Les tests d'intégration restent une partie importante du cycle de production de CI / CD, y compris le développement d'applications conteneurisées. Les tests d'intégration, en règle générale, ne sont pas des charges de travail très longues, mais très gourmandes en ressources. Voyons comment vous pouvez combiner des technologies et des outils de test d'intégration avec des outils d'orchestration de conteneurs (en particulier, avec
Red Hat OpenShift ) pour accélérer les tests, augmenter son dynamisme et utiliser les ressources plus efficacement.
Créons des tests BDD d'intégration (
développement axé sur le comportement ) à l'aide de
Cucumber ,
Protractor et
Selenium et exécutons-les sur la plate-forme OpenShift à l'aide de Zalenium.
Test BDD
Lors du développement de tests d'intégration, BDD permet aux analystes commerciaux (BA) de créer des définitions de tests d'intégration, et pas seulement aux programmeurs. Grâce à BDD, le processus de développement peut être organisé de manière à ce que les exigences fonctionnelles et les définitions des tests d'intégration soient préparées en même temps et en même temps qu'elles soient créées par des analystes commerciaux.
C'est beaucoup mieux que les approches traditionnelles, lorsque vous déterminez d'abord la fonctionnalité métier de l'application, puis que le service QA crée des tests d'intégration, comme indiqué dans le diagramme ci-dessous:
Et voici à quoi cela ressemble lorsque vous utilisez BDD:
De plus, dans ce nouveau schéma, chaque itération prend généralement moins de temps.
Les analystes commerciaux peuvent créer des définitions pour les tests d'intégration car BDD décrit ces tests dans un langage
Gherkin simple et compréhensible dont les principaux mots clés sont donnés, quand et puis. Chaque énoncé en langue cornichon doit commencer par l'un de ces mots.
Par exemple:Étant donné que l'utilisateur a accédé à la page de connexion (à condition que l'utilisateur ait accédé à la page de connexion)
Lorsque l'utilisateur saisit son nom d'utilisateur et son mot de passe
Lorsque le nom d'utilisateur et le mot de passe sont corrects
Ensuite, le système les connecte (puis le système lui permet de se connecter)Un runtime populaire qui peut interpréter les tests de Gherkin est
Cucumber . Pour utiliser Cucumber, un développeur doit implémenter certaines fonctions afin que toutes les directives Gherkin puissent être exécutées. Cucumber a des liaisons avec de nombreux langages de programmation. Il est recommandé (mais pas obligatoire) de rédiger les tests dans la même langue que l'application testée.
Pile de technologies de test
Jetons
un coup d'œil à la procédure de test en utilisant l'application Web
TodoMVC comme
exemple dans la
mise en
œuvre d'AngularJS . AngularJS est un framework populaire pour créer des applications monopages (SPA).
Comme AngularJS est JavaScript, nous utiliserons
Cumcumber.js , Cucumber se liant à JavaScript.
Pour émuler le travail de l'utilisateur dans un navigateur, nous utiliserons
Selenium . Selenium est un processus qui peut lancer un navigateur et lire les actions des utilisateurs sur les commandes reçues via l'API.
Enfin, nous utiliserons
Protractor pour prendre en compte les nuances des émulations d'applications SPA écrites en AngularJS. Protractor prendra en charge l'attente que les vues dans la page se chargent correctement.
Ainsi, notre pile de tests est la suivante:
Le processus présenté dans ce diagramme est décrit comme suit:
- Lorsque le test Cucumber s'exécute, Cucumber lit la définition du test dans le fichier Gherkin.
- Ensuite, il commence à appeler le code d'implémentation du code de test.
- Le code de mise en œuvre du script de test utilise un rapporteur pour effectuer des actions sur une page Web
- Lorsque cela se produit, Protractor se connecte au serveur Protractor et envoie des commandes à Selenium via l'API.
- Selenium exécute ces commandes dans une instance de navigateur.
