
Bon après-midi Je voudrais parler de l'architecture des applications embarquées. Malheureusement, il existe très peu de livres sur ce sujet, et en raison du fait que, récemment, l'intérêt pour l'embarqué et l'IoT se développe, je veux prêter attention à cette question. Dans cet article, je voudrais décrire l'une des options possibles pour la conception de telles applications.
C'est une question discutable! Par conséquent, ils proposent de partager leur vision dans les commentaires!
Pour commencer, nous déterminerons le domaine: dans le cadre de cet article, par développement embarqué, nous entendons le développement de logiciels pour microcontrôleurs (ci-après MK, par exemple STM32) en langage C / Asm.
Les projets pour les systèmes basés sur MK peuvent être conditionnellement divisés en
ceux qui ne nécessitent pas et
nécessitent le multitâche. Quant aux solutions du premier type, elles sont généralement peu complexes (d'un point de vue structurel). Par exemple, un projet simple, dans lequel il est nécessaire de lire les données du capteur et de les afficher à l'écran, ne nécessite pas de multitâche; ici, il suffit de mettre en œuvre l'exécution séquentielle des opérations ci-dessus.
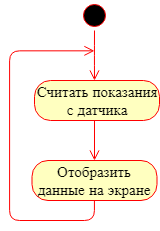
Si l'application est plus complexe: dans le cadre de laquelle il est nécessaire de lire des données à la fois de capteurs numériques et analogiques, de sauvegarder les valeurs obtenues en mémoire (par exemple, sur une carte SD), de maintenir l'interface utilisateur (écran + clavier), et de donner accès aux données via une interface numérique (par exemple, RS-485 / Modbus ou Ethernet / TCP / IP) et réagir le plus rapidement possible à certains événements du système (en appuyant sur les boutons d'urgence, etc.), dans ce cas, il sera difficile de se passer du multitâche. Il existe deux façons de résoudre le problème du multitâche: l'implémenter vous-même ou utiliser une sorte de système d'exploitation (ci-après dénommé le système d'exploitation). Aujourd'hui, l'un des systèmes d'exploitation en temps réel les plus populaires pour les systèmes embarqués est FreeRTOS.
Essayons d’imaginer à quoi devrait ressembler l’architecture d’une application embarquée «complexe» qui effectue un nombre assez important d’opérations hétérogènes. J'admets qu'il est possible de proposer une option encore plus compliquée, qui implique de résoudre des problèmes de traitement du son, de cryptographie, etc., mais nous nous attarderons sur l'option qui vient d'être décrite ci-dessus.
Nous fixons la tâche plus clairement, même si dans le cadre de notre application il faut:
- Lisez les données des capteurs sur le RS-485 / Modbus.
- Lisez les données des capteurs sur le bus I2C.
- Lisez les données des entrées numériques.
- Sortie relais de contrôle.
- Maintenir l'interface utilisateur (écran + clavier).
- Fournissez l'accès aux données via RS-485 / Modbus.
- Enregistrez les données sur un support externe.
Parce que nous devons implémenter un nombre suffisamment important de sous-tâches différentes, nous utiliserons le système d'exploitation en temps réel (par exemple, le FreeRTOS déjà mentionné) comme base. Les threads dans le système d'exploitation seront parfois appelés tâches - similaires à FreeRTOS. Je veux vous avertir tout de suite: il n'y aura pas de code source dans l'article, c'est l'aspect architectural de ce numéro qui est intéressant.
Si nous analysons la tâche, nous pouvons voir que différents composants du système utilisent les mêmes données. Par exemple: les données des capteurs doivent être obtenues, affichées sur un écran, écrites sur un support et fournies à des systèmes externes pour lecture. Cela suggère qu'une sorte de base de données en temps réel (RTDB) est nécessaire pour stocker et fournir les données les plus pertinentes à divers sous-systèmes.
Les tâches effectuées dans le système (lecture de données, écriture, affichage, etc.) peuvent avoir des exigences différentes quant à la fréquence de leur appel. Cela n'a aucun sens de mettre à jour les données sur l'affichage avec une fréquence de 1 fois par 100 ms, car ce n'est pas critique pour une personne, mais il est souvent nécessaire de lire les données des capteurs (surtout s'il est nécessaire de leur donner des actions de contrôle) (bien que cela ne soit pas possible selon les savoirs traditionnels). Un autre point important concerne la résolution du problème d'accès aux mêmes données pour la lecture et l'écriture. Par exemple: un flux interrogeant les capteurs écrit les valeurs reçues sur RTDB, et à ce moment le flux chargé de mettre à jour les informations sur l'écran les lit. Ici, les mécanismes de synchronisation fournis par le système d'exploitation nous aideront.
Commençons à concevoir l'architecture de notre application!
Base de données en temps réel

