Capture d'écran des données collectées:
 Les systèmes de sécurité modernes sont TRÈS gourmands en ressources.
Les systèmes de sécurité modernes sont TRÈS gourmands en ressources. Pourquoi? Parce qu'ils comptent plus que de nombreux serveurs de production et systèmes de Business Intelligence.
Qu'en pensent-ils? Je vais vous expliquer maintenant. Commençons par un simple: par convention, la première génération de dispositifs de protection était très simple - au niveau du «démarrage» et du «non démarrage». Par exemple, un pare-feu autorise le trafic selon certaines règles et n'autorise pas le trafic selon d'autres. Naturellement, une puissance de calcul spéciale n'est pas nécessaire pour cela.
La prochaine génération a acquis des règles plus complexes. Il y avait donc des systèmes de réputation qui, en fonction des actions étranges des utilisateurs et des changements dans les processus métier, leur attribuaient une cote de fiabilité selon des modèles prédéfinis et définissaient manuellement des seuils de fonctionnement.
Désormais, les systèmes UBA (User Behavior Analytics) analysent le comportement des utilisateurs, les comparent avec les autres employés de l'entreprise et évaluent la cohérence et l'exactitude de l'action de chaque employé. Cela est dû aux méthodes Data Lake et au traitement assez gourmand en ressources, mais automatisé par des algorithmes d'apprentissage automatique - principalement parce qu'il faut plusieurs milliers de jours-homme pour écrire tous les scénarios possibles avec vos mains.
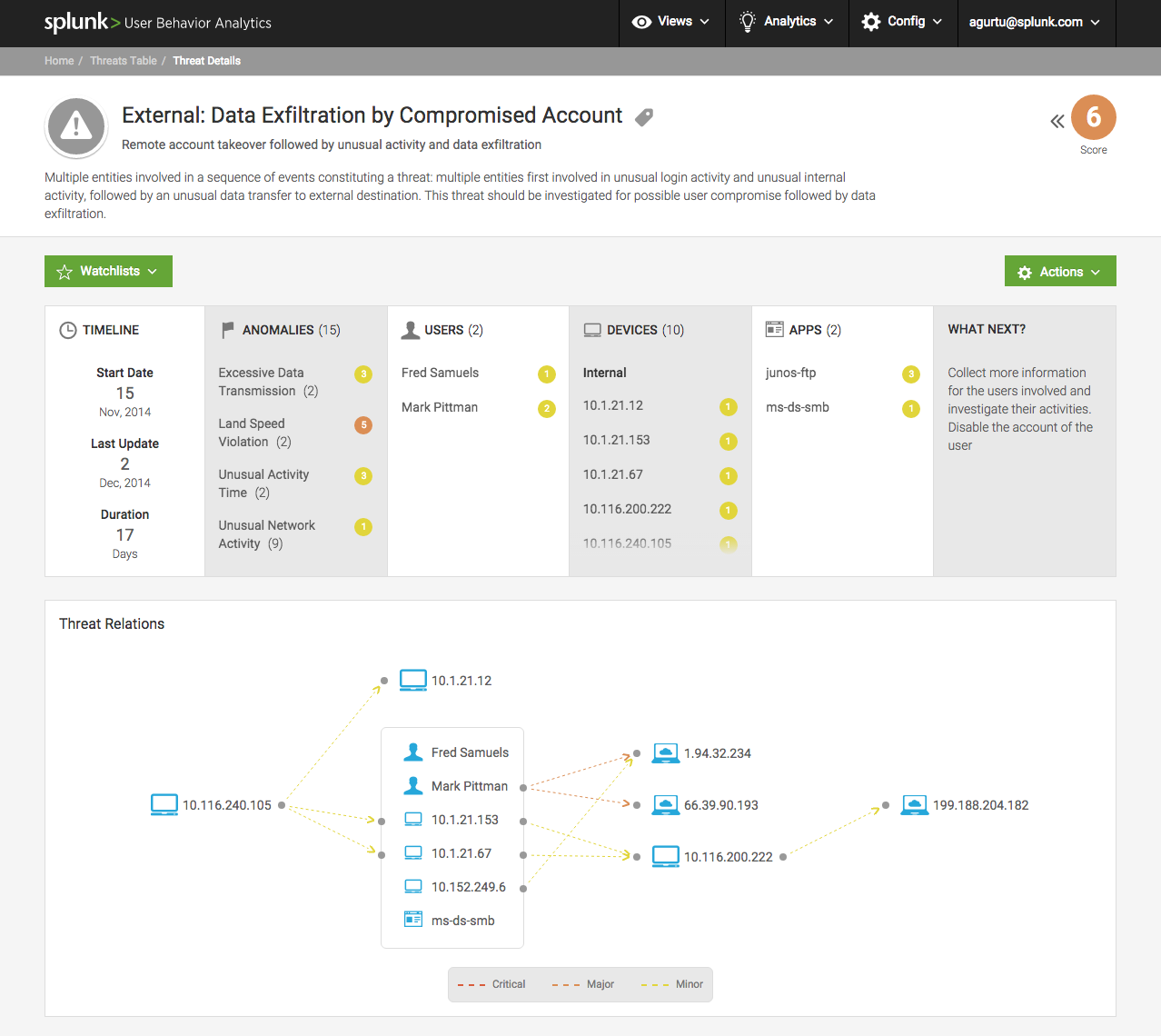
SIEM classique
Jusqu'en 2016 environ, l'approche était considérée comme progressive lorsque tous les événements de tous les nœuds du réseau sont collectés au même endroit où se trouve le serveur d'analyse. Le serveur d'analyse peut collecter, filtrer les événements et les mapper aux règles de corrélation. Par exemple, si un enregistrement de fichier massif démarre sur un poste de travail, il peut s'agir d'un signe de virus de chiffrement, ou il peut ne pas l'être. Mais juste au cas où, le système enverra une notification à l'administrateur. S'il y a plusieurs stations, la probabilité de déploiement du malware augmente. Nous devons tirer la sonnette d'alarme.
