
Nous avons commencé à mettre à jour la surveillance de PgBouncer dans notre service et avons décidé de tout peigner un peu. Pour que tout soit en forme, nous avons utilisé les méthodologies de surveillance des performances les plus célèbres: USE (Utilisation, Saturation, Erreurs) de Brendan Gregg et RED (Requêtes, Erreurs, Durées) de Tom Wilkie.
Sous la cinématique se trouve une histoire avec des graphiques sur le fonctionnement de pgbouncer, la configuration qui le gère et comment utiliser USE / RED pour choisir les bonnes mesures pour le surveiller.
Tout d'abord sur les méthodes elles-mêmes
Bien que ces méthodes soient assez connues (à propos d’ elles, c’était déjà sur Habré, bien qu’elles ne soient pas très détaillées ), ce n’est pas qu’elles soient répandues dans la pratique.
UTILISATION
Pour chaque ressource, gardez une trace de l'élimination, de la saturation et des erreurs.
Brendan gregg
Ici, une ressource est un composant physique distinct - un processeur, un disque, un bus, etc. Mais pas seulement - les performances de certaines ressources logicielles peuvent également être prises en compte par cette méthode, en particulier les ressources virtuelles, telles que les conteneurs / groupes de contrôle avec des limites, il est également pratique de le considérer.
U - Élimination : soit un pourcentage du temps (à partir de l'intervalle d'observation) lorsque la ressource était occupée à un travail utile. Comme, par exemple, le chargement du processeur ou de l'utilisation du disque à 90% signifie que 90% du temps a été pris par quelque chose d'utile) ou, pour des ressources telles que la mémoire, c'est le pourcentage de mémoire utilisé.
Dans tous les cas, un recyclage à 100% signifie que la ressource ne peut pas être utilisée plus que maintenant. Et soit le travail restera bloqué en attendant sa sortie / aller dans la file d'attente, soit il y aura des erreurs. Ces deux scénarios sont couverts par les deux métriques USE restantes correspondantes:
S - Saturation , c'est aussi la saturation: une mesure de la quantité de travail «différé» / en file d'attente.
E - Erreurs : nous comptons simplement le nombre d'échecs. Les erreurs / pannes affectent les performances, mais peuvent ne pas être immédiatement visibles en raison de la récupération des opérations inversées ou des mécanismes de tolérance aux pannes avec des périphériques de sauvegarde, etc.
Rouge
Tom Wilkie (qui travaille maintenant à Grafana Labs) a été frustré par la méthodologie USE, ou plutôt, par sa faible applicabilité dans certains cas et son incohérence avec la pratique. Comment, par exemple, mesurer la saturation de la mémoire? Ou comment mesurer les erreurs de bus système dans la pratique?
Il s'avère que Linux rapporte vraiment le nombre de bogues.
T. Wilkie
Bref, pour suivre les performances et le comportement des microservices, il propose une autre méthode adaptée: mesurer, là encore, trois indicateurs:
R - Rate : Le nombre de requêtes par seconde.
E - Erreurs : combien de demandes ont renvoyé une erreur.
D - Durée : temps nécessaire au traitement de la demande. C'est la latence, la "latence" (© Sveta Smirnova :), le temps de réponse, etc.
En général, USE est plus approprié pour surveiller les ressources, et RED pour les services et leur charge de travail / charge utile.
Pgbouncer
Être un service, il a en même temps toutes sortes de limites et de ressources internes. On peut en dire autant de Postgres, auquel les clients accèdent via ce PgBouncer. Par conséquent, pour une surveillance complète dans cette situation, les deux méthodes sont nécessaires.
Pour comprendre comment appliquer ces méthodes à un videur, vous devez comprendre les détails de son appareil. Il ne suffit pas de le surveiller comme une boîte noire - "le processus pgbouncer est-il vivant" ou "le port est-il ouvert", car en cas de problème, cela ne permettra pas de comprendre exactement quoi et comment il s'est cassé et quoi faire.
