Dans la continuité du «
débriefing » avec HighLoad ++ 2017, nous avons préparé une brève revue des cinq meilleurs rapports en anglais (selon les participants à la conférence).
Les meilleures notes ont été accordées aux sujets liés à l'utilisation de ProxySQL (dans le TOP 5, il y avait deux rapports sur cet outil), aux tests d'applications dans le cloud public Amazon, ainsi qu'aux principes de la journalisation à l'échelle lorsque cela devient un problème et à la surveillance d'Apache Kafka.
Nous venons de publier des vidéos de tous les rapports de HighLoad ++ 2017 en accès libre. Une liste complète de 150 rapports sur notre chaîne YouTube dans cette playlist .
En plus de cette liste de lecture, la chaîne a plusieurs centaines de vidéos sur les bases de données, les architectures, la mise à l'échelle, les files d'attente, l'apprentissage automatique et d'autres sagesse à haute charge :)
Mesurer la variabillité des performances de EC2
Henrik Ingo (architecte de solution MongoDB, et maintenant ingénieur en chef de la productivité chez Mongo DB).Le premier rapport, noté par les participants, fait valoir que le cloud public peut en effet être utilisé pour tester leurs propres produits, y compris les tests de charge. Dans ce cas, le SGBD MongoDB, qui est testé à l'aide du cloud Amazon, était le «expérimental». Au total, environ 400 000 heures sont consacrées à cette tâche par mois, environ 5% de ce temps ne sont que des tests de performances, dont la tâche principale n'est même pas de fournir une optimisation, et de ne pas permettre un «affaissement» à la suite de certaines améliorations.