Si un utilisateur a frappé sur un domaine étrange enregistré il y a quelques semaines, et après quelques minutes, toute cette musique en couleur a disparu, alors il s'agit presque certainement d'un virus de chiffrement. Il est nécessaire d'éteindre le poste de travail et d'isoler le segment de réseau, tout en avertissant les administrateurs.
SIEM a comparé les données du DLP, du pare-feu, de l'antispam, etc., ce qui a permis de répondre très bien aux différentes menaces. Le point faible était ces modèles et déclencheurs - ce qu'il faut considérer comme une situation dangereuse et ce qui ne l'est pas. De plus, comme dans le cas des virus et des divers DDoS délicats, les spécialistes du centre SOC ont commencé à former leurs bases de signes d'attaque. Pour chaque type d'attaque, un scénario a été envisagé, des symptômes se sont détachés, des actions supplémentaires leur ont été attribuées. Tout cela a nécessité un perfectionnement et un ajustement continus du système en mode 24 x 7.
Cela fonctionne - ne le touchez pas, mais tout fonctionne bien!
C'est pourquoi il est impossible de se passer d'UBA? Le premier problème est qu'il est impossible de prescrire avec vos mains. Parce que différents services se comportent différemment - et différents utilisateurs aussi. Si vous enregistrez des événements pour l'utilisateur moyen au sein de l'entreprise, le support, la comptabilité, le service d'appel d'offres et les administrateurs seront très distingués. L'administrateur du point de vue d'un tel système est clairement un utilisateur malveillant, car il en fait beaucoup et y rampe activement. Le support est malveillant car il se connecte à tout le monde. La comptabilité transmet les données via des tunnels cryptés. Et le service des appels d'offres fusionne constamment les données de l'entreprise lors de la publication de la documentation.
Conclusion - il est nécessaire de prescrire des scénarios d'utilisation des ressources pour chacun. Puis plus profondément. Puis encore plus profondément. Puis quelque chose change dans les processus (et cela arrive tous les jours) et doit être à nouveau prescrit.