À quoi ressemble généralement PgBouncer du point de vue du client:
- le client se connecte
- [le client fait une demande - reçoit une réponse] x combien de fois il a besoin
Ici, j'ai dessiné un diagramme des états clients correspondants du point de vue de PgBoucer:

Dans le processus de connexion, l'autorisation peut se produire à la fois localement (fichiers, certificats, et même PAM et hba à partir de nouvelles versions), et à distance - c'est-à-dire dans la base de données à laquelle la connexion est tentée. Ainsi, l'état de connexion a un sous-état supplémentaire. Appelons-le Executing pour indiquer que auth_query est en auth_query dans la base de données à ce moment:
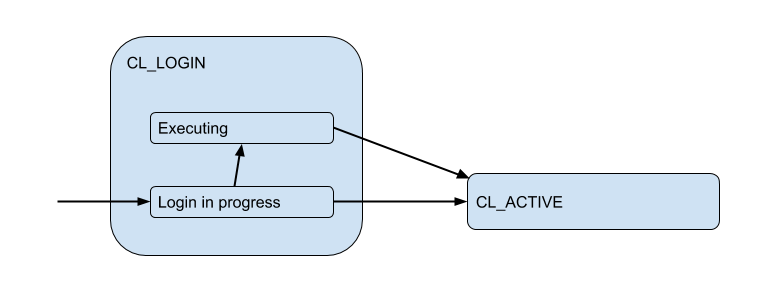
Mais ces connexions client correspondent en fait aux connexions backend / amont que PgBouncer ouvre dans le pool et en détient un nombre limité. Et ils donnent une telle connexion au client uniquement pour le temps - pour la durée de la session, de la transaction ou de la demande, selon le type de regroupement (déterminé par le paramètre pool_mode ). Le plus souvent, le regroupement de transactions est utilisé (nous en discuterons principalement plus tard) - lorsque la connexion est établie avec le client pour une transaction, et le reste du temps, le client n'est pas connecté au serveur en fait. Ainsi, l'état "actif" du client nous en dit peu, et nous le diviserons en substrats:
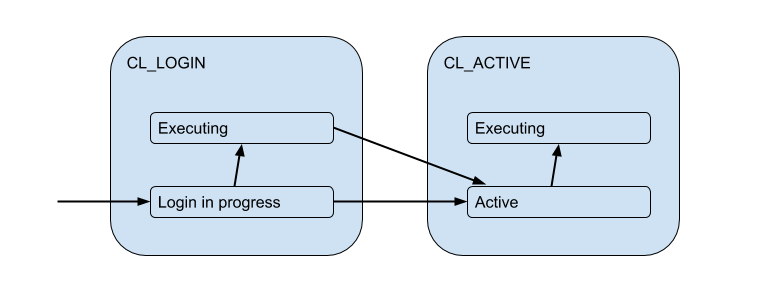
Chacun de ces clients appartient à son propre pool de connexions, qui sera émis pour être utilisé par la connexion réelle à Postgres. C'est la tâche principale de PgBouncer - limiter le nombre de connexions à Postgres.
En raison des connexions de serveur limitées, une situation peut se produire lorsque le client doit répondre directement à la demande, mais il n'y a pas de connexion gratuite maintenant. Le client est ensuite mis en file d'attente et sa connexion passe à l'état CL_WAITING . Ainsi, le diagramme d'état doit être complété:
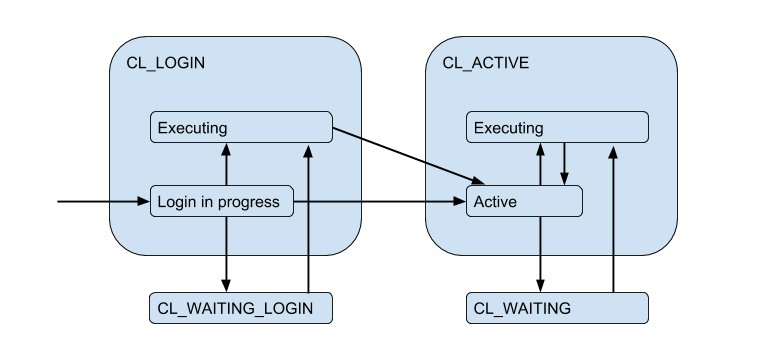
Étant donné que cela peut se produire dans le cas où le client se connecte uniquement et qu'il doit exécuter une demande d'autorisation, l'état CL_WAITING_LOGIN également.
Si nous regardons maintenant de l'arrière - du côté des connexions au serveur, alors, en conséquence, ils sont dans de tels états: lorsque l'autorisation se produit immédiatement après la connexion - SV_LOGIN , émis et (éventuellement) utilisé par le client - SV_ACTIVE , ou librement - SV_IDLE .
