Aujourd'hui, l'un des principaux obstacles à l'introduction de l'apprentissage automatique dans les entreprises est l'incompatibilité des métriques et indicateurs ML avec lesquels la direction générale opère. L'analyste prévoit une augmentation des bénéfices? Mais vous devez comprendre dans quels cas l'apprentissage automatique deviendra la cause de l'augmentation et dans quels autres facteurs. Hélas, bien souvent, l'amélioration des mesures de ML ne conduit pas à une croissance des bénéfices. De plus, la complexité des données est parfois telle que même les développeurs expérimentés peuvent choisir des métriques incorrectes qui ne peuvent pas être orientées.
Voyons ce que sont les métriques ML et quand elles sont appropriées à utiliser. Nous analyserons les erreurs courantes et discuterons des options de réglage du problème pouvant convenir à l'apprentissage automatique et aux affaires.
Mesures ML: pourquoi y en a-t-il autant?
Les métriques d'apprentissage automatique sont très spécifiques et souvent trompeuses, montrant un
bon visage sur un mauvais jeu, un bon résultat pour les mauvais modèles. Pour tester des modèles et les améliorer, vous devez choisir une métrique qui reflète correctement la qualité du modèle et comment la mesurer. Habituellement, un ensemble de données de test distinct est utilisé pour évaluer la qualité du modèle. Et comme vous le savez, choisir la bonne métrique est une tâche difficile.
Quelles tâches sont le plus souvent résolues à l'aide de l'apprentissage automatique? Tout d'abord, il s'agit de régression, de classification et de regroupement. Les deux premiers sont ce que l'on appelle la formation avec l'enseignant: il existe un ensemble de données étiquetées, basé sur une certaine expérience, vous devez prédire la valeur définie. La régression est une prédiction d'une certaine valeur: par exemple, combien le client achètera, quelle est la résistance à l'usure du matériau, combien de kilomètres la voiture parcourra avant la première panne.
Le clustering est la définition d'une structure de données en mettant en évidence les clusters (par exemple, les catégories de clients), et nous n'avons aucune hypothèse sur ces clusters. Nous ne considérerons pas ce type de problème.
Les algorithmes d'apprentissage automatique optimisent (en calculant la fonction de perte) la métrique mathématique - la différence entre la prédiction du modèle et la valeur réelle. Mais si la métrique est la somme des écarts, alors avec le même nombre d'écarts dans les deux directions, cette somme sera nulle et nous ne saurons tout simplement pas s'il y a une erreur. Par conséquent, ils utilisent généralement l'absolu moyen (la somme des valeurs absolues des écarts) ou l'erreur quadratique moyenne (la somme des carrés des écarts par rapport à la valeur réelle). Parfois la formule est compliquée: prenez le logarithme ou extrayez la racine carrée de ces sommes. Grâce à ces mesures, vous pouvez évaluer la dynamique de la qualité des calculs du modèle, mais pour cela, vous devez comparer le résultat avec quelque chose.
Ce ne sera pas difficile s'il existe déjà un modèle construit avec lequel comparer les résultats. Et si la première fois que vous créiez un modèle? Dans ce cas, le coefficient de détermination, ou R2, est souvent utilisé. Le coefficient de détermination est exprimé comme suit:
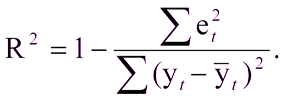
Où:
R ^ 2 - coefficient de détermination,
e
t ^ 2 est l'erreur quadratique moyenne,
y
t est la valeur correcte,
y
t avec une couverture est la valeur moyenne.
Unité moins le rapport de l'erreur quadratique moyenne du modèle à l'erreur quadratique moyenne de la valeur moyenne de l'échantillon d'essai.Autrement dit, le coefficient de détermination nous permet d'évaluer l'amélioration de la prédiction par le modèle.
Il arrive parfois qu'une erreur dans un sens ne soit pas équivalente à une erreur dans l'autre. Par exemple, si un modèle prédit une commande de marchandises dans l'entrepôt d'un entrepôt, il est tout à fait possible de faire une erreur et de commander un peu plus, les marchandises attendront leur temps dans l'entrepôt. Et si le modèle fait une erreur dans l'autre sens et commande moins, vous pouvez perdre des clients. Dans de tels cas, une erreur quantile est utilisée: les écarts positifs et négatifs par rapport à la valeur réelle sont pris en compte avec des poids différents.
Dans le problème de classification, le modèle d'apprentissage automatique répartit les objets en deux classes: l'utilisateur quitte le site ou ne quitte pas, la pièce est défectueuse ou non, etc. La précision des prédictions est souvent estimée comme le rapport entre le nombre de classes correctement définies et le nombre total de prédictions. Cependant, cette caractéristique peut rarement être considérée comme un paramètre adéquat.
