intelligence artificielle en matière de sécurité en ce moment est trop de battage médiatique et de conneries marketing franches. L'expression «intelligence artificielle» attire les investisseurs. Les gens viennent dans l'industrie et sont prêts à appeler l'IA la corrélation d'événements la plus simple. Les acheteurs de solutions pour leur propre argent n'obtiennent pas ce qu'ils espéraient (même si ces attentes étaient initialement trop élevées).

Comme on peut le voir sur la carte CB Insights, il existe des dizaines de zones où MO est utilisé. Mais l'apprentissage automatique n'est pas encore devenu la «pilule magique» de la cybersécurité en raison de plusieurs limitations sérieuses.
La première limitation est l'applicabilité étroite de la fonctionnalité de chaque modèle particulier. Un réseau de neurones peut bien faire une chose. S'il reconnaît bien les images, le même réseau ne pourra pas reconnaître le son. La même chose avec la sécurité de l'information, si le modèle a été formé pour classer les événements des capteurs réseau et détecter les attaques informatiques sur les équipements réseau, il ne pourra pas fonctionner avec des appareils mobiles, par exemple. Si le client est un fan de l'IA, il achètera, achètera et achètera.
La deuxième limitation est le manque de données de formation. Les solutions sont pré-formées, mais pas sur vos données. Si la situation «Qui considère un faux positif au cours des deux premières semaines de fonctionnement» peut encore être acceptée, alors à l'avenir il y aura une légère perplexité du «personnel de sécurité», car ils ont acheté une décision pour que la machine reprenne la routine, et non l'inverse.

La troisième et probablement la plus importante à ce jour est que les produits MO ne peuvent pas être tenus pour responsables de leurs décisions. Même le développeur d'un «moyen de protection unique grâce à l'intelligence artificielle» peut répondre à de telles affirmations: «Eh bien, que vouliez-vous? Un réseau de neurones est une boîte noire! Pourquoi a-t-elle décidé de cette façon, personne sauf elle ne le sait. » Par conséquent, les gens confirment désormais les incidents de sécurité des informations. Les machines aident, mais les gens sont toujours responsables.
Il y a des problèmes avec la protection des informations. Ils seront résolus tôt ou tard. Mais qu'en est-il de l'attaque? Le MO et l'IA peuvent-ils devenir la «solution miracle» des cyberattaques?
Options d'utilisation de l'apprentissage automatique pour augmenter les chances de réussite ou d'analyse de sécurité
Probablement, maintenant il est plus rentable d'utiliser MO où:
- vous devez créer quelque chose de similaire à ce que le réseau neuronal a déjà rencontré;
- il est nécessaire d'identifier des modèles qui ne sont pas évidents pour l'homme.
Le MO fait déjà très bien dans ces tâches. Mais en plus de cela, certaines tâches peuvent être accélérées. Par exemple, mes collègues ont déjà écrit sur l'
automatisation des attaques en utilisant python et metasploit .
Essayer de tromper
Ou vérifiez la sensibilisation des employés aux problèmes de sécurité de l'information. Comme le montre notre pratique de tests de pénétration, l'ingénierie sociale fonctionne - dans presque tous les projets où une telle attaque a été menée, nous avons réussi.
Supposons que nous ayons déjà restauré en utilisant des méthodes traditionnelles (site Web de l'entreprise, réseaux sociaux, sites d'emploi, publications, etc.):
- structure organisationnelle;
- liste des employés clés;
- Modèles d'adresse e-mail ou adresses réelles
- téléphoné, fait semblant d'être un client potentiel, a découvert le nom du vendeur, directeur, secrétaire.
Ensuite, nous devons obtenir des données afin de former un réseau de neurones qui imitera la voix d'une personne particulière. Dans notre cas, quelqu'un de la direction de l'entreprise testée. Cet
article déclare qu'une minute de voix suffit pour faire semblant authentique.
