Toutes les organisations qui ont au moins quelque chose à voir avec les données, tôt ou tard, sont confrontées au problème du stockage des bases de données relationnelles et non structurées. Il n'est pas facile de trouver une approche pratique, efficace et peu coûteuse de ce problème à la fois. Et pour vous assurer que les scientifiques des données peuvent travailler avec succès avec des modèles d'apprentissage automatique. Nous l'avons fait - et même si j'ai dû le bricoler, le bénéfice final a été encore plus que prévu. Nous discuterons de tous les détails ci-dessous.

Au fil du temps, des quantités incroyables de données d'entreprise s'accumulent dans n'importe quelle banque. Un montant comparable n'est stocké que dans les sociétés Internet et les télécommunications. Cela s'est produit en raison des exigences réglementaires élevées. Ces données ne sont pas inutiles - les dirigeants des institutions financières ont depuis longtemps compris comment en tirer profit.
Nous avons tous commencé par la gestion et les rapports financiers. Sur la base de ces données, nous avons appris à prendre des décisions commerciales. Il était souvent nécessaire d'obtenir des données de plusieurs systèmes d'information de la banque, pour lesquels nous avons créé des bases de données consolidées et des systèmes de reporting. De cela s'est formé progressivement ce qu'on appelle aujourd'hui un entrepôt de données. Bientôt, sur la base de ce stockage, nos autres systèmes ont commencé à fonctionner:
- CRM analytique, permettant d'offrir au client des produits plus pratiques pour lui;
- des convoyeurs de prêt qui vous aident à prendre une décision rapide et précise sur un prêt;
- des systèmes de fidélité calculant des cashbacks ou des points bonus selon des mécanismes de complexité variable.
Toutes ces tâches sont résolues par des applications analytiques qui utilisent des modèles d'apprentissage automatique. Plus les modèles d'informations peuvent prendre du référentiel, plus ils fonctionneront avec précision. Leur besoin de données augmente de façon exponentielle.
À propos de cette situation, nous sommes arrivés il y a deux ou trois ans. À l'époque, nous disposions d'un stockage basé sur le SGBD MPP Teradata utilisant l'outil SAS Data Integration Studio ELT. Nous avons construit ce magasin depuis 2011 en collaboration avec Glowbyte Consulting. Plus de 15 grands systèmes bancaires y ont été intégrés, et en même temps, suffisamment de données ont été accumulées pour la mise en œuvre et le développement d'applications analytiques. Soit dit en passant, juste à ce moment-là, le volume de données dans les couches principales du magasin, en raison de nombreuses tâches différentes, a commencé à croître de manière non linéaire, et l'analyse client avancée est devenue l'une des principales directions du développement de la banque. Oui, et nos scientifiques des données étaient impatients de la soutenir. En général, pour construire la plateforme de recherche de données, les étoiles se sont formées comme il se doit.
Planifier une solution
Ici, il faut expliquer: les logiciels industriels et les serveurs sont un plaisir cher même pour une grande banque. Toutes les organisations ne peuvent pas se permettre de stocker une grande quantité de données dans le SGBD MPP supérieur. Il faut toujours faire un choix entre prix et rapidité, fiabilité et volume.
Pour tirer le meilleur parti des opportunités disponibles, nous avons décidé de procéder comme suit:
- La charge ELT et la partie la plus demandée des données historiques du CD doivent être laissées sur le SGBD Teradata;
- expédiez l'histoire complète à Hadoop, ce qui vous permet de stocker des informations beaucoup moins cher.
À cette époque, l'écosystème Hadoop est devenu non seulement à la mode, mais aussi suffisamment fiable et pratique pour une utilisation en entreprise. Il fallait choisir un kit de distribution. Vous pouvez créer le vôtre ou utiliser Apache Hadoop ouvert. Mais parmi les solutions d'entreprise basées sur Hadoop, les distributions toutes faites d'autres fournisseurs - Cloudera et Hortonworks - ont fait leurs preuves. Par conséquent, nous avons également décidé d'utiliser une distribution prête à l'emploi.
