Parlons aujourd'hui des performances de Kotlin sur Android en production. Regardons sous le capot, implémentons des optimisations délicates, comparons le code d'octet. Enfin, nous aborderons sérieusement la comparaison et mesurerons les repères.
Cet article est basé sur un rapport d'
Alexander Smirnov lors de AppsConf 2017 et aidera à déterminer s'il est possible d'écrire du code dans Kotlin, qui ne sera pas inférieur à Java en termes de vitesse.
À propos du conférencier: Alexander Smirnov CTO chez PapaJobs, dirige le blog vidéo
Android in Faces et est également l'un des organisateurs de la communauté Mosdroid.
Commençons par vos attentes.
Pensez-vous que Kotlin à l'exécution est plus lent que Java? Ou plus vite? Ou peut-être qu'il n'y a pas beaucoup de différence? Après tout, les deux fonctionnent sur le bytecode que la machine virtuelle nous fournit.
Faisons les choses correctement. Traditionnellement, lorsque la question de la comparaison des performances se pose, tout le monde veut voir des repères et des chiffres spécifiques. Malheureusement, pour Android, il n'y a pas de JMH (
Java Microbenchmark Harness ), donc nous ne pouvons pas mesurer à quel point cela peut être cool en Java. Alors, que pouvons-nous faire pour faire la mesure, comme décrit ci-dessous?
fun measure() : Long { val startTime = System.nanoTime() work() return System.nanoTime() - startTime } adb shell dumpsys gfxinfo %package_name%
Si jamais vous essayez de mesurer votre code de cette façon, alors l'un des développeurs JMH sera triste, pleurera et viendra à vous dans un rêve - ne faites jamais ça.
Sur Android, vous pouvez faire des références, en particulier, Google l'a démontré lors des E / S de l'année dernière. Ils ont dit qu'ils avaient considérablement amélioré la machine virtuelle, dans ce cas ART, et si sur Android 4.1 une allocation d'un objet prenait environ 600 à 700 nanosecondes, alors dans la huitième version, cela prendrait environ 60 nanosecondes. C'est-à-dire ils ont pu le mesurer avec une telle précision dans une machine virtuelle. Pourquoi nous ne pouvons pas faire non plus - nous n'avons pas de tels outils.
Si nous regardons toute la documentation, la seule chose que nous pouvons trouver est la recommandation ci-dessus, comment mesurer l'interface utilisateur:
shell adb dumpsys gfxinfo% nom_package%En fait, faisons-le de cette façon et voyons à la fin ce que cela donnera. Mais d'abord, nous déterminerons ce que nous mesurerons et ce que nous pouvons faire d'autre.
La prochaine question. Où pensez-vous que les performances sont importantes lorsque vous créez une application de première classe?
- Certainement partout.
- Fil d'interface utilisateur.
- Vue personnalisée + animations.

J'aime surtout la première option, mais il est fort probable qu'il soit impossible de faire fonctionner tout le code très, très rapidement et il est important qu'au moins il n'y ait pas d'UiThread ou de vue personnalisée. Je suis également d'accord avec cela - c'est très, très important. Personne ne remarquera le fait que dans votre flux JSON séparé sera désérialisé pendant 10 millisecondes de plus.
La psychologie de la Gestalt dit que lorsque nous clignons des yeux, pendant environ 150 à 300 millisecondes, l'œil humain est flou et ne voit pas ce qui s'y passe réellement. Et puis ces 10 millisecondes de temps ne le font pas. Mais si nous revenons à la psychologie gestalt, il est important non pas ce que je vois vraiment et ce qui se passe réellement, mais ce que je comprends en tant qu'utilisateur est important.
C'est-à-dire si nous faisons croire à l'utilisateur qu'il a tout très, très vite, mais en fait, il sera simplement magnifiquement battu, par exemple, à l'aide d'une belle animation, alors il sera satisfait, même si ce n'est pas le cas.
Les motifs de psychologie de la Gestalt dans iOS évoluent depuis un certain temps. Par conséquent, si vous prenez deux applications avec le même temps de traitement, mais sur des plates-formes différentes, et que vous les mettez côte à côte, il semblera que sur iOS tout est plus rapide. L'animation dans les processus iOS est un peu plus rapide, une animation antérieure démarre au démarrage et de nombreuses autres animations, pour que ce soit beau.
La
première règle est donc de penser à l'utilisateur.Et pour la deuxième règle, vous devez vous immerger dans le hardcore.
KOTLIN STYLE
Pour évaluer honnêtement les performances de Kotlin, nous allons le comparer avec Java. Par conséquent, il s'avère qu'il est impossible de mesurer certaines choses qui ne sont que dans Kotlin, par exemple:
- Collection Api.
- Paramètres par défaut de la méthode.
