
Récemment, le phishing a été le moyen le plus simple et le plus populaire pour les cybercriminels de voler de l'argent ou des informations. Par exemple, vous n'avez pas besoin d'aller loin. L'année dernière, les principales entreprises russes ont été confrontées à une attaque à l'échelle sans précédent - les attaquants ont massivement enregistré de fausses ressources, des copies exactes des sites des fabricants d'engrais et de produits pétrochimiques pour conclure des contrats en leur nom. Les dommages moyens d'une telle attaque sont de 1,5 million de roubles, sans parler des dommages à la réputation subis par l'entreprise. Dans cet article, nous expliquerons comment détecter efficacement les sites de phishing à l'aide de l'analyse des ressources (CSS, images JS, etc.) plutôt que HTML, et comment un spécialiste de la science des données peut résoudre ces problèmes.
Pavel Slipenchuk, architecte de systèmes d'apprentissage automatique, Groupe IB
L'épidémie de phishing
Selon le Groupe IB, plus de 900 clients de diverses banques sont quotidiennement victimes de phishing financier en Russie - ce chiffre représente 3 fois le nombre quotidien de victimes de logiciels malveillants. Les dégâts d'une attaque de phishing sur un utilisateur varient de 2 000 à 50 000 roubles. Les fraudeurs ne se contentent pas de copier le site Web d'une entreprise ou d'une banque, leurs logos et couleurs d'entreprise, leur contenu, leurs coordonnées, d'enregistrer un nom de domaine similaire, ils annoncent toujours activement leurs ressources sur les réseaux sociaux et les moteurs de recherche. Par exemple, ils essaient de mettre des liens vers leurs sites de phishing vers le haut des résultats de recherche pour la demande «Transférer de l'argent sur une carte». Le plus souvent, les faux sites sont créés précisément pour voler de l'argent lors du transfert de carte en carte ou avec un paiement instantané pour les services des opérateurs mobiles.
Le phishing (eng. Phishing, from fishing - fishing, fishing) est une forme de fraude sur Internet dont le but est d'inciter la victime à fournir des informations confidentielles au fraudeur. Le plus souvent, ils volent des mots de passe d'accès à un compte bancaire pour voler de l'argent, des comptes de réseaux sociaux (pour extorquer de l'argent ou envoyer du spam au nom de la victime), s'inscrire à des services payants, envoyer du courrier ou infecter un ordinateur, ce qui en fait un lien dans le botnet.
Par méthodes d'attaque, il existe 2 types de phishing ciblant les utilisateurs et les entreprises:
- Sites de phishing qui copient la ressource d'origine de la victime (banques, compagnies aériennes, magasins en ligne, entreprises, agences gouvernementales, etc.).
- Envois de phishing, e-mails, sms, messages sur les réseaux sociaux, etc.
Les individus sont souvent attaqués par les utilisateurs, et le seuil d'entrée dans ce segment de l'activité criminelle est si bas qu'un «investissement» minimal et des connaissances de base suffisent pour le mettre en œuvre. La propagation de ce type de fraude est également facilitée par des kits de phishing, des programmes de création de sites de phishing qui peuvent être achetés gratuitement dans Darknet sur les forums de pirates.
Les attaques contre les entreprises ou les banques sont différentes. Ils sont exécutés par des attaquants techniquement plus avertis. En règle générale, les grandes entreprises industrielles, les magasins en ligne, les compagnies aériennes et le plus souvent les banques sont choisies comme victimes. Dans la plupart des cas, le phishing revient à envoyer un e-mail avec un fichier infecté joint. Pour qu'une telle attaque réussisse, le «personnel» du groupe doit disposer de spécialistes de l'écriture de code malveillant, de programmeurs pour automatiser leurs activités, et de personnes capables d'effectuer une reconnaissance initiale de la victime et de trouver des faiblesses en elle.
En Russie, selon nos estimations, 15 groupes criminels sont impliqués dans le phishing visant des institutions financières. Le montant des dégâts est toujours faible (dix fois moins que celui des chevaux de Troie bancaires), mais le nombre de victimes qu'ils attirent sur leurs sites est estimé à des milliers par jour. Environ 10 à 15% des visiteurs des sites de phishing financier saisissent eux-mêmes leurs données.
Lorsqu'une page de phishing apparaît, la facture dure des heures, voire des minutes, car les utilisateurs encourent de graves dommages financiers et, dans le cas des entreprises, des atteintes à la réputation. Par exemple, certaines pages de phishing réussies étaient disponibles pendant moins d'une journée, mais ont pu infliger des dommages à des montants de 1 000 000 de roubles.