Il serait logique d'utiliser quelque chose comme une «moyenne mobile» lorsque la norme pour l'utilisateur est automatiquement déterminée. Nous y reviendrons.
Le deuxième problème est que les attaquants sont devenus beaucoup plus précis. Auparavant, la vidange des données, même si vous aviez raté le moment du piratage, était assez facile à détecter - par exemple, les pirates pouvaient se télécharger un fichier d'intérêt par courrier ou hébergement de fichiers et, au mieux, le chiffrer dans une archive pour éviter la détection par le système DLP.
Maintenant, tout est plus intéressant. C'est ce que nous avons vu dans nos centres SOC au cours de la dernière année.
- Stéganographie par l'envoi de photos sur Facebook. Le malware s'est enregistré auprès de FB et s'est abonné au groupe. Chaque photo publiée dans le groupe était équipée d'un bloc de données intégré contenant des instructions pour le logiciel malveillant. Compte tenu des pertes lors de la compression JPEG, il s'est avéré transférer environ 100 octets par image. De plus, le malware lui-même a publié 2-3 photos par jour sur le réseau social, ce qui était suffisant pour transférer les identifiants / mots de passe fusionnés via mimikatz.
- Remplir des formulaires sur les sites. Le logiciel malveillant a exécuté un simulateur d'action de l'utilisateur, s'est rendu sur certains sites, y a trouvé des formulaires de «rétroaction» et a envoyé des données, encodant des données binaires en BASE64. Nous l'avons déjà compris dans un système de nouvelle génération. Sur le SIEM classique, ne connaissant pas une telle méthode d'envoi, ils ne remarqueraient probablement rien.
- D'une manière standard - hélas, d'une manière standard - ils ont mélangé des données dans le trafic DNS. Il existe de nombreuses technologies pour la stéganographie dans le DNS et généralement la construction de tunnels via le DNS, ici l'accent n'était pas mis sur l'interrogation de certains domaines, mais sur les types de requêtes. Le système a déclenché une alarme mineure concernant la croissance du trafic DNS pour l'utilisateur. Les données ont été envoyées lentement et à des intervalles différents pour rendre l'analyse difficile avec les fonctions de sécurité.
Pour la pénétration, ils utilisent généralement des virus strictement personnalisés créés directement sous les utilisateurs de la société cible. De plus, les attaques passent souvent par un lien intermédiaire. Par exemple, au début, l'entrepreneur est compromis, puis le logiciel malveillant est introduit dans l'entreprise principale.
Les virus de ces dernières années se trouvent presque toujours strictement dans la RAM et sont supprimés dès les premières perspectives - l'accent étant mis sur l'absence de traces. La criminalistique dans de telles conditions est très difficile.
Résultat global - SIEM fait un mauvais travail. Beaucoup de ce qui est hors de vue. Quelque chose comme ça, une place vide est apparue sur le marché: pour que le système n'ait pas à être adapté au type d'attaque, mais elle-même a compris ce qui n'allait pas.
Comment s'est-elle "comprise"?
Les premiers systèmes de sécurité de réputation étaient des modules antifraude pour la protection contre le blanchiment d'argent dans les banques. Pour la banque, l'essentiel est d'identifier toutes les transactions frauduleuses. Autrement dit, ce n'est pas dommage de reprendre un peu, l'essentiel est que l'opérateur humain comprenne ce qu'il faut regarder en premier. Et il n'a pas été submergé par de très petites alarmes.
Les systèmes fonctionnent comme ceci:
- Ils construisent un profil utilisateur basé sur de nombreux paramètres. Par exemple, comment il dépense habituellement de l'argent: ce qu'il achète, comment il achète, à quelle vitesse il entre un code de confirmation, à partir de quels appareils il le fait, etc.
