Bonjour, Habr! Je vous présente la traduction de l'article "
Détecter le sarcasme avec les réseaux neuronaux convolutionnels profonds " d'Elvis Saravia.
L'un des problèmes clés du traitement du langage naturel est la détection des sarcasmes. La détection du sarcasme est importante dans d'autres domaines, tels que le calcul émotionnel et l'analyse de l'humeur, car cela peut refléter la polarité de la phrase.
Cet article montre comment détecter le sarcasme et fournit également un lien vers un
détecteur de sarcasme de réseau neuronal .
Le sarcasme peut être considéré comme une expression de moquerie ou d'ironie. Exemples de sarcasmes: «Je travaille 40 heures par semaine pour rester pauvre» ou «Si le patient veut vraiment vivre, les médecins sont impuissants».
Pour comprendre et détecter le sarcasme, il est important de comprendre les faits associés à l'événement. Cela révèle une contradiction entre la polarité objective (généralement négative) et les caractéristiques sarcastiques véhiculées par l'auteur (généralement positives).
Prenons l'exemple: «J'aime la douleur de la séparation».
Il est difficile de comprendre le sens s'il y a du sarcasme dans cette déclaration. Dans cet exemple, «j'aime la douleur» donne la connaissance des sentiments exprimés par l'auteur (dans ce cas, positifs), et «se séparer» décrit le sentiment contradictoire (négatif).
D'autres problèmes qui existent dans la compréhension des déclarations sarcastiques sont une référence à plusieurs événements et la nécessité d'extraire un grand nombre de faits, de bon sens et de raisonnement logique.
Modèle
Un «changement d'humeur» est souvent présent dans la communication où il y a du sarcasme; ainsi, il est proposé de préparer d'abord un modèle d'humeur (basé sur CNN) pour extraire les signes d'humeur. Le modèle sélectionne les entités locales dans les premières couches, qui sont ensuite transformées en entités globales à des niveaux supérieurs. Les expressions sarcastiques sont spécifiques à l'utilisateur - certains utilisateurs utilisent plus de sarcasme que d'autres.
Dans le modèle proposé pour la détection du sarcasme, des traits de personnalité, des signes d'humeur et des signes basés sur les émotions sont utilisés. Un ensemble de détecteurs est un cadre conçu pour détecter les sarcasmes. Chaque ensemble d'attributs est étudié par des modèles pré-formés distincts.
Cadre CNN
Les CNN sont efficaces pour modéliser la hiérarchie des entités locales pour mettre en évidence les entités globales, ce qui est nécessaire pour examiner le contexte. Les données d'entrée sont présentées sous forme de vecteurs de mots. Pour le traitement initial des données d'entrée, word2vec de Google est utilisé. Les paramètres des vecteurs sont obtenus au stade de la formation. L'union maximale est ensuite appliquée aux mappes de fonctions pour créer des fonctions. Après la couche entièrement liée, il y a une couche softmax pour obtenir la prédiction finale.
L'architecture est illustrée dans la figure ci-dessous.
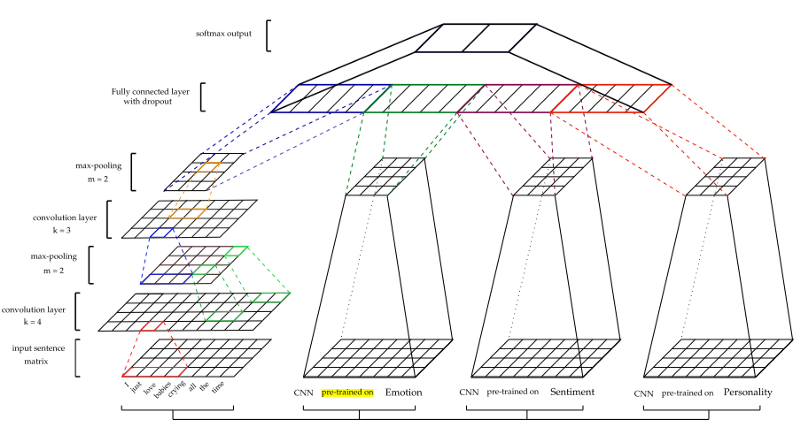
Pour obtenir d'autres caractéristiques - humeur (S), émotion (E) et personnalité (P) - les modèles CNN subissent une formation préliminaire et sont utilisés pour extraire les traits des ensembles de données sur le sarcasme. Pour la formation de chaque modèle, différents ensembles de données de formation ont été utilisés. (Pour plus de détails voir le document)
Deux classificateurs sont testés - classificateur CNN pur (CNN) et caractéristiques extraites CNN transmises au classificateur SVM (CNN-SVM).
Un classificateur de base distinct (B) est également formé, composé uniquement du modèle CNN sans inclure d'autres modèles (par exemple, les émotions et les humeurs).
Les expériences
Données. Des ensembles de données équilibrées et non équilibrées ont été obtenus auprès de (Ptacek et al., 2014) et d'
un détecteur de sarcasme . Les noms d'utilisateur, les URL et les balises de hachage sont supprimés, puis le tokenizer NLTK Twitter est appliqué.
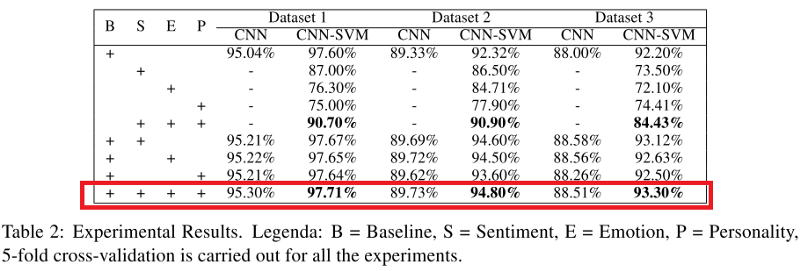
Les métriques du classificateur CNN et CNN-SVM appliquées à tous les ensembles de données sont présentées dans le tableau ci-dessous. Vous remarquerez peut-être que lorsqu'un modèle (en particulier CNN-SVM) combine les signes du sarcasme, les signes des émotions, des sentiments et des traits de caractère, il surpasse tous les autres modèles, à l'exception du modèle de base (B).
Les possibilités de généralisabilité des modèles ont été testées, et la principale conclusion était que si les ensembles de données étaient de nature différente, cela influençait considérablement le résultat, comme le montre la figure ci-dessous. Par exemple, une formation a été dispensée sur l'ensemble de données 1 et testée sur l'ensemble de données 2; Le score F1 du modèle était de 33,05%.