Dans cet article, nous nous attarderons sur le premier type de phishing: les sites de phishing. Les ressources «suspectées» d'hameçonnage peuvent être facilement détectées à l'aide de divers moyens techniques: pots de miel, robots d'exploration, etc., cependant, il est problématique de s'assurer qu'il s'agit bien d'hameçonnage et d'identifier la marque attaquée. Voyons comment résoudre ce problème.
La pêche
Si une marque ne surveille pas sa réputation, elle devient une cible facile. Il est nécessaire de saisir l'initiative des criminels immédiatement après l'enregistrement de leurs faux sites. En pratique, la recherche d'une page de phishing est divisée en 4 étapes:
- Formation de nombreuses adresses suspectes (URL) pour les scans d'hameçonnage (crawler, pots de miel, etc.).
- La formation de nombreuses adresses de phishing.
- Classification des adresses de phishing déjà détectées par domaine d'activité et technologie attaquée, par exemple «RBS :: Sberbank Online» ou «RBS :: Alfa-Bank».
- Recherchez une page de donateur.
La mise en œuvre des paragraphes 2 et 3 incombe aux spécialistes de la science des données.
Après cela, vous pouvez déjà prendre des mesures actives pour bloquer la page de phishing. En particulier:
- mettre sur liste noire les produits du Groupe IB et les produits de nos partenaires;
- envoyer automatiquement ou manuellement des lettres au propriétaire de la zone de domaine avec une demande de suppression de l'URL de phishing;
- envoyer des lettres au service de sécurité de la marque attaquée;
- etc.

Méthodes d'analyse HTML
La solution classique aux tâches de vérification des adresses de phishing suspectes et de détection automatique d'une marque affectée consiste à analyser les pages source HTML de différentes manières. La chose la plus simple est d'écrire des expressions régulières. C'est drôle, mais cette astuce fonctionne toujours. Et aujourd'hui, la plupart des hameçonneurs novices copient simplement le contenu du site d'origine.
De plus, des chercheurs de kits de phishing peuvent développer des systèmes anti-phishing très efficaces. Mais dans ce cas, vous devez examiner la page HTML. De plus, ces solutions ne sont pas universelles - leur développement nécessite une base des «baleines» elles-mêmes. Certains kits de phishing peuvent ne pas être connus du chercheur. Et, bien sûr, l'analyse de chaque nouvelle «baleine» est un processus assez laborieux et coûteux.
Tous les systèmes de détection de phishing basés sur l'analyse de pages HTML cessent de fonctionner après l'obscurcissement HTML. Et dans de nombreux cas, il suffit de simplement changer le cadre de la page HTML.
Selon Group-IB, il n'y a actuellement pas plus de 10% de ces sites de phishing, mais même en manquer un peut coûter cher à la victime.
Ainsi, pour qu'un pêcheur contourne le verrou, il suffit de changer le cadre HTML, moins souvent - pour obscurcir la page HTML (confondre le balisage et / ou charger le contenu via JS).
Énoncé du problème. Méthode basée sur les ressources
Les méthodes basées sur l'analyse des ressources utilisées sont beaucoup plus efficaces et universelles pour détecter les pages de phishing. Une ressource est un fichier qui est téléchargé lors du rendu d'une page Web (toutes les images, feuilles de style en cascade (CSS), fichiers JS, polices, etc.).
Dans ce cas, vous pouvez créer un graphe bipartite, où certains sommets seront des adresses suspectes de phishing, tandis que d'autres seront des ressources qui leur seront associées.
