Au sein de l'entreprise, notre équipe de lutte contre les attaques DDoS s'appelle les «droppers de paquets». Alors que toutes les autres équipes font des choses sympas avec le trafic passant par notre réseau, nous nous amusons à trouver de nouvelles façons de s'en débarrasser.
 Photo: Brian Evans , CC BY-SA 2.0
Photo: Brian Evans , CC BY-SA 2.0La possibilité de supprimer rapidement des paquets est très importante pour s'opposer aux attaques DDoS.
Les paquets de dépôt atteignant nos serveurs peuvent être effectués à plusieurs niveaux. Chaque méthode a ses avantages et ses inconvénients. Sous la coupe, nous regardons tout ce que nous avons testé.
Note du traducteur: dans la sortie de certaines des commandes présentées, des espaces supplémentaires ont été supprimés pour maintenir la lisibilité.
Site de test
Pour la commodité de comparer les méthodes, nous vous fournirons quelques chiffres, cependant, ne les prenez pas trop à la lettre, en raison du caractère artificiel des tests. Nous utiliserons l'une de nos cartes réseau Intel 10 Gb / s. Les autres caractéristiques du serveur ne sont pas si importantes, car nous voulons nous concentrer sur les limites du système d'exploitation, pas sur le matériel.
Nos tests se présenteront comme suit:
- Nous créons une charge d'un grand nombre de petits paquets UDP, atteignant une valeur de 14 millions de paquets par seconde;
- Tout ce trafic est dirigé vers un cœur de processeur du serveur sélectionné;
- Nous mesurons le nombre de paquets traités par le noyau sur un seul cœur de processeur.
Le trafic artificiel est généré de manière à créer une charge maximale: une adresse IP aléatoire et un port d'expéditeur sont utilisés. Voici à quoi cela ressemble dans tcpdump:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234 IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16 IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16 IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16 IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16 IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16 IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16 IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16 IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16 IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16 IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
Sur le serveur sélectionné, tous les paquets deviendront dans une file d'attente RX et, par conséquent, seront traités par un cœur. Nous y parvenons grâce au contrôle de flux matériel:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
Les tests de performances sont un processus complexe. Lorsque nous avons préparé les tests, nous avons remarqué que la présence de sockets bruts actifs affecte négativement les performances, donc avant d'exécuter les tests, vous devez vous assurer qu'aucun
tcpdump n'est en cours d'exécution. Il existe un moyen simple de vérifier les mauvais processus:
$ ss -A raw,packet_raw -l -p|cat Netid State Recv-Q Send-Q Local Address:Port p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
Et enfin, nous désactivons Intel Turbo Boost sur notre serveur:
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Malgré le fait que Turbo Boost soit une excellente chose et augmente le débit d'au moins 20%, il gâche considérablement l'écart-type dans nos tests. Avec turbo activé, l'écart atteint ± 1,5%, alors que sans lui seulement 0,25%.