- Classes de données.
- Types réifiés.
- Coroutines.
L'API de collecte que Kotlin nous fournit est très cool, très rapide. En Java, cela n'existe tout simplement pas, il n'y a que différentes implémentations. Par exemple, la bibliothèque d'API Liteweight Stream sera plus lente car elle fait tout de la même manière que Kotlin, mais avec une ou deux allocations supplémentaires à l'opération, car tout se transforme en objet supplémentaire.
Si nous prenons l'API Stream de Java 8, cela fonctionnera plus lentement que l'API Kotlin Collection, mais à une condition - il n'y a pas une telle paralysie dans l'API Collection, si nous incluons en parallèle, sur de gros volumes de données Stream API, Java contournera l'API Kotlin Collection. Par conséquent, nous ne pouvons pas comparer de telles choses, car nous effectuons la comparaison précisément du point de vue d'Android.
La deuxième chose, qui, à mon avis, ne peut être comparée, est les
paramètres par défaut de la méthode - une fonctionnalité très intéressante, qui, soit dit en passant, se trouve dans Dart. Lorsque vous appelez une méthode, elle peut avoir certains paramètres qui peuvent prendre une certaine valeur, mais peut être NULL. Et par conséquent, vous ne faites pas 10 méthodes différentes, mais faites une méthode et dites que l'un des paramètres peut être NULL, et à l'avenir l'utiliser sans aucun paramètre. C'est-à-dire il va regarder, le paramètre est venu, ou il n'est pas venu. C'est très pratique car vous pouvez écrire beaucoup moins de code, mais l'inconvénient est que vous devez payer pour cela. C'est du sucre syntaxique: vous, en tant que développeur, pensez que c'est une méthode API, mais en réalité, sous le capot, chaque variation de la méthode avec des paramètres manquants est générée dans le bytecode. Et chacune de ces méthodes vérifie également, petit à petit, si ce paramètre est arrivé. Si c'est le cas, alors ok, si ce n'est pas le cas, nous créons un masque de bits, et en fonction de ce masque de bits, la méthode d'origine que vous avez écrite est en fait appelée. Les opérations au niveau du bit, tout
si / sinon coûtent un peu d'argent, mais très peu, et il est normal que vous deviez payer pour plus de commodité. Il me semble que c'est absolument normal.
L'élément suivant qui ne peut pas être comparé est
les classes de données .
Tout le monde pleure qu'en Java, il existe des paramètres pour lesquels il existe des classes de modèle. C'est-à-dire vous prenez des paramètres et faites plus de méthodes, de getters et de setters pour tous ces paramètres. Il s'avère que pour une classe avec dix paramètres, vous avez toujours besoin de toute une nappe de getters, de setters et de tout un tas de plus. De plus, si vous n'utilisez pas de générateurs, vous devez écrire avec vos mains, ce qui est généralement terrible.
Kotlin vous permet de vous éloigner de tout. Tout d'abord, comme il existe des propriétés dans Kotlin, vous n'avez pas besoin d'écrire des getters et des setters. Il n'a
pas de paramètres de classe, toutes les propriétés . En tout cas, nous le pensons. Deuxièmement, si vous écrivez qu'il s'agit de classes de données, un tas de tout le reste sera généré. Par exemple, equals (), toStrung () / hasCode (), etc.
Bien sûr, cela présente également des inconvénients. Par exemple, je n'avais pas besoin que les 20 paramètres de mes classes de données soient comparés à la fois dans mes égaux (), je n'avais qu'à comparer 3. Quelqu'un n'aime pas tout cela parce que les performances sont perdues sur ce point, et en plus, beaucoup est généré fonctions de service, et le code compilé est assez volumineux. Autrement dit, si vous écrivez tout à la main, il y aura moins de code que si vous utilisez des classes de données.
Je n'utilise pas de classes de données pour une autre raison. Auparavant, il y avait des restrictions sur l'expansion de ces classes et autre chose. Maintenant, tout le monde va mieux avec ça, mais l'habitude demeure.
Qu'est-ce qui est très, très cool dans Kotlin, et qu'est-ce qui sera toujours plus rapide que Java? Il s'agit de
types réifiés , qui, soit dit en passant, se
trouvent également dans Dart.
Vous savez que lorsque vous utilisez des génériques, l'effacement de type est effacé au stade de la compilation et au moment de l'exécution, vous ne savez plus quel objet de ce générique est réellement utilisé.
Avec les types Reified, vous n'avez pas besoin d'utiliser la réflexion à de nombreux endroits lorsque vous en auriez besoin en Java, car avec les méthodes en ligne, c'est avec Reified que vous connaissez le type, et il s'avère donc que vous n'utilisez pas la réflexion et votre code fonctionne plus rapidement. La magie.
