
Aujourd'hui, le développement de logiciels de haute qualité est difficile à imaginer sans utiliser
des méthodes d'analyse de code statique . L'analyse statique du code du programme peut être intégrée dans l'environnement de développement (par des méthodes standard ou à l'aide de plug-ins), elle peut être effectuée par un logiciel spécialisé avant que le code ne soit mis en service commercial, ou «manuellement» par un expert régulier ou externe.
On fait souvent valoir que
l'analyse de code dynamique ou
les tests de pénétration peuvent remplacer l'analyse statique, car ces méthodes de vérification révéleront de vrais problèmes et il n'y aura pas de faux positifs. Cependant, il s'agit d'un point discutable, car l'analyse dynamique, contrairement à l'analyse statique, ne vérifie pas tout le code, mais vérifie uniquement la résistance du logiciel à un ensemble d'attaques qui imitent les actions d'un attaquant. Un attaquant peut être plus inventif que le vérificateur, peu importe qui effectue la vérification: une personne ou une machine.
L'analyse dynamique ne sera complète que si elle est effectuée sur une couverture de test complète, ce qui, lorsqu'il est appliqué à des applications réelles, est une tâche difficile. La preuve de l'exhaustivité de la couverture du test est un problème algorithmiquement insoluble.
L'analyse statique obligatoire du code du programme est l'une des étapes nécessaires lors de la mise en service d'un logiciel avec des exigences accrues pour la sécurité de l'information.
À l'heure actuelle, il existe de nombreux analyseurs de code statique différents sur le marché, et de plus en plus de nouveaux apparaissent constamment. Dans la pratique, il existe des cas où plusieurs analyseurs statiques sont utilisés ensemble pour améliorer la qualité de la vérification, car différents analyseurs recherchent des défauts différents.
Pourquoi n'y a-t-il pas d'analyseur statique universel qui vérifierait complètement n'importe quel code et y trouverait tous les défauts sans faux positifs et en même temps travailler rapidement et ne nécessitant pas beaucoup de ressources (temps CPU et mémoire)?
Un peu sur l'architecture des analyseurs statiques
La réponse à cette question réside dans l'architecture des analyseurs statiques. Presque tous les analyseurs statiques sont en quelque sorte construits sur le principe des compilateurs, c'est-à-dire que dans leur travail, il y a des étapes de conversion de code source - les mêmes que celles effectuées par le compilateur.
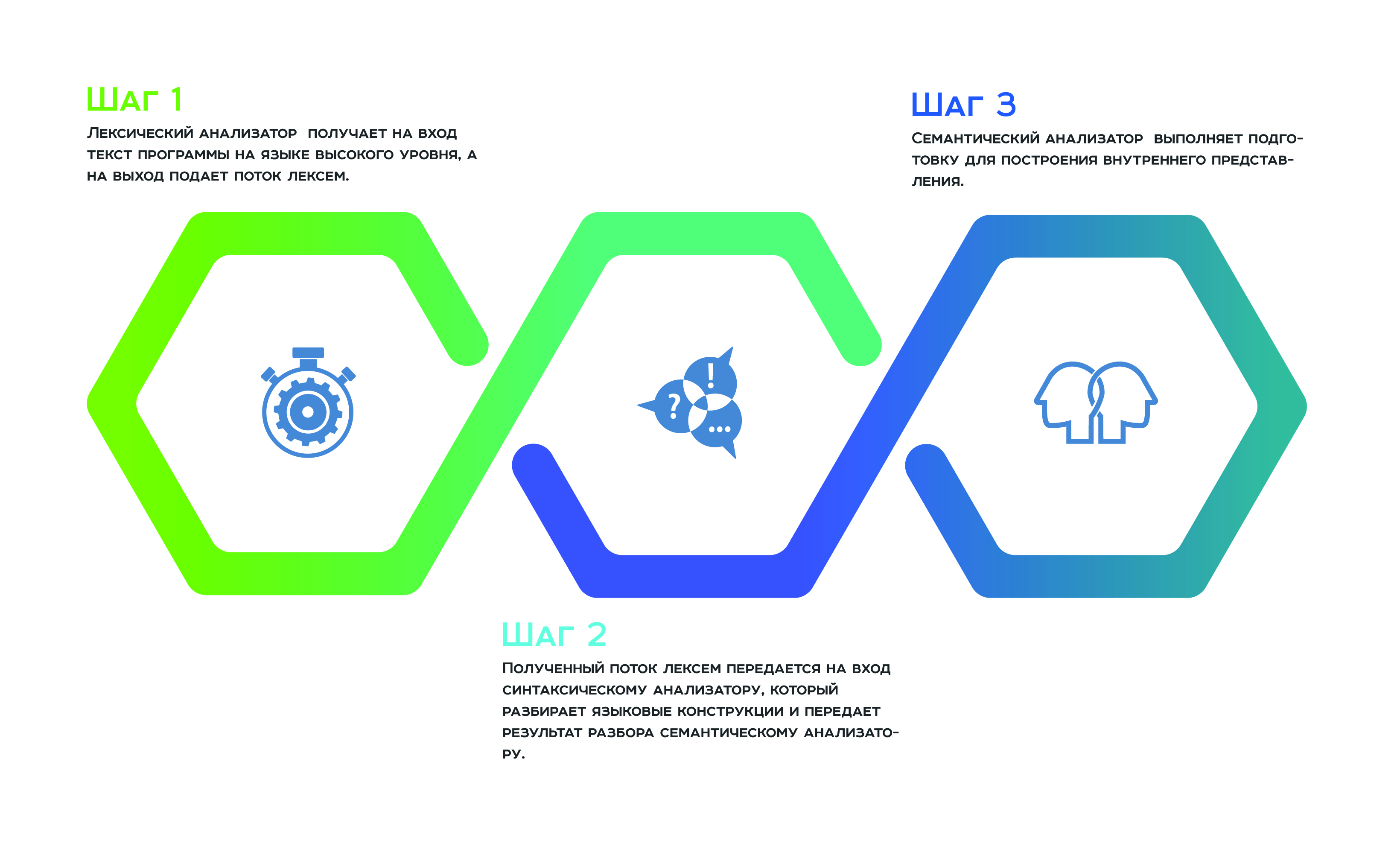
Tout commence par une
analyse lexicale , qui reçoit le texte du programme dans une langue de haut niveau en entrée, et un flux de jetons vers la sortie. Ensuite, le flux de jetons reçu est transmis à l'entrée
de l'analyseur , qui analyse les constructions de langage et transmet le résultat de l'analyse à l'
analyseur sémantique , qui, à la suite de son travail, se prépare à construire la représentation interne. Cette représentation interne est une caractéristique de chaque analyseur statique. L'efficacité de l'analyseur dépend de son succès.