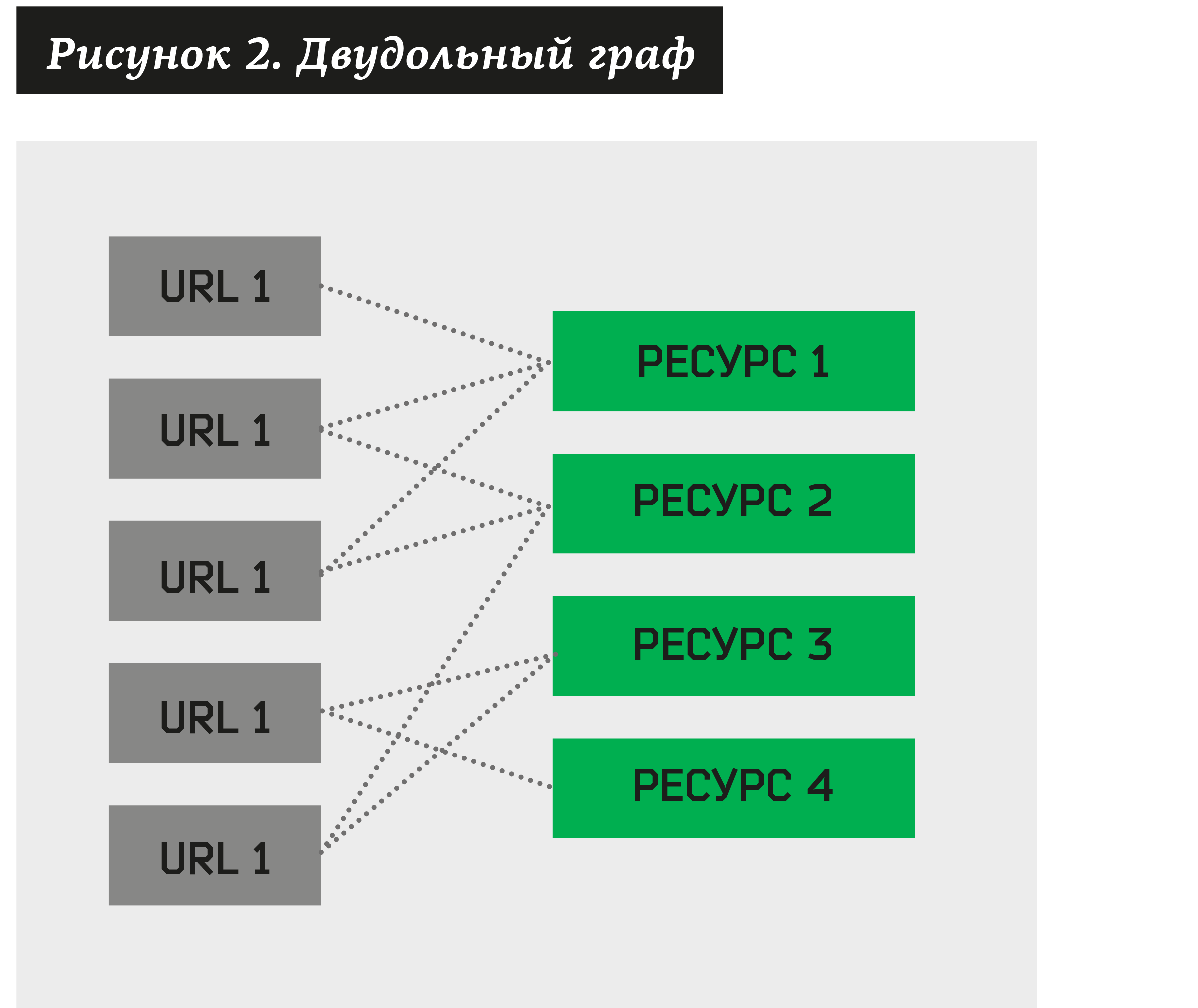
La tâche du clustering se pose - pour trouver une collection de telles ressources qui possèdent un assez grand nombre d'URL différentes. En construisant un tel algorithme, nous pouvons décomposer tout graphe biparti en grappes.
L'hypothèse est que, sur la base de données réelles, avec un degré de probabilité assez élevé, on peut dire que le cluster contient une collection d'URL appartenant à la même marque et générées par un kit de phishing. Ensuite, pour tester cette hypothèse, chacun de ces clusters peut être envoyé pour vérification manuelle au CERT (Information Security Incident Response Center). L'analyste, à son tour, donnerait le statut du cluster: +1 («approuvé») ou –1 (rejeté). Un analyste attribuerait également une marque attaquée à tous les clusters approuvés. Ce «travail manuel» prend fin - le reste du processus est automatisé. En moyenne, un groupe approuvé représente 152 adresses de phishing (données en juin 2018), et parfois des grappes de 500 à 1 000 adresses se rencontrent même! L'analyste passe environ 1 minute pour approuver ou réfuter le cluster.
Ensuite, tous les clusters rejetés sont supprimés du système, et après un certain temps, toutes leurs adresses et ressources sont à nouveau alimentées à l'entrée de l'algorithme de clustering. En conséquence, nous obtenons de nouveaux clusters. Et encore une fois, nous les envoyons pour vérification, etc.
