Le développement de logiciels est considéré comme un processus mal mesurable, et il semble que pour le gérer efficacement, vous avez besoin d'une touche spéciale. Et si l'intuition avec l'intelligence émotionnelle n'est pas très développée, alors les termes changeront inévitablement, la qualité du produit baissera et la vitesse de livraison baissera.
 Sergei Semenov
Sergei Semenov estime que cela se produit principalement pour deux raisons.
- Il n'y a pas d'outils ni de normes pour évaluer le travail des programmeurs. Les gestionnaires doivent recourir à une évaluation subjective, qui à son tour conduit à des erreurs.
- Aucun moyen de contrôle automatique des processus dans l'équipe n'est utilisé. Sans contrôle approprié, les processus dans les équipes de développement cessent de remplir leurs fonctions, car ils commencent à être partiellement exécutés ou simplement ignorés.
Et il propose une approche de l'évaluation et du contrôle des processus basée sur des données objectives.
Vous trouverez ci-dessous une version vidéo et textuelle du rapport de Sergey, qui, selon les résultats du vote du public, a pris la deuxième place à
Saint TeamLead Conf .
À propos de l'orateur: Sergey Semenov ( sss0791 ) travaille dans l'informatique depuis 9 ans, était développeur, chef d'équipe, chef de produit, aujourd'hui PDG de GitLean. GitLean est un produit analytique pour les gestionnaires, les directeurs techniques et les chefs d'équipe, conçu pour prendre des décisions de gestion objectives. La plupart des exemples de cette histoire sont basés non seulement sur l'expérience personnelle, mais aussi sur l'expérience des entreprises clientes avec un personnel de développement de 6 à 200 personnes.Déjà avec mon collègue Alexander Kiselev, nous avons parlé de l'
évaluation des développeurs en février lors de la précédente TeamLead Conf. Je ne m'attarderai pas là-dessus en détail, mais je ferai référence à un article sur certaines mesures. Aujourd'hui, nous allons parler des processus et comment les contrôler et les mesurer.
Sources de données
Si nous parlons de mesures, il serait bon de comprendre où obtenir les données. Tout d'abord, nous avons:
- Git avec des informations de code;
- Jira ou tout autre tracker de tâches avec des informations sur les tâches;
- GitHub , Bitbucket, Gitlab avec des informations de révision de code.
En outre, il existe un mécanisme aussi intéressant que la collecte de diverses évaluations subjectives. Je ferai une réserve quant à son utilisation systématique si l'on veut s'appuyer sur ces données.

Bien sûr, la saleté et la douleur vous attendent dans les données - vous ne pouvez rien y faire, mais ce n'est pas si effrayant. La chose la plus désagréable est qu'il n'y a tout simplement pas de données sur le travail de vos processus dans ces sources. Cela peut être dû au fait que les processus ont été créés de manière à ne laisser aucun artefact dans les données.
La première règle que nous recommandons de suivre lors de la conception et de la création de processus est de les faire en sorte qu'ils laissent des artefacts dans les données. Vous devez construire non seulement Agile, mais aussi le rendre
Agile mesurable.
Je vais vous raconter l'histoire d'horreur que nous avons rencontrée avec l'un des clients qui est venu nous voir pour améliorer la qualité du produit. Pour vous faire comprendre l'échelle, environ 30 à 40 bogues de production ont été envoyés à une équipe de 15 développeurs par semaine. Ils ont commencé à comprendre les raisons et ont constaté que 30% des tâches ne tombaient pas dans le statut de «test». Au début, nous pensions que c'était juste une erreur de données, ou les testeurs n'avaient pas mis à jour l'état de la tâche. Mais il s'est avéré que 30% des tâches ne sont tout simplement pas testées. Une fois, il y avait un problème dans l'infrastructure, à cause duquel 1-2 tâches dans l'itération ne tombaient pas dans les tests. Ensuite, tout le monde a oublié ce problème, les testeurs ont cessé d'en parler et, au fil du temps, il est passé à 30%. En conséquence, cela a conduit à des problèmes plus mondiaux.
Par conséquent, la première métrique importante pour tout processus est qu'il laisse des données. Assurez-vous de suivre ceci.

