
Je m'appelle Yuri Nevinitsin et je suis engagé dans le système de statistiques internes en OK. Je veux parler de la façon dont nous avons transféré un système analytique de 50 téraoctets en temps réel, dans lequel des milliards d'événements sont journalisés quotidiennement, de Microsoft SQL vers une base de colonnes appelée Druid. Et en même temps, vous apprendrez quelques recettes pour utiliser
Druid .
Pourquoi avons-nous besoin de statistiques?
Nous voulons tout savoir sur notre site, nous enregistrons donc non seulement le comportement des disques, des processeurs, etc., mais aussi chaque action de l'utilisateur, chaque interaction entre les sous-systèmes et tous les processus internes de presque tous nos systèmes. Le système statistique est étroitement intégré au processus de développement.
Sur la base des données du système statistique, nos managers fixent des objectifs pour les équipes, suivent leurs réalisations et indicateurs clés. Les administrateurs et les développeurs surveillent le fonctionnement de tous les systèmes, enquêtent sur les incidents et les anomalies. La surveillance automatique surveille constamment et à un stade précoce identifie les problèmes, fait des prévisions de dépassement des limites. De plus, des fonctionnalités et des expériences sont constamment lancées, des mises à jour et des modifications sont apportées. Et nous surveillons l'effet de toutes ces actions via le système statistique. Si elle refuse, nous ne pourrons pas apporter de modifications au site.
Nos statistiques sont présentées principalement sous forme de graphiques. En règle générale, le graphique affiche plusieurs jours à la fois, de sorte que la dynamique est claire. Voici un exemple de mes expériences avec Druid. Voici un graphique de chargement des données (lignes / 5 min).
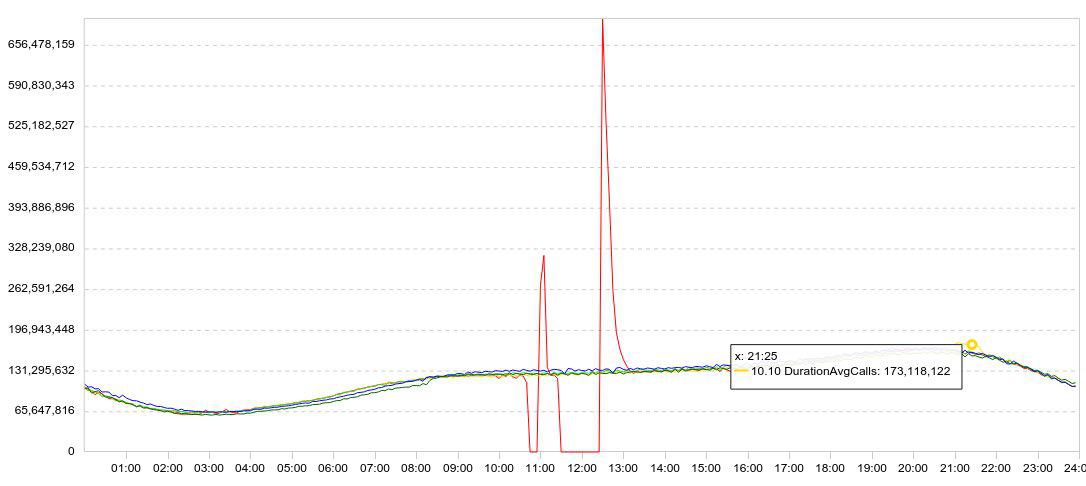
J'ai ralenti le téléchargement (le graphique rouge tombe à zéro), j'ai attendu un moment, j'ai redémarré le téléchargement et j'ai regardé à quelle vitesse Druid pouvait charger les données accumulées (pics après échecs).
Toute planification peut être développée par n'importe quel paramètre, par exemple, par hôte, table, opération, etc. Nous avons également des graphiques à long terme avec une dynamique annuelle. Par exemple, ci-dessous est un graphique de l'augmentation quotidienne du nombre d'entrées dans Druid.
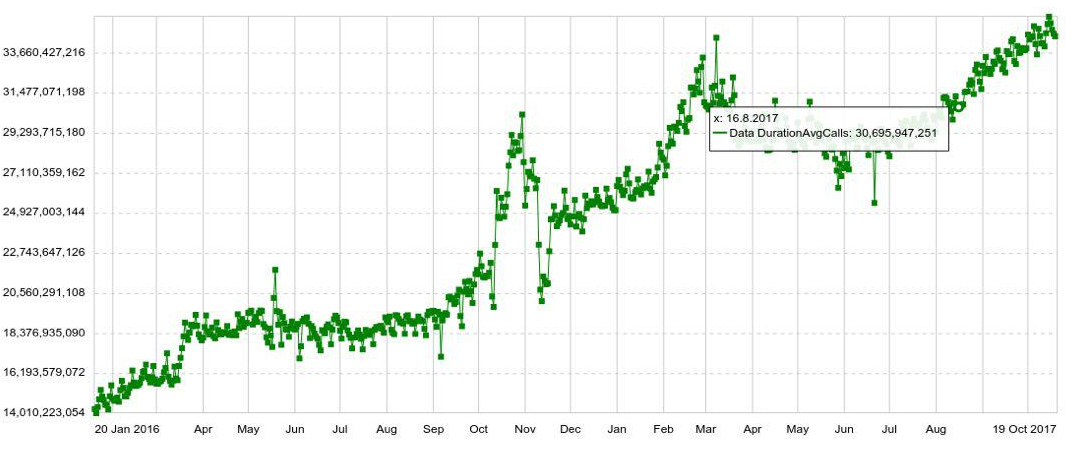
Nous pouvons également combiner plusieurs graphiques sur des panneaux séparés (tableaux de bord), ce qui s'est avéré très pratique. Et même si l'utilisateur n'a besoin de voir que quelques centaines de graphiques, il les ouvre toujours non pas individuellement, mais dans le panneau, ce qui augmente la charge sur le système.