Étant donné que notre tâche principale consistait toujours à stocker des données volumineuses structurées, dans la pile Hadoop, nous étions intéressés par des solutions aussi proches que possible des SGBD SQL classiques. Les dirigeants ici sont Impala et Hive. Cloudera développe et intègre les solutions Impala, Hortonworks - Hive.
Pour une étude approfondie, nous avons organisé des tests de charge pour les deux SGBD, en tenant compte de la charge de profil pour nous. Je dois dire que les moteurs de traitement des données dans Impala et Hive sont sensiblement différents - Hive présente généralement plusieurs options différentes. Cependant, le choix est tombé sur Impala - et, par conséquent, la distribution de Cloudera.
Ce que j'ai aimé chez Impala
- Grande vitesse d'exécution des requêtes analytiques grâce à une approche alternative par rapport à MapReduce. Les résultats intermédiaires des calculs ne se replient pas dans HDFS, ce qui accélère considérablement le traitement des données.
- Travail efficace avec stockage de données de parquet dans Parquet . Pour les tâches analytiques, les tables dites larges avec de nombreuses colonnes sont souvent utilisées. Toutes les colonnes sont rarement utilisées - la possibilité de lever à partir de HDFS uniquement celles qui sont nécessaires au travail vous permet d'économiser de la RAM et d'accélérer considérablement la demande.
- Une solution élégante avec des filtres d'exécution qui incluent le filtrage de floraison. Hive et Impala sont tous deux limités dans leur utilisation des index communs aux SGBD classiques en raison de la nature du système de stockage de fichiers HDFS. Par conséquent, pour optimiser l'exécution de la requête SQL, le moteur de SGBD doit utiliser efficacement le partitionnement disponible même s'il n'est pas explicitement spécifié dans les conditions de la requête. En outre, il doit essayer de prédire la quantité minimale de données de HDFS qui doit être augmentée pour garantir le traitement de toutes les lignes. À Impala, cela fonctionne très bien.
- Impala utilise LLVM , un compilateur de machine virtuelle avec des instructions de type RISC, pour générer le code d'exécution de requête SQL optimal.
- Les interfaces ODBC et JDBC sont prises en charge. Cela vous permet d'intégrer les données Impala avec des outils et des applications analytiques presque prêts à l'emploi.
- Il est possible d'utiliser Kudu pour contourner certaines des limitations de HDFS et, en particulier, écrire des constructions UPDATE et DELETE dans des requêtes SQL.
Sqoop et le reste de l'architecture
L'outil le plus important suivant sur la pile Hadoop était Sqoop pour nous. Il vous permet de transférer des données entre un SGBD relationnel (nous étions bien sûr intéressés par Teradata) et HDFS dans un cluster Hadoop sous différents formats, dont Parquet. Lors des tests, Sqoop a montré une flexibilité et des performances élevées, nous avons donc décidé de l'utiliser - au lieu de développer nos propres outils pour capturer des données via ODBC / JDBC et les enregistrer sur HDFS.
Pour les modèles de formation et les tâches connexes de Data Science, qui sont plus pratiques à exécuter directement sur le cluster Hadoop, nous avons utilisé Apache
Spark . Dans son domaine, il est devenu une solution standard - et il y a une raison:
- Bibliothèques d'apprentissage automatique Spark ML
- prise en charge de quatre langages de programmation (Scala, Java, Python, R);
- intégration avec des outils analytiques;
- le traitement des données en mémoire donne d'excellentes performances.
Le serveur Oracle Big Data Appliance a été acheté en tant que plate-forme matérielle. Nous avons commencé avec six nœuds dans un circuit productif avec un processeur 2x24 cœurs et 256 Go de mémoire chacun. La configuration actuelle contient 18 des mêmes nœuds avec une extension jusqu'à 512 Go de mémoire.