Parfois, pour des raisons de mesurabilité, vous devez sacrifier une partie des principes d'Agile et, par exemple, préférer quelque part la communication écrite à l'oral.
La pratique de la date d'échéance, que nous avons mise en œuvre dans plusieurs équipes afin d'améliorer la prévisibilité, s'est avérée très bonne. Son essence est la suivante: lorsque le développeur prend la tâche et la fait glisser sur «en cours», il doit définir la date d'échéance à laquelle la tâche sera soit publiée, soit prête à être publiée. Cette pratique apprend au développeur à être un gestionnaire de micro-projets conditionnel de ses propres tâches, c'est-à-dire à prendre en compte les dépendances externes et à comprendre que la tâche n'est prête que lorsque le client peut utiliser son résultat.
Pour que la formation ait lieu, après la date d'échéance, le développeur doit aller à Jira et définir une nouvelle date d'échéance et laisser des commentaires sous une forme spécialement donnée, pourquoi cela s'est produit. Il semblerait pourquoi une telle bureaucratie est nécessaire. Mais en fait, après deux semaines de cette pratique, nous déchargeons tous ces commentaires de Jira avec un script simple et réalisons une rétrospective avec cette texture. Il s'avère que de nombreuses informations expliquent pourquoi les délais sont dépassés. Cela fonctionne très bien, je recommande de l'utiliser.
Approche par problème
Dans la mesure des processus, nous professons l'approche suivante: nous devons partir des problèmes. Nous imaginons des pratiques et des processus idéaux, puis nous sommes créatifs sur les façons dont ils peuvent ne pas fonctionner.
Il est nécessaire de surveiller la violation des processus , et non la façon dont nous suivons certaines pratiques. Les processus ne fonctionnent souvent pas, non pas parce que les gens les violent par malveillance, mais parce que le développeur et le gestionnaire n'ont pas assez de contrôle et de mémoire pour les suivre tous. En suivant les violations des réglementations, nous pouvons automatiquement rappeler aux gens ce qui doit être fait et nous obtenons des contrôles automatiques.
Pour comprendre quels processus et pratiques vous devez mettre en œuvre, vous devez comprendre pourquoi faire cela dans l'équipe de développement, ce dont l'entreprise a besoin du développement. Tout le monde comprend qu'il n'en faut pas tant:
- que le produit est livré pour une période de prévision adéquate;
- que le produit était de bonne qualité, pas nécessairement parfait;
- pour que tout cela soit assez rapide.
Autrement dit, la
prévisibilité, la qualité et la vitesse sont importantes. Par conséquent, nous examinerons tous les problèmes et les paramètres en tenant compte précisément de la façon dont ils affectent la prévisibilité et la qualité. Nous parlerons à peine de la vitesse, en raison des près de 50 équipes avec lesquelles nous avons travaillé d'une manière ou d'une autre, seules deux pouvaient travailler avec la vitesse. Afin d'augmenter la vitesse, vous devez être capable de la mesurer, et pour qu'elle soit au moins un peu prévisible, et c'est la prévisibilité et la qualité.
En plus de la prévisibilité et de la qualité, nous introduisons une direction telle que la
discipline . Nous appellerons discipline tout ce qui assure le fonctionnement de base des processus et la collecte de données, sur la base duquel une analyse des problèmes de prévisibilité et de qualité est effectuée.
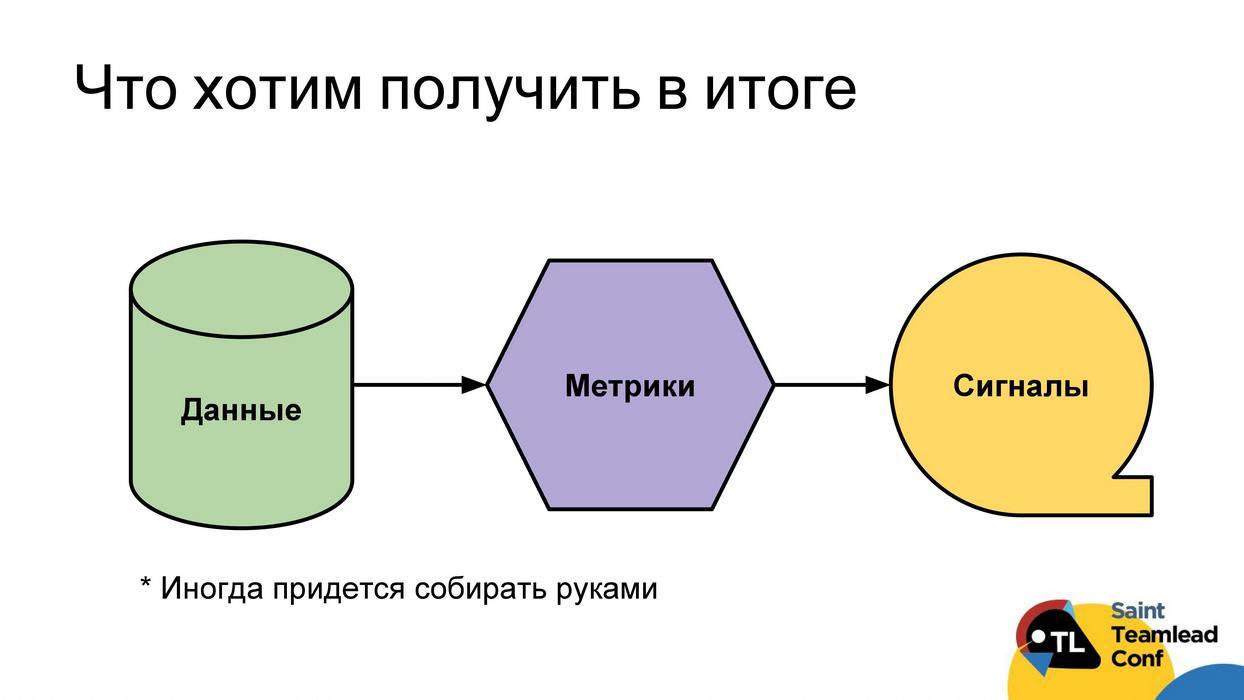
Idéalement, nous voulons construire le schéma de travail suivant: afin d'avoir une collecte automatique des données; à partir de ces données, nous pourrions construire des métriques; Utilisation de mesures pour trouver des problèmes Signalez les problèmes directement au développeur, au chef d'équipe ou à l'équipe. Chacun pourra alors y répondre en temps opportun et faire face aux problèmes rencontrés. Je dois dire tout de suite qu’il n’est pas toujours possible d’obtenir des signaux compréhensibles. Parfois, les mesures resteront uniquement des mesures qui devront être analysées, examiner les valeurs, les tendances, etc. Même avec des données, parfois il y aura un problème, parfois elles ne peuvent pas être collectées automatiquement et vous devez le faire à la main (je clarifierai ces cas séparément).
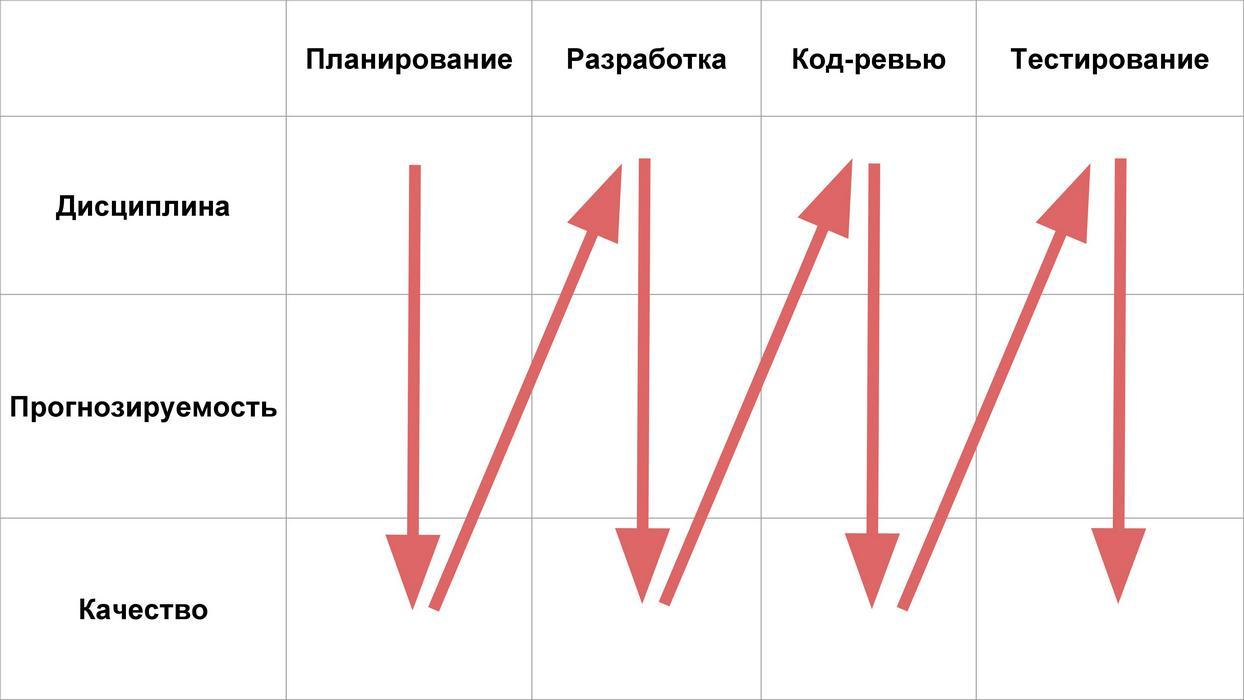
Ensuite, nous considérons 4 étapes de la vie des fonctionnalités:
Et nous analyserons quels problèmes de discipline, de prévisibilité et de qualité peuvent être à chacune de ces étapes.
Problèmes de discipline au stade de la planification
Il y a beaucoup d'informations, mais je fais attention aux points les plus élémentaires. Ils peuvent sembler assez simples, mais ils sont confrontés à un très grand nombre d'équipes.