Nous recherchons des enregistrements de discours lors de conférences, nous les consultons nous-mêmes et les enregistrons, nous essayons de parler avec la personne dont nous avons besoin. Si nous parvenons à imiter une voix, nous pouvons créer nous-mêmes une situation stressante pour une victime spécifique de l'attaque.
- Bonjour?
- Vendeur Preseylovich, bonjour. Voici le directeur Nachalnikovich. Votre téléphone mobile ne répond pas. Là, vous recevrez maintenant une lettre de Vector-Fake LLC, veuillez voir. C'est urgent!
"Oui, mais ..."
- Voilà, je ne peux plus parler. Je suis en réunion. Avant la communication. Réponds-leur!
Qui ne répondra pas? Qui ne verra pas l'attachement? Tout le monde verra. Et vous pouvez tout charger dans cette lettre. Dans le même temps, il n'est pas nécessaire de connaître le numéro de téléphone du réalisateur ou le numéro de téléphone personnel du vendeur; il n'est pas nécessaire de truquer une adresse e-mail sur une adresse d'entreprise interne d'où proviendra un e-mail malveillant.
Soit dit en passant, la préparation des attaques (collecte et analyse des données) peut également être partiellement automatisée. Nous sommes à la recherche d'un
développeur dans une équipe qui résout un tel problème et crée un progiciel qui facilite la vie d'un analyste dans le domaine de la veille concurrentielle et de la sécurité économique d'une entreprise.
Nous attaquons l'implémentation des cryptosystèmes
Supposons que nous puissions écouter le trafic chiffré de l'organisation attaquée. Mais nous aimerions savoir quoi exactement dans ce trafic. Cette recherche des employés de Cisco «
Détection de code malveillant dans le trafic TLS chiffré (sans déchiffrement) » est venue avec l'idée. En effet, si nous pouvons déterminer la présence d'objets malveillants sur la base des données des données de service NetFlow, TLS et DNS, qu'est-ce qui nous empêche d'utiliser les mêmes données pour identifier les communications entre les employés de l'organisation attaquée et entre les employés et les services informatiques de l'entreprise?
Attaquer une crypte sur le front coûte plus cher. Par conséquent, en utilisant des données sur les adresses et les ports de la source et de la destination, le nombre de paquets transmis et leur taille, les paramètres temporels, nous essayons de déterminer le trafic chiffré.
De plus, après avoir déterminé des passerelles cryptographiques ou des nœuds finaux dans le cas des communications p2p, nous commençons à les terminer, forçant les utilisateurs à passer à des méthodes de communication moins sécurisées et plus faciles à attaquer.
Le charme de la méthode comporte deux avantages:
- La machine peut être entraînée à domicile, sur virtualochki. Il existe de nombreux produits gratuits et même open source pour créer des communications sécurisées. «Machine, tel est tel ou tel protocole, il a telle ou telle taille de paquet, telle ou telle entropie. Comprenez-vous? Tu te souviens? " Répétez autant de fois que possible sur différents types de données ouvertes.
- Pas besoin de "piloter" et de passer à travers le modèle tout le trafic, juste des métadonnées suffisent.
Inconvénient - MitM doit encore être reçu.
Recherche de bogues logiciels et de vulnérabilités
La tentative d'automatisation de la recherche, de l'exploitation et de la correction des vulnérabilités est probablement le DARPA Cyber Grand Challenge. En 2016, sept systèmes entièrement automatiques conçus par différentes équipes se sont réunis lors de la bataille finale de type CTF. Bien sûr, l'objectif du développement a été déclaré exclusivement bon - protéger les infrastructures, l'iot, les applications en temps réel et avec une participation minimale des personnes. Mais vous pouvez regarder les résultats sous un angle différent.
La première direction dans laquelle l'OM se développe dans ce domaine est l'automatisation du fuzzing. Les mêmes membres de la CCG ont largement utilisé le lop flou américain. Selon le réglage, les fuzzers génèrent plus ou moins de sortie pendant le fonctionnement. Là où il y a beaucoup de données structurées et faiblement structurées, les modèles MO recherchent parfaitement les modèles. Si la tentative de «suppression» de l'application a fonctionné avec une entrée, il est possible que cette approche fonctionne ailleurs.