UTILISATION pour PgBouncer
Nous arrivons ainsi à la (version naïve) Utilisation d'un pool spécifique:
Pool utiliz = /
PgBouncer possède une base de données d'utilitaires pgbouncer spéciale dans laquelle se trouve une SHOW POOLS qui affiche l'état actuel des connexions de chaque pool:

Il existe 4 connexions client ouvertes et toutes sont cl_active . Sur 5 connexions serveur - 4 sv_active et une dans le nouvel état sv_used .
Qu'est-ce que sv_used vraiment sur les différents paramètres de pgbouncer sans rapport avec la surveillanceDonc, sv_used ne signifie pas «la connexion est utilisée», comme vous pourriez le penser, mais «la connexion a déjà été utilisée et n'a pas été utilisée depuis longtemps». Le fait est que PgBouncer utilise les connexions serveur en mode LIFO par défaut - c'est-à-dire Tout d'abord, les connexions nouvellement publiées sont utilisées, puis celles récemment utilisées, etc. se déplaçant progressivement vers des composés utilisés depuis longtemps. Par conséquent, les connexions au serveur depuis le bas d'une telle pile peuvent «mal tourner». Et ils devraient être vérifiés pour la vivacité avant utilisation, ce qui est fait en utilisant server_check_query , tandis qu'ils sont vérifiés, l'état sera sv_tested .
La documentation indique que LIFO est activé par défaut, comme alors "un petit nombre de connexions obtient la charge de travail la plus importante. Et cela donne les meilleures performances quand il y a un serveur servant la base de données derrière pgbouncer", c'est-à-dire comme dans le cas le plus typique. Je crois que l'augmentation potentielle des performances est due aux économies de commutation des performances entre plusieurs processus backend. Mais cela n'a pas fonctionné de manière fiable, car Ce détail d'implémentation existe depuis> 12 ans et va au-delà de l'historique des validations sur github et de la profondeur de mon intérêt =)
Ainsi, il semblait étrange et server_check_delay avec les réalités actuelles que la valeur par défaut du paramètre server_check_delay , qui détermine que le serveur n'a pas été utilisé depuis trop longtemps et doit être vérifié avant de le donner au client, est de 30 secondes. Ceci malgré le fait que par défaut tcp_keepalive est activé simultanément avec les paramètres par défaut - commencez à vérifier la connexion keep alive avec des échantillons 2 heures après son inactivité.
Il s'avère que dans une situation de rafale / surtension de connexions clientes qui veulent faire quelque chose sur le serveur, un délai supplémentaire est introduit sur server_check_query , qui, bien que " SELECT 1; peut encore prendre ~ 100 microsecondes, et si server_check_query = ';' alors vous pouvez économiser ~ 30 microsecondes =)
Mais l'hypothèse selon laquelle travailler sur quelques connexions = sur plusieurs processus postgres principaux "principaux" sera plus efficace, cela me semble douteux. Le processus de travail postgres met en cache (méta) des informations sur chaque table qui a été consultée dans cette connexion. Si vous avez un grand nombre de tables, alors ce relcache peut augmenter considérablement et prendre beaucoup de mémoire, jusqu'à l'échange des pages du processus 0_o. Pour contourner ce server_lifetime , utilisez le paramètre server_lifetime (la valeur par défaut est 1 heure), par lequel la connexion au serveur sera fermée pour rotation. Mais d'un autre côté, il existe un paramètre server_round_robin qui fera basculer le mode d'utilisation des connexions de LIFO à FIFO, répartissant les demandes des clients sur les connexions de serveur de manière plus uniforme.
SHOW POOLS prenant SHOW POOLS métriques de SHOW POOLS (par un exportateur de prometheus), nous pouvons tracer ces états:
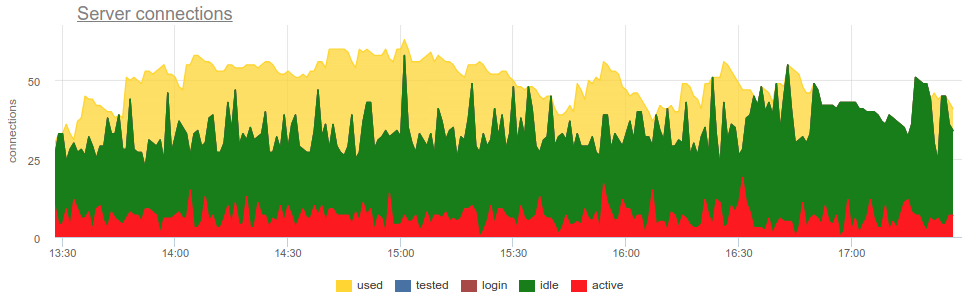
Mais pour vous mettre à disposition, vous devez répondre à quelques questions:
- Quelle est la taille de la piscine?