De nombreux fabricants d'analyseurs statiques prétendent utiliser une représentation interne universelle pour tous les langages de programmation pris en charge par l'analyseur. Ainsi, ils peuvent analyser le code du programme développé dans plusieurs langues dans son ensemble, et non en tant que composants séparés. Une «approche holistique» de l'analyse permet d'éviter l'omission des défauts qui surviennent à l'interface entre les composants individuels d'un produit logiciel.
En théorie, cela est vrai, mais dans la pratique, une représentation interne universelle pour tous les langages de programmation est difficile et inefficace. Chaque langage de programmation est spécial. Une vue interne est généralement un arbre dont les sommets stockent des attributs. En parcourant un tel arbre, l'analyseur collecte et convertit les informations. Par conséquent, chaque sommet de l'arbre doit contenir un ensemble uniforme d'attributs. Étant donné que chaque langue est unique, l'uniformité des attributs ne peut être prise en charge que par la redondance des composants. Les langages de programmation les plus hétérogènes, les composants les plus hétérogènes dans les caractéristiques de chaque sommet, et donc la représentation interne est inefficace de la mémoire. Un grand nombre de caractéristiques hétérogènes affecte également la complexité des marcheurs d'arbres, ce qui signifie qu'elle conduit à des inefficacités dans les performances.
Conversions d'optimisation pour les analyseurs statiques
Pour que l'analyseur statique fonctionne efficacement en mémoire et en temps, vous devez disposer d'une représentation interne universelle compacte, ce qui peut être obtenu par le fait que la représentation interne est divisée en plusieurs arborescences, chacune étant conçue pour les langages de programmation associés.
Le travail d'optimisation ne se limite pas à diviser la représentation interne en langages de programmation associés. De plus, les fabricants utilisent diverses transformations d'optimisation - les mêmes que dans les technologies de compilation, en particulier,
les transformations d'optimisation des cycles . Le fait est que le but de l'analyse statique est idéalement de réaliser la promotion des données dans le programme afin d'évaluer leur transformation pendant l'exécution du programme. Par conséquent, les données doivent être «avancées» à chaque tour du cycle. Donc, si vous économisez sur ces virages et les rendez beaucoup plus petits, nous obtiendrons des avantages significatifs à la fois en mémoire et en performances. C'est à cette fin que de telles transformations sont activement utilisées qui, avec une certaine probabilité, effectuent une extrapolation de la transformation des données à tous les tours du cycle avec le nombre minimum de passes.
Vous pouvez également économiser sur les branches en calculant la probabilité que le programme passe sur l'une ou l'autre branche. Si la probabilité de passage le long d'une branche est inférieure à celle-ci, alors cette branche de programme n'est pas prise en compte.
Évidemment, chacune de ces transformations "perd" les défauts que l'analyseur doit détecter, mais c'est un "prix" pour l'efficacité et les performances de la mémoire.
Que recherche un analyseur de code statique?
Conditionnellement, les défauts qui intéressent en quelque sorte les intrus, et donc les auditeurs, peuvent être répartis dans les groupes suivants:
- erreurs de validation
- erreurs de fuite d'informations,
- erreurs d'authentification.