- Si nécessaire, le navigateur se connecte au (x) serveur (s) Web. Dans notre exemple, l'application SPA est utilisée, par conséquent, une telle connexion ne se produit pas, car l'application a déjà été chargée lors du chargement à partir du serveur de la première page.
Déployer une telle pile dans une infrastructure non conteneurisée n'est pas facile. Et pas seulement à cause du grand nombre de processus et de frameworks utilisés, mais aussi parce que lancer un navigateur sur un serveur sans moniteur a toujours été difficile. Heureusement, dans un monde conteneurisé, tout cela peut être automatisé.
Ferme de tests d'intégration
Les applications Web d'entreprise doivent être testées pour diverses combinaisons du système d'exploitation client et du navigateur. Habituellement, cela se limite à un certain ensemble d'options de base qui reflète la situation sur les machines des utilisateurs finaux de l'application. Mais même dans ce cas, le nombre de configurations de test pour chaque application tombe rarement en dessous d'une demi-douzaine.
Si vous déployez systématiquement une pile pour chaque configuration de test et exécutez les tests correspondants sur celle-ci, cela est trop coûteux en termes de temps et de ressources.
Idéalement, je voudrais exécuter des tests en parallèle.
Selenium-Grid peut nous y aider - une solution qui inclut le courtier de demandes Selenium Hub et un ou plusieurs nœuds sur lesquels ces demandes sont exécutées.
Chaque nœud Selenium qui s'exécute généralement sur un serveur distinct peut être configuré pour une combinaison spécifique de système d'exploitation client et de navigateur (dans Selenium, ces caractéristiques et d'autres du nœud sont appelées capacités). Dans le même temps, le concentrateur Selenium est suffisamment intelligent pour envoyer des demandes qui nécessitent certaines propriétés Selenium aux nœuds qui ont ces propriétés.
Les clusters Selenium-Grid sont assez difficiles à installer et à gérer, à tel point que des entreprises proposant des services associés sont même apparues sur le marché. En particulier, SauceLabs et BrowserStack sont parmi les principaux acteurs.
Tests d'intégration basés sur des conteneurs
Très souvent, j'aimerais pouvoir créer un cluster de sélénium-grille qui fournirait les propriétés de sélénium nécessaires à nos tests et exécuter les tests eux-mêmes avec un haut degré de parallélisation. Ensuite, une fois les tests terminés, j'aimerais pouvoir détruire complètement ce cluster. En d'autres termes, apprendre à travailler de la même manière que les fournisseurs de batteries de tests d'intégration fonctionnent.
Ce domaine de la technologie est encore à un stade précoce de formation, cependant, un projet open source prometteur -
Zalenium - offre une partie de ce dont nous avons besoin.
Zalenium utilise un Hub modifié qui peut créer des nœuds à la demande et les détruire lorsqu'ils ne sont plus nécessaires. Zalenium ne prend actuellement en charge que les navigateurs Chrome et Firefox sur la plate-forme Linux. Mais avec l'avènement des nœuds Windows pour Kubernetes, la prise en charge d'Explorer et Edge sous Windows peut apparaître.
Si vous assemblez tout, la pile technologique est la suivante:
Chaque ovale du diagramme est une cosse distincte dans Kubernetes. Les pods du lecteur test et des émulateurs sont éphémères et détruits à la fin du test.
Exécution de tests d'intégration dans le pipeline CI / CD
Créons un pipeline simple dans Jenkins pour montrer comment intégrer ce type de test d'intégration dans le reste du processus de gestion des versions. Cela ressemble à ceci:
Votre pipeline peut varier, mais vous avez toujours la possibilité de réutiliser la phase de test d'intégration sans refactorisation significative du code.
Étant donné que la plupart des foyers sont éphémères, l'une des tâches du pipeline est de collecter les résultats des tests. Dans Jenkins, cela peut être fait en utilisant les primitives archive et publishHTML.