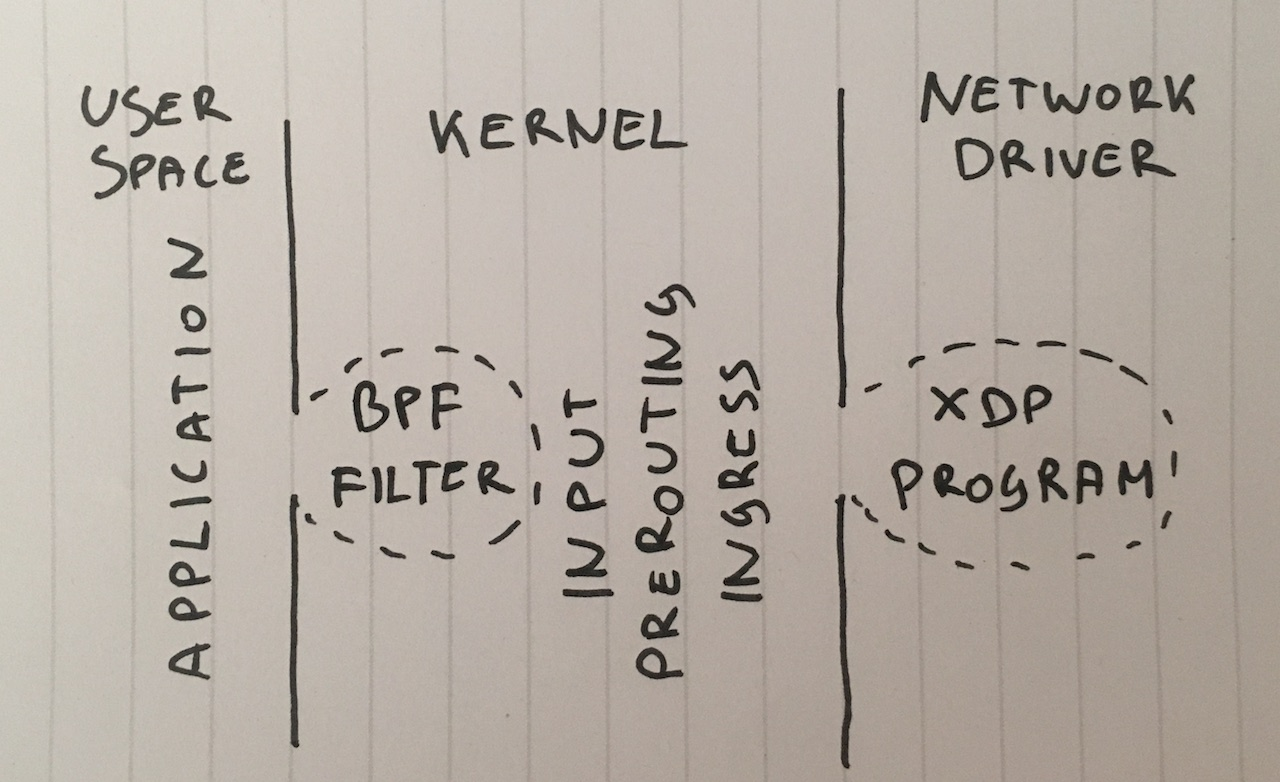
Étape 1. Déposer des paquets dans l'application
Commençons par l'idée de livrer tous les packages à l'application et de les ignorer. Pour l'honnêteté de l'expérience, assurez-vous que les iptables n'affectent en rien les performances:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
L'application est un cycle simple dans lequel les données reçues sont immédiatement rejetées:
s = socket.socket(AF_INET, SOCK_DGRAM) s.bind(("0.0.0.0", 1234)) while True: s.recvmmsg([...])
Nous avons déjà préparé le
code , exécutez:
$ ./dropping-packets/recvmmsg-loop packets=171261 bytes=1940176
Cette solution permet au noyau de ne prendre que 175 000 paquets de la file d'attente matérielle, comme l'ont mesuré l'
ethtool et
nos mmwatch :
$ mmwatch 'ethtool -S ext0|grep rx_2' rx2_packets: 174.0k/s
Techniquement, 14 millions de paquets par seconde arrivent sur le serveur, cependant, un cœur de processeur ne peut pas faire face à un tel volume.
mpstat confirme:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver' 01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14 01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65 01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00 01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
Comme nous pouvons le voir, l'application n'est pas un goulot d'étranglement: le CPU # 1 est utilisé à 27,17% + 2,17%, tandis que la gestion des interruptions prend 100% sur le CPU # 2.