Et il y a des
Coroutines . Ils sont très cool, je les aime beaucoup, mais au moment de la performance, ils n'étaient inclus que dans la version alpha, il n'était donc pas possible de faire des comparaisons correctes avec eux.
CHAMPS
Alors allons-y, passons à ce que nous pouvons comparer avec Java et ce que nous pouvons influencer en général.
class Test { var a = 5 var b = 6 val c = B() fun work () { val d = a + b val e = ca + cb } } class B (@JvmField var a: Int = 5,var b: Int = 6)
Comme je l'ai dit, nous n'avons pas de paramètres pour la classe, nous avons des propriétés.
Nous avons var, nous avons val, nous avons une classe externe, dont l'une des propriétés est @JvmField, et nous verrons ce qui se passe réellement avec la fonction work (): nous additionnons la valeur des champs a et b de notre propre classe et les valeurs des champs a et b de la classe externe, qui sont écrites dans le champ immuable c.
La question est de savoir comment, en fait, sera appelé dans d = a + b. Nous savons tous que cette propriété une fois, le getter de cette classe sera appelée pour ce paramètre.
L0 LINENUMBER 10 L0 ALOAD 0 GETFIELD kotlin/Test.a : I ALOAD 0 GETFIELD kotlin/Test.b : I IADD ISTORE 1
Mais si nous regardons le bytecode, nous verrons que getfield est réellement accessible. Autrement dit, cela dans le bytecode n'est pas un appel à la fonction InvokeVirtual, mais un accès direct au champ. Il n'y a rien qui nous a été promis au départ, que nous ayons toutes les propriétés, pas les champs. Il s'avère que Kotlin nous trompe, il y a un appel direct.
Que se passe-t-il si nous voyons quel bytecode est généré pour une autre ligne: val e = ca + cb?
L1 LINENUMBER 11 L1 ALOAD 0 GETFIELD kotlin/Test.c : Lkotlin/B; GETFIELD kotlin/Ba : I ALOAD 0 GETFIELD kotlin/Test.c : Lkotlin/B; INVOKEVIRTUAL kotlin/B.getB ()I IADD ISTORE 2
Auparavant, si vous accédiez à une propriété privée, vous aviez toujours un appel InvokeVirtual. S'il s'agissait d'une propriété privée, l'accès à celle-ci se faisait via GetField. GetField est beaucoup plus rapide qu'InvokeVirtual, la spécification d'Android prétend que l'accès direct à un champ est 3 à 7 fois plus rapide. Par conséquent, il est recommandé de toujours faire référence à Field, et non par le biais de getters ou setters. Maintenant, en particulier dans la huitième machine virtuelle ART, il y aura déjà des numéros différents, mais si vous prenez toujours en charge la version 4.1, ce sera vrai.
Par conséquent, il s'avère qu'il est toujours avantageux pour nous d'avoir GetField, et non InvokeVirtual.
Maintenant, vous pouvez obtenir GetField si vous accédez à une propriété de votre propre classe, ou s'il s'agit d'une propriété publique, vous devez définir @JvmField. Ensuite, exactement la même chose dans le bytecode sera un appel GetField, qui est 3-7 fois plus rapide.
Il est clair que nous parlons ici en nanosecondes et, avec un trône, c'est très, très petit. Mais, d'autre part, si vous le faites dans le thread d'interface utilisateur, par exemple, dans la méthode ondraw, vous accédez à une sorte de vue, cela affectera le rendu de chaque image, et vous pouvez le faire un peu plus rapidement.
Si nous additionnons toutes les optimisations, alors en somme, cela peut donner quelque chose.STATIQUE!?
Et la statique? Nous savons tous que dans Kotlin statique est un objet compagnon. Auparavant, vous avez probablement ajouté une sorte de balise, par exemple, statique publique, statique finale, etc., si vous la convertissez en code Kotlin, vous obtiendrez un objet compagnon, qui écrira quelque chose comme ceci:
companion object { var k = 5 fun work2() : Int = 42 }
Pensez-vous que cette entrée est identique à la déclaration finale statique standard en Java? Est-ce statique ou pas du tout?
Oui, en effet, Kotlin déclare qu'ici c'est dans Kotlin - statique, cet objet dit qu'il est statique. En réalité, ce n'est pas statique.
Si nous regardons le bytecode généré, nous verrons ce qui suit:
L2 LINENUMBER 21 L2 GETSTATIC kotlin/Test.Companion : Lkotlin/Test$Companion; INVOKEVIRTUAL kotlin/Test$Companion.getK ()I GETSTATIC kotlin/Test.Companion : Lkotlin/Test$Companion; INVOKEVIRTUAL kotlin/Test$Companion.work2 ()I IADD ISTORE 3
Un Test.Companion est généré; un objet singleton pour lequel l'instance est créée, cette instance est écrite dans son propre champ. Après cela, l'accès à l'un des objets compagnons s'effectue via cet objet. Il prend getstatic, c'est-à-dire une instance statique de cette classe, et invoque la fonction getK invokevirtual dessus, et exactement la même chose pour la fonction work2. Nous comprenons donc que ce n'est pas statique.
