Dans le cas de l'organisation de microservices de l'application, un travail important repose sur les mécanismes de communication d'intégration des microservices. De plus, cette intégration doit être tolérante aux pannes, avec un haut degré de disponibilité.
Dans nos solutions, nous utilisons l'intégration avec Kafka, gRPC et RabbitMQ.
Dans cet article, nous partagerons notre expérience du clustering RabbitMQ, dont les nœuds sont hébergés sur Kubernetes.

Avant RabbitMQ version 3.7, le clustering dans K8S n'était pas une tâche très triviale, avec de nombreux hacks et des solutions pas très belles. Dans la version 3.6, un plugin d'autocluster de RabbitMQ Community a été utilisé. Et dans 3.7 Kubernetes Peer Discovery Backend est apparu. Il est intégré par le plug-in dans la livraison de base de RabbitMQ et ne nécessite pas d'assemblage et d'installation séparés.
Nous décrirons la configuration finale dans son ensemble, tout en commentant ce qui se passe.
En théorie
Le plugin a un
référentiel sur le github , dans lequel il y a
un exemple d'utilisation de base .
Cet exemple n'est pas destiné à la production, ce qui est clairement indiqué dans sa description, et de plus, certains des paramètres qu'il contient sont définis contrairement à la logique d'utilisation dans le prod. De plus, dans l'exemple, la persistance du stockage n'est pas du tout mentionnée, donc dans toute situation d'urgence, notre cluster se transformera en zilch.
En pratique
Nous allons maintenant vous dire à quoi vous avez fait face et comment installer et configurer RabbitMQ.
Décrivons les configurations de toutes les parties de RabbitMQ en tant que service dans les K8. Nous préciserons immédiatement que nous avons installé RabbitMQ dans les K8 en tant que StatefulSet. Sur chaque nœud du cluster K8s, une instance de RabbitMQ fonctionnera toujours (un nœud dans la configuration de cluster classique). Nous installerons également le panneau de contrôle RabbitMQ dans les K8 et donnerons accès à ce panneau en dehors du cluster.
Droits et rôles:
rabbitmq_rbac.yaml--- apiVersion: v1 kind: ServiceAccount metadata: name: rabbitmq --- kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader subjects: - kind: ServiceAccount name: rabbitmq roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: endpoint-reader
Les droits d'accès pour RabbitMQ sont entièrement tirés de l'exemple, aucune modification n'y est requise. Nous créons un ServiceAccount pour notre cluster et lui accordons des autorisations de lecture aux points de terminaison K8.
Stockage persistant:
rabbitmq_pv.yaml kind: PersistentVolume apiVersion: v1 metadata: name: rabbitmq-data-sigma labels: type: local annotations: volume.alpha.kubernetes.io/storage-class: rabbitmq-data-sigma spec: storageClassName: rabbitmq-data-sigma capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Recycle hostPath: path: "/opt/rabbitmq-data-sigma"
Ici, nous avons pris le cas le plus simple comme le stockage persistant - hostPath (un dossier normal sur chaque nœud K8s), mais vous pouvez utiliser n'importe lequel des nombreux types de volumes persistants pris en charge par K8s.
rabbitmq_pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: rabbitmq-data spec: storageClassName: rabbitmq-data-sigma accessModes: - ReadWriteMany resources: requests: storage: 10Gi
Créez une revendication de volume sur le volume créé à l'étape précédente. Cette revendication sera ensuite utilisée dans StatefulSet en tant que magasin de données persistantes.
Services:
rabbitmq_service.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq-internal labels: app: rabbitmq spec: clusterIP: None ports: - name: http protocol: TCP port: 15672 - name: amqp protocol: TCP port: 5672 selector: app: rabbitmq
Nous créons un service interne sans tête à travers lequel le plugin Peer Discovery fonctionnera.
rabbitmq_service_ext.yaml kind: Service apiVersion: v1 metadata: name: rabbitmq labels: app: rabbitmq type: LoadBalancer spec: type: NodePort ports: - name: http protocol: TCP port: 15672 targetPort: 15672 nodePort: 31673 - name: amqp protocol: TCP port: 5672 targetPort: 5672 nodePort: 30673 selector: app: rabbitmq
Pour que les applications des K8 fonctionnent avec notre cluster, nous créons un service d'équilibrage.