Le problème
Alors que le volume de données était petit, nous avons assez bien géré SQL. Mais à mesure que le volume de données augmentait, la production de graphiques ralentissait. Et à la fin, les statistiques aux heures de pointe ont commencé à accuser un retard d'une demi-heure, et le temps de réponse moyen d'un graphique a atteint 6 secondes. Autrement dit, quelqu'un a reçu le calendrier en 2 secondes, quelqu'un en 10-20 et quelqu'un en une minute. (Vous pouvez en savoir plus sur le développement du système en SQL
ici )
Lorsque vous enquêtez sur une anomalie ou un incident, vous devez généralement ouvrir et voir une douzaine de graphiques, dont chacun découle du précédent, ils ne peuvent pas être ouverts en même temps. J'ai dû attendre 10 fois pendant 10-20 secondes. C'était très ennuyeux.
La migration
Vous pouvez toujours extraire quelque chose du système, ajouter des serveurs ... Mais à peu près au même moment, Microsoft a changé sa politique de licence. Si nous continuions à utiliser SQL Server, nous devions donner des millions de dollars. Par conséquent, ils ont décidé de migrer.
Les exigences étaient les suivantes:
- Les statistiques ne doivent pas être à la traîne (plus de 2 minutes).
- Le graphique devrait s'ouvrir en moins de 2 secondes.
- Le panneau entier doit s'ouvrir en moins de 10 secondes.
- Le système doit être tolérant aux pannes, capable de survivre à la perte d'un centre de données.
- Le système doit être facilement évolutif.
- Le système devrait être facile à modifier, nous voulions donc qu'il soit en Java.
Tout cela ne nous a été offert que par des druides. Il dispose également d'une agrégation préliminaire, qui vous permet d'économiser un peu plus de volume et d'indexation lors de l'insertion des données. Druid prend en charge tous les types de requêtes nécessaires à nos statistiques. Par conséquent, il semblait que nous pouvions facilement remplacer Druid par SQL Server.
Bien sûr, nous avons considéré non seulement Druide pour le rôle de candidat au déménagement. Ma première pensée a été de remplacer Microsoft SQL Server par PostgreSQL. Cependant, cela ne résoudrait que le problème des coûts financiers, mais ne contribuerait pas à l'accessibilité et à la mise à l'échelle.
Nous avons également analysé Influx, mais il s'est avéré que la partie responsable de la haute disponibilité et de l'évolutivité est fermée. Prometheus, avec tout le respect dû à ses performances, est plus adapté à la surveillance et ne peut se targuer ni de haute disponibilité ni de simple évolutivité. OpenTSDB est également plus adapté à la surveillance, il n'a pas d'index pour tous les champs. Nous n'avons pas considéré Click House, car à cette époque, il n'était pas là.
Mettez Druid. Téraoctets de données migrés. Et immédiatement après le passage de SQL Server à Druid, le nombre de vues graphiques a été multiplié par 5. Ensuite, ils ont commencé à exécuter des statistiques «lourdes», qu'ils avaient peur d'exécuter plus tôt, car SQL ne le gérerait guère.
Désormais, Druid à partir de 12 nœuds (40 cœurs, 196 Go de RAM) prend 500 000 événements par seconde par heure de pointe, alors qu'il existe une grande marge de sécurité (colonne MAX: presque cinq fois la marge du processeur).
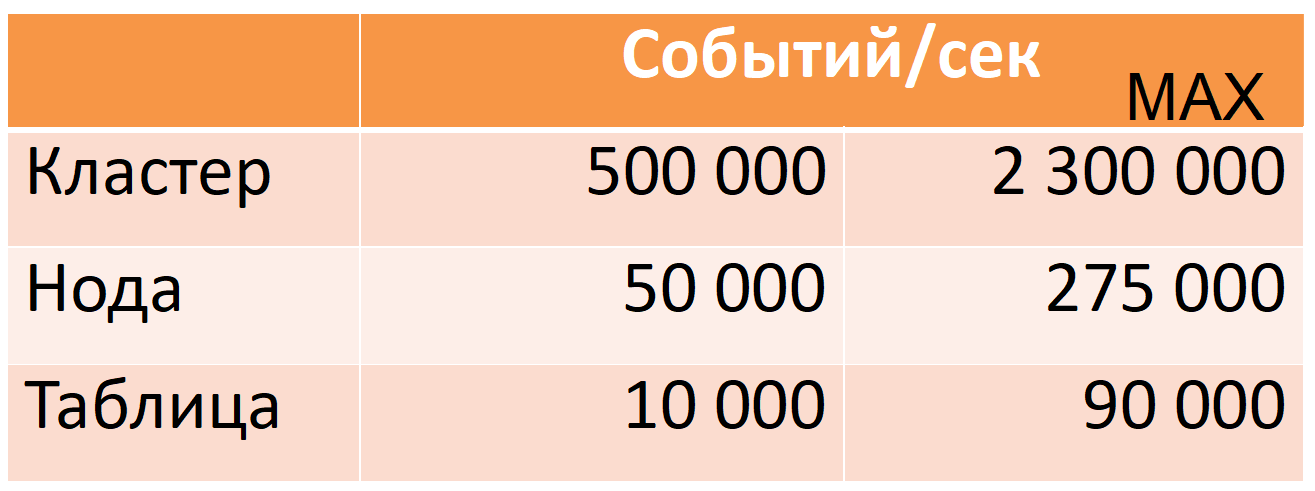
Ces chiffres sont basés sur des données de production. Je vais vous dire comment nous y sommes parvenus, mais je vais d'abord décrire Druid plus en détail.
Druide
Il s'agit d'un système OLAP à colonnes temporelles réparties. Sa documentation ne contient pas les concepts habituels du monde SQL pour une table (source de données à la place) ou une chaîne (événement à la place), mais je les utiliserai pour faciliter la description.
Druid est basé sur plusieurs hypothèses de données (limitations):
- chaque ligne de données a un horodatage qui croît de façon monotone (dans une fenêtre de 10 minutes par défaut).
- les données ne changent pas, insérer uniquement (opération de mise à jour non).
Cela vous permet de découper les données en soi-disant segments de temps. Un segment est une "partition" minimale indivisible et invariable d'une table pendant une certaine période de temps. Toutes les opérations de données, toutes les requêtes sont effectuées segment par segment.
Chaque segment est autosuffisant: en plus de la table principale, écrite sous forme de colonnes, il contient également les répertoires et index nécessaires à l'exécution des requêtes. Nous pouvons dire qu'un segment est une base de données en lecture seule à petite colonne (une description plus détaillée du périphérique de segment sera donnée ci-dessous).