- La couche logique vérifie s'il est possible d'obtenir à temps du point où le paiement a été effectué, à un autre point du transport pour la période entre les transactions. Si l'achat se fait dans une autre ville, il est vérifié si l'utilisateur se rend souvent dans d'autres villes, s'il se trouve dans un autre pays - si l'utilisateur se rend souvent dans d'autres pays, et un billet d'avion récemment acheté ajoute une chance que l'alarme ne soit pas nécessaire.
- Module de réputation - si l'utilisateur fait tout dans le cadre de son comportement normal, alors pour ses actions des points positifs sont attribués (très lentement), et si dans le cadre d'atypique - négatif.
Parlons de ce dernier plus en détail.
Exemple 1. Toute votre vie, vous vous êtes acheté une tarte et du cola chez McDonald's le vendredi, puis avez soudainement acheté 500 roubles mardi matin. Moins 2 points pour un temps non standard, moins 3 points pour un achat non standard. Le seuil d'alarme pour vous est défini sur –20. Il ne se passe rien.
Pour environ 5-6 de ces achats, vous retirerez ces points à zéro, car le système se souviendra qu'il est normal que vous vous rendiez chez McDonald's mardi matin. Bien sûr, je simplifie énormément, mais la logique de travail est à peu près la même.
Exemple 2. Toute votre vie, vous vous êtes acheté diverses petites choses en tant qu'utilisateur régulier. Vous paierez à l'épicerie (le système «sait» déjà combien vous mangez habituellement et où vous achetez le plus souvent, ou plutôt, il ne le sait pas, mais écrit simplement dans votre profil), puis achetez un billet pour le métro pendant un mois, ou commandez quelque chose de petit via la boutique en ligne. Et maintenant, vous achetez un piano à Hong Kong pour 8 mille dollars. Pourrait? Pourrait. Regardons les points: –15 pour ce à quoi cela ressemble une fraude standard, –10 pour un montant non standard, –5 pour un lieu et une heure non standard, –5 pour un autre pays sans acheter de billet, –7 pour n'avoir rien utilisé auparavant ils ont pris à l'étranger, +5 pour leur appareil standard, +5 pour ce que les autres utilisateurs de la banque y ont acheté.
Le seuil d'alarme pour vous est défini sur –20. La transaction est «suspendue», un employé du BI de la banque commence à comprendre la situation. Ceci est un cas très simple. Très probablement, après 5 minutes, il vous appellera et vous dira: "Avez-vous vraiment décidé d'acheter quelque chose dans un magasin de musique à Hong Kong à 4 heures du matin pour 8 mille dollars?" Si vous répondez oui, ils ignoreront la transaction. Les données tomberont dans le profil comme une fois une action terminée, puis pour des actions similaires, moins de points négatifs seront donnés jusqu'à ce qu'ils deviennent la norme.
Comme je l'ai dit, je simplifie vraiment, vraiment. Les banques investissent dans les systèmes de réputation depuis des années et les perfectionnent depuis des années. Sinon, un tas de mules retirerait de l'argent très rapidement.
Comment cela est-il transféré à la sécurité des informations de l'entreprise?
Basés sur les algorithmes anti-fraude et anti-blanchiment, des systèmes d'analyse comportementale apparaissent. Un profil utilisateur complet est collecté: à quelle vitesse il imprime, à quelles ressources il accède, avec qui il interagit, avec quel logiciel il lance - en général, tout ce que l'utilisateur fait tous les jours.
Un exemple. L'utilisateur interagit souvent avec 1C et y entre souvent des données, puis commence soudainement à décharger toute la base de données dans des dizaines de petits rapports. Son comportement va au-delà du comportement standard d'un tel utilisateur, mais il peut être comparé au comportement de profils similaires par type (très probablement, ce seront d'autres comptables) - il est clair qu'ils ont une semaine de rapports qui arrivent à certains moments et ils le font tous. Les chiffres sont les mêmes, il n'y a pas d'autres différences, l'alarme ne se lève pas.