Le premier problème qui survient souvent lors de la planification est un
problème organisationnel banal - toutes les personnes qui devraient être présentes ne sont pas présentes à la réunion de planification.
Exemple: une équipe se plaint qu'un testeur teste quelque chose de mal. Il s'avère que les testeurs de cette équipe ne vont jamais du tout à la planification. Ou au lieu de s'asseoir et de planifier quelque chose, l'équipe cherche frénétiquement un endroit pour s'asseoir parce qu'elle a oublié de réserver une salle de réunion.
Les métriques et les signaux n'ont pas besoin d'être configurés, assurez-vous simplement que vous n'avez pas ces problèmes. La réunion était inscrite au calendrier, tout le monde y était invité, le lieu était pris. Peu importe à quel point cela peut paraître drôle, cela se produit dans différentes équipes.
Nous allons maintenant discuter des situations dans lesquelles des signaux et des mesures sont nécessaires. Au stade de la planification, la plupart des signaux dont je vais parler devraient être envoyés à l'équipe environ une heure après la fin de la réunion de planification, afin de ne pas distraire l'équipe dans le processus, tout en restant concentrés.
Le premier problème disciplinaire est
que les tâches n'ont pas de description ou sont mal décrites. Ceci est contrôlé élémentairement. Il existe un format auquel les tâches doivent correspondre - nous vérifions si tel est le cas. Par exemple, nous suivons que des critères d'acceptation sont définis, ou pour les tâches frontales, il existe un lien vers la mise en page. Vous devez également garder une trace des composants placés, car le format de description est souvent lié au composant. Pour une tâche principale, une description est pertinente; pour une tâche principale, une autre.