Cela est important, car sur les anciennes machines virtuelles Java, invokestatic était environ 30% plus rapide qu'invokevirtual. Maintenant, bien sûr, chez HotSpot, la virtualisation optimisée devient vraiment cool, et elle est presque invisible. Néanmoins, vous devez garder cela à l'esprit, d'autant plus qu'il y a une allocation supplémentaire et qu'un emplacement supplémentaire sur 4ST1 représente 700 nanosecondes de trop.
Examinons le code Java qui sort si vous inversez le déploiement du bytecode:
private static int k = 5; public static final Test.Companion Companion = new Test.Companion((DefaultConstructorMarker)null); public static final class Companion { public final int getK() { return Test.k;} public final void setK(int var1) { Test.k = var1; } public final int work2() { return 42; } private Companion() { }
Un champ statique est créé, une implémentation finale statique de l'objet Companion, des getters et setters sont créés et, comme vous pouvez le voir, se référant au champ statique à l'intérieur, une méthode statique supplémentaire apparaît. Tout est assez triste.
Que pouvons-nous faire en veillant à ce qu'il ne soit pas statique? Nous pouvons essayer d'ajouter @JvmField et @JvmStatic et voir ce qui se passe.
val i = k + work2() companion object { @JvmField var k = 5 JvmStatic fun work2() : Int = 42 }
Je dirai tout de suite que vous ne vous éloignerez pas de @JvmStatic, ce sera le même objet, car il s'agit d'un objet compagnon, il y aura une allocation supplémentaire de cet objet et il y aura un appel supplémentaire.
private static int k = 5; public static final Test.Companion Companion = new Test.Companion((DefaultConstructorMarker)null); public static final class Companion { @JvmStatic public final int work2() { return 42; } private Companion() {}
Mais l'appel ne changera que pour k, car ce sera @JvmField, il sera pris directement comme getstatic, les getters et setters ne seront plus générés. Mais pour la fonction work2, rien ne changera.
L2 LINENUMBER 21 L2 GETSTATIC kotlin/Test.k : I GETSTATIC kotlin/Test.Companion : Lkotlin/Test$Companion; INVOKEVIRTUAL kotlin/Test$Companion.work2 ()I IADD ISTORE 3
La deuxième option sur la façon de créer de la statique est proposée dans la documentation de Kotlin, il est donc dit que nous pouvons simplement créer un objet, et ce sera du code statique.
object A { fun test() = 53 }
En réalité, ce n'est pas non plus le cas.
L3 LINENUMBER 23 L3 GETSTATIC kotlin/A.INSTANCE : Lkotlin/A; INVOKEVIRTUAL kotlin/A.test ()I POP
Il s'avère que nous faisons un appel d'instance getstatic à partir de singletone, qui est créé, et appelons exactement les mêmes méthodes virtuelles.
La seule façon dont nous pouvons réaliser invokestatic est les fonctions d'ordre supérieur. Lorsque nous écrivons simplement une fonction en dehors de la classe, par exemple, fun test2 sera vraiment appelé statique.
fun test2() = 99 L4 LINENUMBER 24 L4 INVOKESTATIC kotlin/TestKt.test2 ()I POP
De plus, la chose la plus intéressante est qu'une classe sera créée, un objet, dans ce cas testKt, il générera un objet pour lui-même, il générera une fonction qu'il mettra dans cet objet, et maintenant il sera appelé invokestatique.
Pourquoi cela a été fait est incompréhensible. Beaucoup sont mécontents de cela, mais il y a ceux qui considèrent qu'une telle implémentation est tout à fait normale. Depuis la machine virtuelle, incl. L'art s'améliore, maintenant il n'est plus aussi critique. Dans la huitième version d'Android, tout comme sur HotSpot, tout est optimisé, mais ces petites choses affectent encore légèrement les performances globales.
NULLABILITÉ
fun test(first: String, second: String?) : String { second ?: return first return "$first $second" }
Ceci est le prochain exemple intéressant. Il semblerait que nous ayons noté que le second peut être annulable, et il doit être vérifié avant de faire quoi que ce soit avec. Dans ce cas, je m'attends à ce que nous en ayons un si. Lorsque ce code est déployé dans si second n'est pas égal à zéro, alors je pense que l'exécution ira plus loin et ne sortira qu'en premier.
Comment tout cela se déroule-t-il vraiment dans le code java? En fait, il y aura un chèque.