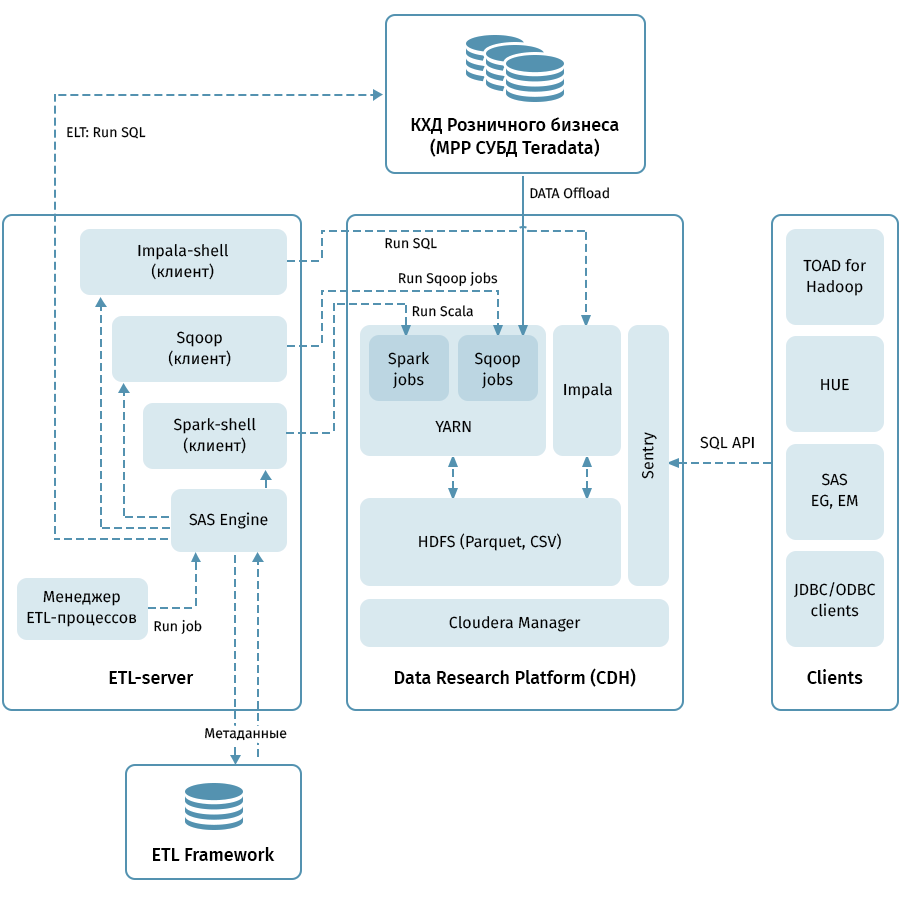
Le diagramme montre l'architecture de niveau supérieur de la plateforme de recherche de données et des systèmes associés. Le lien central est le cluster Hadoop basé sur la distribution Cloudera (CDH). Il est utilisé à la fois pour recevoir avec Sqoop et pour stocker des données QCD en HDFS - au format parquet, permettant l'utilisation de codecs pour la compression, par exemple, Snappy. Le cluster traite également les données: Impala est utilisé pour les transformations de type ELT, Spark - pour les tâches de Data Science. Sentry est utilisé pour partager l'accès aux données.
Impala dispose d'interfaces pour presque tous les outils d'analyse d'entreprise modernes. De plus, des outils arbitraires prenant en charge les interfaces ODBC / JDBC peuvent être connectés en tant que clients. Pour travailler avec SQL, nous considérons Hue et TOAD for Hadoop comme les principaux clients.