Il en va de même pour l'analyse de code statique et l'analyse dynamique des fichiers exécutables lorsque le code source de l'application n'est pas disponible. Les réseaux de neurones peuvent rechercher non seulement des morceaux de code avec des vulnérabilités, mais aussi du code qui semble vulnérable. Heureusement, il y a beaucoup de code avec des vulnérabilités confirmées (et corrigées). Le chercheur devra vérifier ce soupçon. Avec chaque nouveau bug trouvé, un tel NS deviendra de plus en plus «plus intelligent». Grâce à cette approche, vous pouvez éviter d'utiliser uniquement des signatures pré-écrites.
En analyse dynamique, si un réseau de neurones peut «comprendre» la relation entre les données d'entrée (y compris les données utilisateur), l'ordre d'exécution, les appels système, l'allocation de mémoire et les vulnérabilités confirmées, il peut éventuellement en rechercher de nouvelles.
Automatiser le fonctionnement
Maintenant, avec un fonctionnement purement automatique, il y a un problème -
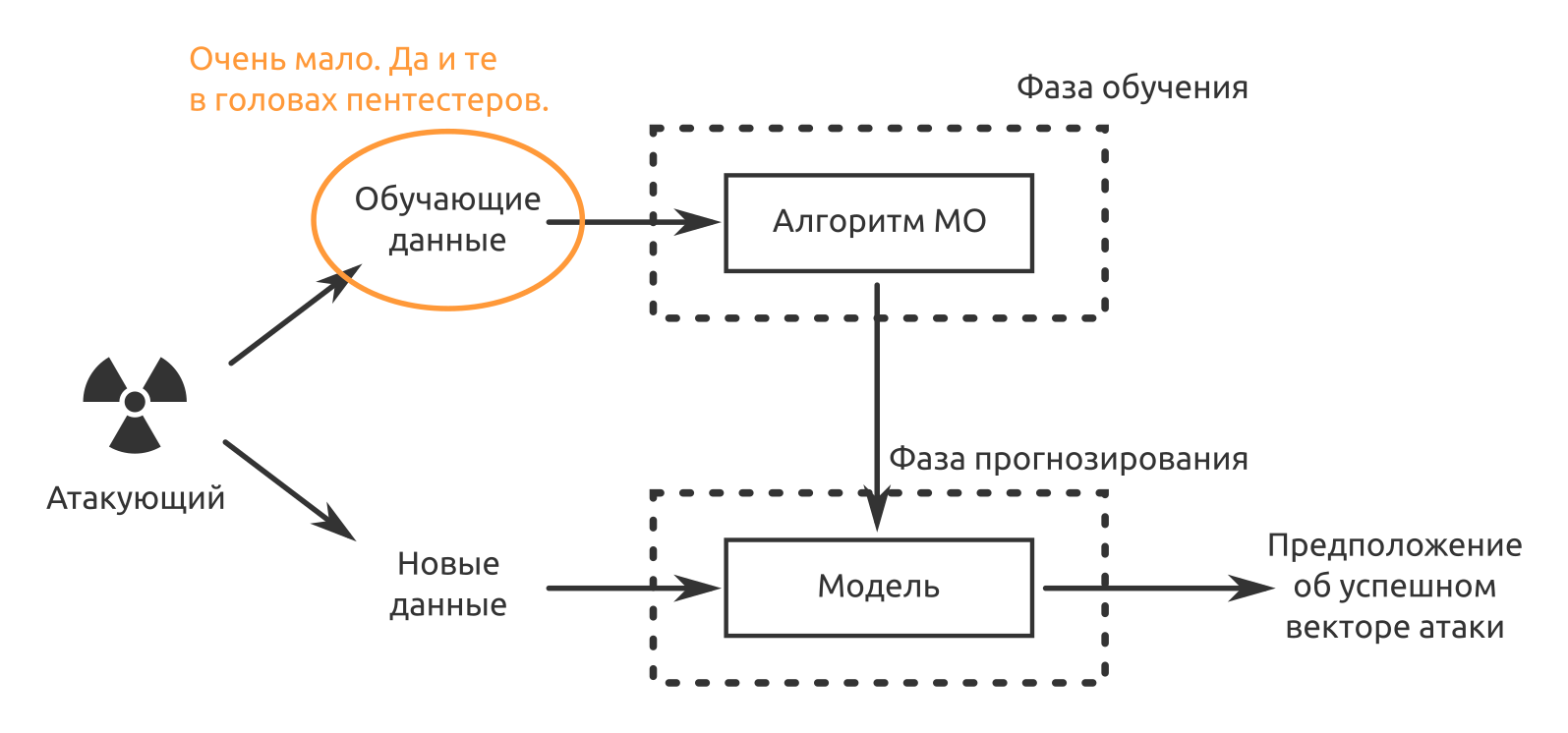
Isao Takaesu et les autres contributeurs qui développent Deep Exploit, «Outil de test de pénétration entièrement automatique utilisant le Machine Learning», tentent de le résoudre. Des détails à son sujet sont écrits
ici et
ici .