Des erreurs de validation se produisent en raison du fait que les données d'entrée ne sont pas correctement vérifiées pour leur exactitude. Un attaquant peut glisser en entrée ce qui n'est pas ce à quoi le programme s'attend, et ainsi obtenir un accès non autorisé au contrôle. Les erreurs de validation des données les plus courantes sont les injections et
XSS . Au lieu de données valides, l'attaquant soumet à l'entrée du programme des données spécialement préparées qui portent un petit programme. Ce programme, en cours de traitement, est exécuté. Le résultat de sa mise en œuvre peut être le transfert de contrôle vers un autre programme, la corruption de données et bien plus encore. De plus, à la suite d'erreurs de validation, le site avec lequel l'utilisateur travaille peut être remplacé. Les erreurs de validation peuvent être détectées qualitativement par des méthodes d'analyse de code statique.
Les erreurs de
fuite d'informations sont des erreurs liées au fait que des informations sensibles de l'utilisateur résultant du traitement ont été interceptées et transmises à l'attaquant. Cela peut être vice versa: les informations sensibles stockées dans le système sont interceptées et transmises à l'attaquant lors de leur déplacement vers l'utilisateur.
Ces vulnérabilités sont tout aussi difficiles à détecter que les erreurs de validation. La détection de ce type d'erreur nécessite de suivre dans les statistiques la progression et la conversion des données à travers le code du programme. Cela nécessite la mise en œuvre de méthodes telles que l'
analyse des souillures et l'
analyse des données interprocédurales . La précision de l'analyse dépend en grande partie de la façon dont ces méthodes sont développées, à savoir la minimisation des faux positifs et des erreurs manquées.
La bibliothèque de règles de détection des défauts, en particulier le format de description de ces règles, joue également un rôle important dans la précision de l'analyseur statique. Tout cela est un avantage concurrentiel de chaque analyseur et est soigneusement protégé des concurrents.
Les erreurs d'authentification sont les
erreurs les plus intéressantes pour un attaquant, car elles sont difficiles à détecter car elles surviennent à la jonction des composants et sont difficiles à formaliser. Les attaquants exploitent ce type d'erreur pour augmenter les droits d'accès. Les erreurs d'authentification ne sont pas détectées automatiquement, car il n'est pas clair ce qu'il faut rechercher - ce sont des erreurs dans la logique de construction du programme.
Erreurs de mémoire
Ils sont difficiles à détecter car une identification précise nécessite la résolution d'un système d'équations encombrant, coûteux en mémoire et en performances. Par conséquent, le système d'équations est réduit, ce qui signifie que la précision est perdue.
Les erreurs de mémoire typiques incluent l'
utilisation après la libération , la
double libération , le
déréférencement de pointeur nul et leurs variétés, par exemple,
hors limites-lecture et
hors limites-écriture .
Lorsque l'analyseur suivant n'a pas détecté de fuite de mémoire, vous pouvez entendre que ces défauts sont difficiles à exploiter. Un attaquant doit être hautement qualifié et faire preuve de beaucoup d'habileté pour, d'une part, découvrir la présence d'un tel défaut dans le code, et, d'autre part, faire un exploit. Eh bien, l'argument se poursuit: "Êtes-vous sûr que votre produit logiciel est intéressant pour un gourou d'un tel niveau?" ... Cependant, l'histoire connaît des cas où des erreurs de mémoire ont été exploitées avec succès et ont causé des dommages considérables. À titre d'exemples, vous pouvez citer des situations bien connues telles que:
- CVE-2014-0160 - une erreur dans la bibliothèque openssl - un compromis potentiel des clés privées nécessitait une réémission de tous les certificats et la régénération du mot de passe.
- CVE-2015-2712 - bug dans l'implémentation js dans mozilla firefox - vérification des limites.
- CVE-2010-1117 - à utiliser après gratuit dans Internet Explorer - exploitable à distance.
- CVE-2018-4913 - utiliser après gratuit dans Acrobat Reader - exécution de code.
De plus, les attaquants aiment exploiter les défauts associés à une mauvaise synchronisation des threads ou des processus. De tels défauts sont difficiles à identifier en statique, car simuler l'état d'une machine sans la notion de «temps» n'est pas une tâche facile. Cela fait référence à des erreurs telles que la
condition de concurrence . Et aujourd'hui, la concurrence est utilisée partout, même dans de très petites applications.
Pour résumer ce qui précède, il convient de noter qu'un analyseur statique est utile dans le processus de développement, s'il est utilisé correctement. Pendant le fonctionnement, il est nécessaire de comprendre ce qu'il faut en attendre et ce qu'il faut faire avec ces défauts que l'analyseur statique ne peut pas identifier en principe. S'ils disent qu'un analyseur statique n'est pas nécessaire pendant le processus de développement, cela signifie qu'ils ne savent tout simplement pas comment le faire fonctionner.
Comment utiliser correctement l'analyseur statique, pour travailler correctement et efficacement avec les informations qu'il fournit, lisez notre blog.