Le prochain problème commun est que les
priorités sont parlées oralement ou pas du tout et ne sont pas reflétées dans les données . En conséquence, à la fin de l'itération, il s'avère que les tâches les plus importantes n'ont pas été effectuées. Il est nécessaire de s'assurer que l'équipe utilise les priorités et les utilise correctement. Si une équipe a 90% des tâches dans l'itération ont une priorité élevée, c'est la même chose que pas de priorités du tout.
Nous essayons de parvenir à une telle distribution: 20% de tâches hautement prioritaires (vous ne pouvez pas vous empêcher de décharger); 60% - priorité moyenne; 20% - faible priorité (ce n'est pas effrayant si nous ne le publions pas). Nous accrochons des signaux sur tout cela.

Le dernier problème avec la discipline, qui se produit au stade de la planification -
il n'y a
pas suffisamment de données , y compris pour les mesures ultérieures. Bases: les tâches n'ont pas de notes (un signal doit être fait) ou les types de tâches sont inadéquats. Autrement dit, les bogues démarrent en tant que tâches, et les tâches de la dette technique ne peuvent pas du tout être retracées. Malheureusement, il n'est pas possible de contrôler automatiquement le deuxième type de problèmes. Nous vous conseillons une seule fois tous les deux mois, surtout si vous êtes CTO et que vous avez plusieurs équipes, parcourez le backlog et assurez-vous que les gens démarrent des bugs comme des bugs, des histoires comme des histoires, des tâches de dette technique comme la dette technique.
Problèmes de prévisibilité au stade de la planification
Nous passons aux problèmes de prévisibilité.

Le problème fondamental est
que nous ne respectons pas les délais et les estimations; Malheureusement, il est impossible de trouver une sorte de signal magique ou de métrique qui résoudra ce problème. La seule façon est d'encourager l'équipe à mieux apprendre, à analyser les causes des erreurs avec l'une ou l'autre évaluation à l'aide d'exemples. Et ce processus d'apprentissage peut être facilité par des moyens automatiques.
La première chose à faire est de traiter des tâches manifestement problématiques avec une estimation élevée du temps d'exécution. Nous suspendons le SLA et contrôlons que toutes les tâches sont suffisamment bien décomposées. Nous recommandons un maximum de deux jours pour commencer l'exécution, puis vous pouvez passer à une journée.
Le paragraphe suivant peut faciliter la collecte des artefacts, sur lesquels il sera possible de mener une formation et d'analyser avec l'équipe pourquoi une erreur s'est produite avec l'évaluation. Nous vous recommandons d'utiliser la pratique de la date d'échéance pour cela. Elle s'est montrée très cool ici.
Une autre façon est une métrique appelée code Churn dans le cadre de la tâche. Son essence est que nous regardons quel pourcentage du code dans le cadre de la tâche a été écrit, mais n'a pas été à la hauteur de la version (plus dans le dernier
rapport ). Cette mesure montre à quel point les tâches sont bien pensées. En conséquence, il serait bon de prêter attention aux problèmes avec les sauts Churn et de les comprendre, ce que nous n'avons pas pris en compte et pourquoi nous avons fait une erreur dans l'évaluation.

