Pour poursuivre l'
article sur les dangers d'une diversification excessive, nous allons créer des outils de sélection de titres utiles. Après cela, nous procéderons à un simple rééquilibrage et ajouterons les conditions uniques des indicateurs techniques, qui font si souvent défaut dans les services populaires. Et puis comparez les rendements des actifs individuels et des différents portefeuilles.
Dans tout cela, nous utilisons des pandas et minimisons le nombre de cycles. Regroupez les séries chronologiques et tracez les graphiques. Familiarisons-nous avec les multi-indices et leur comportement. Et tout cela dans Jupyter en Python 3.6.
Si vous voulez bien faire quelque chose, faites-le vous-même.
Ferdinand Porsche
L'outil décrit vous permettra de sélectionner les actifs optimaux pour le portefeuille et d'exclure les outils imposés par les consultants. Mais nous ne verrons que la situation dans son ensemble - sans tenir compte de la liquidité, du temps pour recruter des postes, des commissions de courtage et du coût d'une action. En général, avec un rééquilibrage mensuel ou annuel des grands courtiers, les coûts seront insignifiants. Cependant, avant d'appliquer, la stratégie choisie doit toujours être vérifiée dans le backtester événementiel, par exemple Quantopian (QP), afin d'éliminer les erreurs potentielles.
Pourquoi pas immédiatement dans QP? Le temps. Là, le test le plus simple dure environ 5 minutes. Et la solution actuelle vous permettra de vérifier des centaines de stratégies différentes avec des conditions uniques en une minute.
Chargement des données brutes
Pour charger les données, suivez la méthode décrite dans cet
article . J'utilise PostgreSQL pour stocker les prix quotidiens, mais maintenant il est plein de sources gratuites à partir desquelles vous pouvez créer le DataFrame nécessaire.
Le code de téléchargement de l'historique des prix à partir de la base de données est disponible dans le référentiel. Le lien sera à la fin de l'article.
Structure DataFrame
Lorsque vous travaillez avec l'historique des prix, pour un regroupement pratique et l'accès à toutes les données, la meilleure solution consiste à utiliser un multi-index (MultiIndex) avec date et tickers.
df = df.set_index(['dt', 'symbol'], drop=False).sort_index() df.tail(len(df.index.levels[1]) * 2)
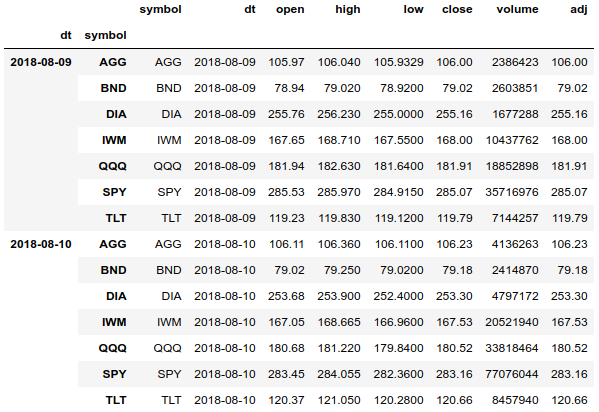
À l'aide d'un multi-indice, nous pouvons facilement accéder à l'historique complet des prix de tous les actifs et pouvons regrouper le tableau séparément par date et actif. Nous pouvons également obtenir l'historique des prix pour un actif.
Voici un exemple de la façon dont vous pouvez facilement regrouper l'historique par semaine, mois et année. Et pour montrer tout cela sur les graphiques des forces des Pandas:
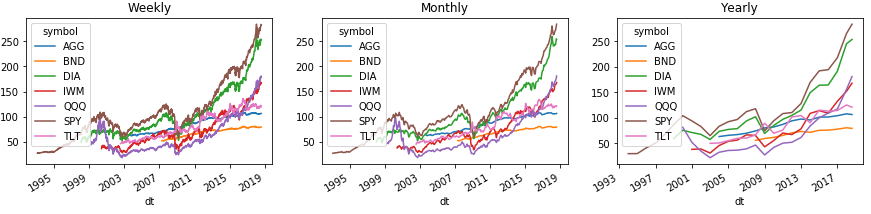
Pour afficher correctement la zone avec la légende du graphique, nous transférons le niveau d'index avec des tickers au deuxième niveau au-dessus des colonnes à l'aide de la commande Series (). Unstack (1). Avec DataFrame (), un tel nombre ne fonctionnera pas, mais la solution est ci-dessous.