L'utilisation de
recvmessagge(2) joue un rôle important. Après la découverte de la vulnérabilité Spectre, les appels système sont devenus encore plus chers en raison du
KPTI et de la
retpoline utilisés dans le noyau
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/* ==> /sys/devices/system/cpu/vulnerabilities/meltdown <== Mitigation: PTI ==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <== Mitigation: __user pointer sanitization ==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <== Mitigation: Full generic retpoline, IBPB, IBRS_FW
Étape 2. Tuer conntrack
Nous avons spécifiquement créé une telle charge avec différents IP et ports d'expéditeur afin de charger le conntrack autant que possible. Le nombre d'entrées dans conntrack pendant le test tend vers le maximum possible et nous pouvons le vérifier:
$ conntrack -C 2095202 $ sysctl net.netfilter.nf_conntrack_max net.netfilter.nf_conntrack_max = 2097152
De plus, dans
dmesg vous pouvez également voir des cris de conntrack:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet [4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet [4029617.175957] net_ratelimit: 5731 callbacks suppressed
Arrêtons-le donc:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
Et redémarrez les tests:
$ ./dropping-packets/recvmmsg-loop packets=331008 bytes=5296128
Cela nous a permis d'atteindre la marque de 333 000 paquets par seconde. Hourra!
PS En utilisant SO_BUSY_POLL, nous pouvons atteindre jusqu'à 470 000 par seconde, cependant, c'est un sujet pour un article séparé.
Étape 3. Filtre de lot Berkeley
Continuons. Pourquoi devons-nous livrer des packages à l'application? Bien que ce ne soit pas une solution courante, nous pouvons lier le filtre de paquets Berkeley classique au socket en appelant
setsockopt(SO_ATTACH_FILTER) et configurer le filtre pour supprimer les paquets dans le noyau.
Préparez le
code , exécutez:
$ ./bpf-drop packets=0 bytes=0
En utilisant un filtre de paquets (les filtres Berkeley classiques et avancés donnent des performances à peu près similaires), nous arrivons à environ 512 000 paquets par seconde. De plus, la suppression d'un paquet pendant une interruption libère le processeur de la nécessité de réactiver l'application.
Étape 4. iptables DROP après le routage
Nous pouvons maintenant supprimer des paquets en ajoutant la règle suivante à iptables dans la chaîne INPUT:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
Permettez-moi de vous rappeler que nous avons déjà désactivé conntrack avec la règle
-j NOTRACK . Ces deux règles nous donnent 608 000 paquets par seconde.
Regardons les chiffres dans iptables:
$ mmwatch 'iptables -L -v -n -x | head' Chain INPUT (policy DROP 0 packets, 0 bytes) pkts bytes target prot opt in out source destination 605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
Bon, pas mal, mais on peut faire mieux.
Étape 5. iptabes DROP in PREROUTING
Une technique plus rapide consiste à supprimer les paquets avant le routage à l'aide de cette règle:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
Cela nous permet de perdre 1,688 million de paquets par seconde.
En fait, il s'agit d'un bond légèrement surprenant des performances. Je ne comprends toujours pas les raisons, peut-être que notre routage est compliqué, ou peut-être juste un bug dans la configuration du serveur.
Dans tous les cas, les iptables bruts sont beaucoup plus rapides.
Étape 6. nftables DROP
L'utilitaire iptables est maintenant un peu ancien. Elle a été remplacée par des nftables. Découvrez
cette vidéo expliquant pourquoi nftables est top. Nftables promet d'être plus rapide que les iptables grisonnants pour diverses raisons, y compris des rumeurs selon lesquelles les retpolines ralentissent beaucoup les iptables.
Mais notre article ne porte toujours pas sur la comparaison des iptables et des nftables, alors essayons le plus rapidement possible:
nft add table netdev filter nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; } nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
Les compteurs peuvent être vus comme ceci:
$ mmwatch 'nft --handle list chain netdev filter input' table netdev filter { chain input { type filter hook ingress device vlan100 priority -500; policy accept; ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop
Le crochet d'entrée nftables a montré des valeurs d'environ 1,53 million de paquets. C'est un peu moins que la chaîne PREROUTING dans iptables. Mais il y a un mystère à cela: théoriquement, le hook nftables va plus tôt que PREROUTING iptables et, par conséquent, devrait être traité plus rapidement.