L'histoire suivante est standard: l'équipe a prévu quelque chose, le sprint a été rempli, mais
n'a finalement pas du tout ce qu'elle avait prévu . Vous pouvez configurer des signaux pour le bourrage, changer les priorités, mais pour la plupart des équipes avec lesquelles nous l'avons fait, ils n'étaient pas pertinents. Ce sont souvent des opérations légales par le chef de produit pour lancer quelque chose dans le sprint, changer la priorité, donc il y aura beaucoup de faux positifs.
Que peut-on faire ici? Calculer des métriques de base assez standard: fermeture du scout sprint initial, nombre de lancers dans le sprint, fermeture des lancers eux-mêmes, changements de priorité, voir la structure des lancers. Après cela, évaluez le nombre de tâches et de bogues que vous jetez habituellement dans l'itération. De plus, en utilisant un signal pour contrôler que vous
fixez ce quota au stade de la planification .
Problèmes de qualité au stade de la planification
Premier problème: l'
équipe ne pense pas à la fonctionnalité des fonctionnalités publiées . Je parlerai de la qualité dans un sens général - un problème de qualité se pose si le client dit qu'elle existe. Il peut s'agir de défauts d'épicerie ou de problèmes techniques.
En ce qui concerne les défauts alimentaires, une mesure telle que le taux de désabonnement de 3 semaines
fonctionne bien , révélant que 3 semaines après la libération de la tâche de désabonnement est supérieure à la normale. L'essence est simple: la tâche n'a pas été publiée, puis en trois semaines, un pourcentage suffisamment élevé de son code a été supprimé. Apparemment, la tâche n'était pas très bien exécutée. Nous capturons et analysons ces cas avec l'équipe.

La deuxième mesure est nécessaire pour les équipes qui ont des problèmes de bugs, de plantages et de qualité. Nous proposons de construire un
graphique de l'équilibre des bogues et des plantages: combien de bogues y a-t-il en ce moment, combien sont arrivés hier, combien sont arrivés hier. Vous pouvez accrocher un tel
moniteur en temps réel juste devant l'équipe pour qu'elle le voie tous les jours. Ce grand concentre l'équipe sur les problèmes de qualité. Les deux équipes et moi l'avons fait, et elles ont vraiment commencé à mieux réfléchir aux tâches.

Le prochain problème très standard est
que l'équipe n'a pas le temps de s'endetter . Cette histoire est facilement surveillée si vous suivez le travail avec des types, c'est-à-dire que les tâches de dette technique sont évaluées et démarrées dans Jira en tant que tâches de dette technique. Nous pouvons calculer le quota de temps alloué à l'équipe technique de la dette au cours du trimestre. Si nous convenions avec l'entreprise qu'il était de 20%, et que nous n'avons dépensé que 10%, cela peut être pris en compte et au cours du prochain trimestre pour consacrer plus de temps à la dette technique.
Problèmes de discipline en cours d'élaboration
Passons maintenant à la phase de développement. Quels sont les problèmes de discipline?
Malheureusement, il arrive que les
développeurs ne fassent rien, ou nous ne pouvons pas comprendre s'ils font quoi que ce soit. Il est facile de suivre cela par deux signes banaux:
- fréquence des commits - au moins une fois par jour;
- au moins une tâche active dans Jira.
Si ce n'est pas le cas, alors ce n'est pas un fait que vous devez battre les mains du développeur, mais vous devez le savoir.
Le deuxième problème qui peut abattre même les personnes les plus puissantes et le cerveau même d'un développeur très cool est
le traitement constant . Ce serait bien si vous, en tant que chef d'équipe, saviez qu'une personne traite: écrit un code ou fait une révision de code après les heures.
Diverses règles Git peuvent également
être violées . La première chose que nous demandons instamment à toutes les commandes de suivre est de spécifier les préfixes de tâche du tracker dans les messages de validation, car ce n'est que dans ce cas que nous pouvons lier la tâche et le code. Ici, il vaut mieux ne même pas générer de signaux, mais configurer directement git hook. Pour toutes les règles git supplémentaires que vous avez, par exemple, vous ne pouvez pas valider dans master, nous configurons également les hooks git.
Il en va de même pour les pratiques convenues. Au stade du développement, il existe de nombreuses pratiques qu'un développeur doit suivre. Par exemple, dans le cas de la date d'échéance, il y aura trois signaux:
- tâches pour lesquelles la date d'échéance n'est pas fixée;
- tâches qui ont expiré la date d'échéance;
- tâches dont la date d'échéance a été modifiée mais aucun commentaire.
Les signaux sont accordés pour tout cela. Des choses similaires peuvent également être configurées pour toute autre pratique.
Problèmes de prévisibilité au stade du développement
Beaucoup de choses peuvent mal tourner dans les prévisions au stade du développement.
Une tâche peut simplement se bloquer pendant le développement pendant une longue période. Nous avons déjà essayé de résoudre ce problème au stade de la planification - décomposer les tâches assez finement. Malheureusement, cela n'aide pas toujours et
il y a des tâches qui se bloquent . Pour commencer, nous recommandons simplement de régler le SLA sur «en cours» afin qu'il y ait un signal que ce SLA est violé. Cela ne vous permettra pas de commencer à publier des tâches plus rapidement pour le moment, mais cela vous permettra à nouveau de collecter des factures, d'y répondre et de discuter avec l'équipe de ce qui s'est passé, pourquoi la tâche se bloque pendant longtemps.
La prévisibilité peut souffrir s'il
y a trop de tâches sur un même développeur . Il est conseillé de vérifier le nombre de tâches parallèles que le développeur effectue par code, et non par Jira, car Jira ne reflète pas toujours les informations pertinentes. Nous sommes tous humains et si nous effectuons de nombreuses tâches parallèles, le risque que quelque chose se passe mal quelque part augmente.