Une structure ordinaire contenant l'ensemble nécessaire de champs ou un tableau peut servir de telle base. Pour accéder à «RTDB», nous utiliserons l'API, qui nous permettra d'écrire et de lire les données de la base de données. La synchronisation de l'accès aux données à l'intérieur des fonctions API peut être construite sur les mutex fournis par le système d'exploitation (ou utiliser un autre mécanisme).

Travailler avec des capteurs sur les pneus
Travailler avec des capteurs implique ce qui suit:
- lire des données;
- le traitement des données (si nécessaire), qui comprend:
- contrôle de validation;
- mise à l'échelle
- filtrage
- validation de valeurs valides;
- enregistrement des données reçues dans RTDB.
Tout ce travail peut être effectué en une seule tâche.
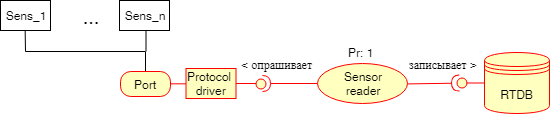
«Port» - le vrai port de MK;
«Pilote de protocole» - pilote de protocole (par exemple, Modbus). Pour un tel pilote, il est conseillé de faire votre interface et de la travailler. Dans le cadre d'une telle interface, il est possible de mettre en œuvre un contrôle d'accès à la ressource via des mutex, comme cela a été fait pour «RTDB». Certains développeurs proposent de le faire au niveau du port, pour être sûr que personne d'autre n'écrira quoi que ce soit sur ce port pendant que nous transmettons nos paquets Modbus via celui-ci.
«Lecteur de capteur» - une tâche (tâche), qui interroge les capteurs, range les informations reçues et les écrit dans «RTDB».
«RTDB» est la base de données en temps réel décrite ci-dessus dans la section correspondante.
L'inscription «Pr: 1» sur la tâche signifie la priorité, le résultat est que chaque tâche peut avoir la priorité si deux tâches en attente de temps processeur ont des priorités différentes, la ressource recevra celle avec la priorité la plus élevée. Si les tâches ont la même priorité, celle avec le temps d'attente le plus long sera lancée.
Travailler avec des entrées discrètes
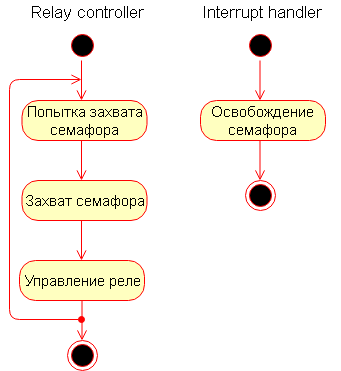
En général, le travail avec les entrées numériques peut être organisé de la même manière qu'avec les capteurs numériques. Mais il peut être nécessaire de réagir rapidement aux changements d'état des entrées. Par exemple, au toucher d'un bouton, fermez la sortie relais le plus rapidement possible. Dans ce cas, il est préférable d'utiliser l'approche suivante: pour traiter la sortie relais, nous créons une tâche séparée spéciale avec une priorité plus élevée que les autres. À l'intérieur de cette tâche se trouve un sémaphore qu'il tente de capturer. Une interruption est déclenchée pour déclencher une entrée numérique particulière, dans laquelle le sémaphore mentionné ci-dessus est réinitialisé. Parce que la priorité d'interruption est maximale, puis la fonction qui lui est associée sera exécutée presque instantanément, dans notre cas, elle réinitialisera le sémaphore, et après cela, la prochaine tâche dans la file d'attente d'exécution sera celle dans laquelle le relais est contrôlé (car il a la priorité est plus élevée que les autres tâches et le verrou sur l'attente du sémaphore est supprimé).
Voilà à quoi peut ressembler le schéma de ce sous-système.