À son tour, cela se traduit par une «distribution»: la capacité de diviser une grande quantité de données en petits segments afin d'effectuer des calculs en parallèle (à la fois sur une machine et sur plusieurs à la fois).
Si vous devez «mettre à niveau» au moins une ligne, vous devrez recharger à nouveau l'intégralité du segment. C'est possible et tout est prêt pour cela. Chaque segment a une version, et un segment avec une version plus récente remplacera automatiquement le segment avec l'ancienne version (cependant, si une mise à jour est requise régulièrement, vous devez réévaluer si Druid est adapté à ce cas d'utilisation).
Pour décrire le segment de périphérique, nous considérons un exemple simple sous la forme tabulaire habituelle:
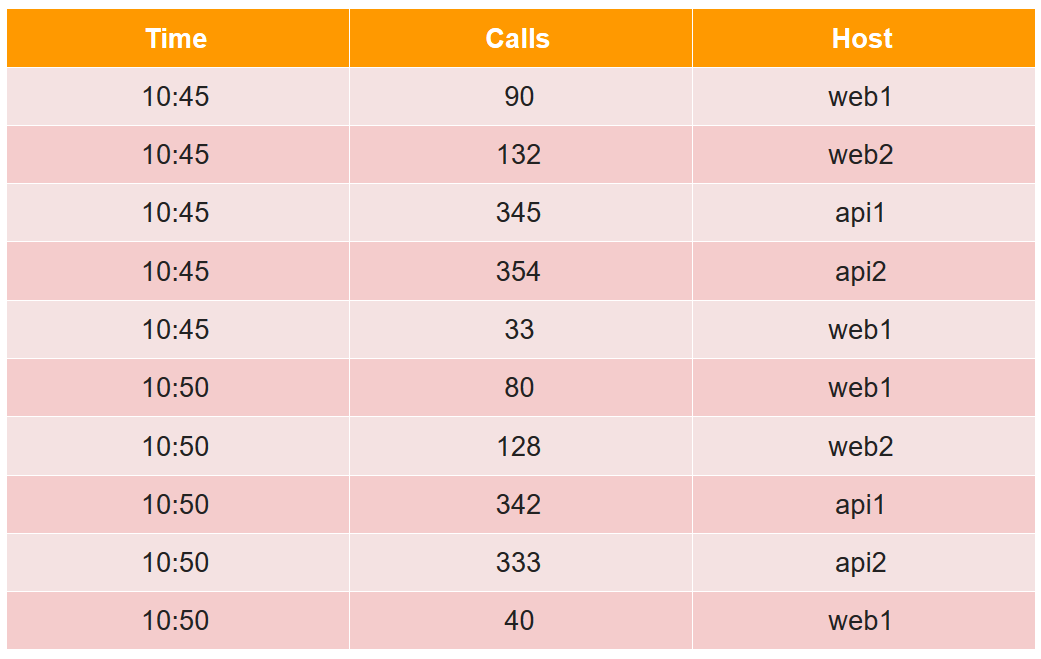
Dans ce tableau, le nombre d'appels en deux cinq minutes à partir de quatre hôtes (notez que pour l'hôte web1, il y a deux lignes dans chaque période de cinq minutes).
Toutes les cellules de données du point de vue du druide sont divisées en trois types:
- timestamp - Horodatage UTC en ms (dans l'exemple c'est Time).
- les métriques sont ce que vous devez calculer (somme, min, max, nombre, ...), et vous devez les connaître à l'avance pour chaque table (dans l'exemple, il s'agit d'Appels, et nous calculerons la somme).
- dimensions - c'est ce que vous pouvez regrouper et filtrer (vous n'avez pas besoin de les connaître à l'avance et vous pouvez les modifier à la volée) (dans l'exemple, il s'agit de l'hôte).
Lors de l'insertion, toutes les lignes sont regroupées par l'ensemble complet de dimensions + horodatage, et si elles correspondent à chacune des métriques, «sa» fonction d'agrégation est appliquée (en conséquence, il n'y a pas de lignes avec le même ensemble de dimensions + horodatage). Ainsi, notre exemple après insertion dans le druide ressemblera à ceci:

L'horodatage et toutes les métriques (dans notre cas, il s'agit du temps et des appels) seront écrits sous forme de tableaux de nombres de type long (float et double sont également pris en charge). Pour chacune des dimensions (dans notre cas, c'est Host), un dictionnaire sera créé - un ensemble trié de chaînes (avec les noms d'hôte). La colonne hôte elle-même sera écrite comme un tableau int, indiquant les nombres dans le dictionnaire.
Veuillez noter qu'après l'insertion dans le druide, des paires de lignes pour l'hôte web1 avec le même horodatage ont été agrégées et le montant total a été enregistré dans les appels (il est impossible d'extraire les données initiales du druide).
Les index sont nécessaires pour un filtrage rapide des données, car il peut y avoir des millions de lignes et des milliers d'hôtes. Les index sont des bitmaps, un pour chaque ligne du dictionnaire.

Les unités indiquent les numéros de ligne auxquels cet hôte participe. Pour filtrer deux hôtes, vous devez prendre deux bitmaps, les combiner via OR et sélectionner les numéros de ligne en unités du bitmap résultant.
Un druide est composé de nombreux composants.
Premièrement, il a plusieurs dépendances externes.

- Stockage Là, Druid stocke simplement les segments sous une forme compressée. Il peut s'agir d'un répertoire local, HDFS, Amazon S3. Seul l'espace est utilisé ici, aucun calcul n'est effectué.
- Meta: une base de données pour les informations Meta. Cette base de données stocke la carte de données complète: quels segments sont pertinents, qui sont obsolètes, quel chemin est en stockage.
- À l'aide de ZooKeeper, le système effectue la découverte et annonce sur quels nœuds de druide quels segments sont disponibles pour la requête.
- Cache des requêtes exécutées, il peut être un cache memcached ou local dans le tas java.
Deuxièmement, Druid lui-même se compose de plusieurs types de composants.
- Les nœuds en temps réel chargent le flux de nouvelles données dans l'ordre de leur réception et répondent aux demandes.