- Comment compter le nombre de composés utilisés? En blagues ou dans le temps, en moyenne ou en pointe?
Taille de la piscine
Tout est compliqué ici, comme dans la vie. Au total, il y a déjà cinq limites de paramètres dans le pbbouncer!
pool_size peut être défini pour chaque base de données. Un pool séparé est créé pour chaque paire DB / utilisateur, c'est-à-dire à partir de n'importe quel utilisateur supplémentaire , vous pouvez créer un autre backend pool_size / Postgres. Parce que si pool_size pas défini, il tombe dans default_pool_size , qui vaut 20 par défaut, puis il s'avère que chaque utilisateur qui a le droit de se connecter à la base de données (et qui travaille via pgbouncer) peut potentiellement créer 20 processus Postgres, ce qui semble être peu. Mais si vous avez de nombreux utilisateurs différents des bases de données ou des bases de données elles-mêmes, et que les pools ne sont pas enregistrés auprès d'un utilisateur fixe, c'est-à-dire sera créé à la volée (puis supprimé par autodb_idle_timeout ), cela peut être dangereux =)
Il peut être utile de laisser default_pool_size petit, juste pour chaque pompier.
max_db_connections - juste nécessaire pour limiter le nombre total de connexions à une base de données, car sinon, les clients qui se comportent mal peuvent créer de nombreux processus d'arrière-plan / postgres. Et par défaut ici - illimité ¯_ (ツ) _ / ¯
Vous devriez peut-être changer les max_db_connections par défaut, par exemple, vous pouvez vous concentrer sur les max_connections vos Postgres (par défaut 100). Mais si vous avez beaucoup de PgBouncers ...
reserve_pool_size - en fait, si pool_size tout utilisé, alors PgBouncer peut ouvrir plusieurs connexions supplémentaires à la base. Si je comprends bien, cela est fait pour faire face à une augmentation de la charge. Nous y reviendrons.max_user_connections - C'est, au contraire, la limite des connexions d'un utilisateur à toutes les bases de données, c'est-à-dire pertinent si vous avez plusieurs bases de données et qu'elles relèvent des mêmes utilisateurs.max_client_conn - combien de connexions client PgBouncer acceptera au total. Par défaut, comme d'habitude, a une signification très étrange - 100. Autrement dit, il est supposé que si plus de 100 clients se bloquent soudainement, alors ils ont juste besoin de reset silencieusement au niveau TCP et de reset (enfin, dans les journaux, je dois admettre, ce sera "plus de connexions autorisées (max_client_conn)")).
Il peut être utile de créer max_client_conn >> SUM ( pool_size' ) , par exemple, 10 fois plus.
En plus de SHOW POOLS service pseudo-base pgbouncer fournit également la SHOW DATABASES , qui montre les limites réellement appliquées à un pool particulier:

Connexions au serveur
Encore une fois - comment mesurer le nombre de composés utilisés?
En blagues en moyenne / en pointe / en temps?