Puisque nous avons besoin d'accéder au cluster RabbitMQ en dehors des K8, nous parcourons NodePort. RabbitMQ sera disponible lors de l'accès à n'importe quel nœud du cluster K8 sur les ports 31673 et 30673. Dans le travail réel, cela n'est pas vraiment nécessaire. La question de la commodité de l'utilisation du panneau d'administration RabbitMQ.
Lors de la création d'un service avec le type NodePort dans K8s, un service avec le type ClusterIP est également implicitement créé pour le servir. Par conséquent, les applications des K8 qui doivent fonctionner avec notre RabbitMQ pourront accéder au cluster sur
amqp: // rabbitmq: 5672Configuration:
rabbitmq_configmap.yaml apiVersion: v1 kind: ConfigMap metadata: name: rabbitmq-config data: enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s]. rabbitmq.conf: | cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443 ### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true cluster_partition_handling = autoheal queue_master_locator=min-masters cluster_formation.randomized_startup_delay_range.min = 0 cluster_formation.randomized_startup_delay_range.max = 2 cluster_formation.k8s.service_name = rabbitmq-internal cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Nous créons des fichiers de configuration RabbitMQ. La magie principale.
enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s].
Ajoutez les plugins nécessaires à ceux autorisés pour le téléchargement. Nous pouvons maintenant utiliser la détection automatique des pairs dans le K8S.
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s
Nous exposons le plugin nécessaire en tant que backend pour la découverte des pairs.
cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443
Spécifiez l'adresse et le port par lesquels vous pouvez atteindre kubernetes apiserver. Ici, vous pouvez spécifier directement l'adresse IP, mais ce sera plus beau de le faire.
Dans l'espace de noms par défaut, un service est généralement créé avec le nom kubernetes menant à k8-apiserver. Dans différentes options d'installation de K8S, l'espace de noms, le nom du service et le port peuvent être différents. Si quelque chose dans une installation particulière est différent, vous devez le corriger en conséquence.
Par exemple, nous sommes confrontés au fait que dans certains clusters, le service est sur le port 443 et dans certains sur 6443. Il sera possible de comprendre que quelque chose ne va pas dans les journaux de démarrage de RabbitMQ, le temps de connexion à l'adresse spécifiée ici y est clairement mis en évidence.
### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname
Par défaut, l'exemple a spécifié le type d'adresse du nœud de cluster RabbitMQ par adresse IP. Mais lorsque vous redémarrez le pod, il obtient à chaque fois une nouvelle adresse IP. Surprise! La grappe se meurt dans l'agonie.
Modifiez l'adressage en nom d'hôte. StatefulSet nous garantit l'invariabilité du nom d'hôte dans le cycle de vie de l'ensemble StatefulSet, ce qui nous convient parfaitement.
cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true
Puisque lorsque nous perdons l'un des nœuds, nous supposons qu'il se rétablira tôt ou tard, nous désactivons l'auto-suppression par un cluster de nœuds inaccessibles. Dans ce cas, dès que le nœud revient en ligne, il entre dans le cluster sans perdre son état précédent.
cluster_partition_handling = autoheal
Ce paramètre détermine les actions du cluster en cas de perte de quorum. Ici, il vous suffit de lire la
documentation sur ce sujet et de comprendre par vous-même ce qui se rapproche le plus d'un cas d'utilisation spécifique.
queue_master_locator=min-masters
Déterminez la sélection de l'assistant pour les nouvelles files d'attente. Avec ce paramètre, l'Assistant sélectionnera le nœud avec le moins de files d'attente, afin que les files d'attente soient réparties uniformément sur les nœuds du cluster.
cluster_formation.k8s.service_name = rabbitmq-internal
Nous nommons le service K8 sans tête (créé par nous plus tôt) à travers lequel les nœuds RabbitMQ communiqueront entre eux.
cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.local
Un nom important pour l'adressage dans un cluster est le nom d'hôte. Le FQDN du foyer K8s est formé comme un nom court (rabbitmq-0, rabbitmq-1) + suffixe (partie de domaine). Ici, nous indiquons ce suffixe. Dans K8S, il ressemble à
. <Nom du service>. <Nom de l'espace de noms> .svc.cluster.localkube-dns résout les noms de la forme rabbitmq-0.rabbitmq-internal.our-namespace.svc.cluster.local en l'adresse IP d'un pod spécifique sans aucune configuration supplémentaire, ce qui rend toute la magie du regroupement par nom d'hôte possible.