Lors du regroupement par périodes standard, Pandas utilise la dernière date de calendrier du groupe dans l'index, qui diffère souvent des dates réelles. Afin de résoudre ce problème, mettez à jour l'index.
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg(agg_rules) \ .set_index(['dt', 'symbol'], drop=False)
Un exemple d'obtention de l'historique des prix d'un actif spécifique (nous prenons toutes les dates, le ticker QQQ et toutes les colonnes):
monthly.loc[(slice(None), ['QQQ']), :]
Volatilité mensuelle des actifs
Maintenant, nous pouvons regarder quelques lignes sur le graphique de l'évolution du prix de chaque actif pour la période qui nous intéresse. Pour ce faire, nous obtenons le pourcentage de changements de prix en regroupant la trame de données par niveau multi-index avec un ticker d'actif.
monthly = df.groupby([pd.Grouper(freq='M', level=0), level_values(1)]).agg( agg_rules).set_index(['dt', 'symbol'], drop=False)
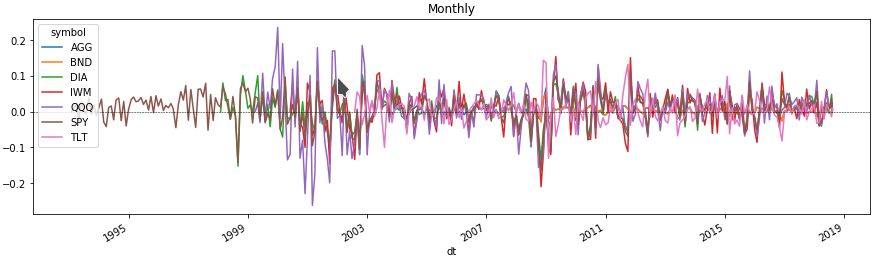
Comparez les rendements des actifs
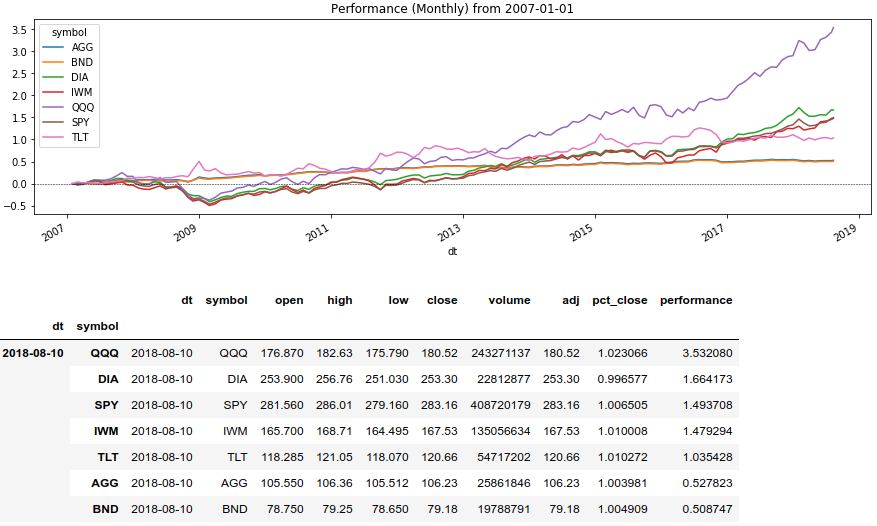
Nous allons maintenant utiliser la méthode de la fenêtre Series (). Rolling () et afficher le rendement des actifs pendant une certaine période:
Code Python rolling_prod = lambda x: x.rolling(len(x), min_periods=1).apply(np.prod)
Méthodes de rééquilibrage de portefeuille
Nous sommes donc arrivés au plus délicieux. Dans les exemples, nous examinerons les résultats du portefeuille dans la répartition du capital en actions prédéterminées entre plusieurs actifs. Et ajouter également des conditions uniques dans lesquelles nous abandonnerons certains actifs au moment de la distribution du capital. S'il n'y a pas d'actifs appropriés, nous supposons que le courtier a le capital dans le cache.
Afin d'utiliser les méthodes Pandas pour le rééquilibrage, nous devons stocker les partages de distribution et les conditions de rééquilibrage dans un DataFrame avec des données groupées. Considérons maintenant les fonctions de rééquilibrage que nous passerons à la méthode DataFrame (). Apply ():
Pour:
- rebalance_simple est la fonction la plus simple qui répartira la rentabilité de chaque actif en actions.
- rebalance_sma est une fonction qui répartit le capital entre les actifs dont la moyenne mobile est supérieure de 50 jours à 200 jours au moment du rééquilibrage.