Dans notre test, nftables est un peu plus lent que iptables, mais les nftables sont quand même plus frais. : P
Étape 7. Tc DROP
De façon quelque peu inattendue, le crochet tc (contrôle du trafic) se produit plus tôt que iptables PREROUTING. tc nous permet de sélectionner des paquets selon des critères simples et, bien sûr, de les supprimer. La syntaxe est un peu inhabituelle, nous vous suggérons donc d'utiliser
ce script pour la configuration. Et nous avons besoin d'une règle assez compliquée qui ressemble à ceci:
tc qdisc add dev vlan100 ingress tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
Et nous pouvons le vérifier en action:
$ mmwatch 'tc -s filter show dev vlan100 ingress' filter parent ffff: protocol ip pref 4 u32 filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1 filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s) match 00110000/00ff0000 at 8 (success 1.8m/s ) match 000004d2/0000ffff at 20 (success 1.8m/s ) match c612000c/ffffffff at 16 (success 1.8m/s ) action order 1: gact action drop random type none pass val 0 index 1 ref 1 bind 1 installed 1.0/s sec Action statistics: Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
Le crochet tc nous a permis de supprimer jusqu'à 1,8 million de paquets par seconde sur un seul cœur. C'est super!
Mais nous pouvons le faire encore plus rapidement ...
Étape 8. XDP_DROP
Et enfin, notre arme la plus puissante: XDP -
eXpress Data Path . En utilisant XDP, nous pouvons exécuter le code Berkley Packet Filter (eBPF) étendu directement dans le contexte du pilote réseau et, surtout, avant même d'allouer de la mémoire pour
skbuff , ce qui nous promet une augmentation de la vitesse.
En règle générale, un projet XDP se compose de deux parties:
- code eBPF téléchargeable
- chargeur de démarrage qui place le code dans la bonne interface réseau
L'écriture de votre chargeur de démarrage est une tâche difficile, alors utilisez simplement la
nouvelle puce iproute2 et chargez le code avec une simple commande:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
Ta Dam!
Le code source du