- Les nœuds historiques contiennent l'intégralité de la masse de données et répondent aux demandes. Lorsque nous disons que nous avons un cluster de 300 To, nous voulons dire des nœuds historiques.
- Le courtier est responsable de la distribution des calculs entre les nœuds historiques et en temps réel.
- Le coordinateur est responsable de l'allocation des segments sur les nœuds historiques et de la réplication.
- Service d'indexation, qui vous permet de (re) charger des données par lots, par exemple, pour "mettre à niveau" une partie des données.
Flux de données
 Les flèches en gras indiquent un flux de données, les flèches fines indiquent un flux de métadonnées.
Les flèches en gras indiquent un flux de données, les flèches fines indiquent un flux de métadonnées.Un nœud en temps réel prend des données, indexe et coupe en segments par heure, par exemple par jour.
Chaque nouveau segment d'un nœud en temps réel écrit dans le stockage et laisse une copie pour répondre aux demandes. Il enregistre ensuite les métadonnées qu'un nouveau segment est apparu dans le référentiel le long de tel ou tel chemin.
Ces informations sont reçues par le coordinateur, relisant périodiquement la base de métadonnées. Lorsqu'il trouve un nouveau segment, (via ZooKeeper) ordonne à plusieurs nœuds historiques de télécharger ce segment. Ils téléchargent et (via ZooKeeper) annoncent qu'ils ont un nouveau segment. Lorsqu'un nœud en temps réel reçoit ce message (via ZooKeeper), il supprime sa copie pour faire de la place pour de nouvelles données.
Traitement des demandes

Trois types de nœuds participent au traitement des demandes: courtier, temps réel et historique. La demande parvient au courtier, qui sait sur quels nœuds quels segments sont situés. Il distribue la demande par des nœuds historiques (et en temps réel) qui stockent les segments souhaités. Les nœuds historiques parallélisent aussi autant que possible les calculs, envoient les résultats au courtier et les remettent au client. En combinant ce schéma avec le stockage des données de colonne, Druid peut traiter de grandes quantités d'informations très rapidement.
Haute disponibilité
Comme vous vous en souvenez, Druid dans la liste des dépendances a une base pour les métadonnées, qui peuvent être MySQL ou PostgreSQL. Apache Derby est également mentionné, mais ce produit ne peut pas être utilisé pour la production, uniquement pour le développement (si je comprends bien, derby est utilisé sous une forme intégrée, afin de ne pas augmenter mysql / pgsql dans un environnement virgo).
Que se passera-t-il si cette base échoue (et / ou le stockage et / ou le coordinateur)? Un nœud en temps réel ne peut pas écrire de métadonnées (et / ou de segments). Le coordinateur ne pourra alors pas les relire et ne trouvera pas de nouveau segment. Le nœud historique ne le téléchargera pas et le nœud en temps réel ne supprimera pas sa copie, mais continuera de télécharger les dernières données. En conséquence, les données commenceront à s'accumuler dans les nœuds en temps réel. Cela ne peut pas durer indéfiniment. Néanmoins, on sait quelles ressources sont disponibles sur les nœuds en temps réel et quel type de flux de données nous avons. Par conséquent, nous disposons d'un délai prévisible pendant lequel nous pouvons réparer la base défaillante (et / ou le stockage et / ou le coordinateur).
Étant donné que mysql / pgsql pris en charge ne garantit pas une haute disponibilité prête à l'emploi, nous avons décidé de la jouer en toute sécurité et avons utilisé notre propre solution (prête à l'emploi) basée sur Cassandra, car elle fournit une haute disponibilité (vous pouvez en savoir plus
ici ).
De plus, nous avons finalisé les nœuds en temps réel de telle manière qu'avec une accumulation excessive, les données les plus anciennes soient supprimées, libérant ainsi de l'espace pour les nouvelles. C'est très important pour nous, car la situation où nous ne pouvons pas élever une base défaillante (et / ou un stockage et / ou un coordinateur) pendant une longue période et que beaucoup de données s'accumulent est probablement la conséquence d'un gros accident. Et en ce moment, les dernières données sont les plus importantes.
Druide et ZooKeeper
Avec ZooKeeper, tout va de mieux en pire. Mieux parce que ZooKeeper lui-même est tolérant aux pannes, il a une réplication prête à l'emploi. Il semblerait que cela pourrait arriver?
D'une manière générale, ce chapitre n'est plus d'actualité. Et ce n'est pas une réussite, c'est une douleur qui (nous et le nouveau druide frais) a décidé de supprimer radicalement presque toutes les données de ZooKeeper, et maintenant les nœuds de druides les demandent directement les uns des autres via HTTP.
ZooKeeper a deux types de délais d'expiration. Le délai d'expiration de la connexion est un délai d'expiration réseau simple, après quoi le client se reconnecte à ZooKeeper et tente de restaurer sa session. Et le délai d'expiration de la session, après quoi la session est supprimée et toutes
les données
éphémères créées dans cette session sont également supprimés (par ZooKeeper lui-même), qui est notifié à tous les autres clients ZooKeeper.
Sur cette base, la découverte dans le druide fonctionne: au démarrage, chaque nœud crée une nouvelle session dans ZooKeeper et écrit
des données
éphémères sur lui-même: hôte: port, type de nœud (courtier / temps réel / historique / ...), horodatage de la connexion, etc. ... D'autres nœuds de druide reçoivent des notifications de ZooKeeper et lisent ces données, afin qu'ils apprennent qu'un nouveau nœud de druide est apparu et de quel type de nœud il s'agit. Si un nœud de druide tombe après l'expiration de sa session, les données le concernant seront supprimées par ZooKeeper et les autres nœuds de druide le sauront. Pour qu'ils en sachent plus vite, nous préférons mettre un petit timeout de session.
Lorsqu'un nœud en temps réel ou historique monte, il, en plus des données le concernant, écrit également dans ZooKeeper une liste de segments qu'il possède (il s'agit également de données
éphémères ). Plus loin sur le chemin, les segments sur les nœuds historiques et en temps réel sont créés nouveaux et anciens sont supprimés, et chaque nœud reflète cela dans sa liste dans ZooKeeper. Cette liste peut être volumineuse, elle est donc divisée en parties afin que toute la liste ne soit pas remplacée, mais uniquement la partie modifiée.