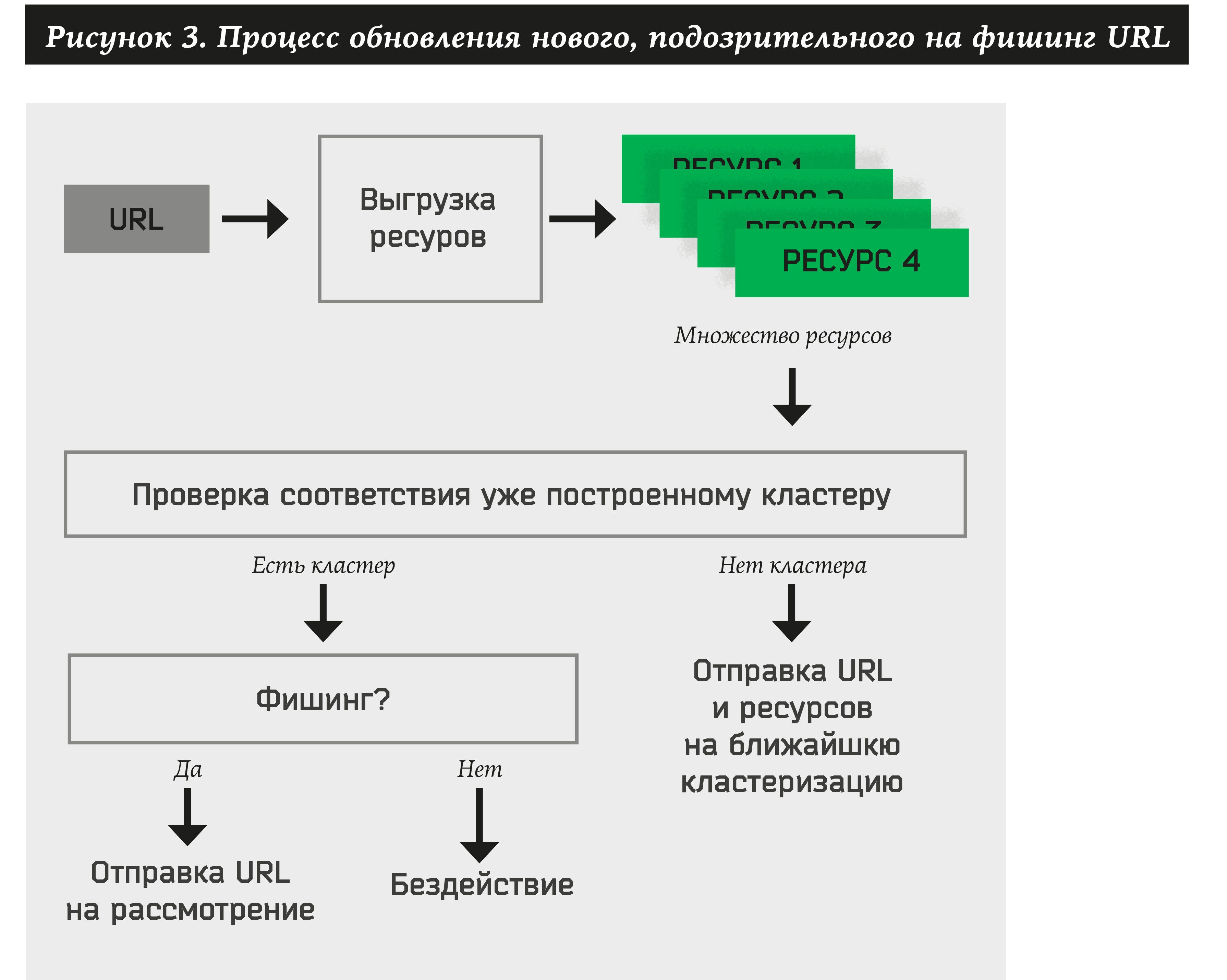
Ainsi, pour chaque adresse nouvellement reçue, le système doit effectuer les opérations suivantes:
- Extraire de nombreuses ressources pour le site.
- Recherchez au moins un cluster précédemment approuvé.
- Si l'URL appartient à un cluster, extrayez automatiquement le nom de la marque et effectuez une action pour celui-ci (avertir le client, supprimer la ressource, etc.).
- Si aucun cluster ne peut être affecté à des ressources, ajoutez l'adresse et les ressources au graphique bipartite. À l'avenir, cette URL et ces ressources participeront à la formation de nouveaux clusters.
Algorithme de regroupement de ressources simple
L'une des nuances les plus importantes qu'un spécialiste de la Data Science en sécurité de l'information devrait prendre en compte est le fait qu'une personne est son adversaire. Pour cette raison, les conditions et les données d'analyse changent très rapidement! Une solution qui résout remarquablement le problème maintenant, après 2-3 mois, peut cesser de fonctionner en principe. Par conséquent, il est important de créer des mécanismes universels (maladroits), si possible, ou les systèmes les plus flexibles qui peuvent être rapidement développés. Le spécialiste de la science des données en sécurité de l'information ne peut pas résoudre le problème une fois pour toutes.
Les méthodes de clustering standard ne fonctionnent pas en raison du grand nombre de fonctionnalités. Chaque ressource peut être représentée comme un attribut booléen. Cependant, dans la pratique, nous obtenons quotidiennement 5000 adresses de sites Web et chacune d'entre elles contient en moyenne 17,2 ressources (données de juin 2018). La malédiction de la dimensionnalité ne permet même pas de charger des données en mémoire, encore moins de construire des algorithmes de clustering.