La question clé de la présentation est de savoir comment obtenir des résultats de test reproductibles dans le cloud public.
Le rapport est construit sur le principe de l'analyse des hypothèses. Dans un premier temps, Henrik Ingo fait des hypothèses sur les facteurs qui devraient influencer le niveau de «bruit» dans les tests (le concept même de «bruit» dans le rapport a une définition très spécifique). Par exemple, l'équipe de test a suggéré que dans les tests «lourds», le «bruit» principal provient du disque dur, ou que dans le cloud, lors de la distribution des ressources, vous pouvez rencontrer de bonnes (entièrement allouées) ou de mauvaises (partagées avec par quelqu'un) des instances qui affectent les résultats du test.
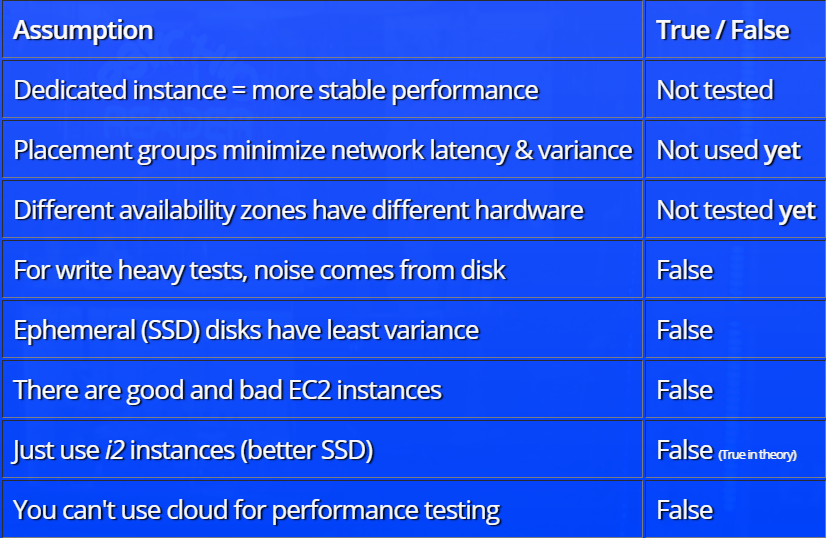
Après cela, les résultats du test de chacune des théories avec une démonstration de quelques dépendances intéressantes sont analysés. Par exemple, voici un graphique de la dépendance du niveau de «bruit» (dans la terminologie du rapport) à la configuration d'instance sélectionnée:
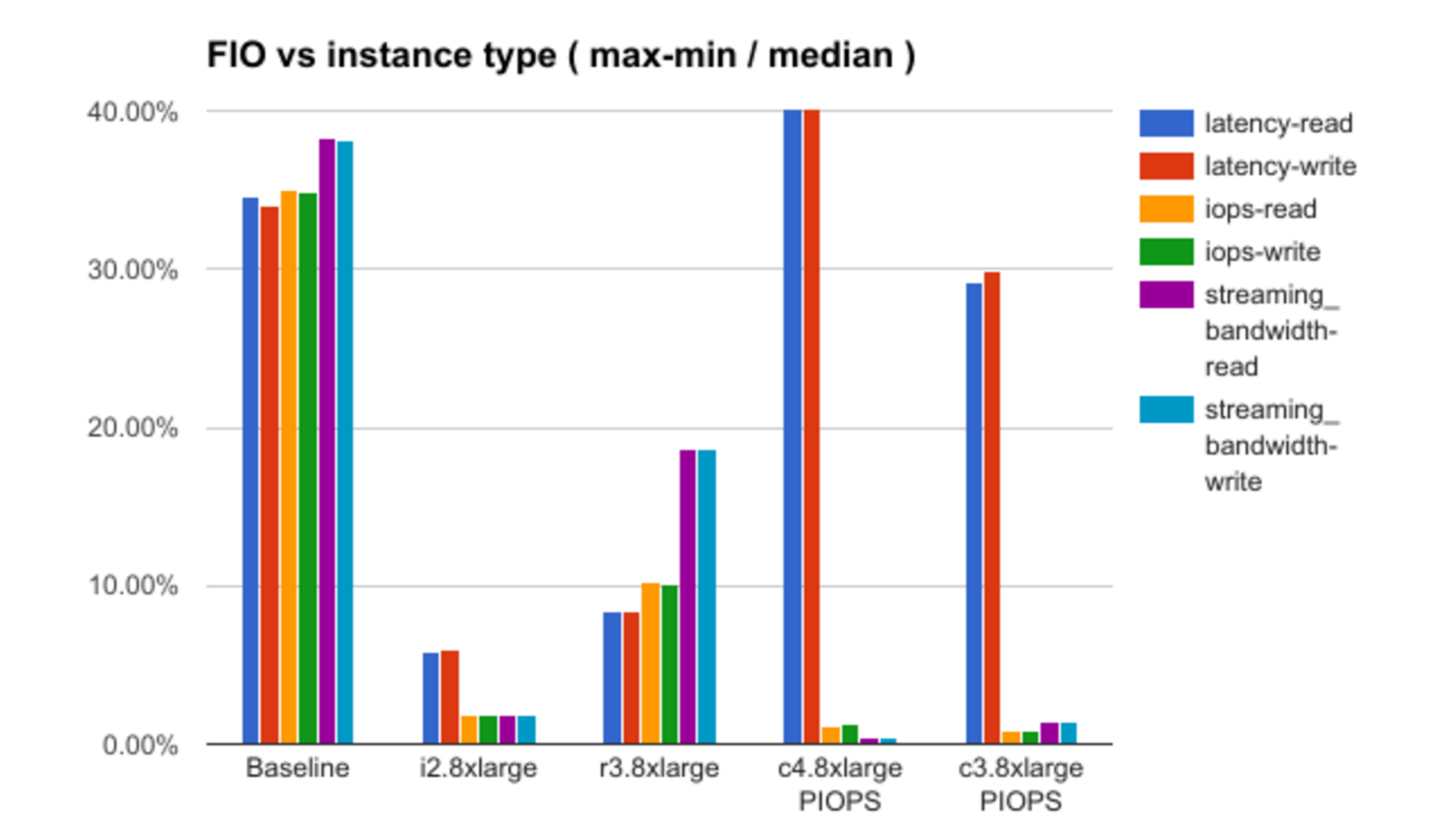
Faute d'informations sur les détails de l'infrastructure d'Amazon, le rapport ne répond pas à toutes les questions, ne faisant dans certains cas que des hypothèses, mais il y a quelque chose à penser.