Cette solution peut fonctionner en deux modes - le mode de collecte de données et le mode de force brute.
Dans le premier mode, DE identifie tous les ports ouverts sur l'hôte attaqué et lance des exploits qui fonctionnaient auparavant pour une telle combinaison.
Dans le deuxième mode, l'attaquant indique le nom du produit et le numéro de port, et DE "frappe par zone" en utilisant toutes les combinaisons disponibles de l'exploit, de la charge utile et de la cible.
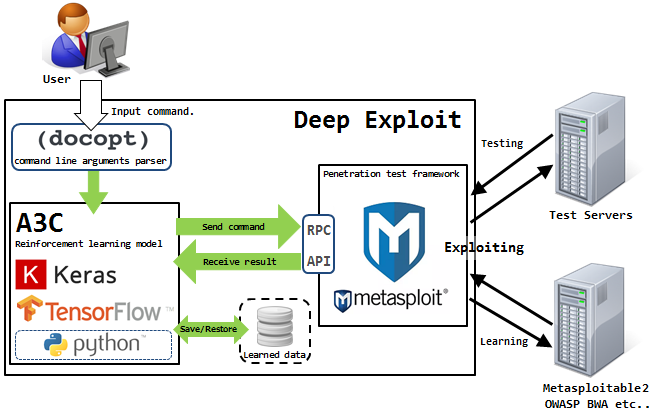
Deep Exploit peut apprendre indépendamment des méthodes opérationnelles en utilisant une formation renforcée (grâce aux commentaires que DE reçoit du système attaqué).
L'IA peut-elle remplacer l'équipe Pentester maintenant?
Probablement
pas encore.
Les machines ont des problèmes avec la construction de chaînes logiques d'exploitation des vulnérabilités identifiées. Mais c'est précisément ce qui affecte souvent directement la réalisation de l'objectif des tests de pénétration. Une machine peut trouver une vulnérabilité, elle peut même créer un exploit à elle seule, mais elle ne peut pas évaluer le degré d'impact de cette vulnérabilité sur un système d'information spécifique, des ressources d'information ou des processus métier de l'organisation dans son ensemble.
Le fonctionnement des systèmes automatisés génère BEAUCOUP de bruit sur le système attaqué, qui est facilement remarqué par les équipements de protection. Les voitures fonctionnent maladroitement. Il est possible de réduire ce bruit et de se faire une idée du système à l'aide de l'ingénierie sociale, et avec cela les machines ne sont pas non plus très bonnes.
Et les voitures n'ont aucune ingéniosité et aucun sens. Nous avons récemment eu un projet où la façon la plus rentable d'effectuer des tests serait d'utiliser un modèle radiocommandé. Je ne peux pas imaginer comment une non-personne pourrait penser à une telle chose.
Quelles idées d'automatisation pourriez-vous proposer?