Une autre idée est d'essayer de se regrouper en grappes en utilisant divers algorithmes de filtrage collaboratif. Dans ce cas, il était nécessaire de créer une autre fonctionnalité - appartenant à une marque particulière. La tâche sera réduite au fait que le système devrait prévoir la présence ou l'absence de ce signe pour les URL restantes. La méthode a donné des résultats positifs, mais avait deux inconvénients:
- pour chaque marque, il fallait créer sa propre caractéristique de filtrage collaboratif;
- avait besoin d'un échantillon de formation.
Récemment, de plus en plus d'entreprises veulent protéger leur marque sur Internet et demandent à automatiser la détection des sites de phishing. Chaque nouvelle marque prise sous protection ajouterait un nouvel attribut. Et créer un échantillon de formation pour chaque nouvelle marque représente un travail manuel supplémentaire et du temps.
Nous avons commencé à chercher une solution à ce problème. Et ils ont trouvé un moyen très simple et efficace.
Pour commencer, nous allons construire des paires de ressources en utilisant l'algorithme suivant:
- Prenons toutes sortes de ressources (nous les désignons comme a) pour lesquelles il existe au moins N1 adresses, nous désignons cette relation par # (a) ≥ N1.
- Nous construisons toutes sortes de paires de ressources (a1, a2) et sélectionnons uniquement celles pour lesquelles il y aura au moins N2 adresses, c'est-à-dire # (a1, a2) ≥ N2.
Ensuite, nous considérons également les paires constituées de paires obtenues dans le paragraphe précédent. En conséquence, nous obtenons quatre: (a1, a2) + (a3, a4) → (a1, a2, a3, a4). De plus, si au moins un élément est présent dans l'une des paires, au lieu de quatre nous obtenons des triplets: (a1, a2) + (a2, a3) → (a1, a2, a3). De l'ensemble résultant, nous ne laissons que les quatre et les triplets qui correspondent à au moins N3 adresses. Et ainsi de suite ...
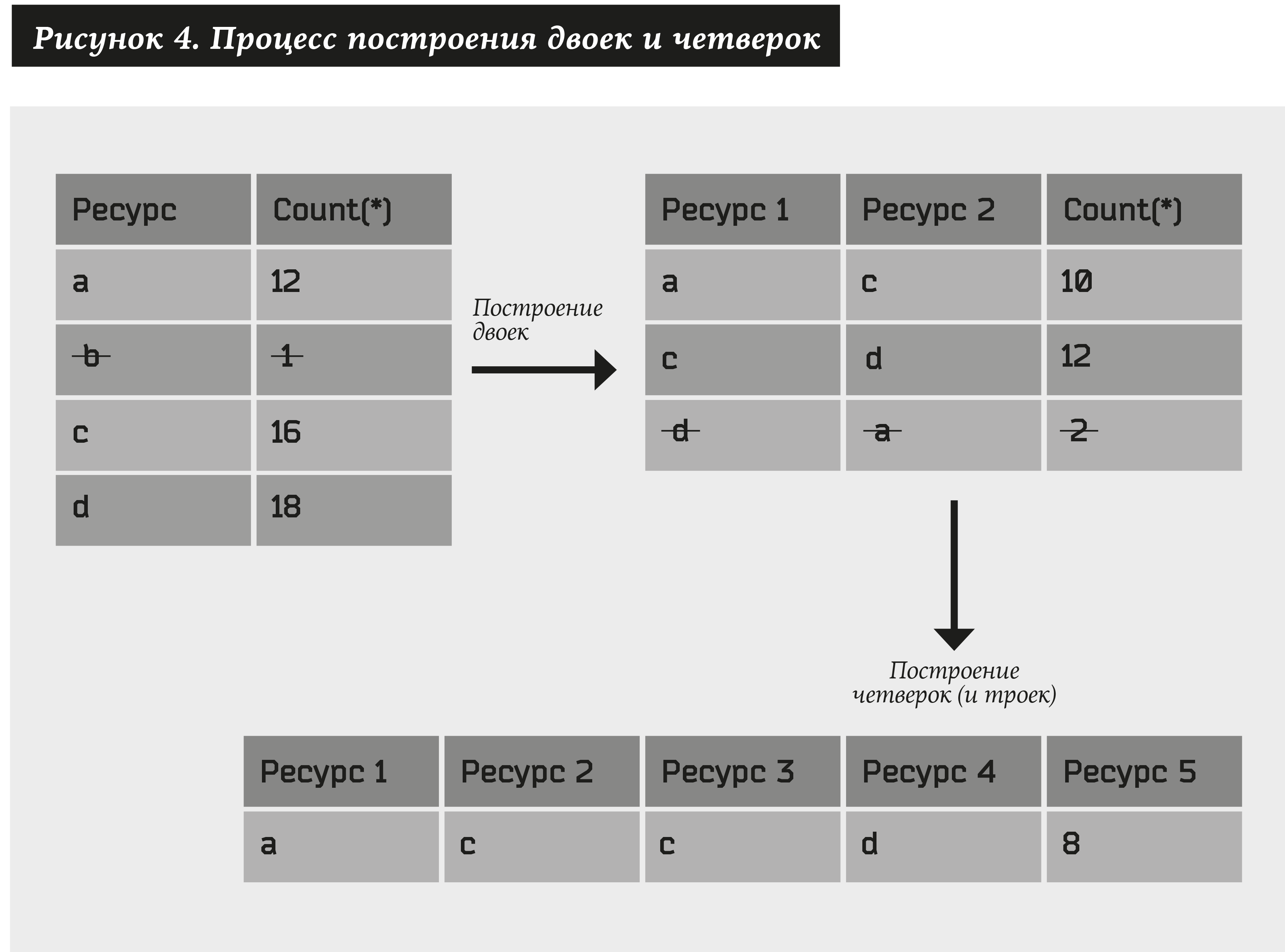
Vous pouvez obtenir plusieurs ressources de longueur arbitraire. Limitez le nombre de pas à U. Alors N1, N2 ... NU sont les paramètres du système.