En pratique, il est assez problématique de surveiller l'utilisation des piscines par le videur avec des outils répandus, comme pgbouncer lui-même ne fournit qu'une image momentanée, et comme souvent ne fait pas d'enquête, il y a toujours la possibilité d'une image erronée en raison de l'échantillonnage. Voici un exemple réel où, selon le moment où l'exportateur a travaillé - au début de la minute ou à la fin - l'image des composés ouverts et utilisés change fondamentalement:
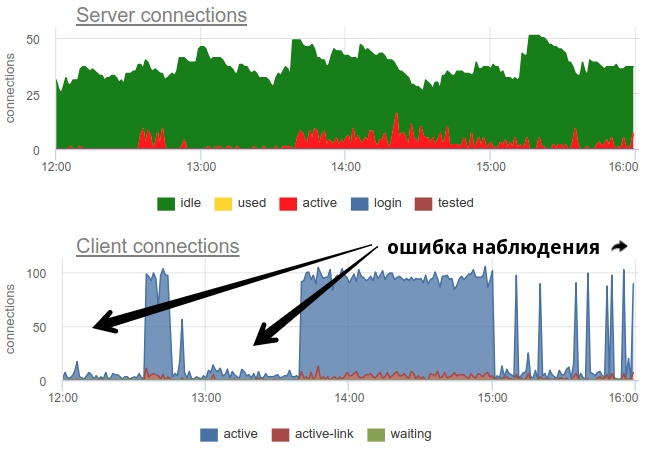
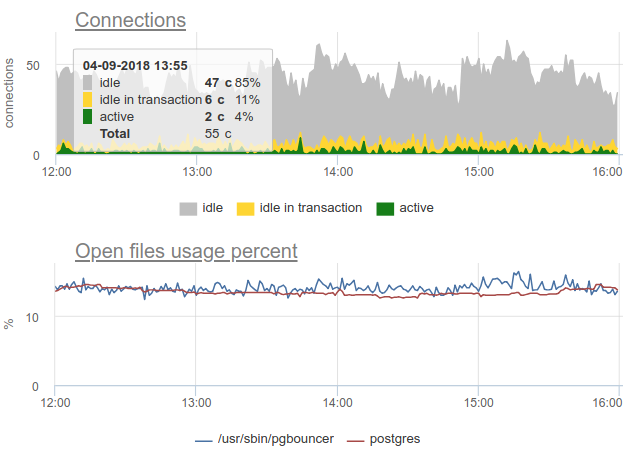
Ici, tous les changements dans la charge / utilisation des connexions ne sont qu'une fiction, un artefact des redémarrages du collecteur de statistiques. Ici vous pouvez voir les graphiques de connexion dans Postgres pendant cette période et les descripteurs de fichiers du videur et de la PG - aucun changement:
Revenons à la question de l'élimination. Nous avons décidé d'utiliser une approche combinée dans notre service - nous échantillonnons SHOW POOLS une fois par seconde, et une fois par minute, nous rendons le nombre moyen et maximum de connexions dans chaque classe:
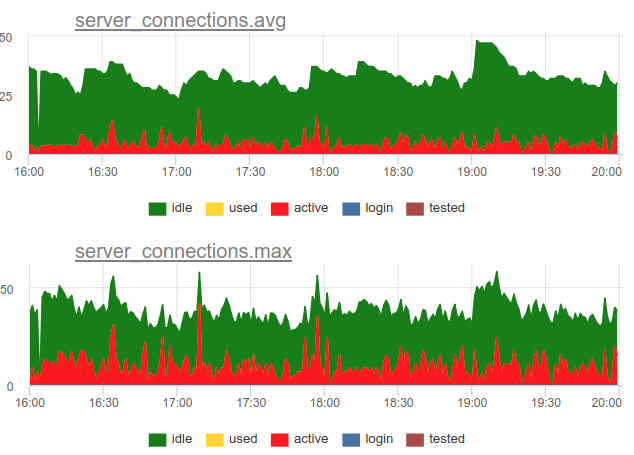
Et si nous divisons le nombre de ces connexions d'état actives par la taille du pool, nous obtenons l'utilisation moyenne et maximale de ce pool et pouvons alerter s'il est proche de 100%.
De plus, PgBouncer dispose d'une commande SHOW STATS qui affichera des statistiques d'utilisation pour chaque base de données proxy:

Nous sommes plus intéressés par la colonne total_query_time - le temps passé par toutes les connexions dans le processus d'exécution des requêtes dans postgres. Et à partir de la version 1.8, il y a aussi la métrique total_xact_time - le temps passé dans les transactions. Sur la base de ces métriques, nous pouvons construire une utilisation du temps de connexion au serveur; cet indicateur n'est pas soumis, contrairement au calcul à partir des états de connexion, à des problèmes d'échantillonnage, car ces total_..._time sont cumulatifs et ne passent rien:

Comparez
On peut voir que l'échantillonnage ne montre pas tous les moments d'utilisation élevée à ~ 100%, et les spectacles query_time.
Saturation et PgBouncer
Pourquoi avez-vous besoin de surveiller la saturation, en raison de la forte utilisation, il est déjà clair que tout va mal?