Un sous-système ETL composé d'outils SAS (Metadata Server, Data Integration Studio) et d'un framework ETL écrit sur la base de scripts SAS et shell utilisant une base de données pour stocker les métadonnées des processus ETL est utilisé pour gérer tous les flux indiqués par des flèches sur le diagramme. . Guidé par les règles spécifiées dans les métadonnées, le sous-système ETL lance des processus de traitement des données à la fois sur QCD et sur la plateforme de recherche de données. En conséquence, nous avons un système de bout en bout pour surveiller et gérer les flux de données quel que soit l'environnement utilisé (Teradata, Impala, Spark, etc., si nécessaire).
À travers le râteau jusqu'aux étoiles
Le déchargement de QCD semble être simple. En entrée et en sortie, SGBD relationnel, prenez et débordez les données via Sqoop. À en juger par la description ci-dessus, tout s'est très bien passé avec nous, mais, bien sûr, cela n'a pas été sans aventures, et c'est peut-être la partie la plus intéressante de tout le projet.

Avec notre volume, nous ne pouvions pas espérer transférer toutes les données entièrement tous les jours. Par conséquent, à partir de chaque installation de stockage, il était nécessaire d'apprendre à distinguer un incrément fiable, ce qui n'est pas toujours facile lorsque les données des dates commerciales historiques peuvent changer dans le tableau. Pour résoudre ce problème, nous avons systématisé les objets en fonction des méthodes de chargement et de maintien de l'historique. Ensuite, pour chaque type, le prédicat correct pour Sqoop et la méthode de chargement dans le récepteur ont été déterminés. Et enfin, ils ont écrit des instructions pour les développeurs de nouveaux objets.
Sqoop est un outil de très haute qualité, mais pas dans tous les cas et combinaisons de systèmes, il fonctionne de manière absolument fiable. Sur nos volumes, le connecteur vers Teradata n'a pas fonctionné de manière optimale. Nous avons profité du code open source de Sqoop et apporté des modifications aux bibliothèques de connecteurs. La stabilité de la connexion lors du déplacement de données a augmenté.
Pour une raison quelconque, lorsque Sqoop appelle Teradata, les prédicats ne sont pas correctement convertis en conditions WHERE. Pour cette raison, Sqoop essaie parfois de retirer une énorme table et de la filtrer plus tard. Nous n'avons pas réussi à patcher le connecteur ici, mais nous avons trouvé un autre moyen: créer de force une table temporaire avec un prédicat imposé pour chaque objet déchargé et demander à Sqoop de le remplir.
Tous les MPP, et Teradata en particulier, ont une fonctionnalité liée au stockage de données parallèle et à l'exécution des instructions. Si cette fonctionnalité n'est pas prise en compte, il peut s'avérer que tout le travail sera pris en charge par un nœud logique du cluster, ce qui rendra l'exécution de la requête beaucoup plus lente, une fois en 100-200. Bien sûr, nous ne pouvions pas permettre cela, par conséquent, nous avons écrit un moteur spécial qui utilise les métadonnées ETL des tables QCD et sélectionne le degré optimal de parallélisation des tâches Sqoop.
L'historicité du stockage est une question délicate, surtout si vous utilisez
SCD2 , alors
qu'Impala ne prend pas en charge UPDATE et DELETE. Bien sûr, nous voulons que les tableaux historiques de la plate-forme de recherche sur les données soient identiques à ceux de Teradata. Ceci peut être réalisé en combinant la réception de l'incrément via Sqoop, en mettant en évidence les clés professionnelles mises à jour et en supprimant les partitions dans Impala. Pour que cette logique élaborée n'ait pas à être écrite par chaque développeur, nous l'avons placée dans une bibliothèque spéciale (sur notre «chargeur» d'argot ETL).
Enfin - une question avec les types de données. Impala est assez libre pour la conversion de type, nous avons donc rencontré des difficultés uniquement dans les types TIMESTAMP et CHAR / VARCHAR. Pour la date-heure, nous avons décidé de stocker les données dans Impala au format texte (STRING) YYYY-MM-DD HH: MM: SS. Cette approche, en fin de compte, permet d'utiliser les fonctions de transformation de la date et de l'heure. Pour les données de chaîne d'une longueur donnée, il s'est avéré que le stockage au format STRING dans Impala ne leur était pas inférieur, nous l'avons donc également utilisé.