Journalisation et diatribes
Vytis Valentinavičius (Lamoda, chef des opérations)Le prochain rapport intéressant est la réflexion d'un spécialiste d'une grande boutique en ligne Lamoda sur la journalisation et comment cela devrait être pour que les développeurs, d'une part, reçoivent les données nécessaires dans leur intégralité, et d'autre part, ne se noient pas dans des gigaoctets d'informations entrantes. Et l'orateur sait de quoi il parle. Le problème qui a commencé à construire le travail avec les journaux dans Lamoda est la perte de 5% des rapports envoyés par les utilisateurs via UDP (dans certains cas, cette part a atteint 100%). Cela a sérieusement déformé toutes les métriques qui pouvaient être construites sur leur base.
Le rapport explique comment ne pas démêler une telle situation, mais comment l'empêcher, en principe, étant donné que de nombreuses solutions évidentes ont leurs pièges.
Vytis Valentinavičius se concentre sur le fait que le journal doit avoir une structure. Mais en même temps, il ne peut pas être gonflé. La collecte et le stockage de chaque champ doivent avoir un objectif, car toutes les données collectées sont de l'argent. Un exemple de Lamoda est 25 000 messages de journal de débogage par seconde (32 To d'informations par semaine, pour lesquels le stockage coûte à lui seul 12 000 $).
De plus, il est important de suivre les événements, pas les erreurs spécifiques. Ils doivent être agrégés, les métriques identifiées et basées sur leur analyse pour créer des événements plus complexes pour une agrégation future.
En plus de considérations théoriques, le rapport décrit certaines des astuces que Lamoda a utilisées dans la production pour travailler avec des grumes.
Les mesures ne suffisent pas: surveillance d'Apache Kafka
Gwen Shapira (Confluent, chef de produit)Le prochain rapport concerne la surveillance d'Apache Kafka, ou plutôt, quelles mesures doivent être sélectionnées parmi l'abondance de paramètres disponibles pour l'analyse afin de comprendre l'état du courtier de messages à tout moment.
L'oratrice a commencé son histoire par une blague, dans laquelle, comme on dit, il n'y a qu'une fraction de la blague: "Même si vous ne vous souvenez pas du contenu de l'ensemble du rapport, souvenez-vous d'une chose: si Kafka est utilisé dans la production, il doit être surveillé" (bon, l'API correspondante )
Faut-il tout surveiller? Dépend de la tâche. C'est d'eux que Gwen Shapira repousse, analysant les métriques recommandées. L'orateur décrit les cas d'utilisation standard et recommande des paramètres à ajouter au tableau de bord pour répondre à ce qui se passe à l'heure et comment ne pas aggraver la situation. En particulier, il rappelle encore une fois qu'il n'est pas nécessaire de redémarrer le courtier au premier changement de métrique, car cela prend beaucoup de temps et parfois (en raison de bugs connus) peut entraîner des conséquences plus graves. En fin de compte, les métriques ne sont que des données initiales. Et pour prendre des décisions, il faut avoir des hypothèses basées sur ces données.

Grâce à la vaste expérience de Gwen Shapira en tant que consultante, toute la présentation est accompagnée d'exemples vivants de la vie.
Scénarios d'utilisation de ProxySQL
Alkin Tezuysal (Percona, équipe Global DBA)Deux rapports immédiatement, qui, selon les estimations des participants, figuraient dans le TOP 5, concernent ProxySQL, un moyen de proxy de requêtes SQL vers MySQL (et, plus récemment, ClickHouse).
Le premier rapport concerne généralement les scénarios d'utilisation de cet outil.
ProxySQL est une solution open source, jusqu'à présent, nous n'avons pas rencontré une telle quintessence d'expérience. Oui, de nombreuses entreprises téléchargent cette solution, mais même le fabricant lui-même ne comprend pas toujours qui l'utilisera et à quelle échelle. Les scénarios collectés dans ce rapport ont été identifiés à la suite de la communication avec les utilisateurs de ProxySQL et de l'analyse de leurs cas.