Le problème est que, quelle que soit la façon dont vous mesurez l'utilisation, même les compteurs accumulés ne peuvent pas afficher une utilisation locale des ressources à 100% si elle ne se produit qu'à des intervalles très courts. Par exemple, vous disposez de couronnes ou d'autres processus synchrones qui peuvent simultanément lancer des requêtes vers la base de données à la commande. Si ces demandes sont courtes, alors l'utilisation, mesurée sur des échelles de minutes et même de secondes, peut être faible, mais en même temps, à un moment donné, ces demandes ont été forcées d'attendre en ligne pour l'exécution. Cela est similaire avec une situation d'utilisation du processeur à 100% et une moyenne de charge élevée - comme le temps processeur est toujours là, mais néanmoins de nombreux processus attendent leur exécution.
Comment cette situation peut-elle être surveillée? cl_waiting bien, encore une fois, nous pouvons simplement compter le nombre de clients dans l'état cl_waiting selon SHOW POOLS . Dans une situation normale, il y a zéro, et plus de zéro signifie un débordement de ce pool:
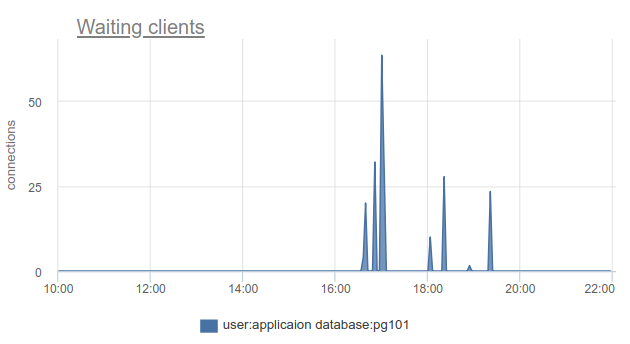
Il reste le problème que SHOW POOLS ne peut être échantillonné, et dans une situation avec des couronnes synchrones ou quelque chose comme ça, nous pouvons simplement ignorer et ne pas voir de tels clients en attente.
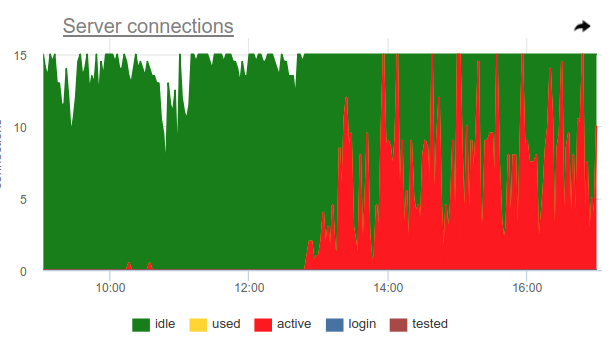
Vous pouvez utiliser cette astuce, pgbouncer lui-même peut détecter une utilisation à 100% du pool et ouvrir le pool de sauvegarde. Deux paramètres en sont responsables: reserve_pool_size - pour sa taille, comme je l'ai dit, et reserve_pool_timeout - combien de secondes un client doit waiting avant d'utiliser le pool de sauvegarde. Ainsi, si nous voyons sur le graphique des connexions serveur que le nombre de connexions ouvertes à Postgres est supérieur à pool_size, alors il y avait une saturation du pool, comme ceci:

De toute évidence, quelque chose comme des couronnes une fois par heure fait beaucoup de demandes et occupe complètement la piscine. Et même si nous ne voyons pas le moment où active connexions active dépassent la limite pool_size , pgbouncer a quand même été obligé d'ouvrir des connexions supplémentaires.
Également sur ce graphique, le travail des paramètres server_idle_timeout est clairement visible - après combien arrêter la fermeture et fermer les connexions qui ne sont pas utilisées. Par défaut, c'est 10 minutes, ce que nous voyons sur le graphique - après les pics active à exactement 5h00, à 6h00, etc. (selon cron 0 * * * * ), les connexions restent idle + used 10 minutes supplémentaires et se ferment.