programme eBPF téléchargeable est disponible ici . Le programme examine les caractéristiques des paquets IP comme le protocole UDP, le sous-réseau expéditeur et le port de destination:
if (h_proto == htons(ETH_P_IP)) { if (iph->protocol == IPPROTO_UDP && (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24 && udph->dest == htons(1234)) { return XDP_DROP; } }
Le programme XDP doit être construit à l'aide de clang moderne, qui peut générer un bytecode BPF. Après cela, nous pouvons télécharger et tester les fonctionnalités du programme BFP:
$ ip link show dev ext0 4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000 link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff prog/xdp id 5 tag aedc195cc0471f51 jited
Et puis voyez les statistiques dans
ethtool :
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"' rx_out_of_buffer: 4.4m/s rx_xdp_drop: 10.1m/s rx2_xdp_drop: 10.1m/s
Yoo hoo! Avec XDP, nous pouvons supprimer jusqu'à 10 millions de paquets par seconde!
 Photo: Andrew Filer , CC BY-SA 2.0
Photo: Andrew Filer , CC BY-SA 2.0Conclusions
Nous avons répété l'expérience pour IPv4 et IPv6 et préparé ce diagramme:
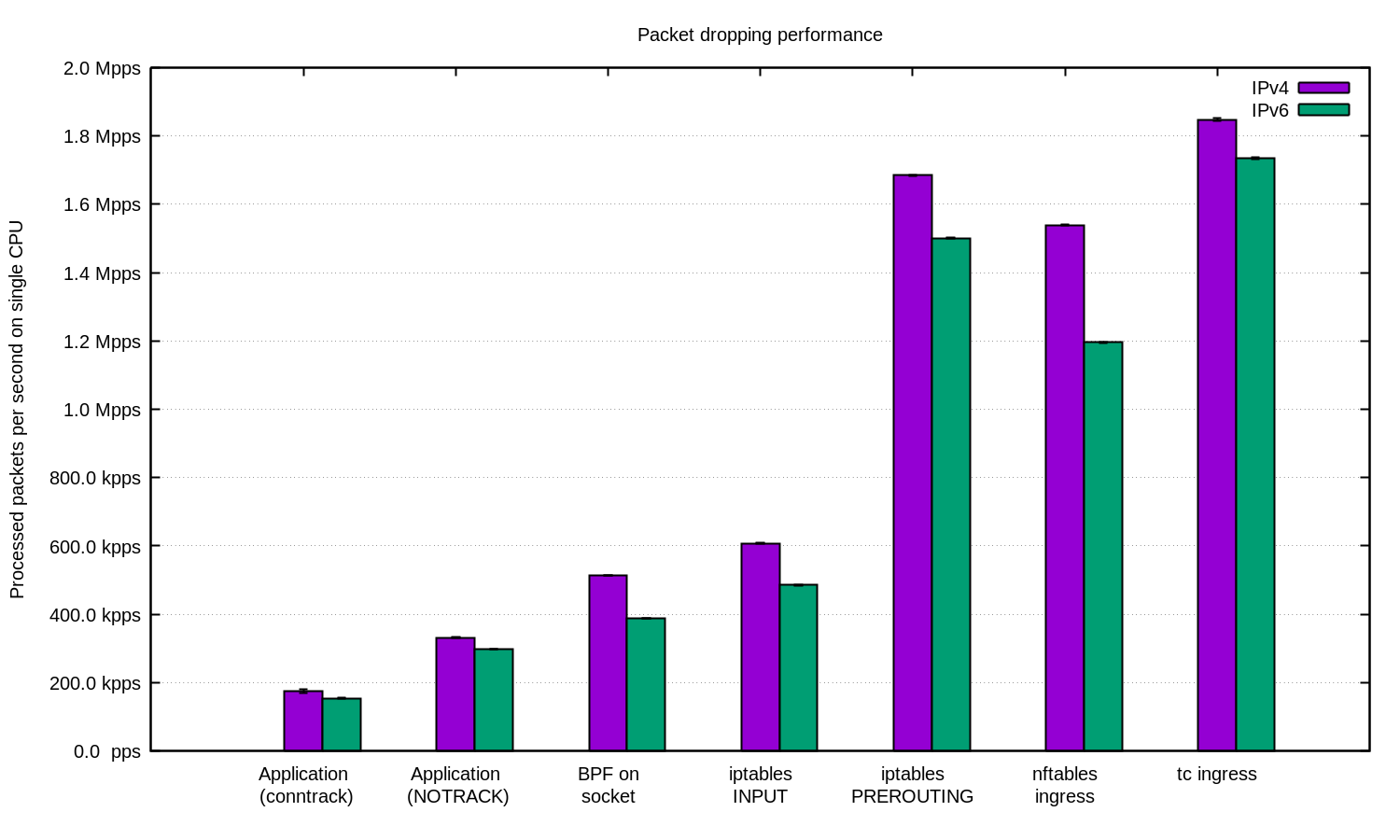
En général, on peut affirmer que notre configuration pour IPv6 est légèrement plus lente. Mais comme les paquets IPv6 sont un peu plus gros, la différence de vitesse est attendue.
Linux a de nombreuses façons de filtrer les packages, chacun avec sa propre vitesse et complexité.
Pour se protéger contre les DDoS, il est tout à fait raisonnable de donner des paquets à l'application et de les traiter là-bas. Une application bien réglée peut donner de bons résultats.
Pour les attaques DDoS avec une adresse IP aléatoire ou usurpée, il peut être utile de désactiver conntrack afin d'obtenir une petite augmentation de la vitesse, mais attention: il existe des attaques contre lesquelles conntrack est très utile.
Dans d'autres cas, il est logique d'ajouter le pare-feu Linux comme l'un des moyens d'atténuer l'attaque DDoS. Dans certains cas, il est préférable d'utiliser la table "-t raw PREROUTING", car elle est beaucoup plus rapide que la table de filtrage.