En général, ProxySQL vous permet de résoudre un grand nombre de tâches, de l'équilibrage de charge et des requêtes de réécriture (qui seront discutées dans le prochain rapport de notre liste), à la file d'attente de requêtes et au chauffage du cache, qui n'est pas dans MySQL. Chacune des options qu'Alkin Tezuysal analyse en détail, mentionnant les avantages et les inconvénients de la solution, ainsi que les cas particuliers dans lesquels elle peut être utile.
Nous ne mentionnons ici que deux exemples concernant l'optimisation de la base de données.
Exemple 1 - utilisation de ProxySQL pour réduire le nombre de requêtes pour établir une connexion d'application à la base de données. L'idée est reflétée graphiquement dans le graphique donné dans le rapport:
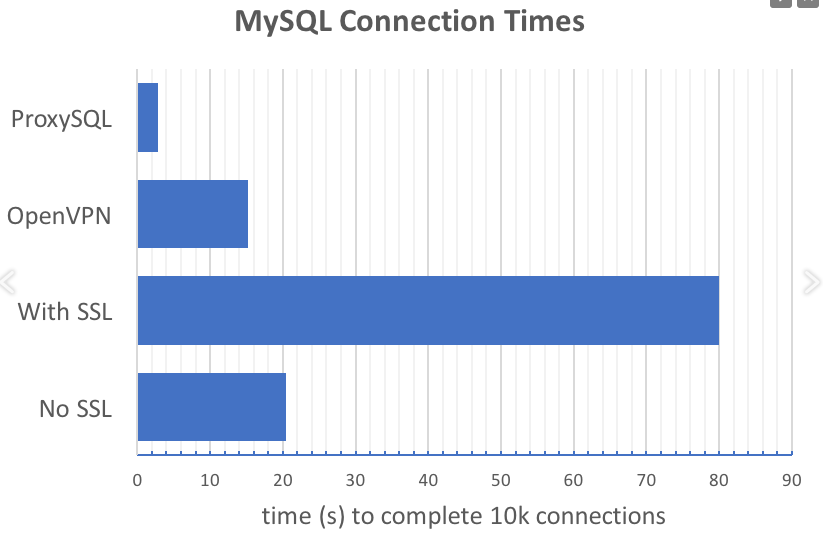
ProxySQL réduit considérablement le nombre de demandes de connexion, en particulier lors de l'utilisation de SSL.
Exemple 2 - filtrage des requêtes inutiles (telles que SELECT 1, manifestées dans des applications à grande échelle) qui ralentissent la base de données. Ici, le résultat est également mieux évalué graphiquement:

Datamasking peu coûteux pour MySQL avec ProxySQL - Anonymisation des données pour les développeurs
René Cannao (fondateur et propriétaire du produit ProxySQL)Le deuxième rapport en anglais sur ProxySQL, qui est entré dans le TOP-5, est dédié à la résolution d'un problème très spécifique - le masquage des données.
Après une brève introduction à ProxySQL pour ceux qui n'ont pas vu le premier rapport, le conférencier plonge dans les capacités de l'outil en ce qui concerne la résolution d'un problème spécifique - masquer (remplacer par des astérisques) une partie du nom ou remplacer le montant réel des revenus par un faux.
Comme le fait remarquer le conférencier, ce problème peut être résolu en utilisant vos propres moyens des mêmes produits MySQL ou tiers. Parmi les tiers, ProxySQL est loin d'être le seul outil. Cependant, bien qu'il n'y ait pas de solution idéale sur le marché, ProxySQL n'est pas pire que beaucoup, permettant aux développeurs d'obtenir des données valides pour des tests qui ne contiennent pas de vraies informations personnelles. De plus, il a du code open source.
Si la première histoire sur ProxySQL était plus théorique, alors voici une pratique continue. Même les règles configurées à l'aide d'expressions régulières sont répertoriées.