Le courtier, à son tour, lorsqu'il voit un nouveau nœud en temps réel ou historique, soustrait également sa liste de segments à ZooKeeper afin de distribuer les demandes à ce nœud. Les nœuds en temps réel lisent cette liste pour supprimer leur copie du segment apparu sur le nœud historique. Étant donné que la liste est divisée en parties et est remplacée en parties, ZooKeeper vous indiquera quelle partie a été modifiée, mais elle sera relue.
Comme je l'ai dit, cette liste peut être longue. Lorsqu'il y a beaucoup de données dans ZooKeeper, il s'avère qu'il n'est plus aussi stable. Dans notre cas, des problèmes évidents ont commencé lorsque le nombre de segments a atteint environ 7 millions, l'instantané ZooKeeper occupait alors 6 Go.
Que se passe-t-il si un nœud druide perd contact avec ZooKeeper?
Druid travaille avec ZooKeeper de telle manière que dans le cas d'un délai d'expiration de session, chaque nœud crée une nouvelle session et y écrit toutes ses données et relit les données des autres nœuds. Puisqu'il y a beaucoup de données, le trafic décolle sur ZooKeeper. Cela peut entraîner un délai d'attente sur d'autres nœuds du druide, puis, eux aussi, commencent à réécrire et à relire. Ainsi, le trafic augmente comme une avalanche au point que ZooKeeper perd la synchronisation entre ses instances et commence à générer des instantanés d'avant en arrière.
Que voit l'utilisateur en ce moment?
Lorsqu'un courtier perd contact avec ZooKeeper (et qu'un délai d'expiration de session se produit), il ne sait plus sur quels segments se trouvent les nœuds historiques. Et donne des réponses vides. Autrement dit, si ZooKeeper est en panne, alors Druid ne fonctionne pas. Il est totalement impossible de le «guérir», mais il est possible d'étaler des pailles à certains endroits.
Premièrement, vous pouvez supprimer des données de ZooKeeper. Ce n'est pas grave s'ils se perdent: Druid les écrasera simplement. Si le problème avec ZooKeeper a déjà commencé, alors pour sa solution la plus rapide, il est recommandé de désactiver ZooKeeper, de supprimer les données et de les augmenter, et de ne pas attendre qu'elles se résolvent.
Maintenant, nous augmentons le délai d'expiration de la session. Que se passe-t-il dans ce cas?
Supposons que le nœud historique ne redémarre pas correctement et ne supprime pas l'ancienne session de ZooKeeper, tout en en créant une nouvelle et en y écrivant un tas de données. Alors que l'ancienne session est toujours en vie et que le délai d'expiration n'est pas écoulé, deux copies des données sont stockées dans ZooKeeper. S'il existe de nombreux nœuds redémarrés immédiatement, un grand nombre de données seront dupliquées. Par conséquent, vous devez conserver une réserve de mémoire pour ZooKeeper afin qu'elle ne s'épuise pas et que ZooKeeper ne cesse pas de fonctionner. Pourquoi n'a pas pu supprimer les données de l'ancienne session?
Pour la même raison, il est nécessaire de terminer correctement le fonctionnement des nœuds historiques, car à ce moment, ils suppriment leurs données de ZooKeeper, et peuvent le faire pendant une longue période. L'achèvement des nœuds historiques prend environ une demi-heure.
Les nœuds historiques ont une fonctionnalité supplémentaire. Au démarrage, ils examinent les segments qui y sont stockés, puis les informations à ce sujet sont écrites dans ZooKeeper. Et comme les données sont réparties plus ou moins uniformément sur les nœuds historiques, si vous les exécutez en même temps, ils commenceront à écrire sur ZooKeeper à peu près au même moment. Cela augmente à nouveau la probabilité d'une croissance du trafic semblable à une vague et de délais d'attente. Par conséquent, vous devez exécuter les nœuds historiques de manière séquentielle afin de répartir les sessions d'enregistrement dans ZooKeeper dans le temps.
Nous avons également fait deux optimisations supplémentaires:
- Nous avons légèrement reprogrammé le travail avec ZooKeeper afin que seuls les nœuds qui en ont besoin soient lus depuis Druid.Et ils ne sont nécessaires que par le temps réel, le courtier et le coordinateur, mais pas par les nœuds historiques. Ils n'ont pas besoin de savoir quels autres nœuds historiques ont des segments. De plus, tout cela n'est pas nécessaire pour le service d'indexation et ses employés, qui peuvent être nombreux.
- Des données écrites sur ZooKeeper, ils ont supprimé tout ce qui était superflu et n'ont laissé que ce qui était nécessaire pour répondre aux demandes. Cela a réduit la quantité de données dans ZooKeeper de 6 Go à 2 Go (c'est la taille de l'instantané).
En conséquence, le volume du trafic en forte croissance a diminué d'environ 8 fois; ainsi, nous avons minimisé la probabilité d'expiration des ventilateurs.Télécharger sur Druid
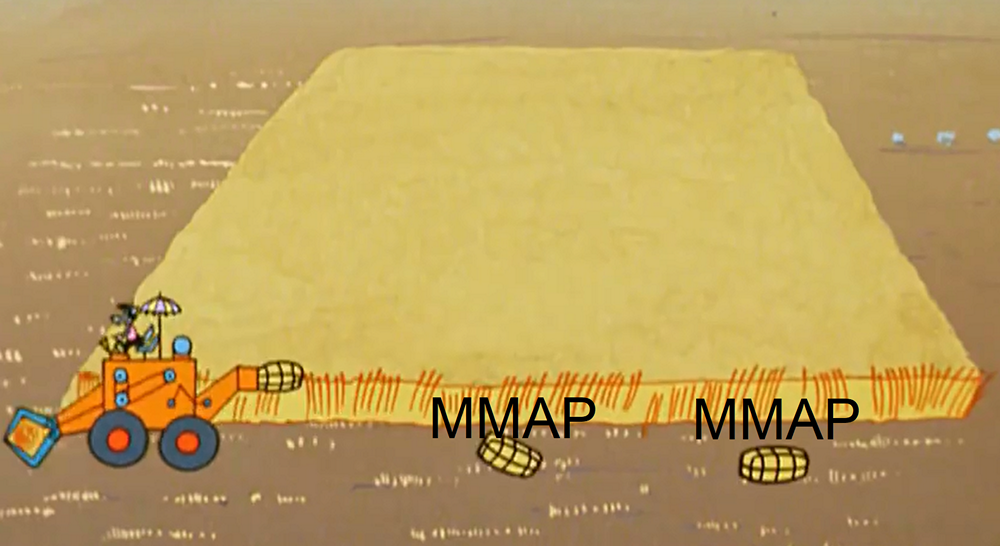 Lors du chargement des données en temps réel, le nœud libère périodiquement de la mémoire en vidant les données en parties sur le disque. Techniquement, ces parties sont des mini-segments (chacun a une table, des répertoires, des index). Et pour le traitement des demandes basées sur ces données, elles sont extraites en utilisant MMAP (ainsi que des segments complets). À la fin du chargement, un segment de ces pièces s'accumule. Deux points sont liés à cela.Tout d'abord, un nœud en temps réel peut corrompre des données, non seulement lors d'un plantage JVM ou d'un redémarrage inattendu du serveur, mais même lors d'un redémarrage correct.