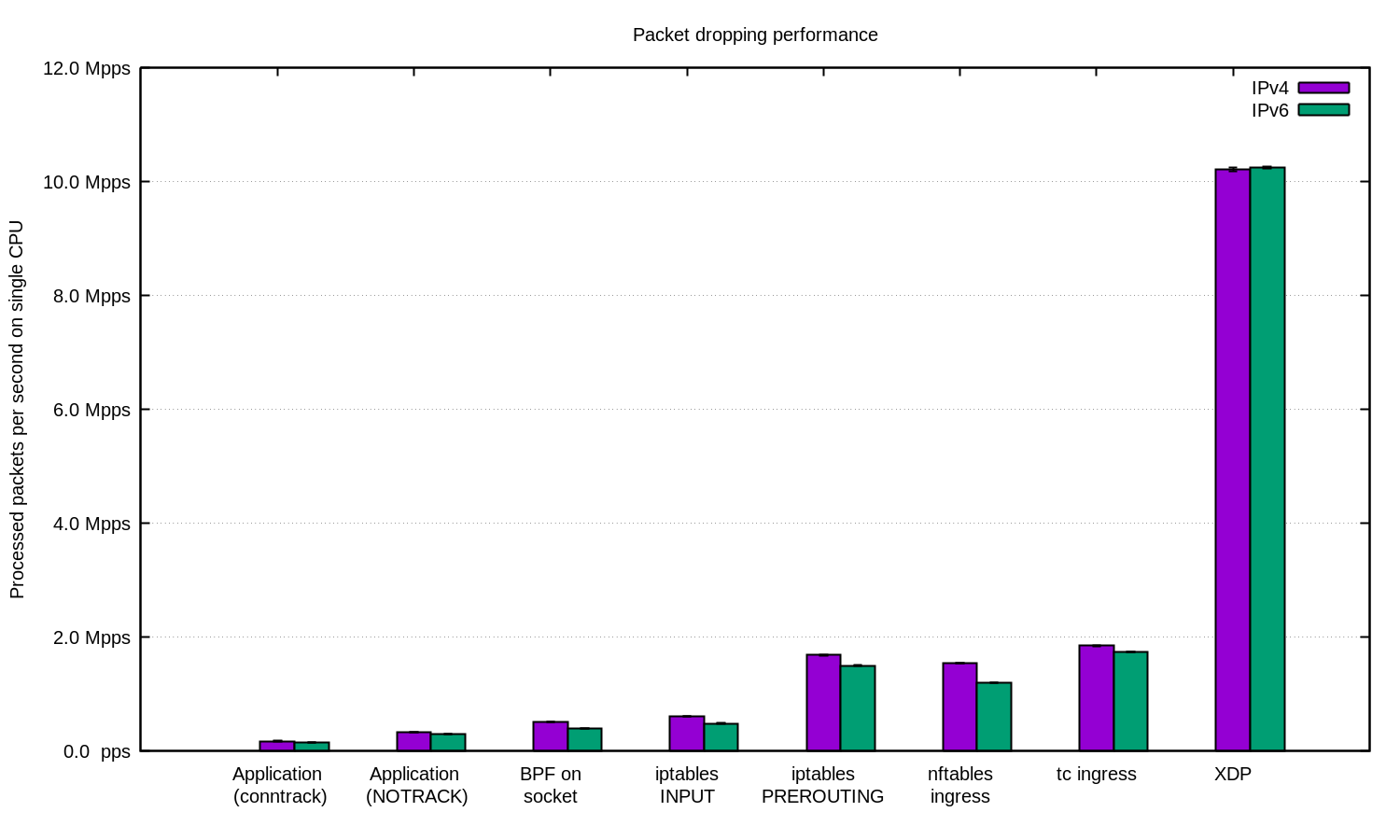
Pour les cas les plus avancés, nous utilisons toujours XDP. Et oui, c'est une chose très puissante. Voici un graphique comme ci-dessus, uniquement avec XDP:
Si vous souhaitez répéter l'expérience, voici le
fichier README, dans lequel nous avons tout documenté .
Chez CloudFlare, nous utilisons ... presque toutes ces techniques. Quelques astuces dans l'espace utilisateur sont intégrées dans nos applications. La technique iptables se trouve dans notre
Gatebot . Enfin, nous remplaçons notre propre solution principale par XDP.
Un grand merci à
Jesper Dangaard Brouer pour leur aide.