@NotNull public final String test(@NotNull String first,@Nullable String second) { Intrinsics.checkParameterIsNotNull(first, "first"); return second != null ? (first + " " + second) : first; }
Nous obtiendrons Intrinsics dans un premier temps. Disons que je dis que celui-ci
Si se développera en un opérateur ternaire. Mais en plus de cela, bien que nous ayons même corrigé que le premier paramètre ne peut pas être annulé, il sera toujours vérifié via Intrinsics.
Intrinsics est une classe interne de Kotlin qui a un certain ensemble de paramètres et de vérifications. Et chaque fois que vous rendez le paramètre de méthode non nul, il le vérifie quand même. Pourquoi? Ensuite, que nous travaillons dans Interop Java, et il peut arriver que vous vous attendiez à ce qu'il ne soit pas annulable ici, mais avec Java cela viendra de quelque part.
Si vous cochez ceci, il ira plus loin dans le code, puis après 10-20 appels de méthode, vous ferez quelque chose avec un paramètre qui, bien qu'il ne puisse pas être annulable, mais pour une raison quelconque, il s'est avéré qu'il l'est. Tout tombera pour vous, et vous ne pourrez pas comprendre ce qui s'est réellement passé. Pour éviter cette situation, chaque fois que vous passerez le paramètre null, vous devrez toujours le vérifier. Et s'il est nullable, il y aura une exception.
Ce chèque vaut également quelque chose, et s'il y en a beaucoup, ce ne sera pas très bon.
Mais en fait, si nous parlons de HotSpot, alors 10 appels de ces Intrinsics prendront environ quatre nanosecondes. C'est très, très petit, et vous ne devriez pas vous en soucier, mais c'est un facteur intéressant.
PRIMITIVES
En Java, il existe des primitives. À Kotlin, comme nous le savons tous, il n'y a pas de primitives, nous fonctionnons toujours avec des objets. En Java, ils sont utilisés pour fournir des performances plus élevées pour les objets sur certains calculs mineurs. Ajouter deux objets coûte beaucoup plus cher que d'ajouter deux primitives. Prenons un exemple.
var a = 5 var b = 6 var bOption : Int? = 6
Il y a trois nombres, car les deux premiers types non nuls seront déduits, et vers le troisième nous dirons qu'il peut être annulable.
private int a = 5; private int b = 6; @Nullable private Integer bOption = Integer.valueOf(6);
Si vous regardez le bytecode et voyez quel code Java est généré, les deux premiers nombres ne sont pas nuls et peuvent donc être des primitives. Mais la primitive ne peut pas contenir Null, seul un objet peut le faire, donc un objet sera généré pour le troisième nombre.
AUTOBOXE
Lorsque vous travaillez avec des primitives et effectuez une opération avec une primitive et une non-primitive, vous devrez soit traduire l'une d'elles en primitive, soit en objet.
Et, il semblerait, il n'est pas surprenant que si vous effectuez des opérations avec nullable et non nullable dans Kotlin, alors vous perdez un peu en performances. De plus, s'il existe de nombreuses opérations de ce type, vous perdez beaucoup.
val a: String? = null var b = a?.isBlank() == true
Voyez où la boxe / unboxing sera ici? Je n'ai pas vu non plus avant d'avoir regardé le bytecode.
if (a != null && a.isBlank()) true else false
En fait, je m'attendais à ce qu'il y ait quelque chose comme cette comparaison: si la chaîne n'est pas nulle et si elle est vide, définissez-la sur true, sinon définissez-la sur false. Tout semble simple, mais en réalité le code suivant est généré:
String a = (String)null; boolean b = Intrinsics.areEqual(a != null ? Boolean.valueOf(StringsKt.isBlank((CharSequence)a)) : null, Boolean.valueOf(true));
Regardons à l'intérieur. La variable
a est prise, elle est castée en CharSequence, après avoir été castée, qui a également été dépensée pendant un certain temps, une autre vérification est appelée - StringsKt.isBlank - c'est ainsi que la fonction d'extension de CharSequence est écrite, donc elle est castée et envoyée. Puisque la première expression peut être nullable, elle la prend et fait de la boxe, et enveloppe tout cela dans Boolean.valueOf. Par conséquent, la vraie primitive devient également un objet, et ce n'est qu'après que la vérification a déjà eu lieu et que Intrinsics.areEqual est appelé.
Cela semblerait une opération si simple, mais un résultat si inattendu. En fait, il y a très peu de telles choses. Mais quand vous pouvez avoir nullable / non nullable, vous pouvez générer un grand nombre de ces choses, et que vous n'auriez jamais imaginé. Par conséquent, je vous recommande de vous éloigner de l'obscurité dès que possible. C'est-à-dire
venez à l'immunité des valeurs le plus tôt possible et éloignez-vous de nullable pour que vous n'opériez pas aussi rapidement que possible.