Les valeurs N1, N2 ... NU sont les paramètres de l'algorithme, elles sont définies manuellement. Dans le cas général, nous avons CL2 paires différentes, où L est le nombre de ressources, c'est-à-dire la difficulté de construire des paires sera O (L2). Ensuite, un quad est créé à partir de chaque paire. Et en théorie, nous obtenons probablement O (L4). Cependant, dans la pratique, ces paires sont beaucoup plus petites, et avec un grand nombre d'adresses, la dépendance O (L2log L) a été obtenue empiriquement. De plus, les étapes suivantes (transformer les deux en quatre, les quadruples en huit, etc.) sont négligeables.
Il convient de noter que L est le nombre d'URL non groupées. Toutes les URL qui peuvent déjà être attribuées à un cluster précédemment approuvé ne font pas partie de la sélection pour le clustering.
En sortie, vous pouvez créer de nombreux clusters constitués des plus grands ensembles de ressources possibles. Par exemple, s'il existe (a1, a2, a3, a4, a5) satisfaisant aux limites de Ni, il faut retirer de l'ensemble des clusters (a1, a2, a3) et (a4, a5).
Ensuite, chaque cluster reçu est envoyé pour vérification manuelle, où l'analyste CERT lui attribue le statut: +1 («approuvé») ou –1 («rejeté»), et indique également si les URL qui tombent dans le cluster sont du phishing ou des sites légitimes.
Lorsque vous ajoutez une nouvelle ressource, le nombre d'URL peut diminuer, rester le même, mais ne jamais augmenter. Par conséquent, pour toutes les ressources a1 ... aN, la relation est vraie:
# (a1) ≥ # (a1, a2) ≥ # (a1, a2, a3) ≥ ... ≥ # (a1, a2, ..., aN).
Par conséquent, il est sage de définir les paramètres:
N1 ≥ N2 ≥ N3 ≥ ... ≥ NU.
En sortie, nous distribuons toutes sortes de groupes pour vérification. Dans la fig. 1 au tout début de l'article présente de véritables clusters dont toutes les ressources sont des images.
Utiliser l'algorithme en pratique
Notez que vous n'avez plus besoin d'explorer les kits de phishing! Le système se met automatiquement en cluster et trouve la page de phishing nécessaire.
Chaque jour, le système reçoit 5 000 pages de phishing et construit au total 3 à 25 nouveaux clusters par jour. Pour chaque cluster, une liste de ressources est téléchargée, de nombreuses captures d'écran sont créées. Ce cluster est envoyé à CERT Analytics pour confirmation ou refus.
Au démarrage, la précision de l'algorithme était faible - seulement 5%. Cependant, après 3 mois, le système a conservé une précision de 50 à 85%. En fait, la précision n'a pas d'importance! L'essentiel est que les analystes aient le temps de visualiser les clusters. Par conséquent, si le système, par exemple, génère environ 10 000 clusters par jour et que vous n'avez qu'un seul analyste, vous devrez modifier les paramètres du système. Si ce n'est pas plus de 200 par jour, c'est une tâche réalisable pour une seule personne. Comme le montre la pratique, l'analyse visuelle prend en moyenne environ 1 minute.
L'exhaustivité du système est d'environ 82%. Les 18% restants sont soit des cas uniques de phishing (par conséquent, ils ne peuvent pas être groupés), soit du phishing, qui a une petite quantité de ressources (il n'y a rien à grouper), ou des pages de phishing qui dépassent les limites des paramètres N1, N2 ... NU.