Configuration de StatefulSet RabbitMQ:
rabbitmq_statefulset.yaml apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: rabbitmq spec: serviceName: rabbitmq-internal replicas: 3 template: metadata: labels: app: rabbitmq annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } } spec: serviceAccountName: rabbitmq terminationGracePeriodSeconds: 10 containers: - name: rabbitmq-k8s image: rabbitmq:3.7 volumeMounts: - name: config-volume mountPath: /etc/rabbitmq - name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia ports: - name: http protocol: TCP containerPort: 15672 - name: amqp protocol: TCP containerPort: 5672 livenessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 60 periodSeconds: 10 timeoutSeconds: 10 readinessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 10 periodSeconds: 10 timeoutSeconds: 10 imagePullPolicy: Always env: - name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local" - name: K8S_SERVICE_NAME value: "rabbitmq-internal" - name: RABBITMQ_ERLANG_COOKIE value: "mycookie" volumes: - name: config-volume configMap: name: rabbitmq-config items: - key: rabbitmq.conf path: rabbitmq.conf - key: enabled_plugins path: enabled_plugins - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
En fait, StatefulSet lui-même. Nous notons des points intéressants.
serviceName: rabbitmq-internal
Nous écrivons le nom du service sans tête via lequel les pods communiquent dans StatefulSet.
replicas: 3
Définissez le nombre de répliques dans le cluster. Nous l'avons égal au nombre de nœuds de travail K8.
annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } }
Lorsque l'un des nœuds K8 tombe, le jeu avec état cherche à conserver le nombre d'instances dans l'ensemble, par conséquent, il crée plusieurs foyers sur le même nœud K8. Ce comportement est totalement indésirable et, en principe, inutile. Par conséquent, nous prescrivons une règle anti-affinité pour les ensembles de foyers à partir d'un état. Nous rendons la règle difficile (obligatoire) afin que le planificateur de kube ne puisse pas la casser lors de la planification des pods.
L'essence est simple: il est interdit au planificateur de placer (dans l'espace de noms) plus d'un pod avec la
balise app: rabbitmq sur chaque nœud. Nous distinguons les
nœuds par la valeur de l'étiquette
kubernetes.io/hostname . Maintenant, si pour une raison quelconque, le nombre de nœuds K8S actifs est inférieur au nombre requis de répliques dans StatefulSet, de nouvelles répliques ne seront pas créées jusqu'à ce qu'un nœud libre réapparaisse.
serviceAccountName: rabbitmq
Nous enregistrons ServiceAccount, sous lequel nos pods fonctionnent.
image: rabbitmq:3.7
L'image de RabbitMQ est complètement standard et est prise à partir du hub docker; elle ne nécessite aucune reconstruction ni révision de fichier.
- name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia
Les données persistantes de RabbitMQ sont stockées dans / var / lib / rabbitmq / mnesia. Ici, nous montons notre revendication de volume persistant dans ce dossier afin que lors du redémarrage des foyers / nœuds ou même de l'ensemble StatefulSet, les données (à la fois le service, y compris sur le cluster assemblé et les données utilisateur) soient saines et saines. Il existe des exemples où le dossier / var / lib / rabbitmq / est rendu persistant. Nous sommes arrivés à la conclusion que ce n'était pas la meilleure idée, car en même temps toutes les informations définies par les configurations Rabbit commencent à être mémorisées. Autrement dit, pour modifier quelque chose dans le fichier de configuration, vous devez nettoyer le stockage persistant, ce qui est très gênant en fonctionnement.
- name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local"
Avec cet ensemble de variables d'environnement, nous demandons d'abord à RabbitMQ d'utiliser le nom FQDN comme identifiant pour les membres du cluster, et deuxièmement, nous définissons le format de ce nom. Le format a été décrit précédemment lors de l'analyse de la configuration.
- name: K8S_SERVICE_NAME value: "rabbitmq-internal"
Nom du service sans tête pour la communication entre les membres du cluster.
- name: RABBITMQ_ERLANG_COOKIE value: "mycookie"
Le contenu du cookie Erlang doit être le même sur tous les nœuds du cluster, vous devez enregistrer votre propre valeur. Un nœud avec un cookie différent ne peut pas entrer dans le cluster.
volumes: - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-data
Définissez le volume mappé à partir de la revendication de volume persistant précédemment créée.
C'est là que nous en avons terminé avec la configuration des K8. Le résultat est un cluster RabbitMQ, qui répartit uniformément les files d'attente entre les nœuds et résiste aux problèmes de l'environnement d'exécution.