Lors du chargement des données en temps réel, le nœud libère périodiquement de la mémoire en vidant les données en parties sur le disque. Techniquement, ces parties sont des mini-segments (chacun a une table, des répertoires, des index). Et pour le traitement des demandes basées sur ces données, elles sont extraites en utilisant MMAP (ainsi que des segments complets). À la fin du chargement, un segment de ces pièces s'accumule. Deux points sont liés à cela.Tout d'abord, un nœud en temps réel peut corrompre des données, non seulement lors d'un plantage JVM ou d'un redémarrage inattendu du serveur, mais même lors d'un redémarrage correct. Voilà pourquoi cela se produit. Le processus de vidage des données sur disque se compose de deux parties: 1) le rinçage direct des données et 2) le maintien de la position à partir de laquelle démarrer après un redémarrage. Ces deux types de données sont enregistrés de manière totalement indépendante, ils ne se connaissent pas. Et, bien sûr, pas atomiquement. Et selon ce qui est exactement perdu, nous avons soit une perte de données, soit une duplication. (Pour le moment, dans le druide d'origine, cela est activement réparé, mais pas réparé).Ce problème peut être résolu si vous n'utilisez pas de nœuds en temps réel et ne chargez pas de données à l'aide du service d'indexation, ou si vous les utilisez par paires, car le service d'indexation n'enregistre pas du tout la position, il chargera le segment entier ou supprimera ce qu'il n'a pas réussi à charger (pour une raison quelconque).Le deuxième point est la dégradation des performances à la demande. Plus ces parties s'accumulent sur le disque, en particulier sur les données et les requêtes volumineuses, pire c'est.Pour comprendre ce problème, nous devons revenir au segment de périphérique dans Druid et à notre exemple. Comme je l'ai montré plus tôt, après avoir chargé les données de l'exemple dans le druide, le segment résultant ressemblera à un ensemble de colonnes, un dictionnaire et des index.Voyons maintenant comment fonctionne la requête sur ce segment. Supposons que vous deviez calculer le nombre total d'appels pour plusieurs classes d'hôtes (web%, api%).
Voilà pourquoi cela se produit. Le processus de vidage des données sur disque se compose de deux parties: 1) le rinçage direct des données et 2) le maintien de la position à partir de laquelle démarrer après un redémarrage. Ces deux types de données sont enregistrés de manière totalement indépendante, ils ne se connaissent pas. Et, bien sûr, pas atomiquement. Et selon ce qui est exactement perdu, nous avons soit une perte de données, soit une duplication. (Pour le moment, dans le druide d'origine, cela est activement réparé, mais pas réparé).Ce problème peut être résolu si vous n'utilisez pas de nœuds en temps réel et ne chargez pas de données à l'aide du service d'indexation, ou si vous les utilisez par paires, car le service d'indexation n'enregistre pas du tout la position, il chargera le segment entier ou supprimera ce qu'il n'a pas réussi à charger (pour une raison quelconque).Le deuxième point est la dégradation des performances à la demande. Plus ces parties s'accumulent sur le disque, en particulier sur les données et les requêtes volumineuses, pire c'est.Pour comprendre ce problème, nous devons revenir au segment de périphérique dans Druid et à notre exemple. Comme je l'ai montré plus tôt, après avoir chargé les données de l'exemple dans le druide, le segment résultant ressemblera à un ensemble de colonnes, un dictionnaire et des index.Voyons maintenant comment fonctionne la requête sur ce segment. Supposons que vous deviez calculer le nombre total d'appels pour plusieurs classes d'hôtes (web%, api%).- Druide prendra d'abord le premier filtre, une expression régulière. Avec son aide, il traite l'intégralité du dictionnaire et trouve les hôtes correspondant au filtre.
- Il prendra les bitmaps appropriés, fusionnera et l'enregistrera dans un bitmap intermédiaire.
- Ensuite, Druid prendra la deuxième saison régulière, le deuxième filtre, faites de même: parcourez le dictionnaire, prenez les bitmaps, combinez, obtenez le deuxième bitmap intermédiaire.
- À la fin de Druid, le paquet résultant de bitmaps intermédiaires est combiné dans un bitmap final, qui montrera à partir de quelles lignes nous devons additionner les appels.