En plus de la réponse rapide pour changer l'état d'une entrée spécifique, vous pouvez en outre définir la tâche «Lecteur DI» pour lire l'état des entrées discrètes. Cette tâche peut être indépendante ou appelée par minuterie.
Le travail du «gestionnaire d'interruption» et du «contrôleur de relais» sous forme de diagrammes est présenté ci-dessous.
Écriture de données sur un support externe
L'écriture de données sur un support externe est idéologiquement très similaire à la lecture de données à partir de capteurs numériques, seul le mouvement des données est effectué dans la direction opposée.

Nous lisons à partir de «RTDB» et écrivons à travers le «pilote de magasin» sur un support externe - il peut s'agir d'une carte SD, d'une clé USB ou autre chose. Encore une fois, n'oubliez pas de mettre des wrappers mutex (ou tout autre outil pour organiser l'accès à la ressource) dans les fonctions d'interface!
Fournir un accès aux données en temps réel
Un point important est la fourniture de données de «RTDB» à des systèmes externes. Il peut s'agir de presque toutes les interfaces et tous les protocoles. Contrairement à un certain nombre de sous-systèmes considérés, la principale différence est que certains des protocoles largement utilisés dans les systèmes d'automatisation ont des exigences particulières pour le temps de réponse à la demande, si la réponse n'arrive pas dans un certain délai, alors il est considéré qu'il n'y a pas communication, même s'il (la réponse) viendra après un certain temps. Et depuis l'accès à «RTDB» dans notre exemple peut être temporairement bloqué (par mutex), il est nécessaire de protéger le dispositif maître externe (le maître est un dispositif qui essaie de lire les données du nôtre) contre un tel blocage. Il convient également de considérer la protection de l'appareil lui-même du fait que le maître l'interrogera à haute fréquence, inhibant ainsi le fonctionnement du système par une lecture constante de "RTDB". Une solution consiste à utiliser un tampon intermédiaire.
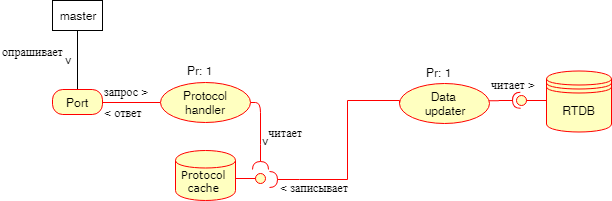
Le «Data Updater» lit les données de «RTDB» à une fréquence donnée et ajoute ce qu'il a lu dans le «Protocol cache», à partir duquel le «Protocol handler» récupérera les données. Dans ce cas, il y a un problème de blocage au niveau du cache de protocole, pour le résoudre, vous pouvez créer un autre cache dans lequel le «gestionnaire de protocole» stockera des données au cas où il ne pourrait pas lire à partir du «cache de protocole» bloqué, vous pouvez en outre:
- faire du «gestionnaire de protocole» une priorité plus élevée;
- augmenter la période de lecture de «RTDB» pour «Data Updater» (qui est une solution médiocre).
Travailler avec l'interface utilisateur
Travailler avec l'interface utilisateur implique de mettre à jour les données à l'écran et de travailler avec le clavier. L'architecture de ce sous-système peut ressembler à ceci.

L'intervenant UI est responsable de la lecture des frappes, de la prise des données de «RTDB» et de la mise à jour de l'affichage que l'utilisateur voit.
Structure générale du système
Jetez maintenant un œil à ce qui s'est finalement passé.

Afin d'équilibrer la charge, vous pouvez définir des caches supplémentaires, comme nous l'avons fait dans le sous-système chargé de fournir l'accès à ces systèmes externes. Certaines tâches de transfert de données peuvent être résolues à l'aide de files d'attente, car elles sont généralement prises en charge par les systèmes d'exploitation en temps réel (à coup sûr, dans FreeRTOS).
C'est tout, j'espère que c'était intéressant.
PSEn tant que littérature, je recommanderais «Créer des systèmes embarqués: modèles de conception pour de grands logiciels» Elecia White et des articles d'
Andrey Kournits «FreeRTOS - un système d'exploitation pour les microcontrôleurs»