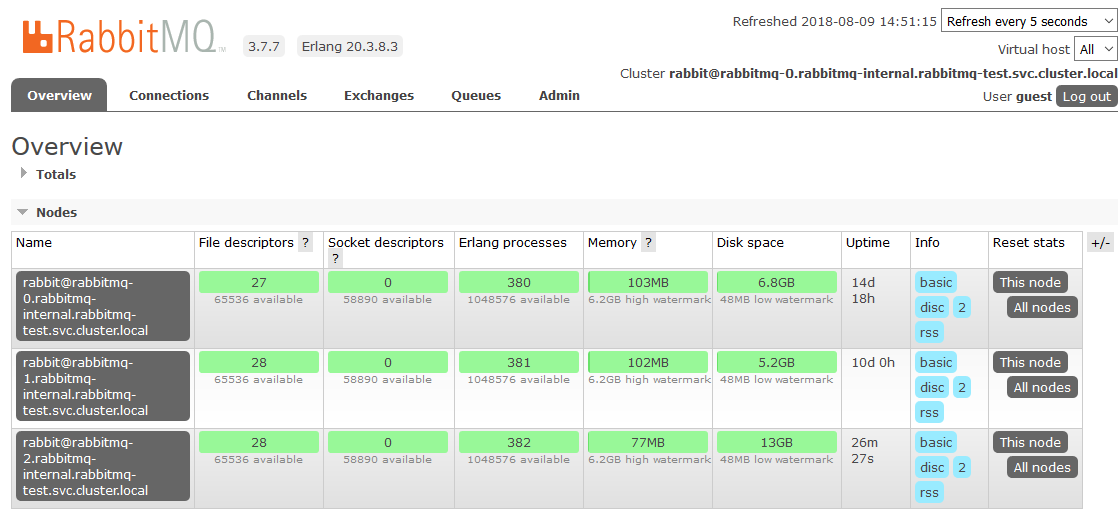
Si l'un des nœuds du cluster n'est pas disponible, les files d'attente qu'il contient cesseront d'être accessibles, tout le reste continuera de fonctionner. Dès que le nœud sera de nouveau opérationnel, il reviendra au cluster et les files d'attente pour lesquelles il était maître redeviendront opérationnelles, en conservant toutes les données qui y sont contenues (si le stockage persistant ne s'est pas cassé, bien sûr). Tous ces processus sont entièrement automatiques et ne nécessitent aucune intervention.
Bonus: personnaliser HA
L'un des projets était une nuance. Les exigences sonnaient une mise en miroir complète de toutes les données contenues dans le cluster. Cela est nécessaire pour que dans une situation où au moins un nœud de cluster est opérationnel, tout continue à fonctionner du point de vue de l'application. Ce moment n'a rien à voir avec les K8, nous le décrivons simplement comme un mini mode d'emploi.
Pour activer la haute disponibilité complète, vous devez créer une stratégie dans le tableau de bord RabbitMQ sur l'onglet
Admin -> Stratégies . Le nom est arbitraire, le modèle est vide (toutes les files d'attente), dans les définitions, ajoutez deux paramètres:
ha-mode: all ,
ha-sync-mode: automatic .