 Fig. 1. Matrice d'erreur pour le problème de prédiction de retour clientExemple
Fig. 1. Matrice d'erreur pour le problème de prédiction de retour clientExemple : si 7 personnes assurées sur 100 demandent une indemnisation, le modèle prédisant l'absence d'un événement assuré aura une précision de 93% sans aucun pouvoir prédictif.
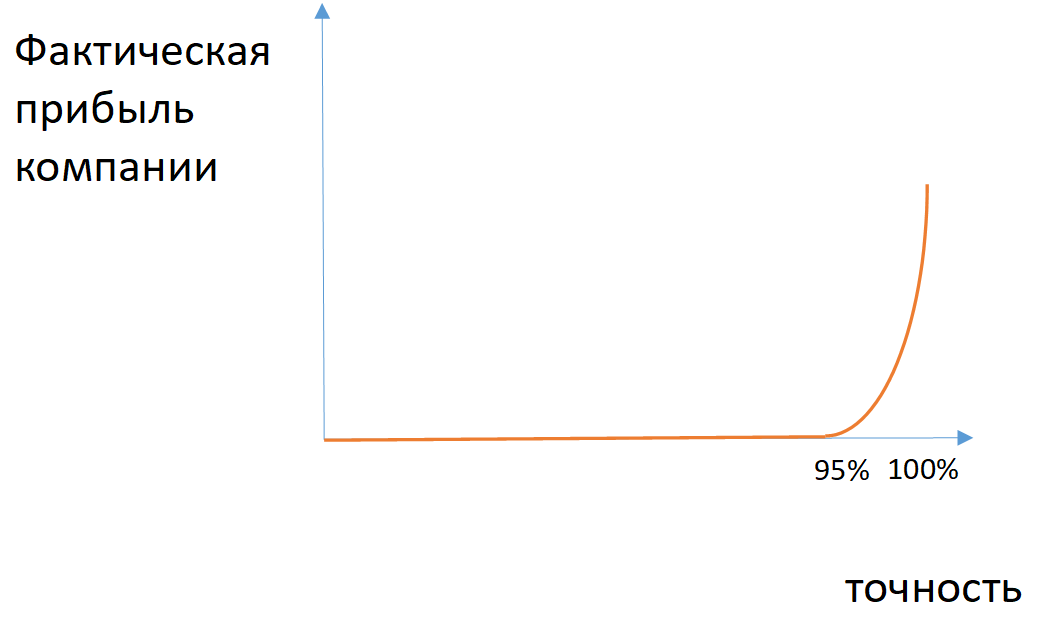 Fig. 2. Un exemple de la dépendance du profit réel de l'entreprise à l'exactitude du modèle dans le cas de classes déséquilibrées
Fig. 2. Un exemple de la dépendance du profit réel de l'entreprise à l'exactitude du modèle dans le cas de classes déséquilibréesPour certaines tâches, vous pouvez appliquer les métriques d'exhaustivité (le nombre d'objets correctement définis de la classe parmi tous les objets de cette classe) et de précision (le nombre d'objets correctement définis de la classe parmi tous les objets que le modèle a attribués à cette classe). S'il est nécessaire de prendre en compte à la fois l'exhaustivité et la précision, appliquer la moyenne harmonique entre ces valeurs (mesure F1).
À l'aide de ces mesures, vous pouvez évaluer les classifications effectuées. Cependant, de nombreux modèles prédisent la probabilité d'une relation entre un modèle et une classe particulière. De ce point de vue, il est possible de modifier le seuil de probabilité par rapport auquel les éléments seront affectés à l'une ou l'autre classe (par exemple, si le client part avec une probabilité de 60%, alors il peut être considéré comme restant). Si un seuil spécifique n'est pas défini, pour évaluer l'efficacité du modèle, il est possible de construire un graphique de la dépendance des métriques sur différentes valeurs de seuil (
courbe ROC ou courbe PR ), en prenant comme métrique l'aire sous la courbe sélectionnée.
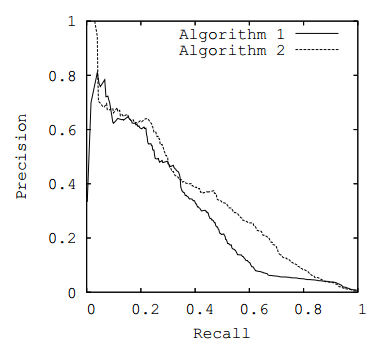 Fig. 3. Courbe PR
Fig. 3. Courbe PRMesures commerciales
Allégoriquement parlant, les mesures commerciales sont des éléphants: elles ne peuvent pas être négligées, et dans un de ces «éléphants», un grand nombre de «perroquets» d'apprentissage automatique peuvent s'adapter. La réponse à la question de savoir quelles mesures ML augmenteront les bénéfices dépend de l'amélioration. En fait, les mesures commerciales sont en quelque sorte liées à l'augmentation des bénéfices, mais nous n'arrivons presque jamais à leur associer directement les bénéfices. Les métriques intermédiaires sont couramment utilisées, par exemple:
- la durée des marchandises en stock et le nombre de demandes de marchandises lorsqu'elles ne sont pas disponibles;
- le montant d'argent que les clients sont sur le point de laisser;
- la quantité de matière économisée dans le processus de fabrication.