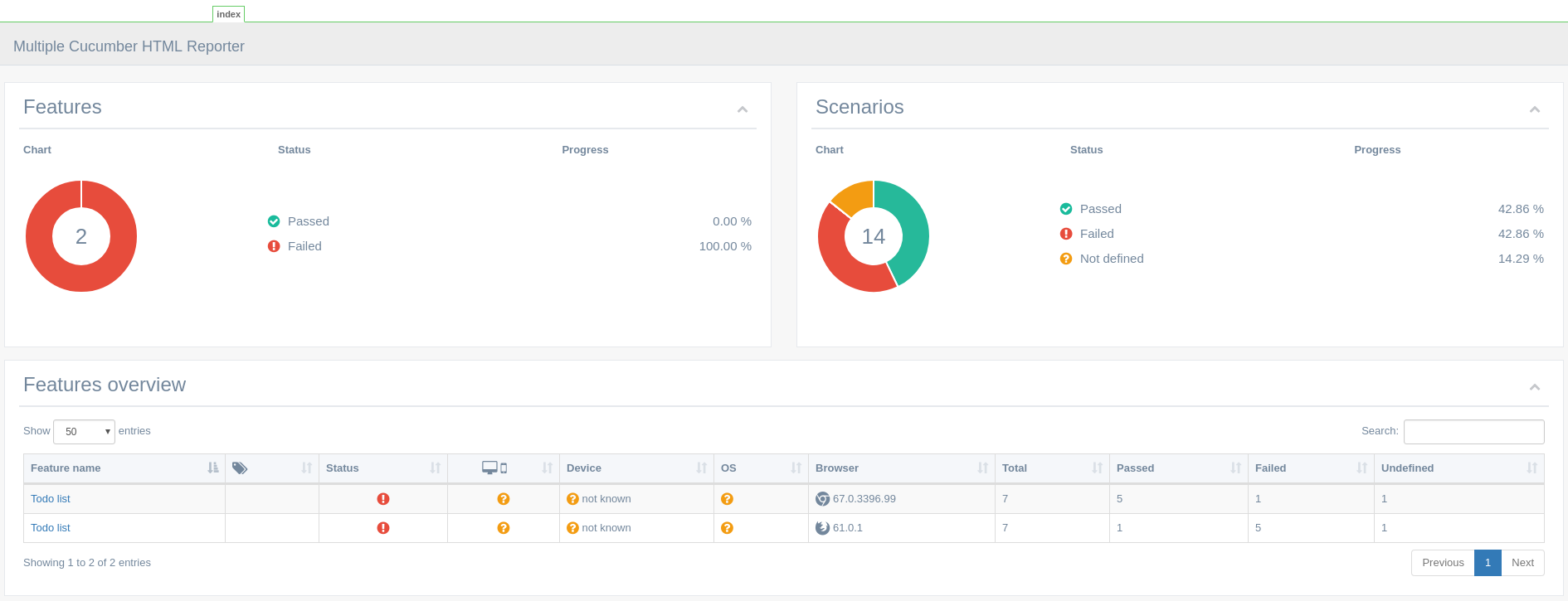
Et voici un exemple de rapport sur les résultats des tests (notez que les tests ont été exécutés sur deux navigateurs):
Conclusion
Ainsi, malgré la complexité de l'organisation d'une infrastructure de test d'intégration de bout en bout, l'approche «infrastructure en tant que code» simplifie le processus. La réalisation de tests d'intégration sur diverses combinaisons de systèmes d'exploitation et de navigateurs prend beaucoup de temps et de ressources, mais les outils d'orchestration de conteneurs et les charges de travail éphémères aident à faire face à ce problème.
Même en l'absence d'outils matures pour organiser des tests d'intégration orientés conteneurs, des tests d'intégration basés sur des plates-formes de conteneurs peuvent déjà être effectués aujourd'hui et tirer parti de l'approche conteneur.
Si vous développez des applications conteneurisées, essayez d'utiliser cette approche dans le pipeline CI / CD et voyez si cela permet de simplifier les tests d'intégration.
Un exemple de code de cet article peut être trouvé sur le site Web de GitHub à redhat-cop / container-pipelinesh.