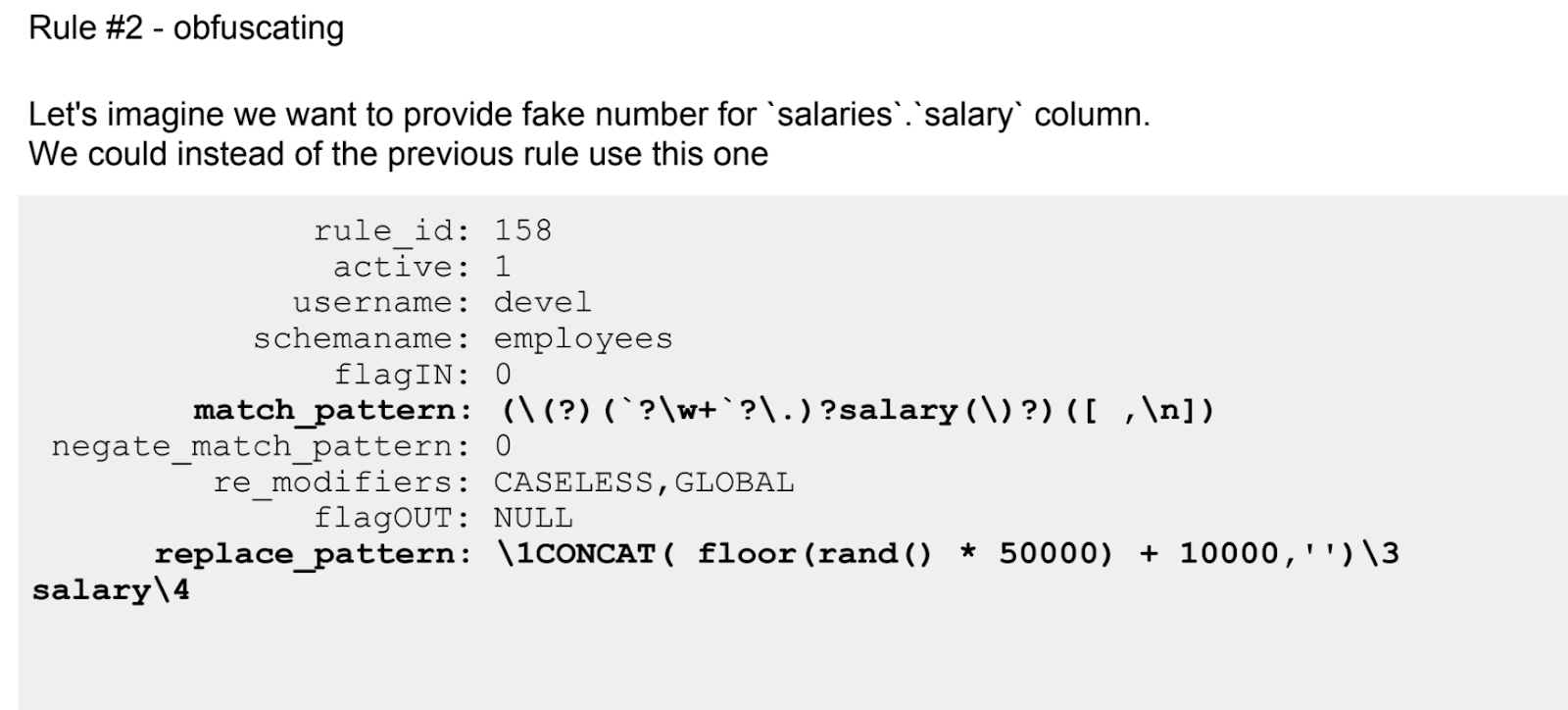
Comme tout outil proxySQL a ses limites. Cela sera également discuté. En particulier, ce n'est pas la meilleure approche pour les transformations complexes.
Le rapport s'est terminé par une section à part entière de questions et réponses, à partir de laquelle vous pouvez également apprendre beaucoup de choses utiles et intéressantes.
Bien sûr, ces cinq anglophones ne sont que la pointe de l'iceberg qui était à HighLoad ++ 2017. Par conséquent, nous rappelons que nous venons de publier des vidéos de tous les rapports de conférence qui peuvent être trouvés dans
cette liste de lecture .
HighLoad ++ 2018 se tiendra les 8 et 9 novembre à Moscou, à Skolkovo. Les travaux sur le programme sont déjà en cours, mais le rapport peut être soumis avant le 1er septembre.