En utilisant le profileur, j'ai découvert que lors du traitement d'une demande, 5% du temps est consacré au calcul du montant et 95% au filtrage.Voyons maintenant ce qui se passe lorsqu'un nœud en temps réel vide les données au niveau du disque au démarrage.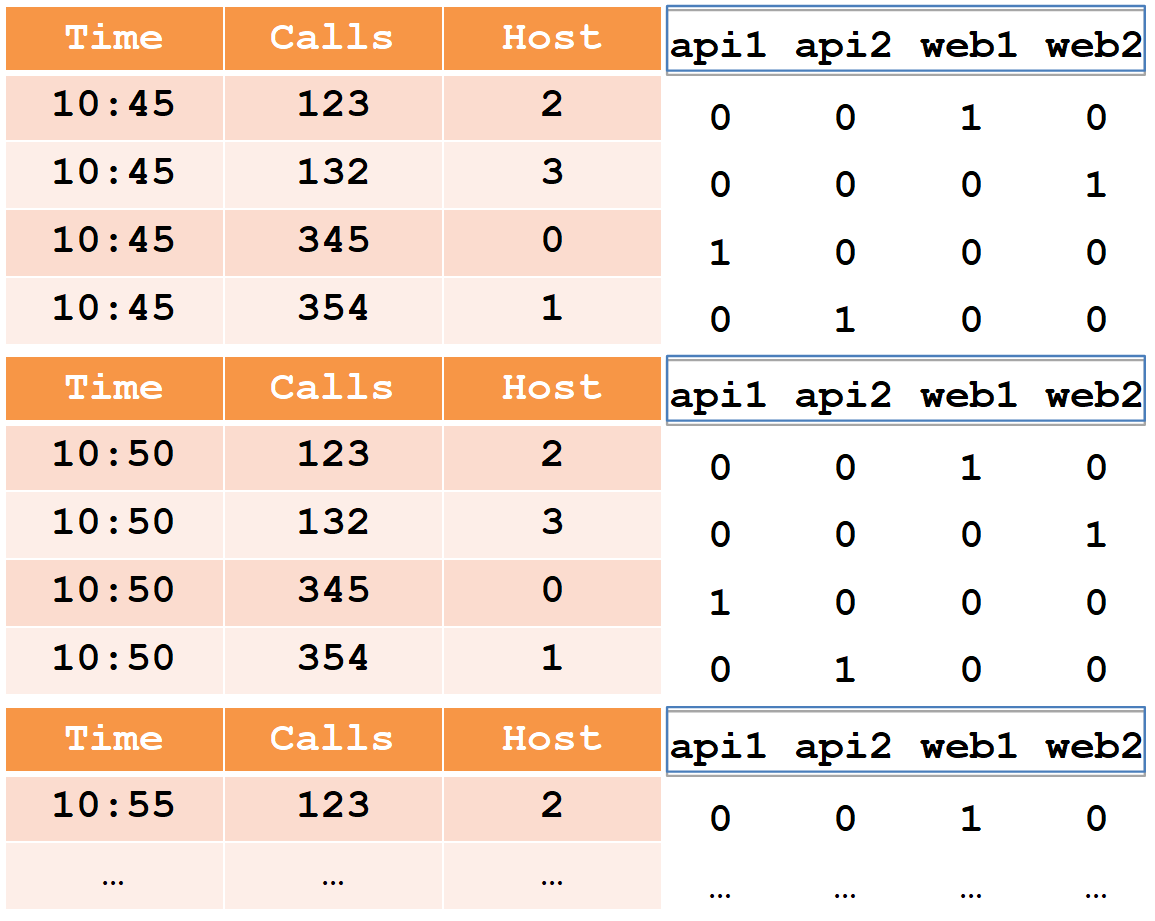 Nous avons commencé à télécharger des données, une partie vidé (à 10:45) sur le disque. Il s'est avéré un mini-segment avec trois colonnes, un dictionnaire et des index bitmap. Nous téléchargeons plus loin, réinitialisons la deuxième partie (à 10:50) sur le disque, encore une fois nous avons un mini-segment.
Nous avons commencé à télécharger des données, une partie vidé (à 10:45) sur le disque. Il s'est avéré un mini-segment avec trois colonnes, un dictionnaire et des index bitmap. Nous téléchargeons plus loin, réinitialisons la deuxième partie (à 10:50) sur le disque, encore une fois nous avons un mini-segment. Et ainsi de suite.
Si nous analysons en parties, nous remarquerons que les colonnes «appels», «temps» et «hôte» dans ces parties ont été coupées proportionnellement.Mais avec le dictionnaire et les index, cela sort différemment. Chaque hôte, une fois toutes les cinq minutes, vide ses données, de sorte que tous les hôtes sont «marqués» dans chaque partie du vidage sur disque. Le dictionnaire est également volumineux, il n'est coupé d'aucune façon et il contient autant d'index. Lors du traitement d'une demande, l'itération dans le dictionnaire et la combinaison de bitmaps (ce qui prend 95% du temps) doit être effectuée pour chacune des parties, de sorte que la dépendance est presque linéaire: plus il y a de parties, plus la demande dure. Ce n'est presque pas visible dans le dictionnaire jusqu'à 100 valeurs, et il deviendra très visible de ralentir lorsqu'il y en a plus de 1000.Que peut-on faire à ce sujet? Vous pouvez contrôler le nombre de pièces vidées sur le disque. Par exemple, si vous avez un segment quotidien et que les requêtes ralentissent dans les nœuds en temps réel, réduisez-le à toutes les heures. Ensuite, le nombre de pièces sera réduit proportionnellement (car les données se déplaceront plus rapidement vers les nœuds historiques et seront supprimées des nœuds en temps réel), et elles ralentiront proportionnellement moins.Il existe également deux paramètres qui vous permettent de contrôler la fréquence de vidage de ces pièces sur le disque: le nombre maximal de lignes en mémoire et l'intervalle de vidage sur le disque. Par exemple, vous pouvez le réinitialiser non pas toutes les cinq minutes, mais toutes les demi-heures. Et pas tous les 100 000 lignes, mais tous les millions. Ensuite, les pièces deviendront plus petites et tout fonctionnera plusieurs fois plus rapidement.Il y a encore un point important. Parfois, 80% du temps passé à filtrer prend un dictionnaire pour parcourir les expressions régulières plutôt que de combiner des bitmaps. Nous ne le savions pas et pendant la migration, tous les filtres ont été créés des expressions régulières. Ce n'est pas nécessaire. Lorsque nous filtrons selon la valeur exacte, nous devons utiliser un filtre du type sélecteur, car il trouvera la valeur souhaitée par recherche binaire et obtiendra immédiatement le bitmap. Cela fonctionne mille fois plus rapidement que l'expression régulière.Optimisation du ruban
Comme vous le savez, dans tout réseau social, il existe un flux d'événements qui recueille le contenu créé par toutes les équipes de développement. Bien sûr, toutes ces équipes veulent regarder et écrire des statistiques. Nous avons des statistiques de bande écrites dans une seule plaque, 8 milliards de lignes par jour. Elle a freiné même en druide. Et le pire, c'est que quand il a ralenti, il a surchargé tout le druide, c'est-à-dire que tout a ralenti pour tout le monde. Dans ces statistiques, il y avait un champ combiné, qui se compose de plusieurs mots reliés par un point. Quelque chose comme ça: Nous pouvons profiter de la photo sur le principal, dans l'album, dans le groupe. Il en va de même pour la vidéo et la musique. Nous pouvons également partager des photos, des vidéos et de la musique sur la page principale, dans l'album et dans le groupe. Et nous pouvons commenter tout. Un total de 27 combinaisons d'événements. En conséquence, le dictionnaire aura 27 lignes, 27 bitmaps.Nous voulons calculer le nombre de likes. Cette requête passe par une expression régulière de 27 valeurs dans le dictionnaire, en sélectionne 9, obtient 9 bitmaps, combine et va compter.Maintenant, coupons-le en trois parties.