- rebalance_rsi - une fonction qui répartit le capital entre les actifs pour lesquels la valeur de l'indicateur RSI pendant 100 jours est supérieure à 50.
- rebalance_custom est la fonction la plus lente et la plus universelle, où nous calculerons les valeurs des indicateurs à partir de l'historique quotidien des prix des actifs au moment du rééquilibrage. Ici, vous pouvez utiliser toutes les conditions et données. Téléchargez même à chaque fois à partir de sources externes. Mais vous ne pouvez pas vous passer d'un cycle.
- drawdown - fonction auxiliaire, montrant le drawdown maximum dans le portefeuille.
Dans les fonctions de rééquilibrage, nous avons besoin d'un tableau de toutes les données pour la date par actifs. La méthode DataFrame (). Apply (), par laquelle nous calculerons les résultats des portefeuilles, transmettra un tableau à notre fonction, où les colonnes deviendront l'index des lignes. Et si nous faisons un multi-index, où les tickers seront au niveau zéro, alors un multi-index viendra à nous. Nous pouvons étendre ce multi-index dans un tableau à deux dimensions et obtenir les données de l'actif correspondant sur chaque ligne.

Rééquilibrage du portefeuille
Il suffit maintenant de préparer les conditions nécessaires et de faire un calcul pour chaque portefeuille du cycle. Tout d'abord, nous calculons les indicateurs sur l'historique des prix journaliers:
Nous allons maintenant regrouper l'histoire pour la période de rééquilibrage souhaitée en utilisant les méthodes décrites ci-dessus. Dans le même temps, nous prendrons les valeurs des indicateurs en début de période afin d'exclure les perspectives d'avenir.
Nous décrivons la structure des portefeuilles et indiquons le rééquilibrage souhaité. Nous calculerons les portefeuilles dans un cycle, car nous devons spécifier des actions et des conditions uniques:
Cette fois, nous devons faire un tour avec les indices de colonne et de ligne pour obtenir le multi-index souhaité dans la fonction de rééquilibrage. Nous y parviendrons en appelant les méthodes DataFrame (). Stack (). Unstack ([1, 2]) en séquence. Ce code transférera les colonnes vers un multi-index en minuscules, puis renverra le multi-index avec des tickers et des colonnes dans l'ordre souhaité.
Porte-documents prêts à l'emploi pour les cartes
Reste maintenant à tout dessiner. Pour ce faire, réexécutez le cycle de portefeuille, qui affiche les données sur les graphiques. À la fin, nous utiliserons SPY comme référence pour la comparaison.
Code Python fig = plt.figure(figsize=(15, 4), facecolor='white') ax_perf = fig.add_subplot(121) ax_dd = fig.add_subplot(122) for p in portfolios: p['performance'].rename(p['name']).plot(ax=ax_perf, legend=True, title='Performance') p['drawdown'].rename(p['name']).plot(ax=ax_dd, legend=True, title='Max drawdown')
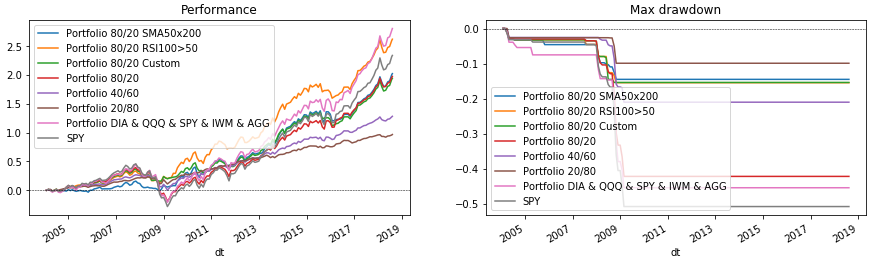
Conclusion
Le code considéré vous permet de sélectionner différentes structures de portefeuille et conditions de rééquilibrage. Avec son aide, vous pouvez rapidement vérifier si, par exemple, il vaut la peine de détenir de l'or (GLD) ou des marchés émergents (EEM) dans un portefeuille. Essayez-le vous-même, ajoutez vos propres conditions pour les indicateurs ou sélectionnez les paramètres déjà décrits. (Mais souvenez-vous de l'erreur du survivant et du fait que l'adaptation aux données passées peut ne pas répondre aux attentes à l'avenir.) Et ensuite décider avec qui vous faites confiance à votre portefeuille - Python ou des consultants financiers?
Référentiel:
rebalance.portfolio