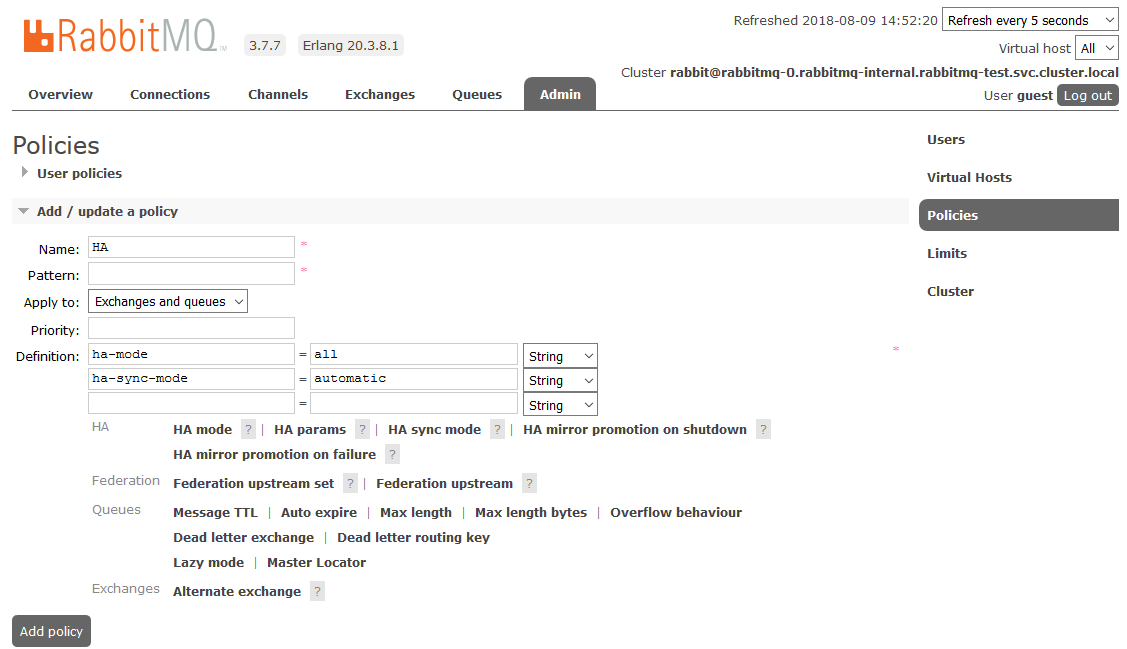
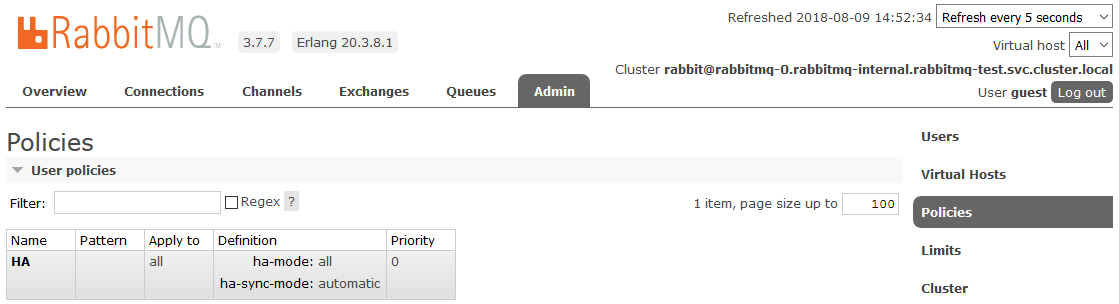
Après cela, toutes les files d'attente créées dans le cluster seront en mode haute disponibilité: si le nœud maître n'est pas disponible, l'un des esclaves sera automatiquement sélectionné par le nouvel assistant. Et les données entrant dans la file d'attente seront reflétées sur tous les nœuds du cluster. Qui, en fait, devait recevoir.
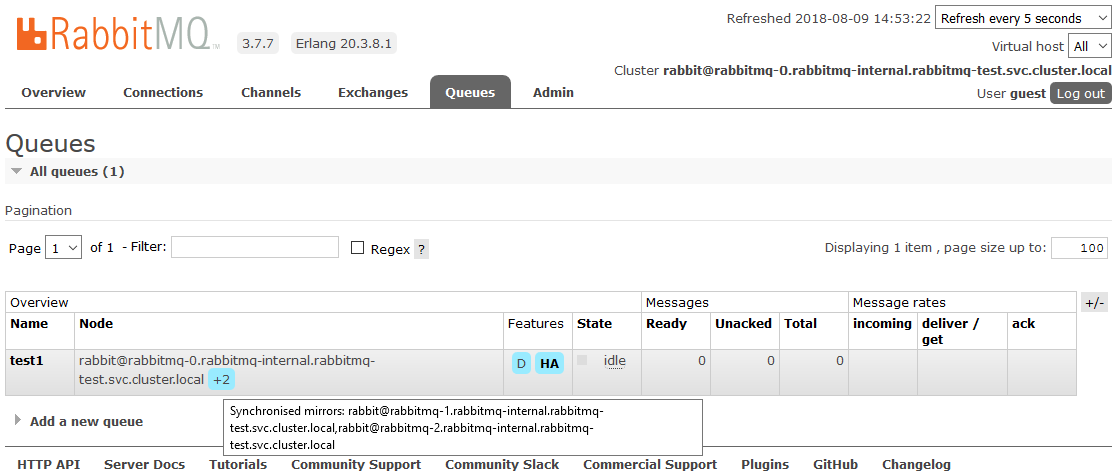
En savoir plus sur HA dans RabbitMQ
iciLittérature utile:
Bonne chance!