Le développeur peut avoir des problèmes dont il ne parle pas, mais qui sont faciles à identifier sur la base des données. Par exemple, hier, le développeur avait peu d'activité de code. Cela ne signifie pas nécessairement qu'il y a un problème, mais vous, en tant que chef d'équipe, pouvez venir le découvrir. Il est peut-être coincé et a besoin d'aide, mais il est gêné de lui demander.
Un autre exemple, le développeur, au contraire, a une sorte de grosse tâche qui ne cesse de croître et de croître dans le code. Cela peut également être détecté et éventuellement décomposé de sorte qu'à la fin il n'y ait pas de problèmes au stade de la révision ou du test du code.
, . , , . .
. , , .
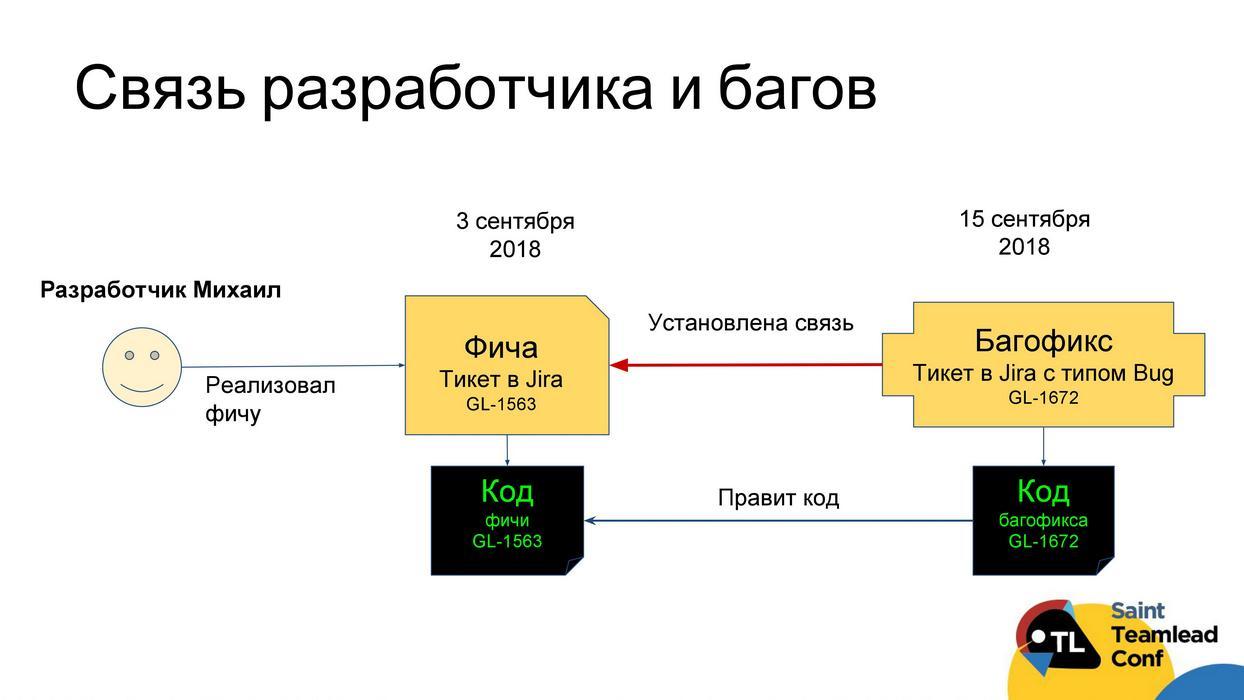
.
«» : , ; «»; «»; , bug fix. , , , , , — « ».
, , , , . , - , .
, , ,
, «» . , . ,
Legacy Refactoring , , , .
, —
SLA high-priority- . , . , , : high-priority critical .
, —
. -, . -, , . , .
-
Code review. ? , , — pull requests. -, pull request, . , , «in review», , Jira. , . , 2-3 , .

, , , pull request, . — , pull request ticket Jira .

, , , . pull requests, . , , : «, , - ». , . pull requests , , Jira.
pull request, , — , , - , - , , . .
, , — , , , , . : , « , ». , .