Un autre exemple. Un utilisateur a travaillé avec une boule de fichiers toute sa vie, enregistrant quelques dizaines de documents par jour, puis soudainement il a commencé à en extraire des centaines et des milliers de fichiers. Et un autre DLP dit qu'il envoie quelque chose d'important. Peut-être que le département des appels d'offres a commencé les préparatifs du concours, peut-être que le «rat» divulgue des données aux concurrents. Le système, bien sûr, ne le sait pas, mais décrit simplement son comportement et alerte les agents de sécurité. Fondamentalement, le comportement d'un nouvel employé, du support technique ou du PDG, peut différer peu du comportement du «Cosaque mal géré», et la tâche du personnel de sécurité est de dire au système qu'il s'agit d'un comportement normal. Le profil suivra de toute façon, et si le compte du directeur général est compromis et que la réputation tombe sur des points, l'alarme se lèvera.
Les profils d'utilisateurs donnent lieu à des règles pour le système UBA. Plus précisément, des milliers d'heuristiques qui changent régulièrement. Chaque groupe d'utilisateurs a ses propres principes. Par exemple, les utilisateurs de ce type envoient 100 Mo par jour, les utilisateurs de l'autre envoient 1 Go par jour, si ce n'est pas un week-end. Et ainsi de suite. Si le premier envoie 5 Go, c'est suspect. Et si le second - alors il y aura des points négatifs, mais ils ne briseront pas le seuil d'alarme. Mais si à proximité, il a activé DNS sur de nouveaux domaines suspects, il y aura encore quelques points négatifs et l'alarme se déclenchera déjà.
L'approche est que ce n'est pas la règle "s'il y a eu des requêtes DNS étranges et que le trafic a bondi, alors ...", et la règle "si la réputation a atteint –20, alors ..." - chaque source individuelle de points pour la réputation de l'utilisateur ou du processus est indépendante et déterminée exclusivement la norme de son comportement. Automatiquement.
Dans le même temps, dans un premier temps, le service de la sécurité de l'information aide à former le système et à déterminer ce qui est la norme et ce qui ne l'est pas, puis le système s'adapte, se reconstitue sur le trafic réel et les journaux d'activité des utilisateurs.
Ce que nous mettons
En tant qu'intégrateur de systèmes, nous proposons à nos clients un service de gestion opérationnelle de la sécurité de l'information (service
SOC CROC géré). Un élément clé, associé à des systèmes comme Asset Management, Vulnerability Management, Security Testing et Threat Intelligence, disponible à partir de notre infrastructure cloud, est le lien entre SIEM classique et UBA proactif. En même temps, selon les souhaits du client, pour UBA, nous pouvons utiliser à la fois des solutions industrielles de grands fournisseurs et notre propre système analytique basé sur le bundle Hadoop + Hive + Redis + Splunk Analytics for Hadoop (Hunk).
Les solutions suivantes sont disponibles pour l'analyse comportementale à partir de notre cloud SOC CROC ou selon le modèle sur site:
- Exabeam: peut-être le système UBA le plus convivial qui vous permet d'enquêter rapidement sur un incident grâce à la technologie de suivi des utilisateurs, qui relie l'activité dans l'infrastructure informatique (par exemple, la connexion à la base de données locale sous le compte SA) avec un utilisateur réel. Comprend environ 400 modèles de notation des risques qui ajoutent des points de pénalité pour chaque action étrange ou suspecte;
- Securonix: un système d'analyse comportementale très gourmand en ressources mais extrêmement efficace. Le système est placé au-dessus de la plate-forme Big Data, près de 1000 modèles sont disponibles prêts à l'emploi. La plupart d'entre eux utilisent une technologie de clustering propriétaire pour l'activité des utilisateurs. Le moteur est très flexible, vous pouvez suivre et regrouper n'importe quel champ du format CEF, à partir de l'écart par rapport au nombre moyen de demandes par jour par les journaux du serveur Web et se terminant par l'identification de nouvelles interactions réseau pour le trafic des utilisateurs;
- Splunk UBA: Un bon ajout à Splunk ES. La base de règles hors de la boîte est petite, mais en référence à la chaîne de destruction, qui vous permet de ne pas être distrait par des incidents mineurs et de vous concentrer sur un vrai pirate. Et bien sûr, nous avons à notre disposition toute la puissance du traitement statistique des données sur Splunk Machine Learning Toolkit et une analyse rétrospective de tout le volume de données accumulées.