Un point important: à quelle fréquence démarrer un nouveau clustering sur de nouvelles URL non livrées? Nous faisons cela toutes les 15 minutes. De plus, selon la quantité de données, le temps de clustering lui-même prend 10-15 minutes. Cela signifie qu'après l'apparition de l'URL de phishing, il y a un décalage de 30 minutes.
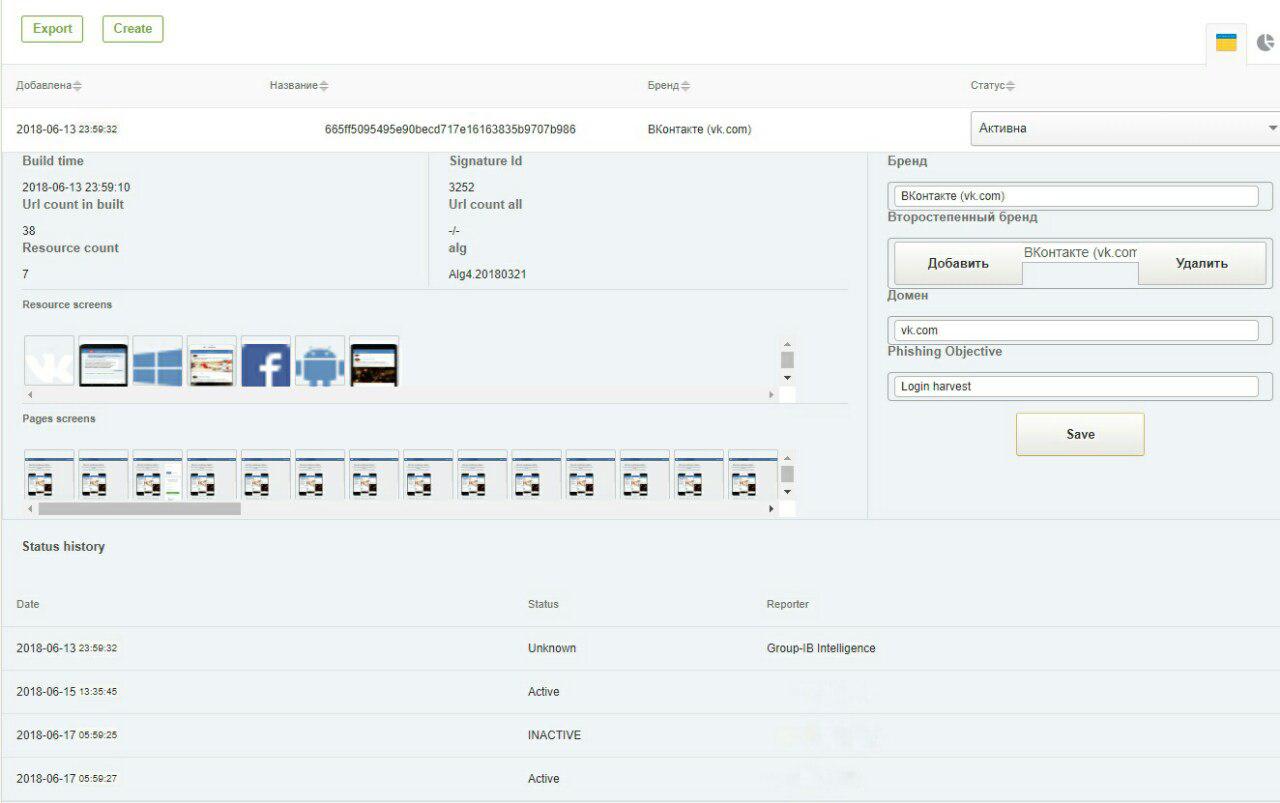
Vous trouverez ci-dessous 2 captures d'écran du système GUI: signatures pour détecter le phishing sur les réseaux sociaux VKontakte et Bank Of America.