Si vous vivez à la pointe du progrès et avez mis à jour PgBouncer au cours des 9 derniers mois, vous pouvez trouver dans la colonne SHOW STATS total_wait_time , qui montre le mieux la saturation, car considère cumulativement le temps passé par les clients en waiting . Par exemple, ici - l' waiting est apparu à 16h30:
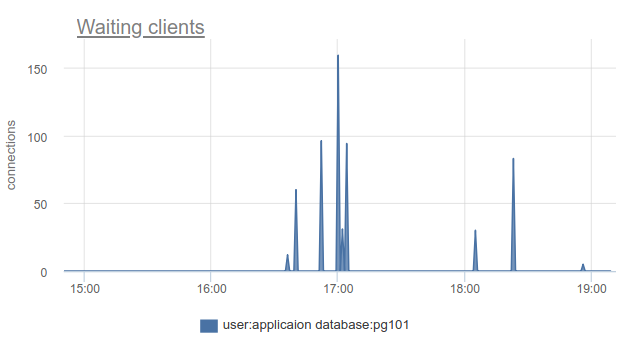
Et wait_time , qui est comparable et affecte clairement average query time , peut être vu de 15h15 à presque 19:

Néanmoins, la surveillance de l'état des connexions client est toujours très utile, car cela vous permet de découvrir non seulement le fait que toutes les connexions à une telle base de données ont été dépensées et que les clients doivent attendre, mais aussi parce que SHOW POOLS divisé en pools séparés par les utilisateurs, et SHOW STATS ne le fait pas, il vous permet de savoir quels clients ont utilisé toutes les connexions à la base spécifiée - selon la colonne sv_active du pool correspondant. Ou par métrique
sum_by(user, database, metric(name="pgbouncer.clients.count", state="active-link")):
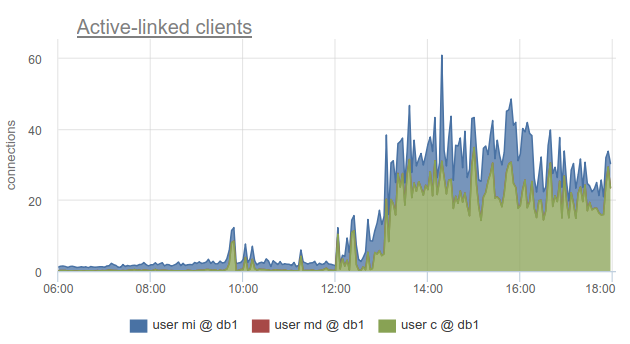
Chez okmeter, nous sommes allés encore plus loin et avons ajouté une ventilation des connexions utilisées par les adresses IP des clients qui les ont ouvertes et utilisées. Cela vous permet de comprendre exactement quelles instances d'application se comportent différemment:

Nous voyons ici les adresses IP de kubernetes spécifiques de foyers que nous devons traiter.
Des erreurs
Il n'y a rien de particulièrement compliqué ici: pgbouncer écrit des journaux dans lesquels il signale des erreurs si la limite de connexions client est atteinte, le délai de connexion au serveur, etc. Nous n'avons pas encore atteint les journaux de pgbouncer :(
ROUGE pour PgBouncer
Alors que l'USAGE est plus axé sur les performances, au sens de goulots d'étranglement, RED, à mon avis, concerne davantage les caractéristiques du trafic entrant et sortant en général, et non les goulots d'étranglement. Autrement dit, RED répond à la question - tout fonctionne-t-il bien, et sinon, USE aidera à comprendre quel est le problème.
Prérequis
Il semblerait que tout soit assez simple pour la base de données SQL et pour l'extracteur de proxy / connexion dans une telle base de données - les clients exécutent des instructions SQL, qui sont des requêtes. A partir de SHOW STATS nous prenons total_requests et total_requests sa dérivée temporelle
rate(metric(name="pgbouncer.total_requests", database: "*"))

Mais en fait, il existe différents modes de tirage, et le plus courant est les transactions. L'unité d'oeuvre pour ce mode est une transaction, pas une requête. Par conséquent, à partir de la version 1.8, Pgbouner fournit déjà deux autres statistiques - total_query_count , au lieu de total_requests , et total_xact_count - le nombre de transactions terminées.
Désormais, la charge de travail peut être caractérisée non seulement en termes de nombre de demandes / transactions terminées, mais, par exemple, vous pouvez consulter le nombre moyen de demandes par transaction dans différentes bases de données, en les divisant les unes les autres
rate(metric(name="total_requests", database="*")) / rate(metric(name="total_xact", database="*"))

Ici, nous voyons des changements évidents dans le profil de charge, ce qui peut être la raison du changement de performances. Et si vous ne regardez que le taux de transactions ou de demandes, vous ne le verrez peut-être pas.