Nous pouvons profiter de la photo sur le principal, dans l'album, dans le groupe. Il en va de même pour la vidéo et la musique. Nous pouvons également partager des photos, des vidéos et de la musique sur la page principale, dans l'album et dans le groupe. Et nous pouvons commenter tout. Un total de 27 combinaisons d'événements. En conséquence, le dictionnaire aura 27 lignes, 27 bitmaps.Nous voulons calculer le nombre de likes. Cette requête passe par une expression régulière de 27 valeurs dans le dictionnaire, en sélectionne 9, obtient 9 bitmaps, combine et va compter.Maintenant, coupons-le en trois parties. Le premier est l'action: aimer, partager, commenter. La deuxième partie est un objet: photo, vidéo, musique. La troisième partie est le lieu: sur la principale, dans l'album, dans le groupe. Ensuite, la requête ira dans un seul dictionnaire - une action dans laquelle il n'y a que trois valeurs et trois bitmaps. Pour la pureté de l'expérience, supposons qu'il s'agit également d'une expression régulière. Autrement dit, dans ce cas, il y aura trois expressions régulières, et dans la précédente il y en avait 27. Il y avait 9 bitmaps, maintenant il y en a une. En conséquence, nous avons réduit la réussite du dictionnaire et la combinaison de bitmaps (ce qui prend 95% du temps) de 9 fois. Et nous venons de couper un dictionnaire de 27 lignes en trois.En réalité, nous avions 14 000 combinaisons. En conséquence, dans notre dictionnaire, il y avait 14 000 valeurs et 14 000 bitmaps. Par conséquent, lorsque nous avons coupé ce champ en petites parties selon les mots, la vitesse des statistiques sur bande a été multipliée par 10 et la taille des données a été divisée par deux. Maintenant, tout fonctionne rapidement.
Le premier est l'action: aimer, partager, commenter. La deuxième partie est un objet: photo, vidéo, musique. La troisième partie est le lieu: sur la principale, dans l'album, dans le groupe. Ensuite, la requête ira dans un seul dictionnaire - une action dans laquelle il n'y a que trois valeurs et trois bitmaps. Pour la pureté de l'expérience, supposons qu'il s'agit également d'une expression régulière. Autrement dit, dans ce cas, il y aura trois expressions régulières, et dans la précédente il y en avait 27. Il y avait 9 bitmaps, maintenant il y en a une. En conséquence, nous avons réduit la réussite du dictionnaire et la combinaison de bitmaps (ce qui prend 95% du temps) de 9 fois. Et nous venons de couper un dictionnaire de 27 lignes en trois.En réalité, nous avions 14 000 combinaisons. En conséquence, dans notre dictionnaire, il y avait 14 000 valeurs et 14 000 bitmaps. Par conséquent, lorsque nous avons coupé ce champ en petites parties selon les mots, la vitesse des statistiques sur bande a été multipliée par 10 et la taille des données a été divisée par deux. Maintenant, tout fonctionne rapidement.Priorités de demande
Mais voici que vient l'utilisateur et veut voir les statistiques de l'année, c'est 2 To. Sur notre cluster, vous devez lever 11 Go à partir du disque, cela prendra 74 secondes. L'utilisateur sait qu'il demande des données lourdes et est prêt à attendre. Mais que feront les autres utilisateurs ces 74 secondes? Pour le dire doucement, ils seront nerveux et demanderont pourquoi les graphiques ne fonctionnent pas.Druid vous permet de prioriser les demandes. Nous avons essayé de réduire la priorité pour les données lourdes, c'est devenu plus facile, mais cela a quand même ralenti, car les priorités fonctionnent au niveau de la file d'attente. Cela signifie que si une partie de la lourde demande a déjà été traitée, tout le monde devra attendre. Ensuite, les requêtes légères et rapides progressent, et les requêtes lourdes prennent à nouveau toutes les ressources. On a le sentiment que le système travaille dur, à la limite.Nous avons profité du fait que Druid dispose de toutes les informations sur la demande et les données. Ils ont implémenté une hiérarchisation simple, qui définit la priorité pour le nombre (en mégaoctets) de données que cette demande va transmettre. Dans le même temps, nous avons fait 5 files d'attente: une pour les demandes les plus difficiles, une pour les plus légères et trois intermédiaires. Ils ont dispersé les demandes de priorité calculée. Chaque file d'attente a une priorité au niveau du système d'exploitation (définie par des moyens standard et des paramètres java), de sorte que les demandes rapides évincent les demandes lourdes. Maintenant, enfin, Druid a gagné comme vous l'attendez.Résumé
Nous avons implémenté un système rapide, tolérant aux pannes et distribué au lieu de SQL Server, et n'avons pas donné plusieurs millions de dollars à Microsoft.Nous avons obtenu une évolutivité horizontale facile, il vous suffit d'ajouter des disques et / ou des serveurs selon vos besoins.Nous avons obtenu une grande marge de performance pour l'insertion de données et de requêtes, et la possibilité de détailler nos statistiques par ordre de grandeur.Actuellement, nous avons plus de 20 tableaux, dont chacun écrit plus d'un milliard de lignes par jour, le plus grand écrit 18 milliards de lignes par jour.Notre druide est presque entièrement transféré vers un cloud ( https://habr.com/company/odnoklassniki/blog/346868/ ), ce qui simplifie encore plus le processus de mise à l'échelle.