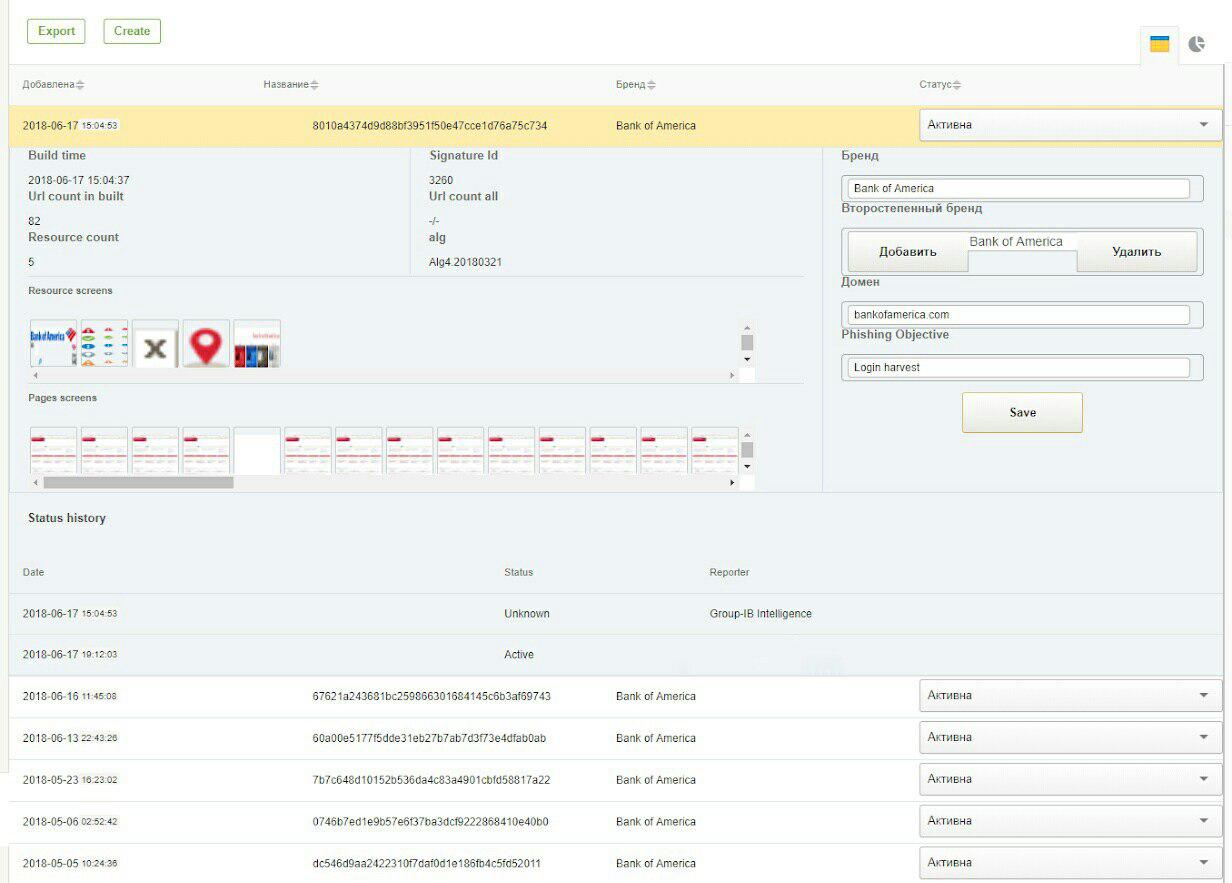
Lorsque l'algorithme ne fonctionne pas
Comme déjà mentionné ci-dessus, l'algorithme ne fonctionne pas en principe si les limites spécifiées par les paramètres N1, N2, N3 ... NU ne sont pas atteintes, ou si la quantité de ressources est trop petite pour former le cluster nécessaire.
Un phishing peut contourner l'algorithme en créant des ressources uniques pour chaque site de phishing. Par exemple, dans chaque image, vous pouvez modifier un pixel, et pour les bibliothèques JS et CSS chargées, utilisez l'obscurcissement. Dans ce cas, il est nécessaire de développer un algorithme de hachage comparable (hachage perceptuel) pour chaque type de documents chargés. Toutefois, ces problèmes dépassent le cadre de cet article.
Tout mettre ensemble
Nous connectons notre module avec les habitués HTML classiques, les données obtenues de Threat Intelligence (système de cyber-intelligence), et nous obtenons une plénitude de 99,4%. Bien sûr, il s'agit de l'exhaustivité de données qui ont déjà été classées par Threat Intelligence comme suspectes de phishing.
Personne ne connaît l'intégralité de toutes les données possibles, car il est impossible de couvrir l'ensemble de Darknet en principe, cependant, selon les rapports de Gartner, IDC et Forrester, Group-IB est l'un des principaux fournisseurs internationaux de solutions Threat Intelligence dans ses capacités.
Qu'en est-il des pages de phishing non classifiées? Environ 25 à 50 d'entre eux par jour. Ils peuvent être vérifiés manuellement. Dans l'ensemble, il y a toujours du travail manuel dans toute tâche qui est assez difficile pour Data Sciense dans le domaine de la sécurité de l'information, et toute allégation d'automatisation à 100% est une fiction marketing. La tâche d'un spécialiste Data Sciense est de réduire le travail manuel de 2 à 3 ordres de grandeur, ce qui rend le travail de l'analyste aussi efficace que possible.
Article publié sur
JETINFO