Boucles
La prochaine chose intéressante.
Vous pouvez utiliser l'habituel pour, qui est en Java, mais vous pouvez également utiliser la nouvelle API pratique - écrire immédiatement l'énumération des éléments dans la liste.
Par exemple, vous pouvez appeler la fonction de travail dans une boucle, où ce sera un élément de cette liste. list.forEach { work(it * 2) }
Un itérateur sera généré et il y aura une recherche itérative banale. C'est normal, c'est beaucoup recommandé. Mais si nous examinons le type de conseils que Google nous donne, nous découvrirons, du point de vue des performances spécifiques à ArrayList, une énumération des travaux 3 fois plus rapide que celle d'un itérateur. Dans tous les autres cas, l'itérateur fonctionnera de manière identique.Par conséquent, si vous êtes sûr d'avoir une ArrayList, il est logique de faire autre chose - écrivez votre foreach. inline fun <reified T> List<T>.foreach(crossinline action: (T) -> Unit): Unit { val size = size var i = 0 while (i < size) { action(get(i)) i++ } } list.foreach { }
API, - . , Kotlin: extension , «», reified, .. , , , crossinline. , , . 3 , Android Google.
RANGES
Ranges.
inline fun <reified T> List<T>.foreach(crossinline action: (T) -> Unit): Unit { val size = size for(i in 0..size) { work(i * 2) } }
: Unit -. −1, until , , . , , ranges. C'est-à-dire , . step. .
INTRINSICS
- Intrinsics, :
class Test { fun concat(first: String, second: String) = "$first $second" }
Intrinsics — second, first.
public final class Test { @NotNull public final String concat(@NotNull String first, @NotNull String second) { Intrinsics.checkParameterIsNotNull(first, "first"); Intrinsics.checkParameterIsNotNull(second, "second"); return first + " " + second; } }
, gradle. , - 4 , . Kotlin UI, , nullable, Kotlin :
kotlinc -Xno-call-assertions -Xno-param-assertions Test.ktIntrinsics, , .
, , . — Xno-param-assertions — Intrinsics, .
, , , , , . , , , .
REDEX
, , , Proguard. , 99% , , . Android 8.0 , . , .
, Proguard, Facebook,
Redex . -, , . , Jvm Fields , .
, Redex . , , , Proguard, , . Redex 7% APK. , .
BENCHMARKS
. , , .
, . , dumpsys gfxinfo , . github
github.com/smred .
, Huawei.
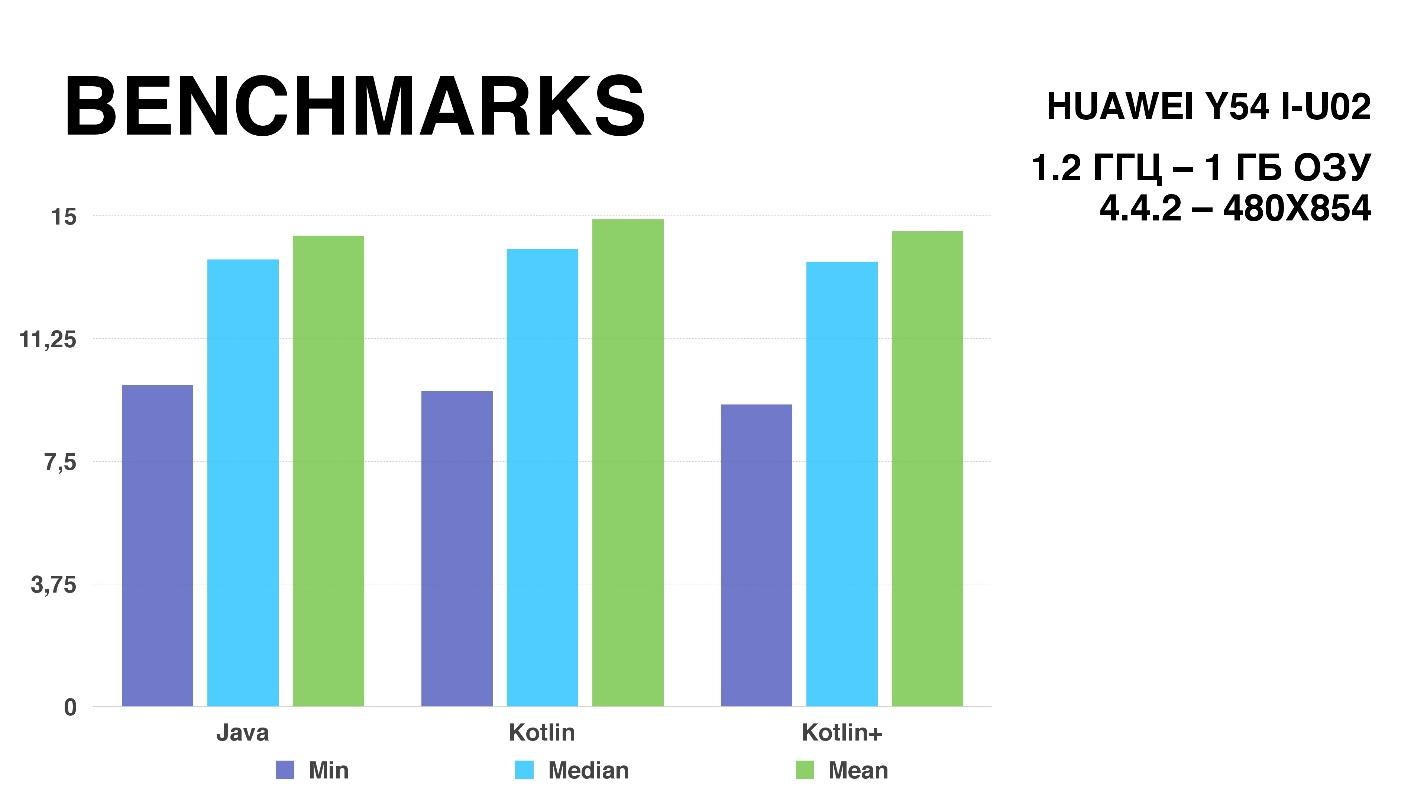
. — , . , , 0,04 . , , — , .
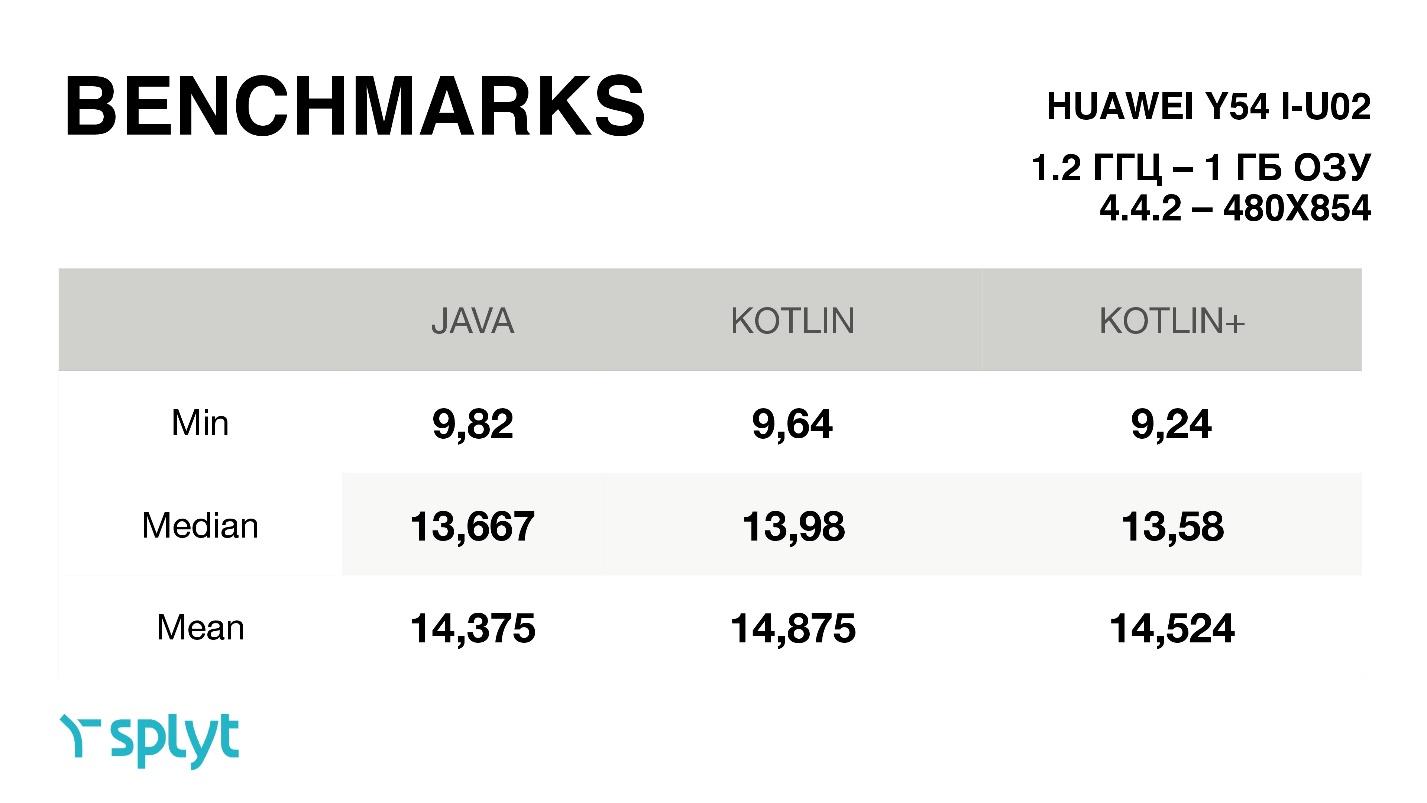
Kotlin, . , , . - , Kotlin , Java. , , , , . .