, , linter. , , - linter, - - , .
-
, SLA , , . , , .
SLA , "
- " — . , -. pull request .

,
- , . , CTO , , , . -. - , 6 50% - . , , 50%, CTO . , CTO - , 100%.
, — , - . :
, -.
-
, -. , .
100 . - 10 , - 1-2 . , .
— , , . , , , .

, , , , .
—
, - , . — churn -, .. pull request , .
,
- , , , . , commit, , -.

, - ( pull request ), - . , commit, . , .
. , — Jira. Jira. , «testing». task-tracker. , , - .

SLA . SLA , .
-, , , — . . , , ,
.

pipeline test- — , , , . build' , , — , . , 1-2 , , . , .
— . , . , , «» , , , , , .
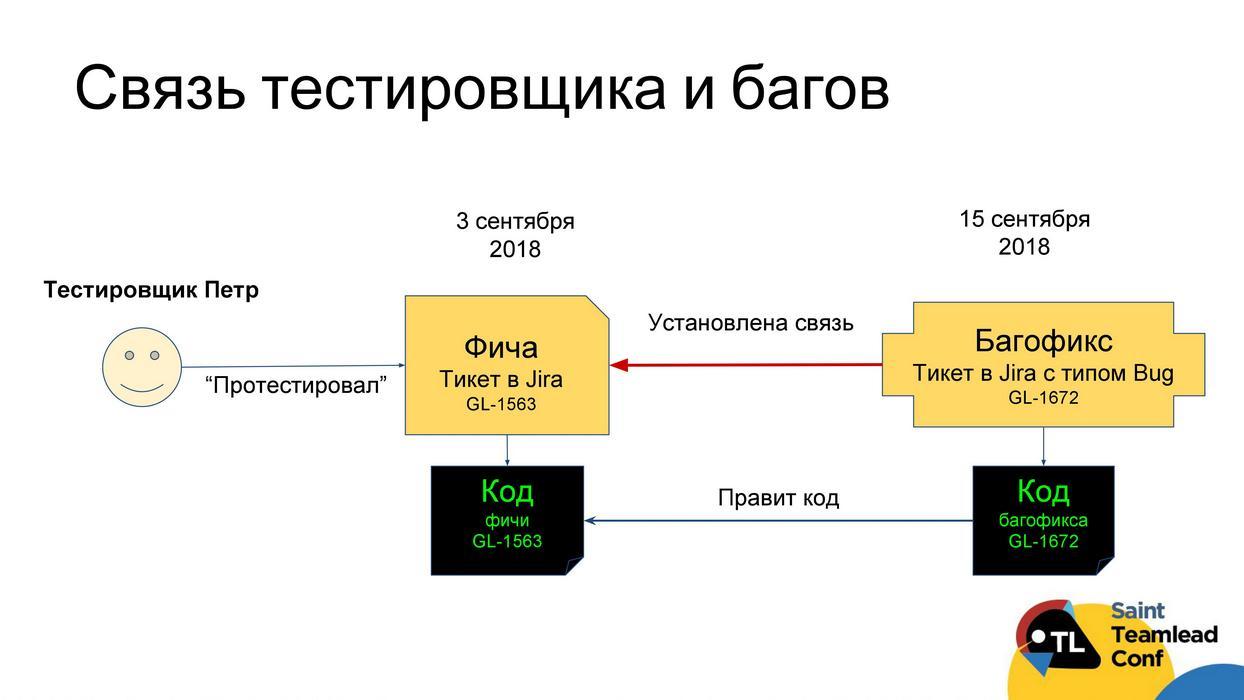
, , ,
. . , , , , . , , , . : , , , .

, «» , , . , , , .
 Une autre histoire qui affecte la qualité de la phase de test est un ping-pong constant entre les tests et le développement . Le testeur renvoie simplement la tâche au développeur et, à son tour, sans rien changer, la renvoie au testeur. Vous pouvez le regarder soit comme une métrique, soit configurer le signal pour de telles tâches et regarder de près ce qui s'y passe et s'il y a des problèmes.
Une autre histoire qui affecte la qualité de la phase de test est un ping-pong constant entre les tests et le développement . Le testeur renvoie simplement la tâche au développeur et, à son tour, sans rien changer, la renvoie au testeur. Vous pouvez le regarder soit comme une métrique, soit configurer le signal pour de telles tâches et regarder de près ce qui s'y passe et s'il y a des problèmes.Méthodologie des métriques
Nous avons parlé de métriques, et maintenant la question est - comment travailler avec tout cela? Je n'ai dit que les choses les plus élémentaires, mais même beaucoup d'entre elles. Que faire de tout cela et comment l'utiliser?
Nous vous recommandons d'automatiser ce processus au maximum et de fournir tous les signaux à l'équipe via un bot dans les messageries instantanées. Nous avons essayé différents canaux de communication: e-mail et tableau de bord - cela ne fonctionne pas très bien. Le bot a fait ses preuves. Vous pouvez écrire un bot vous-même, vous pouvez prendre OpenSource auprès de quelqu'un, vous pouvez acheter chez nous.
Le point ici est très simple: l'équipe réagit beaucoup plus calmement aux signaux du bot qu'au manager, qui indique des problèmes. Si possible, envoyez d'abord la plupart des signaux directement au développeur, puis à l'équipe, si le développeur ne répond pas, par exemple, dans un délai d'un à deux jours.