En règle générale, pour organiser Data Lake, ils copient les données source dans des formats semi-structurés dans une zone d'étape spéciale dans Hadoop, après quoi Hive ou Impala a configuré un schéma de désérialisation pour ces données à utiliser dans les requêtes SQL. Nous avons fait de même. Il est important de noter que ce n'est pas tout et qu'il n'est pas toujours logique de le faire glisser dans l'entrepôt de données, car le développement de processus de copie de fichiers et l'installation du schéma sont beaucoup moins chers que le chargement d'attributs métier dans le modèle QCD à l'aide de processus ETL. Quand on ne sait toujours pas combien, pour combien de temps et à quelle fréquence les données sources sont nécessaires, Data Lake dans l'approche décrite est une solution simple et bon marché. Maintenant, nous téléchargeons régulièrement sur Data Lake principalement des sources qui génèrent des événements utilisateur: données d'analyse d'application, journaux et scénarios de transition pour le numéroteur automatique Avaya et le répondeur, transactions par carte.
Boîte à outils d'analyste
Nous n'avons pas oublié un autre objectif de l'ensemble du projet: permettre aux analystes d'utiliser toute cette richesse. Voici les principes de base qui nous ont guidés ici:
- Commodité de l'outil dans l'utilisation et le support
- Applicabilité dans les tâches de science des données
- La possibilité maximale d'utiliser les ressources informatiques du cluster Hadoop, plutôt que les serveurs d'applications ou l'ordinateur du chercheur
Et voici où nous nous sommes arrêtés:
- Python + Anaconda. L'environnement utilisé est iPython / Jupyter
- R + brillant. Le chercheur travaille dans la version desktop ou web de R Studio, Shiny est utilisé pour développer des applications web qui sont affinées par l'utilisation d'algorithmes développés en R.
- Spark Pour travailler avec des données, les interfaces pour Python (pyspark) et R sont utilisées, qui sont configurées dans les environnements de développement spécifiés dans les paragraphes précédents. Les deux interfaces vous permettent d'utiliser la bibliothèque Spark ML, ce qui permet de former des modèles ML sur le cluster Hadoop / Spark.
- Les données Impala sont accessibles via Hue, Spark et à partir des environnements de développement en utilisant l'interface ODBC standard et des bibliothèques spéciales comme implyr
Actuellement, Data Lake contient environ 100 To de données provenant du stockage de détail, plus environ 50 To provenant d'un certain nombre de sources OLTP. Le lac est mis à jour quotidiennement progressivement. À l'avenir, nous allons accroître la commodité pour les utilisateurs, introduire une charge ELT sur Impala, augmenter le nombre de sources téléchargées sur Data Lake et élargir les possibilités d'analyses avancées.
En conclusion, je voudrais donner quelques conseils généraux à des collègues qui commencent tout juste leur parcours dans la création de grands référentiels:
- Utilisez les meilleures pratiques. Si nous n'avions pas de sous-système ETL, de métadonnées, de stockage versionné et d'une architecture compréhensible, nous n'aurions pas maîtrisé cette tâche. Les meilleures pratiques sont rentables, mais pas immédiatement.
- N'oubliez pas la quantité de données. Le Big Data peut créer des difficultés techniques dans des endroits très inattendus.
- Restez à l'écoute des nouvelles technologies. De nouvelles solutions apparaissent souvent, toutes ne sont pas utiles, mais parfois de véritables joyaux sont trouvés.
- Expérimentez plus. Ne vous fiez pas uniquement aux descriptions marketing des solutions - essayez-le vous-même.
Soit dit en passant, vous pouvez découvrir comment nos analystes ont utilisé le machine learning et les données bancaires pour gérer les risques de crédit dans un article séparé.