, , , , Kotlin Java. , - , , , , , .
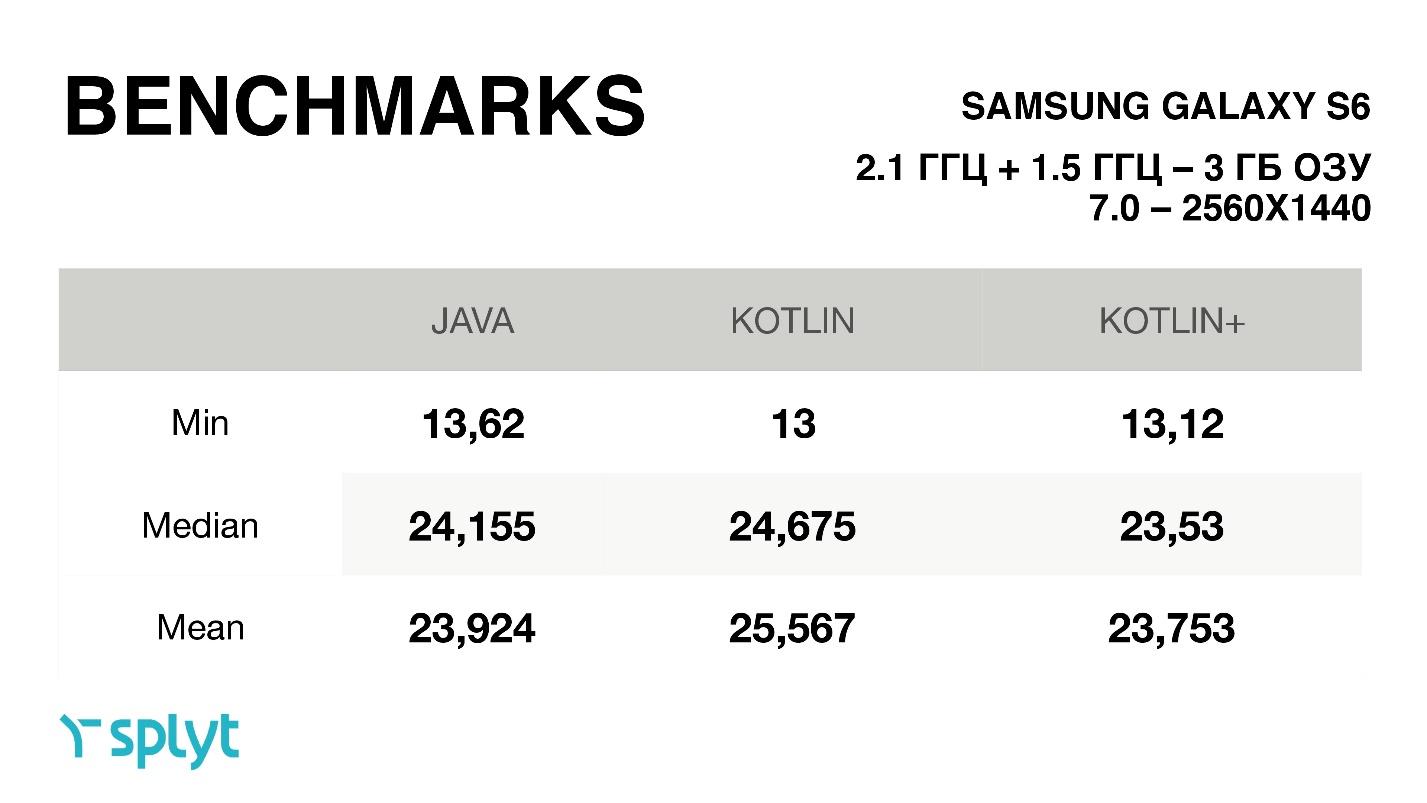
, : - Kotlin , .. . , . - - — 2 , Galaxy S6, .

Google Pixel. , 0,1 .
, , ,
- UI custom view.
- onmeasure-onlayout-ondraw. autoboxing, not null ..
- Kotlin, Java , .
- — .
, , . , , , , Kotlin, . , Kotlin .
, .
brand new AppsConf , Android . , . , 8 9 .