Pas besoin d'essayer de construire tous les signaux à la fois. La plupart d'entre eux ne fonctionneront tout simplement pas, car vous n'aurez pas de données, en raison de problèmes triviaux de discipline. Par conséquent, nous établissons d'abord la discipline et mettons en place des signaux pour les pratiques disciplinaires. Selon l'expérience des équipes avec lesquelles nous avons parlé, il a fallu un an et demi pour simplement construire la discipline dans l'équipe de développement sans automatisation. Avec l'automatisation, à l'aide de signaux constants, l'équipe commence à travailler normalement de manière disciplinée quelque part après quelques mois, c'est-à-dire beaucoup plus rapidement.
Tous les signaux que vous rendez publics ou que vous dirigez directement vers le développeur, vous ne pouvez en aucun cas capter et allumer. Vous devez d'abord coordonner cela avec le développeur, parler à lui et à l'équipe. Il est conseillé de saisir par écrit toutes les valeurs de seuil dans un accord d'équipe, les raisons pour lesquelles vous effectuez cette opération, les prochaines étapes, etc.

Il ne faut pas oublier que tous les processus ont des exceptions et en tenir compte au stade de la conception.
Nous ne construisons pas un camp de concentration pour les développeurs où il est impossible de faire un pas à droite, un pas à gauche. Tous les processus ont une exception, nous voulons juste les connaître. Si le bot jure constamment au sujet d'une tâche qui ne peut vraiment pas être décomposée et qui prend 5 jours pour travailler, vous devez mettre une marque de «non-suivi» afin que le bot en tienne compte. En tant que gestionnaire, vous pouvez surveiller séparément le nombre de ces tâches de «non-suivi», et ainsi comprendre à quel point ces processus et ces signaux que vous générez sont bons. Si le nombre de tâches étiquetées «sans suivi» augmente régulièrement, cela signifie malheureusement que les signaux et les processus que vous avez inventés sont difficiles pour l'équipe, elle ne peut pas les suivre et il est plus facile de les contourner.
 Le contrôle manuel demeure
Le contrôle manuel demeure . Il ne fonctionnera pas pour allumer le bot et partir quelque part à Bali - vous devez toujours faire face à toutes les situations. Vous avez reçu une sorte de signal, la personne n'a pas répondu - vous devrez trouver la raison dans un jour ou deux, parler du problème et trouver une solution.
Pour optimiser ce processus, nous vous recommandons d'introduire une pratique telle qu'un
assistant de processus . Il s'agit d'une position de transition d'une personne (une fois par semaine) qui comprend les problèmes signalés par le bot. Et vous, en tant que chef d'équipe, aidez le préposé à gérer ces problèmes, c'est-à-dire supervisez-le. Ainsi, le développeur augmente la motivation à travailler avec ce produit. Il en comprend les avantages, car il voit comment ces problèmes peuvent être résolus et comment y réagir. Ainsi, vous réduisez votre unicité à l'équipe et
rapprochez le moment où l'équipe devient autonome , et vous pouvez toujours aller à Bali.
ConclusionsRecueillir des données. Créez des processus pour collecter des données. Même si vous ne voulez pas créer de métriques et de signaux maintenant, vous pouvez faire une analyse rétrospective intéressante à l'avenir si vous commencez à les collecter maintenant.
Contrôlez automatiquement les processus. Lors de la conception de processus, pensez toujours à la façon dont vous pouvez les pirater et à la façon dont vous pouvez reconnaître ces hacks à partir des données.
Quand les signaux sont peu nombreux pendant plusieurs semaines - bravo! Nous étions confrontés au fait que lorsque l'équipe voit qu'il y a moins de signaux, et il semble que la situation s'améliore, elle commence à trouver frénétiquement d'autres pratiques, commence à mettre en œuvre quelque chose afin de voir à nouveau ces paquets de signaux. Ce n'est pas toujours nécessaire, peut-être s'il y a moins de signaux - tout va bien pour vous, l'équipe a commencé à travailler comme vous le vouliez dès le début, et vous avez terminé :)
Venez partager vos trouvailles Timlid sur TeamLead Conf . La conférence de février aura lieu à Moscou et l' appel à communications est déjà ouvert .
Voulez-vous vivre l'expérience des autres? Inscrivez-vous à notre bulletin de gestion pour recevoir des nouvelles sur le programme et ne manquez pas le temps de négocier des billets pour la conférence.