Lorsqu'il s'agit d'optimiser une entreprise à l'aide du machine learning, la création de deux modèles est toujours implicite: prédictive et optimisation.
Le premier est plus compliqué, le second utilise ses résultats. Les erreurs dans le modèle de prédiction nous obligent à étendre une marge plus grande dans le modèle d'optimisation, de sorte que la quantité optimisée est réduite.
Exemple : plus la précision de prédiction du comportement des clients ou la probabilité de défauts industriels est faible, moins les clients sont en mesure de conserver et moins la quantité de matériaux économisés.
Les mesures généralement acceptées de la réussite commerciale (EBITDA, etc.) sont rarement obtenues lors de la définition des tâches ML. Habituellement, vous devez étudier en profondeur les spécificités et appliquer les métriques acceptées dans le domaine dans lequel nous introduisons l'apprentissage automatique (vérification moyenne, assiduité, etc.).
Difficultés de traduction
Ironiquement, il est plus pratique d'optimiser les modèles à l'aide de mesures difficiles à comprendre pour les représentants des entreprises. Comment l'aire sous la courbe ROC dans le modèle de tonalité des commentaires est-elle liée à une taille de revenus spécifique? De ce point de vue, l'entreprise est confrontée à deux tâches: comment mesurer et comment maximiser l'effet de l'introduction du machine learning?
La première tâche est plus facile à résoudre si vous avez des données rétrospectives et en même temps d'autres facteurs peuvent être nivelés ou mesurés. Rien ne vous empêche alors de comparer les valeurs obtenues avec des données rétrospectives similaires. Mais il y a une complication: l'échantillon doit être représentatif et en même temps similaire à celui avec lequel nous testons le modèle.
Exemple : vous devez trouver les clients les plus similaires pour savoir si leur chèque moyen a augmenté. Mais en même temps, l'échantillon de clients devrait être suffisamment grand pour éviter les poussées dues à un comportement inhabituel. Ce problème peut être résolu en créant d'abord une sélection suffisamment large de clients similaires et en l'utilisant pour vérifier le résultat de leurs efforts.
Cependant, vous pouvez demander: comment traduire la métrique sélectionnée en une fonction de perte (que le modèle minimise) pour l'apprentissage automatique. Cette tâche ne peut pas être résolue immédiatement: les développeurs du modèle devront approfondir les processus métier. Mais si vous utilisez une métrique qui dépend de l'entreprise lors de la formation du modèle, la qualité des modèles augmente immédiatement. Supposons que si le modèle prédit les clients qui quitteront, alors dans le rôle d'une mesure commerciale, vous pouvez utiliser un graphique où le nombre de clients quittant, selon le modèle, est tracé sur un axe et le montant total des fonds pour ces clients sur l'autre axe. Avec l'aide d'un tel calendrier, un client professionnel peut choisir un point qui lui convient et travailler avec lui. Si, en utilisant des transformations linéaires, nous réduisons le graphique à une courbe PR (précision sur un axe, deuxième complétude), nous pouvons optimiser la zone sous cette courbe simultanément avec la métrique commerciale.
 Fig. 4. Courbe d'effet monétaire
Fig. 4. Courbe d'effet monétaireConclusion
Avant de définir la tâche d'apprentissage automatique et de créer un modèle, vous devez choisir une mesure raisonnable. Si vous souhaitez optimiser le modèle, vous pouvez utiliser l'une des métriques standard comme fonction d'erreur. Assurez-vous de coordonner avec le client la métrique sélectionnée, ses poids et d'autres paramètres, en convertissant les métriques commerciales en modèles ML. En termes de durée, cela peut être comparé au développement du modèle lui-même, mais sans cela, cela n'a aucun sens de commencer à travailler. Si vous impliquez des mathématiciens dans l'étude des processus métier, vous pouvez réduire considérablement la probabilité d'erreurs dans les métriques. Une optimisation efficace du modèle est impossible sans une compréhension du sujet et une déclaration conjointe du problème au niveau des affaires et des statistiques. Et après tous les calculs, vous pourrez évaluer le profit (ou les économies), en fonction de chaque amélioration du modèle.
Nikolay Knyazev ( iRumata ), chef du groupe d'apprentissage automatique, Jet Infosystems