Et pour les segments critiques, qu'il s'agisse d'un système de contrôle de processus automatisé ou d'une application commerciale clé, nous plaçons des capteurs supplémentaires pour collecter des analyses avancées et des hanitopes afin de détourner l'attention du pirate des systèmes productifs.
Pourquoi une mer de ressources?
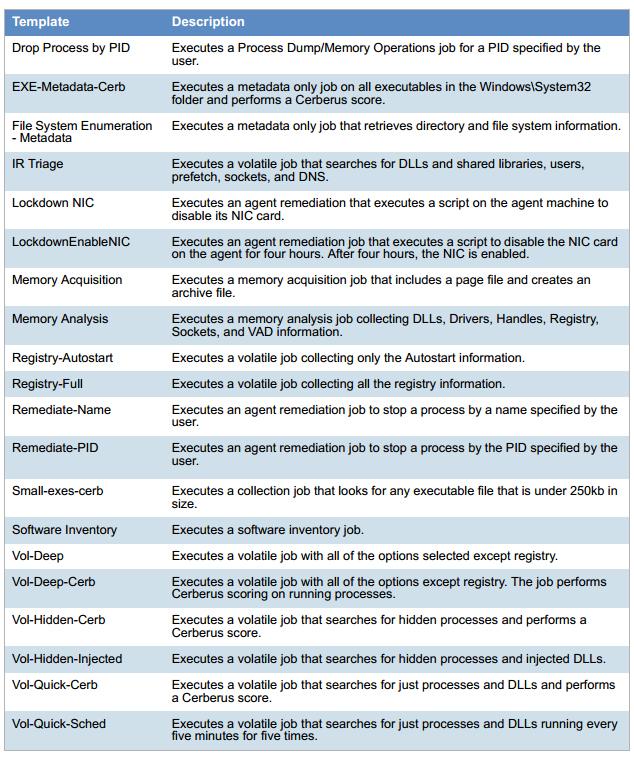
Parce que tous les événements sont écrits. C'est comme Google Analytics, uniquement sur le poste de travail local. Sur le réseau local, les événements sont envoyés à Data Lake tout au long des métadonnées Internet sur les statistiques et les événements clés, mais si l'opérateur SOC souhaite enquêter sur l'incident, il existe également un journal complet enregistré. Tout est collecté: fichiers temporaires, clés de registre, tous les processus en cours d'exécution et leurs sommes de contrôle, qui sont écrites au démarrage, actions, screencast - peu importe. Vous trouverez ci-dessous un exemple des données collectées.
Liste des paramètres du poste de travail:


Les systèmes en termes de stockage et de RAM deviennent beaucoup plus compliqués. Le SIEM classique commence avec 64 Go de RAM, quelques processeurs et un demi-téraoctet de stockage. UBA provient d'un téraoctet de RAM et plus. Par exemple, notre dernière implémentation était sur 33 serveurs physiques (28 nœuds de calcul pour le traitement des données + 5 nœuds de contrôle pour l'équilibrage de charge), 150 To de lacs (600 To de matériel, y compris le cache rapide sur les instances) et 384 Go de RAM chacun.
Qui en a besoin?
Tout d'abord, ceux qui se trouvent dans la «zone à risque» et qui sont constamment attaqués sont les banques, les institutions financières, le secteur pétrolier et gazier, la grande distribution et bien d'autres.
Pour ces entreprises, le coût de la fuite ou de la perte de données peut atteindre des dizaines voire des centaines de millions de dollars. Mais l'installation d'un système UBA coûtera beaucoup moins cher. Et bien sûr, les entreprises publiques et les télécommunications, car personne ne veut à un moment donné que les données de millions de patients ou la correspondance de dizaines de millions de personnes soient diffusées en libre accès.
Les références