Erreurs RED
Il est clair que RED et USE se recoupent sur la surveillance des erreurs, mais il me semble que les erreurs dans USE concernent principalement des erreurs de traitement des demandes dues à une utilisation à 100%, c'est-à-dire lorsque le service refuse d'accepter plus de travail. Et pour RED, il serait préférable de mesurer précisément les erreurs du point de vue du client, des demandes du client. C'est-à-dire, non seulement dans une situation où le pool dans PgBouncer est plein ou une autre limite a fonctionné, mais aussi lorsque des délais d'expiration de demande tels que "l'annulation de la déclaration en raison du délai de la déclaration", les annulations et les annulations de transactions par le client lui-même ont fonctionné, etc. e. niveau supérieur, plus proche des types d'erreurs de la logique métier.
Durées
Ici encore, SHOW STATS avec les compteurs cumulatifs total_xact_time , total_query_time et total_wait_time nous aidera, en les divisant par le nombre de demandes et de transactions, respectivement, nous obtenons le temps moyen de demande, le temps moyen de transaction, le temps d'attente moyen par transaction. J'ai déjà montré un graphique sur le premier et le troisième:
Que pouvez-vous obtenir d'autre? L'antipattern bien connu pour travailler avec la base de données et Postgres, en particulier, lorsque l'application ouvre une transaction, fait une demande, puis commence (pendant longtemps) à traiter ses résultats, ou pire encore - va à un autre service / base de données et y fait des demandes. Pendant tout ce temps, la transaction «se bloque» dans le postgres ouvert, le service retourne et fait encore plus de requêtes, met à jour dans la base de données, et seulement alors ferme la transaction. Pour les postgres, c'est particulièrement désagréable, car pg les travailleurs sont chers. Nous pouvons donc surveiller quand une telle application est idle in transaction dans le postgres lui-même - selon la colonne d' state dans pg_stat_activity , mais il y a toujours les mêmes problèmes décrits avec l'échantillonnage, car pg_stat_activity ne donne que l'image actuelle. Dans PgBouncer, nous pouvons soustraire le temps passé par les clients dans les requêtes total_query_time du temps passé dans les transactions total_xact_time - ce sera le temps d'une telle marche au ralenti. Si le résultat est toujours divisé par total_xact_time , il sera normalisé: une valeur de 1 correspond à une situation où les clients sont idle in transaction 100% du temps. Et avec une telle normalisation, il est facile de comprendre à quel point tout est mauvais:
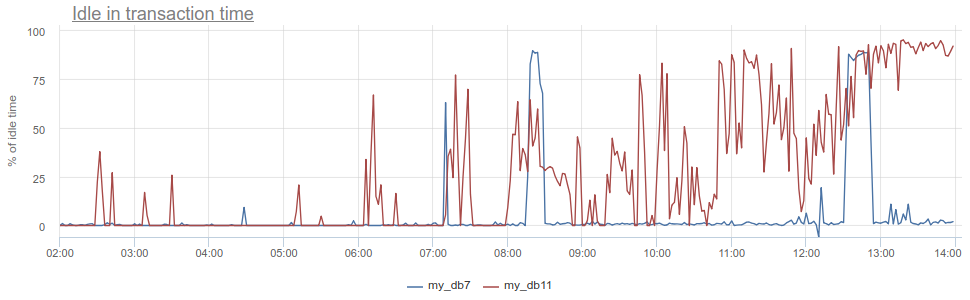
De plus, en revenant à Duration, la métrique total_xact_time - total_query_time peut être divisée par le nombre de transactions pour voir le montant moyen de l'application inactive par transaction.
À mon avis, les méthodes USE / RED sont les plus utiles pour structurer les mesures que vous prenez et pourquoi. Étant donné que nous sommes engagés dans une surveillance à temps plein et que nous devons effectuer la surveillance de divers composants d'infrastructure, ces méthodes nous aident à prendre les mesures correctes, à faire les bons calendriers et déclencheurs pour nos clients.
Un bon suivi ne peut pas être fait tout de suite, c'est un processus itératif. Dans okmeter.io, nous avons juste une surveillance continue (il y a beaucoup de choses, mais demain ce sera mieux et plus détaillé :)